简介
- 索引是一种用于快速查询和检索数据的数据结构。常见的索引结构有: B 树, B+树和 Hash。
- 索引的效率取决于索引列的值是否散列,即该列的值如果越互不相同,那么索引效率越高。反过来,如果记录的列存在大量相同的值,那创建索引就无意义
mysql索引本质是可以让数据库系统不必扫描整个表,而是直接定位到符合条件的记录,所以直接查索引列速度最快
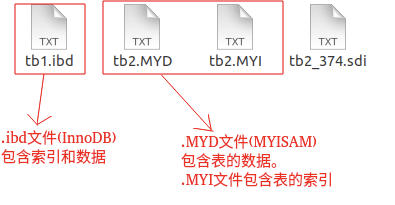
索引文件
优缺点
优点 :
- 使用索引可以大大加快 数据的检索速度(大大减少检索的数据量), 这也是创建索引的最主要的原因。
- 通过创建唯一性索引,可以保证数据唯一性
- 缺点 :
- 创建索引和维护索引需要耗费许多时间。当对表中的数据进行增删改的时候,如果数据有索引,那么索引也需要动态的修改,会降低 SQL 执行效率。
- 即牺牲增删改的时间换更快的查询时间
- 索引需要使用物理文件存储,也会耗费一定空间。
- 创建索引和维护索引需要耗费许多时间。当对表中的数据进行增删改的时候,如果数据有索引,那么索引也需要动态的修改,会降低 SQL 执行效率。
大多数情况下:使用索引查询都比全表查快,如果数据量不大,效果不明显
索引底层结构
这里的索引是指计算机科学中索引这一大的概念,而非特指mysql中的索引。
Hash表
hash表是键值对的集合。通过哈希算法,我们可以快速找到 key 对应的 index,找到了 index 也就找到了对应的 value。
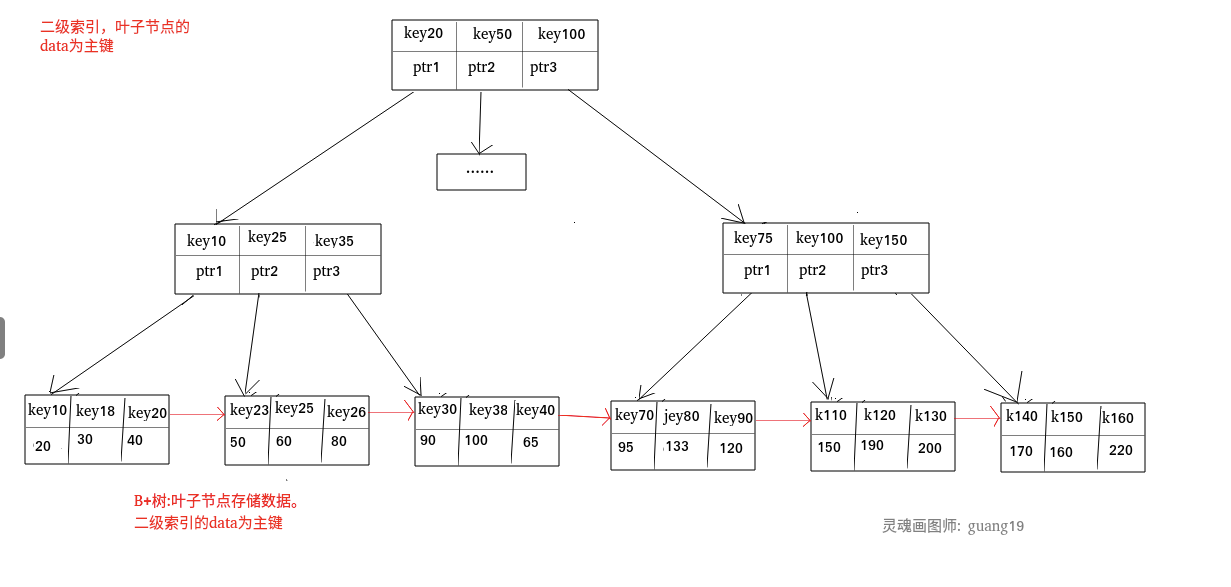
在 MySQL 中,MyISAM 引擎和 InnoDB 引擎都是使用 B+Tree 作为索引结构,但是,两者的实现方式不太一样。
- MyISAM 引擎中,B+Tree 叶节点的 data 域存放的是数据记录的地址。在索引检索的时候,首先按照 B+Tree 搜索算法搜索索引,如果指定的 Key 存在,则取出其 data 域的值,然后以 data 域的值为地址读取相应的数据记录。这被称为“非聚簇索引”。
- InnoDB 引擎中,其数据文件本身就是索引文件。相比 MyISAM,索引文件和数据文件是分离的,其表数据文件本身就是按 B+Tree 组织的一个索引结构,树的叶节点 data 域保存了完整的数据记录。这个索引的 key 是数据表的主键,因此 InnoDB 表数据文件本身就是主索引。这被称为“聚簇索引(或聚集索引)
- 其余的索引都作为辅助索引,辅助索引的 data 域存储相应记录主键的值而不是地址,这也是和 MyISAM 不同的地方。InnoDb在根据主索引搜索时,直接找到 key 所在的节点即可取出数据;在根据辅助索引查找时,则需要先取出主键的值,再走一遍主索引。(通过辅助索引找主键,然后主键找数据)
- 因此,在设计表的时候,不建议使用过长的字段作为主键,也不建议使用非单调的字段作为主键,这样会造成主索引频繁分裂。
- 叶子节点的k?即是主键索引与数据,而其他节点都是存储二级索引和主键索引的索引,以便尽快到达叶子节点
-
为什么选择B+
因为 B 树、Hash、红黑树或二叉树存在以下问题。
- B 树:不管叶子节点还是非叶子节点,都会保存数据,这样导致在非叶子节点中能保存的指针数量变少(有些资料也称为扇出),指针少的情况下要保存大量数据,只能增加树的高度,导致 IO 操作变多,查询性能变低。
- Hash:虽然可以快速定位,但是没有顺序,IO 复杂度高。
- 二叉树:树的高度不均匀,不能自平衡,查找效率跟数据有关(树的高度),并且 IO 代价高。
-
索引类型
主键索引
主键索引:一个表只能有一个主键,主键自带唯一,非空约束
在 MySQL 的 InnoDB 的表中,当没有显示的指定表的主键时,InnoDB 会自动先检查表中是否有唯一索引且不允许存在null值的字段,如果有,则选择该字段为默认的主键,否则 InnoDB 将会自动创建一个 6Byte 的rowid(行id)作为自增主键(不可见)
二级索引
