六 正则表达式
简介

模式修正符号:
i 不区分大小写
m 字符串分割,每一行分别匹配
s 修正点的换行
U 取消贪婪模式
x 忽略模式中的空白符
A 必须以这个开头
D $ 对反斜n的忽略
u 中文匹配
e php7已经去掉
正则表达式PCRE函数
PHP中使用PCRE库函数进行正则匹配
<?phppreg_match() — 查找,在第一次匹配后 将会停止搜索,返回0或者1preg_match_all() — 执行一个全局正则表达式匹配,返回全部匹配次数,或者如果发生错误返回FALSE。preg_replace() — 执行一个正则表达式的搜索和替换preg_split() — 通过一个正则表达式分隔字符串preg_quote() — 转义正则表达式字符,会向特殊字符前增加一个反斜线
基本语法
如果字符中包含较多的分割字符,建议更换其他的字符作为分隔符,也可以采用preg_quote进行转义。如:http://www.abc.com/a/b/c/index.html,中就有很多的左斜线,与正则的分隔符冲突了,需要将url中的左斜线进行转义,或者使用其它正则分隔符,如:# ~
分隔符中是元字符,元字符有强大的分割,查找,匹配,替换的能力
分隔符后面可以使用模式修饰符,模式修饰符包括:i, m, s, x等,例如使用i修饰符可以忽略大小写匹配:
<?php
$str = "Http://www.imooc.com/";
if (preg_match('/http/i', $str)) {
echo '匹配成功';
}
元字符
* + ? {n} {n,} {n,m} 共6种为限定符,用来指定正则表达式的一个给定组件必须要出现多少次才能满足匹配。
| \ | 将下一个字符标记为一个特殊字符、或一个原义字符、或一个 向后引用、或一个八进制转义符。例如,’n’ 匹配字符 “n”。’\n’ 匹配一个换行符。序列 ‘\\‘ 匹配 “\“ ,”\(“ 则匹配 “(“。 |
|---|---|
| ^ | 匹配输入字符串的开始位置。也就是匹配的字符串必须以什么开头,不能有其它字符。如果设置了 RegExp 对象的 Multiline 属性,^ 也匹配 ‘\n’ 或 ‘\r’ 之后的位置。 |
| $ | 匹配输入字符串的结束位置。也就是匹配的字符串必须以什么结尾,不能有其它字符。如果设置了RegExp 对象的 Multiline 属性,$ 也匹配 ‘\n’ 或 ‘\r’ 之前的位置。 |
| * | 匹配前面的子表达式零次或多次。例如,zo 能匹配 “z” 以及 “zoo”。 等价于{0,}。 |
| + | 匹配前面的子表达式一次或多次。例如,’zo+’ 能匹配 “zo” 以及 “zoo”,但不能匹配 “z”。+ 等价于 {1,}。 |
| ? | 匹配前面的子表达式零次或一次。例如,”do(es)?” 可以匹配 “do” 或 “does” 。? 等价于 {0,1}。 |
| {n} | n 是一个非负整数。匹配确定的 n 次。例如,’o{2}’ 不能匹配 “Bob” 中的 ‘o’,但是能匹配 “food” 中的两个 o。 |
| {n,} | n 是一个非负整数。至少匹配n 次。例如,’o{2,}’ 不能匹配 “Bob” 中的 ‘o’,但能匹配 “foooood” 中的所有 o。’o{1,}’ 等价于 ‘o+’。’o{0,}’ 则等价于 ‘o*’。 |
| {n,m} | m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。例如,”o{1,3}” 将匹配 “fooooood” 中的前三个 o。’o{0,1}’ 等价于 ‘o?’。请注意在逗号和两个数之间不能有空格。 |
| ? | 当该字符紧跟在任何一个其他限制符 (*, +, ?, {n}, {n,}, {n,m}) 后面时,匹配模式是非贪婪的。非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。例如,对于字符串 “oooo”,’o+?’ 将匹配单个 “o”,而 ‘o+’ 将匹配所有 ‘o’。 |
| . | 匹配除 “\n” 之外的任何单个字符。要匹配包括 ‘\n’ 在内的任何字符,请使用像”(.|\n)“的模式。 |
| (pattern) | 匹配 pattern 并获取这一匹配。所获取的匹配可以从产生的 Matches 集合得到,在VBScript 中使用 SubMatches 集合,在JScript 中则使用 $0…$9 属性。要匹配圆括号字符,请使用 ‘\(‘ 或 ‘\)’。 |
| (?:pattern) | 匹配 pattern 但不获取匹配结果,也就是说这是一个非获取匹配,不进行存储供以后使用。这在使用 “或” 字符 (|) 来组合一个模式的各个部分是很有用。例如, ‘industr(?:y|ies) 就是一个比 ‘industry|industries’ 更简略的表达式。 |
| (?=pattern) | 正向肯定预查(look ahead positive assert),在任何匹配pattern的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如,”Windows(?=95|98|NT|2000)”能匹配”Windows2000”中的”Windows”,但不能匹配”Windows3.1”中的”Windows”。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。 |
| (?!pattern) | 正向否定预查(negative assert),在任何不匹配pattern的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如”Windows(?!95|98|NT|2000)”能匹配”Windows3.1”中的”Windows”,但不能匹配”Windows2000”中的”Windows”。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。 |
| (?<=pattern) | 反向(look behind)肯定预查,与正向肯定预查类似,只是方向相反。例如,”(?<=95|98|NT|2000)Windows”能匹配”2000Windows”中的”Windows”,但不能匹配”3.1Windows”中的”Windows”。 |
| (?<!pattern) | 反向否定预查,与正向否定预查类似,只是方向相反。例如”(?<!95|98|NT|2000)Windows”能匹配”3.1Windows”中的”Windows”,但不能匹配”2000Windows”中的”Windows”。 |
| x|y | 匹配 x 或 y。例如,’z|food’ 能匹配 “z” 或 “food”。’(z|f)ood’ 则匹配 “zood” 或 “food”。 |
| [xyz] | 字符集合。匹配所包含的任意一个字符。例如, ‘[abc]’ 可以匹配 “plain” 中的 ‘a’。 |
| [^xyz] | 负值字符集合。匹配未包含的任意字符。例如, ‘[^abc]’ 可以匹配 “plain” 中的’p’、’l’、’i’、’n’。 |
| [a-z] | 字符范围。匹配指定范围内的任意字符。例如,’[a-z]’ 可以匹配 ‘a’ 到 ‘z’ 范围内的任意小写字母字符。 |
| [^a-z] | 负值字符范围。匹配任何不在指定范围内的任意字符。例如,’[^a-z]’ 可以匹配任何不在 ‘a’ 到 ‘z’ 范围内的任意字符。 |
| \b | 匹配一个单词边界,也就是指单词和空格间的位置。例如, ‘er\b’ 可以匹配”never” 中的 ‘er’,但不能匹配 “verb” 中的 ‘er’。 |
| \B | 匹配非单词边界。’er\B’ 能匹配 “verb” 中的 ‘er’,但不能匹配 “never” 中的 ‘er’。 |
| \d | 匹配一个数字字符。等价于 [0-9]。 |
| \D | 匹配一个非数字字符。等价于 [^0-9]。 |
| \n | 匹配一个换行符。等价于 \x0a 和 \cJ。 |
| \r | 匹配一个回车符。等价于 \x0d 和 \cM。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。 |
| \S | 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 |
| \w | 匹配字母、数字、下划线。等价于’[A-Z a-z 0-9_]’。 |
| \W | 匹配非字母、数字、下划线。等价于 ‘[^A-Za-z0-9_]’。 |
| \num | num为正整数。对所获取的匹配的引用。例如,’(.)\1’ 匹配两个连续的相同字符。 |
| \n | 标识一个八进制转义值或一个向后引用。如果 \n 之前至少 n 个获取的子表达式,则 n 为向后引用。否则,如果 n 为八进制数字 (0-7),则 n 为一个八进制转义值。 |
| i | 是指忽略大小写,注意仅是忽略大小写,并不忽略全半角。 |
后向引用
对一个正则表达式模式或部分模式两边添加圆括号将导致相关匹配存储到一个临时缓冲区中,所捕获的每个子匹配都按照在正则表达式模式中从左到右出现的顺序存储。缓冲区编号从 1 开始,最多可存储 99 个捕获的子表达式。每个缓冲区都可以使用 \n访问,其中 n 为一个标识特定缓冲区的一位或两位十进制数。
可以使用非捕获元字符 ?:、?= 或 ?! 来重写捕获,忽略对相关匹配的保存。
反向引用的最简单的、最有用的应用之一,是查找文本中两个相同的相邻单词的匹配项
例子
<?php
// .*在str中匹配到的是第一个b和最后一个闭合b标签的内容,preg_replace函数会替换str为第一个b和最后一个闭合b标签的内容,也就是abc</b><b>def</b><b>qwe
$str = '<b>abc</b><b>def</b><b>qwe</b>';
$pattern = '/<b>(.*)<\/b>/';
// preg_replace第一个参数是要搜索的模式,第二个参数为要替换的内容:\\1,表示替换str在正则pattern中匹配到的第一个项,第三个参数是要搜索替换的目标
$a=preg_replace($pattern, '\\1', $str);
echo '<pre>';
var_dump($a);//abc</b><b>def</b><b>qwe
echo '</pre>';
// .*?在str中匹配到的第一个值是第一个b标签的内容abc,符合条件会执行多次替换,所以最后,会取出所有的b标签的内容
$pattern2 = '/<b>(.*?)<\/b>/';
$a2=preg_replace($pattern2, '\\1', $str);
echo '<pre>';
var_dump($a2);//abcdefqwe
echo '</pre>';
die;
贪婪模式
通过在 *、+ 或 ? 限定符之后放置 ?,该表达式从”贪心”表达式转换为”非贪心”表达式或者最小匹配。
实例
139开头的11位手机号码的正则表达式
//^字符串以139开头,如果在139前面加一个其它字符就不符合要求,\d数字字符,{8}出现8次,$结束位置,结尾必须符合139开头加8个数字,结尾不能有其它字符
