1. 基础架构
1.1 基础知识
1.1.1 基础概念
RDD(Resillient Distributed Dataset):弹性分布式数据集。Spark应用程序通过TransForm算子,可将RDD封装为一系列有血缘关系的RDD,也就是DAG。只有通过action算子才会将RDD及其DAG提交到DAGSchulder。RDD的祖先一定是一个跟数据源相关的RDD,负责从数据源迭代读取数据。
DAG(Directed Acycle Graph):有向无环图。Spark使用DAG反应各RDD之间的血缘关系。
Partition:数据分区,一个RDD的划分分区情况。Spark根据分区数量确定Task数量。
NarrowDependency:窄依赖,即子RDD依赖于父RDD中固定的Partition。窄依赖分为OneToOneDependency和RangeDependency两种。
ShuffleDenpendency:宽依赖,即子RDD对父RDD中的所有Partition都可能产生依赖。子RDD对父RD的Partition依赖取决于分区算法(Partitioner)。
Job:用户提交的作业。当RDD及其DAG被提交到DAGScheduler调度后,DAGScheduler会将所有RDD中的TransForm和Action视为一个Job。一个Job由一到多个Task组成。
Stage:Job的执行阶段。DAGScheduler根据宽依赖算子切分Stage,因此一个Job可能包含一到多个Stage。Stage分为ShuffleMapStage和ResuletStage。
Task:具体执行任务。一个Job的每个Stage内部都会根据RDD的分区数量创建多个Task。Task分为ShuffleMapTask和ResultTask。
Shuffle:Shuffle是所有MR计算框架的核心执行阶段。Shuffle用于打通map任务的输出(ShuffleWrite)和reduce任务的输入(ShuffleRead)。
1.1.2 Spark模块设计
Spark由SparkCore、SparkSQL、SparkStreaming、SparkStucredStreaming、GraphX、Mlib组成,SparkCore为核心引擎。
SparkCore的核心功能:
- 基础设施
- SparkContext
- SparkEnv
- 存储体系
- 调度系统
- 计算引擎
1. 2事件总线(ListenerBus)
Spark定义了一个特质ListenerBus,可以接收事件并且将事件提交到对应事件的监听器。
代码位置:Spark_Core-2.12
主类:org.apache.spark.util.ListenerBus
1.2.1 ListenerBus的继承体系
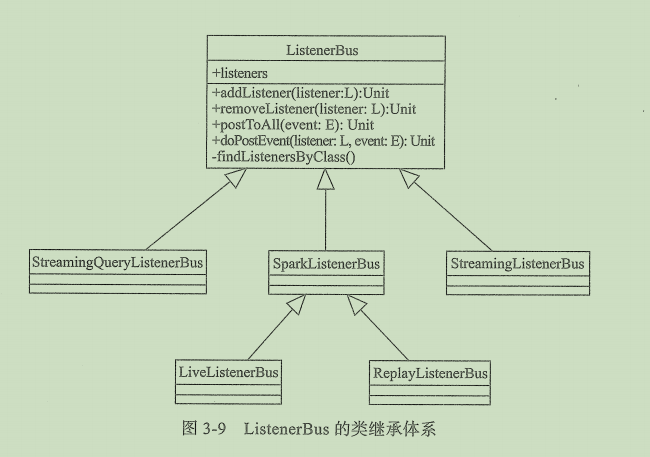
- SparkListenerBus:
- StreamingQueryListenerBus:
- StreamingListnerBus:
1.2.2 LiveListennerBus详解
LiveListennerBus集成了SparkListennerBus,并实现了将事件异步投递给监听器,达到实时刷新Spark-UI数据的效果。
1.3 度量系统
Spark基于第三方度量仓库Metrics构建度量系统的原理和实现。
2. SparkContext的初始化
Spark的运行的第一步就是对SparkContext的初始化,也就是对Driver的初始化,这一步是Spark应用程序提交和执行的前提。
