所有的数据结构都是为了更高效的 存储 以及 增删改查
数组 (Array) 是一种线性表(只能往前,或者往后)数据结构。它用一组连续的内存空间,来存储一组具有相同类型的数据。
链表 (Linked)也是一种线性表的数据结构,它是通过指针将一组零散的内存块串联起来使用,其中我们把内存块成为链表的节点 (单链表,双链表,循环链表)
栈 是一种“操作受限”的线性表数据结构,只允许在一端插入和删除数据。可以用数组实现 (顺序表),也可以用链表实现(链式表),更多得是一种规范 入栈 push 出栈pop
队列** 是一种“操作受限”的线性表数据结构,支持在队尾插入元素,队头移除元素。用数组实现的队列叫作顺序队列 (有界队列) 用链表实现的队列叫作链式队列 (无界队列)。 入队enqueue 出队dequeue
在Python 的处理就是 list.pop(0) ,从队头取数据
递归 所有的递归问题都是树的问题
重复解决子问题 -> 可以得到主问题得解 重复计算 (缓存) 爬楼梯
解决栈溢出问题 ->迭代循环
只要遇到递归问题 -> 抽象递推公式 ->找到终止条件
排序
关键字 最好情况,最坏情况,平均情况时间复杂度
原地排序 (空间复杂度为O(1)) 稳定排序 (相同数字前后顺序不变化)
冒左右 稳定不停得左右两个值对比得排序 O(n2)
插移动 稳定 选择最小de 位置,然后往对应位置 插入,数组移动 O(n2)
选最小 不稳定 选择排序是交换 两个数值得位置O(n2)
归并排序 稳定排序 非原址排序 时间复杂度O(nlogn) 空间复杂度O(nlogn)
把数组切开 ,然后归并 分治是一种解决问题的处理思想,递归是一种编程技巧
快排 原地,不稳定 O(nlogn) 选最后一个值 , 走两边指针 ,然后把最后那个值放中央 nlogn
