一 什么是消息传递方案
将卷积算子推广到不规则域通常表示为邻域聚合或消息传递方案。其中
 表示在第
表示在第 层的节点
层的节点 的节点特征
的节点特征 表示从节点
表示从节点 到节点的边的特征
到节点的边的特征
所以消息传递网络可以被描述为:
上述式子一中的参数解释:
 表示一个可微分的,改变位置但是不改变值得函数,例如:求和函数
表示一个可微分的,改变位置但是不改变值得函数,例如:求和函数 、平均数或者最大数
、平均数或者最大数 和
和 表示可微分的函数,例如:MLP(多层感知机)
表示可微分的函数,例如:MLP(多层感知机)
二 消息传递基类
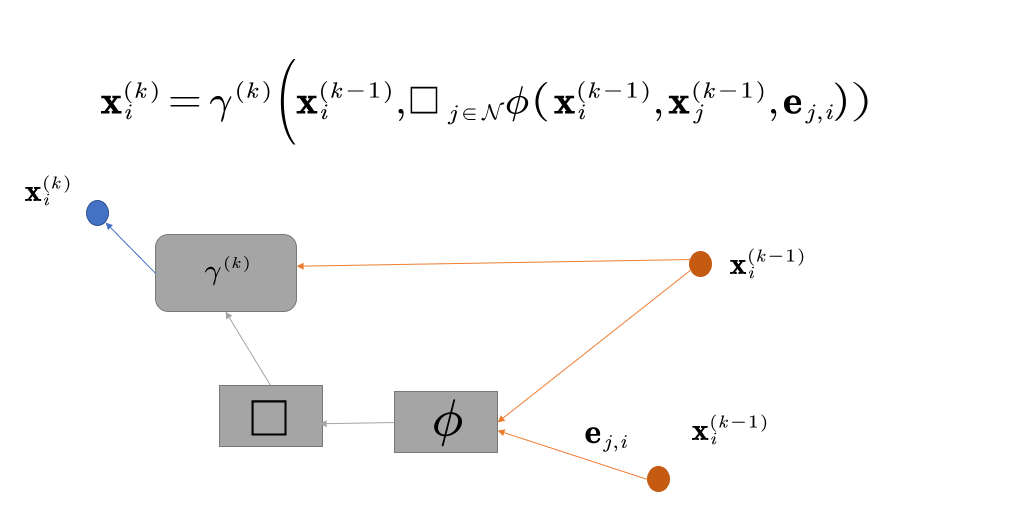
PyTorch Geometric(后面简称为PyT)提供了MessagePassing作为消息传递得基类,只需要处理好这个基类得关系我们就可以自定义一些自己的网络出来,由公式1来看,我们在使用这个网络过程当中需要关注的东西只有3个
- 函数:对应
message()函数 - 函数
 :对应
:对应update()函数 - 以及我们要使用到的聚合模式:
aggr="add"、aggr="mean"或者aggr="max"
下面是官方文档给的关于这3个需要重点关注的一些帮助:
MessagePassing(aggr="add", flow="source_to_target", node_dim=-2):这个就是PyT提供的MessagePassing接口需要输入的3个参数,- 第一个就是聚合模式,就是上述说的3中聚合模式
- 第二个是表示聚合的方向,上面给的是
source_to_target,那么同理会有target_to_source - 第三个参数
node_dim表示的是沿着哪个轴进行传递消息
MessagePassing.propagate(edge_index, size=None, **kwargs):调用消息传递的初始函数。这个函数使用到的参数edge_index是边的索引,另外要想构建一个网络肯定还需要别的数据。propagate()这个传递函数并不局限于只传递邻接矩阵为 大小的对称矩阵,它也可以传递
大小的对称矩阵,它也可以传递 大小的邻接矩阵,这个时候传递的参数
大小的邻接矩阵,这个时候传递的参数size=(N,M),而我们上述默认的size=None就代表是一个对称的邻接矩阵。通过数组索引,我们就能找到邻接矩阵中对应节点,例如 。
。

图2. 邻接矩阵
MessagePassing.message(...):在flow="source_to_target"的情况下,就创建向节点流动的消息;如果flow="target_to_source"就传递向节点的消息。它会处理propagate()中的输入参数edge_index,然后通过给节点的名字后面添上_i或_j来确定带有_i是的中心节点(source),带有_j的邻边节点。对应的是公式1中的函数。
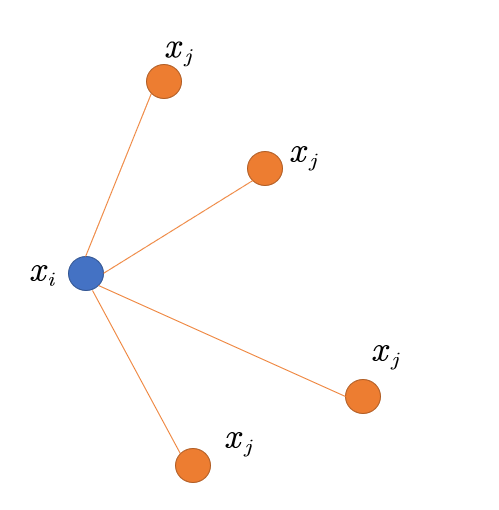
图3. 中心节点和邻边节点
MessagePassing.update(aggr_out, ...):对于每个节点更新节点的状态,对应的是公式1中的函数。
下面通过使用两个简单的GNN的例子,GCN和EdgeConv来看一下怎么使用。
三 GCN例子
GCN层在数学上定义为:
通过上面的式子2,我们可以看到一个GCN层做了3个工作:
- 输入的节点特征首先被权重矩阵
 进行了改变
进行了改变 - 然后通过它们的度进行归一化
- 再将其相加
同样的,在写代码的时候,我们也可以将步骤分解,步骤如下:
- 在邻接矩阵中添加自循环(self-loops)
- 对节点的特征矩阵进行线性变换
- 计算归一化参数
- 在中归一化节点特征
- 将邻边节点特征加起来(对应的
aggr="add")
其中的步骤1-3在消息传递之前被计算,通过使用MessagePassing这个基类接口步骤4-5也同样能够很简单地实现,整个网络层实现如下:
import torchfrom torch_geometric.nn import MessagePassingfrom torch_geometric.utils import add_self_loops, degreeclass GCNConv(MessagePassing):def __init__(self, in_channels, out_channels):super(GCNConv, self).__init__(aggr='add') # 对应步骤5的aggr="add"聚类方式self.lin = torch.nn.Linear(in_channels, out_channels)def forward(self, x, edge_index):# x的大小为[N, in_channels]# edge_index的大小为[2, E]# 步骤1:给邻接矩阵添加自循环edge_index, _ = add_self_loops(edge_index, num_nodes=x.size(0))# 步骤2:给特征矩阵进行线性变换x = self.lin(x)# 步骤3:计算归一化row, col = edge_indexdeg = degree(col, x.size(0), dtype=x.type)deg_inv_sqrt = deg.pow(-0.5)norm = deg_inv_sqrt[row] * deg_inv_sqrt[col]# 步骤4-5:开始传递消息return self.propagate(edge_index, x=x, norm=norm)def message(self, x_j, norm):# x_j的大小为 [E, out_channels]# 步骤4: 归一化节点特征return norm.view(-1,1) * x_j
在上述代码中中,数据在进入网络->出去网络都是在forward()函数中进行的。上述代码中通过使用torch_geometric.utils.add_self_loops()函数实现步骤1,即给边索引添加自循环。通过使用torch.nn.Linear函数实现节点特征的线性变换,实现了步骤2。
3.1 add_self_loops()函数
下面是add_self_loops()函数的源码:
def add_self_loops(edge_index, edge_weight: Optional[torch.Tensor] = None,fill_value: float = 1., num_nodes: Optional[int] = None):r"""Adds a self-loop :math:`(i,i) \in \mathcal{E}` to every node:math:`i \in \mathcal{V}` in the graph given by :attr:`edge_index`.In case the graph is weighted, self-loops will be added with edge weightsdenoted by :obj:`fill_value`.Args:edge_index (LongTensor): The edge indices.edge_weight (Tensor, optional): One-dimensional edge weights.(default: :obj:`None`)fill_value (float, optional): If :obj:`edge_weight` is not :obj:`None`,will add self-loops with edge weights of :obj:`fill_value` to thegraph. (default: :obj:`1.`)num_nodes (int, optional): The number of nodes, *i.e.*:obj:`max_val + 1` of :attr:`edge_index`. (default: :obj:`None`):rtype: (:class:`LongTensor`, :class:`Tensor`)"""N = maybe_num_nodes(edge_index, num_nodes)loop_index = torch.arange(0, N, dtype=torch.long, device=edge_index.device)loop_index = loop_index.unsqueeze(0).repeat(2, 1)if edge_weight is not None:assert edge_weight.numel() == edge_index.size(1)loop_weight = edge_weight.new_full((N, ), fill_value)edge_weight = torch.cat([edge_weight, loop_weight], dim=0)edge_index = torch.cat([edge_index, loop_index], dim=1)return edge_index, edge_weight
通过上述源码的解释,可以知道这个函数是对节点 添加一条边
添加一条边 ,添加的值默认为1.
