前言
本文作为Pulsar系列的第二篇文章,主要介绍Apache BookKeeper在存储上的设计,主要聚焦于以下两点:
- BookKeeper的读写流程是怎样的,怎么去存储数据
- 多副本存储下BookKeeper如何处理一致性问题
同时强调下BookKeeper本身是个独立的项目,本文是在Pulsar原理探究过程中对BookKeeper存储设计的系统性学习总结。
读写流程设计
BookKeeper采用读写分离的设计
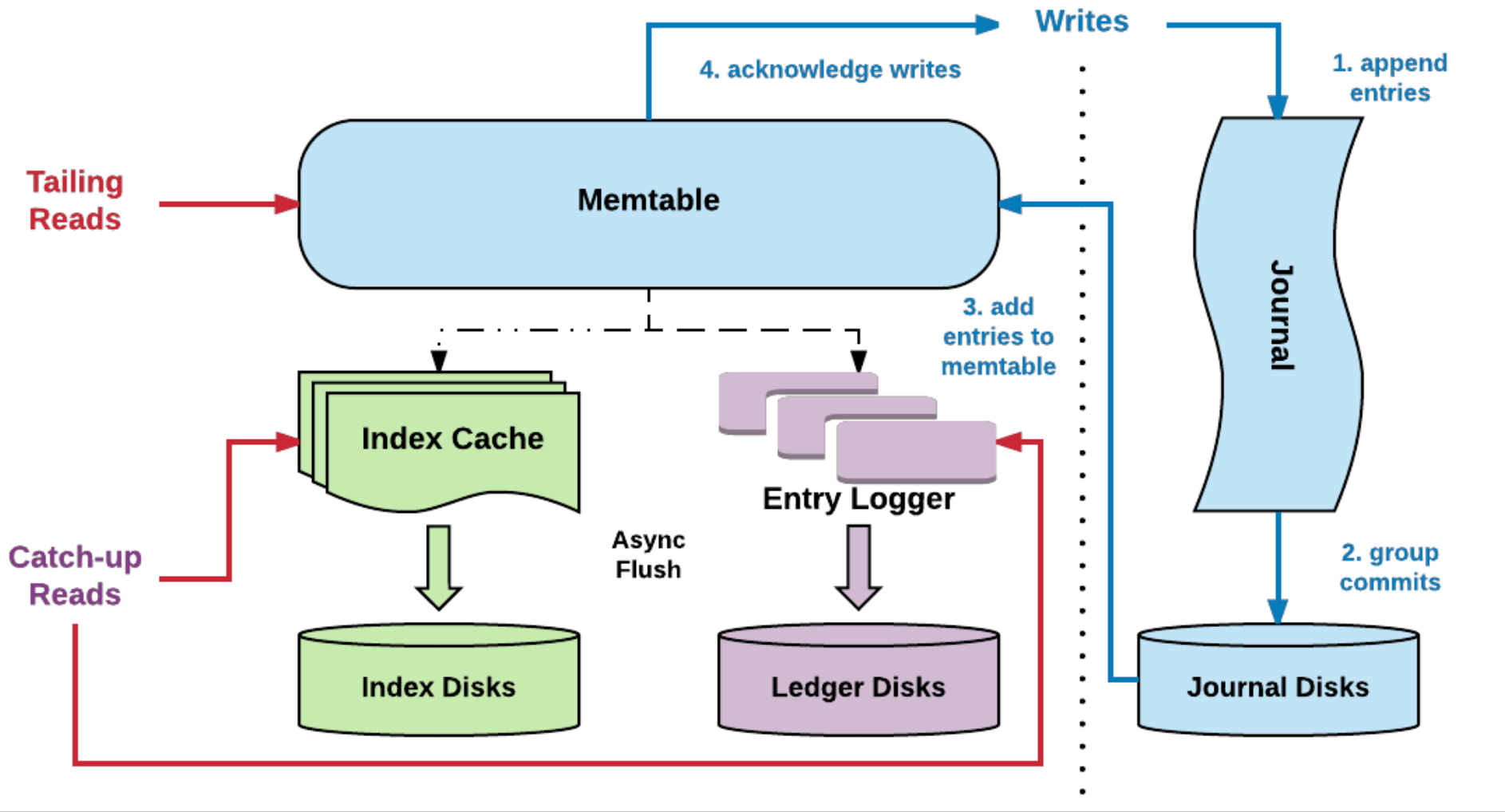
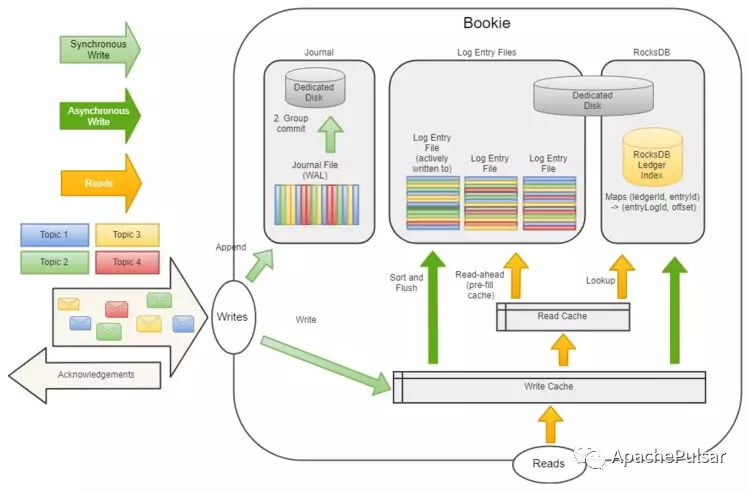
写流程设计
1)同步流程
- 将数据写入Journal文件中(即预写日志文件),如果同时有多个数据写入,可进行批量提交(Group commit),刷到Journal磁盘中
- 将数据写入内存中(即memtable/Write Cache,作为写缓存)
- 返回写入成功响应,注意到这里整个流程都是同步的
2)异步流程
- 异步将缓存的数据进行聚合+排序,聚合针对同一个Ledger,排序针对一个Ledger下以时间为顺序的数据
- 将排序好的Entry放入Log Entry File,刷新(flush)到磁盘中
- 以<(LedgerID, EntryID), EntryLogID>写入RocksDB,用于在随机读时可以快速找到Entry
值得一提的是,Log Entry File创建的条件是:bookie刚建立,或者旧的Log Entry File已经达到文件大小阈值。这意味着不同的Ledger会聚合到同一个Log Entry File。
