规则执行顺序
- 一个查询语句中from如果有多个规则,如有where 有group 有分页…。先执行最左边的,然后对左边第一个规则的结果再执行第二个规则….
连接> where > group by >having>排序 >分页 聚合函数位置不定,但是一般都是位于where having里
基本查询
单表查询
部分字段查询
select 字段1,字段2... from 表;-
投影查询
输出部分字段的操作就叫做投影查询
- 通过
**select**后面的字段的先后顺序可以指定结果集的字段顺序 - 通过设置别名可以指定结果集的字段名,结果集不会输出为原来的字段名
字段1 别名,字段2 别名...在字段后空格 别名即可添加一个别名- 实际上是
**字段1 as 别名**但是as可以省略
- 还可以给表设置别名,然后使用别名来引用字段,可以简化命令
students.id 学号,students.name 姓名,... from students;->s.id 学号,s.name 姓名,... from students s;- 连接查询
join 表那里也可以设置别名
- 连接查询
- 结果集出现重名字段时最好设置别名以区分,特别是在多表查询时,
- 重名时输出*可以输出,但是输出重名字段则必须进行表引用才能区分
```sql
students表: id class_id name gender score
select score,id 学号 from students;
- 重名时输出*可以输出,但是输出重名字段则必须进行表引用才能区分
```sql
students表: id class_id name gender score
输出: 实现了部分输出,指定输出顺序(先输出了score),别名(将id输出为了学号) +———-+———+ | score | 学号 | +———-+———+ | 90 | 1 | | 95 | 2 | | 88 | 3 | +———-+———+ ```
排序
- 在查询语句末尾添加
order by 字段 [desc]排序在where后面order by顺序,低到高 其实这是省略了的,完整是order by ... ascorder by ... desc倒叙,高到低
如果第一次排序出现重复,可以增加字段表示重复再根据剩余字段进行排序
查询语句末尾添加子句
limit n offset m- 可以简写为
limit n,m - 分页子句位置顺序<排序<where 即先where,再对where结果进行排序,最后再进行分页
- m指的是查询时跳过前m条数据,对剩下的数据进行分页
- m是可选的,不写时默认为是
offset 0 - 一般是用于查询指定某页,如n为3,查询第三页,就跳过前2页,即m为6(2*3)
- m大于全部数据时,得到空结果集
Empty result set
- m是可选的,不写时默认为是
