SSD
论文:https://arxiv.org/pdf/1512.02325.pdf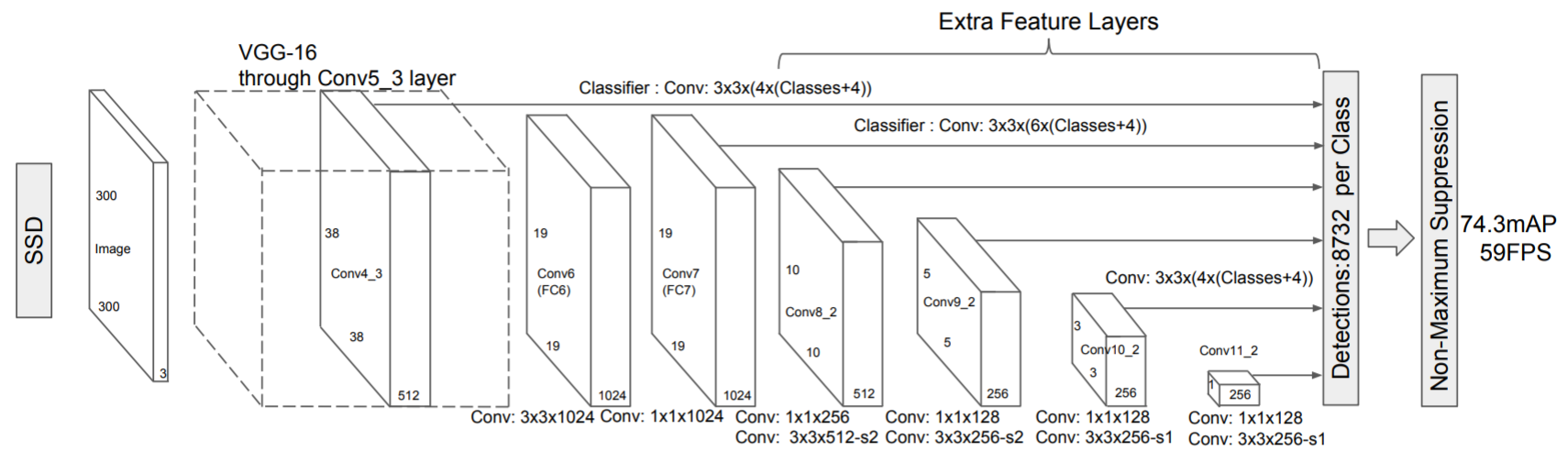
SSD原始论文中使用的backbone以VGG16为基础,去除了全连接并继续堆叠卷积层,用于提取不同尺度的特征图用于预测。每个提取出来的特征图都直接通过一个3x3卷积得到输出,其中输出也是一个二维向量,代表每个位置上对应的各个分类的概率和目标框的偏移,这和Faster R-CNN中每个候选框经过ROI pool后单独过head网络得到一维输出有所不同,SSD是一次性把所有位置上的预测都做完了(类似Faster R-CNN的RPN)。
不同level的特征图的每个位置上都会被生成4个(1:1、2:1、1:2、面积较大的1:1)或6个锚框(1:1、2:1、1:2、3:1、1:3、面积较大的1:1),当然这个数字也能根据应用自行调整。每个锚框对应的回归结果包括分类概率(Classes维)和预测框偏移(4维),因此每个用于得到回归结果的3x3卷积的输出维度为 。
。
论文中图像输入分辨率为 ,较小锚框的标准尺寸为
,较小锚框的标准尺寸为 ,较大锚框的标准尺寸为
,较大锚框的标准尺寸为 。
。
Faster R-CNN
在另一篇博文中单独详细写了:Faster R-CNN
FPN
论文:https://arxiv.org/pdf/1612.03144.pdf
FPN的提出受语义分割UNet(引用郑老师链接)启发,增加了上采样路径(top-down Path)并且与浅层特征融合,如下图(d)。(一般网络浅层叫“down”深层叫“top”)。通常采用了FPN的backbone成为“xxx-FPN”,例如“ResNet50-FPN”,FPN的使用不依赖于原始的特征提取网络,只需要在原有网络基础上添加组件(类似SE模块),原始网络只需要改一下forward函数即可。
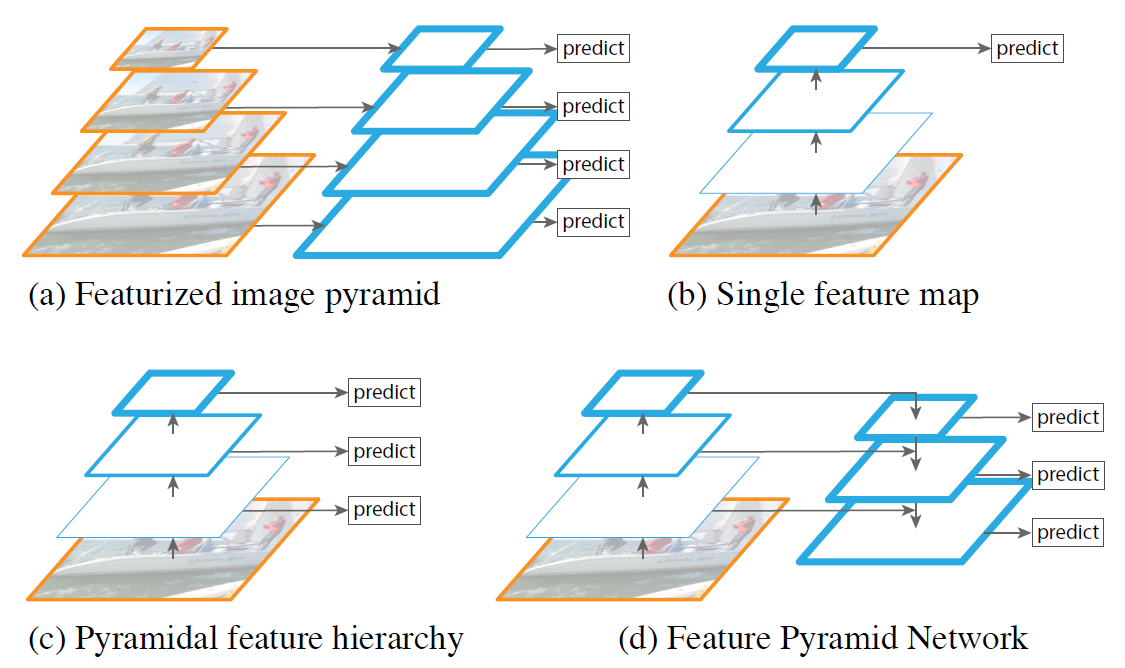
金字塔模型的提出能够帮助目标检测任务更好地同时检测大小目标,上图中(a)即是最原始的一种图像金塔。
(a) 图像金字塔
将输入图像做多次下采样后,每个level的输入分别经过不同的backbone后进行预测,慢!
