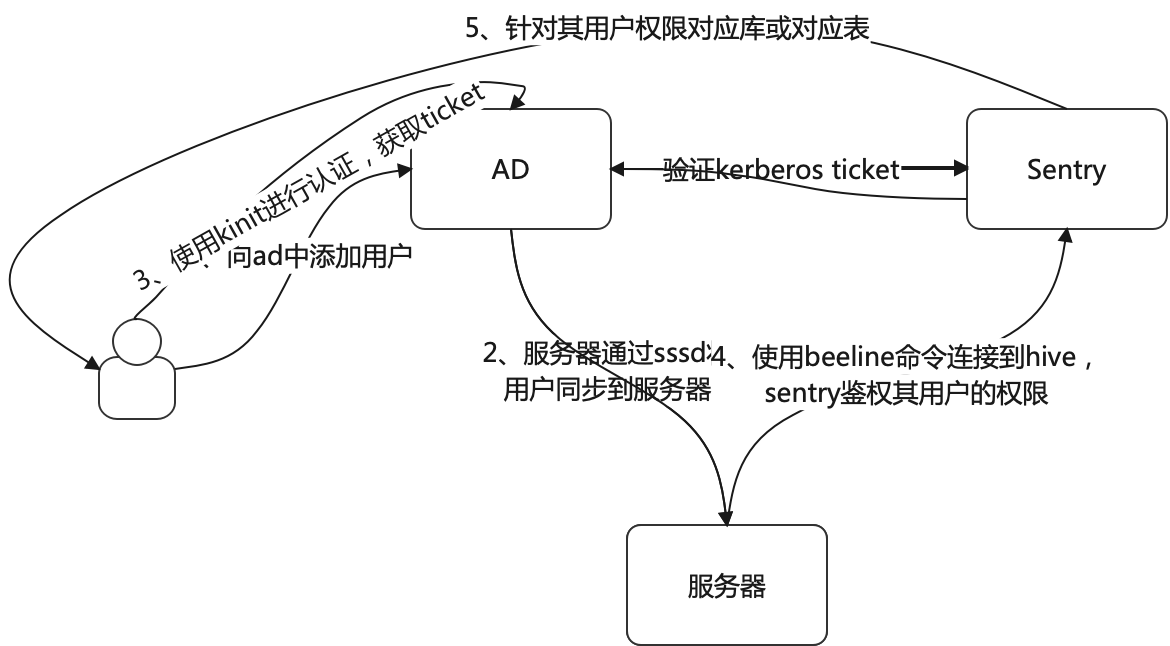
1、实现方案
用户管理:微软的Active Directory 等同于 ldap + kerberos。对应的免费实现是redhat的freeipa
权限管理:sentry
用户同步:sssd
可以使用hdfs groups来判断对应的用户
Active Directory
管理用户的域账号、用户信息、企业通信录(与电子邮箱系统集成)、用户组管理、用户身份认证、用户授权管理、按需实施组管理策略等。
sssd
架构
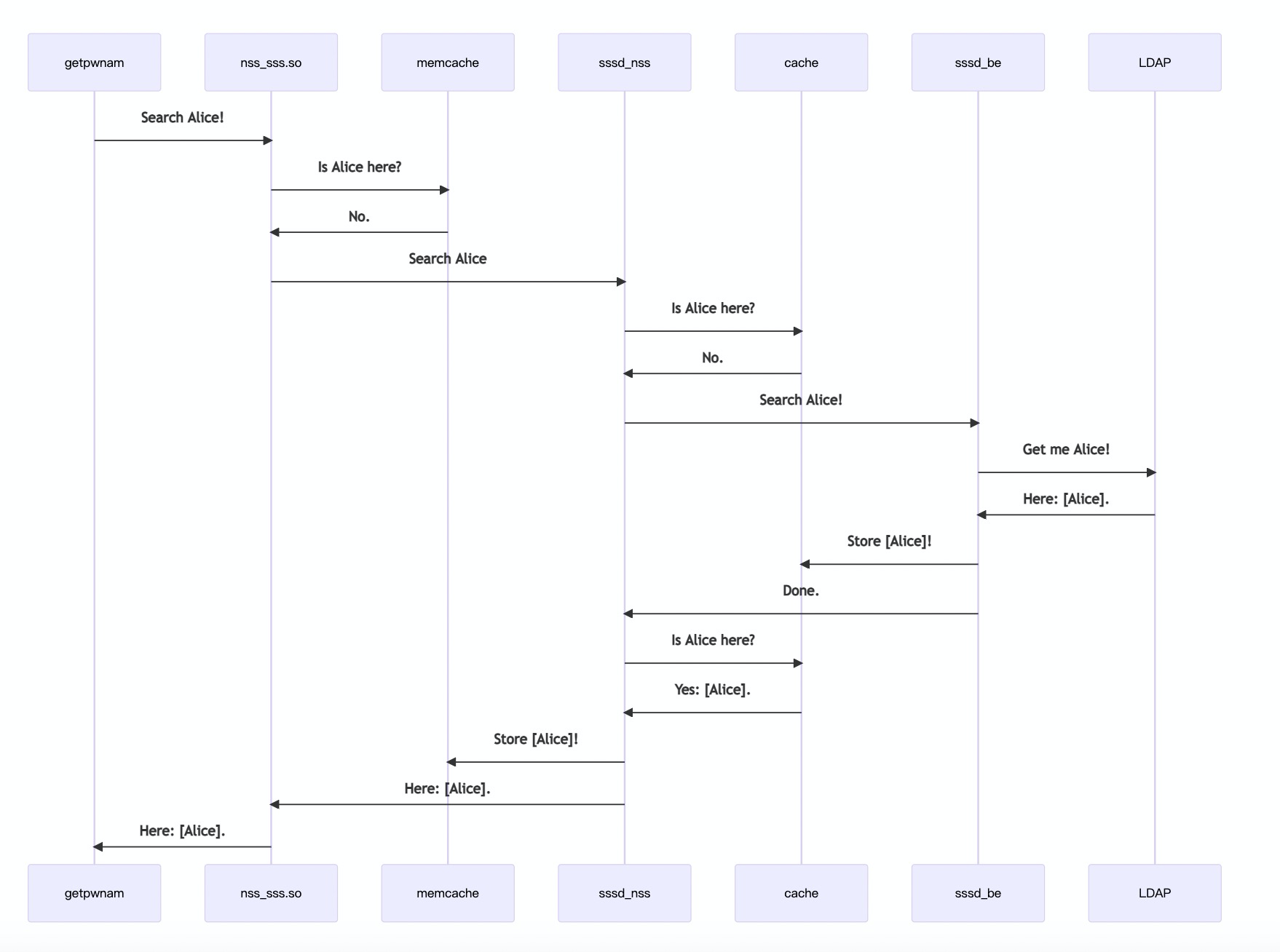
sssd的主要作用是将远程数据库中的数据存储在本地的缓存中,然后将这些数据提供给用户使用。是缓存数据保持为最新和有效比较难。要做到这一点,sssd由多个组件组成。这些组件通过各种进程间通信技术相互通信。下图为sssd的架构
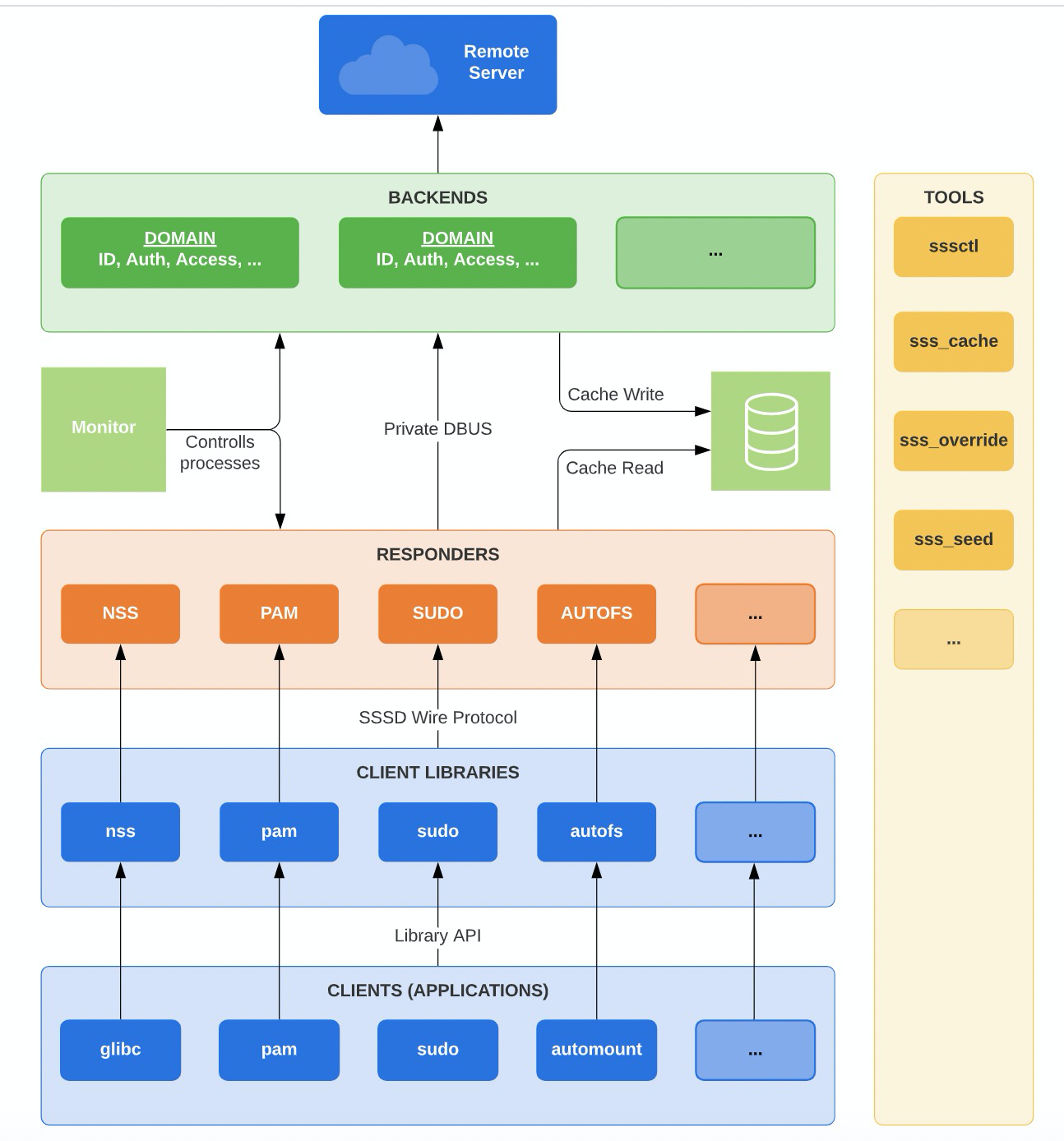
backends:用来保持缓存数据最新,他和远程的服务器进行通信,请求所需的数据存储在缓存中
responders: 充当目标应用程序和本地缓存的中间人,当应用程序请求数据时(如 id 用户),responder会查看缓存,如果缓存汇总数据有效,则返回他,如果说数据失效则要求后迁去查询数据库,然后返回结果
client libraries: 实现了目标应用程序使用的接口,是用来安排应用程序和responder之间的通信,用来检索缓存中的数据
