文本信息处理中,传统的方法以单词向量表示文本的语义内容,以单词向量空间的度量表示文本之间的语义相似度。潜在语义分析旨在解决这种方法不能准确表示语义的问题,试图从大量的文本数据中发现潜在的话题,以话题向量表示文本的语义内容,以话题向量空间的度量更准确地表示文本之间的语义相似度。这也是话题分
析topic modeling 的基本想法。
统计学习方法第2版》PDF,484页,带书签,文字可复制;配套源代码;配套课件。
下载: https://pan.baidu.com/s/1Efr9T0fh62PFcmHoHubA2g
提取码: 3pbd
潜在语义分析latent semantic analysis是一种无监督学习方法,主要用于文本的话题分析,其特点是通过矩阵分解发现文本与单词之间的基于话题的语义关系。潜在语义分析由Deerwester 等于1990 年提出,最初应用于文本信息检索,所以也被称为潜在语义索引latent semantic indexing ,在推荐系统、图像处理、生物信息学等领域也有广泛应用。
统计学习方法即机器学习方法,是计算机及其应用领域的一门重要学科。《统计学习方法第2版》分为监督学 习和无监督学习两篇,全面系统地介绍了统计学习的主要方法。包括感知机、k 近邻法、朴素贝叶斯法、决策树、逻辑斯谛回归与最大熵模型、支持向量机、提升方法、EM 算法、隐马尔可夫模型和条件随机场,以及聚类方法、奇异值分解、主成分分析、潜在语义分析、概率潜在语义分析、马尔可夫链蒙特卡罗法、潜在狄利克雷分配和 PageRank 算法等。除有关统计学习、监督学习和无监督学习的概论和总结的四章外,每章介绍一种方法。叙述力求从具体问题或实例入手, 由浅入深,阐明思路,给出必要的数学推导,便于掌握统计学习方法的实质,学会运用。 介绍了一些相关研究,给出了少量习题, 适用于从事文本数据挖掘、信息检索及自然语言处理等专业的研发人员参考。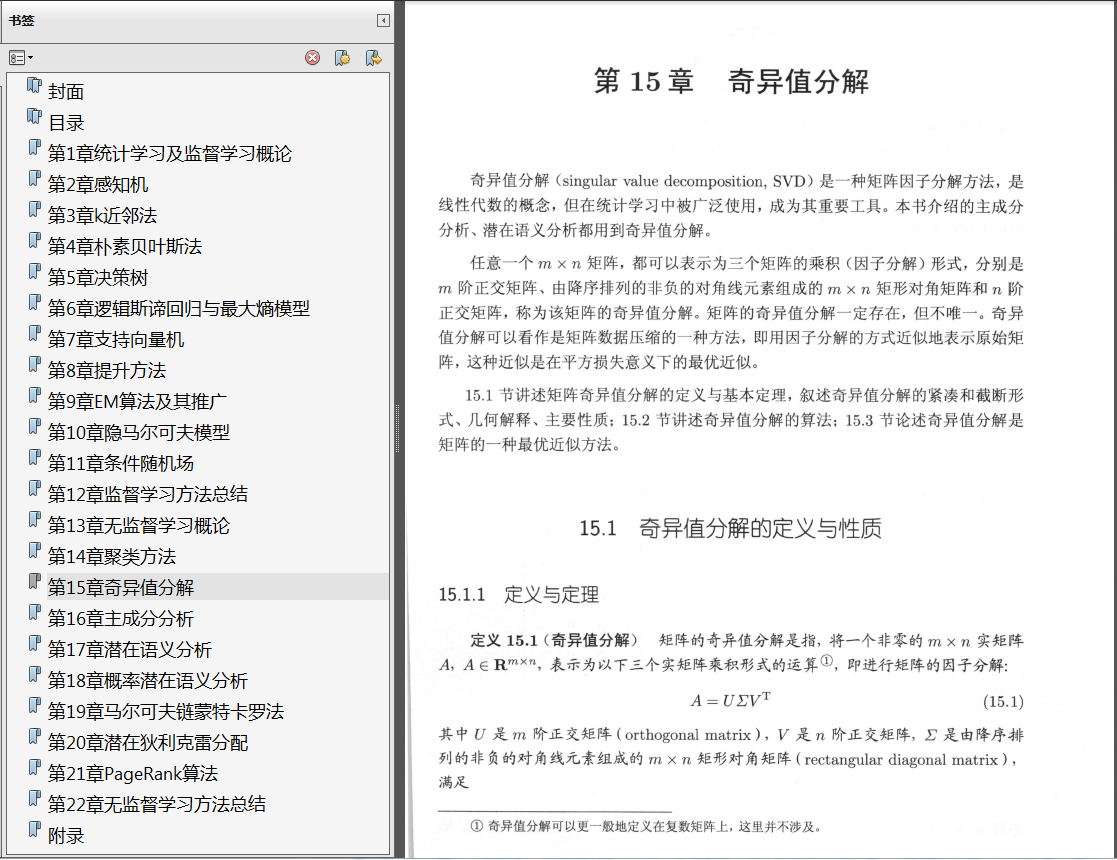
建议统计学习方法路线,ng课程入门,知道有哪些算法,大致怎么做,然后去kaggle打个入门赛,别做特征工程,把会的算法全用上。然后放下比赛,开始读《统计学习方法第2版》,同时看机器学习基石或其他比较数学化的进阶课程,这一步不需要你敲代码,你要会的是滚瓜烂熟的推导,做到这一步,再去kaggle参加奖金赛,阅读kernel,学习state of the art 模型,学习特征工程,再在学习过程中阅读最新的论文或者经典的论文,不断迭代这个过程,别淹死在什么机器学习实战上,有现成的轮子不用,非得费那个劲,除非你科班毕业,代码能力扎实,不然你能不能从头实现一遍决策树对你找不找到工作没有任何一毛钱关系。笔试不会考你如何实现hmm,只会考数据结构与算法,面试只会让你推导。
我虽然很喜欢模式识别和机器学习,但我暂时并不希望在这上面做深入的研究,只想把别人研究好的成熟的理论用在计算机视觉任务上。比如SVM,Adaboost,EM,朴素贝叶斯,K近邻,决策树等等。能够知道每种算法的原理,而并不想深究其实现过程以及理论证明。比如SVM,我想知道的是这种算法如何实现分类,有哪几种类型,每种适合什么样的分类任务,对应的参数的意义是什

若有收获,就点个赞吧
0 人点赞
