2019.12
做完了MNIST想做一个相对来说稍微复杂点的项目,更多的了解一下深度学习项目的过程,包括预处理、图像增强、处理过拟合、调参,等等…
识短浅不知道还有什么稍微复杂点的项目,Imagenet的又太大了,就根据高神的毕设做了个类似的人脸属性分析,高神做过了性别识别和年龄识别我就做了个颜值评分23333
实验平台
用了vgg16_bn网络,因为resnet的论文还没看想先找个简单的网络试试看。vgg16的存储空间非常大,但是绝大部分存储都是用于全连接的,250884096的全连接简直毁天灭地,2508840964=392MB。Pytorch里定义的vgg16_bn和传统的vgg16有些许不同,除了多了BN层,输出部分也从77卷积~4096通道变成了自适应pooling成25088个神经元(自适应pooling就是不管输入的FeatureMap多大都pool成指定大小)。
数据集
使用了SCUT_FBP_v2数据集。
参考论文:SCUT-FBP5500z A Diverse Benchmark Dataset for Multi-Paradigm Facial Beauty Prediction.pdf
然而这篇论文感觉没什么卵用,没有什么技术,只是讲了下60名志愿者的评分分布是怎样的以及他们怎么对这些评分进行了降噪与预处理。
数据集包含了2000亚洲男性、2000亚洲女性、750欧洲男性、750欧洲女性的人脸数据。数据集的优点是图片质量较高(实名diss后来丢给我的那个不知道让谁去爬来的垃圾数据集),并且都裁成350350了。但是数据集非常单一,统统是类似证件照的非常正的正脸图,而且人脸基本均居中并在图片中占有大部分面积。感觉使用这个数据集训出来的模型*鲁棒性可能会比较差。
数据集倒是很好用,所有的图片都在image文件夹下,All_Ratings.xlsx中是lable。那些评分重复性较差的评分者被要求二次评分,All_Ratings中original这列这列记录了他们原来的那次评分数据。
迁移学习
因为自己的数据集很小,这里我们直接使用了vgg16_bn的ImageNet预训练模型,丢弃全连接层部分进行Fine-tune。反正不预训练也试了,结果非常惨。
找预训练模型的话,torchvision.models里已经集成了很多常用分类网络的ImageNet预训练模型了。
model = torchvision.models.vgg16_bn(pretrained=True)
具体的Fine-tune流程参见另一篇博文,以当前项目为例详细讲解了Fine-tune的细节。迁移学习实战
TensorboardX可视化
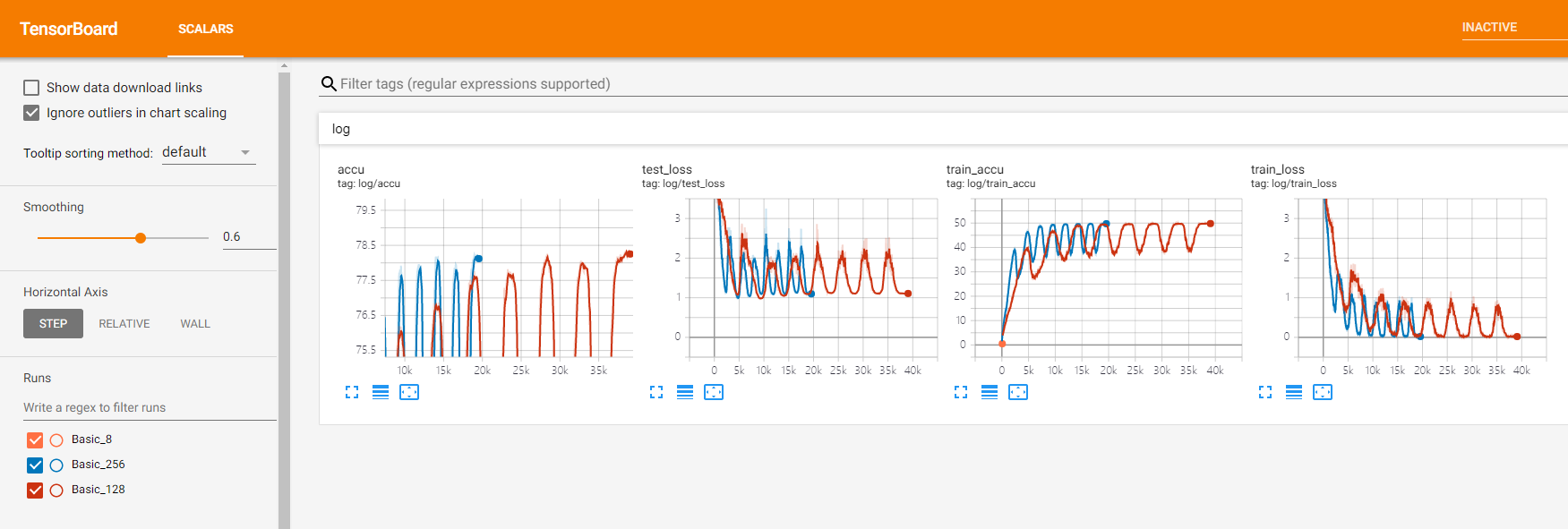
环境配置
tensorboard依赖tensorflow(windows上tensorflow装好就直接有tensorboard了),按以下顺序安装:
pip install tensorflow==1.14.0
pip install tensorboard==1.14.0 (如果还没有的话)
pip install tensorboardx==1.6.0
首先用conda install装会出奇怪的问题,所以用pip。其次不指定版本的话,会自动安最新的tensorflow和
tensorboard都是2.x.x的,实测2.x.x版本用起来爆炸,服务器开启端口后windows端连不上。
pip list | grep tensorboard可以显示tensorboard的版本,把tensorboard换成1.14.0,把tensorboardx换成1.6.0后来竟然奇迹般能用了?!?!更新版本的话,直接用pip install —upgrade tensorboardx==1.6.0这样
