- 对于程序设计来说,输入输出(Input/Output)系统是非常核心的功能。
- 输入(Input)指的是:可以让程序从外部系统获得数据(核心含义是“读”,读取外部数据)。
- 输出(Output)指的是:将程序获取到的数据输出到外部。
文件相关知识
1. 文件的路径
1. 文件的路径一般表示为: "C:/Users/zs/Desktop/th.jpg";2. 在Windows中文件的路径表示为: "C:\Users\zs\Desktop\th.jpg"3. 在我们的编译中"\"作为转义字符使用,所以我们一般会用"\\"表示我们的"\".4. 除过斜杆拼接,我们在Java中还有"File.separator"可以作为拼接常量,供我们使用.
2. 构建文件对象
String path = "C:/Users/zs/Desktop/th.jpg";
File src = new File(path);
// 通过字符串对象的路径构建File对象
src = new File("C:/Users/zs/Desktop/th.jpg");
// 直接通过字符串的路径构建File对象
src = new File(new File("C:/Users/zs/Desktop/"),"th.jpg");
// 首先确定要构造文件目录的对象,然后再确定相对应的文件.
3. 相对路径与绝对路径
// 从文件根路径开始的路径就是绝对路径
// 不是从文件根路径开始的路径就是相对路径
File src = new File(path);
src.getAbsolutePath();
// 获取文件的绝对路径
System.getProperty("user.dir");
// 获取项目的相对路径
4. 获取文件的名称和路径
src.getName(); //获取文件的名称
src.getPath(); //获取文件的路径
src.getAbsolutePath(); //获取文件的绝对路径
src.getParent(); //获取文件的父节点
src.getParentFile(); //获取文件的父对象
5. 获取文件的状态
src.exists(); // 判断文件是否存在
src.isFile(); // 判断是否文件
src.isDirectory(); //判断是否文件夹
// 文件状态判断的完整操作
src = new File("xxx");
if (src == null || !src.exists()) {
// 文件不存在
} else {
if (src.isFile()) {
// 文件操作
} else {
// 文件夹操作
}
}
6. 文件的长度
src.length(); // 获取文件的长度(大小)
// 注意:只能获取文件的长度,不能获取整个文件夹的大小
7. 创建/删除文件
File src = new File("C:/Users/zs/Desktop/th.txt");
boolean flag = src.createNewFile();
// 创建文件,不存在才创建,创建成功返回true
flag = src.delete();
// 删除文件,删除成功,返回true
// 再创建文件时要注意:con con3... 操作系统的设备名,不能正确的创建.
8. 创建文件夹
// 1. mkdir():确保上级目录存在,不存在创建失败
// 2. mkdirs():上级目录可以不存在,不存在创建失败
// 都是通过返回boolean值来表示文件夹是否创建成功
File dir = new File("F:/IDEA_project/Java300/dir/test");
boolean flag = dir.mkdirs();
flag = dir.mkdir();
9. 列出目录的下一级
// list():列出下级名称
// listFiles():列出下级File对象,这儿可以得到下一级文件夹/文件的对象
String[] subNames = dir.list();
File[] subFiles = dir.listFiles();
10. 文件的解码/编码
// decode 解码 : 字节数组-->字符串
msg = new String(dates,0,datas.length,"UTF-8");
// encode 编码 : 字符串-->字节数组
byte[] datas = msg.getBytes();
11. 乱码
- 字节数不够:在使用
