ConcurrentHashMap的面试问题:
- ConcurrentHashMap和HashMap的区别是什么?为什么ConcurrentHashMap线程安全
- Hash扩容为什么要扩大两倍
JDK1.7
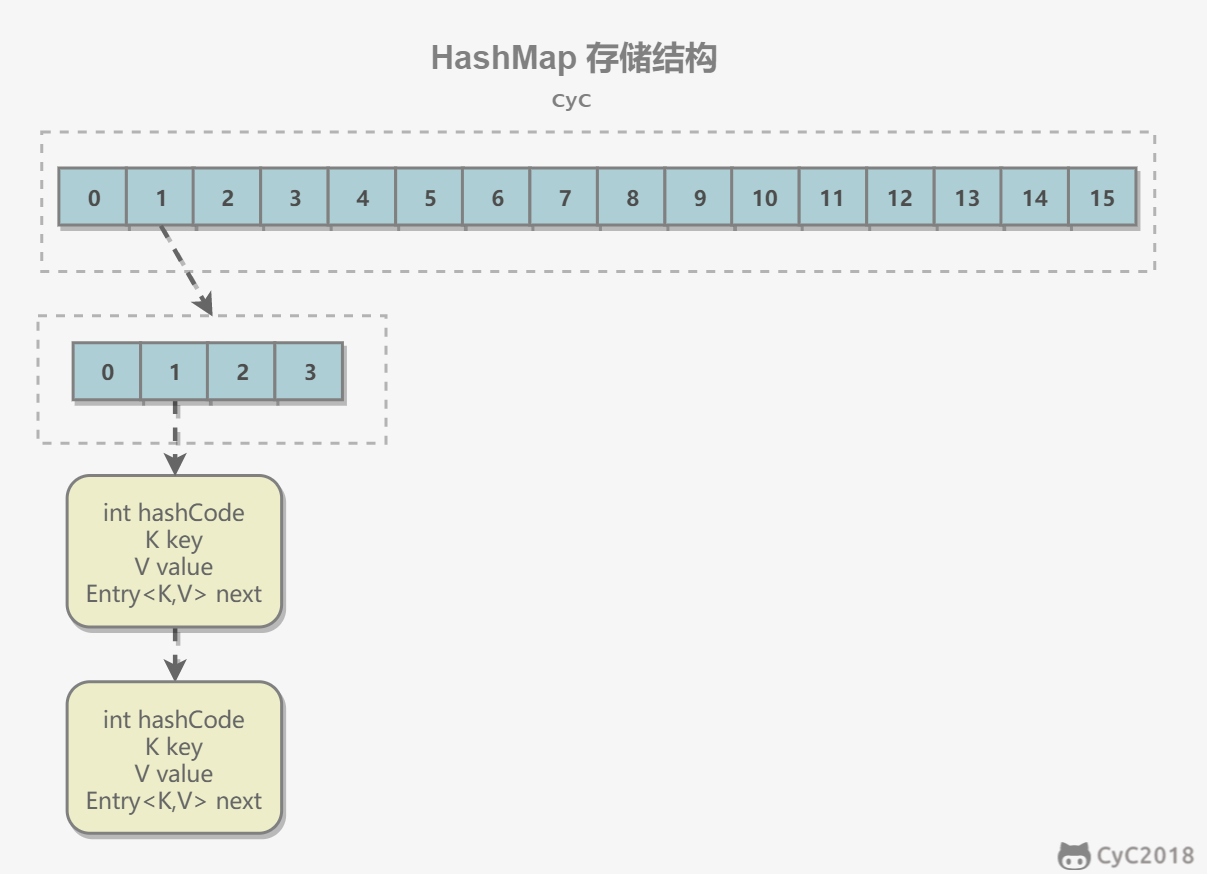
java7的ConcurrentHashMap采用了分段锁(Segment),每个段维护了几个HashEntry,多个线程可以访问不同段的HashEntry,从而使并发度提高,并发度就是Segment的个数。
默认创建16个Segment,并发度默认为16。
在执行 size 操作时,需要遍历所有 Segment 然后把 count 累计起来。
ConcurrentHashMap 在执行 size 操作时先尝试不加锁,如果连续两次不加锁操作得到的结果一致,那么可以认为这个结果是正确的。
尝试次数使用 RETRIES_BEFORE_LOCK 定义,该值为 2,retries 初始值为 -1,因此尝试次数为 3。
如果尝试的次数超过 3 次,就需要对每个 Segment 加锁。
JDK1.8
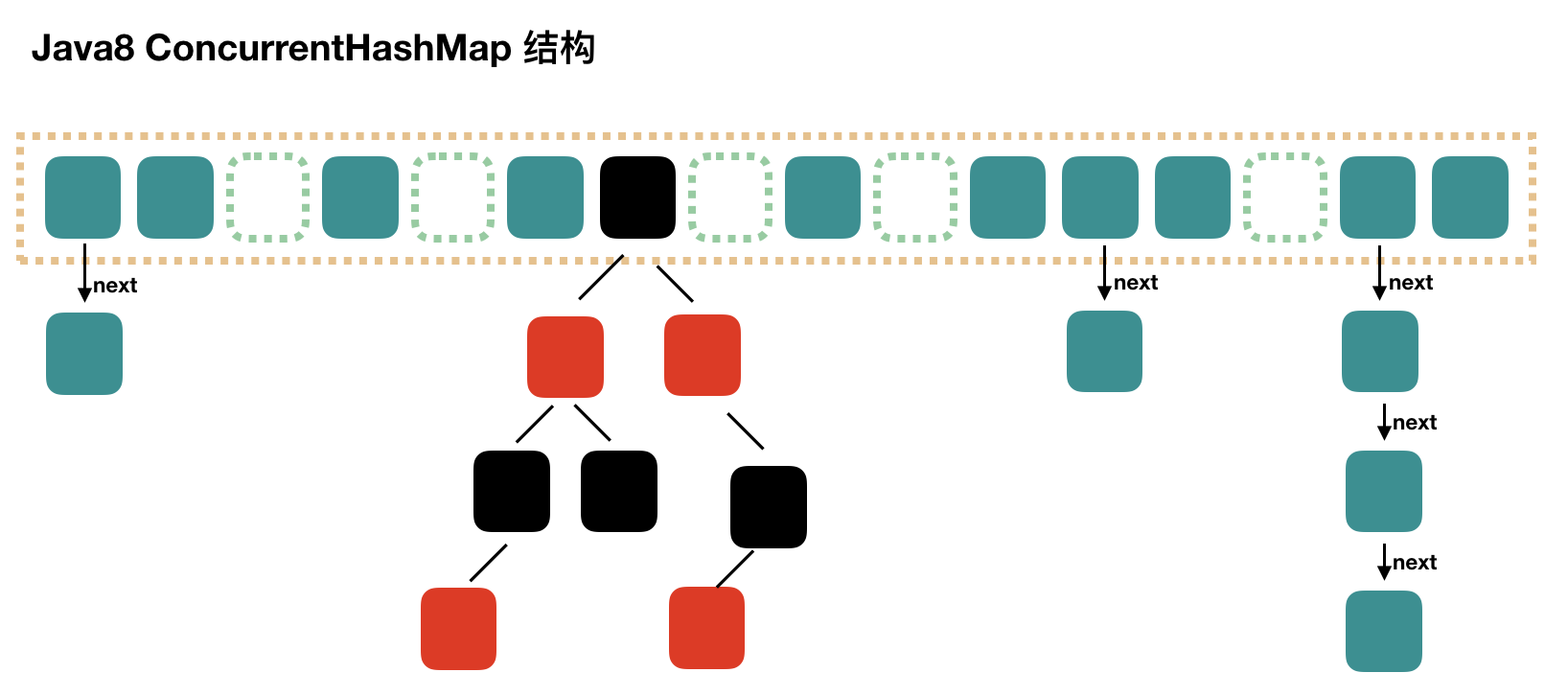
Java8的ConcurrentHashMap相对于java7,不再是之前的Segment数组+HashEntry数组+链表,而是Node数组+链表/红黑树。当链表达到一定长度时,链表会转换为红黑树。
初始化initTable()
private final Node<K,V>[] initTable() {Node<K,V>[] tab; int sc;while ((tab = table) == null || tab.length == 0) {//若sizeCtl < 0表示其他线程执行CAS成功,正在初始化或者正在扩容if ((sc = sizeCtl) < 0)Thread.yield(); // lost initialization race; just spinelse if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {try {if ((tab = table) == null || tab.length == 0) {int n = (sc > 0) ? sc : DEFAULT_CAPACITY;@SuppressWarnings("unchecked")Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];table = tab = nt;//1-0.25 = 0.75,设置容量的0.75倍为阈值sc = n - (n >>> 2);}} finally {//将阈值赋给sizeCtlsizeCtl = sc;}break;}}return tab;}
