是什么
MNN模型压缩工具箱提供了包括低秩分解、剪枝、量化等模型压缩算法的实现,并且MNN进一步实现了其中一些需要软件特殊实现的算法(如稀疏计算和量化)的底层计算过程,因此,此工具箱需要配合MNN推理框架来使用。
具体来说,MNN压缩工具箱包含两个组成部分:
MNN框架自身提供的压缩工具(输入MNN模型,输出MNN模型)
和
mnncompress(基于主流训练框架TF/Pytorch的模型压缩工具)。
有什么能力
目前提供的能力如下表所示:
| 原始模型格式 | 提供的工具 | 支持的压缩算法类别 |
|---|---|---|
| MNN | 量化工具(python,c++) 模型转换工具(python,c++) |
离线量化 训练量化(不成熟) 权值量化(转换时直接完成) FP16(转换时直接完成) |
| TensorFlow 1.X | python压缩算法插件(mnncompress) | 低秩分解 线性过参数化 模型剪枝 离线量化 训练量化 训练权值量化 |
| Pytorch | python压缩算法插件(mnncompress) | 低秩分解 模型剪枝 离线量化 训练量化 训练权值量化 |
各类压缩算法的特点:
| 压缩算法类别 | 特点 | 支持的算法 |
|---|---|---|
| 低秩分解 | 将原始模型进行分解,降低模型计算量、存储量,分解之后的模型仍是一个规整的模型,不需要特殊的软件底层实现;需要进行finetune训练 | Tucker分解,SVD分解 |
| 线性过参数化 | 用于模型从0开始训练的过程中,设计一个小模型,然后使用此算法对模型进行过参数化扩展为一个大模型,提高模型的表达能力,然后基于此大模型进行训练,训练完成之后可以将大模型中的层合并得到原始小模型一样的结构,而且精度和大模型一致 | 改进的 linear over parameterization |
| 模型剪枝 | 将模型的权值矩阵进行稀疏,并进行finetune训练,利用稀疏编码(通道剪枝不需要)压缩模型大小,底层稀疏计算实现加速 | 11随机剪枝,14block剪枝,通道剪枝 |