<?php
$str = '13988888888';
$pattern = '/^139\d{8}$/';
preg_match($pattern, $str, $match);
print_r($match);
匹配所有img标签中的src的值
<?php
$str = '<img alt="高清" id="button" src="av.jpg" />';
//匹配多个img, . 匹配除 "\n" 之外的任何单个字符,*匹配前面的子表达式零次或多次,.*是贪婪模式,匹配更多的符合要求的,
//因为<img前面或许还有其它标签,所以这里不写字符串开始符^
// i忽略大小写
// (.*?),使用括号会将其存储到一个临时缓冲区中
// \/?> ,\/转义/>结束标签中的左斜线,/?>,有的结束标签中不一定写的/,只是以一个>结束,所以这里使用问号匹配0次或一次
$pattern = '/<img.*src="(.*?)".*?\/?>/i';
//匹配一个img,当?紧跟在任何一个其他限制符后面是,匹配模式是非贪婪的,尽可能匹配少的,0次或1次
$pattern2 = '/<img.*?src="(.*?)".*? \/?>/i';
preg_match($pattern2, $str, $match);
var_dump($match);
$match[1]就是图片的src属性
邮件
实例1、只允许英文字母、数字、下划线、英文句号、以及中划线- 组成
举例:kiki-9047@163.com
分析邮件名称部分:
26个大小写英文字母表示为a-zA-Z
数字表示为0-9
下划线表示为_
中划线表示为-
由于名称是由若干个字母、数字、下划线和中划线组成,所以需要用到 + 表示出现一次或多次
根据以上条件得出邮件名称表达式:[a-zA-Z0-9-]+ 如果没有中划线的话,可以使用\w+表示:匹配字母、数字、下划线。等价于’[A-Z a-z 0-9]’
分析域名部分:
一般域名的规律为“[四级域名][三级域名.]二级域名.顶级域名”,比如“qq.com”、“www.qq.com”、“mp.weixin.qq.com”、“12-34.com.cn”,分析可得域名类似“ . . .”组成。
“”部分可以表示为[a-zA-Z0-9_-]+
“.”部分可以表示为.[a-zA-Z0-9-]+
多个“.**”可以表示为(.[a-zA-Z0-9-]+)+
综上所述,域名部分可以表示为[a-zA-Z0-9-]+(.[a-zA-Z0-9-]+)+
最终:
/^[a-zA-Z0-9_-]+@[a-zA-Z0-9_-]+(\.[a-zA-Z0-9_-]+)+$/
中文匹配
Unicode字符表示的utf-8编码范围是:[\u4e00-\u9fa5],但是:
PHP正则表达式中不支持下列 Perl 转义序列:\L, \l, \N, \P, \p, \U, \u, or \X
在 UTF-8 模式下,PHP允许用“\x{…}”的形式表示
php中utf-8编码下用正则表达式匹配汉字的最终正确表达式:
\u换为\x,中间要有花括号{},结尾要有u。直接就可以从原字符串中进行匹配或者过滤
/^[\x{4e00}-\x{9fa5}]+$/u,
GBK/GB2312编码:[x80-xff]+ 或 [xa1-xff]
如果要用\u4e00表示的话,只能将原字符转为json,从json里面匹配出对应的字符,
不推荐,麻烦。
<?php
$je = json_encode($content); // \u200b
$pattern = "/\\\u200b/u"; //将Unicode当做字符串进行匹配
$content = preg_replace($pattern, '', $je);

验证输入的必须是中文
<?php
$str="张三";
// +出现一次或多次,u中文匹配
$pattern = '/^[\x{4e00}-\x{9fa5}]+$/u';//中文
// gbk $pattern = '/['.chr(0xb0).'-'.chr(0xf7).']['.chr(0xa1).'-'.chr(0xfe).']/';
if(!preg_match($pattern, trim($str) )){
echo "含有违法字符";
}else{
echo "完全合法";
}
<?php
//js验证:
var myReg = /^[\u4e00-\u9fa5]+$/;
if(!myReg.test(valid)){
alert("姓名必须是中文!");
}
过滤不可见字符
过滤不可见字符
常用正则验证
http://caibaojian.com/zhongwen-regexp.html
<?php
http://caibaojian.com/zhongwen-regexp.html
\w匹配的是:字母、数字、下划线。等价于'[A-Z a-z 0-9_]'。
匹配中文字符的正则表达式: [\u4e00-\u9fa5]
或许你也需要匹配双字节字符,中文也是双字节的字符
匹配双字节字符(包括汉字在内):[^\x00-\xff]
注:可以用来计算字符串的长度(一个双字节字符长度计2,ASCII字符计1)
更多常用正则表达式匹配规则:
英文字母:[a-zA-Z]
数字:[0-9]
匹配中文,英文字母和数字及_:
^[\u4e00-\u9fa5_a-zA-Z0-9]+$
//同时判断输入长度:
[\u4e00-\u9fa5_a-zA-Z0-9_]{4,10}
^[\w\u4E00-\u9FA5\uF900-\uFA2D]*$
1、一个正则表达式,只含有汉字、数字、字母、下划线不能以下划线开头和结尾:
^(?!_)(?!.*?_$)[a-zA-Z0-9_\u4e00-\u9fa5]+$
其中:
^ 与字符串开始的地方匹配
(?!_) 不能以_开头
(?!.*?_$) 不能以_结尾
[a-zA-Z0-9_\u4e00-\u9fa5]+ 至少一个汉字、数字、字母、下划线
$与字符串结束的地方匹配
放在程序里前面加@,否则需要\\进行转义 @"^(?!_)(?!.*?_$)[a-zA-Z0-9_\u4e00-\u9fa5]+$"
(或者:@"^(?!_)\w*(?<!_)$" 或者 @" ^[\u4E00-\u9FA50-9a-zA-Z_]+$ " )
2、只含有汉字、数字、字母、下划线,下划线位置不限:
^[a-zA-Z0-9_\u4e00-\u9fa5]+$
3、由数字、26个英文字母或者下划线组成的字符串
^\w+$
4、2~4个汉字
@"^[\u4E00-\u9FA5]{2,4}$";
七 文件及目录处理
fopen方式操作文件
文件打开函数
fopen — 打开文件或者 URL
$handle = fopen(“c:\folder\resource.txt”, “r”);
第二个参数为打开方式
| ‘r’ | 只读方式打开,将文件指针指向文件头。 |
|---|---|
| ‘r+’ | 读写方式打开,将文件指针指向文件头。 |
| ‘w’ | 写入方式打开,将文件指针指向文件头并将文件大小截为零。如果文件不存在则尝试创建之。 |
| ‘w+’ | 读写方式打开,将文件指针指向文件头并将文件大小截为零。如果文件不存在则尝试创建之。(虽然开始会清空文件,但是w+可以边写,边读。w则只能写,不能读) |
| ‘a’ | 写入方式打开,将文件指针指向文件末尾。如果文件不存在则尝试创建之。 |
| ‘a+’ | 读写方式打开,将文件指针指向文件末尾。如果文件不存在则尝试创建之。 |
| ‘x’ | 创建并以写入方式打开,将文件指针指向文件头。如果文件已存在,则 fopen() 调用失败并返回 FALSE,并生成一条 E_WARNING 级别的错误信息。如果文件不存在则尝试创建之。 |
| ‘x+’ | 创建并以读写方式打开,其他的行为和 ‘x’ 一样。 |
注意:
不同的操作系统家族具有不同的行结束习惯。当写入一个文本文件并想插入一个新行时,需要使用符合操作系统的行结束符号。基于 Unix 的系统使用 \n 作为行结束字符,基于 Windows 的系统使用 \r\n 作为行结束字符,基于 Macintosh 的系统使用 \r 作为行结束字符
Windows 下提供了一个文本转换标记(‘t’)可以透明地将 \n 转换为 \r\n。
还可以使用 ‘b’ 来强制使用二进制模式,这样就不会转换数据。也无需考虑移植系统时候的换行问题。
为移植性考虑,强烈建议在用 fopen() 打开文件时总是使用 ‘b’ 标记。最后重写那些依赖于 ‘t’ 模式的代码使其使用正确的行结束符并改成 ‘b’ 模式。
例子:wb
<?php
$handle = fopen("/home/rasmus/file.txt", "r");
$handle = fopen("/home/rasmus/file.gif", "wb");//二进制模式写入
$handle = fopen("http://www.example.com/", "r");
$handle = fopen("ftp://user:password@example.com/somefile.txt", "w");
文件写入函数
fwrite — 写入文件(可安全用于二进制文件)
fputs — fwrite() 的别名
<?php
$fp = fopen('./test.txt', 'w');
fwrite($fp, 'hello');
fwrite($fp, 'world');
fclose($fp);
文件读取函数
fread() - 读取文件(可安全用于二进制文件),可读取所有文件内容,第一个参数是fopen打开的文件句柄,第二个参数是读取的字节数,使用filesize(‘./ceshi.html’)读取该文件的字节数。所以是读出全部的文件内容。
读取文件的所有内容:
<?php
$fp = fopen('./ceshi.html', 'rb');
$count = fread($fp,filesize('./ceshi.html'));
fclose($fp);
echo $count;
fgets() - 从文件指针中读取一行,只会读取一行,遇到换行就停止
fgetc — 从文件指针中读取一个字符
feof — 测试文件指针是否到了文件结束的位置
读取文件的所有内容:
<?php
$fp = fopen('./ceshi.html', 'rb');
while(!feof($fp)) {
echo fgets($fp); //读取一行
}
fclose($fp);
file_get_contents方式
file_get_contents() 函数是用来将文件的内容读入到一个字符串中的首选方法。如果操作系统支持还会使用内存映射技术来增强性能。
file_put_contents — 将一个字符串写入文件
<?php
$filename = './test.txt';
$data = 'test';
file_put_contents($filename, $data);
上例中,$data参数可以是一个一维数组,当$data是数组的时候,会自动的将数组连接起来,相当于$data=implode(‘’, $data);
file()方式
file — 把整个文件读入一个数组中
readfile — 输出文件
访问远程文件
