参考文章:https://www.zhihu.com/question/39859266
在关注hbase的适用场景之前,先了解一下hbase的特性。
简介
HBase(Hadoop database)是一个分布式、可扩展、面向列的 NoSQL 数据库,本质上是一个 Key-Value 系统,底层存储基于 HDFS,原生支持 MapReduce 计算框架,具有高吞吐、低延时的读写特点。
- 容量大: Hbase单表可以有百亿行、百万列,数据矩阵横向和纵向两个维度所支持的数据量级都非常具有弹性。
- 多版本:Hbase的每一个列的数据存储有多个Version,比如住址列,可能有多个变更,所以该列可以有多个version
- 高可靠性:WAL机制,保证数据写入的时候不会因为集群异常而导致写入数据丢失。Replication机制,保证了在集群出现严重的问题时候,数据不会发生丢失或者损坏。Hbase底层使用HDFS,本身也有备份。
- 拓展性:底层依赖HDFS,当磁盘空间不足的时候,只需要动态增加datanode节点服务(机器)就可以
- 高性能:底层的LSM数据结构和RowKey有序排列等架构上的独特设计,使得Hbase写入性能非常高。
Region切分、主键索引、缓存机制使得Hbase在海量数据下具备一定的随机读取性能,该性能针对Rowkey的查询能够到达毫秒级别。
LSM树,树形结构,最末端的子节点是以内存的方式进行存储的,内存中的小树会flush到磁盘中(当子节点达到一定阈值以后,会放到磁盘中,且存入的过程会进行实时merge成一个主节点,然后磁盘中的树定期会做merge操作,合并成一棵大树,以优化读性能。) - 稀疏存储:为空的列并不占用存储空间,表可以设计的非常稀疏。不必像关系型数据库那样需要预先知道所有列名然后再进行null填充
- 强一致性读写:HBase并不是最终一致性,而是强一致性的系统,这使得HBase非常适合做高速的聚合操作。
- 自动sharding:HBase的表在水平方向上以region为单位分布式存储在各个节点上,当region达到一定大小时,就会自动split重新分布数据。
- 自动故障转移:这是HBase高可用的体现,当某一个节点故障下线时,节点上的region也会下线并会自动转移到状态良好的节点上线。 面向列的存储和权限控制,并支持独立检索,可以动态增加列,即,可单独对列进行各方面的操作。列式(列族)存储,其数据在表中是按照某列存储的,这样在查询只需要少数几个字段的时候,能大大减少读取的数量。
- 面向列的存储:HBase是面向列的存储系统,相同特征(列族相同)的数据会被尽量放到一起,这有利于提高数据读取的效率。
- 无缝结合Hadoop:HBase被定义为Hadoop database,就是基于HDFS做的数据存储,同时原生的支持MapReduce计算引擎。
- 非常友好的API操作:HBase提供了简单易用的Java API,并且提供了Thrift与REST的API供非Java环境使用。
- Block Cache与Bloom Filter:查询优化方面HBase支持Block Cache与Bloom Filter,使得HBase能够对海量数据做高效查询。
什么时候使用 HBase
HBase作为一款NoSQL数据库,并不能解决所有问题。关于我们在实际生产过程中满足哪些条件的时候可以选择HBase作为底层存储,这里给出几点建议:
- 数据量规模非常庞大
一般而言,单表数据量如果只有百万级或者更少,不是非常建议使用HBase而应该考虑关系型数据库是否能够满足需求;单表数据量超过千万或者十亿百亿的时候,并且伴有较高并发,可以考虑使用HBase。这主要是充分利用分布式存储系统的优势,如果数据量比较小,单个节点就能有效存储的话则其他节点的资源就会存在浪费。 - 要求是实时的点查询