(b) 单一特征图
这也是传统的Faster R-CNN采用的方法,只使用了最深层的特征图,该特征图虽然包含的语义信息丰富但是失去了多尺度信息,特征图分辨率较低,往往对于小目标的检测能力较弱。
(c) 层级特征金字塔
这也是传统的SSD采用的方法,浅层的特征图和深层的特征图一起分别用于预测。该方法虽然保留了多尺度空间信息,但是由于浅层的特征图语义信息过于匮乏,效果也有所欠佳。
(d) 特征金字塔
这是FPN采用的方法,深层的特征图在上采样后(插值、反卷积等)与浅层特征图融合(文中采用了元素级相加的形式,UNet中是concat)后分别用于预测。该方法在保留多尺度空间信息的基础上,为每个level的特征图都引入了深层语义信息,相对效果更好。
上采样模块
与传统Faster R-CNN的对比
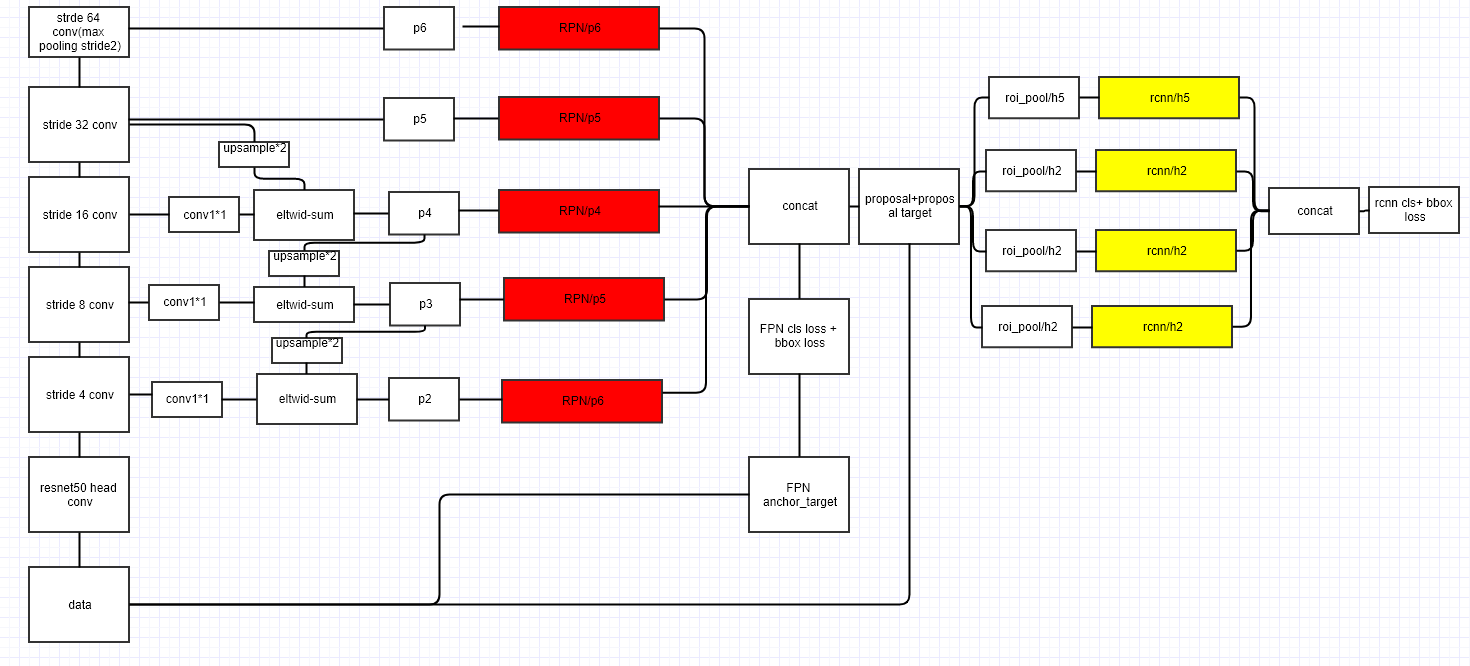
作者构建了Faster R-CNN with FPN,其结构如下所示。
**
- 在最深层的特征图上直接做一次maxpool再生成一系列分辨率更小的特征图F6以帮助大目标的检测,但是该特征图不参与上采样,上采样从特征图F5开始。由于目标检测输入很大(FPN文中是短边800),不用担心下采样64倍后的特征图太小。
(后来用 的一些网络在
的一些网络在 上做stride-2 conv得到
上做stride-2 conv得到 ,再做ReLU + stride-2 conv得到
,再做ReLU + stride-2 conv得到 )
)
- F5经过1x1卷积将通道数压缩为256后得到P5(这个图中没画出来)
- 每一次特征图上采样后,都取出与之分辨率相符的浅层特征图,经过1x1卷积变换通道数为256后做元素级加和。加和的结果再经过一个3x3卷积得到最终用于预测的特征图Pn。
- 每一level的特征图
 都会经过独立的RPN分别生成proposals,毕竟这些特征图的分辨率都不一样(如果不用反卷积做up-sample,直接用插值做up-sample的话似乎用同一个RPN也行?)。但是不同proposals在ROI池化后会被采样为同样的分辨率,并经过相同且唯一的head网络做最终预测。
都会经过独立的RPN分别生成proposals,毕竟这些特征图的分辨率都不一样(如果不用反卷积做up-sample,直接用插值做up-sample的话似乎用同一个RPN也行?)。但是不同proposals在ROI池化后会被采样为同样的分辨率,并经过相同且唯一的head网络做最终预测。 - 特征金字塔中的特征图有若干多个,根据proposal对应原始图像的大小来确定从特征金字塔中的哪一层裁取特征图送入head网络:
 。其中
。其中 代表裁出来的FeatureMap对应的原始图像的大小,
代表裁出来的FeatureMap对应的原始图像的大小, 。也就是说如果ROI大小为
。也就是说如果ROI大小为 ,则从P4中裁取。这也很容易理解,大目标需要从低分辨率的特征图中获取信息,小目标需要从大分辨率的特征图中获取信息。
