hbase是什么
是Google开源的bigtable的演化版本,存储数据基于hdfs,提供高可靠性,高性能,列存储,可伸缩,实时读写的海量kv数据数据存储系统。介于nosql与RDBMS之间,查询仅能通过rowkey和rowkey range 进行查询检索数据,仅支持单行事务(可通过hive映射hbase表,进行复杂的多表join查询,也可通过phoenix进行sql化处理查询)。一张hbase表的特点包括可能有上亿行,上百万列、面向列簇存储和权限控制、列族独立检索、对于数据为空的列不做存储,表可以设计的非常稀疏。
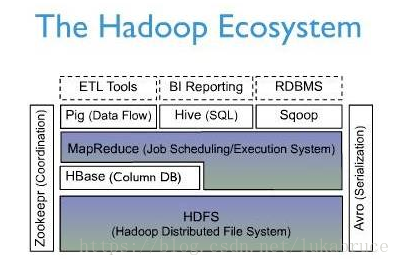
逻辑存储视图
hbase以表的形式存储,由行和列组成。列划分为若干个列族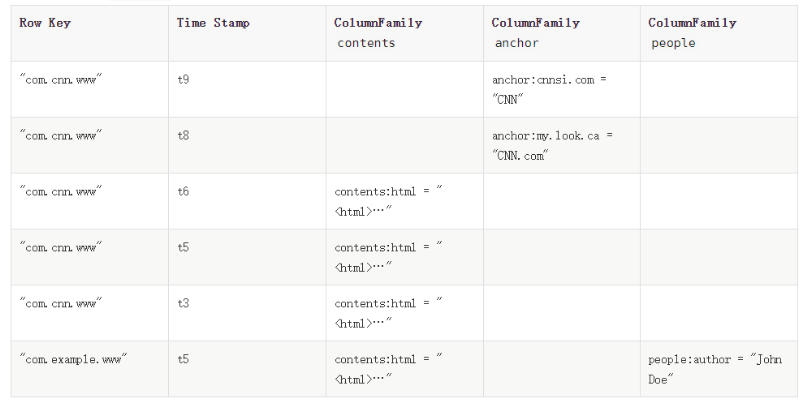
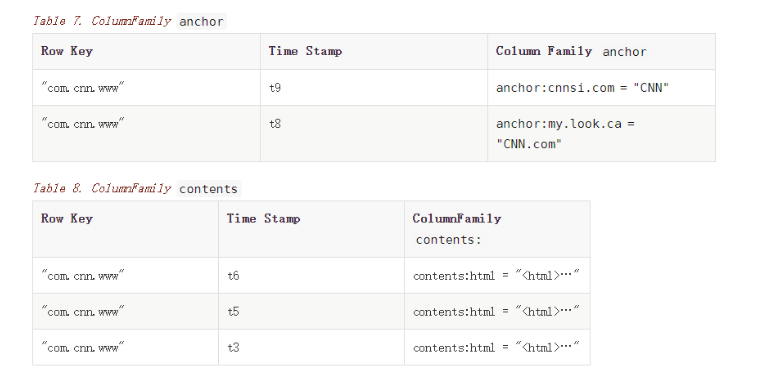
{"com.cnn.www": {contents: {t6: contents:html: "<html>..."t5: contents:html: "<html>..."t3: contents:html: "<html>..."}anchor: {t9: anchor:cnnsi.com = "CNN"t8: anchor:my.look.ca = "CNN.com"}people: {}}"com.example.www": {contents: {t5: contents:html: "<html>..."}anchor: {}people: {t5: people:author: "John Doe"}}}
rowkey:行键,类似关系型数据库中的主键,用来检索记录的唯一主键。访问hbase的行,仅有如下三种方式:
1、通过单个rowkey访问,get方式
2、通过rowkey range 访问,scan限定startrowkey 、endrowkey
3、全表扫描,scan不设限定
rowkey可以设计成任意字符串,最大长度为64kb,在hbase内部,rowkey保存为字节数组。
column family:列族