还有别的坑:
server端报错unable to get first event timestamp for run。Windows端就UI里一直收不到任何数据。和没写writer.close()没有任何关系!!!后来把版本调成和郑老师一样的就能用了,就是上面给出的版本。
报错Not a TBLoader or TBPlugin subclass:
使用方法:tensorboard —logdir xxx —port xxx(其中logdir是记录的路径,port是通讯端口)
若在服务器上运行了tensorboard,windows端在浏览器里输入类似192.168.50.201:6123即可(6123用定义的port替换);若在windows上运行了tensorboard,则在浏览器里输入类似localhost:6123即可(6123用定义的port替换)。
更新:任意版本的tensorboard、tensorboardx均可!
服务器端跑tensorboard —logdir runs —port 6111命令,Windows端本地浏览器跑192.168.50.201:6111会报错“ERR_CONNECTION_REFUSED”,服务器端需要跑tensorboard —logdir runs —host 192.168.50.201 —port 6111
使用教程
[https://www.jianshu.com/p/46eb3004beca](https://www.jianshu.com/p/46eb3004beca)<br /> [https://blog.csdn.net/qq_31478771/article/details/91047666](https://blog.csdn.net/qq_31478771/article/details/91047666)<br /> 怎么用的话,上面这个博文里倒是已经讲的很详细了。以下是一个世界上最简单的教程
import numpy as npfrom tensorboardX import SummaryWriterwriter = SummaryWriter(logdir) # logdir为log的路径为"./xxx"for epoch in epoch_cnt:#log为一级目录,loss为二级目录,只写一级也行writer.add_scalar('log/x', np.random.rand(), epoch)writer.add_scalars('log/y', {'sin':np.sin(epoch), 'cos':np.cos(epoch)}, epoch)
add_scalar的第一个参数是写文件路径,第二个参数是y值,第三个参数是x值。
add_scalar和add_scalars的区别是后者在一个x坐标上以字典的形式写多个y值。
图像增强与预处理
用了预处理还是能起到很不错的防止过拟合的作用的,train error从0.01+涨到0.04+的同时test error从0.1+降到了0.08+。
torchvision.transforms里已经有很多图像增强的方法了。
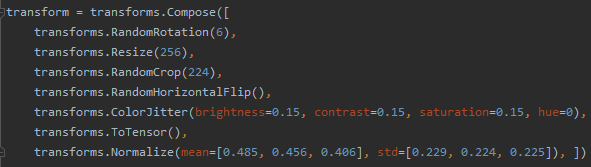
Normalize踩了个大坑!已知输入各通道mean为[0.485,0.456,0.406],std为[0.229,0.224,0.225],Normalize将其归一化为mean=0和std=1,而不是将三个通道归一化为mean=[0.485,0.456,0.406],std=[0.229,0.224,0.225]!
