简述
hadoop在设计之初,并不是为了在存在大量小文件的情况下高效运行。
在HDFS中,数据和元数据是独立的实体。文件被分割为数据块,存储在datanode上的本地文件系统中,并在集群中进行复制。hdfs命名空间文件树和相关的元数据存储在namenode的内存中(并备份到磁盘中)。一般情况下,每个字节占用150字节左右
上面的2个方案体现出了小文件的问题
方案1中,1个192M的大文件,被分割为128M和64M的数据块,按照每个数据块的元数据为150字节来计算。
这个文件所占用的内存大小为150bytes (1 个inode数量 + (block块的个数集群中块的备份数))
则方案1中192M大小文件占用的namenode内存大小为150(1+(23))=1050bytes
在方案2中共有192个1M大小的文件。则占用namenode内存大小为105(192+(1923))=115200bytes
我们看到,相对于一个192M的大文件,存储192个1M的小文件所占用namenode 堆中内存要比存储大文件占用内存多得多。
对存储层的影响
在namenode重启时,需要将磁盘中的元数据加载到内存中,如果存在大量小文件,就代表到namenode的元数据很大,加载就需要更多的时间,会导致重启速度很慢。并且namenode还需要追踪每个block的变化,大量的小文件会导致namenode在耗尽内存后,datanode中存储数据的空间还没使用完。datanode还需要通过网络向namenode汇报block块的变化,更多的block就代表着要通过网络汇报更多的元数据信息,更多的文件就意味着更多的信息去请求namenode,这可能会阻塞namenode。增加RPC队列和处理延迟。最严重的是可能会导致集群宕机
对应用层的影响
一般来说,对于impala 等ad-hoc的服务,或者mapreduce和spark。更多的小文件会导致磁盘更多的读写请求
小文件数如何产生的
1、流式数据处理(spark streaming flink等流式计算框架 )小的timewindow
2、过度分区表(指每个分区的数据量很小小于256M)
如何识别小文件
1、分析fsimage
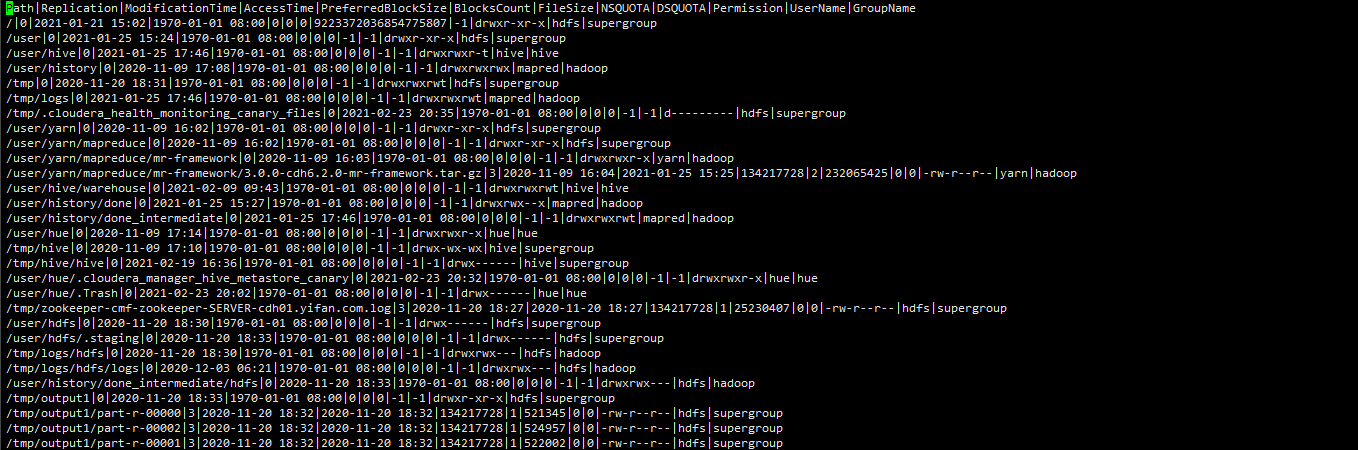
由于namenode中存储了所有与文件相关的元数据信息,他将整个命名空间保存在内存中,而fsimage是namenode在文件系统中的持久化记录。我们可以通过fsimage的元信息。以下为fsimag中可用的字段
path replication Modificationtime,AccessTime,preferredblocksize,blockscount,filesize,NSQUOTA,DSQUOTA,PERMISSION,username,groupname
我们可以复制namenode数据目录下的fsimage文件到其他目录,然后使用hdfs oiv 进行解析
hdfs oiv -p Delimited -delimiter "|" -t /tmp/tmpfsimage/ -i fsimage_0000000000002666356 -o fsimage.out

若有收获,就点个赞吧
0 人点赞