sizeCtl :默认为0,用来控制table的初始化和扩容操作
-1 代表table正在初始化
-N 表示有N-1个线程正在进行扩容操作
其余情况:
1、如果table未初始化,表示table需要初始化的大小。
2、如果table初始化完成,表示table扩容的阈值,默认是table大小的0.75倍
put方法
public V put(K key, V value) {return putVal(key, value, false);}/** Implementation for put and putIfAbsent */final V putVal(K key, V value, boolean onlyIfAbsent) {if (key == null || value == null) throw new NullPointerException();int hash = spread(key.hashCode());int binCount = 0;for (Node<K,V>[] tab = table;;) {Node<K,V> f; int n, i, fh;//判断是否初始化,没有就去初始化if (tab == null || (n = tab.length) == 0)tab = initTable();else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {//如果桶为空,不加锁插入,成功break跳出if (casTabAt(tab, i, null,new Node<K,V>(hash, key, value, null)))break; // no lock when adding to empty bin}else if ((fh = f.hash) == MOVED)tab = helpTransfer(tab, f);else {V oldVal = null;synchronized (f) {if (tabAt(tab, i) == f) {if (fh >= 0) {binCount = 1;for (Node<K,V> e = f;; ++binCount) {K ek;if (e.hash == hash &&((ek = e.key) == key ||(ek != null && key.equals(ek)))) {oldVal = e.val;if (!onlyIfAbsent)e.val = value;break;}Node<K,V> pred = e;if ((e = e.next) == null) {pred.next = new Node<K,V>(hash, key,value, null);break;}}}else if (f instanceof TreeBin) {Node<K,V> p;binCount = 2;if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,value)) != null) {oldVal = p.val;if (!onlyIfAbsent)p.val = value;}}}}if (binCount != 0) {if (binCount >= TREEIFY_THRESHOLD)treeifyBin(tab, i);if (oldVal != null)return oldVal;break;}}}addCount(1L, binCount);return null;}
步骤大概分为:
- 根据key先计算出hashcode
- 根据表是否为空,表长是否为0判断是否进行初始化。
- 根据hash定位Node节点,如果节点为空,则用CAS尝试写入。
- 若hashcode==-1的话,表示map正在扩容,该线程调用
helpTransfer()帮助扩容。 - 若以上都不满足,则用synchronize锁住这个Node节点。
- 之后判断是否是链表,是的话遍历链表,遍历的过程中如果有节点key和待加入的key相同,则覆盖,遍历到尾部则说明无覆盖情况,直接插入。
- 不是链表若是红黑树则对树做一次put操作。
- 之后检查map大小是否超过阈值,根据具体情况调用transfer来扩容。
get方法
get逻辑相对简单而且连CAS都不用,不贴源码了,直接写逻辑
- 根据key计算hash
- 根据hash确定头结点,头结点存在则进入下一步
- key的hash相同,key值也相同,直接返回元素
- 若头结点hash值小于0,表示正在扩容,或是红黑树,调用find查找
- 如果是链表,就遍历查找

若有收获,就点个赞吧
0 人点赞
