Kubernetes是容器集群管理系统,是一个开源的平台,可以实现容器集群的自动化部署、自动扩缩容、维护等功能。
官方文档:https://kubernetes.io/docs/home/
中文文档:http://docs.kubernetes.org.cn/
工作原理详解
原理图
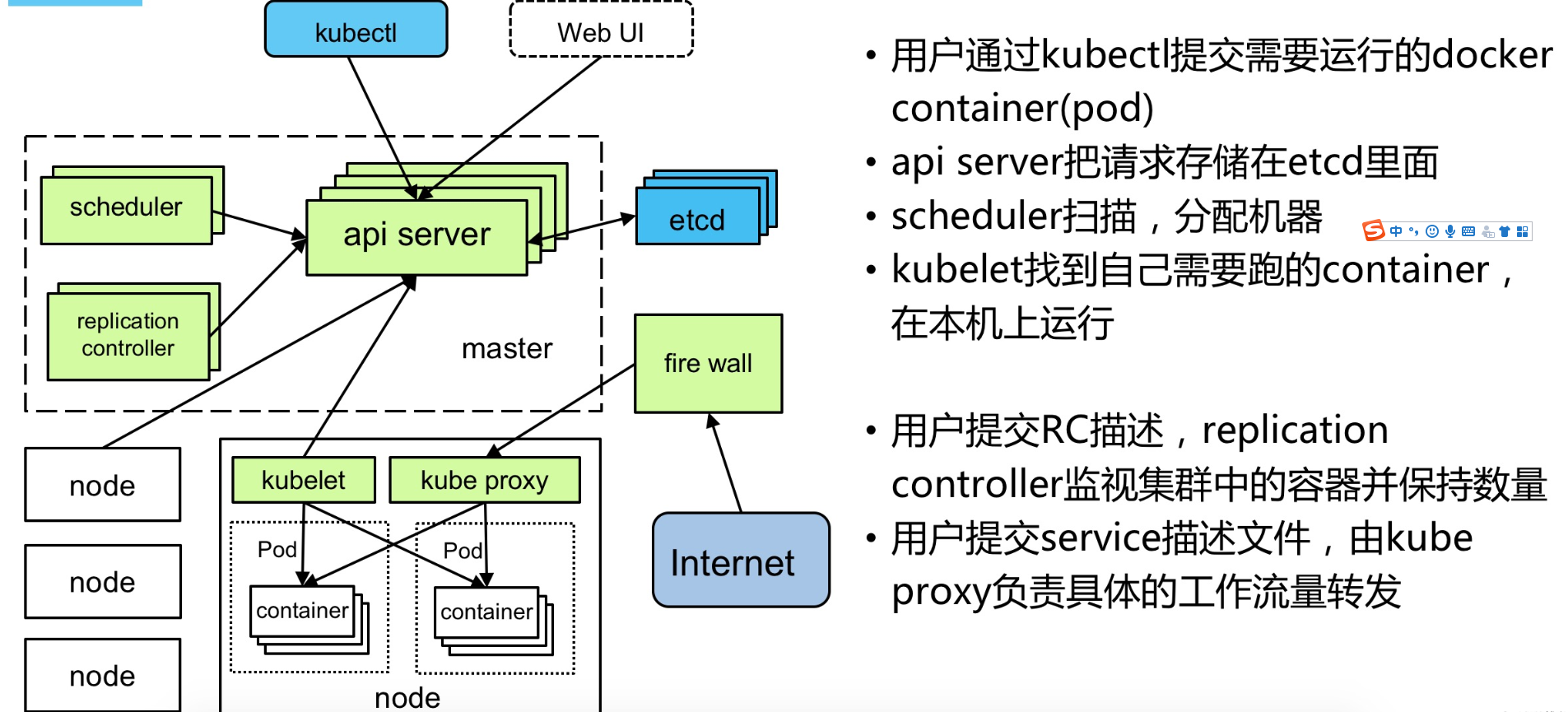
工作原理描述:
1、用户通过kubectl或者API server的REST API接口,提交需要运行的docker容器(创建pod请求);
2、api server将创建pod的相关请求数据存储到etcd(存储中心)中;
3、scheduler监听API server,查询还未分配的Node的Pod,然后根据调度策略为这些Pod分配节点;
4、kube-let则负责在所在的Node节点上接收主节点发来的指令,管理Pod以及Pod中的容器,并定时向master主节点汇报节点资源的使用情况以及容器的情况;
5、controller-manager 则通过api-service监控整个集群的状态,并确保集群处于预期的工作状态
基础概念:
将Docker应用于具体的业务实现,是存在困难的——编排、管理和调度等各个方面,都不容易。于是,人们迫切需要一套管理系统,对Docker及容器进行更高级更灵活的管理。 K8S,就是基于容器的集群管理平台,它的全称,是kubernetes。 一个K8S系统,通常称为一个K8S集群(Cluster)。 这个集群主要包括两个部分: 一个Master节点(主节点) 一群Node节点(计算节点) Master节点主要还是负责管理和控制。Node节点是工作负载节点,里面是具体的容器。 Master节点包括API Server、Scheduler、Controller manager、etcd。 API Server是整个系统的对外接口,供客户端和其它组件调用,相当于“营业厅”。 Scheduler负责对集群内部的资源进行调度,相当于“调度室”。 Controller manager负责管理控制器,相当于“大总管”。
Node节点包括Docker、kubelet、kube-proxy、Fluentd、kube-dns(可选),还有就是Pod。 Pod是Kubernetes最基本的操作单元。一个Pod代表着集群中运行的一个进程,它内部封装了一个或多个紧密相关的容器。 除了Pod之外,K8S还有一个Service的概念,一个Service可以看作一组提供相同服务的Pod的对外访问接口。Kubelet,主要负责监视指派到它所在Node上的Pod,包括创建、修改、监控、删除等。 Kube-proxy,主要负责为Pod对象提供代理。 Fluentd,主要负责日志收集、存储与查询。