client: 就比如使用的id ,getent,或者使用hadoop集群所需的权限
缓存查找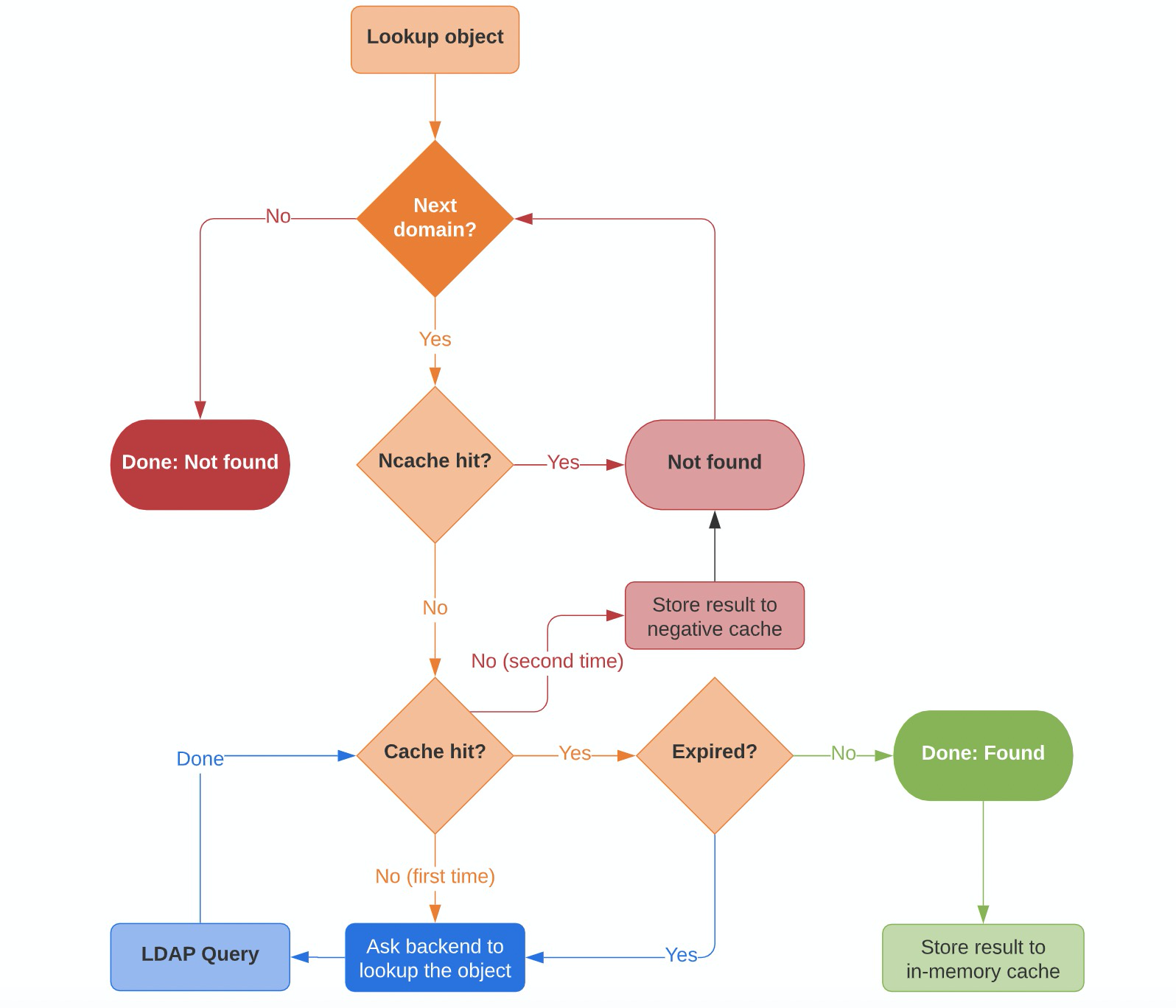
sentry
Apache Sentry是Cloudera公司发布的一个Hadoop开源组件,2016年3月从Incubator毕业,成为Apache顶级项目。
Sentry是一个基于角色的粒度授权模块,提供了对Hadoop集群上经过身份验证的用户提供了控制和强制访问数据或数据特权的能力。它可以和Hive/Hcatalog、Apache Solr 和Cloudera Impala等集成,未来可以扩展到其他Hadoop生态系统组件,如HDFS和HBase。
Sentry旨在成为可插拔授权引擎的Hadoop组件。允许定义授权规则以验证用户或应用程序对Hadoop资源的访问请求。
架构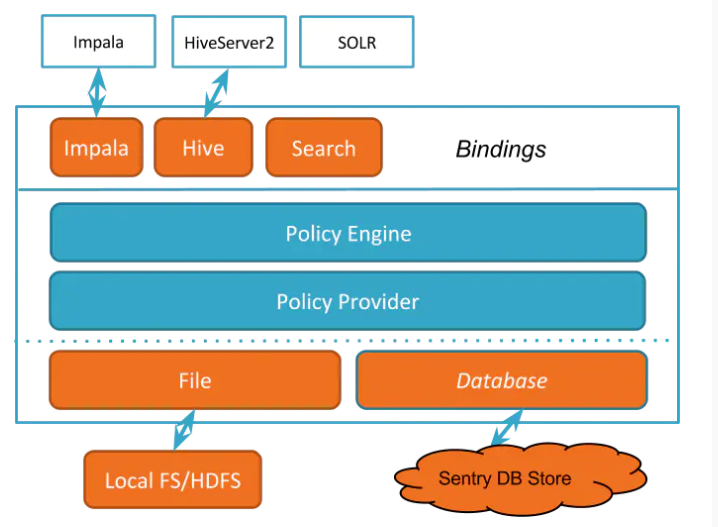
1、和hive的集成
Sentry策略引擎通过hook的方式插入到hive中,hiveserver2在查询成功编译之后执行这个hook。
这个hook获得这个查询需要以读和写的方式访问的对象,然后Sentry的Hive binding基于SQL授权模型将他们转换为授权的请求。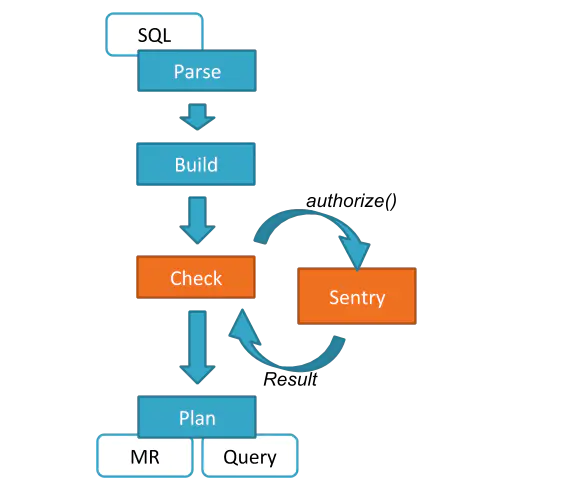
策略维护:
策略维护包括两个步骤。在查询编译期间,hive调用Sentry的授权任务工厂来生产会在查询过程中执行的Sentry的特定任务行。这个任务调用Sentry存储客户端发送RPC请求给Sentry服务要求改变授权策略。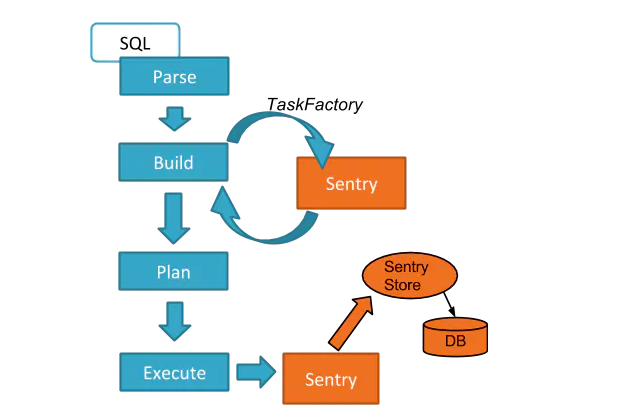
2、sssd部署
安装
yum install -y openldap-clients sssd authconfig
[domain/FAYSON.COM]
autofs_provider = ldap
ldap_schema = ad
#krb5_realm = FAYSON.COM
ldap_search_base = dc=fayson,dc=com
#krb5_server = adserver.bosch.com
id_provider = ldap
auth_provider = ldap
chpass_provider = ldap
ldap_uri = ldap://192.168.31.10:389
ldap_id_use_start_tls = false
cache_credentials = false
#ldap_tls_cacertdir = /etc/openldap/certs
# General
debug_level = 7
enumerate = false
case_sensitive = false
cache_credentials = true
min_id = 100
# Providers
full_name_format = %1$s
