本文由 简悦 SimpRead 转码, 原文地址 www.cnblogs.com
总结
https://www.laruence.com/2020/06/27/5963.html
opcache扩展 将 PHP 代码 预编译生成 Opcode 操作码(字节码,又叫中间码)缓存在共享内存中供以后反复使用,从而避免重复编译,Opcode交给zend vm执行,zend vm是CPU和操作码之间的一层,由zend vm交由CPU执行
JIT (Just In Time)在运行时直接生成编译后的机器码,因此 PHP 可以跳过 Zend VM 并直接被 CPU 执行
jit是否可以代替zend vm?
因为PHP是弱类型语言,所以无法推断类型来提前编译,所以大多是时候还得经过zend vm 处理,那jit有什么用?
为了寻求平衡, PHP 的 JIT 尝试只编译有价值的 Opcodes 。为此, JIT 会分析 Zend VM 要执行的 Opcodes 并检查可能编译的地方(根据配置文件),如果已编译,则 Opcodes 不会通过 Zend VM 执行。
- PHP8的JIT目前是在Opcache之中提供的
- JIT在Opcache优化之后的基础上,结合Runtime的信息再次优化,直接生成机器码
- JIT不是原来Opcache优化的替代,是增强
Opcache
鸟哥在博客中说,提高 PHP 7 性能的几个 tips,第一条就是开启 opcache:
记得启用 Zend Opcache, 因为 PHP7 即使不启用 Opcache 速度也比 PHP-5.6 启用了 Opcache 快, 所以之前测试时期就发生了有人一直没有启用 Opcache 的事情
那么什么是 Opcache 呢?
Opcache 的前生是 Optimizer+ ,它是 PHP 的官方公司 Zend 开发的一款闭源但可以免费使用的 PHP 优化加速组件。 Optimizer+ 将 PHP 代码 预编译生成 Opcode 操作码(**字节码,又叫中间码**) 缓存在共享内存中供以后反复使用,从而避免了从磁盘读取代码再次编译的时间消耗。同时,它还应用了一些代码优化模式,使得代码执行更快。从而加速 PHP 的执行。
PHP 的正常执行流程如下

request 请求(nginx,apache,cli 等)—>Zend 引擎读取.php 文件 —>扫描其词典和表达式 —>解析文件 —>创建要执行的计算机代码 (称为 Opcode)—> 最后执行 Opcode—> response 返回
(计算机只能执行机器码,但是并不是把PHP代码直接转为机器码执行,而是转化为一条条的opcode操作码(字节码,又叫中间码),交给zend vm执行,zend vm是CPU和操作码之间的一层,其实opcode对应的是一个C函数,执行一条opcode就是执行这条opcode对应的C函数)
每一次请求 PHP 脚本都会执行一遍以上步骤,如果 PHP 源代码没有变化,那么 Opcode 也不会变化,显然没有必要每次都重新生成 Opcode,结合在 Web 中无所不在的缓存机制,我们可以把 Opcode 缓存下来,以后直接访问缓存的 Opcode 岂不是更快,
启用 Opcode 缓存之后的流程图如下所示:
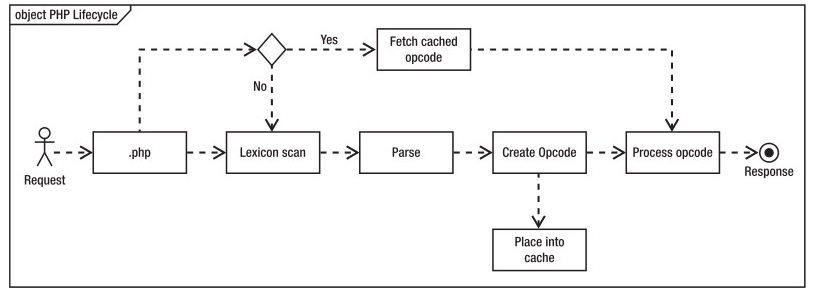
Opcode cache 的目地是避免重复编译,减少 CPU 和内存开销。
Opcache 的安装
安装:
1、找到opcache的扩展,我的是php7.1yum list php71*2、安装扩展yum install php71w-opcache.x86_64
配置:
zend_extension=opcache.so
