01 什么是感知器
基本结构
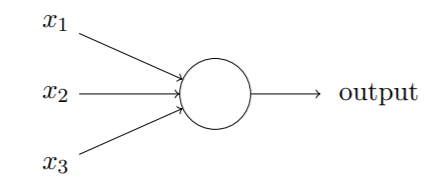
参数
搭建调整神经网络主要调整的参数:
- 权重(weight)
阈值(threshold)- 偏置(bias):神经元被激活的难易程度
输出规则
加权和是否超过阈值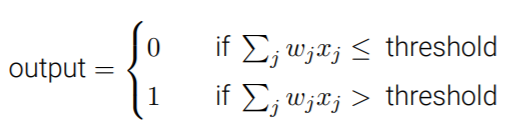
更一般的形式:使用向量与偏置(bias)
感知器网络
多个感知器组成的网络,具有多层决策结构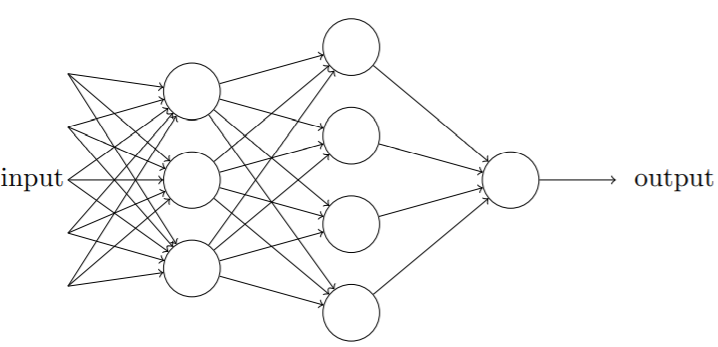
输入层
在日常描述网络时,通常将多个输入作为单独的输入层加入感知器网络中。一个标准的输入元如下: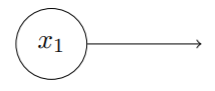
没有标注输入并不代表其输入为0,感知器不应看做一般意义上的感知器,⽽是简单定义为输出期望值的特殊单元
输出
- 一个感知器只能有一个输出。当网络结构中画了多个输出,表明有多个地方都调用了该感知器的唯一输出。
当多个输出输出到同一个地方时,可以简单合并该输出,即:该输出作为输入的权重翻倍
逻辑运算及与非门
感知器可应用于基本逻辑的计算
与:11→1,10/01/00→0
- 或:11/10/01→1,00→0
- 与非:11→0,10/01/00→1
可以使用感知器构建一个与非门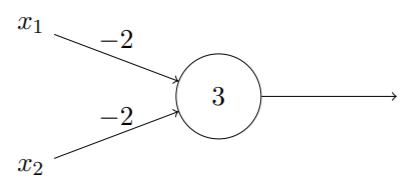
因此,通过构建感知器网络,可以模拟包含很多与非门的电路。