1.ETCD[主节点安装] etcd服务是数据中心。用于持久化存储信息。要求高可用和数据一致性。即多部署几个master节点 存储哪些信息:k8s有本身的节点信息、组件信息、运行的pod、service都需要做持久化 2.kube-api-server[主节点安装] api-server提供集群管理的API接口,包括认证授权、数据校验、集群状态变更、其他模块之间的数据交互和通信 其他模块,都是通过api-server查询操作数据,也就是说只有api-server才能直接操作etcd 3.controllerManager[主节点安装] controllerManager是kubernetes的大脑,它通过api-service监控整个集群的状态,并确保集群处于预期的工作状态 组成:controller-manager是由 kube-controller-manager 和 cloud-controller-manager组成 kube-controller-manager是由 一系列控制器组成,Replication Controller控制副本、Node Controller节点控制、Deployment Controller管理deployment等等 cloud-controller-manager是在k8s启用Cloud provider的时候,需要用来配合云服务提供商的控制 4.Scheduler[主节点安装] kube-scheduler负责实现调度策略,分配调度Pod到集群内的节点上,它监听api-server,查询还未分配的Node的Pod,然后根据调度策略为这些Pod分配节点 5.Calico[所有节点安装] Calico实现了CNI接口,是kubernetes网络方案的一种选择。 Calico在每一个计算节点利用Linux Kernel实现了一个高效的vRouter来负责数据转发, 而每个vRouter通过BGP协议负责把自己上运行的workload的路由信息像整个Calico网络内传播——小规模部署可以直接互联,大规模下可通过指定的BGP route reflector来完成。 这样保证最终所有的workload之间的数据流量都是通过IP路由的方式完成互联的。 5.flannel[所有节点安装] kubernetes网络方案的另一种选择 6.kube-ctl[任意节点安装] kubectl是Kubernetes的命令行工具,是Kubernetes用户和管理员必备的管理工具。 kubectl提供了大量的子命令,方便管理Kubernetes集群中的各种功能。 