ToTensor/ToPILImage
ToTensor用于image转tensor,它干了以下几件事:
- img.tobytes() 将图片转化成内存中的存储格式
- torch.BytesStorage.frombuffer(img.tobytes())将字节以流形式输入,转化成一维张量
- 对张量进行reshape和transpose(从2242243变成3224224)
- 将当前张量的每个元素除以255
ToPILImage用于tensor转image,它干了以下几件事:
- 将张量的每个元素乘上255
- 将张量的数据类型有FloatTensor转化成Uint8
- 将张量转化成numpy的ndarray类型
- 对ndarray对象做transpose (1, 2, 0)的操作(从3224224变成2242243)
- 利用Image下的fromarray函数,将ndarray对象转化成PILImage形式
由于ToTensor与ToPILImage都是类而不是函数,只能实例化以后使用:
trans = transforms.ToPILImage()img = trans(img) # is ok.img1 = transforms.ToPILImage(img1) # boom boom shakalaka!
空间操作
RandomRotation(n):随机旋转(-n~n)度
Resize(n):更改大小为n*n,注意图像长宽比防止拉伸
RandomCrop(n)/CentorCrop(n):顾名思义,随机裁剪和中心裁剪
RandomHorizontalFlip:随机水平翻转,还有个垂直翻转
色彩抖动
ColorJitter:brightness亮度(0~1),contrast对比度(0~1),saturation饱和度(0~1),hue色调(0~0.5),数字全部表示变换幅度,会在1-x,1+x间变化(色调不一样)
查看预处理后的图片
有的时候不知道这么做了以后图像会被处理成什么样,想输出一下看看。
import numpy as npimport matplotlib.pyplot as pltimport torchvisionimport torchvision.transforms as transformsfrom PIL import Imagetransform = transforms.Compose([xxx,xxx,xxx])transformback = transforms.Compose([transforms.ToPILImage()])img = Image.open('C:\\Users\\LouZhenyu\\Desktop\\Facial\\data\\test3.jpg')img = transform(img)img_pil = transformback(img)plt.imshow(img_pil)plt.show()
更强的图像增强第三方库imgaug(搁置)
[https://github.com/aleju/imgaug](https://github.com/aleju/imgaug)
模型存储与加载
参考:https://www.cnblogs.com/leebxo/p/10920134.html
model.static_dict是一个字典,{‘name’: parameters() }
# 保存模型结构和模型参数torch.save(model, 'model.pth')# 加载模型结构和模型参数model = torch.load('model.pth')# 只保存模型参数torch.save(model.state_dict(), 'model.pth')# 只加载模型参数model.load_state_dict(torch.load('model.pth'))
以下举例,一个被我们自定义加了一个t2p层,更改了分类器部分的结构的vgg16_bn网络的加载操作。
class Net(nn.Module):def __init__(self, img):super(Net, self).__init__()self.t2p = tensor2para(img) # 自己加的一个层self.features = torchvision.models.vgg16_bn().featuresself.avgpool = nn.AvgPool2d(kernel_size=7) # 自己更改的分类器结构self.classifier = nn.Linear(512, 1)model = Net(img)model = torch.load('./vgg16_bn.pth')
以上操作或导致model加载整个vgg16_bn的结构和所有参数,t2p层直接消失了,分类器也变成了原始的vgg16_bn网络中使用的分类器。
