1.导入包
导入包
import numpy as npimport pandas as pd
2.创建向量
使用Series函数让pandas创建默认的整数索引
import numpy as npimport pandas as pds = pd.Series([1, 3, 5, np.nan, 6, 8])print(s)
0 1.0 1 3.0 2 5.0 3 NaN 4 6.0 5 8.0 dtype: float64
import numpy as npimport pandas as pds = pd.Series([1, 3, 5, np.nan, 6, 8])print(s[0], s[2])
1.0 5.0
3.创建DataFrame
通过Numpy array创建一个有日期和标记的列的数据框架
import numpy as npimport pandas as pddates = pd.date_range('20130101', periods=6) %使用data_range创建连续的向量print(dates)
DatetimeIndex([‘2013-01-01’, ‘2013-01-02’, ‘2013-01-03’, ‘2013-01-04’, ‘2013-01-05’, ‘2013-01-06’], dtype=’datetime64[ns]’, freq=’D’)
import numpy as npimport pandas as pddates = pd.date_range('20130101', periods=6)print(dates[2])
2013-01-03 00:00:00
DataFrame创建矩阵用法一
import numpy as npimport pandas as pddates = pd.date_range('20130101', periods=6)%使用DataFrame创建矩阵,columns(矩阵的行标头),index(矩阵的列标头)df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list('ABCD'))print(df)
A B C D2013-01-01 0.652211 0.351307 -0.047034 0.233530 2013-01-02 -0.997980 0.292630 -1.312628 0.222933 2013-01-03 -0.733029 0.878319 0.789346 0.547204 2013-01-04 -2.428614 -1.820740 -0.884209 0.454380 2013-01-05 0.500799 0.293417 0.384024 1.294105 2013-01-06 0.257280 -0.692720 0.376611 -1.718606
DataFrame创建矩阵用法二
import numpy as npimport pandas as pd# dates = pd.date_range('20130101', periods=6)# df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list('ABCD'))#使用字典创建DataFramedf = pd.DataFrame({'A': 1,'B': pd.Timestamp('20130102'),'C': pd.Series(1, index=list(range(4)), dtype='float32'),'D': np.array([3]*4, dtype='int32'),'E': pd.Categorical(['test', 'train', 'test', 'train']),'F': 'foo'})print(df)
A B C D E F0 1 2013-01-02 1.0 3 test foo 1 1 2013-01-02 1.0 3 train foo 2 1 2013-01-02 1.0 3 test foo 3 1 2013-01-02 1.0 3 train foo
从结果可以看出,DataFrame的行标头默认为数字,我们用字典赋值的是列标头
查看这个df的每列的数据类型
A int64 B datetime64[ns] C float32
D int32
E category
F object
dtype: object
4.查看数据
df.head()
import numpy as npimport pandas as pd# dates = pd.date_range('20130101', periods=6)# df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list('ABCD'))df = pd.DataFrame({'A': 1,'B': pd.Timestamp('20130102'),'C': pd.Series(1, index=list(range(4)), dtype='float32'),'D': np.array([3]*4, dtype='int32'),'E': pd.Categorical(['test', 'train', 'test', 'train']),'F': 'foo'})print(df.head()) %查看所有数据
A B C D E F0 1 2013-01-02 1.0 3 test foo
1 1 2013-01-02 1.0 3 train foo
2 1 2013-01-02 1.0 3 test foo
3 1 2013-01-02 1.0 3 train foo
df.tail()
print(df.tail(2)) %查看最后的两行数据
A B C D E F2 1 2013-01-02 1.0 3 test foo
3 1 2013-01-02 1.0 3 train foo
df.index
print(df.index) %查看DataFrame的行标头
Int64Index([0, 1, 2, 3], dtype=’int64’)
df.columns
print(df.columns) %查看DataFrame的列标头
Index([‘A’, ‘B’, ‘C’, ‘D’, ‘E’, ‘F’], dtype=’object’)
df.to_numpy()
注意:使用df.to_numpy()将DataFrame转换为Numpy是需要很高的代价的。这是因为:Numpy arrays对于整个矩阵而言只会有一个数据类型,而DataFrame每列都可为不同的数据类型。这就很可能导致,Numpy arrys中的数据最终只有一个父类: object类型。