7.kube-let[工作节点安装] kube-let就是会在每个工作节点上都运行一个kubelet服务进程,默认监听10250端口。 kube-let负责接收并执行master发来的指令,管理Pod以及Pod中的容器。 每个kubelet进程会在API Server上注册节点自身信息,定期向master节点汇报节点的资源使用情况,并通过cAdvisor监控节点和容器的资源。 8.kube-proxy[工作节点安装][对外] kube-proxy保证集群内的服务,可以被集群外访问到。 每台工作节点上都应该运行一个kube-proxy服务,它监听API server中service和endpoint的变化情况,并通过iptables等来为服务配置负载均衡,是让我们的服务在集群外可以被访问到的重要方式。 9.kube-dns[独立服务][对内] kube-dns保证集群内的服务,可以被集群内的pod互相访问到。 kube-dns为Kubernetes集群提供命名服务,主要用来解析集群服务名和Pod的hostname。目的是让pod可以通过名字访问到集群内服务。它通过添加A记录的方式实现名字和service的解析。普通的service会解析到service-ip。headless service会解析到pod列表。
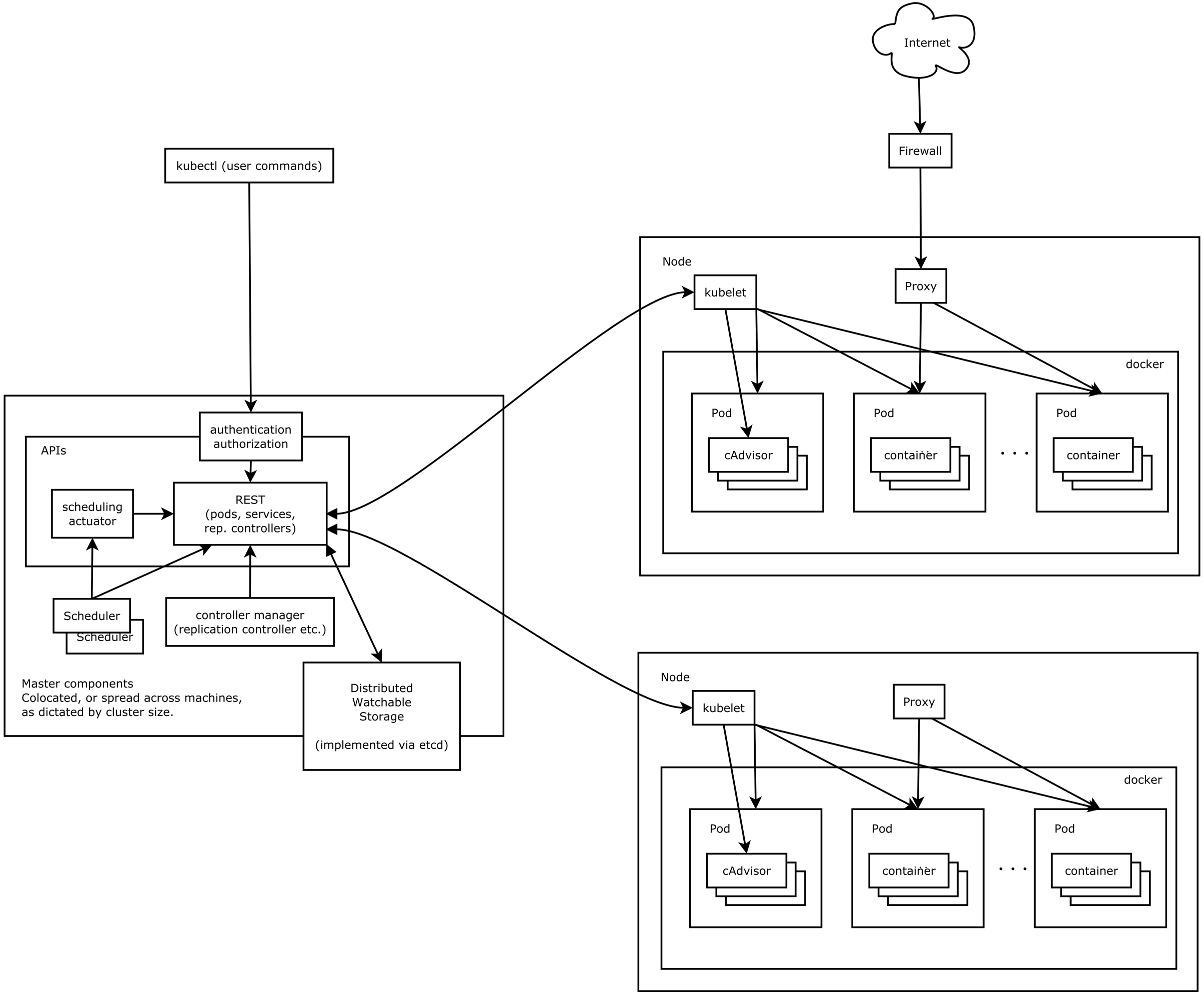
基础架构
Kubernetes 是一个跨主机集群的 开源的容器调度平台,它可以自动化应用容器的部署、扩展和操作 , 提供以容器为中心的基础架构。
使用 Kubernetes, 您可以快速高效地响应客户需求:
- 快速、可预测地部署您的应用程序
- 拥有即时扩展应用程序的能力
- 不影响现有业务的情况下,无缝地发布新功能
- 优化硬件资源,降低成本
我们的目标是构建一个软件和工具的生态系统,以减轻您在公共云或私有云运行应用程序的负担。
Kubernetes 具有如下特点:
- 便携性: 无论公有云、私有云、混合云还是多云架构都全面支持
- 可扩展: 它是模块化、可插拔、可挂载、可组合的,支持各种形式的扩展
- 自修复: 它可以自保持应用状态、可自重启、自复制、自缩放的,通过声明式语法提供了强大的自修复能力
集群有Master和Node节点,架构如下: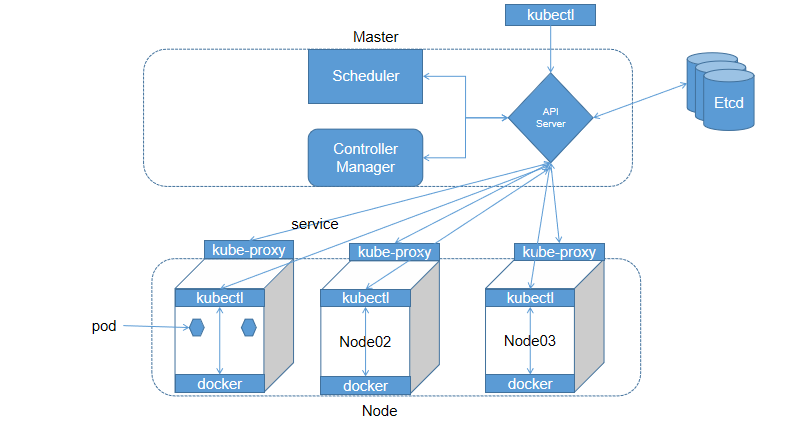
其中:
- etcd 保存了整个集群的状态,就是一个数据库,只有API Server能与其通信;
- apiserver 提供了资源操作的唯一入口,并提供认证、授权、访问控制、API 注册和发现等机制;
