数据库简介
- 数据库>数据表>数据
- SQL就是访问和处理关系数据库的计算机标准语言
- 数据库有3中存储模型:层次模型 网状模型 关系模型。其中关系模型占据了绝对的份额(因为关系模型理解和使用起来最简单)
- MySQL默认不区分大小写。而且不仅仅是表名,列名不区分。字段值也不区分大小写
- 数据库连接端口:3306
- 数据库默认存储引擎:InnoDB
information_schema、mysql、performance_schema和sys是系统自带的数据库,不要去改动它们数据库配置
字符集
mysql中的utf-8并非标准意义的utf-8,utf8mb4才是,mysql中的utf8其实全程为
utf8mb3-
大小写敏感设置
数据类型
- 数据类型有数值,字符串,时间等
- 选择最小的可用类型,如果值永远不超过127,则使用TINYINT要比使用INT好
- 从速度方面考虑,要选择固定的列,可以使用CHAR类型。
- 要节省空间,使用动态的列,可以使用VARCHAR类型。
| 名称 | 类型 | 说明 |
| —- | —- | —- |
| INT | 整型 | 4字节整数类型,范围约+/-21亿 |
| BIGINT(long) | 长整型 | 8字节整数类型,范围约+/-922亿亿 |
| REAL 又可写作FLOAT24 | 浮点型 | 4字节浮点数,范围约+/-1038 |
| DOUBLE | 浮点型 | 8字节浮点数,范围约+/-10308 |
| DECIMAL(M,N) | 高精度小数 | 由用户指定精度的小数,例如,DECIMAL(20,10)表示一共20位,其中小数10位,通常用于财务计算 |
| CHAR(N)注意SQL中的char是字符串 | 定长字符串 | 存储指定长度的字符串,例如,CHAR(100)总是存储100个字符的字符串 |
| VARCHAR(N) | 变长字符串 | 存储可变长度的字符串,例如,VARCHAR(100)可以存储0~100个字符的字符串 |
| BOOLEAN | 布尔类型 | 存储True或者False |
| DATE | 日期类型 | 存储日期,例如,2018-06-22 |
| TIME | 时间类型 | 存储时间,例如,12:20:59 |
| DATETIME | 日期和时间类型 | 存储日期+时间,例:2018-06-22 12:20:59 |
| YEAR | 年份 | 可以指定年份限制 |
| DATESTAMP | 日期与时间 | 跟datetime不同在于,
- datestamp会根据设置的时区自动变化,
- 且stamp只存储1970-2038内的数据,所以stamp更加轻量
|
对应表
- https://blog.csdn.net/qiunian144084/article/details/87099425
- mysql有数据类型可以存储媒体文件,不过不是很合适,原理自然是保存为二进制文件。
-
数据引擎
mysql本身实际上只是一个SQL接口,数据引擎相当于接口实现。
- 数据引擎又称为存储引擎
5.5前MyISAM 引擎是 MySQL 的默认存储引擎。之后默认的引擎是_InnoDB(_事务性数据库引擎_)_
- MyISAM 的性能还行,各种特性也还不错。
- 但是MyISAM 不支持事务和行级锁(myisam为表级锁)和外键,而最大的缺陷就是崩溃后无法安全恢复,所以被淘汰
- innoDB行级锁和表级锁均支持,默认为行级锁
- innoDb最核心的功能就是事务与外键
- 表级锁:貌似是不能同时对一张表进行写入。行锁类似
- MyISAM 总的来说查询性能比InnoDB高,但是InnoDB 主键查询性能高于 MyISAM。
- MyISAM 支持 FULLTEXT 类型的全文索引,InnoDB 不支持 FULLTEXT 类型的全文索引,但是 InnoDB 可以使用 sphinx 插件支持全文索引,并且效果更好;
- MVCC 可以看作是行级锁的一个升级,可以有效减少加锁操作,提供性能
使用 InnoDB 的数据库在异常崩溃后,数据库重新启动的时候会保证数据库恢复到崩溃前的状态。这个恢复的过程依赖于
redo log**(重做日志)**MySQL 日志 主要包括错误日志、查询日志、慢查询日志、事务日志、二进制日志几大类。
用来记录 MySQL 服务器运行过程中的错误信息。
又叫通用日志,
general log查询日志里面记录了数据库执行的所有命令,不管语句是否正确,都会被记录,具体原因如下、慢查询会导致 CPU、IOPS、内存消耗过高,当数据库遇到性能瓶颈时,大部分时间都是由于慢查询导致的。开启慢查询日志,可以让 MySQL 记录下查询超过指定时间的语句