但,与传统与非门电路相比,神经网络可以通过设计学习算法使得计算机自动调整人工神经元的权重和偏置,这种调整可以响应外部的刺激,使得神经网络学会解决简单的问题。
02 感知器缺陷与S型神经元
 **
**
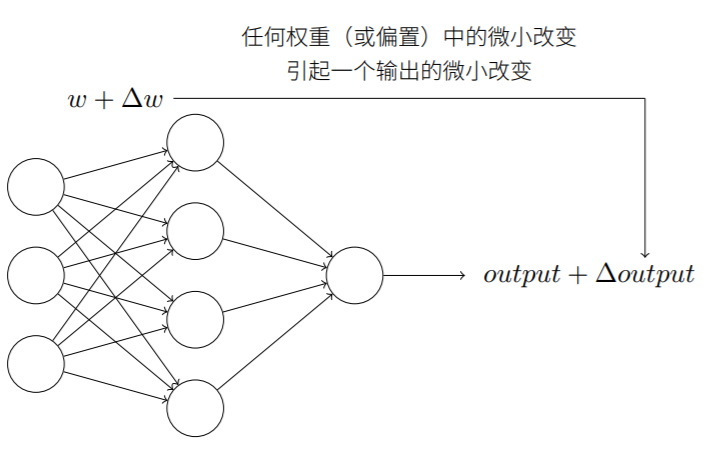
由于权重和偏置的微小改变会使输出产生改变。每当输出结果并不符合预期时,可以通过对参数小幅度的调整来不断修正网络以产生更好的输出。这时⽹络就在学习。
但,当网络包含感知器时,微小改动可能会引起输出的完全更改(0/1),使得总体输出结果产生很大变化,这使得逐步修改权重和偏置来让⽹络接近预期变得困难。
S型神经元
亦称逻辑神经元,实现了“权重和偏置的微小改变只造成输出的微小变化”
与感知器的区别:
- 输入和输出均不再局限于0/1
- 输出函数的改变:

此处的输出函数为S型(逻辑)函数(sigmoid function),即:
对应的函数图象: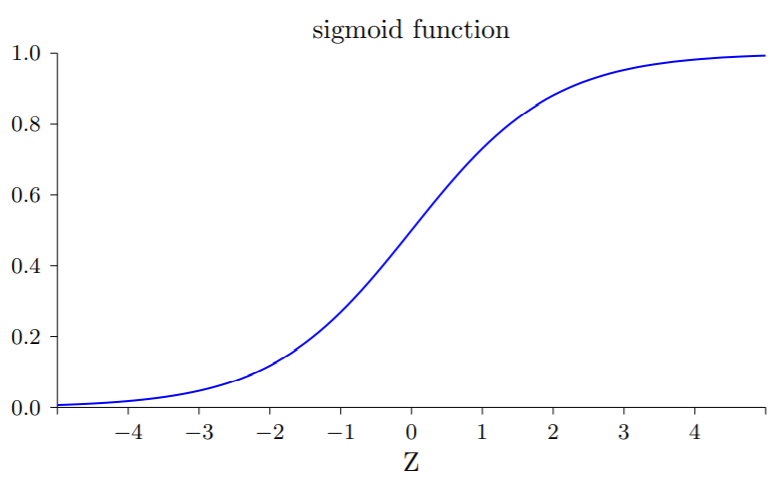
即越阶函数的平滑version: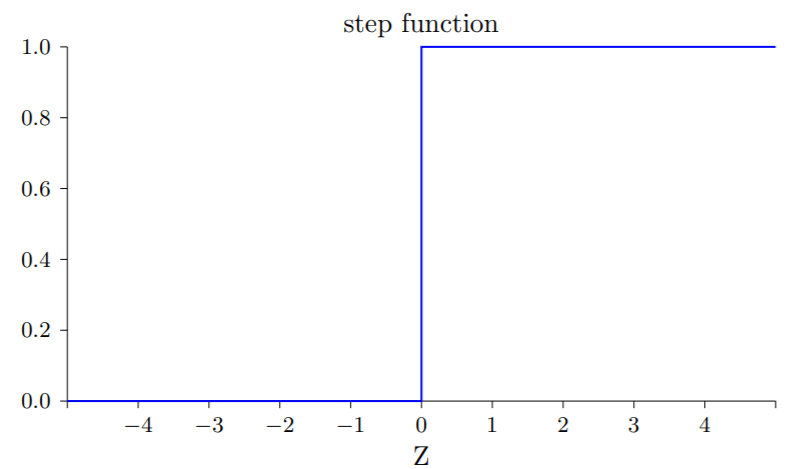
此时输出的变化可以表示为如下形式(多元函数的微分),即S型函数实现了输出变化的平滑
输出函数不一定限于该形式,但由于其具有的良好性质,一般情况更多地采用S型神经元。
由于输出不再是0/1变量,当需要进行对最终输出是非判断时,往往会采用新的判断准则(如:输出>0.5?)
