本篇讲的是Prometheus的四种数据类型。Counter,Gauge,Histogram,Summary
Prometheus客户端库提供四种核心指标类型。目前,它们仅在客户端库(以支持针对特定类型的使用而定制的api)和wire协议中有所区别。Prometheus server还没有使用类型信息,而是将所有数据平展为非类型化的时间序列。这在将来可能会改变。
计数器 Counter (只能增加的值)
Counter 是一个累计的指标,它标识一个单调递增的计数器,它的值只能增加或在重启的时候被重置为0。例如:您可以使用计数器来表示服务的请求数、完成的任务数或错误数。
不要使用Counter去暴露一个可能缩小的值。例如:不要使用counter统计当前运行的进程数。应该用gauge。
Counter的客户端库使用文档:
- Go
- Java
- Python
-
Gauge (可以随意增减的值)
Gauge是一个指标的值。它可以随意的增加和减小。
Gauge通常用于缓慢变化的值。例如:温度,内存,它还能用于能够增减的值,例如并发量请求的数量。
Gauge的客户端库使用文档: - Java
- Python`
-
累计直方图 Histogram (每个桶包含前边所有区间的值)
Histogram 会在一段时间范围内对数据进行采样(通常是请求持续时间或响应大小等),并将其计入可配置的存储桶(bucket)中。他还提供了所有值的总和。
一个指标名为的Histogram,会在数据采集期间暴露多个时间序列: 存储桶(bucket)的累计计数器,暴露的指标名(metric name)为:
<basename>_bucket{le="<upper inclusive bound>"}- 所有样本值的总和,暴露的指标名(metic name)为:
<basename>_sum - 所有采样的次数和。暴露的指标名(metic name)为:
<basename>_count(与上边<basename>_bucket{le="+Inf"}①相同)
使用histogram_quantile()从直方图或直方图集合中计算分位数。histogram也适用于计算Apdex得分。当在直方图每个区间操作运算时,请记住每个区间是累计前面所有区间的个数。有关Histogram用法的详细信息以及与Summary的区别,请参见Histogram和summary。
Histogram的客户端使用文档:
- Go
- Java
- Python
-
Summary
与Histogram类似,Summary也是对观察结果进行采样(通常是请求持续时间和响应大小)。它不仅记录了采样的次数和所有样本值的和,它还可以计算事先提供的分位数的值。
一个指标名为的Summary,会在数据采集期间暴露多个时间序列: 设置一个φ-quantiles(0 ≤ φ ≤ 1)②,暴露的指标名(metic name)为:
<basename>{quantile="<φ>"}- 所有样本值得总和。暴露的指标名(metic name)为:
<basename>_sum - 所有采样的次数和。暴露的指标名(metic name)为:
<basename>_count
详细的φ-分位数、摘要用法以及与直方图的差异解释请参见histogram和summary
Summary的客户端使用文档:
- Go
- Java
- Python
- Ruby
①
_bucket{le=” “} ,这个指标可以取直方图的一个区间的样本个数,但是都是0-x模式,其中n就为le,当le为0-x之间时,都取的是部分的样本个数,而当le=x,即为直方图x轴的最大值时,这个指标的结果就为所有样本的个数。也就是与 <basename>_count的值相等。 ②由于φ为分位数,则只能取0-1之间,也就是0%-100%。