new String(dates,0,datas.length,"UTF-8")解码的时候date.length-1长度缺失 - 字符集不统一:使用的编码字符集不同,就会造成这种问题:
UTF-8或者GBK字符集
数据源(data source)
- 数据源分为:源设备、目标设备。
- 源设备(src):为程序提供数据,一般对应输入流。
- 目标设备(dest):程序数据的目的地,一般对应输出流。
流(stream)
- 流是一个抽象、动态的概念,是一连串连续动态的数据集合。
- 输入流:我们通过流(Stream)将数据源(Source)中的数据(information)输送到程序(program)中。
- 输出流:目标数据就是目的地(dest),我们通过流(Stream)将程序(Program)中的数据(information)输送到目的数据源(dest)中。
- 输入流/输出流的划分并不是相对数据源的,是相对程序而言的。
IO标准步骤
- 创建源
- 选择流
- 操作
- 释放资源(先打开的后释放)
- 标准代码
import java.io.*;
/**
* 这是输入流
* @auther 张辉
*/
public class IOStreamStandard{
public static void main(String[] args) {
// 1. 创建源
File src = new File("abc.txt");
// 2. 选择流
Reader reader = null;
try {
reader = new FileReader(src);
// 3. 操作(读取)
char[] flush = new char[1024];
// 缓冲容器
int len = -1;
// 接收长度
while ((len = reader.read(flush)) != -1) {
// 字符数组到字符串
String str = new String(flush, 0, len);
System.out.println(str);
}
} catch (FileNotFoyundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
// 4. 释放资源
try {
if (reader != null) {
reader.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
Java中流的概念细分
按流的方向分类
- 输入流:数据流向是数据源到程序(以InputStream、Reader结尾的流)。
- 输出流:数据流向是程序到目的地(以OutputStream、Write结尾的流)。
按处理的数据单元分类
- 字节流:以字节为单位获取数据,命名以上Stream结尾的流一般是字节流,如:FileInputStream、FileOutputStream。
- 字符流:以字符为单位获取数据,命名上以Reader/Writer结尾的流一般是字符流,如:FileReader、FileWriter。
按处理对象不同分类
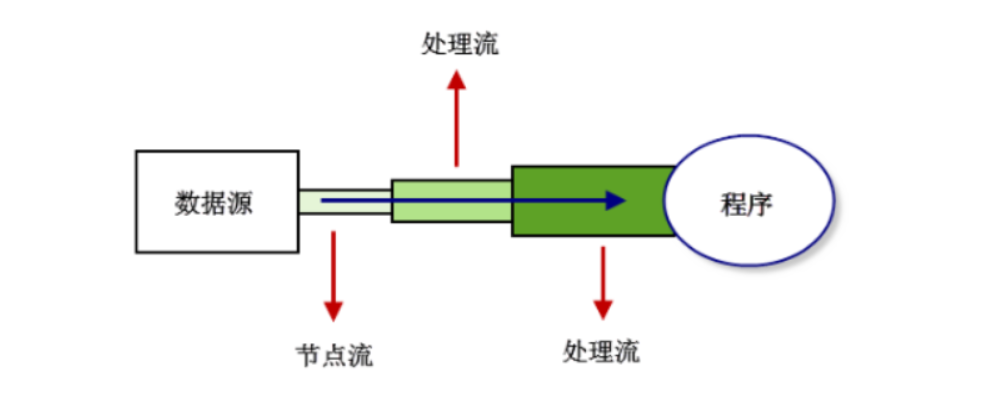
- 节点流:可以直接从数据源或目的地读写数据,如:FileInputStream、FileReader、DataInputStream等。
- 处理流:不直接连接到数据源或目的地,是”处理流的流“。通过对其他流的处理提高程序的性能,如BufferedInputStream、BufferedReader等。处理流也叫包装流。
- 节点流初于IO操作的第一线,所有操作必须通过他们进行;处理流可以对节点进行包装,提高性或提高程序的灵活性。
Java中IO流类的体系
InputStream/OutputStream: 字节流的抽象类Reader/Writer:字符流的抽象类FileInputStream/FileOutputStream
- 节点流 : 以字节为单位直接操作”文件”.
ByteArrayInputStream/ByteArrayOutputStream
- 节点流 : 以字节为单位直接操作”字节数组对象”.
FileReader/FileWriter
- 节点流 : 以字符为单位直接操作”文本文件” (注意 : 只能读写文本文件).
ObjectInputStream/ObjectOutputStream
- 处理流 : 以字节为单位直接操作”对象”.
DataInputStream/DataOutputStream- 处理流 : 以字节为单位直接操作”基本类型与字符串类型”.