- n指的是一页的数据数量
- m指的是查询时跳过前m条数据,对剩下的数据进行分页
- 一页数量不足n时,就按照实际数据数量输出,一般都是末尾页会出现这种情况。所以n实际上指的是一页最多的数据量
limit只有一个参数时即只输出指定前n条数据 如
limit 2输出前2条聚合查询
聚合查询即使用
聚合函数快速进行一些统计操作的查询- 聚合查询不能用于where后,where是顺序最前的子句关键字,所以只要用了where就不能再在后面用聚合。having例外
- 聚合结果会直接拼接在正常字段结果集后,即聚合查询可以和普通字段一起使用
count(*)得到结果集的数据行数,得到的是字段名为count的数字- 建议给
**count(*)**设置别名,如select count(*) 总数 from ...; - count(*)会统计含null值的数据,即便一条数据全是null值也会统计
count(字段)则只统计该字段不为null的数据数- count(1) 结果等同于count(*),不过速度上有一点点差异,不必纠结,知道有这么个东西就行
- 建议给
sum(...)计算某一列的合计值,该列必须为数值类型avg(...)计算某一列的平均值,该列必须为数值类型max(...)计算某一列的最大值min(...)计算某一列的最小值ceiling()向上取整 如select ceiling(count(*) / 3) from students;表示计算limit 3,0时students会有多少页floor()向下取整
- 要特别注意:如果聚合查询的WHERE条件没有匹配到任何行,COUNT()会返回0,而SUM()、AVG()、MAX()和MIN()会返回NULL
时间函数,可以用于where
其实就是对结果集进行拆分分组,分组后对于输出和条件表达式均生效。即from前后都生效。
- 分组后使用聚合就是对每一组都进行一次聚合查询
- 此时avg,max,min得到的还是那一组相同的值,如第一组有4个2,无论是平均,最大最小,还是2
- 分组查询输出的正常字段只能是被分组的字段,否则会得到错误的结果
- 如下,name输出的就是每组数组的第一个name。按逻辑应该是右边的样子,但是sql引擎不允许多个数据放进一条数据中
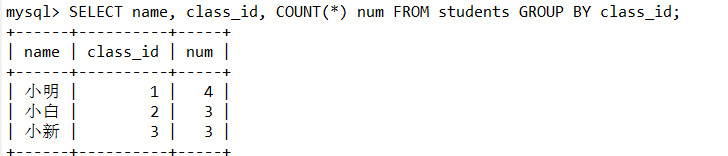

- 但是可以对多个字段分组达到右边的效果,这样就可以输出name。这里因为每个人姓名不一样,最后得到的就是每个班不同名字的为一组,没什么实际意义,以如下举例:
select class_id, gender, count(*) num from students group by class_id, gender;以每个班的男女生各一组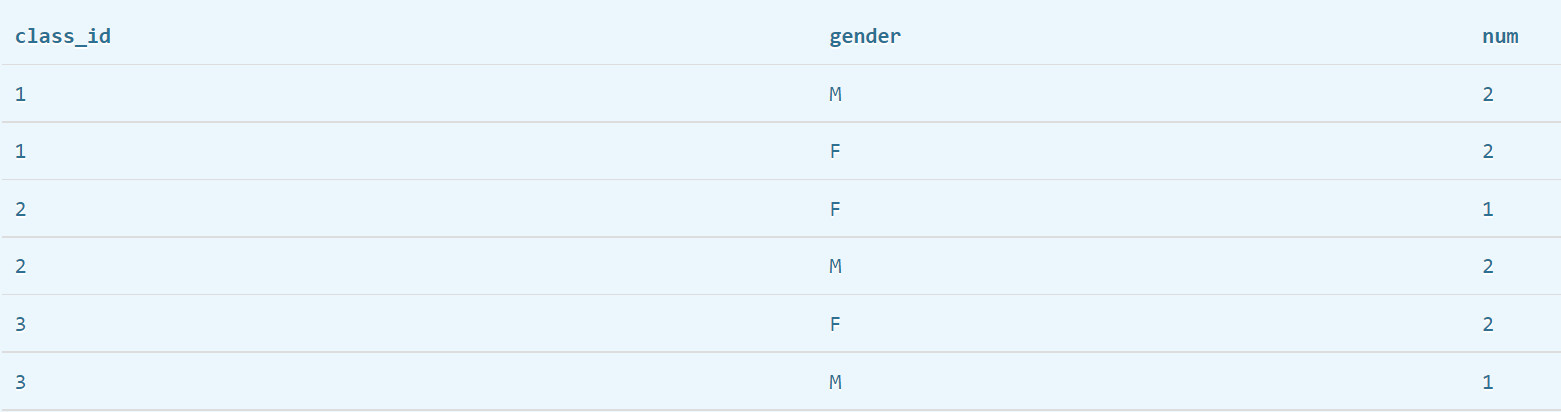