开启allow_url_fopen,HTTP协议连接只能使用只读,FTP协议可以使用只读或者只写
文件属性
filesize — 取得文件大小,返回文件大小的字节数
<?php
$filename = '/data/webroot/usercode/code/resource/test.txt';
$size = filesize($filename);
//如果要转换文件大小的单位,可以自己定义函数来实现。
function getsize($size, $format = 'kb') {
$p = 0;
if ($format == 'kb') {
$p = 1;
} elseif ($format == 'mb') {
$p = 2;
} elseif ($format == 'gb') {
$p = 3;
}
$size /= pow(1024, $p);//$size是字节,除以1024就是kb,除以1024的二次方就是mb
return number_format($size, 3);//以千位分隔符方式格式化一个数字
}
$size = getsize($size, 'kb'); //进行单位转换
echo $size.'kb';
is_file — 判断给定文件名是否为一个正常的文件
file_exists — 检查文件或目录是否存在
判断文件是否存在:
如果只是判断文件存在,使用file_exists就行,file_exists不仅可以判断文件是否存在,同时也可以判断目录是否存在,is_file是确切的判断给定的路径是否是一个文件。
is_readable与is_writeable在文件是否存在的基础上,判断文件是否可读与可写。
is_readable — 判断给定文件名是否可读
is_writable — 判断给定的文件名是否可写
is_executable — 判断给定文件名是否可执行
filectime — 取得文件的 inode(索引节点) 修改时间
注意:在大多数 Unix 文件系统中,当一个文件的 inode 数据被改变时则该文件被认为是修改了。也就是说,当文件的权限,所有者,所有组或其它 inode 中的元数据被更新时
fileatime — 取得文件的上次访问时间
filemtime — 取得文件修改时间
判断文件是否过期:
<?php
$filename = './test.txt';
$filemtime = filemtime($filename);//文件修改时间
if (time() - $filemtime > 3600) {
echo '<br>缓存已过期';
} else {
echo file_get_contents($filename);
}
文件锁,指针
<?php
flock() — 锁定或释放文件
第二个参数设置锁类型
LOCK_SH取得共享锁定(读取的程序)。
LOCK_EX 取得独占锁定(写入的程序。
LOCK_UN 释放锁定(无论共享或独占)。
ftell() — 返回文件指针读/写的位置
fseek() — 在文件指针中定位
rewind() — 倒回文件指针的位置
文件其它函数
<?php
copy() — 拷贝文件
unlink() — 删除文件
filetype() — 取得文件类型
rename() — 重命名一个文件或目录
move_uploaded_file() — 将上传的文件移动到新位置
ftruncate() — 将文件截断到给定的长度
目录操作函数
名称相关
basename() — 返回路径中的文件名部分
dirname() — 返回路径中的目录部分
pathinfo() — 返回文件路径的信息
目录创建
mkdir — 新建目录
目录读取
chdir — 改变目录
chroot — 改变根目录
opendir — 打开目录句柄
readdir — 从目录句柄中读取条目
closedir — 关闭目录句柄
rewinddir — 倒回目录句柄
scandir — 列出指定路径中的文件和目录
目录删除
rmdir — 删除目录,目录必须为空才能删除
删除一个目录下的所有文件:
需要使用递归,注意过滤掉.和..否则会删除根目录
<?php
//循环删除目录和文件函数
function delDirAndFile( $dirName )
{
if ( $handle = opendir( "$dirName" ) ) {
while ( false !== ( $item = readdir( $handle ) ) ) {
if ( $item != "." && $item != ".." ) {
if ( is_dir( "$dirName/$item" ) ) {
delDirAndFile( "$dirName/$item" );
} else {
if( unlink( "$dirName/$item" ) )echo "成功删除文件: $dirName/$item<br />\n";
}
}
}
closedir( $handle );
if( rmdir( $dirName ) )echo "成功删除目录: $dirName<br />\n";
}
}
文件大小
目录大小
遍历目录,将目录中的所有文件加起来
disk_total_space — 返回一个目录的磁盘总大小
disk_free_space — 返回目录中的可用空间
目录复制
需要用到递归来实现
<?php
// opendir readdir方式:
// opendir — 打开目录句柄
// readdir — 从目录句柄中读取条目,返回目录中下一个文件的文件名
// src原目录,dst复制到的目录
function recurse_copy($src,$dst) {
$dir = opendir($src);
@mkdir($dst);
while(false !== ( $file = readdir($dir)) ) {
if (( $file != '.' ) && ( $file != '..' )) {
// 是目录的话递归调用
if ( is_dir($src . '/' . $file) ) {
recurse_copy($src . '/' . $file,$dst . '/' . $file);
}
else {
copy($src . '/' . $file,$dst . '/' . $file);
}
}
}
closedir($dir);
}
recurse_copy('a','b');
// dir,Directory::read 方式
// dir — 返回一个 Directory 类实例 ,以面向对象的方式访问目录。
// Directory::read — 从目录句柄中读取条目,与 readdir() 函数功能一样
//参数说明:$source:源目录名 $destination:目的目录名 $child:复制时,是不是包含的子目录
function xCopy($source, $destination, $child){
if(!is_dir($source)){
echo("Error:the $source is not a direction!");
return 0;
}
if(!is_dir($destination)){
mkdir($destination,0777);
}
// dir — 返回一个 Directory 类实例 ,以面向对象的方式访问目录。
$handle=dir($source);
// Directory::read — 从目录句柄中读取条目,与 readdir() 函数功能一样
while($entry=$handle->read()) {
if(($entry!=".")&&($entry!="..")){
if(is_dir($source."/".$entry)){
// 有子目录递归调用
if($child){
xCopy($source."/".$entry,$destination."/".$entry,$child);
}
}
else{
copy($source."/".$entry,$destination."/".$entry);
}
}
}
return 1;
}
// xCopy("feiy","feiy2",1):拷贝feiy下的文件到 feiy2,包括子目录
// xCopy("feiy","feiy2",0):拷贝feiy下的文件到 feiy2,不包括子目录
考题
在文件头加入hello world
<?php
// 打开文件,将文件的内容读取出来,在开头加入Hello World
// 然后将上次的文件内容加上拼接好的hello world写入文件里,采用w清空写或者r+文件头写都可以,因为新写入的文件比原先的文件大,所以r+会覆盖原先的文件
//确保这个文件对Apache这个用户有读写的权限,4r+2w,chmod 666 hello.txt,最起码确保chmod 446 hello.txt,其让使用者具有读写权限
$file = './hello.txt';
// 只读打开文件
$handle = fopen($file, 'r');
// 读取所有文件,第二个参数为读取的字节数,设置读取这个文件大小的字节,也就是所有的文件
$content = fread($handle, filesize($file));
$content = 'Hello World'.$content;
fclose($handle);
$handle = fopen($file, 'w');
fwrite($handle, $content);
fclose($handle);
/**
* 不断的向文件头部写入内容
*/
$fileName = 'hello.txt';
if (!is_file($fileName)) {
touch('hello.txt');
$file = fopen($fileName, 'rb+');
fwrite($file, 'hello world');
fclose($file);
return ;
} else {
$file = fopen($fileName, 'r');
$content = fread($file, filesize($fileName));
$hello = 'hello world123' . PHP_EOL . $content;
fclose($file);
$file = fopen($fileName, 'w');
fwrite($file, $hello);
fclose($file);
}
读取一个目录下的所以文件和目录
<?php
/**
* 递归方式显示目录结构
* @param $dir 目录
* @param $count 遍历次数
* @param &$result 存放树
* @return $result 返回目录树结构
*/
function loopDir($dir,$count=0,&$result=array())
{
$count++;
$handle = opendir($dir);
// 目录不为空
while(($file = readdir($handle)) !== false)
{
// 排除掉.和..,目录里面都有隐藏的.和..
if ($file != '.' && $file != '..')