默认情况下,慢查询日志是不开启的
set global general_log=1set global log_output=‘table’;#使用 set global slow_query_log='ON' 开启慢查询日志,只是对当前数据库有效,如果 MySQL 数据库重启后就会失效。因此如果要永久生效,就要修改配置文件 my.cnf,设置 slow_query_log=1 并重启 MySQL 服务器。
重做日志
redo log:innodb独有的日志/。保证数据的完整性和持久性。本质是mysql采用了这样一种缓存机制,先将数据写入内存中,再批量把内存中的数据统一刷回磁盘。为了避免将数据刷回磁盘过程中,因为掉电或系统故障带来的数据丢失问题回滚日志
用于存储日志被修改前的值,从而保证如果修改出现异常,可以使用 undo log 日志来实现回滚操作。
undo log 和 redo log 记录物理日志不一样,它是逻辑日志,可以认为当 delete 一条记录时,undo log 中会记录一条对应的 insert 记录,反之亦然,当 update 一条记录时,它记录一条对应相反的 update 记录,当执行 rollback 时,就可以从 undo log 中的逻辑记录读取到相应的内容并进行回滚。undo log 默认存放在共享表空间中,在 MySQL 5.6 中,undo log 的存放位置还可以通过变量 innodb_undo_directory 来自定义存放目录,默认值为「.」表示 datadir 目录。
二进制日志
即bin log,又叫归档日志。是一个二进制文件,主要记录所有数据库表结构变更,比如,CREATE、ALTER TABLE 等,以及表数据修改,比如,INSERT、UPDATE、DELETE 的所有操作,bin log 中记录了对 MySQL 数据库执行更改的所有操作,并且记录了语句发生时间、执行时长、操作数据等其他额外信息。但是它不记录 SELECT、SHOW 等那些不修改数据的 SQL 语句
- 和redo log的区别:
- redo log 是物理日志,记录的是「在某个数据页上做了什么修改」;
- binlog 是逻辑日志,记录的是这个语句的原始逻辑,比如「给 ID=2 这一行的 c 字段加 1」;
- redo log 是 InnoDB 引擎特有的,binlog 是 MySQL 的 Server 层实现的,所有引擎都可以使用;
- redo log 是循环写的,空间固定会用完,binlog 是可以追加写入的,「追加写」是指 binlog 文件写到一定大小后会切换到下一个,并不会覆盖以前的日志。
- 这个日志有如下作用:
- 恢复数据库
- 拷贝数据库
- 审计:可以通过日志文件分析是否有过sql注入等信息
- 配合redo log保证数据完整性:在开启 binlog 的情况下,为了保证 binlog 与 redo 的一致性,MySQL 将采用事务的两阶段提交协议。当 MySQL 系统发生崩溃时,事务在存储引擎内部的状态可能为 prepared(准备状态)和 commit(提交状态)两种,对于 prepared 状态的事务,是进行提交操作还是进行回滚操作,这时需要参考 binlog,如果事务在 binlog 中存在,那么将其提交;如果不在 binlog 中存在,那么将其回滚,这样就保证了数据在主库和从库之间的一致性。
- binlog 默认是关闭状态,可以在 MySQL 配置文件(my.cnf)中通过配置参数 log-bin = [base-name] 开启记录 binlog 日志,如果不指定 base-name,则默认二进制日志文件名为主机名,并以自增的数字作为后缀,比如:mysql- bin.000001,所在目录为数据库所在目录(datadir)
- binlog日志格式分为 STATEMENT、ROW 和 MIXED 三种:
- STATEMENT 格式的 binlog 记录的是数据库上执行的原生 SQL 语句。这种格式的优点是简单且节省空间。但是对于某些sql不适合,入sql里存在获取当前时间戳
- ROW 格式是从 MySQL 5.1 开始支持基于行的复制,这种方式会将实际数据记录在二进制日志中,它有其自身的一些优点和缺点,最大的好处是可以正确地复制每一行数据。缺点是二进制日志可能会很大。
- 是主流的方式,优远大于弊
- MIXED:默认采用STATEMENT 的语句方式,如果碰到无法确定的sql,就采用ROW的行数据的方式
show variables like ‘log_%’;
其他问题
时区问题