线性排序 时间复杂度是线性(非比较) ,就是O(n) . 非基于比较的排序算法,都不涉及元素之间的比较操作
桶排序、计数排序、基数排序
桶排序
把数组分配到有限的桶中,每个桶再个别排序。取出的时候是有序数组
适合使用在外部排序,数据量有限,无法存在内存当中
计数排序 特殊的桶排序,比如只有10种结果,那就放10个桶,(桶内不需要排序)
基数排序 多次桶排序 时间复杂度O(dn) d 是维度 原理: 对数据的每一位进行桶排序或计数排序,对每位排序后结果就是有序的。()

二分查找针对的是一个 有序 的 数组 。连续内存(数组) 排好序 O(log2n)
跳表 链表加多级索引的结构(如何让链表支持二分)
在有序链表中,每隔几个抽几个元素出来做索引
用来解决 有序链表查询速度慢得问题 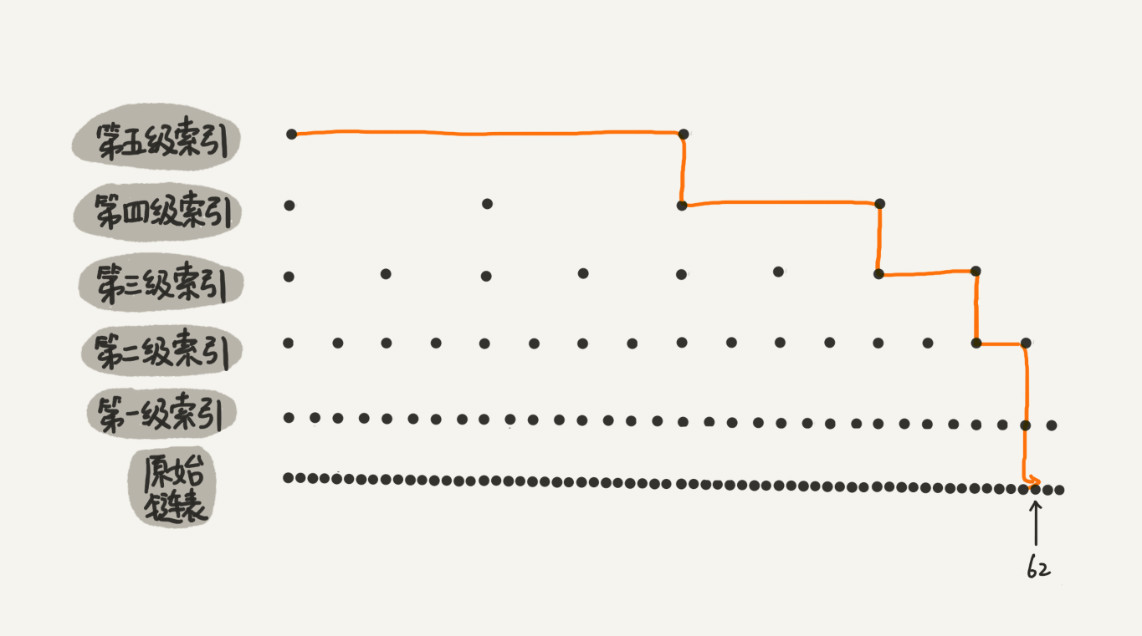
散列表 (散列表用的是数组支持按照下标随机访问数据的特性)
如何避免哈希冲突
1.如果只要数组实现,那么散列冲突, 开放寻址(往指定位置后面+1位置 存放 )
2.如果只要数组实现,那么散列冲突,再哈希(双重散列)
3.数组的指定下标下面跟随一个链表,用链表放
安全算法 ,对称 DES/3DES/IDEA/AES 非对称 RSA 信息摘要 MD5/SHA-1
为了效率 对称加密 为了安全传输私钥 非对称 为了完整性 信息摘要
树
满二叉树
完全二叉树(在数组中最节省内存的存储方式)
每一排第一个数 ,2 的(i-1) 次方
每排最大个数 2 ( i-1 ) 个数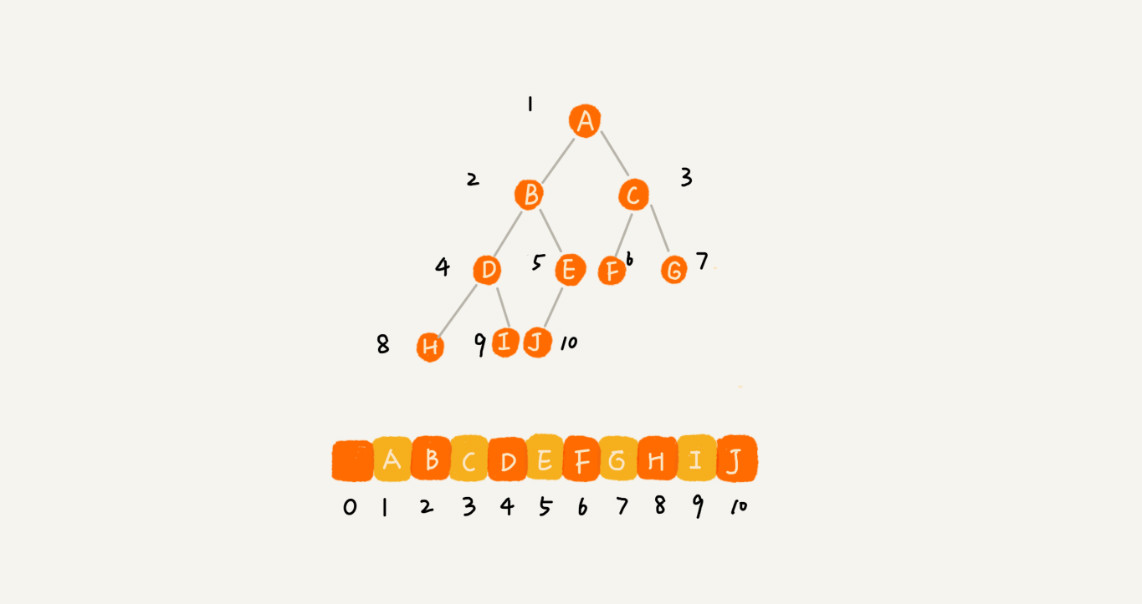
二叉树 * 前序 后续 中序
1.搜索二叉树中序遍历后有序
2.时间复杂度是O(n)
二叉查找树 不一定是完全二叉树
二叉树最大的特点是 支持动态数组集合的快速插入,删除,查找操作
为啥会有二叉查找树?