,添加的值默认为1.
3.2 torch.nn.Linear()
这个函数是比较常见的,在CNN网络中也非常常见,这里就不解释了。
3.3 归一化
 对应的有度
对应的有度 ,然后将其归一化
,然后将其归一化 。
。
3.4 传递消息
之后就开始在节点和节点之间传递消息,在上述的例子中调用的是函数propagate()。这个函数会一次调用message()、aggregate和update()函数,我们需要传递节点的特征x和归一化因子norm从而完成整个消息的传递。
3.5 使用网络
conv = GCNConv(16, 32)x = conv(x, edge_index)
四 EdgeConv例子
edge卷积层是用来处理点云数据的,数学上定义为:
其中的 表示的是一个多层感知机,类比于上面的GCN,我们同样可以使用
表示的是一个多层感知机,类比于上面的GCN,我们同样可以使用MessagePassing基类实现这个网络,这次使用的是aggr="max".
import torchfrom torch.nn import Sequential as Seq, Linear, ReLUclass EdgeConv(MessagePassing):def __init__(self, in_channels, out_channels):super(EdgeConv, self).__init__(aggr="max") # 聚合方式为maxself.mlp = Seq(Linear(2*in_channels, out_channels), ReLU(), Linear(out_channels, out_channels))def forward(self, x, edge_index):# x的大小[N, in_channels]# edge_index的大小[2,E]return self.propagate(edge_index, x=x)def message(self, x_i, x_j):# x_i的大小[E, in_channels]# x_j的大小[E, in_channels]tmp = torch.cat([x_i, x_j-x_i], dim=1) # tmp的大小 [E, 2*in_channels]return self.mlp(tmp)
在这个message()函数中,使用了self.mlp同时计算了目标节点的特征x_i和对每条边 其相邻的节点的特征
其相邻的节点的特征x_j - x_i.
边缘卷积实际上是一种动态卷积,它使用特征空间中的最近邻方法重新计算每一层的图,PyT中有一个函数带有GPU加速的分批k-NN图生成方法,是torch_geometric.nn.pool.knn_graph().
这里的knn_graph()计算了最近邻的图,并且调用了EdgeConv中的forward()函数.
使用上述定义的网络:
conv = DynamicEdgeConv(3, 128, k=6)x = conv(x, batch)
五 MessagePassing()源码
最后将官方的源码放上,可以自己调试一下这个MessagePassing()接口,看看到底做了什么.
import osimport reimport inspectimport os.path as ospfrom uuid import uuid1from itertools import chainfrom inspect import Parameterfrom typing import List, Optional, Setfrom torch_geometric.typing import Adj, Sizeimport torchfrom torch import Tensorfrom jinja2 import Templatefrom torch_sparse import SparseTensorfrom torch_scatter import gather_csr, scatter, segment_csrfrom .utils.helpers import expand_leftfrom .utils.jit import class_from_module_reprfrom .utils.typing import (sanitize, split_types_repr, parse_types,resolve_types)from .utils.inspector import Inspector, func_header_repr, func_body_reprclass MessagePassing(torch.nn.Module):r"""Base class for creating message passing layers of the form.. math::\mathbf{x}_i^{\prime} = \gamma_{\mathbf{\Theta}} \left( \mathbf{x}_i,\square_{j \in \mathcal{N}(i)} \, \phi_{\mathbf{\Theta}}\left(\mathbf{x}_i, \mathbf{x}_j,\mathbf{e}_{j,i}\right) \right),where :math:`\square` denotes a differentiable, permutation invariantfunction, *e.g.*, sum, mean or max, and :math:`\gamma_{\mathbf{\Theta}}`and :math:`\phi_{\mathbf{\Theta}}` denote differentiable functions such asMLPs.See `here <https://pytorch-geometric.readthedocs.io/en/latest/notes/create_gnn.html>`__ for the accompanying tutorial.Args:aggr (string, optional): The aggregation scheme to use(:obj:`"add"`, :obj:`"mean"`, :obj:`"max"` or :obj:`None`).(default: :obj:`"add"`)flow (string, optional): The flow direction of message passing(:obj:`"source_to_target"` or :obj:`"target_to_source"`).(default: :obj:`"source_to_target"`)node_dim (int, optional): The axis along which to propagate.(default: :obj:`-2`)"""special_args: Set[str] = {'edge_index', 'adj_t', 'edge_index_i', 'edge_index_j', 'size','size_i', 'size_j', 'ptr', 'index', 'dim_size'}def __init__(self, aggr: Optional[str] = "add",flow: str = "source_to_target", node_dim: int = -2):super(MessagePassing, self).__init__()self.aggr = aggrassert self.aggr in ['add', 'mean', 'max', None]self.flow = flowassert self.flow in ['source_to_target', 'target_to_source']self.node_dim = node_dimself.inspector = Inspector(self)self.inspector.inspect(self.message)self.inspector.inspect(self.aggregate, pop_first=True)self.inspector.inspect(self.message_and_aggregate, pop_first=True)self.inspector.inspect(self.update, pop_first=True)self.