,则从P4中裁取。这也很容易理解,大目标需要从低分辨率的特征图中获取信息,小目标需要从大分辨率的特征图中获取信息。 - 原来的Faster R-CNN只在最深层的特征图上处理,特征图上的每个位置都会生成9个anchor(3种大小的,1:1、1:2、2:1长宽比的锚框);但是在FPN上,多尺度通过不同level的特征图实现,因此每个level的特征图上,每个位置都仅生成3个anchor(固定大小的,1:1、1:2、2:1长宽比的锚框)。
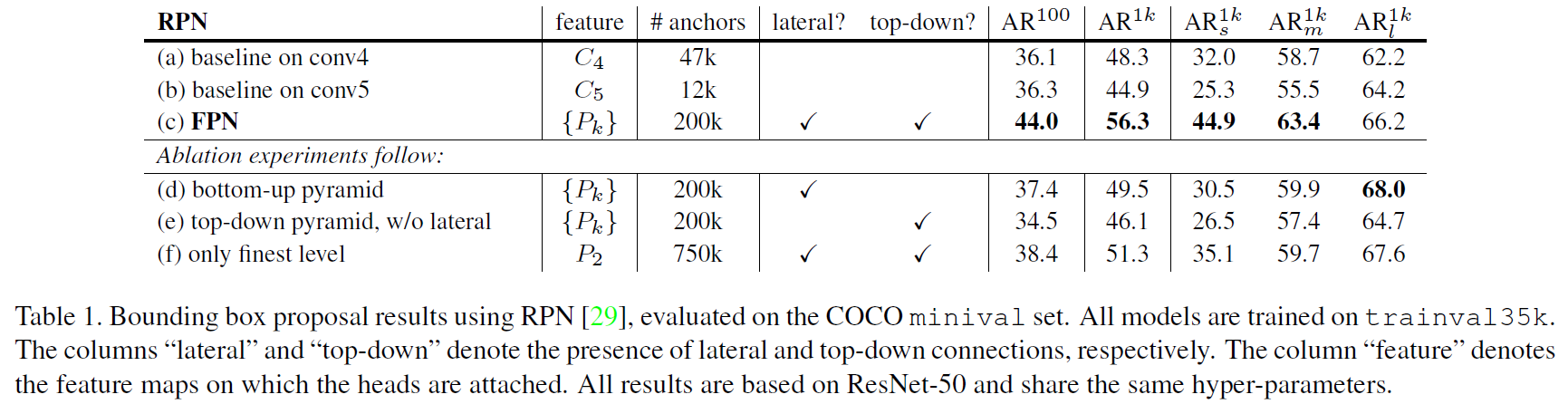
实验结果
单独使用RPN结果作为最终结果( 对应特征金字塔中的
对应特征金字塔中的 ):
):
使用上一步中(c)例中FPN结构下的RPN的proposals作为候选框时,Fast R-CNN的结果(比较同样候选框时不同特征图的效果):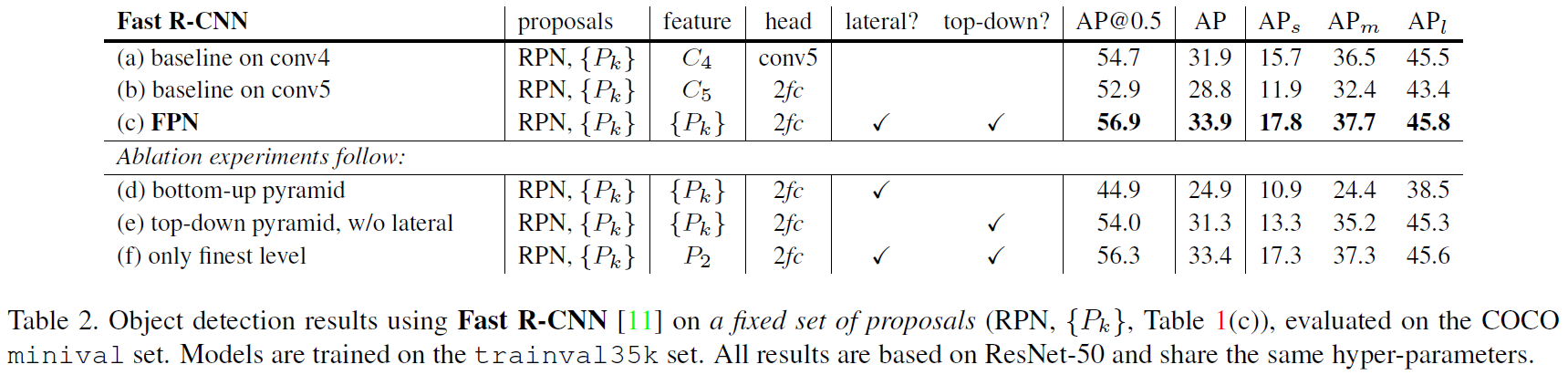
Faster R-CNN结果:
RetinaNet
论文:RetinaNet
网络结构
RetinaNet的backbone与SSD非常类似,但是head部分复杂了不少。head网络的classification子网络是在对K个类做0/1二分类,而非(K+1)分类,但最骚的是不同层级共享head网络的权重是我没想到的。(不同层级的输入分辨率不一样,但共享权重)
不同于FPN采用了P2~P6作为特征,RetinaNet采用了P3~P7(论文中输入分辨率是600x600)。在上做stride-2 conv得到,再做ReLU + stride-2 conv得到。没采样P2是由于开销原因,采用了P7是为了更好地检测大样本(毕竟FPN检测大样本能力较弱,从上一章FPN的实验结果也能看出)。NAS-FPN中也提出了另一种说法,水平连接导致网络更关注backbone的浅层(累积到更多的梯度)而忽略了backbone高层特征的学习从而导致大样本检测精度劣化。
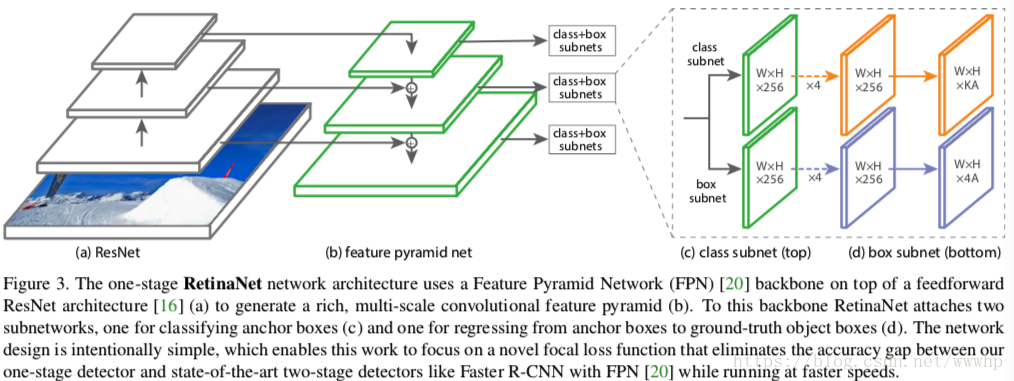
另外虽然RetinaNet采用了FPN作为neck以获取多尺度信息,但RetinaNet采用了更加密集的锚框大小采样,在每个level的特征图的每个点上都生成了9个anchor(边长倍率为 ,1:1、1:2、2:1长宽比)。锚框边长大小的分辨率从
,1:1、1:2、2:1长宽比)。锚框边长大小的分辨率从 倍上升到了
倍上升到了 倍。
倍。
Focal loss
RetinaNet的一大创新点是,优化了一阶段检测器训练过程中正负样本严重不平衡的问题。在Faster R-CNN这类二阶段检测器中,我们可以通过两阶段级联、固定前景和背景1:3采样、在线难例挖掘等方式缓解正负样本不平衡的问题,但一阶段检测器中所有样本都直接进行预测,无法进行类似的正负样本平衡。这导致一阶段检测器训练过程中,loss被easy Negtive主导(虽然单个样例loss低但奈何数量实在太大)。
