一、hbase-是不是列式存储?
在介绍 HBase 是不是列式存储数据库之前,我们先来了解一下什么是行式数据库和列式数据库。
行式数据库和列式数据库
在维基百科里面,对行式数据库和列式数据库的定义为:
列式数据库是以列相关存储架构进行数据存储的数据库,主要适合于批量数据处理(OLAP)和即时查询。相对应的是行式数据库,数据以行相关的存储体系架构进行空间分配,主要适合于小批量的数据处理,常用于联机事务型数据处理(OLTP)。
比如以下的表格: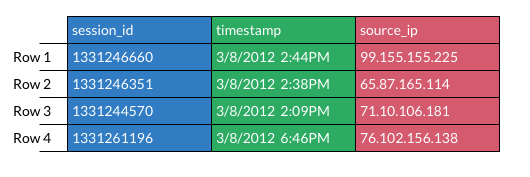

那么行式数据库和列式数据库存储模型分别如上面的左图和右图。可以看到,行式数据一行的数据是在相邻位置存储的;而列式数据相同列是相邻存储的,比如上面的 session_id 这列是放在一起存储的。
HBase 是列式数据库吗
现在我们已经了解了行式数据库和列式数据库的存储格式的简单区别了。那么进入正文,我们来看下 HBase 是不是列式数据库。很多地方介绍 HBase 有这么一句话:HBase is a column-oriented database management system that runs on top of Hadoop Distributed File System (HDFS)。注意里面的 column-oriented 一词,很多资料或者初学者都把它翻译成列式,这句话就中文翻译就变成 HBase 是运行在 HDFS 之上的列式数据库管理系统。那么 HBase 到底是不是列式存储呢?其实 HBase 不是列式存储数据库!本文就从底层存储模式来解释这个。
不管是存储在内存的 MemStore,还是存储在 HDFS 上的 HFile,其都是基于 LSM(Log-Structured Merge-Tree)结构存储的。下图有助于我们简单理解 MemStore 和 HFile 是怎么存储数据的,假设我们有以下一张 HBase 表。
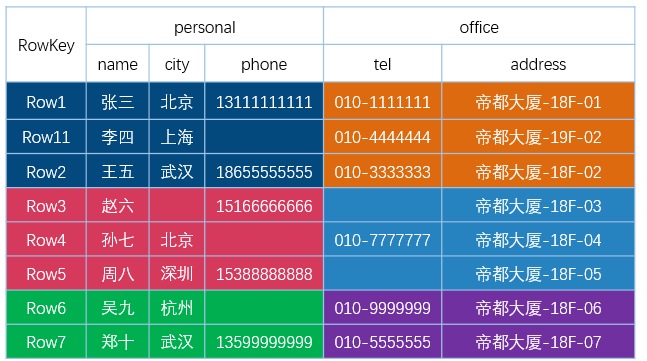
那么,HBase 底层的 KV 存储大概如下所示的: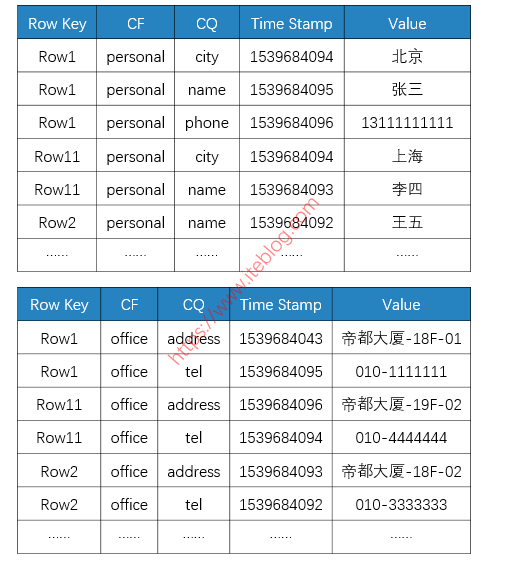
从上图可以看出:
- 不同的列族存在不同的文件中(上面两个表格代表不同的 HFile);
- 整个数据是按照 Rowkey 进行字典排序的;
- 每一列数据在底层 HFile 中是以 KV 形式存储的;
- 相同的一行数据中,如果列族也一样,那么这些数据是顺序放在一起的。
到这里大家应该可以看到,HBase 其实不是列式数据库,因为同一行数据,如果列族也一样,这些数据是存储在相邻位置的;这和上面的列式存储不太一样。所以说,HBase 既不像行式存储,又不像列式存储。它其实更像是面向列族的存储数据库,因为不同行相同的列族数据是相邻存储的;而同一行不同列族的数据是存储在不同位置的。
所以 HBase is a column-oriented database management system that runs on top of Hadoop Distributed File System (HDFS) 这句话应该翻译成 HBase 是运行在 HDFS 之上的面向列的数据库管理系统。
二、为什么不建议在hbase中使用过多的列簇
我们知道,hbase表可以设置一个至多个列簇(column families),但是为什么说越少的列簇越好呢?