{
echo $file. "\n";
$newfile['tree'] = str_repeat(' ',$count).'|-'.$file;
$newfile['level'] = $count;
$result[]= $newfile;
// 如果是目录的话,递归遍历
if (filetype($dir. '/'. $file) == 'dir')
{
loopDir($dir. '/'. $file,$count,$result);
}
}
}
return $result;
}
$a = loopDir($dir);
foreach ($a as $key2 => $value2) {
echo '<pre>';
print_r($value2['tree'].'层级'.$value2['level']);
echo '</pre>';
}
八 会话控制
会话的发明填补了 HTTP 协议的局限:HTTP 协议被认为是无状态协议,无法得知用户的浏览状态,当它在服务端完成响应之后,服务器就失去了与该浏览器的联系
会话的发明使得一个用户在多个页面间切换时能够保存他的信息
会话控制实现方式:
1 通过get参数传递。不采用,如用户登录之后url中添加一个isLogo = 1,然后每个页面中通过get方式传递这个参数,也可以判断用户是否登录,但是不安全,可以随意改动
2 Cookie,浏览器大小有限制 4k,客户端不安全,
3 session,大小无限制,支持多种数据类型,服务端较安全
cookie
简介
Cookie是服务器发送给客户端的片段信息,存储在客户端的内存或者硬盘中。保存了用户的一些信息。如没有设置cookie的过期时间,默认关闭浏览器就过期了,此时可以说是内存cookie,设置了过期时间,那么cookie是存在了硬盘中。
Cookie通过HTTP headers从服务端返回到客户端,因为Cookie是存在于HTTP的标头之中,所以必须在其他信息输出以前进行设置,类似于header函数的使用限制。
在使用会话Session时通常使用Cookie来存储会话id来识别用户。
设置cookie
setcookie()设置cookie,具有7个可选参数,我们常用到的为前5个:
name( Cookie名)
value(Cookie的值)
expire(过期时间)Unix时间戳格式,默认为0,表示浏览器关闭即失效
path(有效路径)如果路径设置为’/‘,则整个网站都有效
domain(有效域)默认当前主机名,默认最小范围域,
如果设置了’oauth2.php123.com’,则在oauth2子域中有效以及它的三级域名中也有效,a.oauth2.php123.com,
domain 设置成为 php123.com,或者www.php123.com,对整个域名有效。cookie在php123.com或者php123的所有子域中都能接收到。
secure(安全设置)是否通过https连接传递给客户端,如果设置成true,只有安全连接存在时才会设置cookie
<?php
//设置路径与域,对path目录以及子目录有效,整个域名及其子域都有效
setcookie("TestCookie", $value, time()+3600, "/path/", "imooc.com");
$_COOKIE['TestCookie']//获取设置的值
setrawcookie(),设置cookie,和setcookie()基本一致,唯一不同是value值不会自动的进行url编码:urlencode,因此在需要的时候要手动的进行urlencode
setrawcookie('cookie_name', rawurlencode($value), time()+60*60*24*365);
header方式
因为Cookie是通过HTTP标头进行设置的,所以也可以直接使用header方法进行设置。
header("Set-Cookie:cookie_name=value");
将用户数据加密保存到cookie中的一个简单方法
<?php
$secureKey = 'imooc'; //加密密钥
$str = serialize($userinfo); //将用户信息序列化
//用户信息加密
$str = base64_encode(mcrypt_encrypt(MCRYPT_RIJNDAEL_256, md5($secureKey), $str, MCRYPT_MODE_ECB));
//将加密后的用户数据存储到cookie中
setcookie('userinfo', $str);
//当需要使用时进行解密
$str = mcrypt_decrypt(MCRYPT_RIJNDAEL_256, md5($secureKey), base64_decode($str), MCRYPT_MODE_ECB);
$uinfo = unserialize($str);
echo "解密后的用户信息:<br>";
print_r($uinfo);
删除cookie
删除cookie也是采用setcookie函数来实现。
setcookie(‘test’, ‘’, time()-1);
通过header来删除cookie。
header("Set-Cookie:test=1393832059; expires=".gmdate('D, d M Y H:i:s \G\M\T', time()-1));
session
session是将用户的会话数据存储在服务端,没有大小限制,启用session的时候,访问网站的来客会被分配一个唯一的标识符,即所谓的会话 ID,即session_id,通过这个session_id进行用户识别,或者说是通过session_id来获取保存在服务器上的内容
PHP默认情况下session id是通过cookie来保存的,因此从某种程度上来说,seesion依赖于cookie。但这不是绝对的,session id也可以通过url参数来实现,或者保存在数据库,只要能将session id传递到服务端进行识别的机制都可以使用session。
使用session
先执行session_start方法开启session,然后通过全局变量$_SESSION进行读写。
<?php
session_start();
$_SESSION['test'] = time();
var_dump($_SESSION);
session会自动的对要设置的值进行encode与decode,因此session可以支持任意数据类型,包括数据与对象等<br /> 默认情况下,session是以文件形式存储在服务器上的,因此当一个页面开启了session之后,会独占这个session文件,这样会导致当前用户的其他并发访问session的时候无法执行而等待。可以采用缓存或者数据库的形式存储来解决这个问题<br /> <br />**session配置**<br />[http://php.net/manual/zh/session.configuration.php](http://php.net/manual/zh/session.configuration.php)<br />php.ini中可以设置session的一些信息:<br />_session.use_trans_sid_ 指定是否启用透明 SID 支持。默认为 _0_(禁用)。通过url默认传递SID,无需手动在URL进行session_id的传递<br />session.auto_start=1:自动开启session,无需session_start(),<br />session.save_handler = memcache (默认是files,改成memcache)<br />session.save_path = "tcp://localhost:11211" (session保存地址,memcache server的地址或者域名)<br />session.cookie_domain = .test.com (将cookie的有效域设置成同一个域名,目的是为让各个web server对同一个客户端生成同一个SESSION ID)<br />session.use_cookies:默认的值是“1”,代表SessionID使用Cookie来传递,反之就是使用Query_String来传递;<br />session.cookie_lifetime:这个代表SessionID在客户端Cookie储存的时间,默认是0,代表浏览器一关闭SessionID就作废……就是因为这个所以Session不能永久使用<br />session.gc_maxlifetime:这个是Session数据在服务器端储存的时间,如果超过这个时间,那么Session数据就自动删除!<br />session.name:这个就是SessionID储存的变量名称,可能是Cookie,也可能是Query_String来传递,默认值是“PHPSESSID”; <br />_session.cookie_path_ 指定了要设定会话 cookie 的路径<br /> <br />**session垃圾回收:**<br />session.gc_probability<br />_session.gc_probability_ 与 _session.gc_divisor_ 合起来用来管理 gc(garbage collection 垃圾回收)进程启动的概率。默认为 _1_。<br />session.gc_divisor<br />_session.gc_divisor_ 与 _session.gc_probability_ 合起来定义了在每个会话初始化时启动 gc(garbage collection 垃圾回收)进程的概率。此概率用 gc_probability / gc_divisor 计算得来。例如 1/100 意味着在每个请求中有 1% 的概率启动 gc 进程。_session.gc_divisor_ 默认为 _100_。<br />session.gc_maxlifetime<br />指定过了多少秒之后数据就会被视为“垃圾”并被清除。 垃圾搜集可能会在 session 启动的时候开始( 取决于[session.gc_probability](session.configuration.php#ini.session.gc-probability) 和 [session.gc_divisor](session.configuration.php#ini.session.gc-divisor)<br />如:超过1800秒的session文件,在每次session_strat的时候有百分之1的几率删除
<?php
session.gc_probability = 1;
session.gc_divisor = 100;
session.gc_maxlifetime = 1800;
删除与销毁session
删除某个session值使用PHP的unset函数,删除后就会从全局变量$_SESSION中去除,无法访问。
如果要删除所有的session,可以使用session_destroy函数销毁当前session,session_destroy会删除所有数据,但是session_id仍然存在。
session_destroy() 并不会立即的销毁全局变量$_SESSION中的值,只有当下次再访问的时候,$_SESSION才为空,因此如果需要立即销毁$_SESSION,可以使用unset函数。