作者提出的focal loss是一个能动态缩放的交叉熵损失函数:

其中 为标准交叉熵。
为标准交叉熵。 为考虑了正负样本平衡的交叉熵,通过对负样本加较小的
为考虑了正负样本平衡的交叉熵,通过对负样本加较小的 以达到正负样本
以达到正负样本
平衡的效果。 为focal loss损失函数,除了考虑到平衡正负样本外,还能够让模型更多地关注难例。
为focal loss损失函数,除了考虑到平衡正负样本外,还能够让模型更多地关注难例。
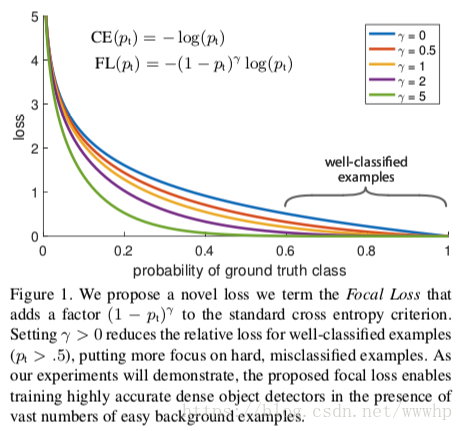

这里涉及到一个问题就是算focal loss的时候 是否进行复合求导还是直接detach作为权重计算。简单在CIFAR上跑了下实验,结果差不多,复合求导相比detach高0.5个点。不过这也可能是因为CIFAR数据集太简单训到后来train acc全是100%不存在“难例”了。
是否进行复合求导还是直接detach作为权重计算。简单在CIFAR上跑了下实验,结果差不多,复合求导相比detach高0.5个点。不过这也可能是因为CIFAR数据集太简单训到后来train acc全是100%不存在“难例”了。
Mask RCNN
论文:Mask R-CNN
多任务学习
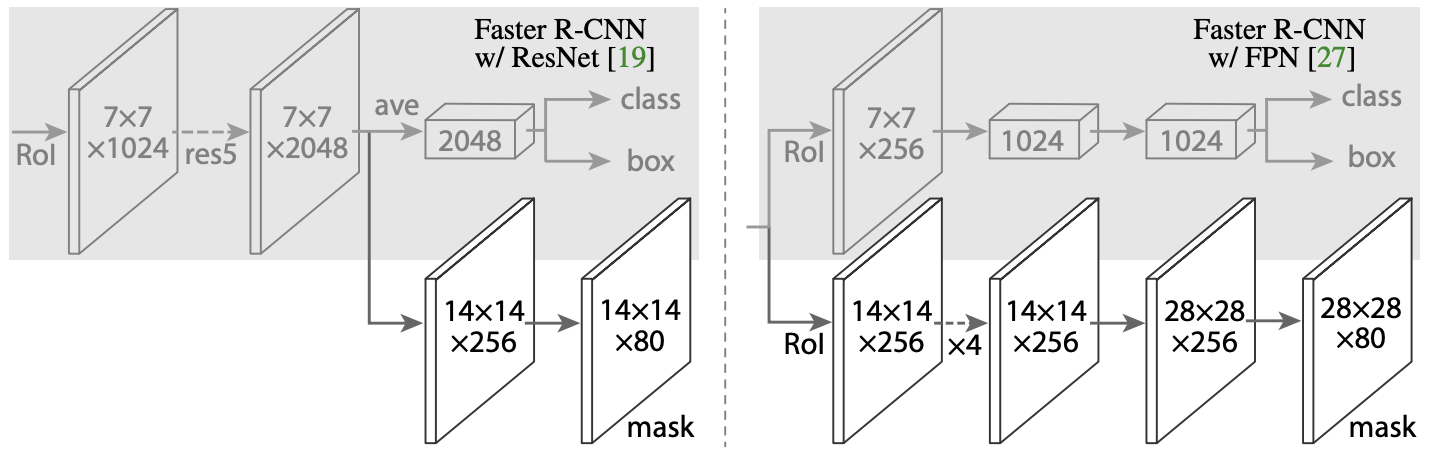
上图展示了Mask RCNN的head网络部分,灰色部分是原始的Faster RCNN网络的head,下面的分支是Mask RCNN添加的,用于粗粒度图像分割任务的分支。最终的mask对每个类别都做了0/1二分类,用Softmax作用于输出层而非Softmax。训练时每个分类的输出均做交叉熵计入损失,推理时根据分类结果产生单个分类的粗粒度分割结果用于辅助。
ROI Align
Mask RCNN将此前Faster RCNN使用的ROI Pooling改为了ROI Align,因为ROI Pooling中有两次取整过程,而ROI Align只有一次。
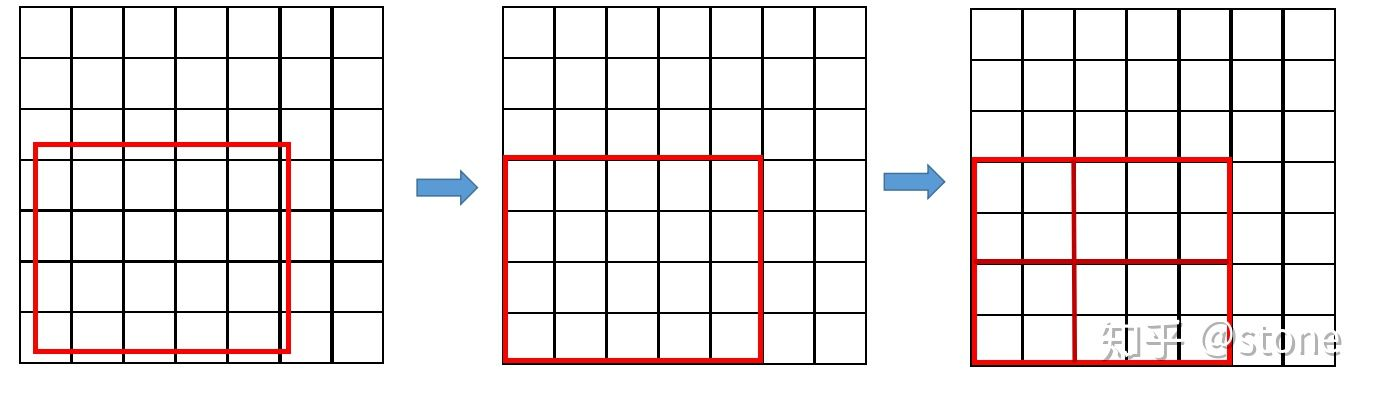
ROI Pooling的取整
- 由于RPN输出的候选框的中心点、长宽都是小数,为了能从FeatreMap上裁取需要对裁切区域做取证操作;
- ROI Pooling中,划分区域需要进行一次取整。
下图展示了ROI Pooling的这两次取整过程
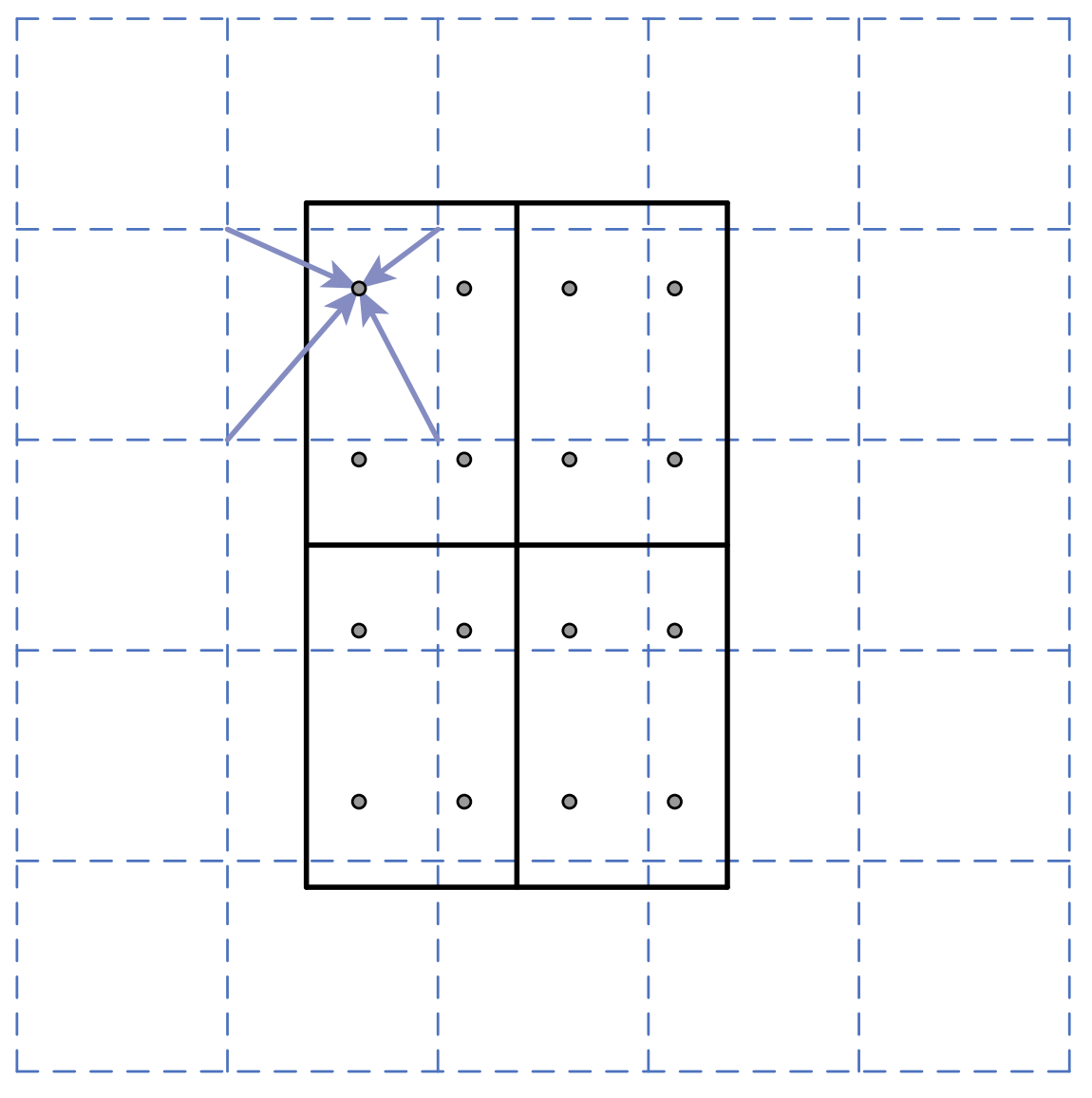
<br />**ROI Align的取整**
直接利用双线性插值,在以上ROI Pooling中最左边这张图的框中进行采样。
PANet
论文:PANet
参考:https://blog.csdn.net/u014380165/article/details/81273343
Bottem-up Path