fallback_homedir = /home/%u
default_shell = /bin/bash
ldap_id_mapping = True
# LDAP user search settings
ldap_user_search_base = ou=cluster_user,ou=xiaox,dc=fayson,dc=com
# LDAP group search settings
ldap_group_search_base = ou=cluster_user,ou=xiaox,dc=fayson,dc=com
# LDAP Class settings
ldap_user_object_class = user
ldap_user_principal = userPrincipalName
ldap_user_name = sAMAccountName
ldap_user_gecos = displayName
ldap_group_object_class = group
ldap_group_name = sAMAccountName
ldap_user_home_directory = unixHomeDirectory
# LDAP connection settings
ldap_uri = ldap://192.168.31.10:389
ldap_default_bind_dn = administrator@fayson.com
ldap_default_authtok_type = password
ldap_default_authtok = 2wsx#EDC
[autofs]
[sssd]
config_file_version = 2
services = nss, pam, autofs
domains = FAYSON.COM
[nss]
#filter_groups = root
#filter_users = root
reconnection_retries = 3
将sssd进行启动
systemctl start sssd && systemctl enable sssd

3、sentry配置
sentry是基于角色的授权,ranger可以基于角色和基于资源进行授权
g_xiaox作为管理员组,拥有sentry的所有权限
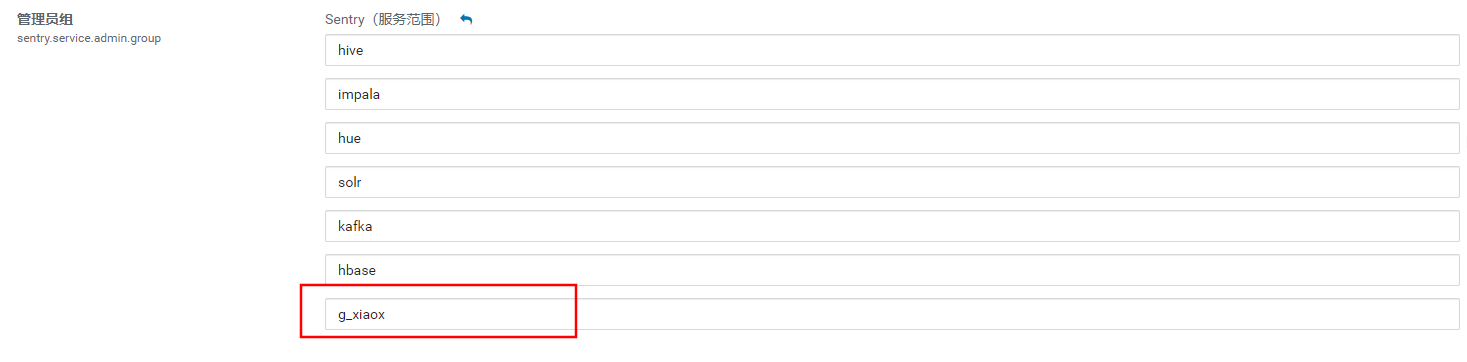
使用sentry的管理员连接到hive,设置hive的管理员角色
1、连接hive
beeline -u "jdbc:hive2://cdh01:10000/default;principal=hive/cdh01.fayson.com@FAYSON.COM"
2、进行授权
create role admin_role;
grant all on server server1 to role admin_role with grant option; ##with option ,代表可以给其他用户进行授权
