语义分割在cv中的定义:
宏观上,指的是识别并分割出图像中的各部分内容;微观上,语义分割应当完成对每个像素的分类任务,例如在下图中,有的像素分到“人”类(输出部分的红色),有的分为“摩托”类,剩余不必关注的在“背景”类。
cv中语义分割分出了“人”和“摩托”两个关键要素
FCN:
(在很久之前zck介绍反卷积时提到过。。。
FCN的目标是建立像素到像素的映射,而CNN只需要输出图片分类。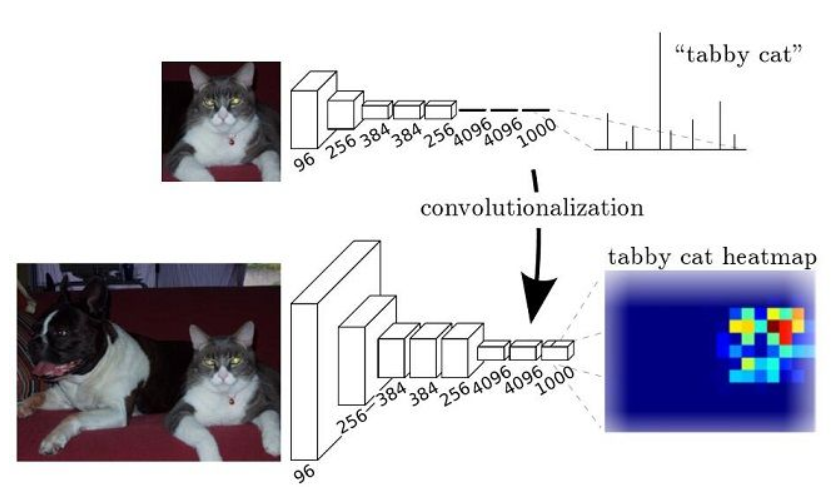
图上半部分是 CNN 网络,下半部分是FCN 网络
整个FCN网络基本原理示意图: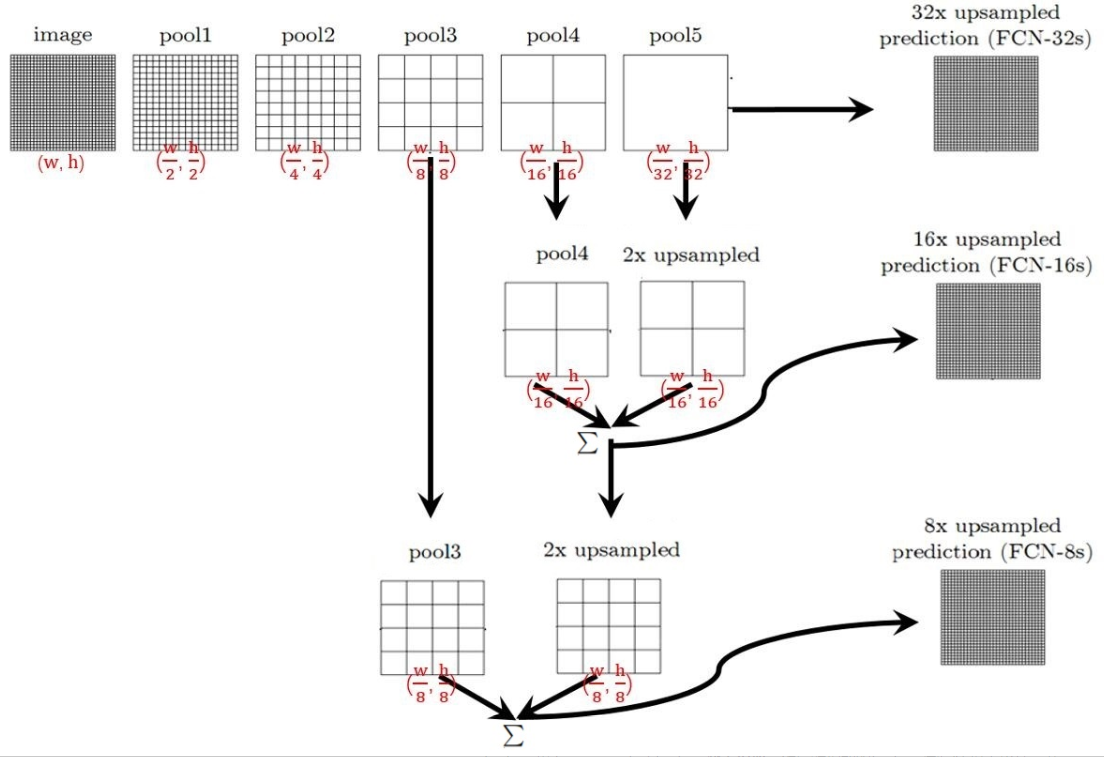
FCN网络结构示意图
image经过多个conv和+一个max pooling变为pool1 feature,宽高变为1/2
pool1 feature再经过多个conv+一个max pooling变为pool2 feature,宽高变为1/4
pool2 feature再经过多个conv+一个max pooling变为pool3 feature,宽高变为1/8
……
直到pool5 feature,宽高变为1/32。
对于FCN-32s(FCN网络的一种),直接对pool5 feature进行32倍上采样(上采样的其中一种方式就是反卷积)获得32x upsampled feature,再对32x upsampled feature每个点做softmax prediction获得32x upsampled feature prediction(即分割图)。
对于FCN-16s,首先对pool5 feature进行2倍上采样获得2x upsampled feature,再把pool4 feature和2x upsampled feature逐点相加,然后对相加的feature进行16倍上采样,并softmax prediction,获得16x upsampled feature prediction。
对于FCN-8s,首先进行pool4+2x upsampled feature逐点相加,然后又进行pool3+2x upsampled逐点相加,即进行更多次特征融合。具体过程与16s类似,不再赘述。
作者在原文中给出3种网络结果对比,明显可以看出效果:FCN-32s < FCN-16s < FCN-8s,即使用多层feature融合有利于提高分割准确性。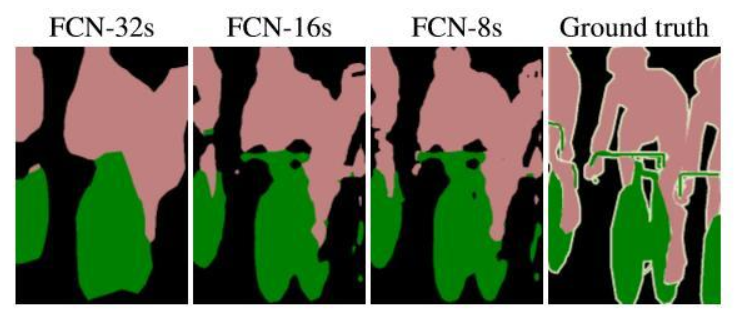
参考:https://zhuanlan.zhihu.com/p/31428783
想法:
可以利用语义分割减少计算量,因为分割后分为background的像素不再参与计算。
具体的思路和tx在注意力机制的笔记中的最后第二点一致:
https://nova.yuque.com/reid/progress/qs2zsc
通过将深层的粗略分割对浅层的训练进行引导,可以精准计算有效内容而略去无关的背景。

若有收获,就点个赞吧
0 人点赞
