前言
本文以一个接口(后文叫接口A)为例,总结性能优化的一些分析思路及工具使用
性能现状
接口A在上次压测结果中的表现如下:
40个线程 压5分钟 rt130 tps290
(随着线程数增加,rt也随之增加,40个线程是比较优的并发数)
性能预估
应用为单个实例,配置为4C8G,DB配置最大可为8C16G
接口A查了5次表,且全部走索引,按照经验预估tps不至于290,应该可以达到1000左右
瓶颈分析与优化
分析思路
先分析接口的调用链路,接口A调用链路比较简单,就查了5次表,并且全部走索引,那么可以先看每次查询的耗时,看是否符合预期;接着可以从CPU、内存、网络带宽、JVM指标等角度分析是否达到瓶颈
链路耗时
通过metrics埋点上报,可以看到平均每次调用DB的耗时达到了30多ms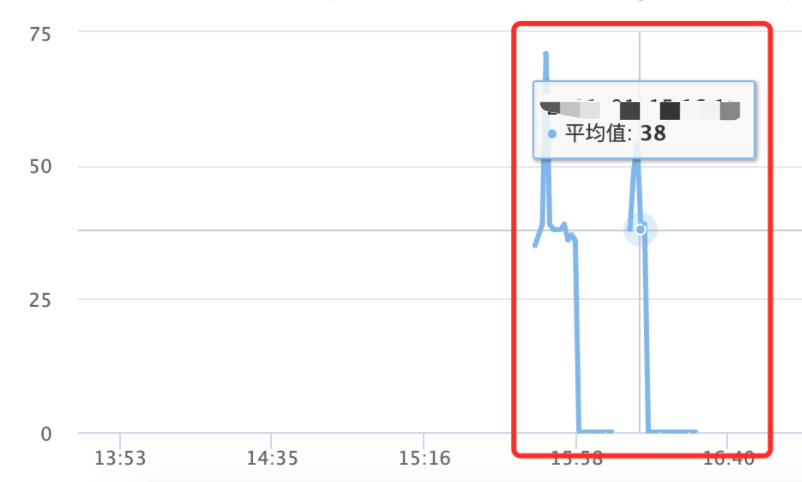
看到sql耗时偏高,怀疑是否没有走到索引
以其中一个查询为例,使用EXPLAIN分析SQL执行是否走索引,发现sql并没有什么问题:
查看该sql的耗时
命令:set profiling = 1;select语句show profiles;
