本文由 简悦 SimpRead 转码, 原文地址 programmercarl.com
什么是链表
链表是一种通过指针串联在一起的线性结构,每一个节点是又两部分组成,一个是数据域一个是指针域(存放指向下一个节点的指针),最后一个节点的指针域指向 null(空指针)
链接的入口点称为链表的头结点也就是 head。
链表的几种类型:
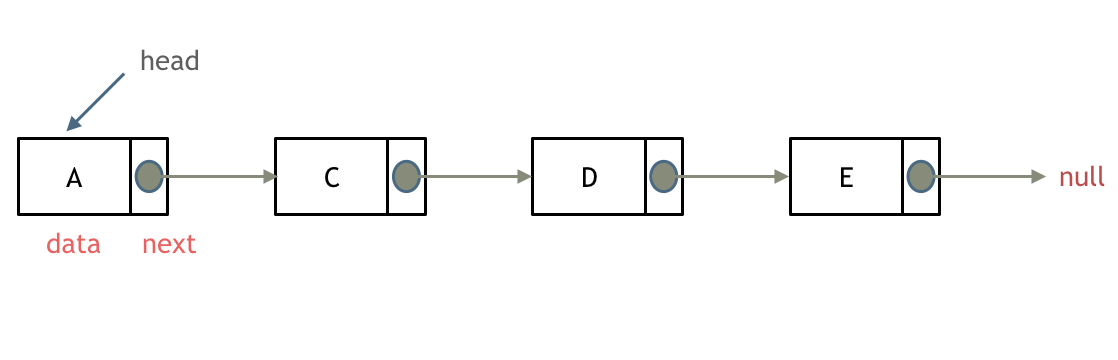
单链表
单链表中的节点只能指向节点的下一个节点。
上面说的就是单链表
双链表
双链表:每一个节点有两个指针域,一个指向下一个节点,一个指向上一个节点。
既可以向前查询也可以向后查询。
如图所示: 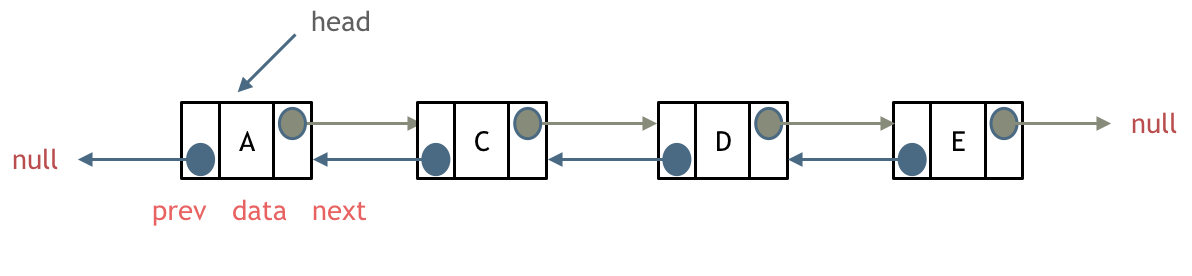
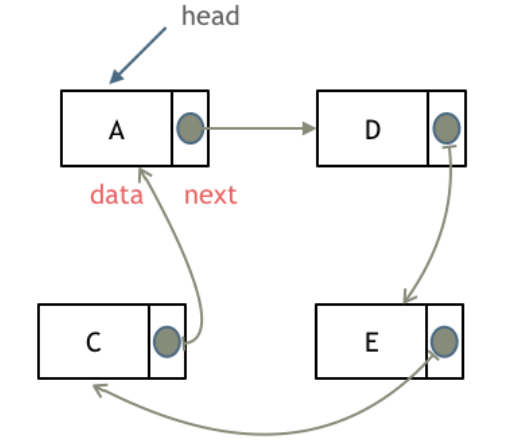
循环链表
链表首尾相连。
循环链表可以用来解决约瑟夫环问题。
链表在内存中的存储方式
数组是在内存中是连续分布的,
链表在内存中不是连续分布的。
链表是通过指针链接在内存中各个节点。所以链表中的节点是散乱分布在内存中的某地址上,分配机制取决于操作系统的内存管理
如图所示:
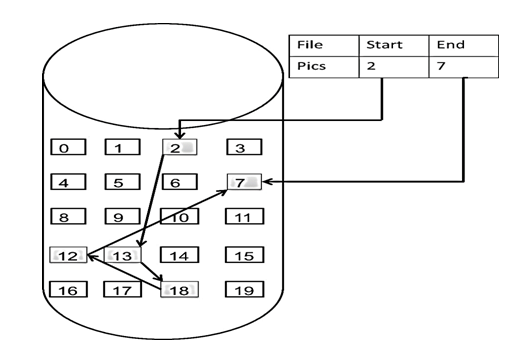
这个链表起始节点为 2, 终止节点为 7, 各个节点分布在内存中不同地址空间上,通过指针串联在一起。
链表的定义
在刷 leetcode 的时候,链表的节点都默认定义好了,直接用就行了,所以没有注意到链表的节点是如何定义的。
如何手写链表?
这里我给出 C/C++ 的定义链表节点方式,如下所示:
// 单链表struct ListNode {int val; // 节点上存储的元素ListNode *next; // 指向下一个节点的指针ListNode(int x) : val(x), next(NULL) {} // 节点的构造函数};
如果不定义构造函数,C++ 默认生成一个构造函数。
但是这个构造函数不会初始化任何成员变量,在初始化的时候就不能直接给变量赋值!