二级索引又称为辅助索引,是因为二级索引的叶子节点存储的数据是主键。也就是说,通过二级索引,可以定位主键的位置。
- 如果就是根据二级索引的条件进行查询,那么就直接得到数据,不再进行回查(找主键查)。如
SELECT name FROM table WHERE name='guang19';name是二级索引
- 如果就是根据二级索引的条件进行查询,那么就直接得到数据,不再进行回查(找主键查)。如
- 二级索引有如下:
- 唯一索引:值不能重复但是能多个null。唯一索引可以有多个,建立唯一索引的目的一般不是为了查询速度而是为了数据唯一
- 唯一索引必须使用在具有
**unique**约束的列上
- 唯一索引必须使用在具有
- 普通索引:普通索引的唯一作用就是为了快速查询数据,一张表允许创建多个普通索引,并允许数据重复和 NULL。
- 普通索引可以使用在任何列上
- 查询时唯一和普通速度差不多,更新时因为唯一索引需要先将数据读取到内存,然后需要判断是否有冲突,因此比唯一索引要多了判断操作,从而性能就比普通索引性能要低。
- 前缀索引 :前缀索引只适用于字符串类型的数据。前缀索引是对文本的前几个字符创建索引,相比普通索引建立的数据更小, 因为只取前几个字符。
- 全文索引(Full Text) :全文索引主要是为了检索大文本数据中的关键字的信息,是目前搜索引擎数据库使用的一种技术。Mysql5.6 之前只有 MYISAM 引擎支持全文索引,5.6 之后 InnoDB 也支持了全文索引。
- 全文索引只能用于
CAHR、VARCHAR或TEXT类型。
- 全文索引只能用于
- 多列索引:上面的都是单列索引,多级索引指的是多个列组成的索引。但是只有查询条件使用了第一个列时索引才会生效
- 唯一索引:值不能重复但是能多个null。唯一索引可以有多个,建立唯一索引的目的一般不是为了查询速度而是为了数据唯一
为多列字段创建索引,此即多列索引 alter table 表 add index 索引名 (字段1,字段2…);
添加唯一约束但是不添加索引,不清楚和直接修改表结构添加约束的区别 alter table 表 add constraint uni_name unique (name);
删除索引 alert table 表 drop index 索引名
<a name="XBo7n"></a># <br /><a name="HRK2I"></a># 聚集/非聚集索引总结:聚集索引叶子节点的数据区域存的就是数据的位置。**而非聚集索引叶子节点的数据是主键的位置,然后找到主键叶子节点后,才能拿到数据的位置(直接走主键除外)**- **聚集即聚簇**- 聚集索引即索引结构和数据一起存放的索引**。主键索引属于聚集索引**。(如b+树中,对于 InnoDB 引擎表来说,该表的索引(B+树)的每个非叶子节点存储索引,叶子节点存储索引和索引对应的数据。)- 优点:- 聚集索引的查询速度非常的快,因为整个 B+树本身就是一颗多叉平衡树,叶子节点也都是有序的,定位到索引的节点,就相当于定位到了数据。- 缺点- 依赖于有序的数据 :因为 B+树是多路平衡树,如果索引的数据不是有序的,那么就需要在插入时排序,如果数据是整型还好,否则类似于字符串或 UUID 这种又长又难比较的数据,插入或查找的速度肯定比较慢。- 更新代价大 : **如果对索引列的数据被修改时,那么对应的索引也将会被修改,而且聚集索引的叶子节点还存放着数据,修改代价肯定是较大的,所以对于主键索引来说,主键一般都是不可被修改的。**---- 非聚集索引:即索引结构和数据分开存放的索引。**二级索引即非聚集索引,MyIsam也是非聚集索引**- 优点:- 更新代价比聚集索引要小 。非聚集索引的更新代价就没有聚集索引那么大了,非聚集索引的叶子节点是不存放数据的- 缺点- 跟聚集索引一样,非聚集索引也依赖于有序的数据- **可能会二次查询(回表) :**这应该是非聚集索引最大的缺点了。 当查到索引对应的指针或主键后,可能还需要根据指针或主键再到数据文件或表中查询。