__user_args__ = self.inspector.keys(['message', 'aggregate', 'update']).difference(self.special_args)self.__fused_user_args__ = self.inspector.keys(['message_and_aggregate', 'update']).difference(self.special_args)# Support for "fused" message passing.self.fuse = self.inspector.implements('message_and_aggregate')# Support for GNNExplainer.self.__explain__ = Falseself.__edge_mask__ = Nonedef __check_input__(self, edge_index, size):the_size: List[Optional[int]] = [None, None]if isinstance(edge_index, Tensor):assert edge_index.dtype == torch.longassert edge_index.dim() == 2assert edge_index.size(0) == 2if size is not None:the_size[0] = size[0]the_size[1] = size[1]return the_sizeelif isinstance(edge_index, SparseTensor):if self.flow == 'target_to_source':raise ValueError(('Flow direction "target_to_source" is invalid for ''message propagation via `torch_sparse.SparseTensor`. If ''you really want to make use of a reverse message ''passing flow, pass in the transposed sparse tensor to ''the message passing module, e.g., `adj_t.t()`.'))the_size[0] = edge_index.sparse_size(1)the_size[1] = edge_index.sparse_size(0)return the_sizeraise ValueError(('`MessagePassing.propagate` only supports `torch.LongTensor` of ''shape `[2, num_messages]` or `torch_sparse.SparseTensor` for ''argument `edge_index`.'))def __set_size__(self, size: List[Optional[int]], dim: int, src: Tensor):the_size = size[dim]if the_size is None:size[dim] = src.size(self.node_dim)elif the_size != src.size(self.node_dim):raise ValueError((f'Encountered tensor with size {src.size(self.node_dim)} in 'f'dimension {self.node_dim}, but expected size {the_size}.'))def __lift__(self, src, edge_index, dim):if isinstance(edge_index, Tensor):index = edge_index[dim]return src.index_select(self.node_dim, index)elif isinstance(edge_index, SparseTensor):if dim == 1:rowptr = edge_index.storage.rowptr()rowptr = expand_left(rowptr, dim=self.node_dim, dims=src.dim())return gather_csr(src, rowptr)elif dim == 0:col = edge_index.storage.col()return src.index_select(self.node_dim, col)raise ValueErrordef __collect__(self, args, edge_index, size, kwargs):i, j = (1, 0) if self.flow == 'source_to_target' else (0, 1)out = {}for arg in args:if arg[-2:] not in ['_i', '_j']:out[arg] = kwargs.get(arg, Parameter.empty)else:dim = 0 if arg[-2:] == '_j' else 1data = kwargs.get(arg[:-2], Parameter.empty)if isinstance(data, (tuple, list)):assert len(data) == 2if isinstance(data[1 - dim], Tensor):self.__set_size__(size, 1 - dim, data[1 - dim])data = data[dim]if isinstance(data, Tensor):self.__set_size__(size, dim, data)data = self.__lift__(data, edge_index,j if arg[-2:] == '_j' else i)out[arg] = dataif isinstance(edge_index, Tensor):out['adj_t'] = Noneout['edge_index'] = edge_indexout['edge_index_i'] = edge_index[i]out['edge_index_j'] = edge_index[j]out['ptr'] = Noneelif isinstance(edge_index, SparseTensor):out['adj_t'] = edge_indexout['edge_index'] = Noneout['edge_index_i'] = edge_index.storage.row()out['edge_index_j'] = edge_index.storage.col()out['ptr'] = edge_index.storage.rowptr()out['edge_weight'] = edge_index.storage.value()out['edge_attr'] = edge_index.storage.value()out['edge_type'] = edge_index.storage.value()out['index'] = out['edge_index_i']out['size'] = sizeout['size_i'] = size[1] or size[0]out['size_j'] = size[0] or size[1]out['dim_size'] = out['size_i']return outdef propagate(self, edge_index: Adj, size: Size = None, **kwargs):r"""The initial call to start propagating messages.Args:edge_index (Tensor or SparseTensor): A :obj:`torch.LongTensor` or a:obj:`torch_sparse.SparseTensor` that defines the underlyinggraph