官网原文:
HBase currently does not do well with anything above two or three column families so keep the number of column families in your schema low. Currently, flushing and compactions are done on a per Region basis so if one column family is carrying the bulk of the data bringing on flushes, the adjacent families will also be flushed even though the amount of data they carry is small. When many column families exist the flushing and compaction interaction can make for a bunch of needless i/o (To be addressed by changing flushing and compaction to work on a per column family basis).
回顾下hbase表,每张表会切分为多个region,每个region也就是表的一部分子集数据,region会分散到hbase 集群regionserver上;
region中每个columnFamily的数据组成一个Store。每个Store由一个Memstore和多个HFile组成(一个列簇对应一个memstore和N个HFile); 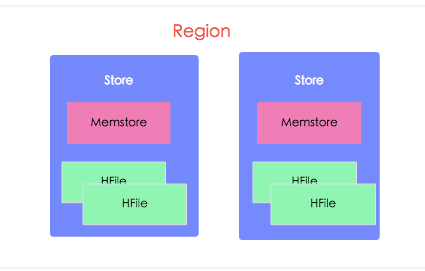
在达到flush条件时候,每个memstore都会flush生成一个HFile文件;另外随着HFile文件的生成,后台minorCompact线程会触发合并HFile文件;
重点:flush和compact都是在region的基础上进行的
比如在flush时候,如果有多个memstore(多个列簇),只要有一个memstore达到flush条件,其他的memstore即使数据很小也要跟着执行flush,这也就导致了很多不必要的I/O开销。触发flush的条件如下:
- Memstore级别限制:当Region中任意一个MemStore的大小达到了上限(hbase.hregion.memstore.flush.size,默认128MB),会触发Memstore刷新。
- Region级别限制:当Region中所有Memstore的大小总和达到了上限(hbase.hregion.memstore.block.multiplier hbase.hregion.memstore.flush.size,默认 2 128M = 256M),会触发memstore刷新。
- Region Server级别限制:当一个Region Server中所有Memstore的大小总和达到了上限(hbase.regionserver.global.memstore.upperLimit * hbase_heapsize,默认 40%的JVM内存使用量),会触发部分Memstore刷新。Flush顺序是按照Memstore由大到小执行,先Flush Memstore最大的Region,再执行次大的,直至总体Memstore内存使用量低于阈值(hbase.regionserver.global.memstore.lowerLimit * hbase_heapsize,默认 38%的JVM内存使用量)。
- 当一个Region Server中HLog数量达到上限(可通过参数hbase.regionserver.maxlogs配置)时,系统会选取最早的一个 HLog对应的一个或多个Region进行flush
- HBase定期刷新Memstore:默认周期为1小时,确保Memstore不会长时间没有持久化。为避免所有的MemStore在同一时间都进行flush导致的问题,定期的flush操作有20000左右的随机延时。
同样在compact时候,由于是建立在region的基础上,同样会产生不必要的I/O开销,触发compcat(minor_compact)条件:
hbase.hstore.compactionThreshold(默认为3)
另外,如果一个表中存在多个列族,请注意数据量(即,行数)。如果ColumnFamilyA有100万行,而ColumnFamilyB有10亿行,ColumnFamilyA的数据很可能分布在许多许多regions(和regionservers)。这使得ColumnFamilyA的大规模scan效率降低。(我们知道hbase split是由参数hbase.hregion.max.filesize值来控制的,但是,触发region split不是说该region下所有的HFile文件大小达到这个值就会触发split,而是region下某个HFile文件达到了这个值才会执行split,也就是说这里ColumnFamilyB在做split时候,ColumnFamilyA的数据量还很小很小,但是也会被带着执行split,这也就会导致更多的HDFS小文件,并且分散到更多的region和regionservers上)
列族数对Split的影响