**主键是主键对应的指针即是数据**<a name="arUIV"></a># 覆盖索引- 如果一个索引包含(或者说覆盖)所有需要查询的字段的值,我们就称之为“覆盖索引”。我们知道在 InnoDB 存储引擎中,如果不是主键索引,叶子节点存储的是主键+列值。最终还是要“回表”,也就是要通过主键再查找一次。这样就会比较慢。**而覆盖索引就是把要查询出的列和索引是对应的,不做回表操作!**<a name="cDGpn"></a># 回表查询- **普通索引查询到主键索引后,回到主键索引树搜索的过程,我们称为回表查询。**<a name="qMcT6"></a># 主键id自增规则- mysql8之前myisam删除数据后新增不会重置主键id自增位置,innodb会- **mysql8之后innodb也不会重置**,可以使用`alter table 表名AUTO_INCREMENT=?;`重置自增位,下一次会从`?+1`的位置开始生成id<a name="ECoyX"></a># 索引失效的情况- **以 % 开头的 LIKE 查询**- 创建了组合索引,但查询条件**不满足 '最左匹配原则**'。如:创建索引 `idx_type_status_uid(type,status,uid)`,但是使用 status 和 uid 作为查询条件。如果使用`type+status`即会走索引(会走2个索引) 使用type和uid则会走一个索引列- **使用了**`**or**`**,且 or 的前后条件中有一个列没有索引,涉及的索引都不会被使用到**- **对于or可以使用**`**union**`**进行替换**- **在索引列上进行了操作,如or、!= (<>),not in 等操作和upper(大小写转换用的)等一些函数**- 隐式转换<a name="gGaDv"></a># 行级锁失效的情况- 如果一个表批量更新,大量使用行锁,可能导致其他事务长时间等待,严重影响事务的执行效率。此时,MySQL会将 行锁 升级为 表锁- 行级锁是针对索引加的锁,如果 条件索引失效,那么 行锁 也会升级为 表锁<a name="QLQT3"></a># 创建索引的规范- 1.选择合适的字段创建索引:- **不为 NULL 的字段** :索引字段的数据应该尽量不为 NULL,因为对于数据为 NULL 的字段,数据库较难优化。如果字段频繁被查询,但又避免不了为 NULL,建议使用 0,1,true,false 这样语义较为清晰的短值或短字符作为替代。- 被频繁查询的字段 :我们创建索引的字段应该是查询操作非常频繁的字段。- 被作为条件查询的字段 :被作为 WHERE 条件查询的字段,应该被考虑建立索引。- 频繁需要排序的字段 :索引已经排序,这样查询可以利用索引的排序,加快排序查询时间。- 被经常频繁用于连接的字段 :经常用于连接的字段可能是一些外键列,对于外键列并不一定要建立外键,只是说该列涉及到表与表的关系。对于频繁被连接查询的字段,可以考虑建立索引,提高多表连接查询的效率。2.被频繁更新的字段应该慎重建立索引。- 虽然索引能带来查询上的效率,但是维护索引的成本也是不小的。 如果一个字段不被经常查询,反而被经常修改,那么就更不应该在这种字段上建立索引了。3.尽可能的考虑建立联合索引而不是单列索引。- 因为索引是需要占用磁盘空间的,可以简单理解为每个索引都对应着一颗 B+树。如果一个表的字段过多,索引过多,那么当这个表的数据达到一个体量后,索引占用的空间也是很多的,且修改索引时,耗费的时间也是较多的。如果是联合索引,多个字段在一个索引上,那么将会节约很大磁盘空间,且修改数据的操作效率也会提升。4.注意避免冗余索引 。- 冗余索引指的是索引的功能相同,能够命中索引(a, b)就肯定能命中索引(a) ,那么索引(a)就是冗余索引。如(name,city )和(name )这两个索引就是冗余索引,能够命中前者的查询肯定是能够命中后者的 在大多数情况下,都应该尽量扩展已有的索引而不是创建新索引。