03 神经网络的架构
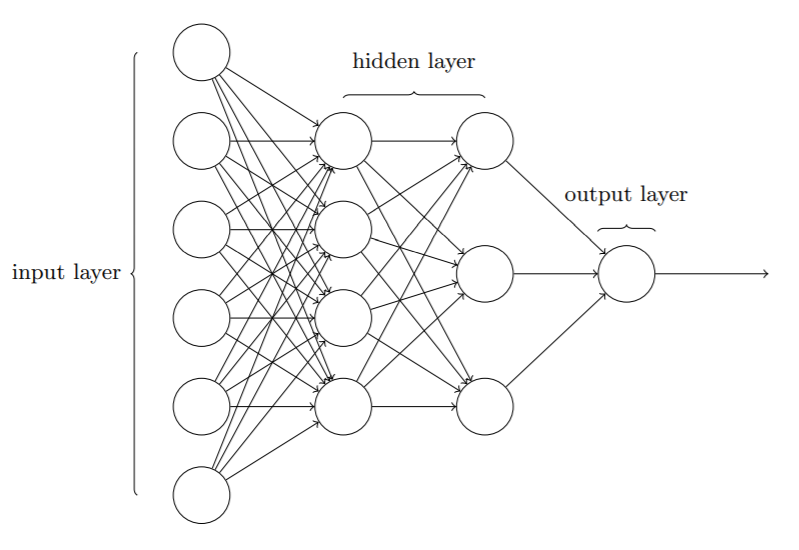
- 输入层(input layer)
- 隐藏层(hidden layer)
- 输出层(output layer)
输入输出层的设计根据需要进行,相对直观。隐藏层设计是难点和重点,研究人员设计了许多最优法则以权衡隐藏层数量和训练⽹络所需的时间开销。
两种神经网络
根据网络中是否存在反馈回路:
- 前馈神经网络:信息向前传播,从不反向回馈,以上一层输出作为下一层输入
递归神经网络:存在反馈回路,基于休眠前会在一段有限时间内保持激活状态的神经元运行,激活的神经元可以刺激其他神经元进入激活状态。神经元的输出在一段时间后而不是即刻影响它的输入。更接近于人脑,尽管研究进展有限。
04 简单的手写数字分类网络
数字图像分割
可以通过对每种分隔方式分割后分割片段进行打分,若各片段分类置信度均较高,得分较高;各片段置信度均较低,得分较低。
对应的基本思想是,若分类器存在问题,很可能是由于分割效果不好导致的。单个数字的分类

输入层:784个神经元,用于输入28×28个像素点的灰度([0,1],数字越大灰度越高)
- 隐藏层:15个神经元,直观的想法是可以用来表示是否含有某个笔画(每个神经元对应数字的某个特征)
- 输出层:10个神经元,分别对应各个数字,当输出神经元被激活,代表网络认为该图象表示该数字
尽管可以用2进制方式表示输出(仅需4个神经元),但相比于启发式设计经设计证明并不具备更好的效果(很难将笔画与二进制位联系起来)
05 使用梯度下降算法进行学习
数据集:MNIST,该数据集包含50000个训练样本与10000个用于测试的样本
训练目标:二次代价函数(Cost Function,均方误差,MSE)最小化:
其中 表示网络中的权重集合,
表示网络中的权重集合, 是所有的偏置,
是所有的偏置, 为对应的期望输出。
为对应的期望输出。
梯度下降算法
神经网络的一种训练方法
基于以下更新原则:

此处的 即为所谓的学习速率,在下降全过程中可能会发生变化。
即为所谓的学习速率,在下降全过程中可能会发生变化。
对应到神经网络的训练中,迭代更新规则即:
因为 ,代价函数等于各样本平方误差的均值,因此需要为每个训练样本输入单独计算梯度值然后求平均值,即
,代价函数等于各样本平方误差的均值,因此需要为每个训练样本输入单独计算梯度值然后求平均值,即
随机梯度下降
用于解决计算代价函数时样本量过大,需要求大量 来求平均值
来求平均值 ,从而造成训练过程缓慢的问题。
,从而造成训练过程缓慢的问题。
核心思想
具体原理
- 每次迭代,随机选取
 个训练输入标记为
个训练输入标记为 ,作为一个小批量数据(mini-batch)
,作为一个小批量数据(mini-batch) - 假设足够大时,
 ,因此,可以间接估算:
,因此,可以间接估算: (即用随机选取的小批量数据梯度估算整体梯度)
(即用随机选取的小批量数据梯度估算整体梯度) - 用估算值代替原式中梯度,得到新的更新规则:

- 每次都随机选取一批(个数据)进行参数训练,直到用完所有训练输入,此时已完成了一个训练迭代期(epoch),然后接着开启一个新的训练迭代期
另外值得提⼀下,对于改变代价函数⼤⼩的参数,和⽤于计算权重和偏置的⼩批量数据的更新规则,会有不同的约定。 我们通过因⼦ 1/n 来改变整个代价函数的⼤⼩,但有时候,我们会忽略 1/n,直接取单个训练样本代价总和,⽽不是平均值。这对我们不能提前知道训练数据数量的情况下特别有效。例如,这可能发⽣在更多训练数据是实时产⽣的情况下。 同样,⼩批量数据的更新规则有时也会舍弃前⾯的 1/m。从概念上这会有⼀点区别,因 为它等价于改变了学习速率
的⼤⼩。但在对不同⼯作进⾏详细对⽐时,需要对它警惕。