- controller manager 负责维护集群的状态,比如故障检测、自动扩展、滚动更新等;
- scheduler 负责资源的调度,按照预定的调度策略将 Pod 调度到相应的机器上;
- kubelet 负责维护容器的生命周期,同时也负责 Volume(CSI)和网络(CNI)的管理;
- Container runtime 负责镜像管理以及 Pod 和容器的真正运行(CRI);
- kube-proxy 负责为 Service 提供 cluster 内部的服务发现和负载均衡;
scheduler和controller-manager都是通过apiserver从etcd中获取各种资源的状态,进行相应的调度和控制操作。
除了上面的这些组件,还有一些第三方的组件:
- kube-dns 负责为整个集群提供 DNS 服务
- Ingress Controller 为服务提供外网入口
- Heapster 提供资源监控
- Dashboard 提供 GUI
组件之间的关系:
从上面图可以看到所有组件均是通过API Server进行通信,所以API Server就是一个中枢神经,在生产中我们会把master部署为多节点,做高可用。
etcd主要是存储集群里的信息,比如集群状态,集群的各Node信息等,只有API能与其通信,所以我们也会把etcd做高可用,etcd是一个单独的组件,一个应用软件,做高可用建议是奇数节点,比如3,5等,节点不应过多,因为节点过多,节点之间的数据同步是会有一定的开销,影响集群的性能。
Schduler负责整个集群的调度,它通过API Server来检测Node上Pod的状态,然后会根据定义的策略来调度pod并绑定Node。
Controller manager负责pod的控制,常见的比如定义了一个Pod为replicaSet,然后因为某些原因当前pod挂掉了,这时候Controller manager就会为你在Node上重启该Pod。
kubelet是Node上的组件,它会检测Node上的Pod,并将其状态更新到API Server。
kube-proxy主要是负责代理转发,主要控制service,并将sevice状态更新到API Server。
kubectl是集群的管理组件,主要也是调用API Server,然后进行整个集群的管理。
高可用
Kubernetes 集群,在生产环境,必须实现高可用:
- 实现Master节点及其核心组件的高可用;
- 如果Master节点出现问题的话,那整个集群就失去了控制;
具体的 HA 示意图: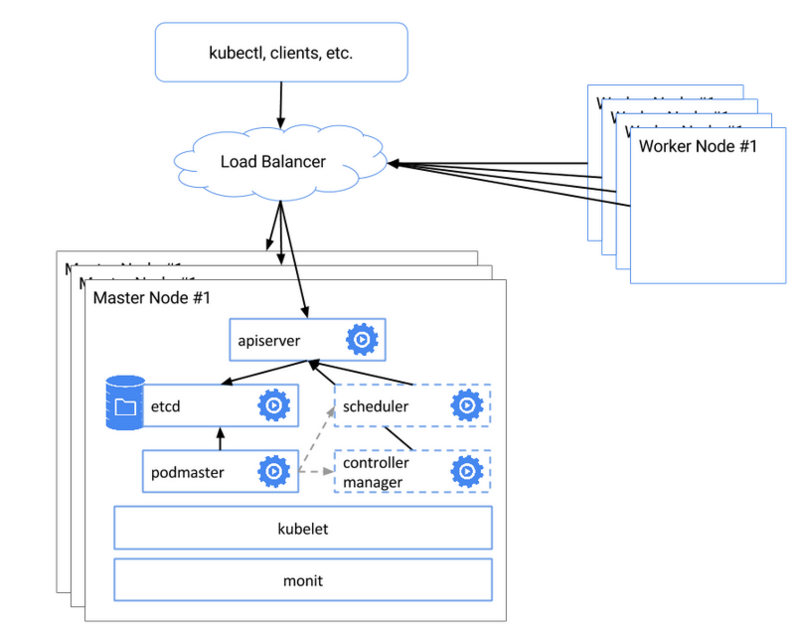
具体工作原理:

若有收获,就点个赞吧
0 人点赞
