卷积神经网络
基本的神经网络没有考虑图像的空间结构(忽略了像素之间的空间距离信息)。而卷积神经网络使用了适用于图像分类的特殊架构,能够在图像分类任务上表现得很好。
基本概念
与传统全连接网络不同,卷积神经网络的输入层不按纵列排布,而是组成一个对应于各个像素输入的方阵。
局部感受野(local receptive field)
输入层的一部分,可以看作是输入像素上的一个小窗口,可以覆盖一定区域的神经元(比如下图就是一个5×5的局部感受野),每个局部感受野对应一个隐藏神经元。
通过在整个输入图像上交叉移动局部感受野,可以得到多个隐藏神经元,这些隐藏神经元组成了第一层隐藏层。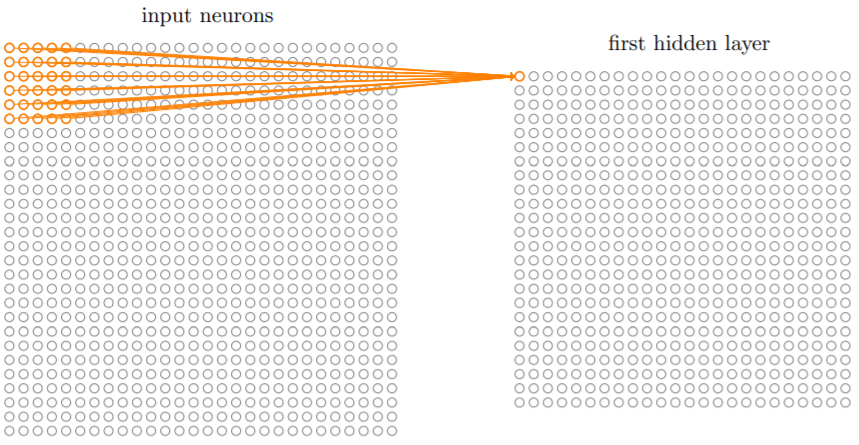
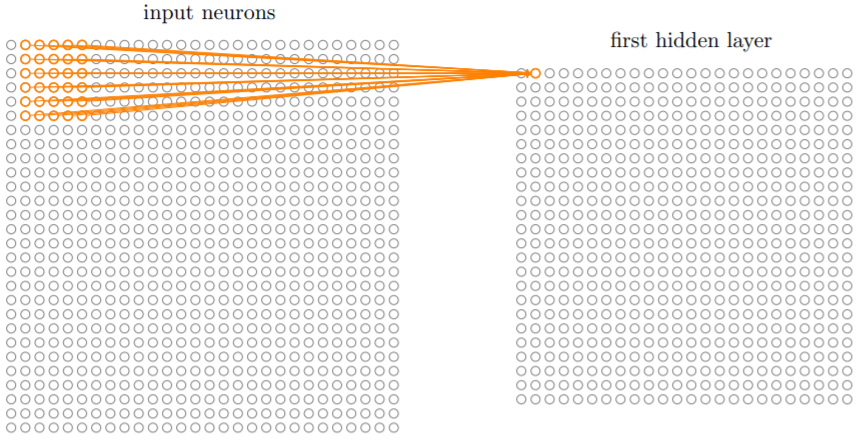
局部感受野的大小可以自定义,同样的每次移动的距离(称为跨距/步长,stride)也可以自定义,一般取1或2。上图中,跨距为1,局部感受野大小为5×5,对于一个28×28的输入图像,可以得到一个包含24×24个神经元的隐藏层。
共享权重和偏置(shared weights)
即对于每一隐藏层,每个隐藏神经元对应的权重数组(局部感受野的每个神经元都有对应的权重,这些权重组成一个权重数组)和偏置是一致(共享)的。
每个隐藏层的第 个隐藏神经元的激活值就可以表示为:
个隐藏神经元的激活值就可以表示为:
 与
与 即共享偏置与权重数组,
即共享偏置与权重数组, 即对应的当前局部感受野中第
即对应的当前局部感受野中第 行第
行第 列神经元的输入值。
列神经元的输入值。
共享权重和偏置表明,每一个隐藏层检测的是同一种特征。它们相当于一个特征筛选器,通过扫描图像的各个区域检测图象是否具有该特征。这种从输入层到隐藏层的映射称为一个特征映射(feature map),定义该映射的权重称为共享权重(shared weight),偏置称为共享偏置(shared bias)。也把它们称作卷积核(kernel)或滤波器(filter)。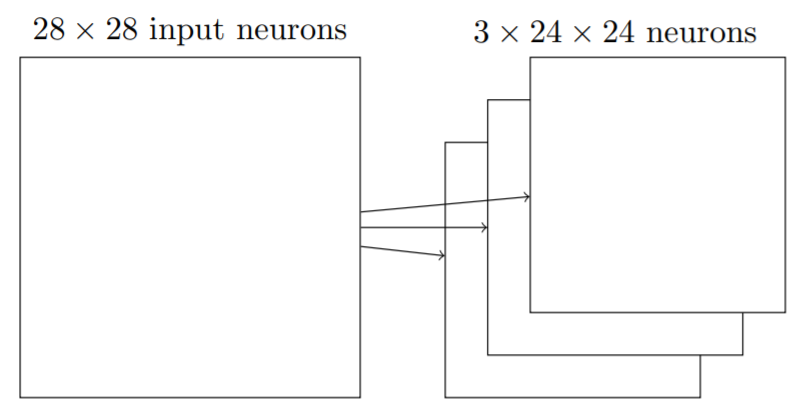
为了获得图像的多个特征信息,相应地就要建立多个特征映射,得到多个并列的隐藏层(区别于全连接网络),这些隐藏层共同组成了所谓的卷积层(convolutional layer)。将每个特征映射的共享权重矩阵按照权重大小绘制热力图,可以得到类似下图的图象,每幅图像对应一个特征映射,显示了卷积层作出响应的特征类型。