在线学习(Online Leaning)
与批量学习的区别、优缺点:
以训练神经网络为例,训练神经网络时需要计算损失函数,根据损失函数计算参数的梯度,从而去更新参数。这就涉及到神经网络学习多少样本后去计算损失函数来更新参数。
- Online Learning:每学习一个样本,就更新参数。
- Batch Learning:学习所有样本后,再去更新参数。
Batch learning的优点是容易找到全局最优解,但样本较大时训练过程很慢,而online learning则相反。为了折中,出现了小批量学习,即学习小批量样本后更新参数,这个小批量的样本数量自己制定。
Online Learning能够根据线上反馈数据,实时快速地进行模型调整,使得模型及时反映线上的变化,提高线上预测的准确率。其流程包括:将模型的预测结果展现给用户,然后收集用户的反馈数据,再用来训练模型,形成闭环的系统。
06 实现手写数字分类网络
主要展示了训练该网络的核心代码,数据集具体导入代码见mnist_loader.py,导入的数据集文件为gz压缩包内的pkl文件,代码对于数据格式进行了一定的调整。
建立一个神经网络——Network类
Class Network(object):def __init__(self,sizes):self.num_layers = len(sizes) # sizes是一个列表,各元素代表各层神经元个数self.sizes = sizesself.biases = [np.random.randn(y,1) for y in sizes[1:]] # 为各层初始化对应的偏置,二维列表self.weights = [np.random.randn(y,x) for x, y in zip(sizes[:-1], sizes[1:])] # 为各层间初始化对应的权重(y*x矩阵),zip函数打包列表为字典,三维列表
说明:
- 输入层没有偏置
- 权重矩阵的行索引代表被连接的下一层神经元序号(注意索引顺序,即
为连接前一层第k个神经元与后一层第j个神经元的权重)
- 设计该索引的意义在于其使得每一层的激活向量更易于计算:
(即[j×k]·[k×1]=[j×1])
举例:建立一个神经网络——初始化Network对象
net = Network([2,3,1]) # 新建一个三层神经网络,其中输入层有2个神经元,隐藏层含3个神经元,输出层有1个神经元
激活函数
定义sigmoid函数sigmoid和用于计算激活向量的函数feedforward
def sigmoid(z):return 1.0/(1.0+np.exp(-z))def feedforward(self, a):for b, w in zip(self.biases, self.weights): # 对应的权重矩阵和偏置列表打包为字典a = sigmoid(np.dot(w,a)+b)return a
随机梯度下降训练函数
def SGD(self, training_data, epochs, mini_batch_size, eta, test_data=None):training_data = list(training_data) # 元组转化为列表n = len(training_data)if test_data:test_data = list(test_data)n_test = len(test_data)for j in range(epochs):random.shuffle(training_data)mini_batches = [training_data[k:k+mini_batch_size] for k in range(0, n, mini_batch_size)] # 均匀划分batch,不整除时是否会超出索引?for