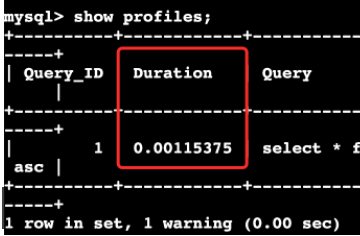
耗时仅为0.1ms
从链路耗时上看不出什么端倪,于是分析CPU、内存、网卡、JVM指标。
CPU
查看CPU使用率
通过top 和 top -H,结合内部监控平台,看到应用CPU利用率达到了80%多,且集中在java进程中,相关线程也是java相关线程,因此怀疑是CPU达到了瓶颈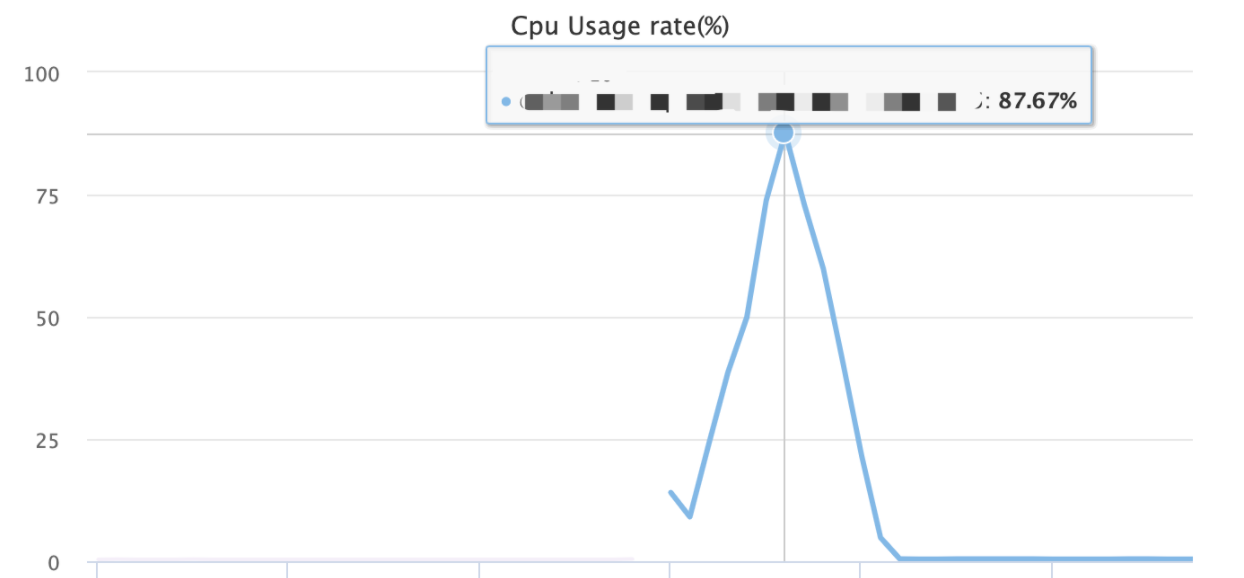
优化日志打印
通过 show-busy-java-threads -c 5,可以看到CPU利用率前5的线程堆栈,其中引起注意的线程如下
该线程是logback异步打日志的线程,但看了接口调用链路,没找到打日志的地方,于是看了下应用的日志,发现打了很多mybatis的debug日志,原来是先前开启了debug日志的配置,关掉即可。
优化连接池数
继续看 show-busy-java-threads -c 5 打印出来的结果,发现如下的线程比较可疑: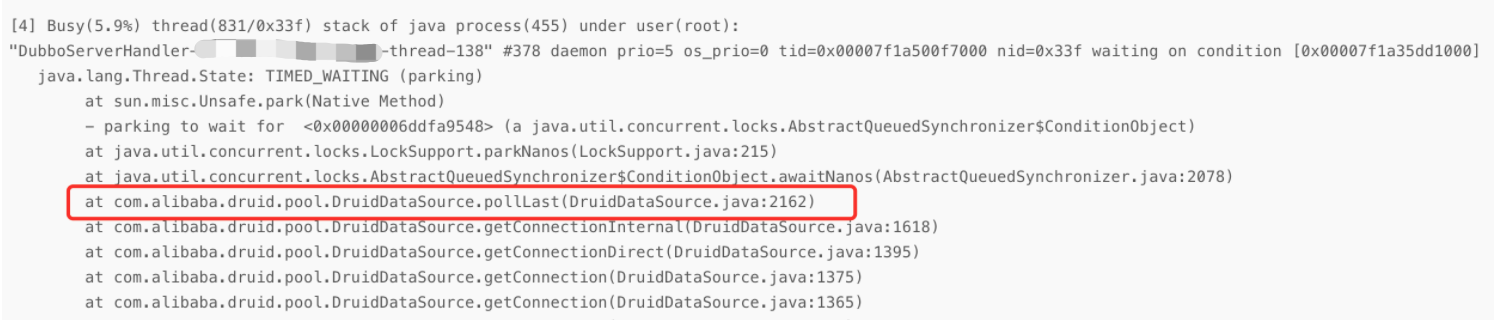