import numpy as npimport pandas as pd# dates = pd.date_range('20130101', periods=6)# df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list('ABCD'))df = pd.DataFrame({'A': 1,'B': pd.Timestamp('20130102'),'C': pd.Series(1, index=list(range(4)), dtype='float32'),'D': np.array([3]*4, dtype='int32'),'E': pd.Categorical(['test', 'train', 'test', 'train']),'F': 'foo'})nf = df.to_numpy() %转换为numpy类型的时候没有行表头和列表头print(nf)
[[1 Timestamp(‘2013-01-02 00:00:00’) 1.0 3 ‘test’ ‘foo’]
[1 Timestamp(‘2013-01-02 00:00:00’) 1.0 3 ‘train’ ‘foo’]
[1 Timestamp(‘2013-01-02 00:00:00’) 1.0 3 ‘test’ ‘foo’]
[1 Timestamp(‘2013-01-02 00:00:00’) 1.0 3 ‘train’ ‘foo’]]
descirbe()
describe() : 展示了数据的统计结果
import numpy as npimport pandas as pd# dates = pd.date_range('20130101', periods=6)# df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list('ABCD'))df = pd.DataFrame({'A': 1,'B': pd.Timestamp('20130102'),'C': pd.Series(1, index=list(range(4)), dtype='float32'),'D': np.array([3]*4, dtype='int32'),'E': pd.Categorical(['test', 'train', 'test', 'train']),'F': 'foo'})print(df.describe())
A C Dcount 4.0 4.0 4.0
mean 1.0 1.0 3.0
std 0.0 0.0 0.0
min 1.0 1.0 3.0
25% 1.0 1.0 3.0
50% 1.0 1.0 3.0
75% 1.0 1.0 3.0
max 1.0 1.0 3.0
df.T
df.T:DataFrame转置
import numpy as npimport pandas as pd# dates = pd.date_range('20130101', periods=6)# df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list('ABCD'))df = pd.DataFrame({'A': 1,'B': pd.Timestamp('20130102'),'C': pd.Series(1, index=list(range(4)), dtype='float32'),'D': np.array([3]*4, dtype='int32'),'E': pd.Categorical(['test', 'train', 'test', 'train']),'F': 'foo'})print(df.T)
0 ... 3A 1 … 1
B 2013-01-02 00:00:00 … 2013-01-02 00:00:00
C 1 … 1
D 3 … 3
E test … train
F foo … foo
[6 rows x 4 columns]
sort_index()
import numpy as npimport pandas as pd# dates = pd.date_range('20130101', periods=6)# df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list('ABCD'))df = pd.DataFrame({'A': 1,'B': pd.Timestamp('20130102'),'C': pd.Series(1, index=list(range(4)), dtype='float32'),'D': np.array([3]*4, dtype='int32'),'E': pd.Categorical(['test', 'train', 'test', 'train']),'F': 'foo'})print(df)print(df.sort_index(axis=1, ascending=False))
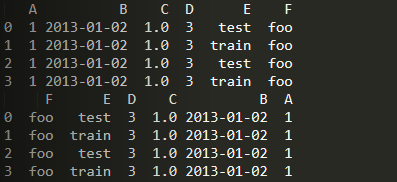
sort_values()
import numpy as npimport pandas as pddates = pd.date_range('20130101', periods=6)df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list('ABCD'))df = pd.DataFrame({'A': 1,'B': pd.Timestamp('20130102'),'C': pd.Series(1, index=list(range(4)), dtype='float32'),'D': np.array(np.random.rand(4), dtype='float32'),'E': pd.Categorical(['test', 'train', 'test', 'train']),'F': 'foo'})print(df)print(df.sort_values(by='D'))
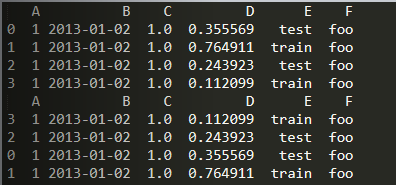
5.选择数据
列
import numpy as npimport pandas as pddates = pd.date_range('20130101', periods=6)df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list('ABCD'))df = pd.DataFrame({'A': 1,'B': pd.Timestamp('20130102'),'C': pd.Series(1, index=list(range(4)), dtype='float32'),'D': np.array(np.random.rand(4), dtype='float32'),'E': pd.Categorical(['test', 'train', 'test', 'train']),'F': 'foo'})print(df)print(df['A'])
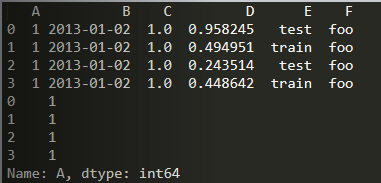
行
