https://www.yduba.com/biancheng-3962519476.html
冒泡排序是一种简单直观的排序算法,它重复地走访过要排序的数列,一次比较两个元素,如果它们的顺序错误就把它们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端。
作为最简单的排序算法之一,冒泡排序给我的感觉就像 Abandon 在单词书里出现的感觉一样,每次都在第一页第一位,所以最熟悉。冒泡排序还有一种优化算法,就是立一个 flag,当在一趟序列遍历中元素没有发生交换,则证明该序列已经有序。但这种改进对于提升性能来说并没有什么太大作用。
算法步骤
1. 比较相邻的元素。如果第一个比第二个大,就交换他们两个。
2. 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。在这一点,最后的元素应该会是最大的数。
3. 针对所有的元素重复以上的步骤,除了最后一个。
4. 持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
效率分析
若文件的初始状态是正序的,一趟扫描即可完成排序。所需的关键字比较次数C和记录移动次数M均达到最小值:C**min = n - 1, Mmin = 0,所以,冒泡排序最好的时间复杂度为O(n)。
若初始文件是反序的,需要进行n-1趟排序。每趟排序要进行 n-i 次关键字的比较(1 ≤ i ≤ n-1),且每次比较都必须移动记录三次来达到交换记录位置。在这种情况下,比较和移动次数均达到最大值:
Cmax = n(n-1)/2 = O(n2)
Mmax = 3n(n-1)/2 = O(n2)
冒泡排序的最坏时间复杂度为O(n**2),综上,因此冒泡排序总的平均时间复杂度为O(n**2)**。
算法稳定性
冒泡排序就是把小的元素往前调或者把大的元素往后调。比较是相邻的两个元素比较,交换也发生在这两个元素之间。所以,如果两个元素相等,我想你是不会再无聊地把他们交换一下的;如果两个相等的元素没有相邻,那么即使通过前面的两两交换把两个相邻起来,这时候也不会交换,所以相同元素的前后顺序并没有改变,所以冒泡排序是一种稳定排序算法。
动图演示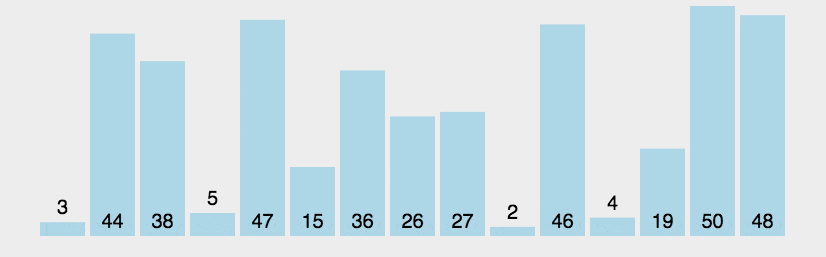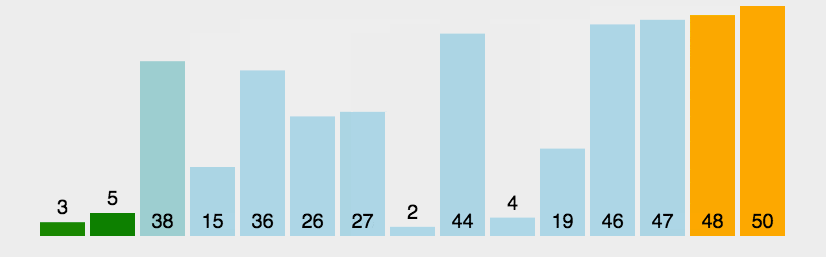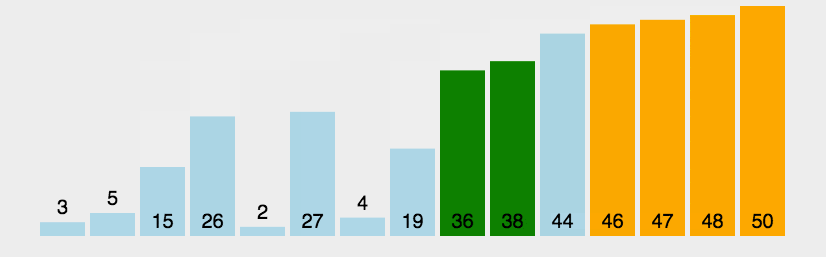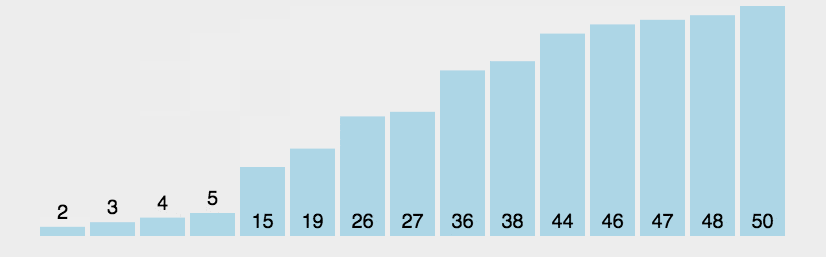
代码实现
<?phpfunction bubbleSort(array $numbers = array()){$count = count( $numbers );if( $count <= 1 ) return $numbers;for( $i = 0; $i < $count-1; $i ++ ){for( $j = 0; $j < $count-$i-1; $j ++ ){if( $numbers[$j] > $numbers[$j + 1] ){$temp = $numbers[$j];$numbers[$j] = $numbers[$j + 1];$numbers[$j + 1] = $temp;}}}return $numbers;}

若有收获,就点个赞吧
0 人点赞