1.需要输出有序数组的时候,散列表是无序存储,二叉查找树只需要中序遍历
2.散列冲突,需要再散列, 装载因子不够的时候需要再扩容
3.散列表构造的时候需要考虑 散列函数设计,冲突解决,扩容 。
红黑树 平衡二叉查找树 , 搜索二叉树 为了防止层级太高
相比于其他,红黑树只是近似平衡,所以维护成本低,不会出现极端情况
哈夫曼树 带权路径最短
堆排序 . 大顶堆 小顶堆 要求 .完全二叉树(适合用数组存) 每个节点都要比子节点大或者小.
典型应用 优先队列
1.针对面试题 Top K (求一个数列的最大)
2.可以用堆来实现多路归并,从而实现有序
深度优先搜索 假设你站在迷宫的某个岔路口,然后想找到出口。你随意选择一个岔路口来走,走着走着发现走不通的时候,你就回退到上一个岔路口,重新选择一条路继续走,直到最终找到出口。这种走法就是一种深度优先搜索策略。
贪心:一条路走到黑,就一次机会,只能哪边看着顺眼走哪边
回溯:一条路走到黑,无数次重来的机会,还怕我走不出来 (Snapshot View)
动态规划:拥有上帝视角,手握无数平行宇宙的历史存档, 同时发展出无数个未来 (Versioned Archive View)
位运算 与$或|非~ ^ 异或 相同为0 (童龄)
异或 交换两个数 的值
x & (x - 1) 用于消去x最后一位的1
https
客户端请求 - 服务端返回 私钥 和证书
客户端验证证书 - 然后生成随机数用来对称加密
图
https://www.yuque.com/nainai-oxe7a/mz5osx/gwesy4
存储一张图
用数组存 邻间矩阵(二维数组) 浪费空间
用链表存 邻间表 (数组配链表)使用时浪费时间
算法是作用于具体的数据结构之上的,深度优先搜索算法和广度优先算法都是基于 图 这种数据结构的
深度优先算法 (DFS Deep) = 回溯 = 递归
借助一个栈
时间复杂度 O(n) 访问过的个数
广度优先算法(BFS) **
借助一个队列
必须要有三个要素
visited (标记当前访问的是否被访问过)
queue (存放当前这一层的数据)