BufferedReader/BufferedWriter
+ 处理流 : 将 `Reader/Writer` 对象进行包装,增加缓存功能 ,提高读写效率.
BufferedInputStream/BufferedOutputStream
+ 处理流 : 将 `InputStream/OutputStream` 对象进行包装,增加缓存功能(一般缓存8k),提高读写效率.
InputStreamReader/OutputStreamWriter
+ 处理流 : 将字节对象转化成字符流对象.
PrintStream
+ 处理流 : 将 `OUtputStream` 进行包装,可以方便地输出字符,更加灵活.
四大IO抽象类
InputStream/OutputStream和Reader/Writer类是所有IO流类的抽象父类.
InputStream
- 此抽象类是标识字节输入流的所有类的父类.
InputStream是一个抽象类,他不可以实例化.- 继承自
InputStream的流都是用于向程序中输入数据,且数据的单位为字节(8 bit). - 常用方法:
- int read() : 读取一个字节的数据,并将字节的值作为int类型返回(0-255之间的一个值).如果未读出字节则返回 -1 (返回值为 -1 表示读取结束)
- void close() : 关闭输入流对象,释放相关系统资源.
OutputStream
- 此抽象类是表示字节输出流的多有类的父类.
- 输出流接收输出字节并将这些字节发送到某个和目的地.
- 常用方法:
- void writer(int n) : 向目的中写入一个字节.
- void close() : 关闭输出流对象,释放相关资源.
Reader
- Reader用于读取的字符流抽象类,数据单位为字符.
- int read() : 读取一个字符的数据,并将字符的值作为int类型返回(0-65535之间的一个值,即 Unicode 值).如果未读出字符则返回 -1 (返回值为 -1 表示读取结束)
- void close() : 关闭流对象,释放相关资源.
Writer
- Writer用于写入的字符流抽象类,数据单位为字符.
- void writer(int n) : 向输出流中写入一个字符.
- void close() : 关闭输出流对象,释放相关资源.
文件字节流
InputStream/OutputStream- 为了减少对硬盘的读写次数,提高效率,通常设置缓存数组.相应地,读取时使用的方法为:
read(byte[] b);写入时方法为:write(byte[] b,int off,int length) - 程序中如果遇到多个流,每个流都要单独关闭,防止防止其中一个流出现异常后导致其他流无法关闭的情况.
- 在关闭多个流的时候,先打开的后关闭.
文件字节输入流
InputStream/FileInputStream文件字节输入流
import java.io.*;
public class InputStreamZh{
public static void main(String[] args) {
// 1. 创建源
File src = new File("abc.txt");
// 2. 选择流
InputStream is = null;
try {
is = new FileInputStream(src);
// 3. 操作(读取)
byte[] flush = new byte[1024];
// 缓冲容器
int len = -1;
// 接收长度
while ((len = is.read(flush)) != -1) {
String str = new String(flush,0,len);
System.out.println(str);
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
// 4. 释放资源(字节输入流可以不用释放,GC会帮我们处理,但是最好还是自己来关闭流,因为GC的回收是不确定的)
try {
if (is != null) {
is.close();
}
} catch (IOExcrption) {
e.printStackTrace();
}
}
}
}
文件字节输出流
OutputStream/FileOutputStream文件字节输出流(在输出流中都需要flush()),使用byte[]
import java.io.*;
public class OutputStreamZh{
public static void main(args) {
// 1. 创建源
File dest = new File("dest.txt");
// 2. 选择流
OutputStream os = null;
try {
os = new FileOutputStream(dest,true);
// 这儿的true,决定了文件是覆盖写入还是append.
