字符编码
ascii
ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,其最多只能用8位来表示(一个字节),即:2**8 = 256-1,所以ASCII码最多只能表示255个字符。
中文
ASCII、GB2312、GBK、GB18030,这些编码方法是向下兼容的,即同一个字符在这些方案中总是有相同的编码,后面的标准支持更多的字符。
GB2312、BGK、GB18030都是占两个字节
gb2312(1980年)
一共收录了7445个字符,包括6763个汉字和682个其他符号
gbk1.0(1995年)
收录了21886个字符,包括21003个汉字
gb18030(2000年)
收录了27484个汉字,还收录了藏文、蒙文、维吾尔文等主要的少数民族文字。现在PC平台必须支持GB18030,嵌入式产品不作要求
unicode
Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了同一并且唯一的二进制编码,规定所有的字符和符号最少有16位来表示(2个字节)
UTF-8
是对Unicode编码的压缩和优化,不再使用最少2个字节,而是将所有的字符和符号进行分类:ASCII中的内容用1个字节保存,欧洲的字符用2个字节保存,东亚的字符用3个字节保存…
二进制
8bits = 1Byte
1024 Bytes = 1KB
1024KB = 1MB
1024MB = 1GB
1024GB = 1TB
1024TB = 1PB
注释
# 这是单行注释'''多行注释(变成字符串)同时也是一个字符串可将它赋值给变量'''"""多行注释(变成字符串)与'''''' 单引号相同"""
循环
for 循环
for i in range(5):print(i)else:# 正常执行完的循环,将执行else中代码print('end')# 输出01234endfor i in range(5):if i > 3:breakprint(i)else:# break 跳出的不执行else中内容print('end')# 输出结果0123
continue
跳过本次循环
for i in range(10):if i % 2 == 0:continueprint(i)# 输出结果13579
break
跳出本层循环
for i in range(10):if i > 5:break;print(i)# 输出结果012345
while
while True:print('这是一个死循环')count = 0while count <5:print(count)count += 1else:# 正常执行完循环,将执行此次代码;print("end")# 输出结果01234end
运算符
算数运算
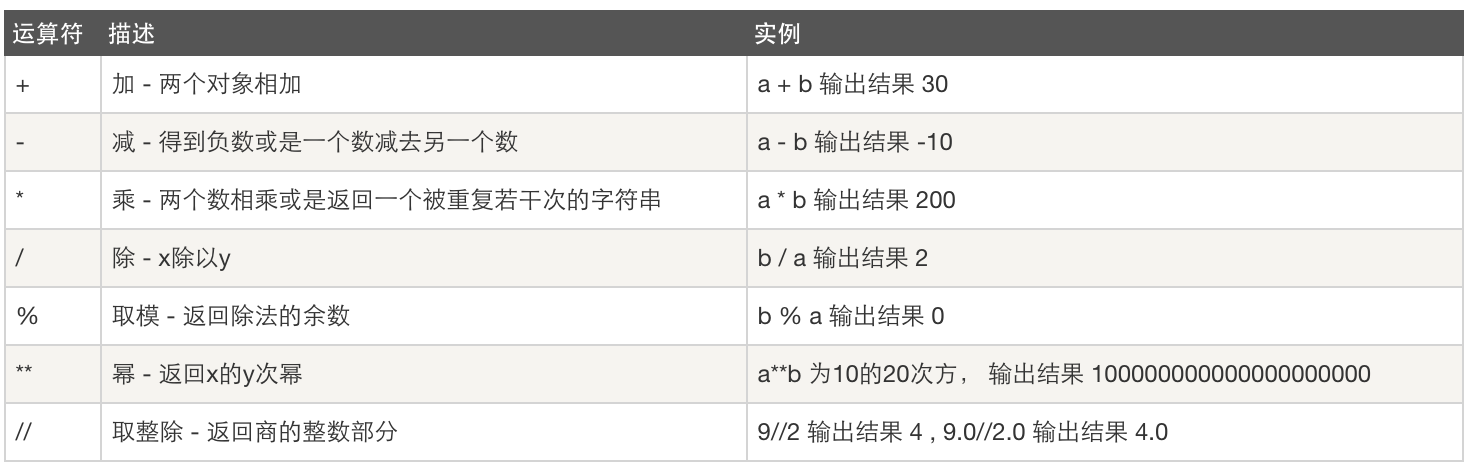
比较运算