[opcache]
;开启opcache
opcache.enable=1
;CLI环境下,PHP启用OPcache
opcache.enable_cli=1
;OPcache共享内存存储大小,单位MB
opcache.memory_consumption=128
;PHP使用了一种叫做字符串驻留(string interning)的技术来改善性能。例如,如果你在代码中使用了1000次字符串“foobar”,在PHP内部只会在第一使用这个字符串的时候分配一个不可变的内存区域来存储这个字符串,其他的999次使用都会直接指向这个内存区域。这个选项则会把这个特性提升一个层次——默认情况下这个不可变的内存区域只会存在于单个php-fpm的进程中,如果设置了这个选项,那么它将会在所有的php-fpm进程中共享。在比较大的应用中,这可以非常有效地节约内存,提高应用的性能。
这个选项的值是以兆字节(megabytes)作为单位,如果把它设置为16,则表示16MB,默认是4MB
opcache.interned_strings_buffer=8
;这个选项用于控制内存中最多可以缓存多少个PHP文件。这个选项必须得设置得足够大,大于你的项目中的所有PHP文件的总和。
设置值取值范围最小值是 200,最大值在 PHP 5.5.6 之前是 100000,PHP 5.5.6 及之后是 1000000。也就是说在200到1000000之间。
opcache.max_accelerated_files=4000
;设置缓存的过期时间(单位是秒),为0的话每次都要检查
opcache.revalidate_freq=60
;从字面上理解就是“允许更快速关闭”。它的作用是在单个请求结束时提供一种更快速的机制来调用代码中的析构器,从而加快PHP的响应速度和PHP进程资源的回收速度,这样应用程序可以更快速地响应下一个请求。把它设置为1就可以使用这个机制了。
opcache.fast_shutdown=1
;如果启用(设置为1),OPcache会在opcache.revalidate_freq设置的秒数去检测文件的时间戳(timestamp)检查脚本是否更新。
如果这个选项被禁用(设置为0),opcache.revalidate_freq会被忽略,PHP文件永远不会被检查。这意味着如果你修改了你的代码,然后你把它更新到服务器上,再在浏览器上请求更新的代码对应的功能,你会看不到更新的效果
强烈建议你在生产环境中设置为0,更新代码后,再平滑重启PHP和web服务器。
opcache.validate_timestamps=0
;开启Opcache File Cache(实验性), 通过开启这个, 我们可以让Opcache把opcode缓存缓存到外部文件中, 对于一些脚本, 会有很明显的性能提升.
这样PHP就会在/tmp目录下Cache一些Opcode的二进制导出文件, 可以跨PHP生命周期存在.
opcache.file_cache=/tmp
查看 phpinfo:
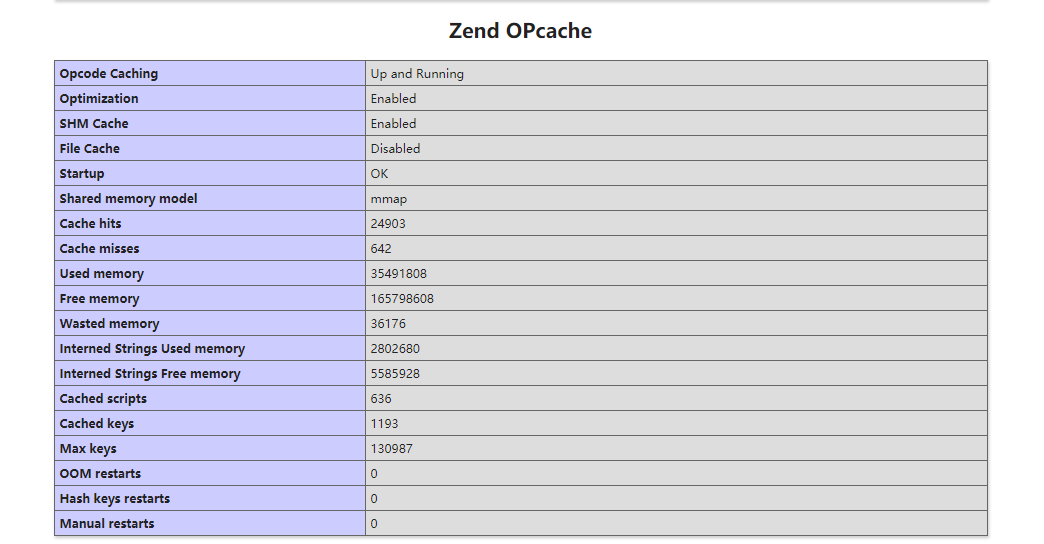
测试结果:

同样的接口从以前的几百毫秒提升到现在的 50ms 左右

PHP 8 JIT
本文由 简悦 SimpRead 转码, 原文地址 www.cnblogs.com
PHP 8 的 JIT
PHP 8 的 JIT(Just In Time)编译器将作为扩展集成到 php 中 Opcache 扩展 用于运行时将某些操作码直接转换为 cpu 指令。
这意味着使用 JIT 后,Zend VM 不需要解释某些操作码,并且这些指令将直接作为 CPU 级指令执行。
PHP 的代码是怎么执行的?