def load_model(trained_dict, new):model_dict = new.state_dict()# 只从本地加载那些当前模型有的参数,过滤当前模型没有的参数,比如原始vgg16_bn的分类器部分trained_dict = {k: v for k, v in trained_dict.items() if k in model_dict}model_dict.update(trained_dict)new.load_state_dict(model_dict)model = Net(img)load_model(torch.load('./vgg16_bn.pth').state_dict(), model)
以上操作可以根据我们希望的,只加载feature部分的参数而没有加载分类器部分的参数,同时保留了t2p层。
学习率策略schedule
https://blog.csdn.net/weixin_42662358/article/details/93732852
pytorch里的schedule是一个类,需要实例化,每次通过调用object.step()函数让schedule走一步。可以自己控制是一个epoch一步还是一个step一步这种。
等步长间隔
每多少epoch砍一次学习率。
sch=optim.lr_scheduler.StepLR(optimizer,step_size,gamma=0.1,last_epoch=-1)
例如每50epoch将学习率降低10倍,则有:
sch=optim.lr_scheduler.StepLR(optimizer,step_size=50,gamma=0.1,last_epoch=-1)for epc in range(200)train()sch.step()
非等间隔
在指定的epoch处砍一次学习率。
sch=optim.lr_scheduler.MultiStepLR(optimizer,milestones,gamma=0.1, last_epoch=-1)
例如在100、140、170epoch时将学习率降低10倍,则有:
sch=optim.lr_scheduler.MultiStepLR(optimizer,[100,140,170],gamma=0.1, last_epoch=-1)for epc in range(200)train()sch.step()
自适应学习率
当loss不再下降或者准确度不再提升持续好几个epoch的时候砍一次学习率。
sch=optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.1, patience=10,verbose=False, threshold=1e-4, threshold_mode='rel',cooldown=0, min_lr=0, eps=1e-8)
指数衰减学习率
每个step或者每个epoch都将学习率变为gamma倍。
sch=optim.lr_scheduler.ExponentialLR(optimizer, gamma, last_epoch=-1)
余弦学习率
论文:https://arxiv.org/pdf/1506.01186.pdf
周期性地结合大学习率和小学习率,大学习率帮助跳出局部最优,小学习率帮助收敛。另一个优点是使用余弦学习率训练的模型可调性强——可以在任何一个周期中学习率变化至最小值时停止训练,不像传统砍2刀学习率调控法,不训完没法玩。
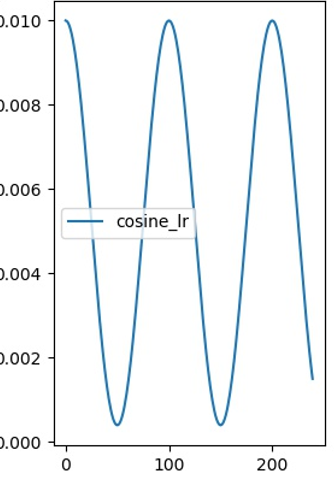
作者建议T_max(半个周期)取2~10epoch,并训练4.5个周期以上。比如dataset=4400,bs=40,一个epoch有110step,那么T_max可以取220~1100step,如果取T_max=220那么就训18、22、26、……个epoch。
还有一种策略叫余弦退火,就是学习率降到最低的时候突变为最大(突变π的相位)
sch=optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max, eta_min=0)
不用于其它schedule在每个epoch结束时调用sch.step(),余弦学习率需要在每个step后调用sch.step()。
有一个坑点是T_max是半个周期的step数,对应π的角度。郑老师说现在很多用的时候会用warm_up,刚开始训的时候从小学习率逐渐递增到最大学习率效果会更好。我魔改的时候直接把cos的角度加上π让它从最小学习率开始。
譬如指定周期为12epoch,训练8轮半,学习率在0.001~0.1间周期变化:
optimizer = optim.SGD(model.parameters(), lr=0.1, weight_decay=0.0001, momentum=0.9)sch=optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=6*len(train_loader), eta_min=0.001)def train():for idx, (data, target) in enumerate(train_loader):do_something()sch.step()for epc in range(100):train()
暴力自定义学习率