hbase中的每个列都归属于每个列族。列族是表的schema的一部分,列不是,列可以不用声明的随意增减扩充。列名都是以列族作为前缀。访问控制、磁盘和内存的使用都是在列族层面上进行的。
column:列
属于每个列族,列里面的数据通过列限定符,每个列族可以有一个或者多个列,列不需要定义表时给出,可以按需动态加入
cell:单元格
由rowkey,列族,列,时间戳唯一决定,cell中的数据没有数据类型,全部以字节码形式贮存
timestamp:时间戳
每个cell有多个版本,利用时间戳进行区分,时间戳由hbase自动生成,也可手动生成
物理存储视图
hbase表的存储物理存储如下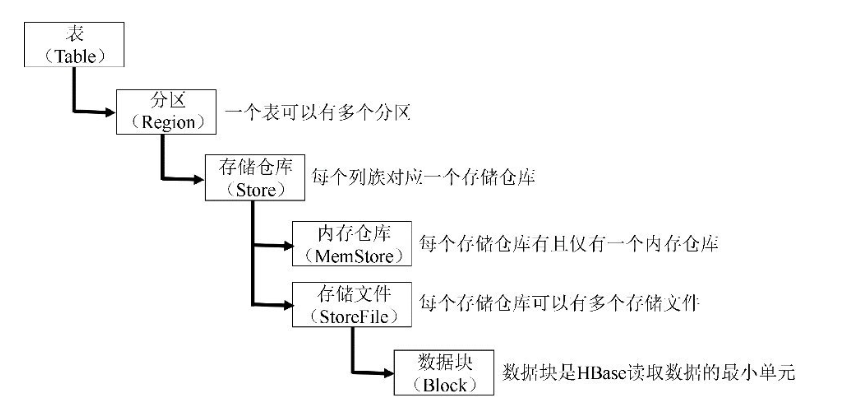
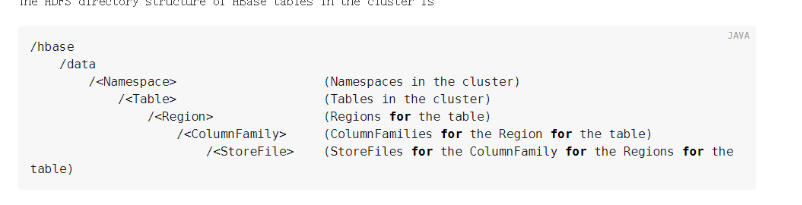
Hregion
一个hbase表在行的方向上切分region, region按大小分割的,每个表一开始只有一个region,随着数据不断插入表,region不断增大,当增大到一个阀值的时候,Hregion就会等分会两个新的Hregion。当table中的行不断增多,就会有越来越多的Hregion。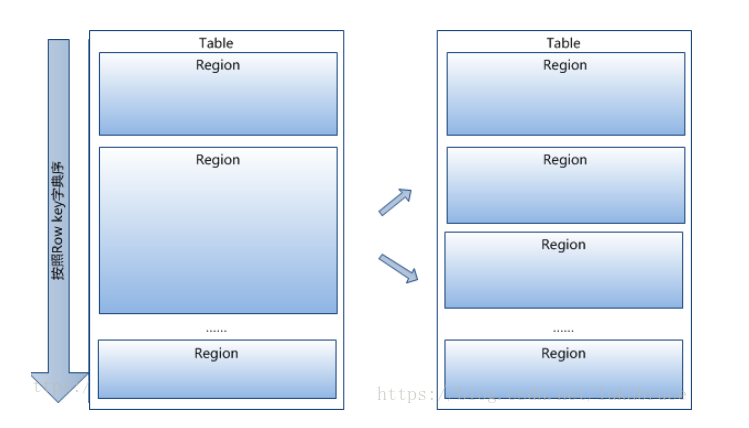
Hregion是Hbase中分布式存储和负载均衡的最小单元。最小单元就表示不同的Hregion可以分布在不同的HRegion server上。但一个Hregion是不会拆分到多个server上的。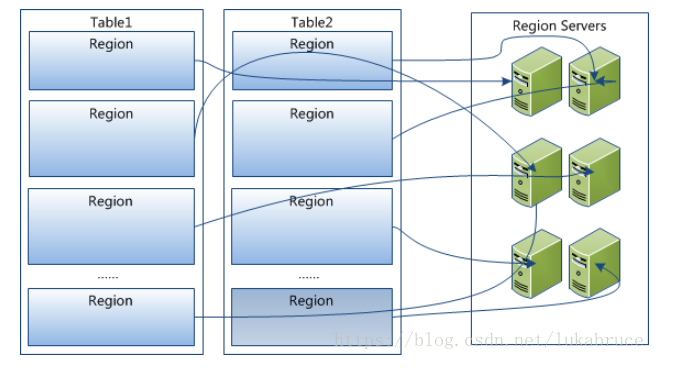
Store
HRegion虽然是分布式存储的最小单元,但并不是存储的最小单元。事实上,HRegion由一个或者多个Store组成,每个store保存一个columns family。每个Strore又由一个memStore和0至多个StoreFile组成。其中0~多个storeFile的拆分标准是当memStore达到一定阈值时,列族会flush切分成多个storeFiles,表现在hdfs上即为多个Hfile。 StoreFile以HFile格式保存在HDFS上。<br />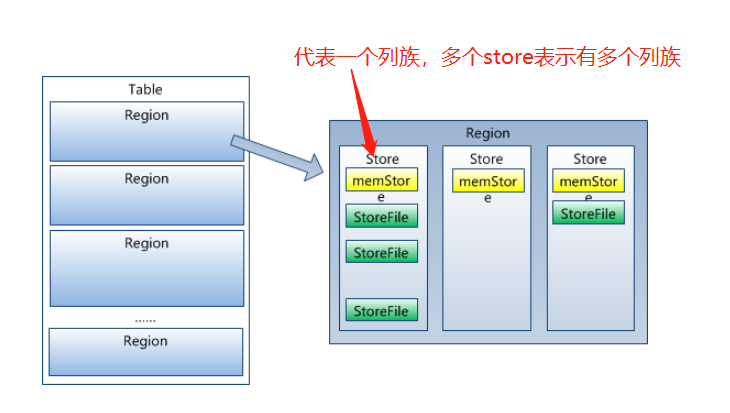

若有收获,就点个赞吧
0 人点赞