// 3. 操作
String msg = "I am groot";
byte[] datas = msg.getBytes();
os.write(datas,0,datas.length);
os.flush();
// 刷新,防止文件内容驻留
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
// 4. 释放资源
try {
if (os != null) {
os.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
文件字节拷贝流
利用文件字节流实现文件的复制
import java.io.*;
/**
* @auther 张辉
* @Description 文件字节流复制的类
*/
public class CopyUtilsByte {
private File src;
private File dest;
private int size = 1024 * 10;
public CopyUtilsByte(String src, String dest) {
this.src = new File(src);
this.dest = new File(dest);
}
public CopyUtilsByte(String src, String dest, int size) {
this.src = new File(src);
this.dest = new File(dest);
this.size = size;
}
public CopyUtilsByte(File src, File dest) {
this.src = src;
this.dest = dest;
}
public CopyUtilsByte(File src, File dest, int size) {
this.src = src;
this.dest = dest;
this.size = size;
}
private void copy() {
try (InputStream is = new FileInputStream(src);
OutputStream os = new FileOutputStream(dest);) {
byte[] flush = new byte[this.size];
int len = -1;
while ((len = is.read(flush)) != -1) {
os.write(flush,0,len);
}
os.flush();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
文件字符流
文件字节流可以处理所有的文件,但是字节流不能很好的处理Unicode字符,经常会出现“乱码”现象。所以,我们处理文本文件,一般可以使用文件字符流,它以字符为单位进行操作。
文件字符输入流
Reader/FileReader
import java.io.*;
public class ReaderZh {
public static void main(String[] args) {
File src = new File("abc.txt");
Reader reader = null;
try (){
reader = new FileReader(src);
char[] flush = new char[1024];
int len = -1;
while((len = reader.read(flush)) != -1) {
System.out.println(new String(flush,0,len));
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (reader != null) {
reader.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
文件字符输出流
Writer/FileWriter
import java.io.*
public class WriterZh {
public static void main(String[] args) {
File dest = new File("dest.txt");
Writer writer = null;
try {
writer = new FileWriter(dest);
// 写法一
//String msg = "I am anglue\t嘀哒哒";
//char[] datas = msg.toCharArray();
// 字符串到字符数组(编码)
//writer.write(datas,0,datas.length);
//writer.flush();
// 写法二
//String msg = "I am anglue\t嘀哒哒";
//writer.write(msg,0,msg.length());
//weiter.write("~~~~~~~~~");
//writer.flush();
// 写法三
writer.append("I am anglue\\t").append("嘀哒哒~~~~~~~~~~~~");
writer.flush();
}catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (writer!=null) {
writer.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
文件字符拷贝流
利用文件字符流实现文件的拷贝
import java.io.*;
/**
* @auther 张辉
* @Description 文件字符流复制的类
*/
public class CopyUtilsChar {
private File src;
private File dest;
private int size = 1024;
public CopyUtilsChar(String src, String dest) {
this.src = new File(src);
this.dest = new File(dest);
Math s;
}
public CopyUtilsChar(String src, String dest, int size) {
this.src = new File(src);
this.dest = new File(dest);
this.size = size;
}
public CopyUtilsChar(File src, File dest) {
this.src = src;
this.dest = dest;
}
public CopyUtilsChar(File src, File dest, int size) {
this.src = src;
this.dest = dest;
this.size = size;
}
private void copy() {
try (Reader reader = new FileReader(src);
Writer writer = new FileWriter(dest)) {
char[] flush = new char[size];
int len = -1;
while ((len = reader.read(flush)) != -1) {