5.考虑在字符串类型的字段上使用前缀索引代替普通索引。- 前缀索引仅限于字符串类型,较普通索引会占用更小的空间,所以可以考虑使用前缀索引带替普通索引<a name="M49A1"></a># 使用索引的一些建议- 对于中到大型表索引都是非常有效的,但是特大型表的话维护开销会很大,不适合建索引- 数据量小的表可以无需使用索引- **避免 where 子句中对字段使用函数**,这会造成无法命中索引。- 在使用 InnoDB 时使用与业务无关的自增主键作为主键,即使用逻辑主键,而不要使用业务主键。- **删除长期未使用的索引**,不用的索引的存在会造成不必要的性能损耗 MySQL 5.7 可以通过查询 sys 库的 schema_unused_indexes 视图来查询哪些索引从未被使用- 在使用 limit offset 查询缓慢时,可以借助索引来提高性能<a name="VfJzL"></a># 表空间```sql什么是独立表空间和共享表空间?它们的区别是什么:共享表空间指的是数据库的所有表数据,索引文件全部放在一个文件中,默认这个共享表空间的文件路径在 data 目录下。 独立表空间:每一个表都将会生成以独立的文件方式来进行存储。共享表空间和独立表空间最大的区别是如果把表放再共享表空间,即使表删除了空间也不会删除,因此表依然很大,而独立表空间如果删除表就会清除空间。
最左匹配原则
- 就是多列索引中的索引生效原则
- 最左匹配原则也叫最左前缀原则,是 MySQL 中的一个重要原则,指的是索引以最左边为起点任何连续的索引都能匹配上,当遇到范围查询(>、<、between、like)就会停止匹配。 生效原则来看以下示例,比如表中有一个联合索引字段 index(a,b,c): ```sql where a=1 只使用了索引 a;
where a=1 and b=2 只使用了索引 a,b;
where a=1 and b=2 and c=3 使用a,b,c;
where b=1 or where c=1 不使用索引;
where a=1 and c=3 只使用了索引 a;
where a=3 and b like ‘xx%’ and c=3 只使用了索引 a,b。 ```
explain
explain sql语句可以分析一个sql的执行过程中的参数以便优化 | 字段 | 说明 | | —- | —- | | id | 选择标识符,id 越大优先级越高,越先被执行 | | select_type | 表示查询的类型。 | | table | 输出结果集的表 | | partitions | 匹配的分区 | | type | 表示表的连接类型 | | possible_keys | 表示查询时,可能使用的索引 | | key | 表示实际使用的索引 | | key_len | 索引字段的长度 | | ref | 列与索引的比较 | | rows | 大概估算的行数 | | filtered | 按表条件过滤的行百分比 | | Extra | 执行情况的描述和说明 |
其中最重要的就是 type 字段,type 值类型如下:
| type 值 | 说明 |
|---|---|
| all | 扫描全表数据 |
| index | 遍历索引 |
| range | 索引范围查找 |
| index_subquery | 在子查询中使用 ref |
| unique_subquery | 在子查询中使用 eq_ref |
| ref_or_null | 对 null 进行索引的优化的 ref |
| fulltext | 使用全文索引 |
| ref | 使用非唯一索引查找数据 |
| eq_ref | 在 join 查询中使用主键或唯一索引关联 |
| const | 将一个主键放置到 where 后面作为条件查询, MySQL 优化器就能把这次查询优化转化为一个常量,如何转化以及何时转化,这个取决于优化器,这个比 eq_ref 效率高一点 |

若有收获,就点个赞吧
0 人点赞