prev (存放已经访问过的数据)
字符串匹配
主串:长的那一串 (长主 厂主)
模式串
1.BF暴力匹配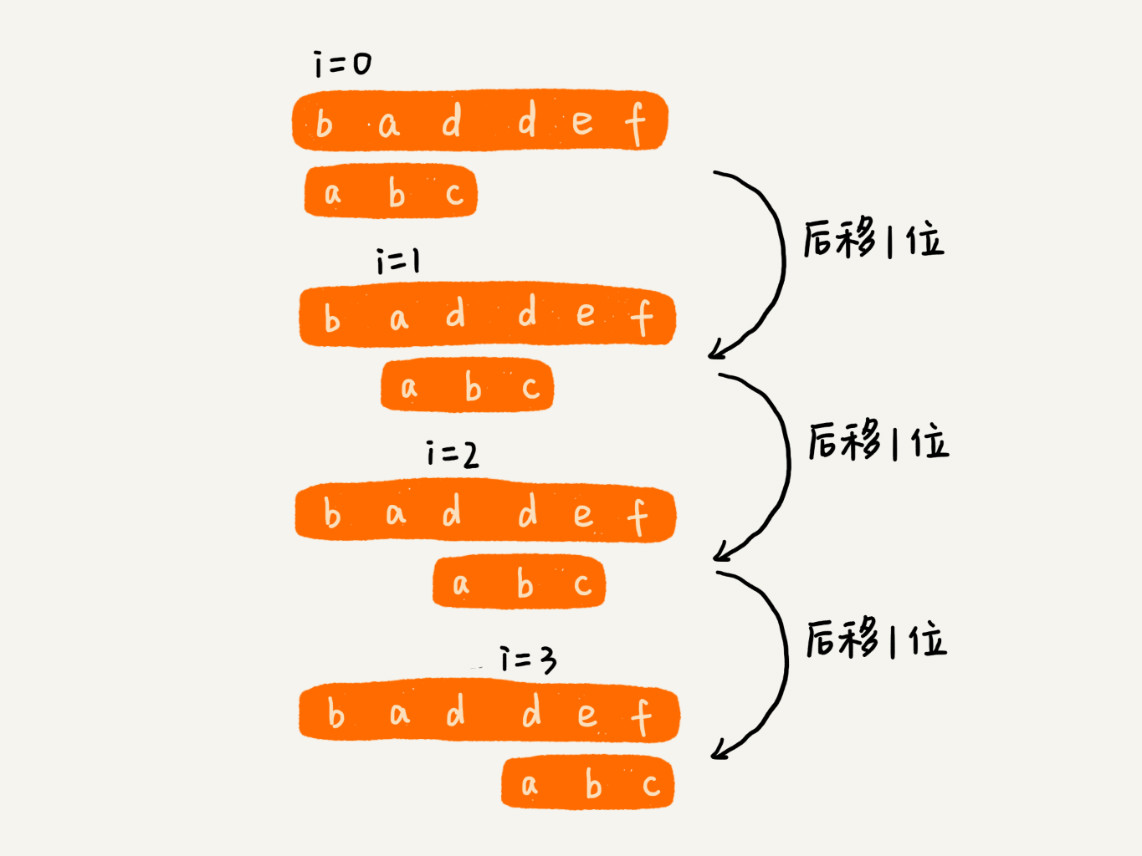
2.RK 计算哈希匹配
将主串分割成和模式串一样长度,然后分别计算哈希 ,然后比对
3.BM算法
坏字符(起码有一个能匹配上才能过去)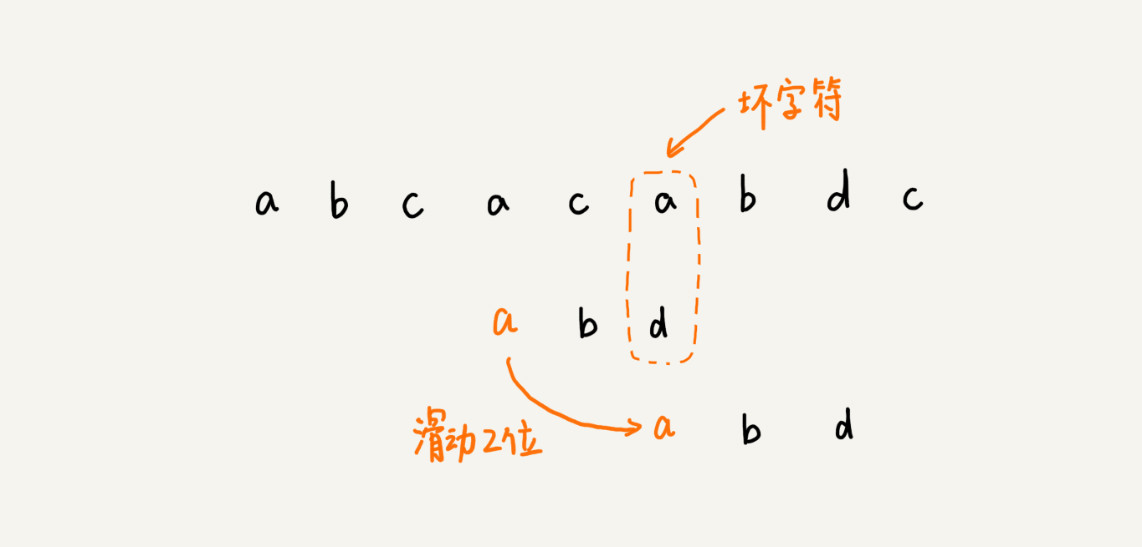
好后缀(连续能匹配上两个才过去完整匹配)
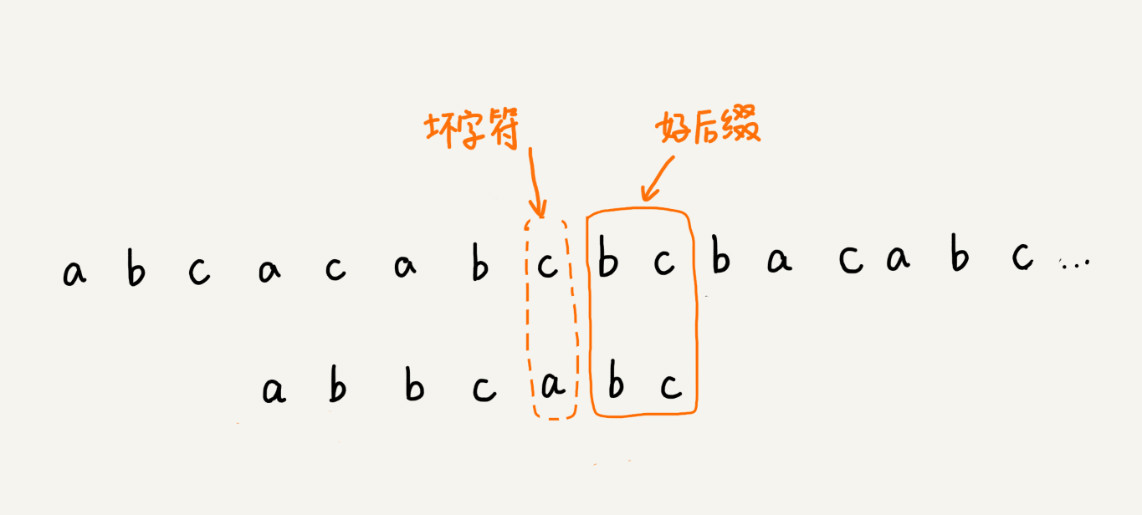
4.KMP算法 (同时使用坏字符,和好前缀)
KMP算法是借鉴了BM算法本质思想的,都是遇到坏字符的时候,把模式串往后多滑动几位
Trie树 字典树
作用:快速在一组字符串中查找某一个字符串
典型关键字: 公共前缀 ,多叉树
存储方式 (数组+链表)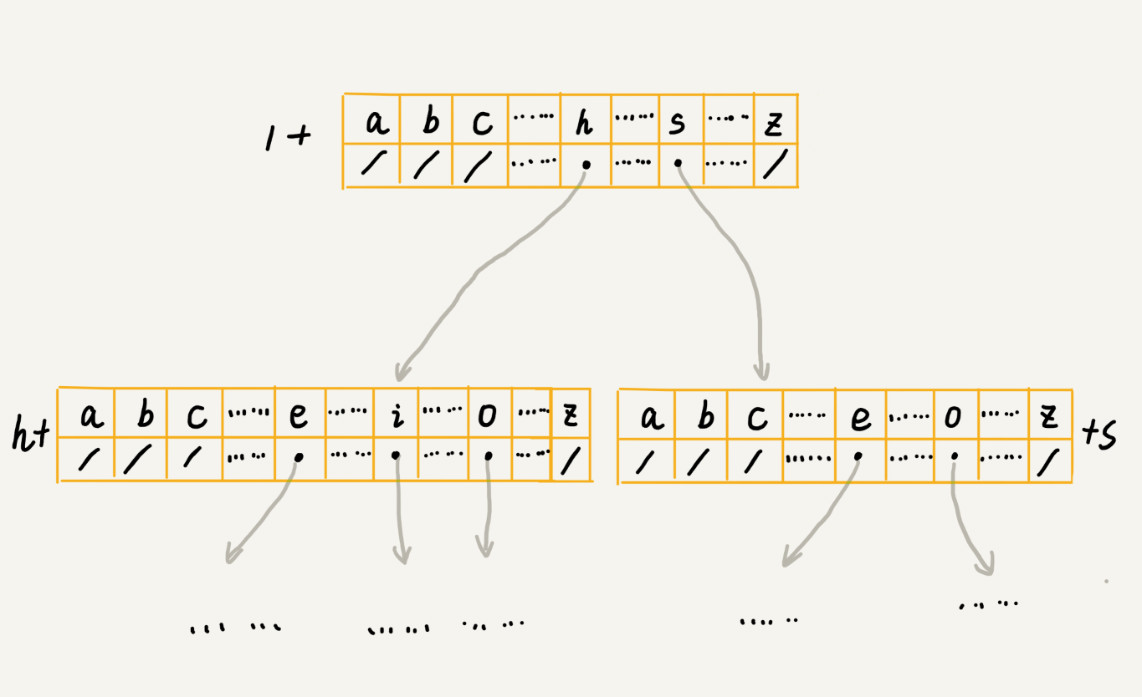
AC自动机

若有收获,就点个赞吧
0 人点赞