当Hbase表中某个Region过大(比如大于 hbase.hregion.max.filesize配置的大小)会被拆分成两个。如果我们有很多列族,而这些列族之间的数据量相差悬殊。比如:有些列有100W行,而有些列族只有10行,这样在Region Split的时候会导致原本数据量很小的Hfile文件进一步被拆分,从而产生更多的小文件。注意:Region Split 是针对所有的列族进行的,这样做的目的是同一行的数据即使在Split后也是存在同一个Region的。
- 注意:Region分裂并不是说整个Region大小加起来大于 hbase.hregion.max.filesize配置的大小就拆分,而是说Region中某个最大的Store/Hfile/StoreFile大于 hbase.hregion.max.filesize才会触发Region拆分的。
列族数对Compaction的影响
- 与Flush操作一样,目前Hbase的Compaction操作也是Region级别的,过多的列族也会产生不必要的IO。
列族数对HDFS的影响
HDFS其实对一个目录下的文件数是有限制的(dfs.namenode.fs-limits.max-directory-items)。如果我们有N个列族,M个Region,那么我们持久化到HDFS至少会产生NM个文件;而每个列族对应底层的HFile文件往往不止一个,我们假设为K个,那么最终表在HDFS目录下的文件数是NMK,这可能会受到HDFS的限制。
列族数对RegionServer内存的影响
一个列族在RegionServer中对应一个MemStore。Hbase在0.90.1版本开始引入了MSLAB(Memstore-Local Allocation Buffers),这个功能是默认开启的,这使得每个Memstore在内存占用2MB的buffer。如果我们有很多的列族,那么光Memstore的缓存就会占用很多内存。
- MSLAB默认开始配置项:hbase.hregion.memstore.mslab.enable
- memstore buffer大小配置项:hbase.hregion.memstore.mslab.chunksize
关于列族数设置的建议
在设置列族之前,我们最好想想,有没有必要将不同的列放到不同的列族里面。如果没有必要最好是放到同一个列族中。如果真要设置多个列族,但是其中的一些列族相对于其他列族数量差距非常悬殊,比如1000W相比100行,是不是考虑用另外一张表来存储相对小的列族。
三、rowkey设计以及加盐读取
HBase中rowkey可以唯一标识一行记录,在HBase查询的时候,有以下几种方式:
- 通过get方式,指定rowkey获取唯一一条记录
- 通过scan方式,设置startRow和stopRow参数进行范围匹配
- 全表扫描,即直接扫描整张表中所有行记录
rowkey是一个二进制码流,最大长度64kb,实际应用10b~100b,以byte[]存储,一般设计为定长,设计遵循三大原则:
- 长度原则:要尽可能短,尽量是8b的倍数,可以有效较少内存寻址时间。
- rowkey在hfile中的物理存储模型如下:
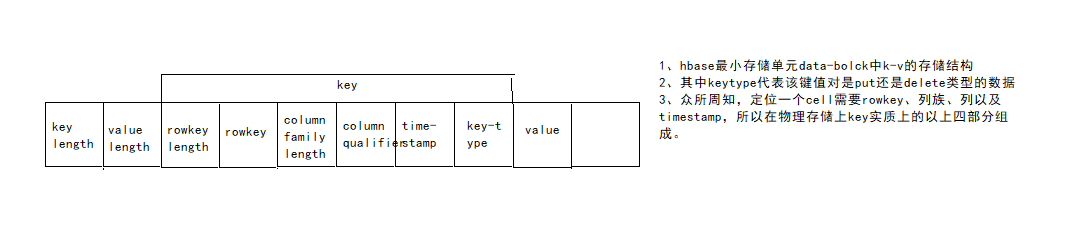 如果rowkey过长,会影响hfile的存储效率。而且hbase的读写都有内存缓存memstore、blockcache,如果rowkey长度过长也会占用较多regionserver内存,影响rs性能。
如果rowkey过长,会影响hfile的存储效率。而且hbase的读写都有内存缓存memstore、blockcache,如果rowkey长度过长也会占用较多regionserver内存,影响rs性能。
- rowkey在hfile中的物理存储模型如下:
- 唯一原则:确保数据唯一不过多赘述
散列随机原则(某些情况下不能完全散列,要保证全局散列,局部有序,在全速写和快速读之前做一个权衡)
热点问题出现
hbase表按照rowkey的字典顺序按顺序写入region中,如果rowkey设计上保持顺序增大,那么在写入时,当前的rowkey总是比之前的大,hbase按照升序写入,数据总是会写入当前最大startkey的那个region中,造成了热点问题。那么集群中的其他rs就会处于空闲状态,没有做到资源的有效利用而且,总是往同一个region中写数据,会造成频繁的region split操作,且split操作会造成rs一段时间内不可用。那么遇到这种热点问题该如何解决呢?参考文章:https://blog.csdn.net/menghuannvxia/article/details/53842320
解决热点问题
参考文章:https://developer.aliyun.com/article/685888
[https://blog.csdn.net/diqijiederizi/article/details/79085852](https://blog.csdn.net/diqijiederizi/article/details/79085852)
- 加盐
加盐后会出现一个问题就是,无法在client重构完整的rowkey get数据,此时要引入hbase新的机制,协处理器解决该问题。
也可以通过spark读取加盐后的hbase表
- 哈希- rowkey反转- 时间戳反转
四、描述 Hbase 中 scan 和 get 的功能以及实现的异同

若有收获,就点个赞吧
0 人点赞