该线程的状态是TIMED_WAITING,是指定一段时间的等待,再看堆栈显示接口请求中,到了druid连接池这一步,在pollLast方法中会阻塞获取可用的数据库连接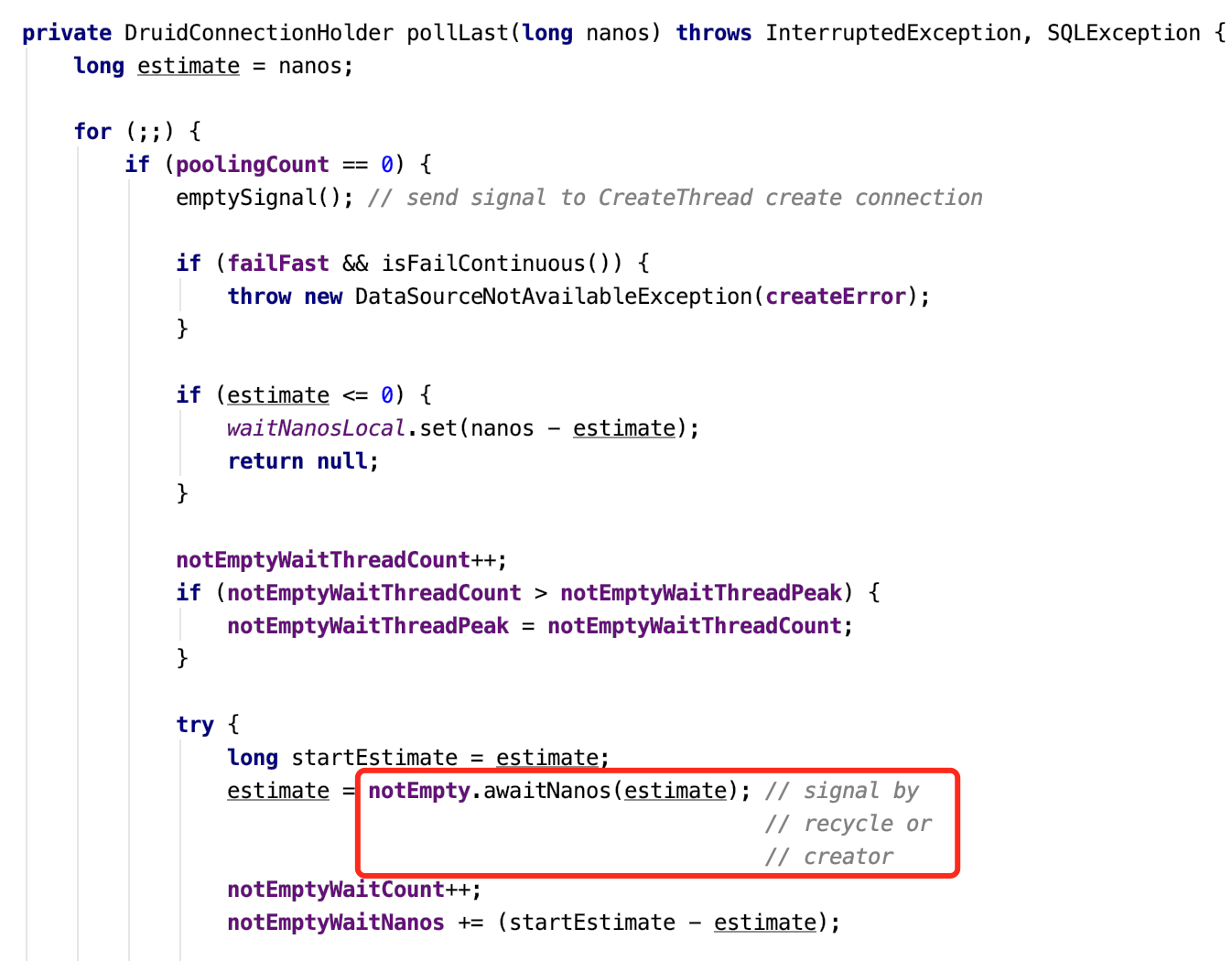
该等待的返回时机是,要么上一个使用者使用完毕后回收,要么是创建了一个新的连接。这里可以怀疑是数据库连接池的数量配置得不合理。
这里再通过arthas的monitor对该方法进行耗时查看,发现平均rt达到了100多ms(图略)
查看配置的Druid连接数,发现最大连接数设置的是10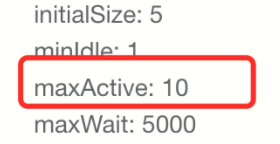
结合数据库server端配置的最大连接数(通过show variables like ‘%max_connection%’; 查看),和实际连接的业务应用数,在不把数据库server端连接池资源耗尽的前提下,将连接数调整为50。
设置完连接池数后,再进行了一轮压测,压测的并发数调整到100,结果出来的提升很明显:
原来:rt130 tps290
现在:rt104,tps来到了857,是原来的三倍
优化druid连接回收时用到的锁