grant role admin_role to group g_xiaox;
4、hive ldap配置
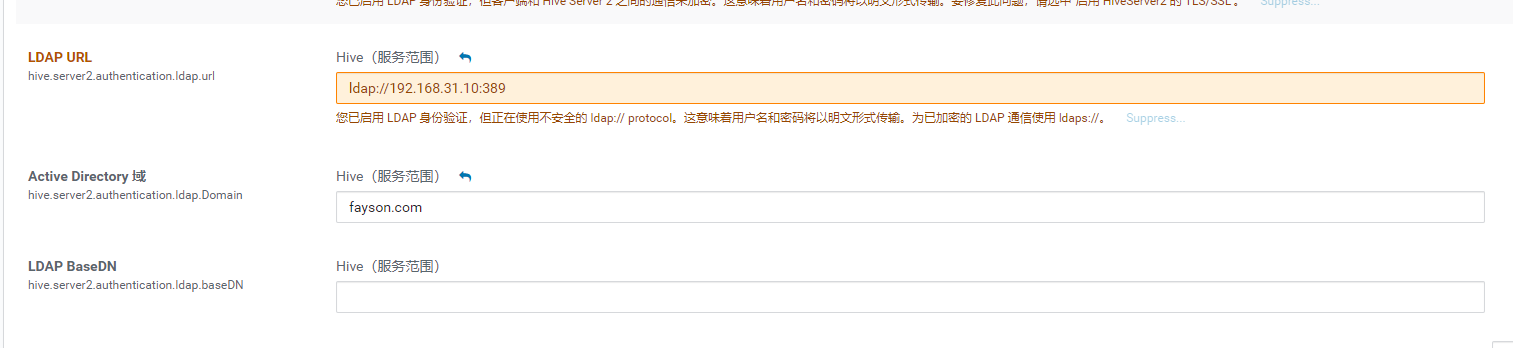
5、yarn资源池配置
1)关闭未声明资源池的自动生成。
进入YARN面板,选择配置->服务范围->资源管理->yarn.scheduler.fair.allow-undeclared-pools,默认选项是开启的,需要关闭,否则如果用户指定一个尚未声明的资源池时,YARN将为自动生成一个相对于的资源池。我们需要关闭该选项,修改之后点击保存更改,重启YARN服务生效。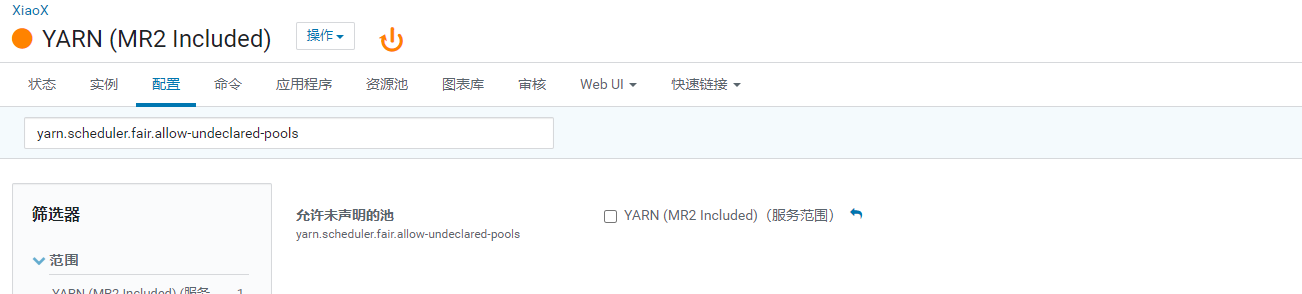
2)关闭”使用默认队列时的Fair Scheduler用户”选项
进入YARN面板,选择配置->ResourceManager Default Group->yarn.scheduler.fair.user-as-default-queue,该选项默认是开启,表示用户提交任务时,如果未指定池名称,就使用用户名作为默认的池名称,我用需要关闭该选项,让未指定此名称时,任务运行在default池中。点击保存更改,重启YARN服务生效。
3)进入动态资源池配置界面
通过集群->资源管理->动态资源池进入。
默认情况下只有一个资源池root.default,我们可以手动添加资源池并分配使用权重、VCores和内存。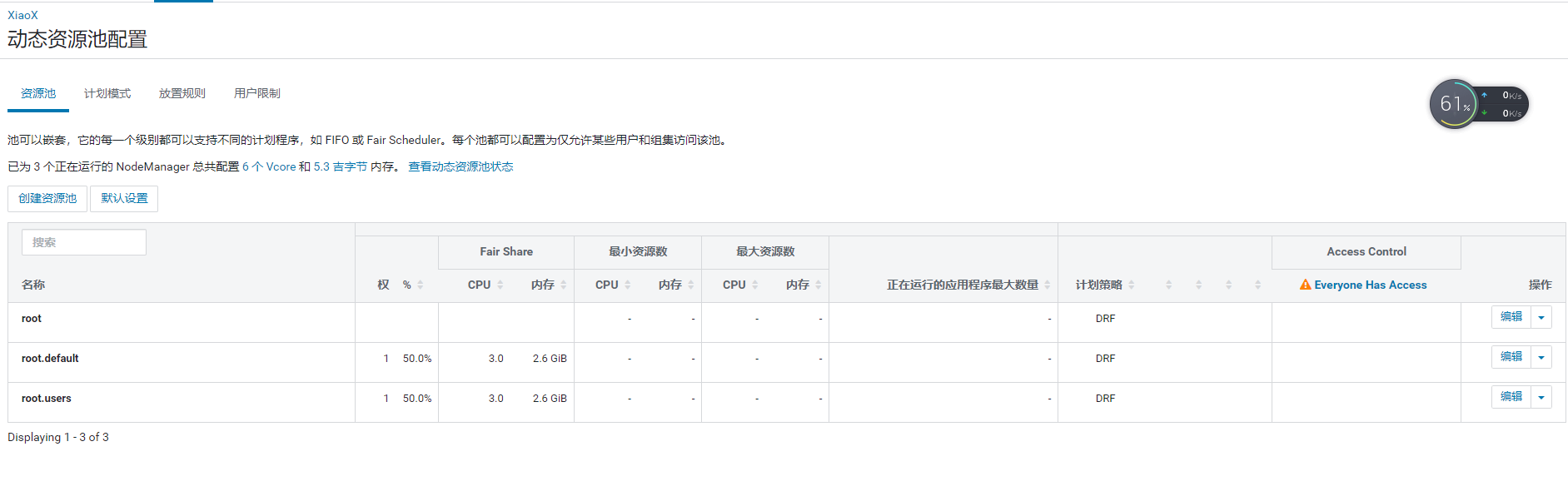