| 离线量化 | 将float卷积转换为int8卷积计算,仅需少量校准图片,降低存储量到原始模型的四分之一,降低内存,加速计算(某些模型可能会比float模型慢,因为float的优化方法和int8不同) | EMA,KL,ADMM |
| 训练量化 | 将float卷积转换为int8卷积计算,需要进行训练,可提高量化模型精度,降低存储量到原始模型的四分之一,降低内存,加速计算(某些模型可能会比float模型慢,因为float的优化方法和int8不同) | LSQ,OAQ,WAQ |
| 直接权值量化 | 仅将模型中的权值进行量化,计算时还原为float进行计算,因此仅减少模型存储量,计算速度和float相同,可以在模型转换时一键完成,8bit量化情况下,精度基本不变,模型大小减小到原来的1/4 | 对称量化,非对称量化 |
| 训练权值量化 | 特点同直接权值量化,但通过mnncompress压缩算法插件实现,因而可以提供更低比特的权值量化,以减少更多的存储量,并提高权值量化之后模型的精度,例如4bit量化情况下,模型大小减小到原来的1/8 | 对称量化 |
| FP16 | 将FP32计算转换为FP16计算,可在模型转换时一键完成,模型大小减小为原来的1/2,精度基本无损,并提高计算速度(需要硬件支持FP16计算) | - |
怎么用
- 如果只想使用离线压缩方法,可以将模型转换为MNN模型之后使用对应的工具进行压缩。这类压缩算法不需要进行训练finetune,所以通常运行得很快。
2. 如果离线压缩方法的精度不满足要求,且能够进行训练finetune的话,可以使用mnncompress中提供的压缩算法插件将原始模型进行压缩,得到压缩之后的模型和压缩信息描述文件,然后将这两个文件输入到MNN模型转换工具得到最终的MNN压缩模型。需要训练的压缩算法可以提供更好的精度,但需要一定的时间进行finetune训练,此finetune训练需要的时间一般比模型从0开始训练要少很多。
3. 这些算法中有些是可以叠加使用的,以取得更好的压缩效果。推荐使用pipeline(其中方框中的算法均为可选,叠加压缩算法若精度不好,可选择使用):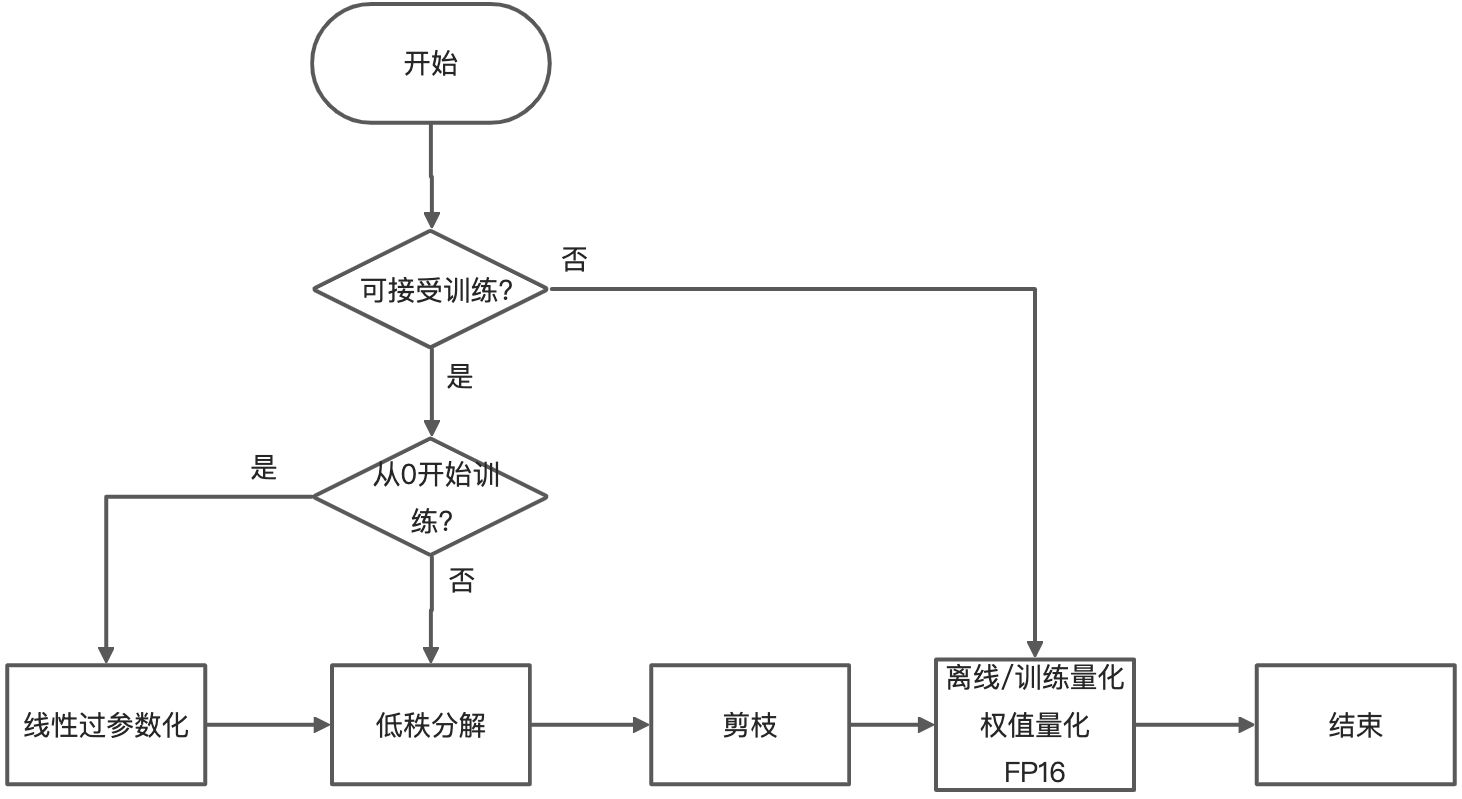

若有收获,就点个赞吧
0 人点赞