2.1 SparkContext概述
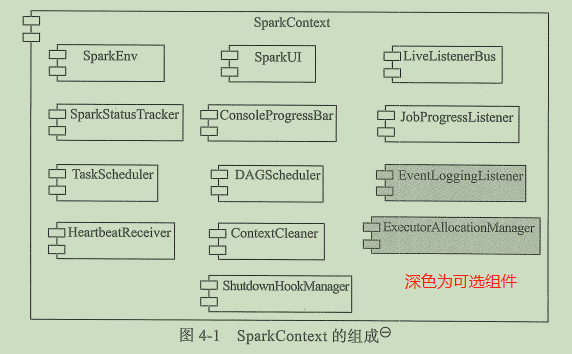
- 创建SparkEnv:初始化Spark基础运行环境
- 创建SparkUI:查看Spark任务运营状态
- 创建HeartBeatReceiver(心跳接收器):监听Executor
- 创建TaskScheduler和DAGScheduler(调度系统):负责请求ClusterManager分配并运行Executor(一级调度)和给任务分配Executor并运行任务(二级调度)。DAGScheduler负责包括创建Job、将DAG中的RDD划分到不同的Stage、提交Stage等。
- 创建和启动ExecutorAllocationManager(动态资源管理器):基于工作负载动态分配和删除Executor 的代理。
- 初始化BlockManager(块管理器):存储系统的核心
- 启动度量系统(Metrics)
创建事件日志监听器(EventLoggingListenner):将事件持久化到存储的监听器,可选组件
2.2 序列化管理器(SerializerManager)
Spark中很多对象在通过网络传输或者写入存储体系事,都需要序列化。
2.2.1 序列化管理器的属性
序列化管理器给各种Spark组件提供序列化、压缩和加密的服务。
其成员属性:- defaultSerializer:默认的序列化器,默认为JavaSerializer
- conf:即SparkConf
- encryptionKey:加密密钥
- kryoSerializer:Spark提供的一种序列化器。
- stringClassTag:字符串类型标记,即ClassTag[String]
- primitiveAndPrimitiveArrayClassTags:原生类型及原生类型数组的类型标记的集合
- compressBroadcast:是否对广播对象进行压缩,通过spark.broadcast.compress配置,默认true
- compressShuffle:是否对Shuffle输出数据压缩,通过spark.shuffle.compress配置,默认true
- compressRdds:是否对RDD压缩,通过spark.rdd.shuffle配置,默认false
- compressShuffleSpill:是否对溢出到磁盘的shuffle数据压缩,通过spark.shuffle.spill.compress配置,默认为true
- compressionCodec:序列化管理器使用的压缩编解码器。
2.2.2 序列化管理器的方法
序列化管理器提供了很多用于序列化、反序列化、压缩、加密的方法。2.3 广播管理器(BroadcastManager)
广播管理器用于将配置信息和序列化后的RDD、Job及ShuffleDependency等信息在本地存储,为了容灾,也会复制到其他节点上。
BroadcastManager最终生成TorrentBroadcast实例,包含以下属性:
- compressionCodec:用于广播对象的压缩接编码器,通过spark.broadcast.compress配置,默认为true
- blockSize:块大小,通过spark.broadcast.blocksize配置,默认4M
- broadcastId:广播ID,实际是样例类BroadcastBlockID,通过原子变量nextBroadcastId自增产生