通过自己定义构造函数初始化节点:
ListNode* head = new ListNode(5);
使用默认构造函数初始化节点:
ListNode* head = new ListNode();head->val = 5;
链表的操作
删除节点
删除 D 节点,如图所示:
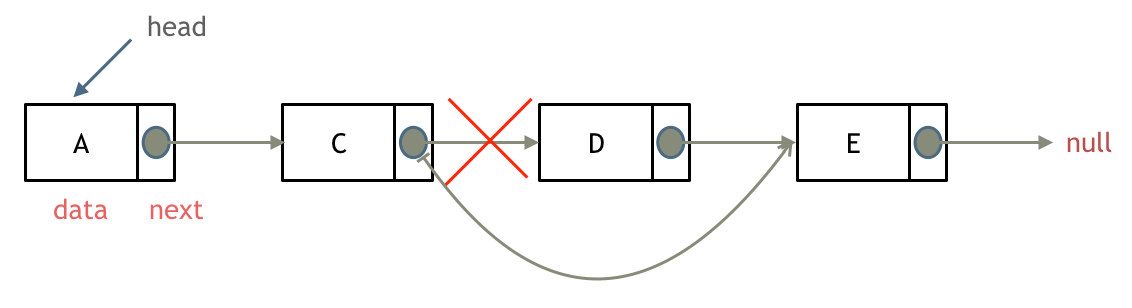
只要将 C 节点的 next 指针 指向 E 节点就可以了。
那有同学说了,D 节点不是依然存留在内存里么?只不过是没有在这个链表里而已。
是这样的,所以在 C++ 里最好是再手动释放这个 D 节点,释放这块内存。
其他语言例如 Java、Python,就有自己的内存回收机制,就不用自己手动释放了。
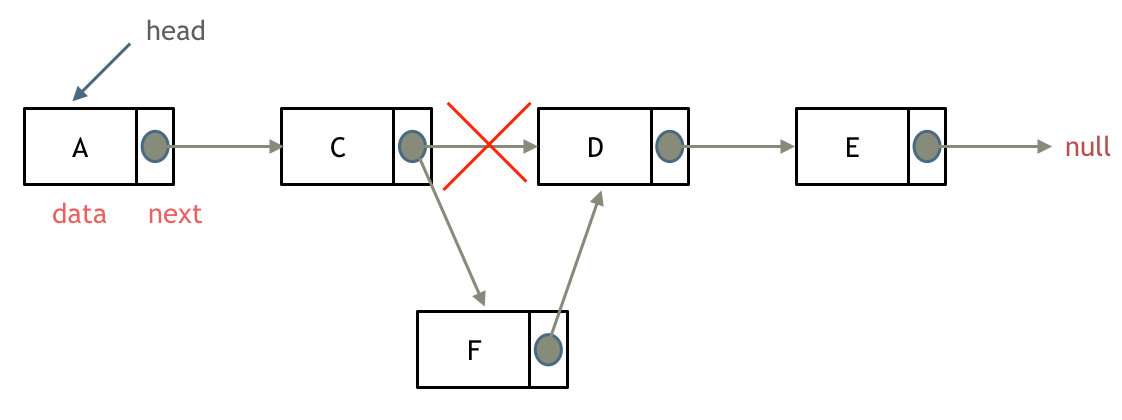
添加节点
如图所示:
时间复杂度
链表的插入,删除操作,或许会伴随着查找操作:
链表的插入,会告知在哪个节点插入,通过这个节点就能找到下一个节点,如果要在当前节点前面插入新的节点,那么就需要先进行遍历查找才能找到上一个节点,查找的复杂度是O(n);
如果是双链表直接就能找到上一个节点,所以插入的复杂度是O(1)
链表的删除,告知删除某一个节点,如果是单链表的话,不知道上一个节点是谁,所以需要先进行遍历查找,查找的复杂度是O(n);
如删除第五个节点,需要从头节点查找到第四个节点通过 next 指针进行删除操作,查找的时间复杂度是 O(n)
双向链表的话,就能知道上一个节点,无需进行查找操作。
链表 vs 数组
再把链表的特性和数组的特性进行一个对比,如图所示:
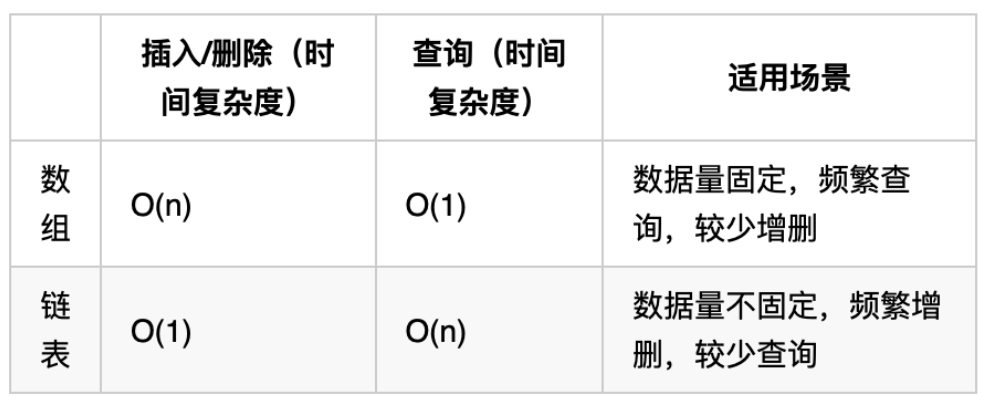
数组在定义的时候,长度就是固定的,如果想改动数组的长度,就需要重新定义一个新的数组。
链表的长度可以是不固定的,并且可以动态增删, 适合数据量不固定,频繁增删,较少查询的场景。

若有收获,就点个赞吧
0 人点赞