发现Druid在做连接回收时,使用的是公平锁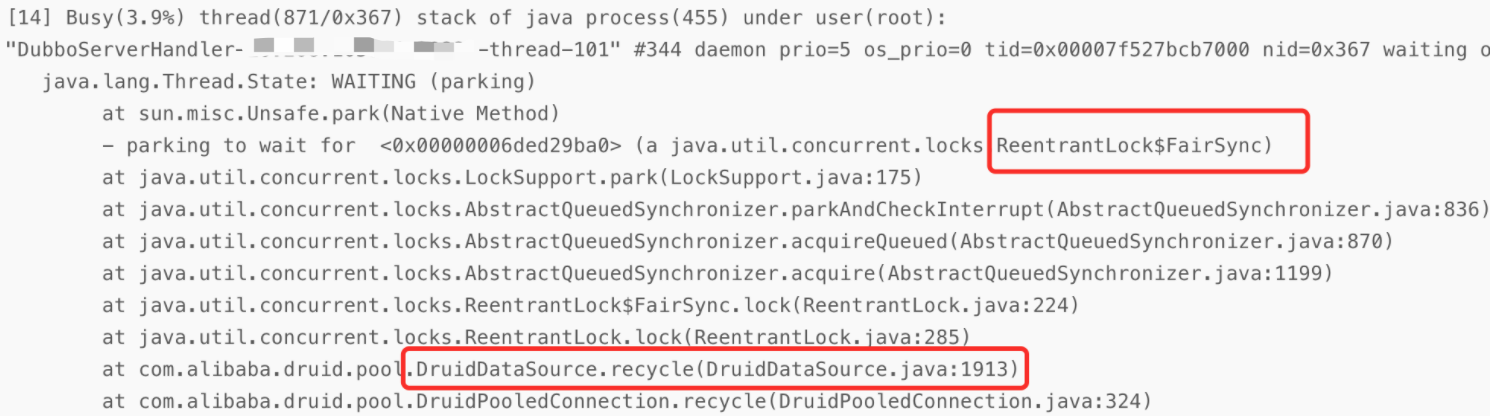
原来是配置的Druid的maxWait属性,会导致自动使用公平锁
maxWait的含义是连接池中获取连接的最大等待时间。为了追求高吞吐量,少数连接等待超时也是可以接受,因此增加useUnfairLock: true调整为非公平锁: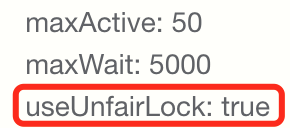
调整之后的结果如下:
- 上次压测:rt104,tps857
- 现在:rt95,tps930,rt减少了9,tps增加了73
再看SQL监控耗时,已经从原来的30左右,降到了10左右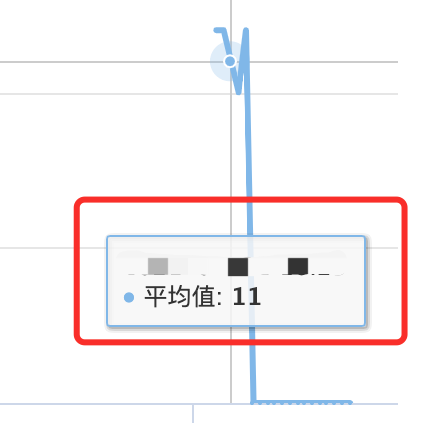
其它优化空间
通过show-busy-java-threads看到一个线程利用率较高,该线程用于上报接口全链路调用耗时,采样率越高上报频率越频繁。结合当前使用情况暂不做调整。
至此,CPU的利用率仍为80%左右,仍然是一个可以提升的点,可通过升级CPU配置来提升性能。