import numpy as npimport pandas as pddates = pd.date_range('20130101', periods=6)df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list('ABCD'))df = pd.DataFrame({'A': 1,'B': pd.Timestamp('20130102'),'C': pd.Series(1, index=list(range(4)), dtype='float32'),'D': np.array(np.random.rand(4), dtype='float32'),'E': pd.Categorical(['test', 'train', 'test', 'train']),'F': 'foo'})print(df)print(df[0: 2])
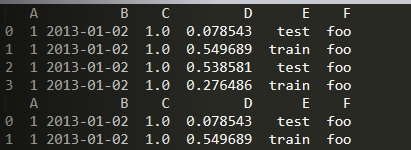
loc函数
不带标头的第一行
import numpy as npimport pandas as pddates = pd.date_range('20130101', periods=6)df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list('ABCD'))# df = pd.DataFrame({# 'A': 1,# 'B': pd.Timestamp('20130102'),# 'C': pd.Series(1, index=list(range(4)), dtype='float32'),# 'D': np.array(np.random.rand(4), dtype='float32'),# 'E': pd.Categorical(['test', 'train', 'test', 'train']),# 'F': 'foo'# })print(df)print(df.loc[dates[0]])
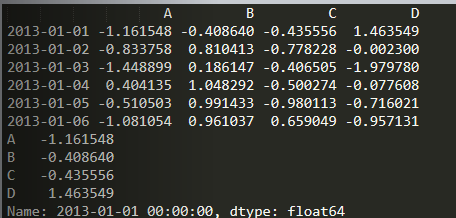
特定列数据
import numpy as npimport pandas as pddates = pd.date_range('20130101', periods=6)df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list('ABCD'))print(df)print(df.loc[:, ['A', 'B']])
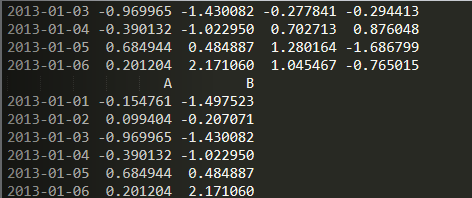
iloc函数
import numpy as npimport pandas as pddates = pd.date_range('20130101', periods=6)df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list('ABCD'))print(df)print(df.iloc[3])
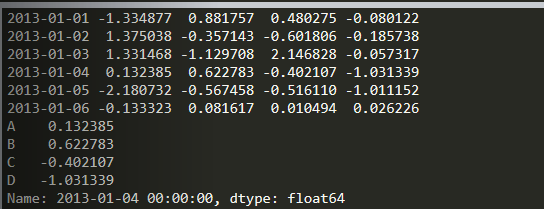
import numpy as npimport pandas as pddates = pd.date_range('20130101', periods=6)df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list('ABCD'))print(df)print(df.iloc[2: 4, 0: 2])

import numpy as npimport pandas as pddates = pd.date_range('20130101', periods=6)df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list('ABCD'))print(df)print(df.iloc[[2, 4], [0, 2]])

iat函数
import numpy as npimport pandas as pddates = pd.date_range('20130101', periods=6)df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list('ABCD'))print(df)print(df.iat[1, 1])
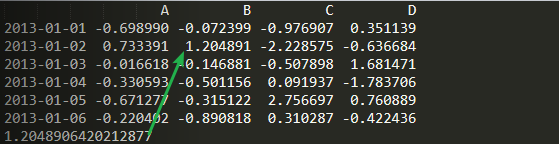
逻辑判断,找到符合条件的数据
import numpy as npimport pandas as pddates = pd.date_range('20130101', periods=6)df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list('ABCD'))print(df)print(df[df['A'] > 0])
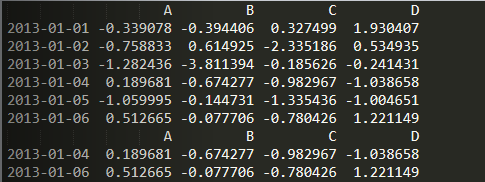
import numpy as npimport pandas as pddates = pd.date_range('20130101', periods=6)df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list('ABCD'))print(df)print(df > 0)print(df[df > 0])
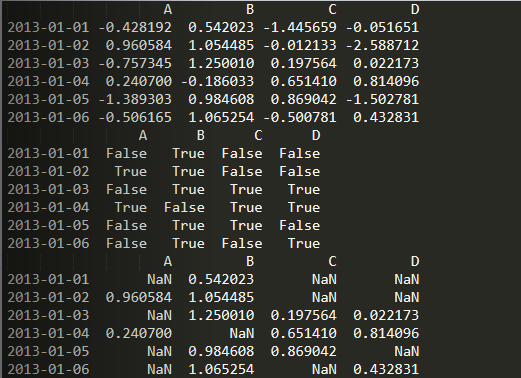
isin函数
import numpy as npimport pandas as pddates = pd.date_range('20130101', periods=6)df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list('ABCD'))df2 = df.copy()df2['E'] = ['one', 'one', 'two', 'three', 'four', 'three']print(df2)print(df[df2['E'].isin(['two', 'three'])])
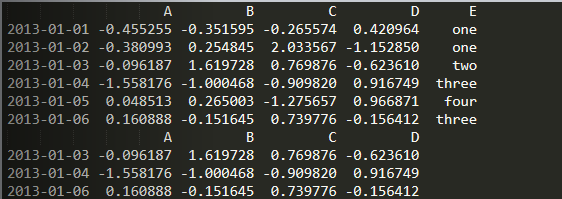
6.改变DataFrame数据
import numpy as npimport pandas as pddates = pd.date_range('20130101', periods=6)df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list('ABCD'))s1 = pd.Series(np.arange(6)+1, index=pd.date_range('20130102', periods=6))print(df)df['F'] = s1df.at[dates[0], 'A'] = 0df.iat[0, 1] = 0df.loc[:, 'D'] = np.array([5] * len(df))print(df)
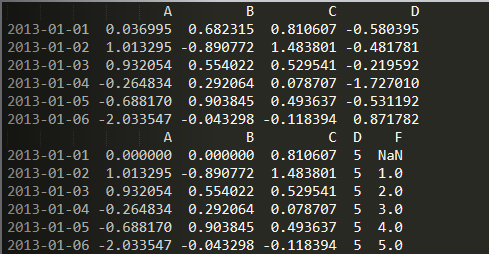

若有收获,就点个赞吧
0 人点赞