FPN提出了Top-down Path,用于帮助模型更好地检测多尺度大小地目标。PANet提出了Bottem-up Path,主要为了将浅层特征(边缘形状等低级特征)融入语义信息丰富的深层特征图,以保证位置更精准的目标检测或图像分割。PANet在COCO2017实例分割中获得了冠军。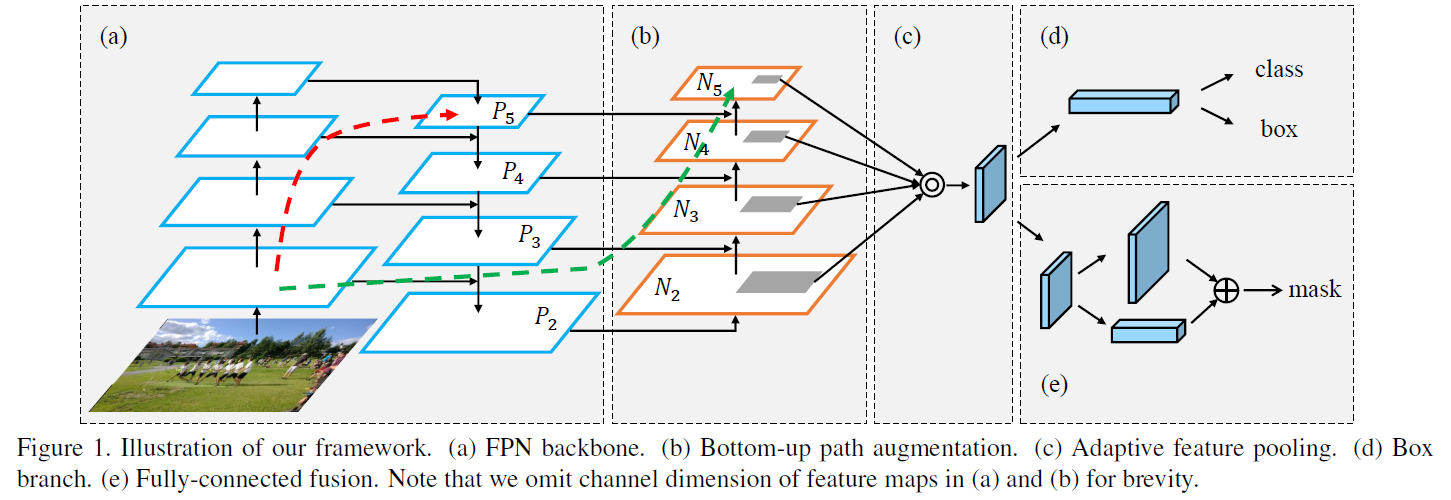
上图中(a)部分即是FPN的backbone和neck部分网络,包括了特征提取CNN(左侧)和Top-down Path(右侧)。由于backbone部分的CNN非常复杂层数也深,FPN结构只能将浅层特征传递至 ,而无法传递至深层的特征图(红色虚线箭头所示)。(b)部分则是PANet提出的Bottem-up Path,浅层特征经过FPN中的水平连接传递到后,只需要经过(b)中的非常简单的网络就能从
,而无法传递至深层的特征图(红色虚线箭头所示)。(b)部分则是PANet提出的Bottem-up Path,浅层特征经过FPN中的水平连接传递到后,只需要经过(b)中的非常简单的网络就能从 传递至
传递至 ,这个网络相比backbone要小得多,因此即使到了层也能保留相当的,从backbone浅层提取到的基础特征(绿色虚线箭头所示)。
,这个网络相比backbone要小得多,因此即使到了层也能保留相当的,从backbone浅层提取到的基础特征(绿色虚线箭头所示)。
不同于FPN用 作为特征图送入head网络,PANet采用
作为特征图送入head网络,PANet采用 。的下采样过程与FPN的上采样过程类似,只不过将x2 up-sample替换成了stride=2的3x3卷积。
。的下采样过程与FPN的上采样过程类似,只不过将x2 up-sample替换成了stride=2的3x3卷积。
Adaptive Feature Pooling
Adaptive Feature Pooling主要做了特征融合,用于替代ROI Pooling和Mask RCNN中的ROI Align。后两者对于每个proposal都只采用了一个尺度的特征图,PANet提出将所有尺度的特征图融合后再送入head网络做最终预测。
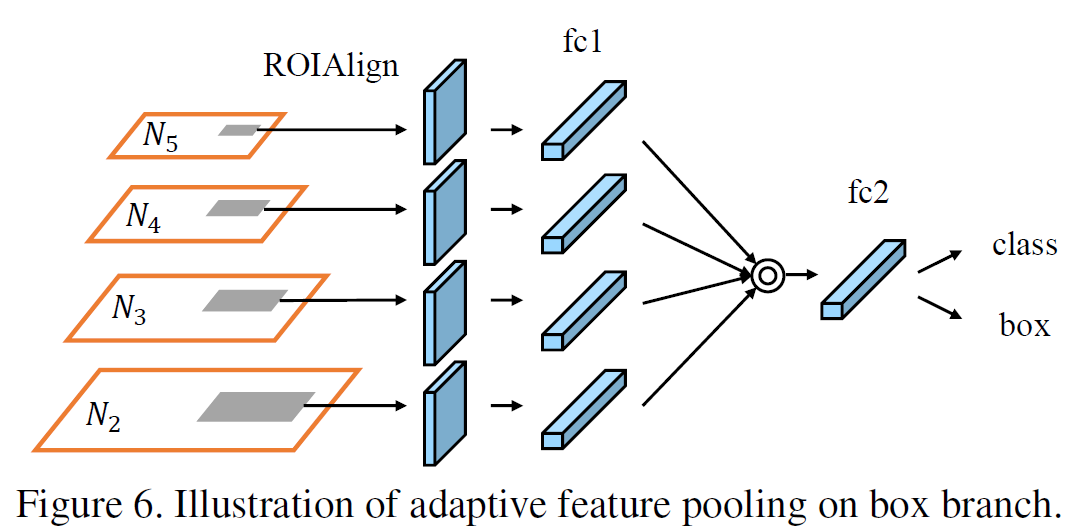
Adaptive Feature Pooling根据proposals的空间位置,从所有4个level的特征图中截取ROI,经过ROI Align后得到尺寸相同的4个特征图,并通过取 的方法进行融合,以利用特征金字塔中不同层级的特征。
的方法进行融合,以利用特征金字塔中不同层级的特征。
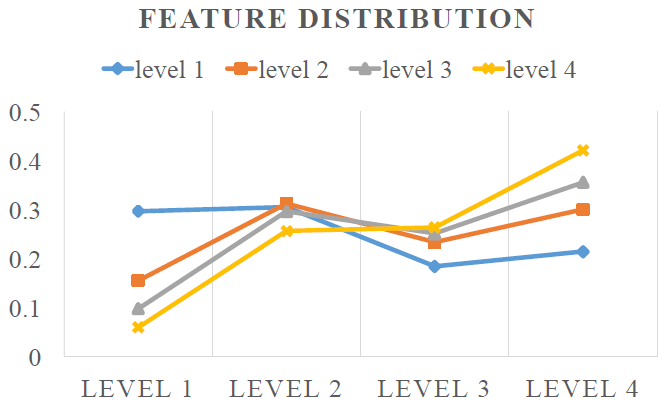
作者统计了融合后的,送入head网络的特征图中,从各个level获取的信息的比例,如下图所示,每条线都代表了大小相似,在FPN中被分为同一层级的proposals。可以看到尺寸最小的 的proposals对应的特征中,只有大约30%的信息来自于最低层的特征图(蓝线最左侧的点),