mini_batch in mini_batches:self.update_mini_batch(mini_batch, eta) # 对每个batch使用一次梯度下降算法if test_data:print('Epoch{}:{}/{}'.format(j,self.evaluate(test_data),n_test))else:print('Epoch{} complete'.format(j))def update_mini_batch(self, mini_batch, eta):nabla_b = [np.zeros(b.shape) for b in self.biases] # 用于存下每层神经元偏置的梯度nabla_w = [np.zeros(w.shape) for w in self.weights] # 用于存下每层间权重的梯度for x, y in mini_batch:delta_nabla_b, delta_nabla_w = self.backprop(x,y) # 反向传播算法,一种计算梯度的方法,计算每个样本的偏导# 更新计算后的梯度与偏置(求和)nabla_b = [nb+dnb for nb, dnb in zip(nabla_b, delta_nabla_b)]nabla_w = [nw+dnw for nw, dnw in zip(nabla_w, delta_nabla_w)]# 得到最终更新后的权重和偏置self.biases = [b-(eta/len(mini_batch))*nb for b, nb in zip(self.biases, nabla_b)]self.weights = [w-(eta/len(mini_batch))*nw for w, nw in zip(self.weights, nabla_w)]
此处使用了反向传播算法(BP)来计算各个样本的偏导数,具体算法原理将在下一章讲述。
测试集精度计算
取输出结果中最大的值作为分类的结果,统计分类正确的数量
def evaluate(self, test_data):"""Return the number of test inputs for which the neuralnetwork outputs the correct result. Note that the neuralnetwork's output is assumed to be the index of whicheverneuron in the final layer has the highest activation."""test_results = [(np.argmax(self.feedforward(x)), y)for (x, y) in test_data]return sum(int(x == y) for (x, y) in test_results)
初探神经网络调试
初始超参数的选择会很大程度上影响结果,一般会选用启发式方法来选择好的参数和好的结构。
当训练效果不好时,可能相关的几个问题:
- 是否用了让初始网络很难学习的初始权重和偏置
- 是否没有足够的训练数据来获得有意义的学习
- 是否没有设置足够的迭代期
- 是否网络本身的结构不适用于该问题的解决
- 是否是学习速率出了问题
为什么说神经网络的效果很好?
在说明效果时,需要和其他思路和方法(其他基线)对比以证明其效果很好:盲猜(10%)、平均暗度(22.25%)、传统机器学习方法(20-50%)、支持向量机(SVM)(94.35%-98.5%)
本文以上的简单神经网络平均能到达95%的正确率,而精心设计的神经网络甚至能够达到99.79%的正确率。
作者提到,对有些问题:
07 什么是深度学习?