writer.write(flush, 0, len);
}
writer.flush();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
字节数组流
ByteArrayInputStream/ByteArrayOutputStream经常用在需要流和数组之间转化的情况。用人话说:FileInputStream是把文件当作数据源。ByteArrayInputStream则是把内存中的“某个字节数组对象”当作数据源。这个数据源是存在内存中的,所以不能太大。这两个流是新增的方法,不要使用InputStream. 字符数组流不用关闭,(GC会自动处理,如果你提出了关闭,也只是一个建议。)
字节数组输入流
ByteArrayInputStream
import java.io.*;
public class ByteArrayInputStreamZh {
public static void main(String[] args) {
byte[] src = "I am groot".getBytes();
ByteArrayInputStream bais = null;
try {
bai = new ByteArrayInputStream(src);
byte[] flush = new byte[16];
int len = -1;
while ((len = bais.read(flush)) != -1) {
System.out.println(new String(flush, 0, len));
}
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (bai != null) {
bais.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
字节数组输出流
ByteArrayOutputStream
import java.io.*;
public class ByteArrayOutputStreamZh {
public static void main(String[] args) {
// 这是输出
byte[] dest = null;
// 选择流
ByteArrayOutputStream baos = null;
try {
baos = new ByteArrayOutputStream();
String msg = "I am groot";
// 数据源
byte[] datas = msg.getBytes();
baos.write(datas,0,datas.length);
baos.flush();
dest = baos.toByteArray();
System.out.println(new String(dest,0,baos.size()));
} catch (FileNotFoundException e) {
e.printStackTrace();
} cathc (Exception e) {
e.printStackTrace();
} finally {
try {
if (baos != null) {
baos.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
字节数组拷贝文件
import java.io.*;
public class IOTest09 {
public static void main(String[] args) {
byte[] datas = fileToByteArray("01.png");
System.out.println(datas.length);
byteArrayToFile(datas,"02.png");
}
/**
* 1. 图片读取到字节数组
* 1.1 图片到程序 FileInputStream
* 1.2 程序到字节数组 ByteArrayOutputStream
* @param filePath
* @return byte[]
*/
public static byte[] fileToByteArray(String filePath){
// 1. 创建源与目的地
File src = new File(filePath);
byte[] dest = null;
// 2. 选择流
InputStream is = null;
ByteArrayOutputStream baos = null;
try {
is = new FileInputStream(src);
baos = new ByteArrayOutputStream();
// 3. 操作(读取)
byte[] flush = new byte[1024*10];
// 缓冲容器
int len = -1;
// 接收长度
while ((len = is.read(flush)) != -1) {
baos.write(flush, 0, len);
// 写出到字节数组中
}
baos.flush();
// 刷新,放置驻留
return baos.toByteArray();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
// 4. 释放资源
try {
if (baos != null) {
baos.close();
}
} catch (IOException e) {
e.printStackTrace();
}
try {
if (is != null) {
is.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
return null;
}
/**
* 2. 字节数组写出到文件
* 2.1 字节数组写出到程序 ByteArrayInputStream
* 2.2 程序写出到文件 FileOutputStream
* @param src
* @param filePath
*/
public static void byteArrayToFile(byte[] src,String filePath){
// 1. 输出源
File dest = new File(filePath);
// 2. 选择流
InputStream is = null;
OutputStream os = null;
try {
is = new ByteArrayInputStream(src);
os = new FileOutputStream(dest);
// 3. 操作(读取)
byte[] flush = new byte[5];
// 缓冲容器
int len = -1;
// 接收长度
while ((len = is.read(flush)) != -1) {
os.write(flush,0,len);
os.flush();
}
} catch (IOException e) {
e.printStackTrace();
} finally {
// 4. 释放资源
try {
if (os!=null) {
os.close();
}
} catch (IOException e) {
e.printStackTrace();
}
try {
if (is != null) {
is.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
缓冲字节流