<?php
session_start();
$_SESSION['name'] = 'jobs';
$_SESSION['time'] = time();
unset($_SESSION);
session_destroy();
var_dump($_SESSION); //此时已为空
如果需要同时销毁cookie中的session_id,通常在用户退出的时候可能会用到,则还需要显式的调用setcookie方法删除session_id的cookie值。<br />
session与cookie的异同
cookie将数据存储在客户端,不会浪费服务器资源<br /> cookie相对不是太安全,容易被盗用导致cookie欺骗,因为存储在客户端所以不安全<br /> 单个cookie的值最大只能存储4k,cookie只支持存储字符串类型的值<br /> 每次请求都要进行网络传输,占用带宽<br /> 用户可以禁止cookie,如果用户禁止了cookie,无法通过cookie保存信息<br /> <br /> session可以方便的存取多种数据类型,而cookie只支持字符串类型,同时对于一些安全性比较高的数据,cookie需要进行格式化与加密存储,而session存储在服务端则安全性较高<br />
session_id传递
默认cookie传递,可设置cookie作用域,主域和子域名可以共享cookie
自动传递SID
URL传递
Session存储
session.save_handler = memcache (默认是files,改成memcache)
session.save_path = “tcp://localhost:11211” (session保存地址,memcache server的地址或者域名)
session默认是保存到当前服务器下的一个文件里,单台服务器还可以,如果采用lvs负载均衡的话,无法共享session文件,所以需要将session保存在单独的一台服务器里,可以是MySQL,Memcache,Redis等进行保存
将session存储到当前服务器下文件里,如果下次请求的时候切换到web4服务器,在当前服务器下找不到这个session_id对应的session文件,所以登录失败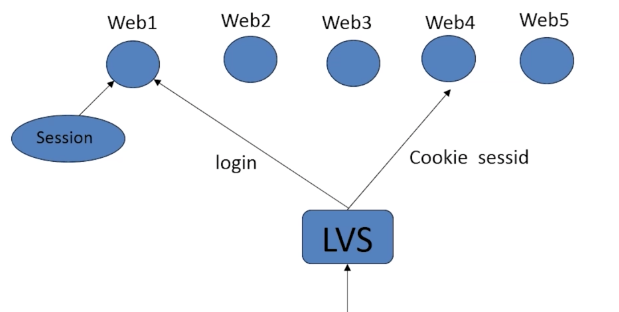
解决办法:将session存到单独的一台服务器里,使用redis保存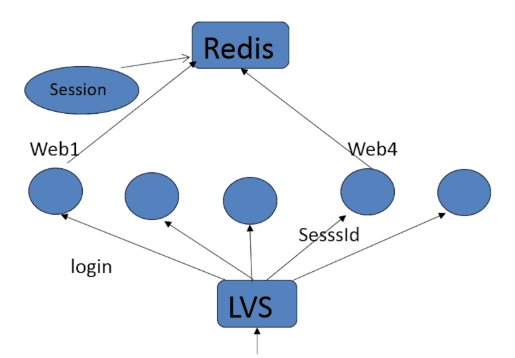
九 面向对象
三大特点
1、封装性:也称为信息隐藏,就是将一个类的使用和实现分开,只保留部分接口和方法与外部联系,或者说只公开了一些供开发人员使用的方法。于是开发人员只 需要关注这个类如何使用,而不用去关心其具体的实现过程,这样就能实现 MVC 分工合作,也能有效避免程序间相互依赖,实现代码模块间松藕合。
2、继承性:就是子类自动继承其父级类中的属性和方法,并可以添加新的属性和方法或者对部分属性和方法进行重写。继承增加了代码的可重用性。PHP 只支持单继承,也就是说一个子类只能有一个父类。
3、多态性:子类继承了来自父级类中的属性和方法,并对其中部分方法进行重写。于是多个子类中虽然都具有同一个方法,但是这些子类实例化的对象调用这些相同的方法后却可以获得完全不同的结果,这种技术就是多态性。多态性增强了软件的灵活性。
对象内部是高内聚的(特定功能,该有的功能都有)
-对象只负责一项特定的职能。
对象对外是低耦合的(相互之间的依赖关系变得小是低耦合的原则,如一个类,给a用可以,b用也可以)
-外部可以看到对象的一些属性(并非全部)
-外部可以看到对象可以做某些事情(并非全部)
面向对象编程的基本原则:
1,单一原则,一个类,只需要做好一件事。
2,开放封闭,一个类,应该是可扩展的,而不可修改的。
3,依赖倒置,一个类,不应该强依赖另外一个类,每个类对于另外一个类都是可替换的。也就是通过注入的方式,获取所需要的依赖
4,配置化,尽可能的使用配置,而不是硬编码。
5,面向接口编程,只需要关心接口,不需要关心实现。
类
创建一个类的实例,
<?php
// 可以使用new关键字创建一个对象。
$car = new Car();
//也可以采用变量来创建
$className = 'Car';
$car = new $className();
方法
方法就是在类中的function,
在面向对象中function则被称之为方法,在面向过程的程序设计中function叫做函数。
访问控制
- public 表示全局,类内部外部子类都可以访问;
2. protected的类成员只能在 该类中 和子类内 访问,该类的实例,子类的实例外部不能直接调用;
3. private 该类型的属性或方法只能在该类中使用,在该类的实例、子类中、子类的实例中都不能调用;父类中也不能直接调用子类的private属性和方法
- public 表示全局,类内部外部子类都可以访问;
可通过一个public的方法访问该类的protected或者private的属性或者方法,达到访问受限方法的目的。
self this static
self
self::表示的是本类,
self不能用于访问类自身的普通成员属性(使用this访问),可以访问自身的静态成员属性,和常量;
self关键字可以用于访问类自身的成员方法(静态和非静态的都可以)
$this
$this表示当前实例,一般在类的内部方法访问未声明为const及static的属性时,$this->属性,$this->方法。
$this 作用域只表示类的当前实例,一个类可以有好多个实例;new一个类返回的就是一个该类的新的实例;
静态static
static 表示的也是当前实例
静态方法中,$this不允许使用,所以不能调用普通属性,因为PHP中调用普通属性使用$this
静态方法内部可调用静态属性,可调用非静态方法;可以使用 static, self,parent,或者类名::方法名。php 里,一个方法被self::后,自动转变为静态方法
调用类的静态函数时不会自动调用类的构造函数,因为没有实例化;
静态成员不需要实例化对象就可以访问,静态属性和方法,在类被调用的时候被创建
静态变量只初始化一次,在每次调用这个函数的时候都会在栈中找到之前存在的值,直到这个进程结束
<?php
// this self static在子类中使用的时候,调用的都是子类的方法;当在父类中使用的时候,区别就大了
// self 表示本类,在父类在使用就是调用父类的方法
// this和static都是表示当前实例,优先调用当前实例的方法属性;也就是子类;如果子类中没有就调用父类的。如果子类的访问控制是私有的private,父类中不能直接调用子类的private属性和方法,所以父类中使用this只能调用父类的私有方法
<?php
class BaseClass {
const CONST_VALUE = '父constant,';
public static $sValue = "父static,";
public $height="父height,";
public function testing() {
// parent::moreTesting(); //parent关键字可以访问父类被重写的成员
//self表示本类,也就是父类,所以调用的是父类的方法;本类中没有该方法时,也不会调用子类的方法
self::called(); //父called
// $this表示当前实例,所以优先调用的是子类的方法;当子类没有该方法时,会调用父类的。
$this->called(); //子called
$this->privateCcalled(); //父privateCcalled
// static 表示的也是当前实例,所以优先调用的是子类的方法;当子类没有该方法时,会调用父类的。
echo static::$sValue; // 子static
static::staticcd(); // 子staticcd
// 想要调用本类的静态属性和方法,使用self
echo self::$sValue; // 父static
self::staticcd(); // 父staticcd
// echo self::$height;// self不能访问自身的普通属性
echo $this->height; //子height
echo self::CONST_VALUE; //父constant
echo static::CONST_VALUE; //子constant,
echo $this::CONST_VALUE; // 子constant,
}
public function called(){
echo "父called,";
}
private function privateCcalled(){
echo "父privateCcalled,";
}
public static function staticcd(){
echo "父staticcd,";
}
}
class ChildClass extends BaseClass {
const CONST_VALUE = '子constant,';
public static $sValue = "子static,";
public $height="子height,";
public function called(){
echo "子called,";
}
private function privateCcalled(){
echo "子privateCcalled,";
}
public static function staticcd(){
echo "子staticcd,";
}
}
$obj = new ChildClass();
$obj->testing();
<?php
//$this就是当前对象,
//self需要new self();才为对象。
//static需要 new static()才是个对象
class A {
public static function get_self() {
return new self();
}
public static function get_static() {
return new static();
}
public function get_this() {
return $this;
}
}
class B extends A {}
// 返回对象的类名
echo get_class(A::get_self()); // A
echo get_class(B::get_self()); // A
echo get_class(A::get_static()); // A
echo get_class(B::get_static()); // B
$a = new A();
echo get_class($a->get_this());//A
$b = new B();
echo get_class($b->get_this());//B
静态
静态类为什么不用实例化,直接使用?
程序启动的时候,静态属性的类,方法,变量都已经被第一时间加载到内存中了!所以你直接调用就可以了!
静态变量只初始化一次,在每次调用这个函数的时候都会在栈中找到之前存在的值,直到这个进程结束(静态变量的作用域也仅限与当前类,当前类中的静态变量,在其它类中是不能使用的)
静态的变量或者是函数是保存在静态内存中的,只有到程序结束时才会被释放,那他是什么时候赋值的呢?