4)添加动态资源池。
选择动态资源池->配置->添加资源池。
将弹出一个引导界面:
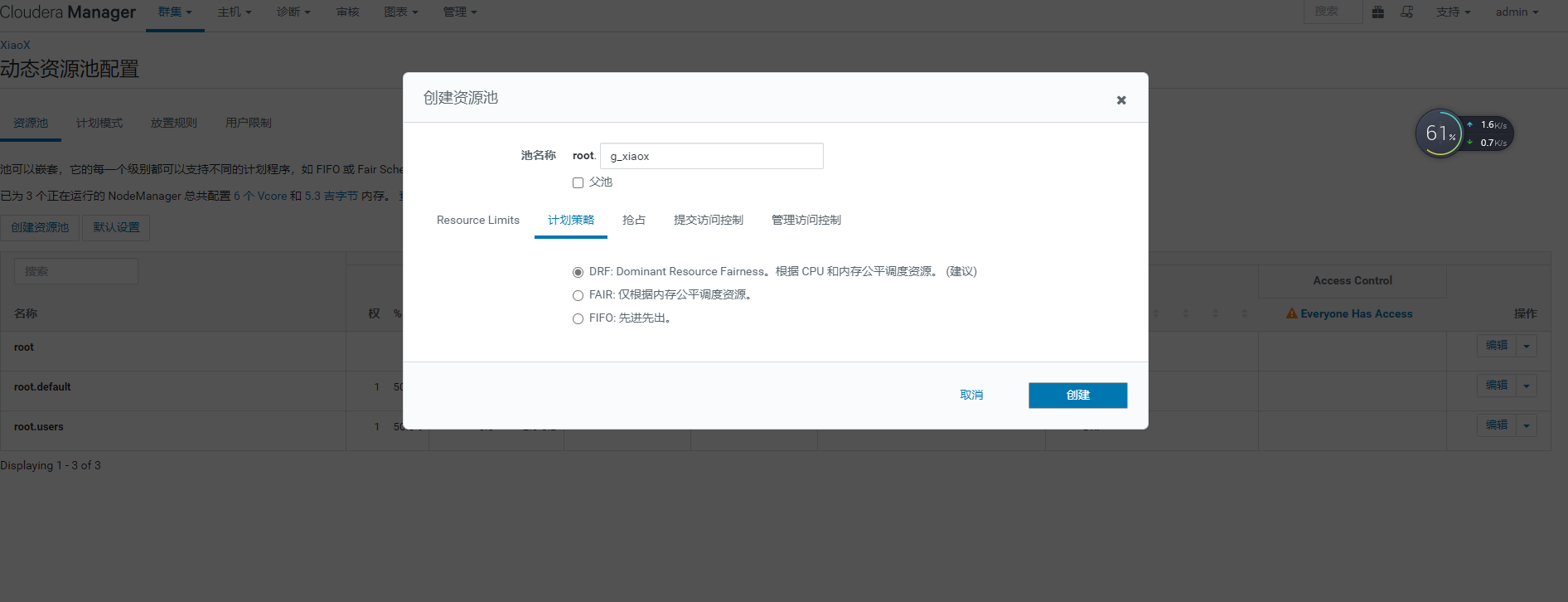
5)根据需要配置计划模式
YARN动态资源池可以根据需要配置在不同时间段选择不同的资源调度规则。
操作流程:
a)选择动态资源池->配置->计划模式->添加计划模式。
我们添加一个工作日的计划模式,在配置集中输入配置集的名称,选择重复的模式,以及重复的天数和时间。
最终我们添加2个计划模式,一个在工作日全天运行,一个在周末全天运行。
b)根据不同的计划模式配置不同的调度规则。
添加2个计划模式后,我们在编辑资源池的编辑界面就可以看到新添加的YARN配置级了,我们可以根据需要配置相应的权重、虚拟内核、内存和运行应用程序的最大数量值。
譬如我们可以配置在weekday模式下选择default池权重为66.7%,oozie池权重为33.3%。
在weekend模式下选择default池权重为50%,g_xiaox池权重为50%。
在default模式下选择default池权重为75%,g_xiaox池权重为25%。
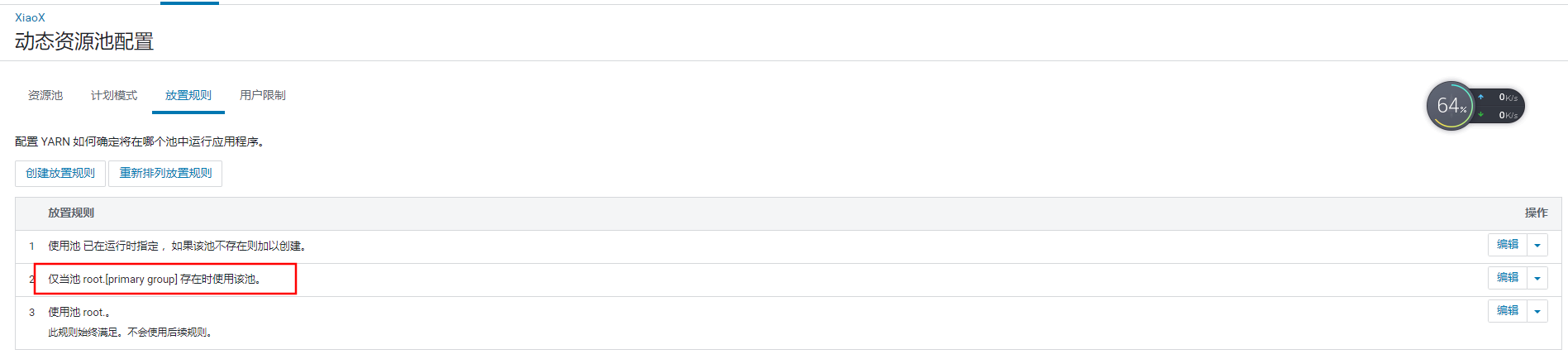
6)放置规则
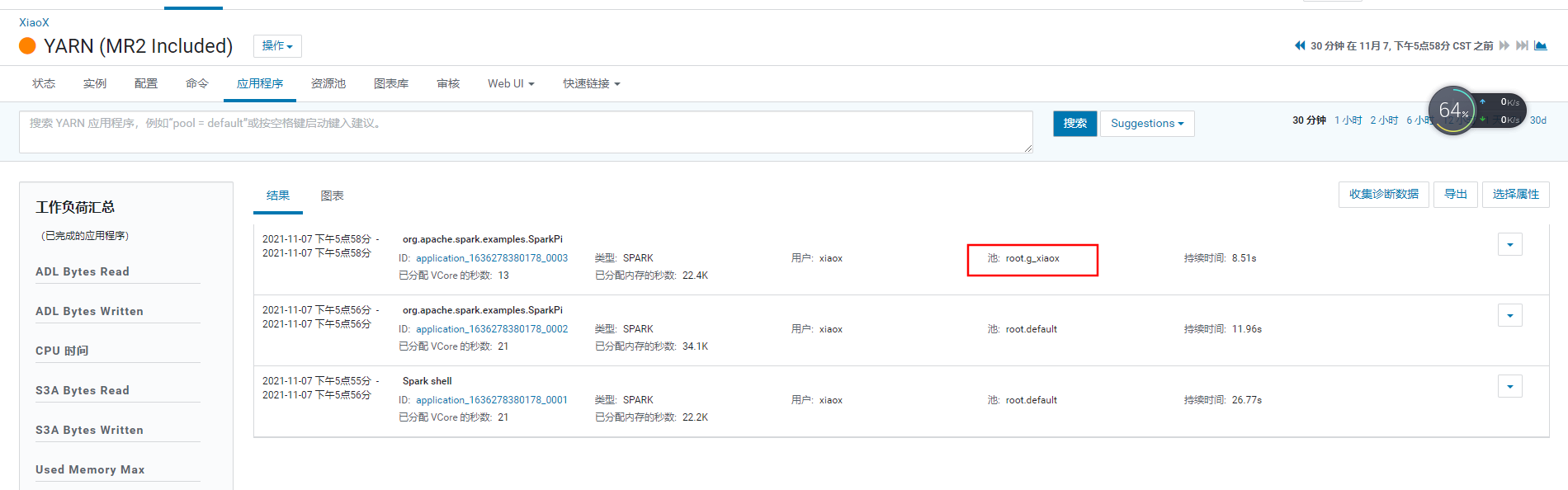
当我们在提交任务时没有设置提交的资源池,则就将任务提交到所属组的队列。
##测试任务