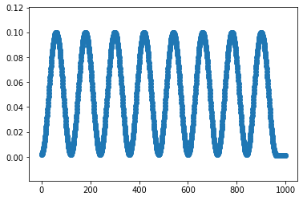
例:以周期为12epoch(T_max=6)的余弦学习率训练,且从余弦学习率最小处开始训练(相位变了π),总共训练8轮共96epoch,此后采用最小学习率持续训练4epoch直至结束。
def adjust_lr(opt):T_max = 6cycles = 8if global_step < (T_max*2) * cycles * len(train_loader):max_learning_rate = learning_ratemin_learning_rate = learning_rate / 100.0step = global_stepTmax = T_max * len(train_loader)amp = (max_learning_rate - min_learning_rate) / 2offset = (max_learning_rate + min_learning_rate) / 2lr = amp * math.cos((step / Tmax + 1) * 3.141592653589) + offsetelse:lr = learning_rate / 100.0for param_group in opt.param_groups:param_group['lr'] = lrdef train():for idx, (data, target) in enumerate(train_loader):adjust_lr(opt)do_something()for epc in range(100):train()
以上学习率调控策略下的<学习率,step>图:
回归任务转分类任务
因为最开始对回归任务的印象是不好做,有的时候也会把回归任务转成分类任务做,所以也想尝试一下在当前任务下转成分类任务做会怎么样。有两种方案:
- 独热码lable
和高神的毕设处理人脸年龄识别一样,划分区间用独热码编码,在我们这儿就是1-1.5分一档,一直到4.5-5分,总共8档,然后直接当分类问题,用one-hot码作为label进行训练。模型的全连接层的输出宽度为8。
依概率分布的lable
label为各个评分的概率,比如对于一个lable为的样例,就代表对这个样例评1分的人有0%,2分的有10%,3分的有20%,4分的有60%,5分的有10%,综合评分为3.6分。模型的全连接层输出宽度为5。训练时,label为数据集中得到的各个评分概率,用smooth交叉熵作loss(类似于知识蒸馏训练过程中的loss计算)。<br />想到这种方法是因为感觉,直接拉平均做回归会丢失一部分信息(评分的分布情况),用这种方法做的可能还能知道一张脸的颜值争议大不大这种???(看评分方差)好了我又开始xjr想了……<br />
训练细节
使用ImageNet预训练的MobileNet v2网络进行Fine-tune,bs=128,SGD(mometum=0.9),共训练200epoch,初始学习率0.064,在140、185epoch时砍学习率。
两种方法在各自训练时采用不同的loss计算方法,但是在测试时全部统一用mse计算loss。实验结果就是,还是回归最好,第二种分类的方案还过得去,第一种差爆。参见runs1/Base0.064rsz224p16、Classify_pd0.064、Classify1_onehot_pd0.064。
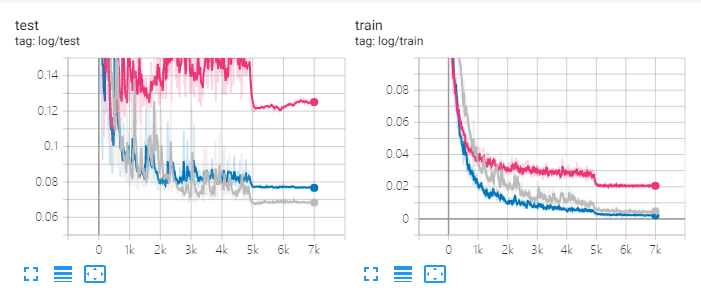
另外由于初始学习率0.064的时候初期震荡,试了下减小学习率到0.04,结果震荡缓了很多但最终效果更差;由于分类与回归相比test loss高了但train loss低了,考虑是不是有过拟合现象,将weigh decay从1e-4加到5e-4,并且全连接层dropout从0.2提到0.5,结果差不多。
异想天开的美颜系统
以下纯属我的异想天开,如有巧合纯属雷同
- 训练一个模型用于预测颜值
- 固定这个模型的所有参数,喂入一张图片
- 把满分5.0分作为lable,和模型的输出取L2 loss,反传梯度时不更新模型参数而更新输入的图片
之后会说,实验结果证明这纯属我YY,但还是把这个过程记下来吧。
候哥说我做的这个有点像生成对抗网络(GAN),以后接触到了可以看一下这方面。这里有个用生成对抗网络做的:AI高颜值人脸生成器,不过和美颜好像也不是一回事。
T2P层
我们需要一个层,将输入tensor转为parameter,因为只有parameter会计算梯度可以训练。
根据郑老师的指导,自己写了一个层tensor2para,这个层只获取输入图片的tensor,并把图片的tensor恒等赋值给一个parameters(parameters就是带梯度的tensor,层里的weight、bias什么的都是parameters类的),然后定义optimizer的时候,需要训练的参数只传model.tensor2para.parameters()。由于我们需要让梯度回传,不能通过其它层requires_grad=False来禁止其它层的训练。
