SPARK-SQL-2.4算子api文档:
https://spark.apache.org/docs/2.4.0/api/sql/
SPARK-SQL最新算子api文档:
https://spark.apache.org/docs/latest/api/sql/
grouging_sets、rollup、cube
organization,appid,serviceid,eventid grouping_id = 0 0 0 0 0
organization,serviceid,eventid grouping_id = 4 0 0 1 0
organization,appid grouping_id = 3 1 1 0 0
organization grouping_id = 7 1 1 1 0
select
organization,
if(app_id is null and (grouping_id=4 or grouping_id=7),’all’,app_id) app_id,
if(serviceid is null and (grouping_id=3 or grouping_id=7),’all’,serviceid) service_id,
if(eventid is null and (grouping_id=3 or grouping_id=7),’all’,eventid) event_id,
day_risk_cnt,
day_active_cnt
from
(select
organization,
appid,
serviceid,
eventid,
count(distinct(if(risklevel=’REJECT’,tokenid,null))) as day_risk_cnt,
count(distinct(tokenid)) day_active_cnt,
grouping_id() as grouping_id
from xuanzhiangtest3
group by organization,appid,serviceid,eventid
grouping sets(
(organization,appid,serviceid,eventid),
(organization,serviceid,eventid),
(organization,appid),
(organization))
)
select
organization,
if(appid is null and (grouping_id()=4 or grouping_id()=7),’all’,appid) app_id,
if(serviceid is null and (grouping_id()=3 or grouping_id()=7),’all’,serviceid) service_id,
if(eventid is null and (grouping_id()=3 or grouping_id()=7),’all’,eventid) event_id,
count(distinct(if(risklevel=’REJECT’,tokenid,null))) as day_risk_cnt,
count(distinct(tokenid)) day_active_cnt
from xuanzhiangtest3
group by organization,appid,serviceid,eventid
grouping sets(
(organization),
(organization,appid),
(organization,serviceid,eventid),
(organization,appid,serviceid,eventid)
)
spark-sql中grouping_sets如何计算得出grouping_id
聚合语句:
select
organization,
if(app_id is null and (grouping_id=1 or grouping_id=7),’all’,app_id) app_id,
if(serviceid is null and (grouping_id=1 or grouping_id=3),’all’,serviceid) service_id,
if(eventid is null and (grouping_id=1 or grouping_id=3),’all’,eventid) event_id,
count(distinct(if(risklevel=’REJECT’,tokenid,null))) as day_risk_cnt
count(distinct(tokenid)) day_active_cnt,
grouping_id() as grouping_id
from xuanzhiangtest3
group by organization,appid,serviceid,eventid
grouping sets(
(organization,appid,serviceid,eventid),
(organization,serviceid,eventid),
(organization,appid),
(organization)
)
order by grouping_id
聚合结果:
+——————————+———-+————-+———-+——————+———————+—————-+
|organization |appid |serviceid|eventid|day_risk_cnt|day_active_cnt|grouping_id|
+——————————+———-+————-+———-+——————+———————+—————-+
|1eFbGOT7fMVhh3YLi4uy|offline|offline |null |1 |1 |0 |
|1Pe5NJspUuFLGSF6lGVy|offline|offline |offline|4 |4 |0 |
|1eFbGOT7fMVhh3YLi4uy|offline|offline |offline|6 |6 |0 |
|1eFbGOT7fMVhh3YLi4uy|offline|null |null |7 |7 |3 |
|1Pe5NJspUuFLGSF6lGVy|offline|null |null |4 |4 |3 |
|1eFbGOT7fMVhh3YLi4uy|null |offline |offline|6 |6 |4 |
|1eFbGOT7fMVhh3YLi4uy|null |offline |null |1 |1 |4 |
|1Pe5NJspUuFLGSF6lGVy|null |offline |offline|4 |4 |4 |
|1Pe5NJspUuFLGSF6lGVy|null |null |null |4 |4 |7 |
|1eFbGOT7fMVhh3YLi4uy|null |null |null |7 |7 |7 |
+——————————+———-+————-+———-+——————+———————+—————-+
得出结果:
spark中对应位置字段出现在groupBy中,则进制赋为0;没有出现则为1
对应字段顺序为groupBy字段顺序。
如语句中groupby为:organization,appid,serviceid,eventid
则对应顺序应为:organization,appid,serviceid,eventid
以groupby字段为准,依次对应聚合纬度出来为(二进制):
organization,appid,serviceid,eventid 0 0 0 0 0
organization,serviceid,eventid 4 0 1 0 0
organization,appid 3 0 0 1 1
organization 7 0 1 1 1
与结果相同
stack
分离n个参数值到n行中
stack(行数,值1,值2….值n)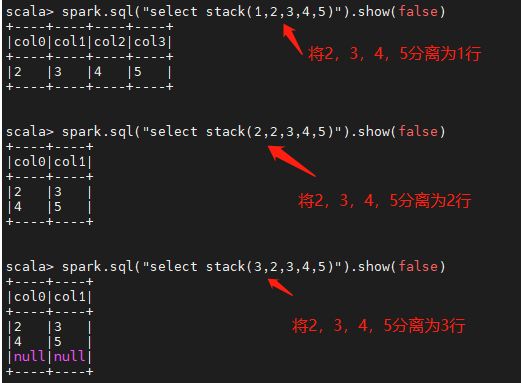

若有收获,就点个赞吧
0 人点赞