BufferedInputStream/BufferedOutputStream,缓冲流用人话来说:就是在字节流/字符流的外边套一个缓冲区,不必每个都输出, 因此缓冲流是一种处理流(包装流)。- 在关闭流时,应该先关闭最外层的包装流,即“后开的先关闭”
- 缓存区的大小默认是8192字节(8K),也可以使用其它的构造方法自己指定大小。
- 主要是缓冲流可以提高IO操作时的性能。
import java.io.*;
public class Buffered{
public void copy(String strPath, String destPath) {
// 1. 创建流
File src = new File(strPath);
// 源头
File dest = new File(destPath);
// 目的地
// 2. 选择流
try (InputStream is = new BufferedInputStream((new FileInputStream(src)));
OutputStream os = new BufferedOutputStream(new FileOutputStream(dest))) {
// 3. 操作
byte[] flush = new byte[1024];
// 缓冲容器
int len = -1;
// 接受长度:当输入流到了末尾是,会返回-1
while ((len = is.read(flush)) != -1) {
// 上边分段读取
// 下边分段写入
os.write(flush, 0, len);
}
os.flush();
// 刷新,放置驻留
} catch (IOException e) {
e.printStackTrace();
}
}
}
缓冲字符流
BufferedReader/BufferedWriter- BufferedReader/BufferedWriter增加了缓存机制,大大提高了读写文本文件的效率,
- 同时,提供了更方便的按行读取的方法:readLine(); 处理文本时,我们一般可以使用缓冲字符流。
- readLine()方法是BufferedReader特有的方法,可以对文本文件进行更加方便的读取操作。
写入一行后要记得使用newLine()方法换行。
import java.io.*;
/**
* @author 张辉
* @Description 纯文本拷贝
* @create 2020-04-26 20:29
*/
public class CopyTxt {
public static void main(String[] args) {
copyTxt("abc.txt","dest.txt");
}
public static void copyTxt(String strPath,String destPath){
// 1. 创建流
File src = new File(strPath);
//源头
File dest = new File(destPath);
// 目的地
// 2. 选择流
try (BufferedReader br = new BufferedReader((new FileReader(src)));
BufferedWriter bw = new BufferedWriter(new FileWriter(dest))) {
String line = null;
// 接受长度:当输入流到了末尾是,会返回-1
while ((line = br.readLine())!=null) {
bw.write(line);
// 逐行写出
bw.newLine();
}
bw.flush();
// 刷新,放置驻留
} catch (IOException e) {
e.printStackTrace();
}
}
}
数据流
- 数据流将“基本数据类型与字符串类型”作为数据源,从而允许程序以与机器无关的方式从底层输入输出流中操作Java基本数据类型与字符串类型。
DataInputStream/DataOutputStream是处理流,可以对其他节点流或处理流进行包装,增加一些更灵活、更高效的功能。DataInputStream/DataOutputStream提供了可以存取与机器无关的所有Java基础类型数据(如:int、double、String等)的方法。- 数据流的写入和读出顺序必须相同
import jva.io.*;
public class DataZh{
public static void main(String[] args) throws IOException {
// 写出
ByteArrayOutputStream baos = new ByteArrayOutputStream();
// 字节数组流不用关闭。(GC会自动处理,如果你提出了关闭的指令,也只是提出一个建议而已)
DataOutputStream dos = new DataOutputStream(new BufferedOutputStream(boas));
dos.writerUTF("这是String串!");
dos.writerInt(18);
dos.writerBoolean(true);
dos.writerChar('a');
dos.flush();
// 只要是OutputStream/Writer都必须flush(),防止数据驻留
byte[] datas = baos.toByteArray();
System.out.println(datas.length);
// 读取
DataInputStream dis = new DataInputStream(new BufferedInputStream(new ByteArrayInputStream(datas)));
String msg = dis.readUTF();
int age = dis.readInt();
boolean flag = dis.readBoolean();
char ch = dis.readChar();
// 在这儿关闭流,先打开的后关闭
}
}
对象流
- 对象流在处理的时候,如果是自己写的类必须有
Serializable,又序列化标志的才能处理。 - 对象流就是对对象进行读写操作的,
ObjectInputStream/ObjectOutputStream。 ObjectInputStream/ObjectOutputStream是以“对象”未数据源,但是必须将传输的对象进行序列化与反序列化操作。- 并不是所有对象都可以序列化;要序列化必须
implements java.io.Serializable
import java.io.*;
import java.util.Date;
public class ObjectZh{
public static void main(String[] args) throws IOException,ClassNotFoundException{
// 写出(序列化:serialization)
ByteArrayOutputStream baos = new ByteArrayOutputStream();
// 字节数组流可以不用关闭。(GC会自动处理,如果你提出了关闭的要求,也只是一个建议,建议总是好的)
ObjectOutputStream oos = new ObjectOutputStream(new BufferedOutputStream(baos));