总所周知, PHP 是解释型语言,但这句话本身是什么意思呢?
每次执行 PHP 代码(命令行脚本或者 WEB 应用)时,都要经过 PHP 解释器。最常用的是 PHP-FPM 和 CLI 解释器。
解释器的工作很简单:接收 PHP 代码,对其进行解释,然后返回结果。
一般的解释型语言都是这个流程。有些语言可能会减少几个步骤,但总体的思路相同。在 PHP 中,这个流程如下:
- 读取 PHP 代码并将其解释为一组称为 Tokens 的关键字。这个过程让解释器知道各个程序都写了哪些代码。 这一步称为 Lexing 词法分析 或 Tokenizing 分词。
- 拿到 Tokens 集合以后,PHP 解释器将尝试解析他们。通过称之为 Parsing 解析 的过程生成抽象语法树(AST)。这里 AST 是一个节点集表示要执行哪些操作。比如,「 echo 1 + 1 」实际含义是 「打印 1 + 1 的结果」 或者更详细的说 「打印一个操作,这个操作是 1 + 1」
- 有了 AST ,可以更轻松地理解操作和优先级。将抽象语法树转换成可以被 CPU 执行的操作需要一个用于过渡的表达式 (IR),在 PHP 中我们称之为 Opcodes 操作码。将 AST 转换为 Opcodes 的过程称为 compilation 编译
- 有了 Opcodes ,有趣的部分就来了: executing 执行 代码! PHP 有一个称为 Zend VM 的引擎,该引擎能够接收一系列 Opcodes 并执行它们。执行所有 Opcodes 后, Zend VM 就会将该程序终止
这个图可以让你更清楚:
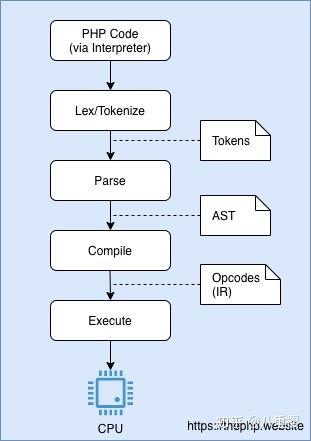
一个简化版的 PHP 解释流程概述。
即使 PHP 代码没改变,每次执行还是会走此流程吗?
让我们看回 Opcodes 。对了!这就是 Opcache 扩展 存在的原因。
Opcache 扩展
Opcache 扩展是 PHP 附带的,通常没必要停用它。使用 PHP 最好打开 Opcache 。
它的作用是为 Opcodes 添加一个内存共享缓存层。它的工作是从 AST 中提取新生成的 Opcodes 并缓存它们,以便执行时
可以跳过 Lexing/Tokenizing 和 Parsing 步骤。
这是包含 Opcache 扩展的流程示意图:
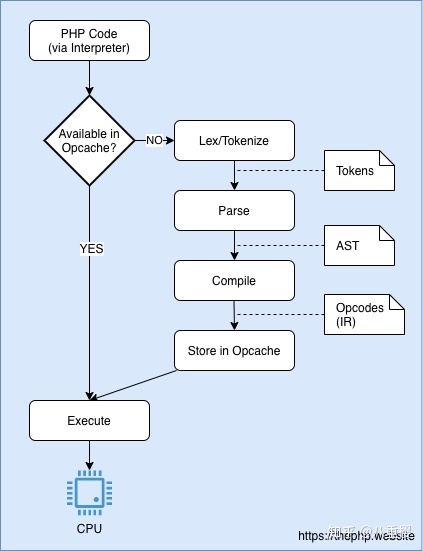
如果文件已经被解析,则 PHP 会为其获取缓存的 Opcodes ,而不是再次解析。
完美的跳过了 Lexing/Tokenizing 、 Parsing 和 Compiling 步骤 。
旁注: 这是超赞的 PHP 7.4 预加载功能 RFC ! 允许你告诉 PHP FPM 解析代码库,将其转换为 Opcodes 并且在执行之前就将其缓存。
你想知道 JIT 是怎么参与这个解释流程的吗?这篇文章的将说明。
Just In Time 编译有什么效果?