- checksumEnabled:是否给广播块生成校验和,通过spark.broadcast.checksum配置,默认为true
- checksums:用于存储每个广播块的校验和的数组
- numBlocks:广播变量包含的块数量,通过writeBlocks获得,在构造TorrentBroadcast实例时调用writeBlocks方法将广播对象写入存储体系
_value:从Executor或Driver上读取的广播块的值
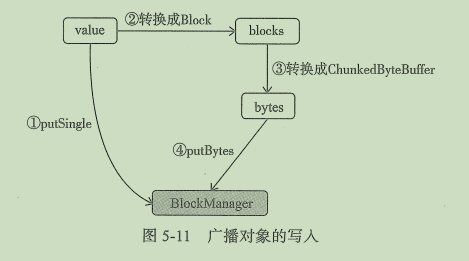
2.3.1 广播对象的写操作
在构造TorrentBroadcast实例时调用writeBlocks方法将广播对象写入存储体系。
writeBlocks的执行步骤如下:- 获取当前SparkEnv的BlockManager组件。
- 调用BlockManager的putSingle方法将广播对象写入本地的存储体系,默认存储等级为MEMORY_AND_DISK,因为只会写入Driver或Executor 的本地存储体系。
- 调用TorrentBroadcast的blockifyObject方法,将对象转换为一系列的块,使用当前SparkEnv中的JavaSerializer组件进行序列化,使用TorrentBroadcast自身的compressionCodec进行压缩。
- 如果需要给分片广播块生成校验和,则创建和上一步转换块数量一致的checksums数组
- 调用BlockManager的putBytes方法将分片广播块以序列化方法写入Driver本地存储体系,默认存储等级为MEMORY_AND_DISK_SER,只会写入Driver或Executor 的本地存储体系。
- 返回块的数量。
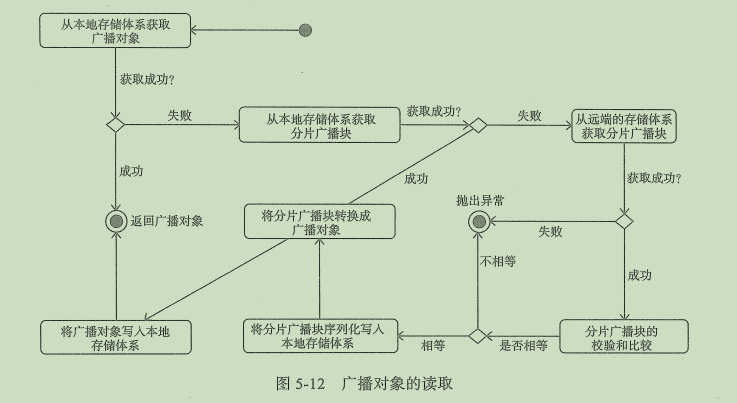
2.3.2 广播对象的读操作
只有在TorrentBroadcast实例的_value在需要时,才会调用readBroadcastBlock方法获取值。
readBroadcastBlock实现步骤如下:
1. 获取当前SparkEnv的BlockManager组件1. 调用BlockManager的getLocalValues方法从本地的存储系统中获取广播对象1. 如果从本地存储体系获取广播对象,则调用releaseLock方法释放锁并返回广播对象(这个锁保证当块被一个运行中的任务使用时,不能被其他任务再次使用,当任务运行完成即释放锁)1. 如果从本地存储体系中没有获取广播对象,那么说明数据是通过BlockManager的putBytes方法以序列化方式写入存储体系的。此时首先调用readBlocks方法从Driver或Executor的存储体系中获取广播块,然后将一系列的分片广播块转换回原来的广播对象,再写入本地存储体系,以便当前Executor 的其他任务不用再次获取广播对象。
2.3.3 广播对象的去持久化
最终调用BlockManagerMaster的removeBroadcast方法对由id标记的广播对象去持久化。
2.4 Map任务输出跟踪器
mapOutputTracker用于跟踪map任务的输出状态,此状态便于reduce任务定位map输出结果所在的节点地址,进而获取中间输出结果。每个map任务或者reduce任务都会有其唯一标识,分别为mapID和reduceID。每个reduce任务的输入可能是多个map,reduce会到多个map任务所在的节点拉取block,这个过程叫shuffle。每次shuffle都有唯一的标识shuffleId。

若有收获,就点个赞吧
0 人点赞