共享权重和偏置的使用使得网络中需要训练的参数大量减少,每个特征只需要 个参数。尽管不能直接在数量上比较卷积网络和全连接网络的参数,但卷积网络的平移不变性确实减少了参数,能够加快卷积模型的训练。
个参数。尽管不能直接在数量上比较卷积网络和全连接网络的参数,但卷积网络的平移不变性确实减少了参数,能够加快卷积模型的训练。
卷积(convolutional)一词来自计算隐藏神经元激活值的式子
,其中的
被称为卷积操作。
混合层(亦称池化层,pooling layer)
简化卷积层输出的信息,对卷积层特征的凝练映射。
混合层的每个单元可能概括了前一层的每个2×2的区域(可以称作池化视野)。常见的混合方式有最大值混合(max-pooling),在最⼤值混合中,⼀个混合单元简单地输出2×2输⼊区域中的最⼤激活值。
卷积层每个映射有24×24个神经元输出,混合后可以得到12×12个神经元。可以把最大值混合看作一种定位特征的方式,一旦发现特征信息,只需要知道它相对于其他特征的相对位置(尽管精确信息可能更好)。混合层凝练了特征信息,使得后续层的参数减少了。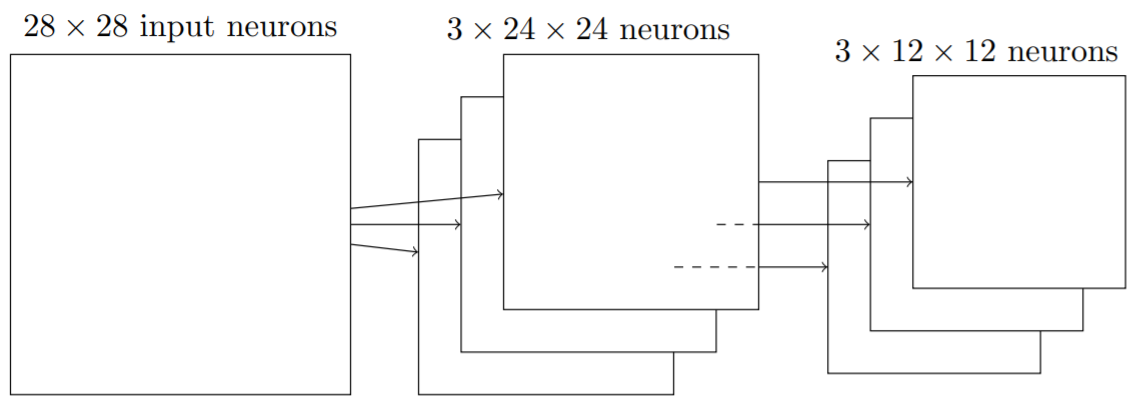
另一种常用的混合方式是L2混合(L2 pooling),取2×2区域中激活值的均方根(L2范数)输出到混合层。
完整的卷积神经网络
将上述概念合并在一起,就可以得到一个简单的卷积神经网络。它由输入层、卷积层、混合层和输出层组成,输入层输入图像的所有像素编码。这些输入像素信息经过5×5的局部感受野进行特征映射,得到3×24×24的隐藏特征神经元层(卷积层)。紧接着,对卷积层的激活值进行最大值混合/L2混合(2×2),得到3×12×12个神经元组成的的混合层。混合层全连接到输出层(由代表十个数字的十个输出神经元组成),输出最终的结果。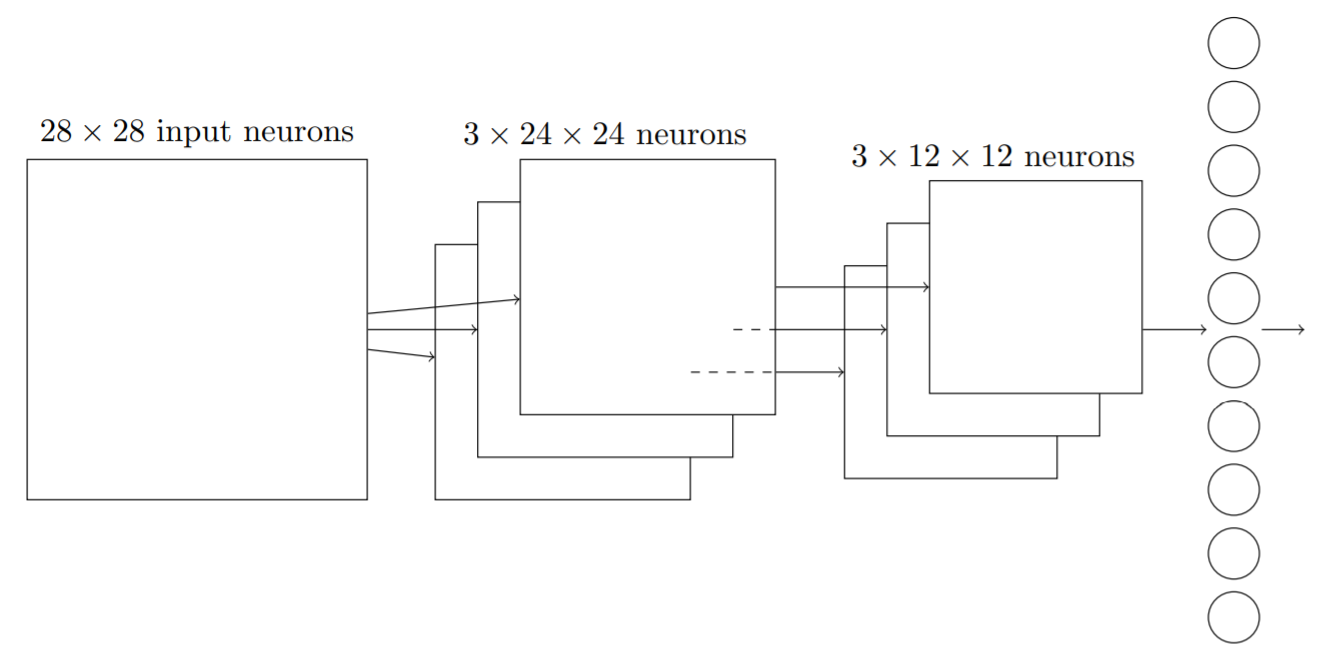
卷积神经网络的BP算法推导相比DNN要复杂,这里不作叙述(因为看了好久才搞明白),可以参考刘建平老师的文章。 CNN与DNN的主要差异在于:
- 池化层没有激活函数
- 卷积层到池化层的前向传播进行了压缩,反向传播时要还原这个压缩
- 卷积层是若干个局部感受野卷积而得到的输出,反向传播时存在差异
- 由于进行的是卷积运算,从
推导该层的共享
和
需要理解的几个地方:
- average-pooling和max-pooling的还原:前者进行平均(如2×2即除4填入池化视野各个单元),后者找到前向传播确定的最大值位置填入
- 卷积层反向传播中,不同于转置,卷积核要翻转180度(要求了解卷积运算、求导等)
- 从误差推导参数的梯度涉及卷积,需要进行转换
一些术语的理解
- 卷积核(kernel):一组共享权重和一个共享偏置称为一个卷积核,可以实现一个特征映射(feature map),有几个卷积核就有几个特征映射。
图像通道数(channel):可以理解为输入了几张图,一张标准的RGB图象由三个颜色通道组成,就有三个输入矩阵。对其进行卷积运算的卷积核大小就为3×3×3。
一些可以进行的改进
数据集
使用充分大的数据集
-
网络结构
S型神经元+交叉熵函数组合→柔性最大值+对数似然代价函数组合:好的代价函数可以避免学习减速(这里提到的两种组合都可以避免减速,主要指对二次代价函数的替换)
- 浅层网络→深层网络
- 增加全连接隐藏层
- 增加卷积-混合层:需要考虑经过一次卷积混合后,输入到下一层的矩阵有多层(several channel)
- 使用tanh/ReLU单元代替S型神经元:加快训练速度
-
训练策略
规范化(正则化):降低过拟合影响
- L2正则化
- drop out(弃权):一般只应用于全连接层。卷积层由于使用了共享权重,强制对整个图像进行学习,更不容易学习局部特质,自身能够避免部分过拟合
- 规范化后应当减少迭代期,因为规范化已经减少了过度拟合,训练过程加快
- 使用好的权重初始化
-
其他的深度学习模型
递归神经网络(RNN)
拥有时间相关特性,体现了随时间动态变化特性的神经网络
适用于处理时序数据和过程(语音识别和自然语言处理)长短期记忆单元(LSTMs)
由于梯度的不稳定性,反向传播的梯度越来越小,这个问题在RNN中被放大,因为梯度不仅仅通过层反向传播,还会根据时间进行反向传播,这就导致模型较难训练。
通过引入长短期记忆单元(LSTMs)可以解决该不稳定梯度的问题,使得RNN的训练变得简单。深度信念网络(DBN)
DBN在深度学习刚刚兴起时很火,现在渐渐被RNN和前馈网络取代。
DBN是一种生成式模型。通过指定某些特征神经元的值,“反向运行”,可以产生输入激活的值,即生成和手写数字类似的图象。
- DBN可以进行无监督和半监督的学习。使用图像数据学习时,DBN可以学会有用的特征来理解其他的图像,即使训练图像是无标记的。

若有收获,就点个赞吧
0 人点赞