听了 Zeev 在 PHP Internals News 发表的 PHP 和 JIT 广播 之后,我弄清了 JIT 实际做了什么事情。
如果说 Opcache 扩展可以更快的获取 Opcodes 将其直接转到 Zend VM,则 JIT 让它们完全不使用 Zend VM 即可运行。
Zend VM 是用 C 编写的程序,充当 Opcodes 和 CPU 之间的一层。 JIT 在运行时直接生成编译后的代码,因此 PHP 可以跳过 Zend VM 并直接被 CPU 执行。 从理论上说,性能会更好。
这听起来很奇怪,因为在编译成机器码之前,需要为每种类型的结构体编写一个具体的实现。但实际上这也是合理的。
PHP 的 JIT 使用了名为 DynASM (Dynamic Assembler) 的库,该库将一种特定格式的一组 CPU 指令映射为许多不同 CPU 类型的汇编代码。因此,编译器只需要使用 DynASM 就可以将 Opcodes 转换为特定结构体的机器码。
但是,有一个问题困扰了我很久。
如果预加载能够在执行之前将 PHP 代码解析为 Opcodes,并且 DynASM 可以将 Opcodes 编译为机器码 (Just In Time 编译) ,为什么我们不立即使用运行前编译 (Ahead of Time 编译) 立即编译 PHP 呢?
通过收听 Zeev 的广播,我找到的原因之一就是 PHP 是弱类型语言,这意味着在 Zend VM 尝试执行某个操作码之前, PHP 通常不知道变量的类型。
可以查看 Zend_value 联合类型 得知,很多指针指向不同类型的变量。每当 Zend VM 尝试从 Zend_value 获取值时,它都会使用像 ZSTR_VAL 这样的宏,获取联合类型中字符串的指针。
例如,这个 Zend VM handler 是处理「小于或等于」(<=) 表达式。看看它编码这么多的 if else 分支,只是为了类型推断。
使用机器码执行类型推断逻辑是不可行的,并且可能变得更慢。
先求值再编译也不是一个好选择,因为编译为机器码是 CPU 密集型任务。因此,在运行时编译所有内容也不好。
那么 Just In Time 编译是怎么做的?
现在我们知道无法很好的推断类型来提前编译。我们也知道在运行时进行编译的运算成本很高。那么 JIT 对 PHP 有何好处呢?
为了寻求平衡, PHP 的 JIT 尝试只编译有价值的 Opcodes 。为此, JIT 会分析 Zend VM 要执行的 Opcodes 并检查可能编译的地方。(根据配置文件)
当某个 Opcode 编译后,它将把执行交给该编译后的代码,而不是交给 Zend VM 。看起来如下:
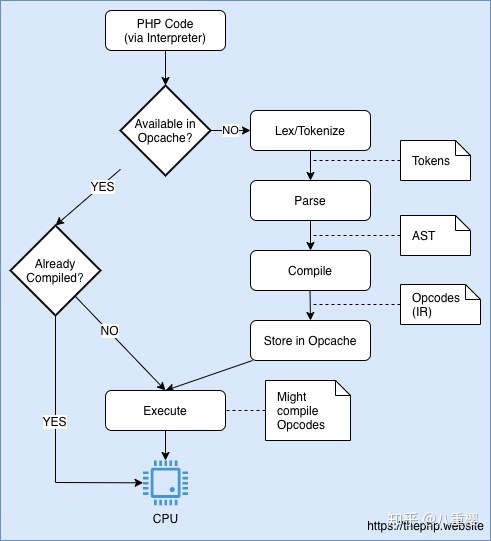
PHP 的 JIT 解释流程。如果已编译,则 Opcodes 不会通过 Zend VM 执行。
因此,在 Opcache 扩展中,有两条检测指令判断要不要编译 Opcode 。如果要,编译器将使用 DynASM 将此 Opcode 转换为机器码,并执行此机器码。
有趣的是,由于当前接口中编译的代码有 MB 的限制 (也是可配置的),所以代码执行必须能够在 JIT 和解释代码之间无缝切换。
顺便说一句,Benoit Jacquemont 在 php 的 JIT 上的这篇演讲帮助我理解了这整件事。
我仍然不确定编译部分什么时候有效进行,但我想现在我真的不想知道。
所以你的性能收益可能不会很大
我希望现在大家都很清楚为什么大多数 php 应用程序不会因为使用即时编译器而获得很大的性能收益。这也是为什么 Zeev 建议为你的应用程序分析和试验不同的 JIT 配置是最好的方法。
如果您使用的是 PHP FPM,则通常会在多个请求之间共享已编译的操作码,但这仍然不能改变游戏规则。
这是因为 JIT 优化了计算密集型的操作,而如今大多数 php 应用程序比其他任何东西都更受 I/O 约束。如果您无论如何都要访问磁盘或网络,则处理操作是否已编译则无关紧要。时间上将非常相似。
除非…
你正在做一些不受 I/O 约束的事情, 像图像处理或机器学习。 任何不接触 I/O 的东西都将受益于 JIT 编译器。
这也是为什么现在人们说我们更愿意用 PHP 编写原生功能而不是 C 编写的原因。 如果仍然要编译此功能,则开销将毫无表现力。

若有收获,就点个赞吧
0 人点赞