的proposals对应的特征中,只有大约30%的信息来自于最低层的特征图(蓝线最左侧的点), 的proposals对应的特征中甚至从获取的信息比
的proposals对应的特征中甚至从获取的信息比 (FPN中使用的特征图层级)都多。每个level的proposals都利用到了所有level的特征,因此融合了多尺度特征的Adaptive Feature Pooling是非常有效的。
(FPN中使用的特征图层级)都多。每个level的proposals都利用到了所有level的特征,因此融合了多尺度特征的Adaptive Feature Pooling是非常有效的。
其它
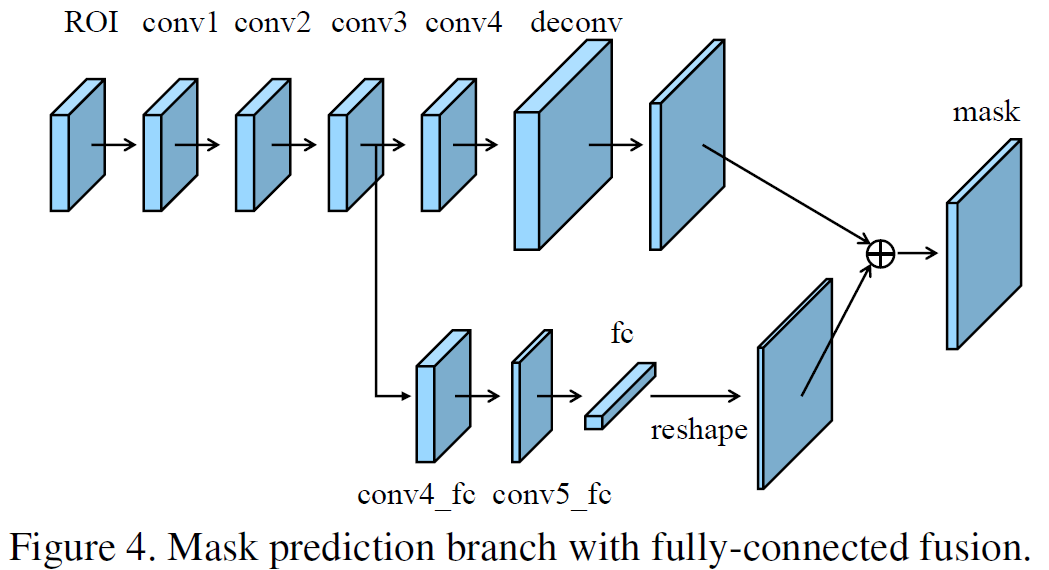
Fully-connected Fusion
作者还优化了Mask RCNN中的分割任务支路,添加了一条支路用于做前景/背景的二分类,辅助对所有类别做0/1二分类的,通道数等于前景分类数的Mask RCNN中采用的mask。
跨GPU的BN层计算
论文的附录B中提到了跨GPU的BN层计算,因为目标检测的时候batch_size小的可怜,直接统计BN参数可能会爆炸。由于暂时没碰到所以先没看。
NAS-FPN
论文:NAS-FPN
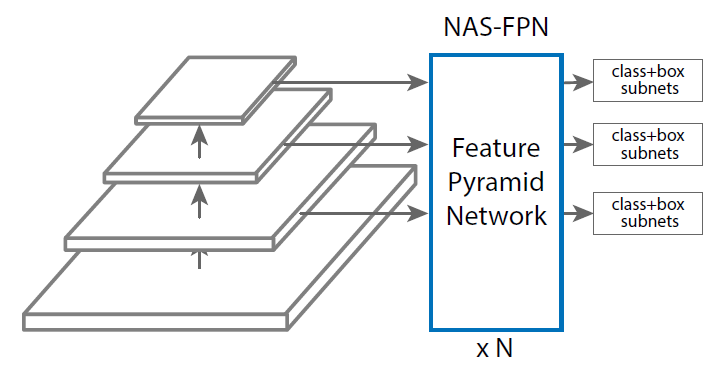
NAS-FPN提出,FPN的水平连接导致网络更关注backbone的浅层(累积到更多的梯度)而忽略了backbone高层特征的学习从而导致大样本检测精度劣化。后来的PANet的提出也是从改进了neck网络层级连接的角度出发的。NAS-FPN即是将NAS方法用到了目标检测neck网络(下图NAS-FPN部分)的搜索中,搜出来的新网络。
NAS-FPN的baseline选取了RetinaNet,以提升搜索速度并排除Two-Stage检测中proposal采样等的影响。(特征金字塔总共有5层 ,别看图里只画了3层。
,别看图里只画了3层。 是直接在
是直接在 上做s2,s4的maxpool得到的,和FPN有所不同)
上做s2,s4的maxpool得到的,和FPN有所不同)
另外NAS-FPN还可以进行堆叠以进一步提高性能(也许?),还可以在堆叠的每一个NAS-FPN后分别拉head分类器做early stop(和自蒸馏分类网络的early stop类似)。
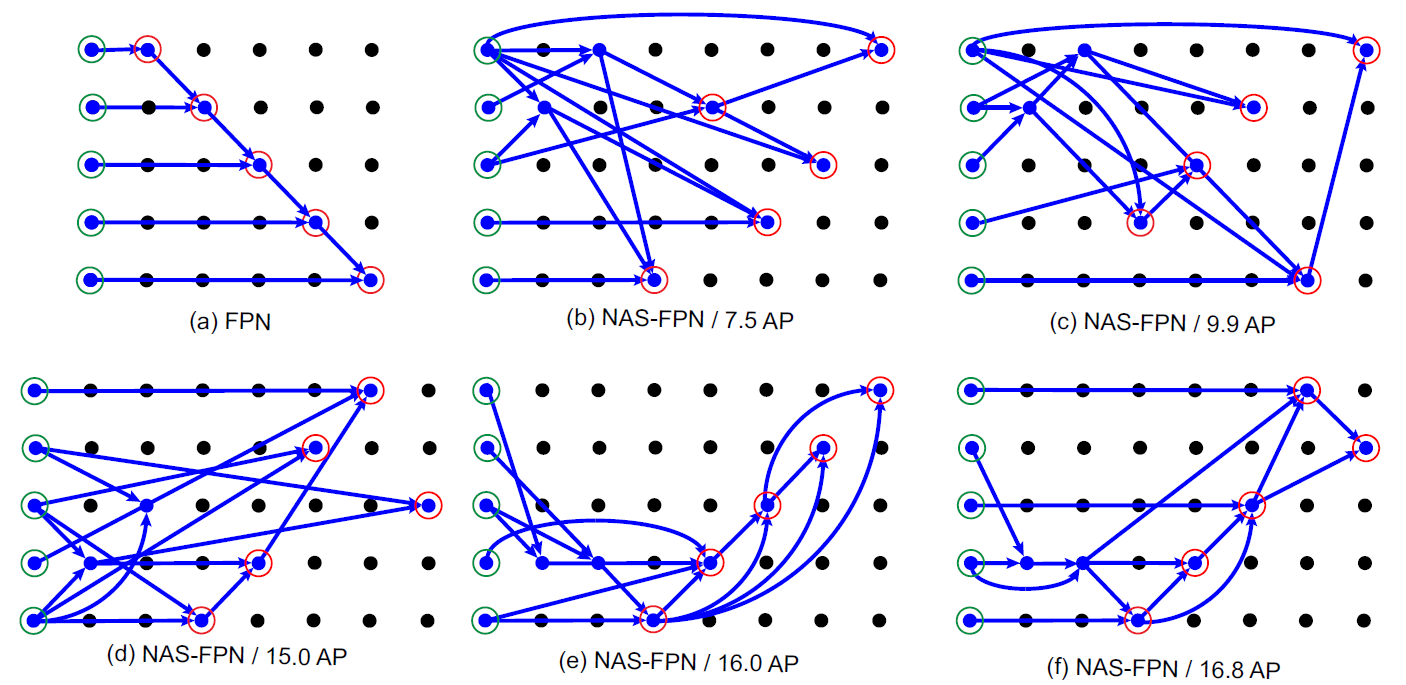
NAS-FPN搜出了一个高效的neck网络,其主要在搜索neck网络中层级间的连接方式,其包括2个任意分辨率的中间节点和5个不同分辨率的输出节点。具体的搜索过程是NAS的范畴了,在NAS-FPN的网络搜索中详细介绍。
下图展示了NAS搜索过程中得到的一些中间结果(b~e)与NAS-FPN的最终结构(f)。可以看出在搜索初期(b),网络就已经发现了Top-down Path,在训练中期(d)又发现了Bottem-up Path。