cd /opt/cloudera/parcels/CDH-6.2.1-1.cdh6.2.1.p0.1425774/lib/spark/examples/jars
spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster spark-examples_2.11-2.4.0-cdh6.2.1.jar 10
[
](https://blog.csdn.net/kissmelove01/article/details/45918185)
通过提交时定义资源池来提交任务,则会创建对应的资源池。也可以设定为不自动创建。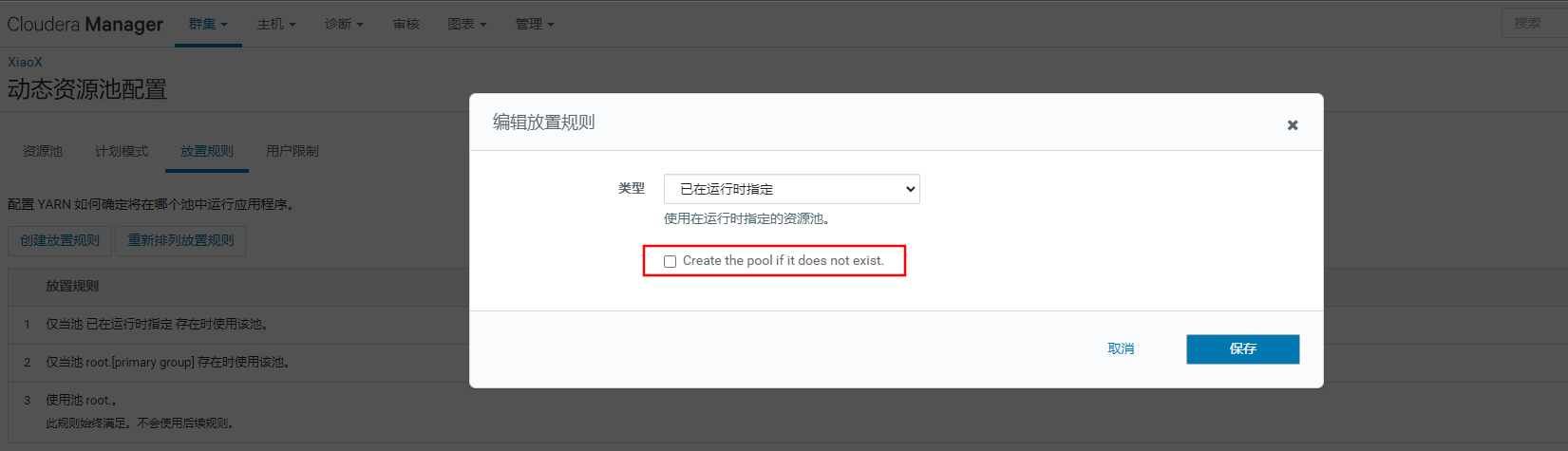
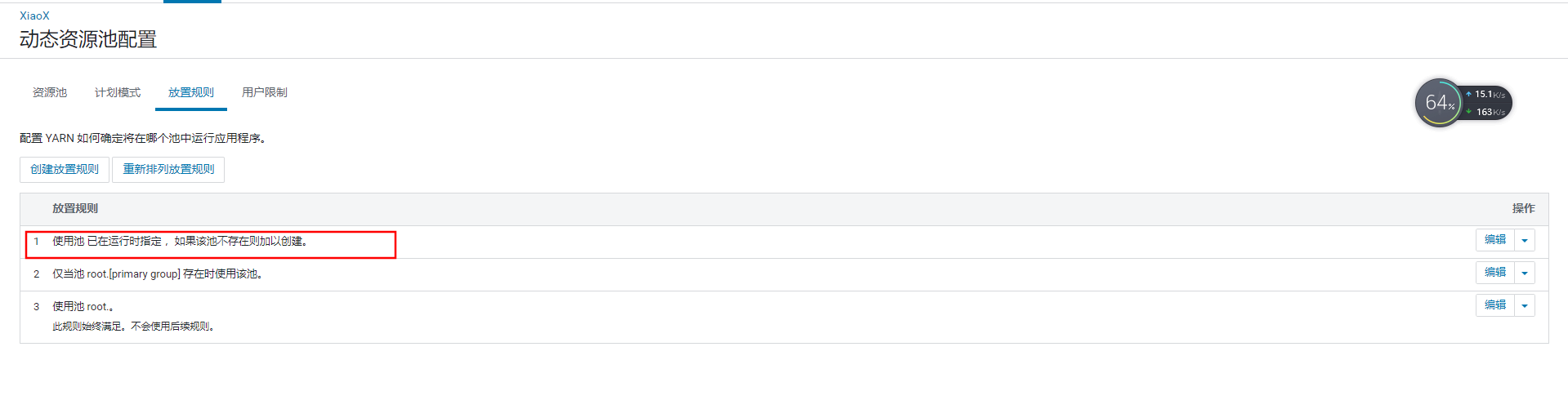
提交任务时设定资源池不存在则自动创建资源池
spark-submit --class org.apache.spark.examples.SparkPi --master yarn --queue root.test --deploy-mode cluster spark-examples_2.11-2.4.0-cdh6.2.1.jar 10
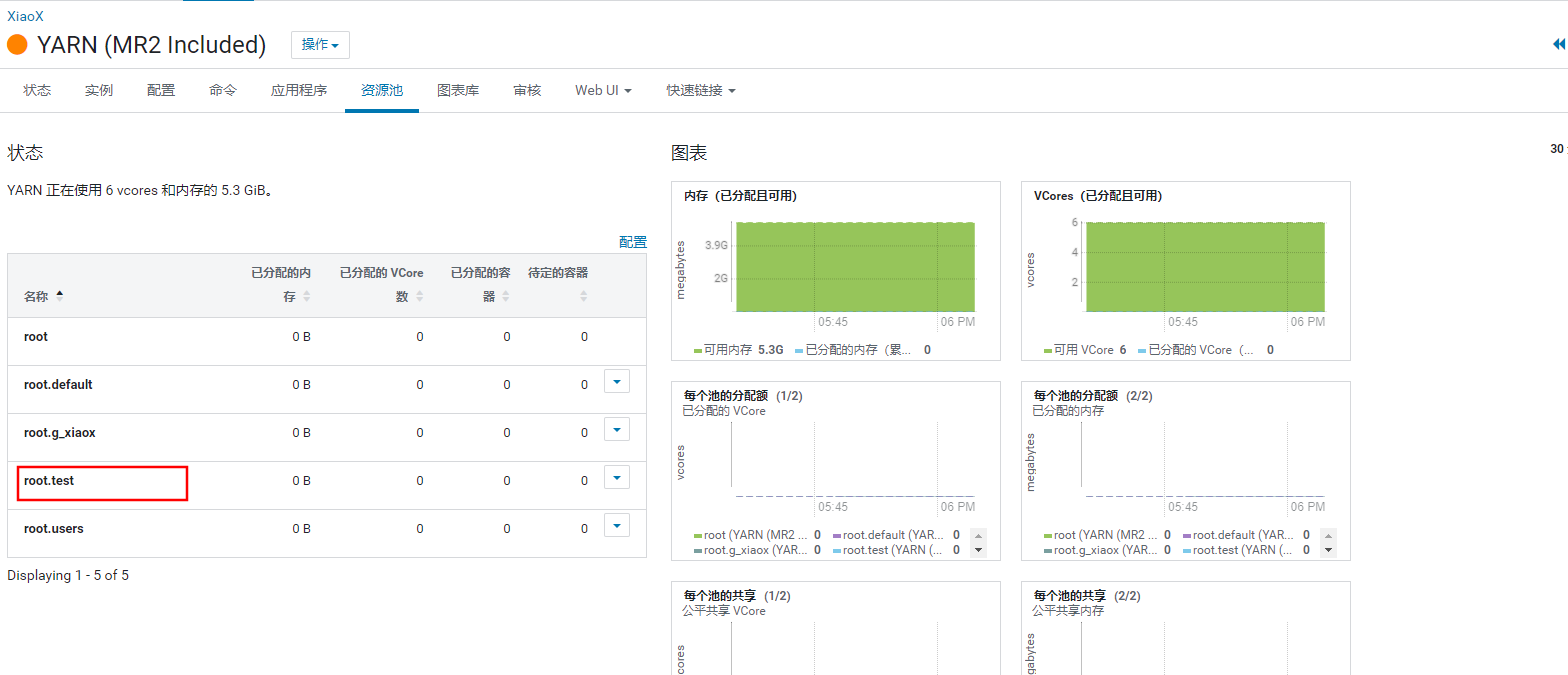
提交任务时设定资源池不存在,不自动创建资源池时,则提交到用户对应的用户组的资源池中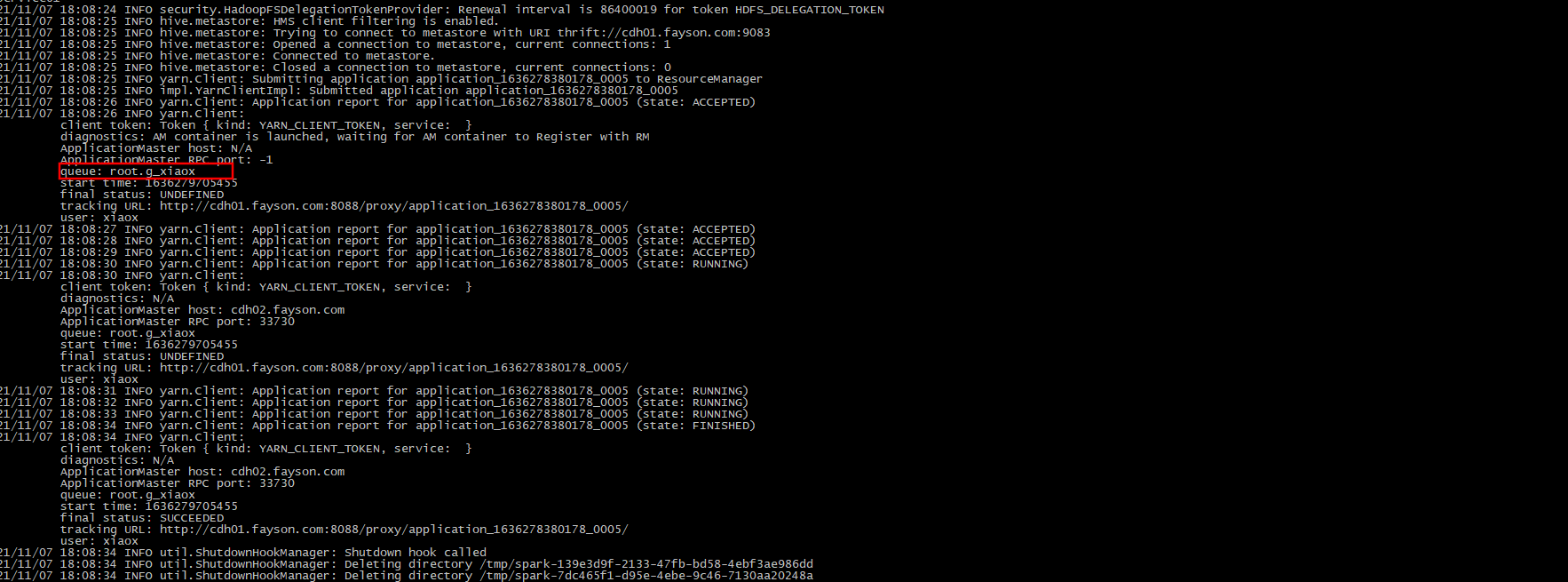

若有收获,就点个赞吧
0 人点赞