oos.writerUTF("这是一个字符串!");
oos.writerInt(18);
oos.writerBoolean(false);
oos.writerChar('a');
// 对象
oos.writerObject("这是一个对象,也是一个串,串也是对象!");
oos.writerObject(new Date());
Employee emp = new Employee("zhangsan",40000);
oos.writerObject(emp);
oos.flush;
byte[] datas = new baos.toByteArray();
System.out.println(datas.length);
// 读取(反序列化:deserialization)
ObjectInputStream ois = new ObjectInputStream(new BufferedInputStream(new ByteArrayInputStream(datas)));
// 写出与读取的顺序必须一致
String msg = ois.readUTF();
int age = ois.readInt();
boolean flag = ois.readBoolean();
char ch = ois.readChar();
Object str = ois.readObject();
Object date = ois.readObject();
Object employee = ois.readObject();
if (str instanceof String) {
String strObj = (String)str;
System.out.println(strObj);
}
if (date instanceof Date) {
Date dateObj = (Date)str;
System.out.println(dateObj);
}
if (employee instanceof Employee) {
String empObj = (Employee)employee;
System.out.println(empObj.getName() + "-->" + empObj.getSalary());
}
}
}
class Employee implements java.io.Serializable{
private transient String name;
// 加了transient的数据,则该数据不需要序列化
private double salary;
public Employee(){
}
public Employee(String name, double salary) {
this.name = name;
this.salary = salary;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public double getSalary() {
return salary;
}
public void setSalary(double salary) {
this.salary = salary;
}
}
序列化(Serializable)
- 序列化就是将对象转换为字节序列的过程。
- 序列化:把Java对象转换为字节序列的过程;
- 反序列化:把字节序列恢复为Java对象的过程。
- 对象序列化的作用:
- 持久化:把对象的字节序列永久地保存到硬盘上,通常存放在一个文件中,比如:休眠地实现;以后服务器session管理,hibernate将对象持久化实现。
- 网络通信:在网络上传送对象的字节序列。比如:服务器之间的数据通信、对象传递。
序列化涉及的类和接口
- ObjectOutputStream代表对象输出流,它的writeObject(Object obj) 方法可对参数指定的obj对象进行序列化,把得到的字节序列写到一个目标流中。
- ObjectInputStream代表对象输入流,他的readObject()方法从一个源输入流中读取字节序列,再把它们反序列化为一个对象,并将其返回。
- 只有实现了Serializable接口的类的对象才能被序列化。Serializable接口是一个空接口,只起到标记的作用。
转换流
InputStreamReader/OutputStreamWriter用来将字节流转化成字符流。- 如:
System.in/System.out都是字节流对象,但是在我们的实际使用中就需要转换成字符流,所以我们就可以使用InputStreamReader/OutputStreamWriter来将字节流转化为字符流。
import java.io.*;
public class Covert{
public static void main(String[] args) {
try (BufferedReader reader = new BufferedReader(new InputStreamReader(System.in));
BufferedWriter writer = new BufferedWriter(new OutputStreamWriter(System.out));) {
String msg = "";
while (!msg.equals("exit")) {
msg = reader.readLine();
writer.write(msg);
writer.newLine();
writer.flush();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
- 也可以操作网络流来下载网络字节流,并且保存成字符。
public static void main(String[] args) {
// 操作网络流 下载百度的源代码
try (BufferedReader reader =
new BufferedReader(
new InputStreamReader(
new URL("http://www.baidu.com").openStream(),"UTF-8"));
BufferedWriter writer =
new BufferedWriter(
new OutputStreamWriter(
new FileOutputStream("beidu.html"),"UTF-8"));) {
String msg = "";
while ((msg = reader.readLine()) != null) {
//System.out.println(msg);
writer.write(msg);
// 出现乱码,字符集不统一
writer.newLine();
}
writer.flush();
} catch (IOException e) {
e.printStackTrace();
}
}
装饰器
- 装饰器就是将一个功能更加强化。
- 它可以实现对原有类的包装和装饰,使新的类具有更强的功能。
- 在IO流中大量使用了装饰器模式,让流具有更强的功能、更强的灵活性。
- 用BufferedInputStream装饰了原有的FileInputStream,让普通的FileInputStream也具备了缓存功能,提高了效率。
- 装饰器就是将原来的方法每继承一次重写一次或者重新写一个新的方法(这个方法继承父类的某个方法),使得子类的功能更加niubi.