需要编译的语言是在编译的时候将静态变量或者函数保存在静态内存中,动态语言是在程序运行的时候动态分配的(PHP)
所有方法都用静态好吗:
如果类中调用一次静态方法或属性,静态类在编译的时候需要多做工作,动态类在执行的时候需要需要多做工作,然而php是动态语言,每一次这两步都不不掉,所以对于只运行一次的类,无所谓谁快谁慢
但是 大量方法都使用静态方法,会导致性能下降,占用内存(因为静态资源直到程序执行完毕才释放)
普通局部变量,一旦函数执行完毕就销毁,但是静态变量不会。
所以对于只运行一次的方法,属性,不必使用静态类
如果一个方法在其他类中多次使用,虽然不在一个线程内启动,也可以使用静态方法,不用 new,用起来省事,这是表面上最容易看到的优点。
静态类场景:
如果一个类在程序当中要多次调用就不一样了,静态类是编译的时候就赋值了,程序之后的运行都可以直接调用过来,而不用动态的分配内存了,就节约了时间
项目中运用到的字典值,在程序运行的时候会多次运行,写为静态方法会好
而路由控制器中的类一般只是运行一次,写成普通类就行。如一个动作,查看的动作,经过一个路由detail,加载一个视图。
静态累加
1 静态变量只存在于函数作用域内,也就是说,静态变量只存活在栈中。一般的函数内变量在函数结束后会释放,比如局部变量,但是静态变量却不会。就是说,下次再调用这个函数的时候,该变量的值会保留下来。
<?php
function test()
{
static $nm = 1;
$nm = 1;
$nm = $nm * 2;
print $nm."<br />";
}
// 第一次执行,$nm = 2
test();
// 第一次执行,$nm = 4
test();
// 第一次执行,$nm = 8
test();
2 静态变量$nm属于nowamagic类,而不属于类的某个实例,(不只属于$nmInstance1,也不止属于$nmInstance2)。这个变量对所有nowamagic的实例都有效。
$this作用域只表示类的当前实例,self::表示的是类本身。
<?php
class nowamagic
{
public static $nm = 1;
public function nmMethod()
{
self::$nm += 2;
echo self::$nm . '<br />';
}
}
$nmInstance1 = new nowamagic();
$nmInstance1 -> nmMethod();//3
$nmInstance2 = new nowamagic();
$nmInstance2 -> nmMethod();//5
3 声明的静态变量,依旧累加
<?php
class nowamagic
{
public function nmMethod()
{
static $nm = 1;
$nm += 2;
echo $nm . '<br />';
}
}
$nmInstance1 = new nowamagic();
$nmInstance1 -> nmMethod();//3
$nmInstance1 -> nmMethod();//5
$nmInstance2 = new nowamagic();
$nmInstance2 -> nmMethod();//7
4 trait类中的静态变量,两个不同的类使用,静态变量是独立的。因为静态变量的累加只在本类有效。trait只是相当于代码块,将trait申明的方法,嵌入到其它地方;两个不同的类使用,属于不同的两个类;
<?php
trait Counter {
public function inc() {
static $c = 0;
$c += 2;
echo "$c\n";
}
}
class C1 {
use Counter;
}
class C2 {
use Counter;
}
// cl类的不同实例,静态变量依旧属于C1类,静态变量会累加
$o = new C1();
$o->inc(); // echo 2
$p = new C1();
$p->inc(); // echo 4
// 另一个类的实例,静态变量属于C2类,是一个独立的类。
$q = new C2();
$q->inc();//2
命名空间
命名空间说白了就是给一个文件里的类,方法,属性都加了一个前缀,防止在一个文件中引入两个不同的文件时候,里面的类,方法,属性出现重名的情况,因为PHP中不允许两个函数或者类出现相同的名字(如果类名不一样,里面的方法名可以一样的),否则会产生一个致命的错误。当然,命名空间也不能出现两个相同的名字。
<?php
namespace my\name1;//命名空间的声明,在第一行申明
require_once("a.php");
use my\name1\className;//在其他文件中使用a.php的命名空间
单一继承extends
- PHP中类不允许同时继承多个父类,也就是extends后面只能跟一个父类名称,这个特性被称为PHP的单继承特性。但一个类可以implements实现多个接口
* parent和$this的作用域不同,效率没差别,都可以调用继承的父类的方法,一般对象方法用$this即可,parent一般是为了子类在覆盖父类方法后还需要调用父类的方法而使用的,比如父类有个get方法,子类也有个get方法,但是子类想在父类的get方法基础上继续做些操作,就只能用parent::get()
重写和Final
- 子类中编写跟父类完全一致的方法可以完成对父类方法的重写,parent关键字可以用于调用父类被重写的类成员
2. 对于不想被任何类继承的类可以在class之前添加final关键字
3. 对于不想被子类重写(overwrite, 修改)的方法,可以在方法定义前面添加final关键字
- 子类中编写跟父类完全一致的方法可以完成对父类方法的重写,parent关键字可以用于调用父类被重写的类成员
接口
接口里面的方法没有具体的实现
实现了某个接口的类必须实现接口中定义的所有方法
接口可以继承接口(interface extends interface)
接口中定义的所有方法都必须是公有,这是接口的特性。
一个类可以实现多个接口,实现关键字implements:class staff implements staff_i1, staff_i2
抽象类
抽象类允许类里面的部分方法暂时没有具体实现,这些方法我们成为抽象方法(接口里面的方法都是没有实现的(没有大括号),普通类里面的方法都是有实现的(有大括号))
2. 一旦类里面有抽象方法,这个类就必须是抽象类
3. 抽象类跟接口一样,不能直接实例化为对象
* 4. 抽象类需要子类继承,继承的子类必须实现父类的所有的抽象方法。 ```php <?php // 抽象类前面以abstract关键字开始 abstract class ACanEat { // 没有实现的方法需要设定为抽象方法 // 抽象方法需要在子类中实现 abstract public function eat($food);public function breath(){ echo “Breath use the air.\n”; } }
// Human类实现了ICanEat接口 class Human extends ACanEat { const cash = ‘cash’; // 子类实现抽象方法 public function eat($food){ echo “Human eating “ . $food . “\n”; } }
// Animal类实现了ICanEat接口 class Animal extends ACanEat { public function eat($food){ echo “Animal eating “ . $food . “\n”; } }
echo Human::cash; // 常量可直接访问 $man = new Human(); $man->eat(“Apple”); $man->breath(); // 和Animal共用了抽象类ICanEat的breath方法 $monkey = new Animal(); $monkey->eat(“Banana”); $monkey->breath();
<a name="kYr5y"></a>
## 多态
* 对接口里定义的方法的具体实现是多种多样的,这种特性称之为’多态‘;<br /> * 通过实现接口实现多态<br /> * 通过继承关系实现多态<br />
<a name="bRtVh"></a>
## 对象比较
当同一个类的两个实例的所有属性都相等时,可以使用比较运算符==进行判断,<br />当需要判断两个变量是否为同一个对象的引用时,可以使用全等运算符===进行判断。
```php
<?php
class Car {
}
$a = new Car();
$b = new Car();
if ($a == $b) echo '=='; //true
if ($a === $b) echo '==='; //false
对象复制
在一些特殊情况下,可以通过关键字clone来复制一个对象,这时__clone方法会被调用,通过这个魔术方法来设置属性的值。<br /> //clone(对象复制)的方式实际上是对整个对象的内存区域进行了一次复制并用新的对象变量指向新的内存<br />//也可以叫做克隆,克隆的只能是克隆的那个时候之前的属性,被克隆的这个对象之后发生任何改变都不影响已经完成克隆的新变量。 <br />//因此赋值后的对象和源对象相互之间是基本来说独立的。因为PHP的object clone采用的是浅拷贝(shallow copy)的方法, <br />//如果对象里的属性成员本身就是reference引用类型或者本身就是clone的一个对象,clone以后这些成员并没有被真正复制,仍然是引用的。因为PHP的object clone采用的是浅拷贝(shallow copy)的方法,
PHP5中默认就是通过引用来调用对象(事实上,绝大部分的编程语言都是如此! 主要原因是内存及性能的问题),但有时你可能想建立一个对象的副本,并希望原来的对象的改变不影响到副本 . 为了这样的目的,PHP定义了一个特殊的方法,称为__clone
1. 对象引用的概念:对象的引用是访问对象属性和方法的媒介
2. 引用赋值会产生一个新的对象引用
3. 使用&进行引用赋值不会产生新的引用,而是产生了引用的一个复制品
4. 当指向对象的所有引用都被设为null时,对象的析构函数才被自动调用
*/
<?php
//实例1:
class myclass {
public $data;
}
$obj1 = new myclass();
$obj1->data = "aaa";
$obj2 = $obj1;
$obj2->data ="bbb"; //$obj1->data的值也会变成"bbb",说明$obj2 = $obj1;是引用的关系
// 在有些时候,我们其实不希望这种reference(引用)式的赋值方式, 我们希望能完全复制一个对象,这是侯就需要用到 Php中的clone (对象复制)
<?php
class myclass {
public $data;
}
$obj1 = new myclass();
$obj1->data ="aaa";
$obj2 = clone $obj1; //完全复制一个对象,$obj2有自己的内存地址
$obj2->data ="bbb"; // $obj1->data的值仍然为"aaa"
// 例2
默认情况下对象是通过引用传递的。这不是完全正确的。(引用的是对象的标识符(一个ID),这个标识符指向对象本身)
php的引用就是两个不同的变量名字指向相同的内容。
在php5,一个对象变量已经不再保存整个对象的值。只是保存一个标识符来访问真正的对象内容,当类生成一个实例(对象)的时候,返回值$instance(实例)并不是对象本身,而只是对象的一个id(或者资源句柄,标识符),
<?php
class SimpleClass{
public $var = 'zhangSan';
}
$instance = new SimpleClass();//变量保存的是这个对象的一个标识符,用来找到这个对象
$assigned = $instance;//复制$instance的标识符给自己,两个变量有两个标识符都指向一个对象
$reference = &$instance;//引用$instance的标识符,两个变量对应一个标识符,标识符都指向一个对象