虽说每个节点只接收两个输入,但是如果有特征图 没有连接至任何中间节点,则会被连接至
没有连接至任何中间节点,则会被连接至 ,因此有些节点会有三个输入,融合方式为先对其它两个节点通过
,因此有些节点会有三个输入,融合方式为先对其它两个节点通过 融合,融合后的节点再和通过
融合,融合后的节点再和通过 融合得到。(如NAS-FPN的
融合得到。(如NAS-FPN的 )
)
非常戏剧性的一点就是,PANet是2018年的论文,NAS-FPN是2019年的论文,但NAS-FPN在一开头提到了PANet但是没有和PANet比而是持续鞭尸FPN。
EfficientDet
论文:EfficientDet
BiFPN
写NAS-FPN的时候也说到了,它明明在Intorduction里提到了PANet但是做实验的时候却不和PANet比,一直在鞭尸FPN。EfficientDet这篇论文把FPN、PANet、NAS-FPN都摆出来一起比较了一下。
作者将PANet(b)简化后(e),提出了一种比PANet更好的neck结构BiFPN,如(f)所示。实际上没多大差别就是把backbone输出的特征又拉了一条到Bottem-up Path上。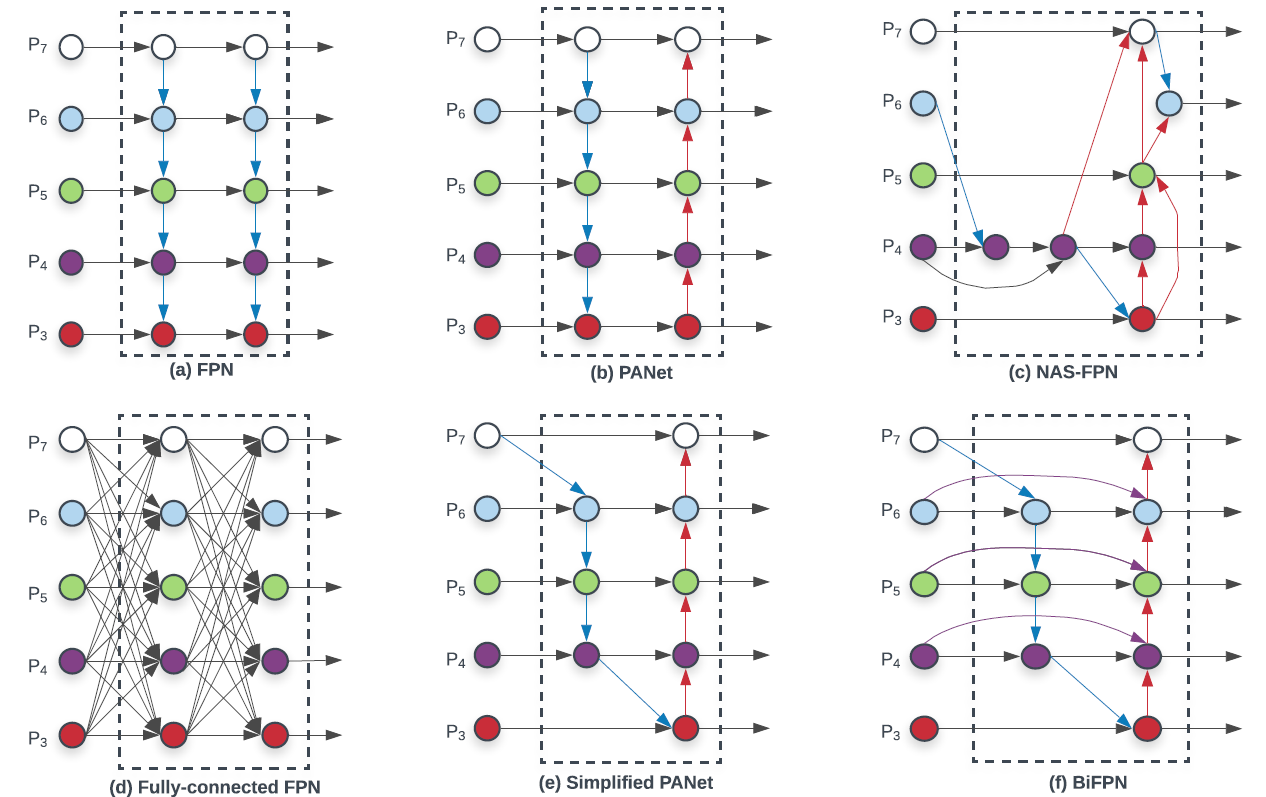
加权特征融合
其实感觉这里提出的Weighted Feature Fusion才算是一个创新点。论文认为不同分支的融合往往不适合用元素级相加进行,因为它们对输出特征图的贡献往往也会不同。为此,作者提出了将每个节点的输入进行加权相加,从原有的 变为了
变为了 ,其中
,其中 可以是一个浮点数(layer-wise),也可以是一个向量用于指导每个通道上的相加权重(channel-wise),也可以是一个权重图(pixel-wise)。作者表示用最简单的浮点数(layer-wise)就能良好地达到目的。
可以是一个浮点数(layer-wise),也可以是一个向量用于指导每个通道上的相加权重(channel-wise),也可以是一个权重图(pixel-wise)。作者表示用最简单的浮点数(layer-wise)就能良好地达到目的。
但简单的加权融合往往会导致模型不稳定,应进行归一化,譬如Softmax:

如此频繁地使用Softmax导致了GPU上地推理速度暴跌30%,因此作者提出了另一种归一化方法:
作者做了实验表示这两种方法的精度区别不大,后者略差(-0.01~-0.11mAP),但是后者速度快得多。
Scale-up
与EfficientNet相似,EfficientDet也是通过多尺度缩放来获得不同容量的高效网络。EfficientNet的缩放尺度包括“输入分辨率、网络深度、网络宽度”,而EfficientDet则通过对“backbone、neck、head”三个组件共同进行了缩放,其缩放尺度包括“输入分辨率、backbone、neck/head宽度、neck深度、head深度”这五个方面。