HBase是一个Key-Value数据库,默认对Rowkey即行键做了索引优化,所以即使数据量非常庞大,根据行键的查询效率依然会很高,这使得HBase非常适合根据行键做单条记录的查询。值得说明的是,允许根据行键的一部分做范围查询,这里涉及到Rowkey的设计问题,不再赘言。百亿行 x 百万列,在百毫秒以内 - 能够容忍NoSQL短板
前面提及了NoSQL并不能解决所有问题,HBase也是一样,如果业务场景是需要事务支持、复杂的关联查询等,不建议使用HBase。HBase有它适合的业务场景,我们不能苛求它能够帮我们解决所有问题。 - 数据分析需求并不多
虽然说HBase是一个面向列的数据库,但它有别于真正的列式存储系统比如Parquet、Kudu等,再加上自身存储架构的设计,使得HBase并不擅长做数据分析,或者说数据分析是HBase的弱项,所以如果主要的业务需求就是为了做数据分析,比如做报表,那么不建议直接使用HBase。 - 面向列,容量大,写入比mysql快但是读取没有,超过五百万条数据的话建议读写用Hbase
适用场景
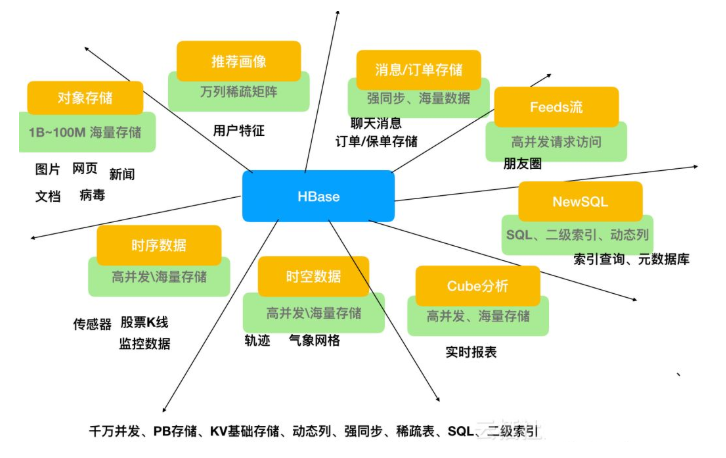
- 对象存储:我们知道不少的头条类、新闻类的的新闻、网页、图片存储在HBase之中,一些病毒公司的病毒库也是存储在HBase之中
- 时序数据:HBase之上有OpenTSDB模块,可以满足时序类场景的需求
- 推荐画像:特别是用户的画像,是一个比较大的稀疏矩阵,蚂蚁的风控就是构建在HBase之上
- 时空数据:主要是轨迹、气象网格之类,滴滴打车的轨迹数据主要存在HBase之中,另外在技术所有大一点的数据量的车联网企业,数据都是存在HBase之中
- CubeDB OLAP:Kylin一个cube分析工具,底层的数据就是存储在HBase之中,不少客户自己基于离线计算构建cube存储在hbase之中,满足在线报表查询的需求
- 消息/订单:在电信领域、银行领域,不少的订单查询底层的存储,另外不少通信、消息同步的应用构建在HBase之上
- Feeds流:典型的应用就是xx朋友圈类似的应用
- NewSQL:之上有Phoenix的插件,可以满足二级索引、SQL的需求,对接传统数据需要SQL非事务的需求
企业实践
网易HBase实践 https://blog.csdn.net/wwd0501/article/details/106337526
HBase in Practise: 性能、监控和问题排查 https://blog.csdn.net/chunbiao0001/article/details/100819640
HBase在风控系统应用和高可用实践 https://cloud.tencent.com/developer/news/322222
上海久耶基于 HBase 实时数仓探索实践 https://www.infoq.cn/article/L6yfEtYlMNAl5p_DmDgL
携程HBase实践 https://blog.51cto.com/u_15060460/2677389
rowKey与索引设计:技巧与案例分析 https://blog.csdn.net/b6ecl1k7BS8O/article/details/82754169
有赞的HBase平台实践和应用之路 https://www.pianshen.com/article/9700393929/

若有收获,就点个赞吧
0 人点赞