得到1班男生有2人,女生有2人。2班男生有1人……
- 增加子句
group by ...字段值相同的会拆分为一组,输出为一条数据。- 如
select class_id,count(*) num from students group by class_id;对学生表中同班的进行分组。得到:
- 如

union
SELECT ... UNION [ALL|DISTINCT] SELECT ...[union ....] 可以使用()包裹每个select
可以将列数相同的查询拼接行在另外一个表结果后
having作用是对分组查询的结果再次进行条件查询(这时直接条件表达式即可,无需where) 、
select 字段 from 表 where 条件表达式where 1=1表示始终为真,但是不过滤,所以输出全部 常常用于条件拼接,以便直接接and ...where 1=2则where始终为假,返回空数据,不知道干啥用的exists
exists和not exists:and &&且,必须都满足or ||或,满足一项即可not !非,都不满足的,等同于**<>**一般用**<>**更多,not不怎么用常用的条件表达式
| 条件 | 表达式举例1 | 表达式举例2 | 说明 | | —- | —- | —- | —- | | = | score = 80 | name = ‘abc’ | 字符串需要用单引号括起来 | | > | score > 80 | name > ‘abc’ | 字符串比较根据ASCII码,中文字符比较根据数据库设置 | | >= | score >= 80 | name >= ‘abc’ | | | < | score < 80 | name <= ‘abc’ | | | <= | score <= 80 | name <= ‘abc’ | | | <>不相等 !=也有不相等的作用,但是不建议使用 | score <> 80 | name <> ‘abc’ | | | 使用like判断相似 | name LIKE ‘ab%’ | name LIKE ‘%bc%’ | %表示任意字符,例如’ab%’将匹配’ab’,’abc’,’abcd’ |
- between value1 and value2
作用相当于where 列``**>=**``value1 and 列``**<=**``value2
- 可以not取反表示取范围外的值
SELECT * FROM students WHERE ``score`` BETWEEN 60 AND 70;
还可以是字符,如between 'a' and 'z'
in
查询一个表的字段在in()中的记录(只能对一个字段进行匹配)
- 值直接作纪录集:
... where 字段 in (value1,value2,...) - 查询语句结果集作in纪录集:
... where 字段 in(查询语句)- 只有in才能获取select的结果,所以如
where number>(select count(*) ...)这样是错误的- 基于这个能力我们可以把复杂问题简单化,拆分为多个子查询 通过in不断组装
- in()内的查询语句只能是返回一个字段的结果集的语句
- 只有in才能获取select的结果,所以如
- 当()中的值或者语句返回数据数为1时,=和in等级
上面的都是对某一列进行查询,还有一种方式可以对多列进行查询
匹配null时不能使用
=null或者<>null而是is null或者is not null-
函数/表达式额外输出
select */列``** ,**`` (kaoshi * 0.6+pingshi) as 'zongchengji' from 表名;在列/旁边在输出一个总成绩列,考试列的值0.6再加上平时分列的值,作为总成绩的值某列不重复数据查询
select distinct 字段 from 表名;重复的数据只会输出一个多表查询
多表查询得到的结果集是多表的乘机,即多表不同字段间进行拼接的结果。结果集列数是多表列数之和,行数是多表行数之积;所以结果集很容易非常大。所以要小心使用。
- 可以通过条件查询剔除不必要数据
- 多表查询只要不是输出全部表的全部数据,就必须使用
表.字段/*的形式- 如果输出全部表的全部数据,可以没必要加
表.
- 如果输出全部表的全部数据,可以没必要加
- 多个表使用,分隔
连接查询
- 连接查询是另一种类型的多表查询。连接查询简单地说,就是先确定一个主表作为结果集,然后,把其他表的行有选择性地“连接”在主表结果集上。即多表查询是列数相加,连接查询是列数相加减一
- 连接逻辑是以主表的一个字段映射为另外一个表的某个字段,然后在主表该字段后添加另外一个表的其他数据
- 如主表
学号 性别 班级号 性别副表班级id 班级名称映射班级号对应副本班级号 得到学号 性别 班级号(班级id) 班级名称 性别
- 如主表
- 连接逻辑是以主表的一个字段映射为另外一个表的某个字段,然后在主表该字段后添加另外一个表的其他数据
- 使用方法:
...from 主表 连接类型 join 附表 on 主表字段=副表字段
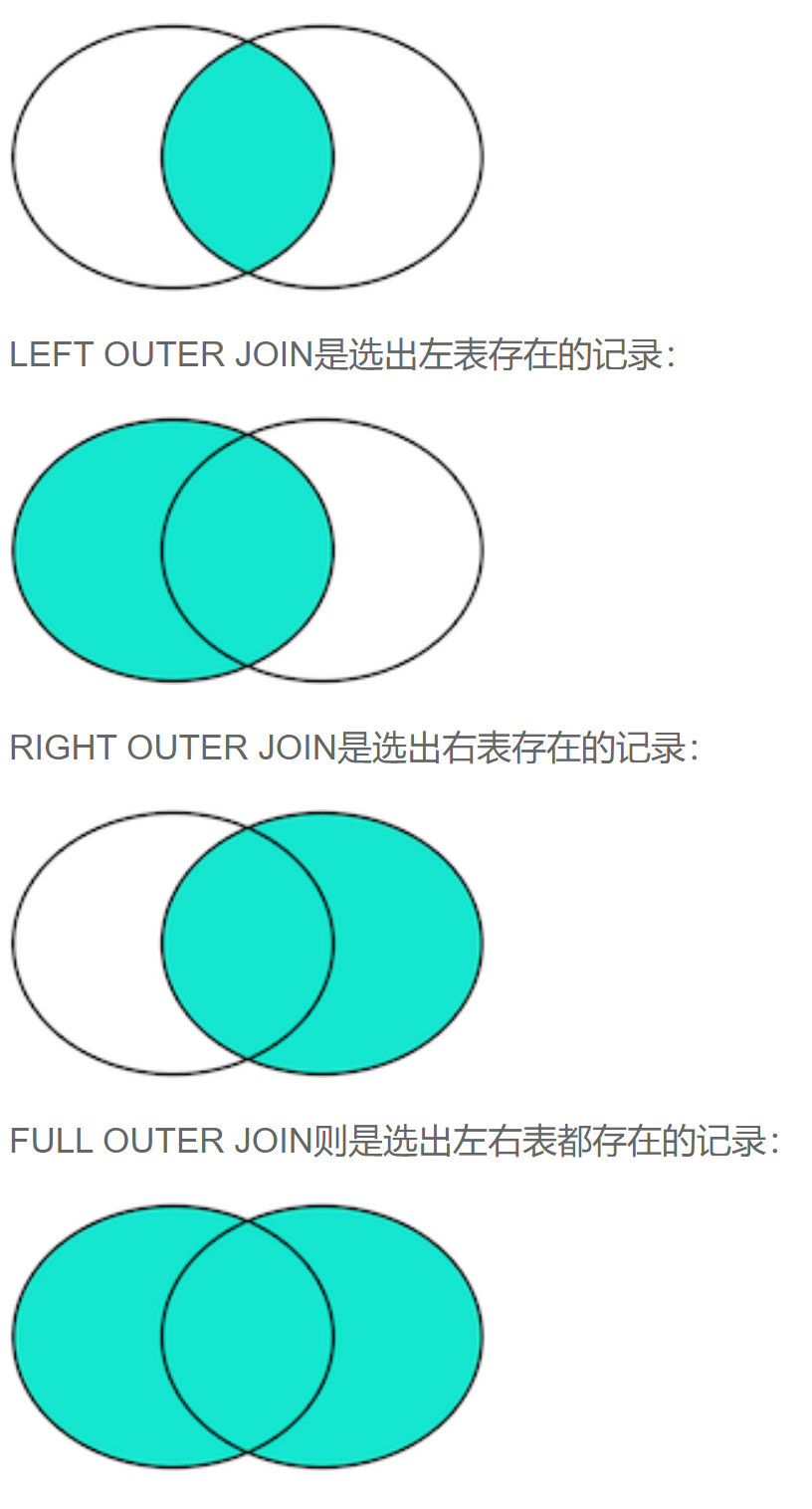
- 共用四种连接
内连接左外连接右外连接全连接(全外连接)- 内联
inner join - 左外连
left outer join如on a.id=b.id如果a得到的id为1,2,3 b得到的id为2,3,4 那么以左表a为主,b表中的id为3,4的数据会正常连接。而结果集中id为1的连接数据有关b表字段的部分都是null;右外连和全连同理 - 右外连
right outer join - 全连接
full outer join
- 内联
子查询
from

若有收获,就点个赞吧
0 人点赞