再多说一句,通过show-busy-java-threads可以很方便地查看CPU使用率高的线程。这是一种大问题拆小问题的找瓶颈方式,CPU使用率高就看到时是哪些任务导致CPU使用率高,对于排查其它问题也可以使用一样的思路。
内存
压测期间内存占用率都是5%以下,因此排除内存瓶颈因素
网络带宽
机器配置为万兆网卡,网络传输带宽也类似,而压测期间应用的入口和出口流量为20MB/s左右,理论上远未达到瓶颈
JVM指标
通过 jstat -gc $进程id 5000 可以每5秒打印出gc情况,重点关注full gc和young gc的情况
下图为内部可视化监控: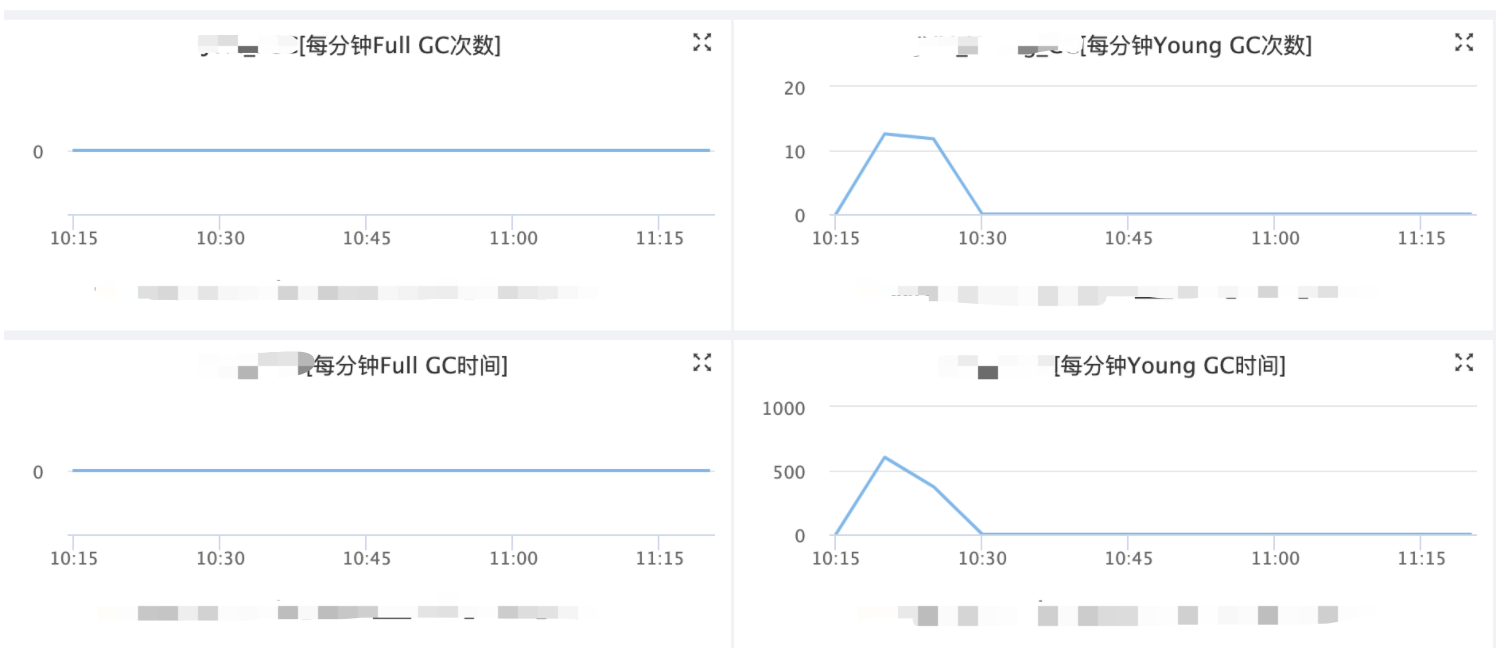
未发现full gc,而ygc每分钟12次能够接受,但每次ygc的时间达到了500/12=41ms左右,相对较大,猜测也是CPU达到瓶颈导致的
优化总结
- 优化结果的性能是原来的三倍多
- 性能差先看调用链路,找拖后腿的环节,对调用链路做优化
- 看系统性指标找瓶颈优化,包括CPU、内存、网络带宽、JVM的GC情况
- 本文为一次过程总结,不排除有更好的优化思路,可持续迭代
参考连接

若有收获,就点个赞吧
0 人点赞