$a = clone $instance;//clone(对象复制)的方式实际上是对整个对象的内存区域进行了一次复制并用新的对象变量指向新的内存
//也可以叫做克隆,克隆的只能是克隆的那个时候之前的属性,被克隆的这个对象之后发生任何改变都不影响已经完成克隆的新变量。因此赋值后的对象和源对象相互之间是基本来说独立的。
//如果对象里的属性成员本身就是reference引用类型或者本身就是clone的一个对象,clone以后这些成员并没有被真正复制,仍然是引用的。因为PHP的object clone采用的是浅拷贝(shallow copy)的方法,
$instance->var = 'liSi';//除了$a不改变,其余几个都改变,因为都指向的一个对象
// $instance = null; //$instance和$reference为null,其余几个都有值。
//$assigned是复制了一份$instance标识符,所以assigned的标识符仍旧存在,有值
//$reference是$instance的引用,对应一个标识符,所以为null,
//$a 是clone了一份原对象,所以也把标识符也克隆了一份给$a,所以有值
echo 1;
echo '<pre>';
print_r($instance);
echo '</pre>';
echo '<hr>';
echo 2;
echo '<pre>';
print_r($assigned);
echo '</pre>';
echo '<hr>';
echo 3;
echo '<pre>';
print_r($reference);
echo '</pre>';
echo '<hr>';
echo 4;
echo '<pre>';
print_r($a);
echo '</pre>';
当对实例初始化的时候,$assigned也被初始化了。但是,当实例$instance被销毁(=null)的时候,因为对应的对象还有一个句柄存在($assigned),所以对象并不会被销毁,析构函数也不会马上被触发。
<?php
class SimpleClass{
public $var = 'zhangSan';
function __destruct() {
echo '销毁';
}
}
$instance = new SimpleClass();//变量保存的是这个对象的一个标识符,用来找到这个对象
$assigned = $instance;//复制$instance的标识符给自己,两个变量有两个标识符都指向一个对象
$reference = &$instance;//引用$instance的标识符,两个变量对应一个标识符,标识符都指向一个对象
$a = clone $instance;
//析构函数会在程序最后运行:销毁销毁,两个。一个是$instance,$assigned,$reference这三个变量指向的都是同一个对象,程序运行完会执行析构函数,另一个是$a 克隆的新对象在程序运行完之后会执行析构函数
// 因为有assigned = $instance,所以不会马上执行析构函数。$assigned是对$instance的复制,当销毁$instance的时候,还有$assigned指向原对象,所以不会执行析构函数
// 如果没有assigned = $instance;,那么将$instance设置null的时候,会马上执行析构函数销毁,程序结束的时候$a克隆的对象在执行一次析构函数。
// 因为$reference引用是共用的标识符,销毁$instance的时候,$reference也销毁了,对象已经没有变量指向它了,所以会执行析构函数
// $a是克隆的副本,和$instance是独立的。销毁$instance的时候,也没有变量指向它。单$a会在程序结束的时候执行析构函数
$instance = null;
echo 1;
echo '<pre>';
print_r($instance);
echo '</pre>';
echo '<hr>';
echo 2;
echo '<pre>';
// print_r($assigned);
echo '</pre>';
echo '<hr>';
echo 3;
echo '<pre>';
print_r($reference);
echo '</pre>';
echo '<hr>';
echo 4;
echo '<pre>';
print_r($a);
echo '</pre>';
// 例子
<?php
class myClass{
public $data;
public $like;
}
$aaa ="aaa";
$like = 'sss';
$obj1 = new myClass();
$obj1->data =&$aaa; //注意,这里是个reference!引用.当clone这个对象的这个引用属性的时候,这个属性为浅复制,所有clone的对象对这个data属性的修改都会影响这个属性在任何地方的值,指向同一个地址。
$obj1->like =$like;
$obj2 = clone $obj1;
$obj2->data="bbb";//浅复制,修改一处,其余地方全部生效。
$obj2->like="mmm";//深复制,完全和$like变量脱离关系。
echo '<pre>';
print_r($obj1);//[data] => bbb,[like] => sss
echo '</pre>';
echo "<hr>";
echo '<pre>';
print_r($obj2);//[data] => bbb,[like] => mmm
echo '</pre>';
$obj1->data="ccc";//浅复制,修改一处,其余地方全部生效。
echo '<pre>';
print_r($obj1);//[data] => ccc,[like] => sss
echo '</pre>';
echo "<hr>";
echo '<pre>';
print_r($obj2);//[data] => ccc,[like] => mmm
echo '</pre>';
// 我们再举一个更实用的例子来说明一下PHP clone这种浅拷贝带来的后果:
<?php
class testClass
{
public $str_data;
public $obj_data;
public function __clone() {
// $this->obj_data = clone $this->obj_data;//obj2的obj_data属性克隆出一份来,实现完全分离。完全克隆
}
}
class SimpleClass{
public $var = 'zhangSan';
}
class Simple{
public $var = 'wanger';
}
$Simple = new Simple();
$dateTimeObj = new SimpleClass();
$obj1 = new testClass();
$obj1->str_data ="aaa";
$obj1->obj_data = clone $dateTimeObj;//$obj1->obj_data也有一份SimpleClass对象的地址。
$obj2 = clone $obj1; //obj2克隆了一份obj1,但是obj_data属性并没有完全复制了一份,因为obj1的obj_data属性本身就是克隆的一个值。obj2的obj_data属性和它共享一份克隆,想要完全克隆,需要将obj_data在克隆出一份来。clone的时候调用__clone魔术方法。
$obj2->str_data ="bbb";
// $obj2->obj_data->var='nnn';//注释掉__clone方法会影响$obj1->obj_data的属性。说明是浅拷贝
// $obj2->obj_data->var = $Simple;//改变为其他对象,注释掉__clone方法会影响$obj1->obj_data的属性。说明是浅拷贝
$obj2->obj_data='tie';//如果改变类型,将obj_data由对象改为字符串,注释掉__clone方法也不会影响$obj1->obj_data的属性。
echo '<pre>';
print_r($obj1);
echo '</pre>';
echo '<pre>';
print_r($obj2);
echo '</pre>';
echo '<pre>';
print_r($dateTimeObj);
echo '</pre>';
// 你用clone来复制对象,希望是把两个对象彻底分开,不希他们之间有任何关联, 但由于clone的shallow copy的特性, 有时候会出现非你期望的结果,上面的例子中,
// 1) $obj1->obj_data =$dateTimeObj 这句话实际上是个引用类型的赋值. 还记得前面提到的PHP中对象直接的赋值是引用操作么?除非你用$obj1->obj_dat = clone $dataTimeObj,$dataTimeObj对象才不受影响
// 2) $obj2 = clone $obj1 这句话生成了一个obj1对象的浅拷贝对象望,并赋给obj2. 由于是浅拷贝,obj2中的obj_data也是对$dateTimeObj的引用!
// 3)$dateTimeObj, $obj1->obj_data, $obj2->obj_data 实际上是同一个内存区对象数据的引用,因此修改其中任何一个都会影响其他两个!
// 如何解决这个问题呢? 采用PHP中的 __clone方法 把浅拷贝转换为深拷这个方法给C++中的copy constructor概念上有些相似,但执行流程并不一样)
对象序列化
可以通过serialize方法将对象序列化为字符串,用于存储或者传递数据,然后在需要的时候通过unserialize将字符串反序列化成对象进行使用。
<?php
class Car {
public $name = 'car';
}
$a = new Car();
$str = serialize($a); //对象序列化成字符串
echo $str.'<br>';
$b = unserialize($str); //反序列化为对象
var_dump($b);
魔术方法:
https://www.php.net/manual/zh/language.oop5.magic.php
PHP有17个魔术方法;注意: 所有的魔术方法 必须 声明为 public
__construct(), __destruct(), __call(), __callStatic(), __get(), __set(), __isset(), __unset(), __sleep(), __wakeup(), __serialize(), __unserialize(), __toString(), __invoke(), __set_state(), __clone() 和 __debugInfo() 等方法在 PHP 中被称为魔术方法(Magic methods)。在命名自己的类方法时不能使用这些方法名,除非是想使用其魔术功能。
构造函数:__construct()
只有在new这个对象的时候才会执行,适合在使用对象之前做一些初始化工作。
如果不实例化,直接调用类的静态方法不会调用构造函数。
子类可以继承父类的构造方法,当new子类的时候,父类的构造方法也会执行。如果子类也有构造方法,发生重写了,只执行子类的构造方法,但可以使用parent::construct(); 调用父类的构造方法
**析构函数:destruct()**
析构函数在某个对象的所有引用都被删除或者当对象被显示销毁时执行。也就是对象在内存中被销毁前调用析构函数。如没有变量指向该对象,程序结束或者手动赋值为Null或unset(),可在构造函数中进行清理程序中使用的系统资源,比如释放打开的文件等等
要执行父类的析构函数,必须在子类的析构函数体中显式调用 parent::destruct()。此外也和构造函数一样,子类如果自己没有定义析构函数则会继承父类的。
**clone
PHP中默认就是通过引用来调用对象,但有时你可能想建立一个对象的副本,并希望原来的对象的改变不影响到副本 . 为了这样的目的,PHP定义了一个特殊的方法,称为__clone
tostring()**
当对象被当做String使用时,tostring()会被自动调用:echo $obj会调用tostring()魔术方法;此方法必须返回一个字符串,否则将发出一条 E_RECOVERABLE_ERROR 级别的致命错误。