connectivity/message passing flow.:obj:`edge_index` holds the indices of a general (sparse)assignment matrix of shape :obj:`[N, M]`.If :obj:`edge_index` is of type :obj:`torch.LongTensor`, itsshape must be defined as :obj:`[2, num_messages]`, wheremessages from nodes in :obj:`edge_index[0]` are sent tonodes in :obj:`edge_index[1]`(in case :obj:`flow="source_to_target"`).If :obj:`edge_index` is of type:obj:`torch_sparse.SparseTensor`, its sparse indices:obj:`(row, col)` should relate to :obj:`row = edge_index[1]`and :obj:`col = edge_index[0]`.The major difference between both formats is that we need toinput the *transposed* sparse adjacency matrix into:func:`propagate`.size (tuple, optional): The size :obj:`(N, M)` of the assignmentmatrix in case :obj:`edge_index` is a :obj:`LongTensor`.If set to :obj:`None`, the size will be automatically inferredand assumed to be quadratic.This argument is ignored in case :obj:`edge_index` is a:obj:`torch_sparse.SparseTensor`. (default: :obj:`None`)**kwargs: Any additional data which is needed to construct andaggregate messages, and to update node embeddings."""size = self.__check_input__(edge_index, size)# Run "fused" message and aggregation (if applicable).if (isinstance(edge_index, SparseTensor) and self.fuseand not self.__explain__):coll_dict = self.__collect__(self.__fused_user_args__, edge_index,size, kwargs)msg_aggr_kwargs = self.inspector.distribute('message_and_aggregate', coll_dict)out = self.message_and_aggregate(edge_index, **msg_aggr_kwargs)update_kwargs = self.inspector.distribute('update', coll_dict)return self.update(out, **update_kwargs)# Otherwise, run both functions in separation.elif isinstance(edge_index, Tensor) or not self.fuse:coll_dict = self.__collect__(self.__user_args__, edge_index, size,kwargs)msg_kwargs = self.inspector.distribute('message', coll_dict)out = self.message(**msg_kwargs)# For `GNNExplainer`, we require a separate message and aggregate# procedure since this allows us to inject the `edge_mask` into the# message passing computation scheme.if self.__explain__:edge_mask = self.__edge_mask__.sigmoid()# Some ops add self-loops to `edge_index`. We need to do the# same for `edge_mask` (but do not train those).if out.size(self.node_dim) != edge_mask.size(0):loop = edge_mask.new_ones(size[0])edge_mask = torch.cat([edge_mask, loop], dim=0)assert out.size(self.node_dim) == edge_mask.size(0)out = out * edge_mask.view([-1] + [1] * (out.dim() - 1))aggr_kwargs = self.inspector.distribute('aggregate', coll_dict)out = self.aggregate(out, **aggr_kwargs)update_kwargs = self.inspector.distribute('update', coll_dict)return self.update(out, **update_kwargs)def message(self, x_j: Tensor) -> Tensor:r"""Constructs messages from node :math:`j` to node :math:`i`in analogy to :math:`\phi_{\mathbf{\Theta}}` for each edge in:obj:`edge_index`.This function can take any argument as input which was initiallypassed to :meth:`propagate`.Furthermore, tensors passed to :meth:`propagate` can be mapped to therespective nodes :math:`i` and :math:`j` by appending :obj:`_i` or:obj:`_j` to the variable name, *.e.g.* :obj:`x_i` and :obj:`x_j`."""return x_jdef aggregate(self, inputs: Tensor, index: Tensor,ptr: Optional[Tensor] = None,dim_size: Optional[int] = None) -> Tensor:r"""Aggregates messages from neighbors as:math:`\square_{j \in \mathcal{N}(i)}`.Takes in the output of message computation as first argument and anyargument which was initially passed to :meth:`propagate`.By default, this function will delegate its call to scatter functionsthat support "add", "mean" and "max" operations as specified in:meth:`__init__` by the :obj:`aggr` argument."""if ptr