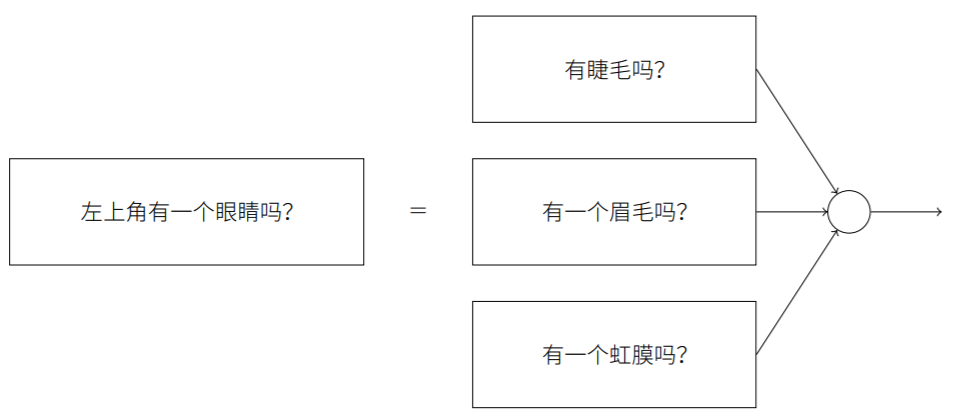
人脸识别问题可以从以上的数字分类得到启发。
通过输入像素点,直观上我们只需将识别人脸的问题不断拆解为识别其中各部分的一系列子问题,最终转化为在单像素层面上就可回答的非常简单的问题。因此,需要将巨大的人脸识别网络递归地分解为多个子网络进行。解决该问题的神经网络通过一系列多层结构来完成,在前⾯的⽹络层,它回答关于输⼊图像⾮常简单明确的问题,在后⾯的⽹络层,它建⽴了⼀个更加复杂和抽象的层级结构。包含这种多层结构 —— 两层或更多隐藏层的⽹络被称为深度神经⽹络。
深度神经网络能够构建起一个复杂的概念的层次结构,在很多复杂问题上表现得更加出色。2006年以来科学家们取得的一系列成果、开发的一系列深度学习技术使得训练含有更多隐藏层的深度网络成为可能。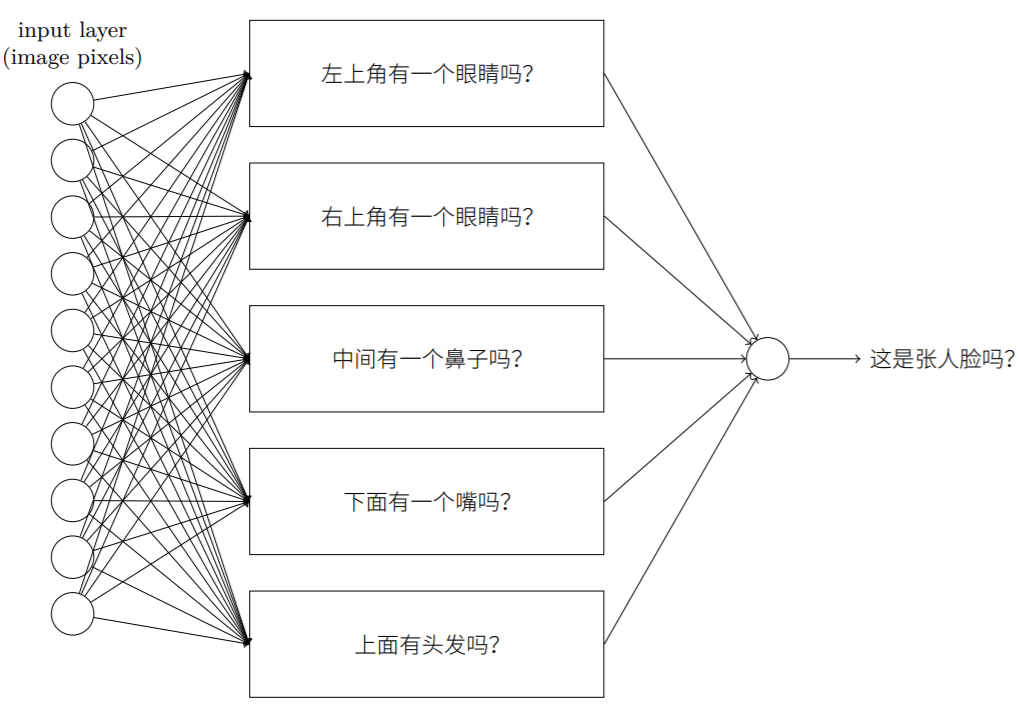

若有收获,就点个赞吧
0 人点赞