赋值运算

逻辑运算

成员运算

身份运算

位运算
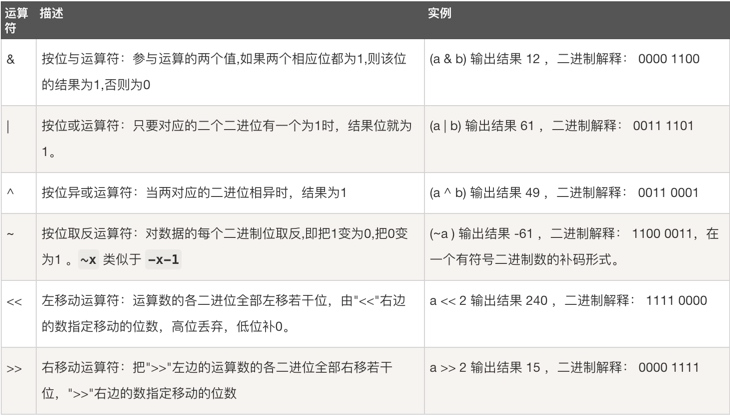
运算优先级
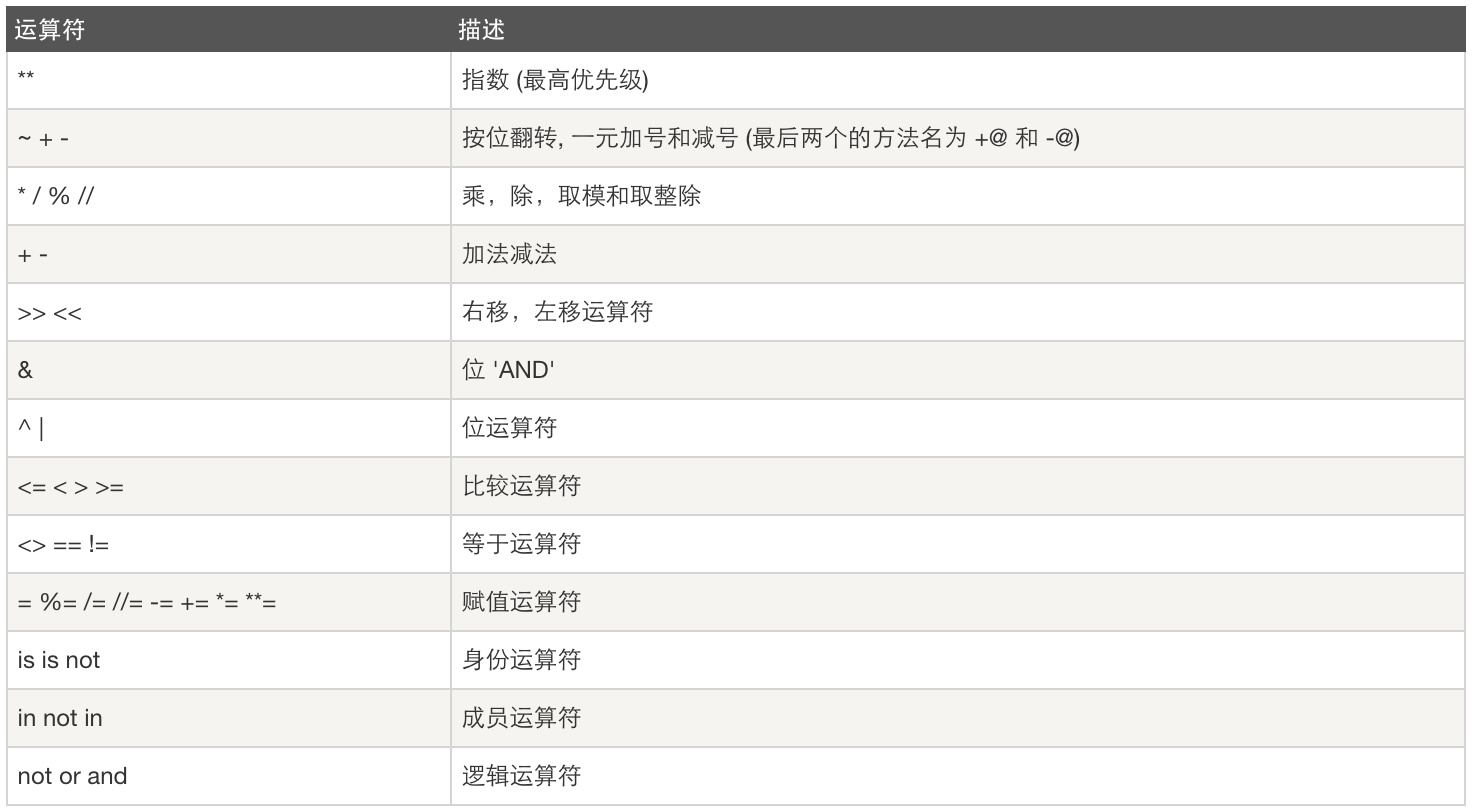
三元运算
值1 if 表达式 else 值2
表达式==True 值 = 值1 否则 值 = 值2
a = 10b = 20x = a if a>b else bprint(x) # 20

若有收获,就点个赞吧
0 人点赞
