容器
泛型(Generics)
- 泛型是JDK1.5之后增加的,它可以给我们建立类型安全的集合。
- 在使用了泛型的集合中,遍历时不必进行强制类型转换。
- 泛型的本质就是“数据类型的参数化”。
- 我们可以把泛型理解为数据类型的一个占位符。
自定义泛型
- 声明:在类的声明处增加泛型列表,如:
泛型的使用
class MyCollection<E> {// E:表示泛型;Object[] objs = new Object[5];public E get(int index) {// E:表示泛型;return (E) objs[index];}public void set(E e, int index) {// E:表示泛型;objs[index] = e;}}public class TestGenerics {public static void main(String[] args) {// 这里的”String”就是实际传入的数据类型;MyCollection<String> mc = new MyCollection<String>();mc.set("aaa", 0);mc.set("bbb", 1);String str = mc.get(1); //加了泛型,直接返回String类型,不用强制转换;System.out.println(str);}}
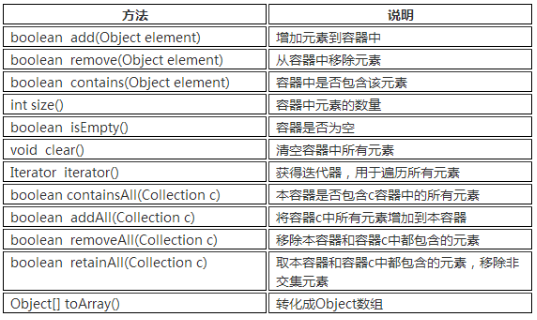
Collection接口
- Collection 表示一组对象,它是集中、收集的意思。
- Collection 接口的两个子接口是 List 、Set 接口。
- 由于List 、Set是Collection 的子接口,意味着所有的List、Set的实现类都有下面的方法。
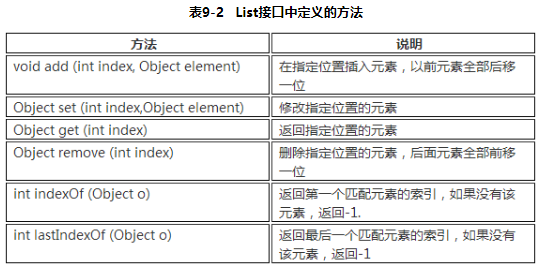
List
- List是
有序、可重复的容器 - 有序:List 中每个元素都有索引表记。可以根据元素的索引标记(在List中的位置)访问元素,从而精确控制这些元素。
- 可重复:List 允许加入重复的元素。List 通常允许满足 e1.equals(e2) 的元素重复加入容器。
- List 不仅继承了 Collection的所有方法,还有以下方法:
- List 有三个实现类: ArrayList,LinkedList和Vector
- ArrayList:底层使用数组实现的存储。特点:查询效率高,增删效率低,线程不安全。(虽然不安全,但是我们使用它。)
- 数组扩容是使用:
int newCapacity = oldCapacity + (oldCapacity >> 1)
- 数组扩容是使用:
- LinkedList:底层用双链表实现的存储。特点:查询效率低,删除效率高,线程不安全。
- Vector:底层使用的数组(实现过程都使用ArrayList的实现方法)实现了List,但是相关方法都加了同步检查,因此“线程安全,效率低”。
- 所有实现都增加了
synchronized
- 所有实现都增加了
如何选用 ArrayList,LinkedList,Vector
- 需要线程安全时,用Vector。
- 不存在线程安全问题时,并且查找较多用ArrayList(一般使用它)。
- 不存在线程安全问题时,增加或删除元素较多用LinkedList.
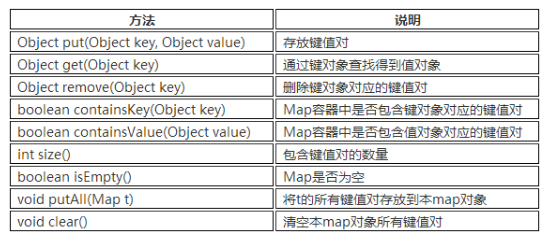
Map接口
- Map就是用来存储“键(key)-值(value)对”的。
- Map 类中存储的“键值对”通过键来标识,所以“键对象”不能重复。
- Map接口的实现类有 HashMap,TreeMap,HashTable,Properties等。
- Map接口中常用的方法
HashMap和HashTable
- HashMap 次啊用哈希算法实现,是Map接口最常用的实现类。
- HashMap 底层采用了哈希表存储数据,我们要求键不能重复,如果发生重复,新的键值对替换旧的键值对。
- HashMap继承了ArrayList和LinkedList的优点,在查找、删除、修改方面都有非常高的效率。
- HashTable类和HashMap用法几乎一样,底层实现几乎一样,只不过HashTablede的添加了
synchronized关键字确保线程同步检查,效率较低。 - HashMap:线程不安全,效率高。允许key或value为null.
- HashTable:线程安全,效率低。不允许key或value为null.
HashMap底层
- HashMap底层实现采用了哈希表,这是一种非常重要的数据结构。
- 数组:占用空间连续。寻址容易,查询速度快。但是,增加和删除效率非常低。
- 链表:占用空间不连续。寻址困难,拆线呢速度慢。但是,增加和删除效率非常高。
- HashMap结合了数组和链表的优点(数组+链表)。
resize利用扩展因子( loadFactor ),默认情况下扩展因子为0.75;每当hashmap中的元素个数超过当桶位元素的个数的0.75倍时,就会将数组大小扩大一倍。hashmap的大小是2的倍数。- hashmap结构:hash|key|value|next
- hashcode使用
value&length-1 - 在JDK8中,对应链表长度大于8时,链表就会转换为红黑树,这样大大提高了查找的效率。

若有收获,就点个赞吧
0 人点赞
