自然语言处理是一门交叉学科,属于人工智能的一个分支,涉及计算机科学、语言学、数学等多个领域的专业知识。外行人很难入门这个小众的圈子。经典教材虽然高屋建瓴,但自学的话
很难读懂,缺乏代码也无法落地;工程类书籍则往往侧重对开源项目的接口介绍,缺乏深度与宏观系统性。曾经跟天书般的术语与公式顽强斗争,也在迷宫般的教学代码中苦苦挣扎。现在
回顾自学历程,当时缺少一本面向普通人的入门书,走了许多弯路。
《自然语言处理入门》PDF+何晗+源代码
《自然语言处理入门》PDF,有书签,390页,文字可复制,作者:何晗,配套源代码。
下载: https://pan.baidu.com/s/1jokSnx7bfagOMQxF5H0-3g
提取码: uk5w
下载: https://pan.baidu.com/s/1cfJlubIrm-SGViDD94-Q9A
提取码: pprp
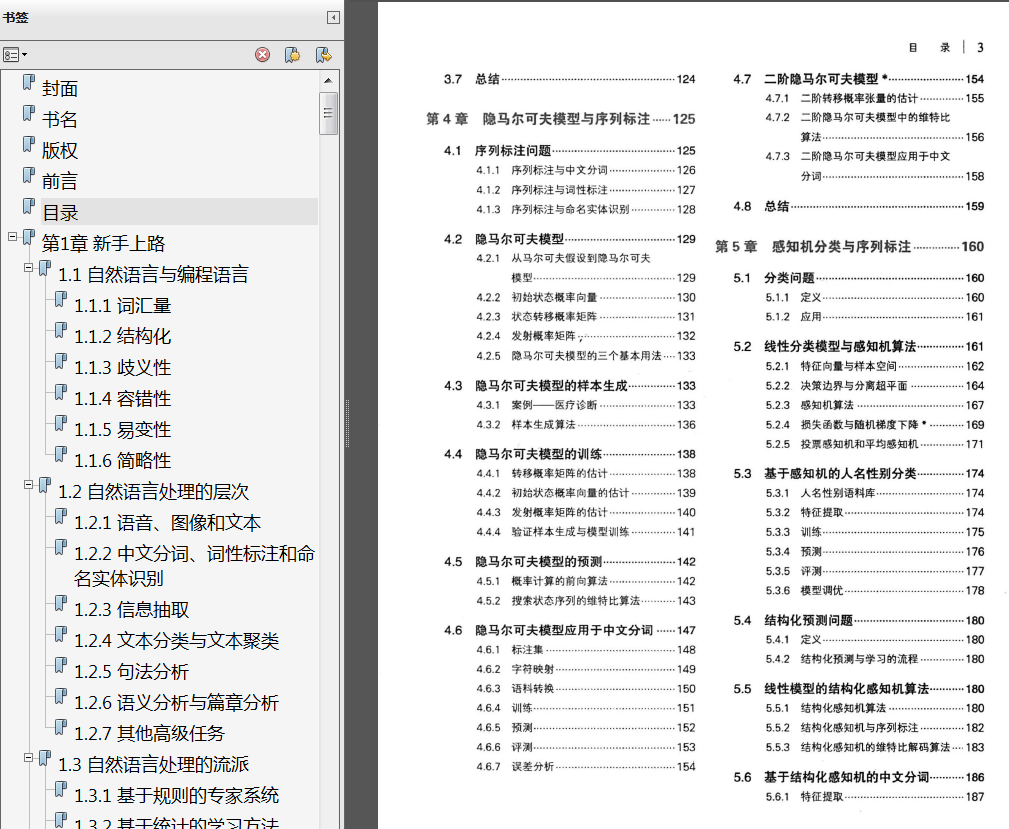
介绍一些字符串算法,让普通程序员从算法的角度思考中文信息处理。由易到难地讲解一些常用的机器学习模型,让算法工程师晋级为机器学习工程师。这部分并非空谈理论,而是由中文
分词这一应用问题贯穿始终,构成一种探索式的递进学习。这些模型也并非局限于中文分词,会在第三部分应用到更多的自然语言处理问题上去。新增了许多与文本处理紧密相关的算法,
让机器学习工程师进化到自然语言处理工程师。特别地,最后一章介绍了当前流行的深度学习方法,起到扩展视野、承上启下的作用。
在开源自然语言处理项目 HanLP 流行起来后,接触了大量 NLP 初学者,看到不少人碰到了当初苦苦思索的问题。许多用户不理解“统计自然语言处理”的设计理念,对 “语料”“训练”“模型”等
概念十分陌生。同时,如果你缺乏自然语言处理基础的话,也无法掌握 HanLP 中的高级功能。还有部分学习热情高涨的用户尝试阅读 HanLP 的代码,却反应即便代码有注释,也看不懂为什
么要这么写……用户的问题和困惑越积越多,有些朋友建议写一本 HanLP 的书。然而认为一本书不应当局限于代码,而应当让读者知其所以然,而彼时觉得自己才疏学浅,写不出满意之作
。后来经过几年的完善,HanLP 成为 GitHub 上最受欢迎的自然语言处理项目,对自然语言处理的理解也系统化了一些。正巧图灵的王军花老师跟我约稿,想是时候将这些年的收获总结一
下了。
避免大而全式地泛泛而谈,又不拘泥于工程实践,这是我写作这本书秉持的原则。我希望这本务实的入门书,能够帮助零起点的你上手这门新学科,并且真正将自然语言处理应用在生产环
境中。书中不是枯燥无味的公式罗列,而是用白话阐述的通俗易懂的算法模型;书中不是对他人开源代码的堆砌,而是工业级开发经验的分享。

若有收获,就点个赞吧
0 人点赞