is not None:ptr = expand_left(ptr, dim=self.node_dim, dims=inputs.dim())return segment_csr(inputs, ptr, reduce=self.aggr)else:return scatter(inputs, index, dim=self.node_dim, dim_size=dim_size,reduce=self.aggr)def message_and_aggregate(self, adj_t: SparseTensor) -> Tensor:r"""Fuses computations of :func:`message` and :func:`aggregate` into asingle function.If applicable, this saves both time and memory since messages do notexplicitly need to be materialized.This function will only gets called in case it is implemented andpropagation takes place based on a :obj:`torch_sparse.SparseTensor`."""raise NotImplementedErrordef update(self, inputs: Tensor) -> Tensor:r"""Updates node embeddings in analogy to:math:`\gamma_{\mathbf{\Theta}}` for each node:math:`i \in \mathcal{V}`.Takes in the output of aggregation as first argument and any argumentwhich was initially passed to :meth:`propagate`."""return inputs@torch.jit.unuseddef jittable(self, typing: Optional[str] = None):r"""Analyzes the :class:`MessagePassing` instance and produces a newjittable module.Args:typing (string, optional): If given, will generate a concreteinstance with :meth:`forward` types based on :obj:`typing`,*e.g.*: :obj:`"(Tensor, Optional[Tensor]) -> Tensor"`."""# Find and parse `propagate()` types to format `{arg1: type1, ...}`.if hasattr(self, 'propagate_type'):prop_types = {k: sanitize(str(v))for k, v in self.propagate_type.items()}else:source = inspect.getsource(self.__class__)match = re.search(r'#\s*propagate_type:\s*\((.*)\)', source)if match is None:raise TypeError('TorchScript support requires the definition of the types ''passed to `propagate()`. Please specificy them via\n\n''propagate_type = {"arg1": type1, "arg2": type2, ... }\n\n''or via\n\n''# propagate_type: (arg1: type1, arg2: type2, ...)\n\n''inside the `MessagePassing` module.')prop_types = split_types_repr(match.group(1))prop_types = dict([re.split(r'\s*:\s*', t) for t in prop_types])# Parse `__collect__()` types to format `{arg:1, type1, ...}`.collect_types = self.inspector.types(['message', 'aggregate', 'update'])# Collect `forward()` header, body and @overload types.forward_types = parse_types(self.forward)forward_types = [resolve_types(*types) for types in forward_types]forward_types = list(chain.from_iterable(forward_types))keep_annotation = len(forward_types) < 2forward_header = func_header_repr(self.forward, keep_annotation)forward_body = func_body_repr(self.forward, keep_annotation)if keep_annotation:forward_types = []elif typing is not None:forward_types = []forward_body = 8 * ' ' + f'# type: {typing}\n{forward_body}'root = os.path.dirname(osp.realpath(__file__))with open(osp.join(root, 'message_passing.jinja'), 'r') as f:template = Template(f.read())uid = uuid1().hex[:6]cls_name = f'{self.__class__.__name__}Jittable_{uid}'jit_module_repr = template.render(uid=uid,module=str(self.__class__.__module__),cls_name=cls_name,parent_cls_name=self.__class__.__name__,prop_types=prop_types,collect_types=collect_types,user_args=self.__user_args__,forward_header=forward_header,forward_types=forward_types,forward_body=forward_body,msg_args=self.inspector.keys(['message']),aggr_args=self.inspector.keys(['aggregate']),msg_and_aggr_args=self.inspector.keys(['message_and_aggregate']),update_args=self.inspector.keys(['update']),check_input=inspect.getsource(self.__check_input__)[:-1],lift=inspect.getsource(self.__lift__)[:-1],)# Instantiate a class from the rendered JIT module representation.cls = class_from_module_repr(cls_name, jit_module_repr)module = cls.__new__(cls)module.__dict__ = self.__dict__.copy()module.jittable = Nonereturn module

若有收获,就点个赞吧
0 人点赞