**invoke()
当对象被当成方法调用时,__invoke()会被自动调用:$obj()会调用此方法;
属性重载:*
<?php
__get():读取不可访问属性的值时,__get() 会被调用。
__set():在给不可访问属性赋值时,__set() 会被调用。
__isset():当对不可访问属性调用 isset() 和empty()时,__isset() 会被调用。
__unset():当对不可访问属性调用 unset() 时,__unset() 会被调用
方法重载:call(),callStatic()
在对象中调用一个不可访问的方法时(如私有的方法,受保护的方法,或者不存在的方法),call() 会被调用。
在对象中调用一个不可访问的静态方法时(如私有的方法,收保护的方法,或者不存在的方法),callStatic()方法会被自动调用
sleep(),wakeup()
当序列化对象时,PHP 将试图在序列动作之前调用该对象的成员函数 sleep()。这样就允许对象在被序列化之前做任何清除操作。类似的,当使用 unserialize() 恢复对象时, 将调用 wakeup() 成员函数。
魔术常量
<?php
__LINE__ 文件中的当前行号。
__FILE__ 文件的完整路径和文件名
__DIR__ 文件所在的目录
__FUNCTION__ 函数名称
__CLASS__ 类的名称
__TRAIT__ Trait 的名字
__METHOD__ 类的方法名
__NAMESPACE__ 命名空间的名称
自动载入
<?php
//__autoload() 在php7.2已经弃用。自动加载类和接口,建议使用 spl_autoload_register() 函数。
一个项目如果要加载其它类库,其它类库如果也有__autoload() 函数,就会报错。因为PHP不允许函数重名,
spl_autoload_register() 提供了一种更加灵活的方式来实现类的自动加载,将自定义函数设置替换为__autoload函数,spl_autoload_register可多次调用,注册的多个函数将在事件发生时依次执行。
// spl_autoload_register可以注册加载多个自定义函数
spl_autoload_register('autoload', true, true);
spl_autoload_register('autoload2', true, true);
设计模式
花更多的代码去办同一件事情,是为了使项目更扩展,可维护,可重构
PSR规范
PSR:Proposing a Standards Recommendation(提出标准建议)
是制定的代码规范,简称PSR,是代码开发的事实标准。
PSR-0规范
[1]命名空间必须与绝对路径一致
[2]类名首字母必须大写
[3]除去入口文件外,其他“.php”必须只有一个类,(一个.php文件内只能有一个class类,属性函数只能写在这一个类里面)
[4]php类文件必须自动载入
[5]单一入口,首页入口只有一个index.php
FIG 制定的PHP规范,简称PSR,是PHP开发的事实标准。
PSR-4和PSR-0最大的区别是对下划线(underscore)的定义不同。PSR-4中,在类名中使用下划线没有任何特殊含义。而PSR-0则规定类名中的下划线_会被转化成目录分隔符。
工厂模式:factory(负责对象的创建)
(包括简单工厂模式、工厂方法模式和抽象工厂模式)
好处:
1、将创建实例的工作与使用实例的工作分开
2、把初始化实例时的工作放到工厂里进行,使代码更容易维护。
3、使得修改代码时不会引起太大的变动,良好的扩展性。
当要创建一个对象的时候,只需要访问一个类里的方法,可以是静态类里的方法,这个类俗称工厂类,这个方法里写new 创建这个对象,其它地方直接使用这个工厂类里的方法就会创建相应的对象,这样当创建的这个类改变的时候,只需要修改工厂里的这个方法即可,便于维护
工厂类负责对象的创建,而其它需要这个类的地方只拥有使用对象的职责即可。将对象的创建和使用分离,也使得系统更加符合“单一职责原则”,有利于对功能的复用和系统的维护。
单例模式:Single
单例模式,使某个类的对象在一次运行只允许创建一个。例如只创建一个数据库连接。
在一个类文件中对此使用了一个对象的话,可以将这个对象作为单例模式存在, 保证一次运行中只有一个实例存在。
在工厂模式中,使用单例模式创建对象,创建之后,还会注册到树上,在一次运行周期中,多次用到一个对象的时候、直接从树上取。
注册树模式:register
将一个对象注册到全局的注册树上(声明的protected static $objects;),需要的时候从这个树上取,不使用实例化对象生成对象,而是运行的时候将对象注册到树上,需要的时候直接传入别名从这个树上取对象
适配器模式:Adapter
可以将截然不同的函数和接口封装成统一的api
实际应用举例:php的数据库操作有mysql,mysqli,pdo 三种,这三种的操作方法不是相同的,我们可以使用适配器模式将其操作方式统一成一致的。类似的场景还有cache适配器,将memcache,redis,file,apc等不同的缓存函数统一成一致的函数
策略模式strategy:(注入模式)
将一组特定的行为和算法封装成类,以适应某些特定的上下文环境,这种模式就是策略模式
实际应用举例:一个电商网站系统,针对男性女性用户要各自跳到不同的商品类目,并且所有广告位展示不同的广告。通常的方式就是在流程中加入if else 的结果,这种就是差的方法,属于硬编码的方式。如果有一天加入的青年,小孩的判断,需要修改的地方大。
使用策略模式,将判断浏览网站的用户的操作,和展示商品以及显示广告流程分离,互不依赖。如登录网站的用户是女士,那么加载首页的时候将女士类注入到首页的方法中,将类当做参数,通过注入不同的类加载不同的数据。显示这个类查询出的商品和广告。以后增加新类别,也只需要在加载首页的入口处判断类别加载对应的类即可。
使用策略模式可以实现IOC(控制反转,还有翻译成为“控制反向”或者“控制倒置”。),依赖倒置,控制反转。属于实现控制反转中的依赖注入方法,为依赖注入的接口注入方法。
数据对象映射模式:DataObjectMapping
是将对象和数据存储映射起来,对一个对象的操作会映射为对数据存储的操作。
比如我们在代码中new一个对象,使用数据对象模式,就可以将这个对象的一个属性等自动保存到数据库。
实例:实现一个ORM类,将复杂的SQL语句映射成对象属性的操作。结合数据对象映射模式,工厂模式,注册模式
观察者模式OBserver
观察者模式(OBserver),当一个对象状态发生改变时,依赖它的对象会全部收到通知,并自动更新。
场景:一个事件发生后,要执行一连串更新操作,传统的编程方式,就是在事件的代码之后直接加入处理逻辑,当更新的逻辑增多之后,代码会变得难以维护,这种方式是耦合的,侵入式的,增加新的逻辑需要修改事件主体的代码。
观察者模式实现了低耦合,非侵入式的通知与更新机制。
如:采用观察者模式,将每一个事件写一个类,观察者模式有一个方法是将所有的事件类注册到树上,每一个事件都调用这个方法,将自己当做参数注入到树上,最后执行观察者模式的通知方法,会循环树上的所有类,执行每个类的方法
原型模式:prototype
与工厂模式作用类似,都是用来创建对象
与工厂模式实现不同,原型模式是先创建好一个原型对象,然后通过clone原型对象来创建新的对象,这样就免去了类创建时重复的初始化操作。
原型模式适用于大对象的创建,创建一个大对象需要很大的开销,如果每次new就会消耗很大,原型模式仅需内存拷贝即可。
如:初始化画布的时候需要画出一个100X100的画布,还需要进行一些装饰,背景色之类的装饰操作。如果我要在这个画布上创建不同的内容。那么每创建一个内容都需要进行初始化 操作。采用原型模式,将初始化操作赋值给一个变量。每次创建不同的内容的时候clone这个原型。在原型的基础上进行创建。减少程序消耗
装饰器模式:decorate
可以动态地添加 修改 类的功能
一个类提供了一项功能,如果要在修改添加额外的功能,传统的编程模式,需要写一个子类继承它,并重新实现类的方法,
使用装饰器模式,仅需在运行时添加一个装饰器对象即可实现,可以 实现最大的灵活性。
如:一个画布,draw方法输出画布,如果要给这个画布增加颜色,传统的方法就是写一个子类继承父类,重写父类的draw方法。不够灵活。装饰器模式类似观察者模式,将每一个装饰写成一个类,将需要的装饰类注入到装饰器的一个方法里,注册到树上,再需要的地方遍历出树上的所有装饰类
迭代器模式:iterator
在不需要了解内部实现的前提下,遍历一个聚合对象的内部元素。
相比传统的编程模式,迭代器模式可以隐藏遍历元素的所需的操作
代理模式:proxy
在客户端与实体之间建立一个代理对象(proxy),客户端对实体进行操作全部委派给代理对象,隐藏实体的具体实现细节。
代理对象proxy还可以与业务代码分离,部署到另外的服务器,业务代码中通过PRC来委派任务。
什么是代理模式呢?我很忙,忙的没空理你,那你要找我呢就先找我的代理人吧,那代理人总要知道被代理人能做哪些事情不能做哪些事情吧,那就是两个人具备同一个接口,代理人虽然不能干活,但是被代理的人能干活呀。
如:西门庆要找一个美女,他想到了潘金莲,通过王婆这个代理,具体的活潘金莲来做。西门庆明天想换另一个人,只需要注入另一个类即可
十:开发环境以及配置
版本控制软件:
集中式: 中央服务器,客户连接上传下载。cvs 和 svn
分布式: 没有中央服务器。每台客户机都有完成版本号。Git
区别:
使用git,在没有网络的情况下,你可以提交给本地,在本地做版本管理的所有处理。比如提交版本1,提交版本2,提交3,然后恢复版本1,开一个分支,切换分支,修改代码,合并分支。
这和集中式的svn非常不同,svn你离线时可以提交吗?绝对不能。git则可以在无网络情况下本地提交,他把提交版本与推送服务器这两个概念分开了。
而svn是融为一体的,提交即推送给服务器。因此,git是去中心的,他的中央服务器并非必须的,只是为了方便大家交流使用,你完全可以把git服务器想象成一个参与者,他得电脑始终在线,他不写代码,只接受大家的推送与合并,然后供其他用户从他这里拉取信息。
所以,我觉得这两个工具主要的区别在于历史版本维护的位置
Git本地仓库包含代码库还有历史库,在本地的环境开发就可以记录历史 ,而SVN的历史库存在于中央仓库,每次对比与提交代码都必须连接到中央仓库才能进行
Git这样的好处在于:
1、自己可以在脱机环境查看开发的版本历史
2、多人开发时如果充当中央仓库的Git仓库挂了,任何一个开发者的仓库都可以作为中央仓库进行服务
PHP运行原理
1、客户端发起URL请求。
2、服务器上的 Web Server 接受到客户断的请求,判断是PHP的请求,然后发起一个socket请求给PHP解释器(php-cgi),然后Web Server 把客户端的请求交给php-cgi来处理,然后 php-cgi 载入程序脚本去处理客户请求,并生成相应html页面(大的字符串),最后 php-cgi 在把这个 html 页面返回给 Web Server 服务器。
3、Web Server 把 php-cgi 处理后的结果返回给客户端浏览器。
CGI FastCGI 和 PHP-FPM的区别
php常见配置项
display_errors: 设定PHP是否将任何错误信息包含在返回给Web服务器的数据流中,关闭之后错误信息不回在页面上显示
error_reposting: 显示错误的配置
error_reporting = E_ALL & ~E_NOTICE ; 除提示外,显示所有的错误。
post_max_size: POST方法提交数据的最大大小限制
file_uploads:允许/禁止 PHP开启HTTP文件上传(布尔)
upload_max_filesize:限制PHP处理上传文件的最大值,值小于post_max_size
max_file_uploads:设置每次最大上传文件数量
register_globals: 自动注册全局变量的。一般关闭。开启之后传递过来的值会被直接的注册为全局变量直接使用,不安全。
allow_url_fopen: 是否允许通过url打开文件,
allow_url_include: 是否允许通过include/require来执行一个远程文件。关闭。有安全漏洞
data.timezone: 设置时区的
safe_mode: 是否启用安全模式。

若有收获,就点个赞吧
0 人点赞