但是不同于EfficientNet,EfficientDet没有用到任何NAS方法,所有尺度的缩放公式都是作者拍脑袋拍出来的,backbone的缩放更是直接照搬了EfficientNet B0~B6。。。
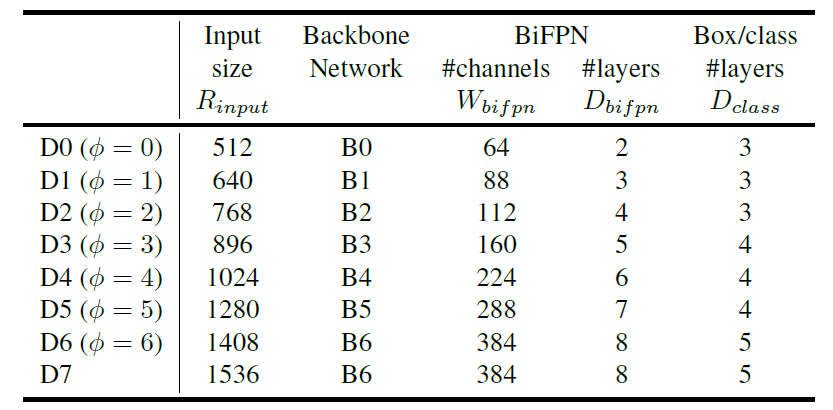
这里的 是缩放因子,这个缩放因子不像EfficientNet里一样代表算力的对数,在这里无任何意义。具体的缩
是缩放因子,这个缩放因子不像EfficientNet里一样代表算力的对数,在这里无任何意义。具体的缩
放公式可以去原论文,实在是没什么新意就不展开讲了。
实验结果
COCO2017实验结果**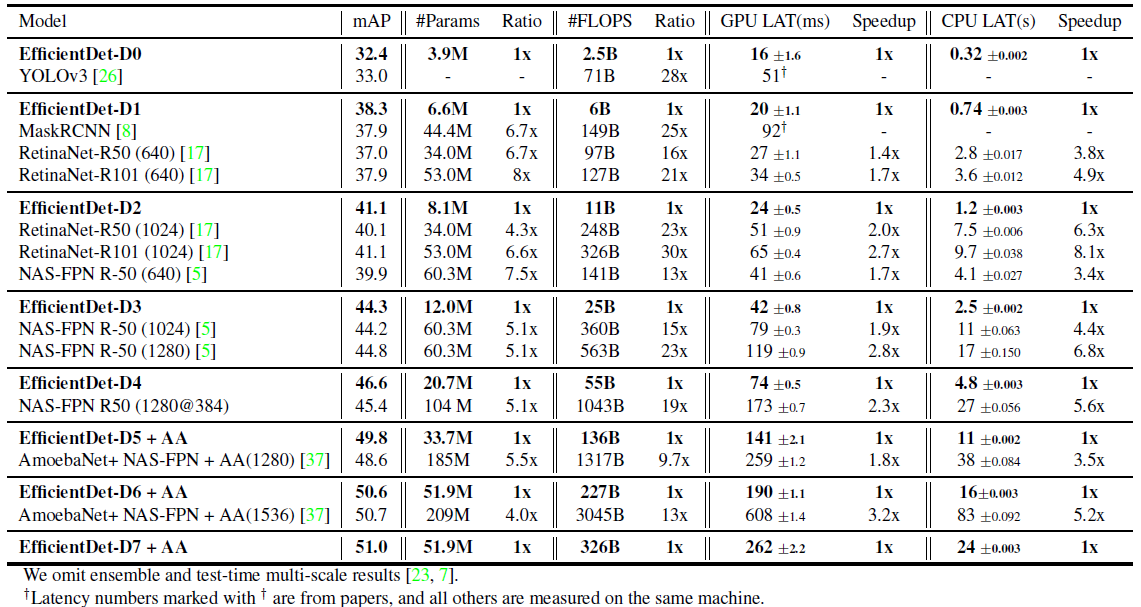
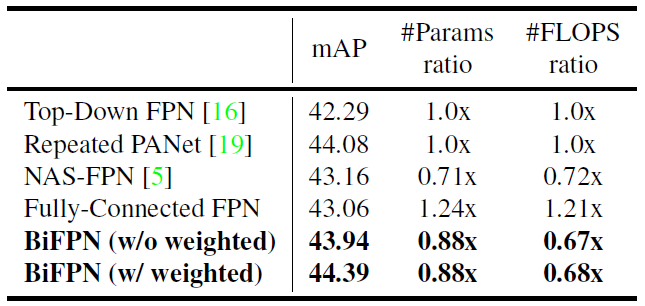
neck网络的对比
作者在固定输入分辨率、backbone、head的情况下,控制变量研究了不同neck网络的影响。其中每个neck网络都被堆叠了5次(neck的网络深度为5)
比较神奇的是在这里PANet吊打了NAS-FPN(这就是NAS-FPN在论文里不和它比的原因么),虽然开销大了点。甚至BiFPN也不如PANet,作者说是因为BiFPN开销小(找理由),加了加权特征融合后才勉强超过PANet。
Scale-up不同尺度的对比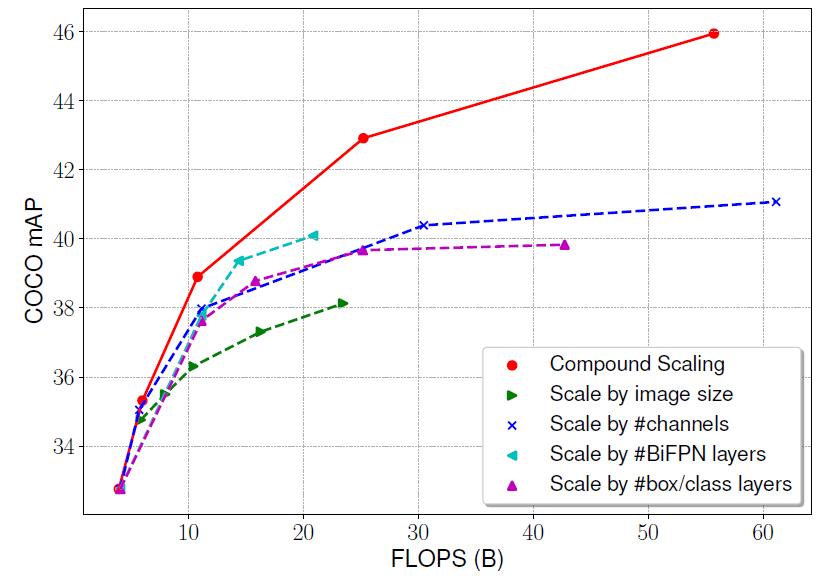
总结
经典的一阶段检测器SSD、经典的二阶段检测器Faster CNN。
FPN提出了Top-down Path的neck,不同于SSD单独利用不同层级的特征图(大的特征图语义信息不足)、Faster RCNN只利用最深层特征图(对小目标检测能力交叉),FPN能帮助检测器良好地利用各层级信息。
RetinaNet是一个和FPN-SSD很像的一阶段检测器,主要改进了检测器的head(以及提出了focal loss)。
Mask RCNN提出了多任务学习,在head中添加了一个分割任务用于辅助检测(以及提出了ROI Align)。
PANet提出了在neck中添加Bottem-up Path,以更好地将backbone中地浅层边缘特征传递至深层。另外还提出了跨层级融合ROI的特征图后送入head。
NAS-FPN通过NAS搜出了一个neck(FPN提出Top-down的neck,PANet加了Bottem-up,我直接搜)。
EfficientDet提出了BiFPN,一个手工设计的neck但比NAS-FPN更强,同时做了scale-up生成了全家桶。
网络初始化
head网络分类器的最后一层的bias不能初始化为0,需要初始化为一定的值(背景概率远大于前景)。RetinaNet论文的4.1节中有讲到这个问题。

若有收获,就点个赞吧
0 人点赞