class tensor2para(nn.Module):def __init__(self, img):super(tensor2para, self).__init__()self.x_para = nn.parameter.Parameter(img)def forward(self):return self.x_paraclass Net(nn.Module):def __init__(self, img):super(Net, self).__init__()self.t2p = tensor2para(img)self.features = torchvision.models.vgg16().featuresself.avgpool = nn.AvgPool2d(kernel_size=7)self.classifier = nn.Linear(512, 1)def forward(self, res):res = self.t2p()res = self.features(res)res = self.avgpool(res)res = res.view(res.size(0), -1)res = self.classifier(res)return res
加载模型的时候需要注意之前<模型加载与存储>一节中讲到的坑。
BN该怎么办啊
这里碰到一个问题,“美颜”进行时batch_size为1,BN计算出来的batch的mean和var是非常不好的,起不到正则化和让数据同分布的作用。BN只对batch_size约10以上的时候才能发挥作用!但又不能直接model.eval()假装自己在预测直接用预训练阶段的running_mean与running_var,那样pytorch就不对整个模型计算梯度了,无法对输入图片进行训练。
使用其它归一化层或者魔改BN层训练的时候也用running_mean和running_var替代batch的mean和var会怎样?反正我只训输入不训γ和β应该也不要紧?这个没试,最后还是屈服于现实用了不带BN的vgg16。
看结果了看结果了
查看训练前和训练后的图:
img = Image.open(os.path.join('./data', 'test.jpg')).convert('RGB')img = transform(img)img = img.unsqueeze(0) # 用于训练,batchsize强行为1model = Net(img)load_model(torch.load('model_noBN_744.pth').state_dict(), model)model = model.cuda()optimizer = optim.SGD(model.t2p.parameters(), lr=learning_rate) # 只传t2p的参数def Train(epoch):target = torch.Tensor([[1.6]])output = model(img)optimizer.zero_grad()loss = F.mse_loss(output.cuda(), target.cuda())if epoch % 10 == 0:print('Train Epoch: {}\tOutput = {:.4f}'.format(epoch, output.item() * 1.25 + 3.0))loss.backward()optimizer.step()if __name__ == '__main__':tran = transforms.ToPILImage()orig = img.squeeze(0) * torch.Tensor([0.229, 0.224, 0.225]).unsqueeze(1).unsqueeze(2)\+ torch.Tensor([0.485, 0.456, 0.406]).unsqueeze(1).unsqueeze(2)orig = tran(orig)plt.figure() # 用于同时显示多个窗口多张图plt.imshow(img_pil)for epoch in range(200):Train(epoch)img = model.t2p.x_para.data.cpu()img = img.squeeze(0) * torch.Tensor([0.229, 0.224, 0.225]).unsqueeze(1).unsqueeze(2)\+ torch.Tensor([0.485, 0.456, 0.406]).unsqueeze(1).unsqueeze(2)print(img * 255)img = tran(img.squeeze(0))plt.figure()plt.imshow(img_pil1)plt.show() # 要把plt.show()写在最后一个imshow后
接下来就是见证奇迹的时刻: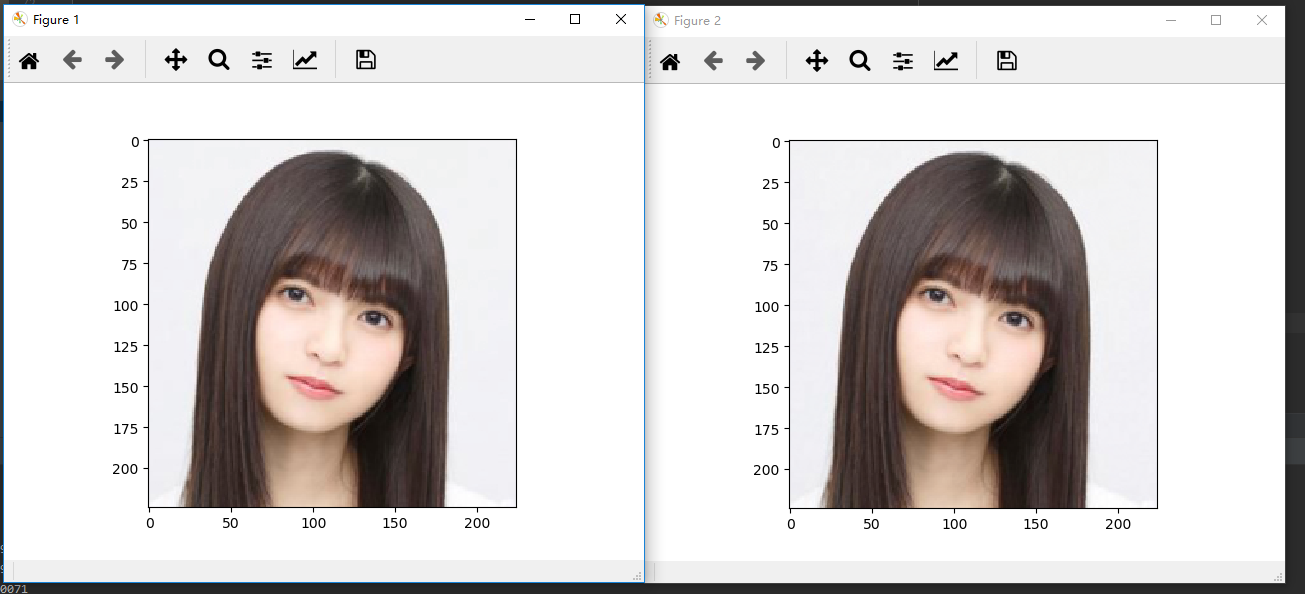
什么鬼啊咋回事啊怎么两边一模一样啊!可是颜值评分模型给出的左边4.2分右边5.0分啊!我不管一定是Asuka小姐姐本来就很好看了不需要美颜了!