MySQL8后引入了时区设置
DBeaver作为连接MySQL的客户端为例子
选中数据库连接->右键编辑连接(F4)->连接设置->驱动属性
找到名称为serverTimeZone,设置值为Asia/Shanghai
点击确定保存设置后,重新执行sql,时间显示恢复正确。
数据库连接也恢复正常
打开sql命令行
输入set global time_zone=’+8:00’;即可
MySQL服务不能启动问题
该问题表现为命令行中找不到或者无法启动mysql。打开mysql自带命令窗口,输入密码后即便密码正确也会自动退出。这种情况一般是mysql未启动。
解决:可以去计算机服管理-服务-mysql找到mysql,右键属性将其启动。
mysql控制台中可以登录,但是navicat无法连接,这是由于mysql的加密方式不能被navicat识别导致。
- mysql8 之前,加密规则是
mysql_native_password;
mysql8 之后,加密规则是caching_sha2_password```java 1:以管理员身份登录控制台
- mysql8 之前,加密规则是
ALTER USER ‘root’@’localhost’ IDENTIFIED BY ‘password’ PASSWORD EXPIRE NEVER;
修改加密规则
ALTER USER ‘root’@’localhost’ IDENTIFIED WITH mysql_native_password BY ‘password’;
更新一下用户的密码,这里密码不用改,照抄
FLUSH PRIVILEGES; #刷新权限
alter user ‘root’@’localhost’ identified by ‘密码’; #重置密码,输入自己要的密码,此时密码就以新的加密方式进行存储 ```
存储过程
- 存储过程即一系列sql语句的集合
- 常用的sql存为存储过程后方便下次调用
- 而且比重新写然后执行速度更快,因为存储过程会被预编译,即存储过程是已经被编译过的代码块
-
sql执行过程
简单来说分为2层:
- Server 层:主要包括连接器、查询缓存、分析器、优化器、执行器等,所有跨存储引擎的功能都在这一层实现,比如存储过程、触发器、视图,函数等,还有一个通用的日志模块 binlog 日志模块。
- 存储引擎: 主要负责数据的存储和读取,采用可以替换的插件式架构,支持 InnoDB、MyISAM、Memory 等多个存储引擎,其中 InnoDB 引擎有自有的日志模块 redolog 模块。现在最常用的存储引擎是 InnoDB,它从 MySQL 5.5.5 版本开始就被当做默认存储引擎了
- Server主要组成如下:
- 连接器: 身份认证和权限相关(登录 MySQL 的时候)。
- 查询缓存: 执行查询语句的时候,会先查询缓存(MySQL 8.0 版本后移除,因为这个功能不太实用)。
- 分析器: 没有命中缓存的话,SQL 语句就会经过分析器,分析器说白了就是要先看你的 SQL 语句要干嘛,再检查你的 SQL 语句语法是否正确。
- 优化器: 按照 MySQL 认为最优的方案去执行。
- 执行器:选择了执行方案后,MySQL 就准备开始执行了,首先执行前会校验该用户有没有权限,如果没有权限,就会返回错误信息,如果有权限,就会去调用引擎的接口,返回接口执行的结果
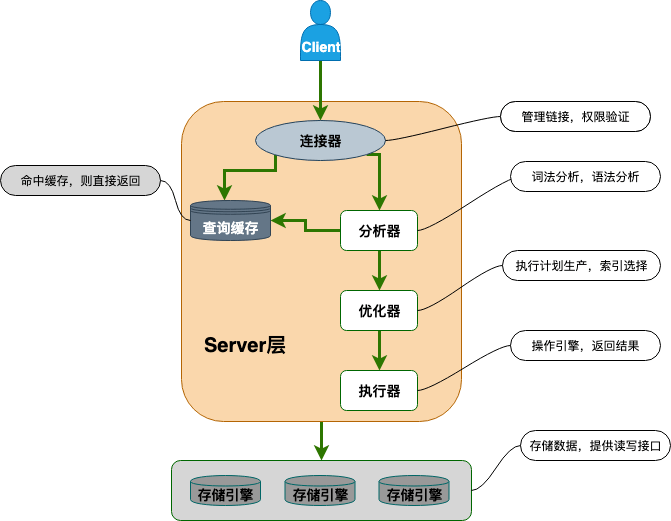
具体分析
mysql数据语句大致就分为2种:一种是查询,一种是更新(包括增加,修改,删除)
查询
select * from tb_student A where A.age='18' and A.name=' 张三 ';- 先检查该语句是否有权限,如果没有权限,直接返回错误信息,如果有权限,在 MySQL8.0 版本以前,会先查询缓存,以这条 sql 语句为 key 在内存中查询是否有结果,如果有直接缓存,如果没有,执行下一步。
- 通过分析器进行词法分析,提取 sql 语句的关键元素,比如提取上面这个语句是查询 select,提取需要查询的表名为 tb_student,需要查询所有的列,查询条件是这个表的 id=’1’。然后判断这个 sql 语句是否有语法错误,比如关键词是否正确等等,如果检查没问题就执行下一步。
- 接下来就是优化器进行确定执行方案,上面的 sql 语句,可以有两种执行方案: a.先查询学生表中姓名为“张三”的学生,然后判断是否年龄是 18。 b.先找出学生中年龄 18 岁的学生,然后再查询姓名为“张三”的学生。 那么优化器根据自己的优化算法进行选择执行效率最好的一个方案(优化器认为,有时候不一定最好)。那么确认了执行计划后就准备开始执行了。
