网络参数选择总原则

评价标准
对未见过数据的预测 (把现有数据分割,一部分训练,一部分预测)
# %25测试数据,%75训练数据x_train = x[:int(len(x)*0.75)] #自动从头开始,:前是开始位置,:后是结束位置x_test = x[int(len(x)*0.75):]y_train = y[:int(len(x)*0.75)]y_test = y[int(len(x)*0.75):]
欠拟合
小规模数据使用小的网络规模可能效果还不错。
再减小网络规模,产生了信息传递瓶颈,引起了欠拟合。
model = keras.Sequential()model.add(layers.Dense(4, input_dim=15, activation='relu'))model.add(layers.Dense(1, activation='relu'))model.add(layers.Dense(1, activation='sigmoid'))model.compile(optimizer='adam',loss='binary_crossentropy',metrics=['acc'])history = model.fit(x_train, y_train, epochs=1000, validation_data=(x_test, y_test))
过拟合
在训练数据正确率非常高, 在测试数据上比较低。
model = keras.Sequential()model.add(layers.Dense(128, input_dim=15, activation='relu'))model.add(layers.Dense(128, activation='relu'))model.add(layers.Dense(128, activation='relu'))model.add(layers.Dense(1, activation='sigmoid'))model.compile(optimizer='adam',loss='binary_crossentropy',metrics=['acc'])# 训练模型的同时测试数据history = model.fit(x_train, y_train, epochs=1000, validation_data=(x_test, y_test))plt.plot(history.epoch, history.history.get('val_acc'), c='r', label='val_acc')plt.plot(history.epoch, history.history.get('acc'), c='b', label='acc')plt.legend() # 添加图例
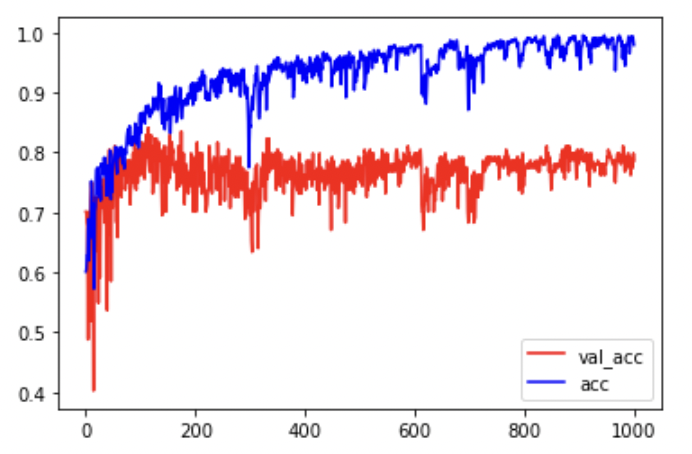
# 训练数据模型评价model.evaluate(x_train, y_train)

# 测试数据模型评价model.evaluate(x_test, y_test)

解决过拟合
Dropout
- 取平均的作用:先回到标准的模型即没有dropout,我们用相同的训练数据去训练5个不同的神经网络,一般会得到5个不同的结果,此时我们可以采用 “5个结果取 均值”或者“多数取胜的投票策略”去决定最终结果。
- 减少神经元之间复杂的共适应关系:因为dropout 程序导致两个神经元不一定每次都在一个dropout网络中出现。这样权值的更新不再依赖于有固定关系的隐含节点的共同作用,阻止了某些特征仅仅在其它特定特征下才有效果的情况 。
- 物种为了生存往往会倾向于适应这种环境,环境突变则会导致物 种难以做出及时反应,性别的出现可以繁衍出适应新环境的变种,有效的阻止过拟合,即避免环境改变时物种可能面临的灭绝
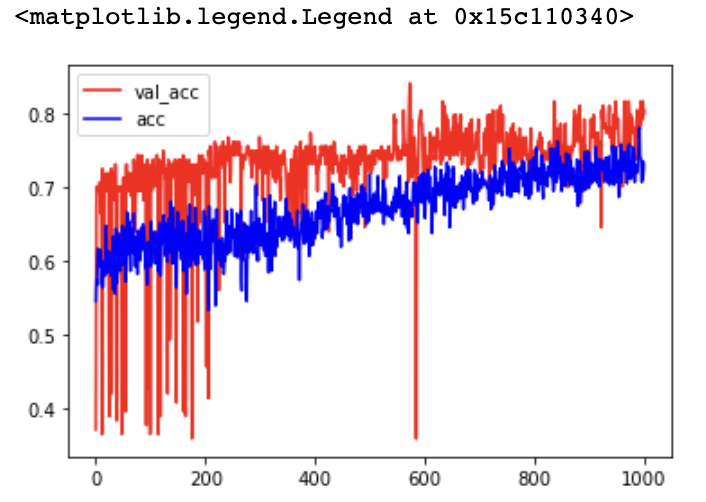
model = keras.Sequential()model.add(layers.Dense(128, input_dim=15, activation='relu'))# 0.5:随机舍弃一半的神经元model.add(layers.Dropout(0.5))model.add(layers.Dense(128, activation='relu'))model.add(layers.Dropout(0.5))model.add(layers.Dense(128, activation='relu'))model.add(layers.Dropout(0.5))model.add(layers.Dense(1, activation='sigmoid'))model.summary()

model.compile(optimizer='adam',loss='binary_crossentropy',metrics=['acc'])history = model.fit(x_train, y_train, epochs=1000, validation_data=(x_test, y_test))
model.evaluate(x_train, y_train)

model.evaluate(x_test, y_test)

plt.plot(history.epoch, history.history.get('val_acc'), c='r', label='val_acc')plt.plot(history.epoch, history.history.get('acc'), c='b', label='acc')plt.legend()
正则化
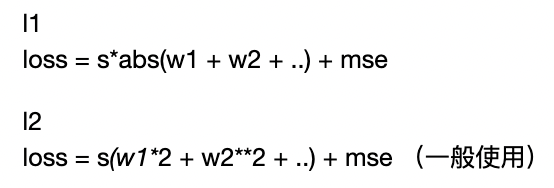
from keras import regularizersmodel = keras.Sequential()# 添加l2正则,参数:mse表示惩罚的力度。model.add(layers.Dense(128, kernel_regularizer=regularizers.l2(0.001), input_dim=15, activation='relu'))model.add(layers.Dense(128, kernel_regularizer=regularizers.l2(0.001), activation='relu'))model.add(layers.Dense(128, kernel_regularizer=regularizers.l2(0.001), activation='relu'))model.add(layers.Dense(1, activation='sigmoid'))model.compile(optimizer='adam',loss='binary_crossentropy',metrics=['acc'])history = model.fit(x_train, y_train, epochs=1000, validation_data=(x_test, y_test))
model.evaluate(x_train, y_train)

model.evaluate(x_test, y_test)


若有收获,就点个赞吧
0 人点赞