个人理解
以下图仅作为讲解,示例图及数据: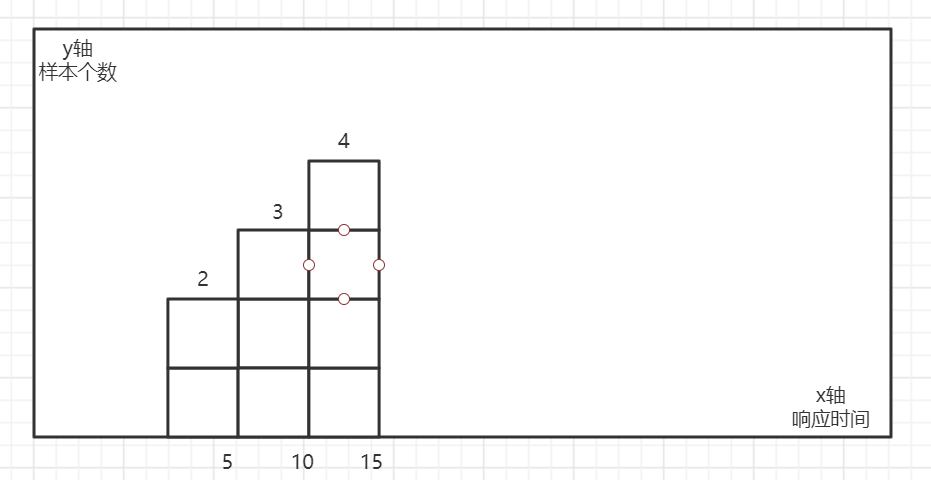
其中落入各个bucket的值为:
[-,5]有两个值:2.5,3.5
[5,10]有三个值:7.5,8.5,9.5
[10,15]有四个值:10.5,11.5,11.6,12.4,13.5
histogram的作用
- 对采样点进行统计,并放到各个桶(bucket)中。如上图则有[-,5],[5,10],[10,15]三个桶
- 对每个采样点的值求和2.5+3.5+7.5+8.5+9.5+10.5+11.5+11.6+12.4+13.5=91
-
histogram的指标名
[basename]_bucket{le=”n”},此处的为bucket的边界,如上图可以为:5,10,15
- [basename]_sum,求值的和 91
- [basename]_count,求个数的和 9
示例: _bucket这个取值是向下包含的关系。 [basename]_bucket{le=”5”} = 2 [basename]_bucket{le=”10”} = 3+2 = 5 [basename]_bucket{le=”15”} = 2+3+4 = 9 [basename]_bucket{le=”+Inf”} = 2+3+4 =9 他和le=”15” ,_count 的值相等 _count [basename]_count = 9 _sum [basename]_sum = 91
histogram的特点
histogram并不会保存数据采样的点值,每个bucket只会记录样本的个数和值的总和(counter),因此客户端在客户端性能上相比Conuter和Gauge差不多,适合高并发的数据收集。
histogram_quantile()函数
histogram常用histogram_quantile来分析数据,计算histogram的分位数。由于histogram并不会保存数据的样本值,在计算分位数时,主要是通过bucket的分段和样本个数来计算的,所以误差比较大。
Summary
因为histogram在客户端就是简单的分bucket计数和求和,在Prometheus 服务端基于这些有限的数据做百分位运算,所以必然会不够准确,summary就是解决这个问题而来。summary直接存储了quantile数据,而不是根据区间计算出来的。
summary作用
举例 http响应时间最高为10s
- 客户端在一段时间内(默认10分钟),对每个采样点进行统计,并形成分位图。(如:统计响应时间低于 1s的比例,统计响应时间低于 5s 的比例,统计响应时间低于 9s 的比例)
- 统计所有样本的值的总和 sum ,所有响应时间的和
-
summary的指标名
[basename]{quantile=”<φ>”} φ分位时候的值
- [basename]_sum
-
限制
Summary 结构有频繁的全局锁操作,对高并发程序性能存在一定影响。histogram仅仅是给每个桶做一个原子变量的计数就可以了,而summary要每次执行算法计算出最新的X分位value是多少,算法需要并发保护。会占用客户端的cpu和内存。
- 不能对Summary产生的quantile值进行aggregation运算(例如sum, avg等)。。
- summary的百分位是提前在客户端里指定的,在服务端观测指标数据时不能获取未指定的分为数。而histogram则可以通过promql随便指定,虽然计算的不如summary准确,但带来了灵活性。
- histogram不能得到精确的分为数,设置的bucket不合理的话,误差会非常大。会消耗服务端的计算资源。

若有收获,就点个赞吧
0 人点赞