Apache
- Apache-commons工具包提供了IOUtils/FileUtils,可以让我们非常的对文件和目录进行操作。
IOUtils/FileUtils是我们上面IO文件和目录操作的封装。- Apache 软件基金会(Apache Software Foundation,简称ASF),官网地址:www.apache.org
- Apache由很多开源项目:commons,maven,hadoop。
- apache commons工具类简介
FileUtils类
cleanFirectory: 清空目录,但不删除目录。
contentEquals: 比较来给两个文件的内容是否相同
copyDirectory: 将一个目录内容拷贝到另一个目录。可以通过FileFilter过滤需要拷贝的文件.
copyFile:将一个文件拷贝到一个新的地址。
copyFileToDirectory:将一个文件拷贝到某个目录下。
copyInputStreamToFile:将一个输入流中的内容拷贝到某个文件。
deleteDirectory:删除目录。
deleteQuietly:删除文件。
listFiles:列出指定目录下的所有文件。
openInputSteam:打开指定文件的输入流。
readFileToString:将文件内容作为字符串返回。
readLines:将文件内容按行返回到一个字符串数组中。
sizeOf:返回文件或目录的大小。
write:将字符串内容直接写到文件中。
writeByteArrayToFile:将字节数组内容写到文件中。
writeLines:将容器中的元素的toString方法返回的内容依次写入文件中。
writeStringToFile:将字符串内容写到文件中。
public class CFileUtils {
public static void main(String[] args) throws IOException {
// 写出文件
FileUtils.write(new File("happy.txt"),"danfkdsnafs\r\n","UTF-8",true);
FileUtils.writeStringToFile(new File("happy.txt"),"danfkdsnafs","UTF-8",true);
FileUtils.writeByteArrayToFile(new File("happy.txt"),"danfkdsnafs学习".getBytes(),true);
// 写出文件
List<String> datas = new ArrayList<String>();
datas.add("码云");
datas.add("马化腾");
datas.add("弼马温");
FileUtils.writeLines(new File("happy.txt"),datas,"-_______",true);
// 拷贝URL内容
String URL = "https://img.zcool.cn/community/0128be58d20fc3a801219c77e6ff8e.jpg@1280w_1l_2o_100sh.jpg";
FileUtils.copyURLToFile(new URL(URL),new File("marvel.jpg"));
}
}
IOUtils类
buffer方法:将传入的流进行包装,变成缓冲流。并可以通过参数指定缓冲大小。
closeQueitly方法:关闭流。
contentEquals方法:比较两个流中的内容是否一致。
copy方法:将输入流中的内容拷贝到输出流中,并可以指定字符编码。
copyLarge方法:将输入流中的内容拷贝到输出流中,适合大于2G内容的拷贝。
lineIterator方法:返回可以迭代每一行内容的迭代器。
read方法:将输入流中的部分内容读入到字节数组中。
readFully方法:将输入流中的所有内容读入到字节数组中。
readLine方法:读入输入流内容中的一行。
toBufferedInputStream,toBufferedReader:将输入转为带缓存的输入流。
toByteArray,toCharArray:将输入流的内容转为字节数组、字符数组。
toString:将输入流或数组中的内容转化为字符串。
write方法:向流里面写入内容。
writeLine方法:向流里面写入一行内容。
public class CIOUtils {
public static void main(String[] args) throws IOException {
//读取URL内容到字符串(百度是UTF-8,163是GBK)
String datas = IOUtils.toString(new URL("https://www.163.com"),"GBK");
System.out.println(datas);
}
}
Java中构建jar包
File —> Project Structure —> Dependencies —> 添加相应的jar包然后Apply

若有收获,就点个赞吧
0 人点赞