- 进行权限校验,如果没有权限就会返回错误信息,如果有权限就会调用数据库引擎接口,返回引擎的执行结果
更新
update tb_student A set A.age='19' where A.name=' 张三 ';- 其实这条语句也基本上会沿着上一个查询的流程走,只不过执行更新的时候肯定要记录日志啦,这就会引入日志模块了,MySQL 自带的日志模块是 binlog(归档日志) ,所有的存储引擎都可以使用,我们常用的 InnoDB 引擎还自带了一个日志模块 redo log(重做日志),我们就以 InnoDB 模式下来探讨这个语句的执行流程。流程如下:
- 先查询到张三这一条数据,如果有缓存,也是会用到缓存。
- 然后拿到查询的语句,把 age 改为 19,然后调用引擎 API 接口,写入这一行数据,InnoDB 引擎把数据保存在内存中,同时记录 redo log,此时 redo log 进入 prepare 状态,然后告诉执行器,执行完成了,随时可以提交。
- 执行器收到通知后记录 binlog,然后调用引擎接口,提交 redo log 为提交状态。
- 更新完成。
- 其实这条语句也基本上会沿着上一个查询的流程走,只不过执行更新的时候肯定要记录日志啦,这就会引入日志模块了,MySQL 自带的日志模块是 binlog(归档日志) ,所有的存储引擎都可以使用,我们常用的 InnoDB 引擎还自带了一个日志模块 redo log(重做日志),我们就以 InnoDB 模式下来探讨这个语句的执行流程。流程如下:
- 为何需要使用2个日志模块
- 这是因为最开始 MySQL 并没有 InnoDB 引擎(InnoDB 引擎是其他公司以插件形式插入 MySQL 的),MySQL 自带的引擎是 MyISAM,但是我们知道 redo log 是 InnoDB 引擎特有的,其他存储引擎都没有,这就导致会没有 crash-safe 的能力(crash-safe 的能力即使数据库发生异常重启,之前提交的记录都不会丢失),binlog 日志只能用来归档。
并不是说只用一个日志模块不可以,只是 InnoDB 引擎就是通过 redo log 来支持事务的。那么,又会有同学问,我用两个日志模块,但是不要这么复杂行不行,为什么 redo log 要引入 prepare 预提交状态?这里我们用反证法来说明下为什么要这么做?
- 先写 redo log 直接提交,然后写 binlog,假设写完 redo log 后,机器挂了,binlog 日志没有被写入,那么机器重启后,这台机器会通过 redo log 恢复数据,但是这个时候 binlog 并没有记录该数据,后续进行机器备份的时候,就会丢失这一条数据,同时主从同步也会丢失这一条数据。
- 先写 binlog,然后写 redo log,假设写完了 binlog,机器异常重启了,由于没有 redo log,本机是无法恢复这一条记录的,但是 binlog 又有记录,那么和上面同样的道理,就会产生数据不一致的情况。
如果采用 redo log 两阶段提交的方式就不一样了,写完 binlog 后,然后再提交 redo log 就会防止出现上述的问题,从而保证了数据的一致性。那么问题来了,有没有一个极端的情况呢?假设 redo log 处于预提交状态,binlog 也已经写完了,这个时候发生了异常重启会怎么样呢? 这个就要依赖于 MySQL 的处理机制了,MySQL 的处理过程如下:
- 判断 redo log 是否完整,如果判断是完整的,就立即提交。
- 如果 redo log 只是预提交但不是 commit 状态,这个时候就会去判断 binlog 是否完整,如果完整就提交 redo log, 不完整就回滚事务。
总结
- 查询语句的执行流程如下:权限校验(如果命中缓存)—->查询缓存—->分析器—->优化器—->权限校验—->执行器—->引擎
更新语句执行流程如下:分析器——>权限校验——>执行器—->引擎—-redo log(prepare 状态)—->binlog—->redo log(commit状态)
mysql实用sql脚本
注意下面的sql脚本建表时没指定字符集等。
- 因为省市区这种基本不怎么变化而且关联性很强,因此下面的脚本使用了外键
多表实现省市区
多表实现省市区县.sql单表实现省市区
- 因为省市区这种基本不怎么变化而且关联性很强,因此下面的脚本使用了外键
单表实现省市区即有三个字段用于存储省市区编码,如果三个字段2个都是空,那么它就是省,如果一个是空那么它就是市,如果都不为空那就是区县

若有收获,就点个赞吧
0 人点赞