** 

所以咋回事啊那你能帮帮我嘛
好了,口嗨完了让我们冷静下来看看这是为什么。
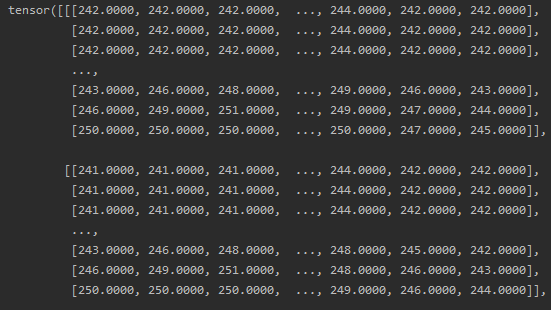
这是训练之前的图像
这是训练之后的图像
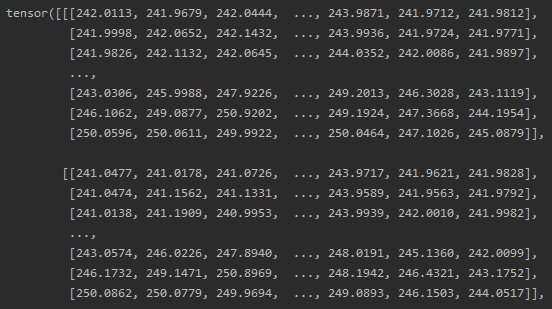
根本没差啊量化以后就跟没训一样好不好!!!!就这个结果来看应该是钻了模型的空子过拟合了,这些细小的变化导致了模型评分的剧变。。。
好了虽然这个东西做失败了但是我尝试过了2333333下一个。。。
骂人时刻
垃圾Windows的垃圾任务管理器
Windows端,GPU负载别看任务管理器,任务管理器里显示的GPU负载是个哈皮,GPU-Z的是准的。这导致刚开始我以为GPU根本没动以为CUDA没启用一直在用CPU跑。
垃圾num_workers
碰到一个问题,Dataloader里的num_workers搞不懂是什么个原理,按理来说0对应禁用多进程,但是开成0的话CPU会占满,开1就不会。另外num_worker开大以后CPU占用率不会变高但是显存占用会变大(速度没测)不知道为什么,也没时间研究这个问题就先不管了。
垃圾GTX970
碰到的神奇的Loss=nan与Loss=inf的情况?有的时候Loss一直是nan有的时候Loss突然变inf了后来又奇迹般的好了?问了小磊师兄和郑老师,依然没得出答案,换了smoothL1 loss,不知道会怎么样,暂时甩锅给显卡和显卡驱动。
好了石锤了就是GTX970太垃圾,服务器上跑一点事情都没。要是我也有一车Tesla V100多好,当然2080ti也行,深度学习学放弃了还能用来打游戏。
汇入自找2000张数据集的后续处理
林总给我的是4个500张的数据集,但听说找的是同一群人标注的,4个数据集的图片互相之间也差距不是特别大,不像SCUT数据集和这2000张一样差距非常巨大。
首先用在SCUT-5500数据集上训出来的MobileNet v2(test loss=0.067)在这2000张上跑了一次test,测出来mse=0.78,我的妈呀直接亲妈爆炸了。
数据清洗
一来是标注做的真的不怎么样,也不知道怎么标的,不过只给了我这样的数据集也没办法,凑合用呗;二来是给SCUT-5500标注的人和给这2000张标注的人不是同一群人,评分的数据域不同。因此用之前必须对这2000张的标注做一下数据清洗。
想到的最简单的办法就是用 这样的简单线性函数处理标注的评分,懒得搞最小二乘法,直接固定了model,训k和b:(k用1初始化,b用0初始化)
这样的简单线性函数处理标注的评分,懒得搞最小二乘法,直接固定了model,训k和b:(k用1初始化,b用0初始化)
norm = nn.Linear(1, 1, bias=True).cuda()nn.init.constant_(norm.weight, 1.0)nn.init.constant_(norm.bias, -0.0)# 注意optimizer优化的对象是norm这个层而不是model,L2正则化需要定为0optimizer = optim.SGD(norm.parameters(), lr=learning_rate, weight_decay=0.0, momentum=0.0)def clip(x, minVal=1.0, maxVal=5.0):x = (x >= minVal).float() * x + (x < minVal).float() * minValx = (x <= maxVal).float() * x + (x > maxVal).float() * maxValreturn xdef train(epoch):model.eval()for data, target in loader:optimizer.zero_grad()output = model(data.cuda())target = norm(target.cuda()) # 这两行是关键target = clip(target) - 3.0 # 放缩后进行裁剪,防止label溢出数据域loss = F.mse_loss(output.cuda(), target.cuda())loss.backward()optimizer.step()norm.eval()test_loss = test()norm.train()
结果训出来4个数据集标注的 和
和 都差不多:
都差不多:
| 数据集1 | y=0.815x-0.038 |
|---|---|
| 数据集2 | y=0.819x-0.049 |
| 数据集3 | y=0.826x-0.045 |
| 数据集4 | y=0.83x-0.04 |
综合一下,选择了y=0.823x-0.042用于对四个数据集的label进行集中清洗。清洗完以后再用SCUT训的模型跑test,可以发现mse loss从之前的0.78下降到了0.166,属于正常范围,可以训练了。
如何用这2000张图的数据集呢
想到了两个方法:
- 在SCUT预训练的模型上做finetune,类似于平时我们用ImageNet预训练的模型finetune一样,这里SCUT的数据集相对更大且标注质量更高。但是缺点是SCUT的人脸图片过于简单(单色背景正面证件照),其预训练模型鲁棒性较差。
- 将这2000张混入SCUT数据集形成一个7500张的新数据集,从头训练。
其中方法(1)可以在自找数据集中可以将mse训到0.0565,但是此时SCUT的mse已经爆炸到了0.288。用其它数据集进行测试时,这时候训练得到的模型非常保守,打分基本只会打2.5~3.5。这感觉看起来还是因为数据集太小,类型与场景不够多。
方法(2)训的挺不错的,能够在总的数据集上获得0.0691的mse,和之前只在SCUT上训出来的0.0667差不多,可以认为新加入的数据能够使得模型的鲁棒性增强。
noise label
这是我自己想出来的一种类似分类网络中smooth label的方法,也能算一种正则化手段。想法非常简单,在原始的[1.0, 5.0]区间内的评分label上加上一个均值为0、方差为0.1的随机高斯噪声作为真正用于训练的label。
用noise label前后,test loss从0.0691下降到了0.0649;train loss从0.006左右上升到了0.015左右(虽然加了噪声本来train loss就会上升)
训练阶段裁剪模型输出?
因为评分的数据范围被限制在[1.0, 5.0]区间,如果在训练阶段将模型的输出截断到这个区间中再计算loss,是否可以使得训练过程有所不同呢?
想到了两个方法:
- Hard Clip,直接1.0分和5.0分处两刀截断,实测loss劣化至0.0722,猜测截断导致梯度消失引起了训练问题。
- Sigmoid Clip,将y=4*Sigmoid(x)+1作为模型的输出,实测loss劣化至0.0693。
↑↑↑↑↑说人话就是没用

若有收获,就点个赞吧
0 人点赞