另外Journal File创建的条件是:bookie刚建立,或者旧的Journal File已经达到Journal文件大小阈值。这意味着Journal遇到多个Ledger写入时顺序写不会变成随机写,也就是不会像kafka分区一多就顺序写变随机写。
读流程设计
- 先从写缓存中读(对于Tailing Reads即尾部读来说,由于读取的是最新的,一般可以从写缓存中拿到数据)
- 如果写缓存不命中,从读缓存(Read Cache)读取数据
- 如果读缓存不命中,则以查询的LedgerID+EntryID通过RocksDB得到数据对应的物理存储位置EntryLogID,然后从Log Entry Files(磁盘上)读取数据
- 把读取到的数据回填到读缓存中
- 返回读取成功响应
一致性设计
对于分布式存储系统,为了高可用,多副本是其通用的解决方案,但也带来了一致性的问题,包括:
- 数据怎么算可读,如何避免读到未ack的数据
- 出现脑裂情况时,如何避免多Writer写入同一个topic/partition导致数据不一致
接下来看BookKeeper是如何解决这些一致性问题的。
一致性模型
在介绍其读写一致性之前,先看下 BK 的一致性模型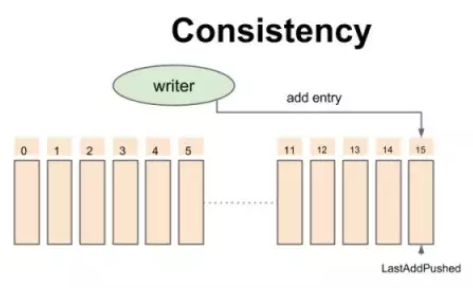
一致性模型-开始时的状态
对于 Write 操作而言,writer 不断添加记录,每条记录会被 writer 赋予一个严格递增的Entry id,所有的追加操作是非阻塞的,也就是说:第二条记录不用等待第一条记录返回结果就可以发出。已发送到Bookie但未被ack的数据的位置指针叫做Last-Add-Pushed(LAP)。
注意这个模型是以writer为视角,Entry实际上可能会存在多个bookie上,多个bookie对应一个writer。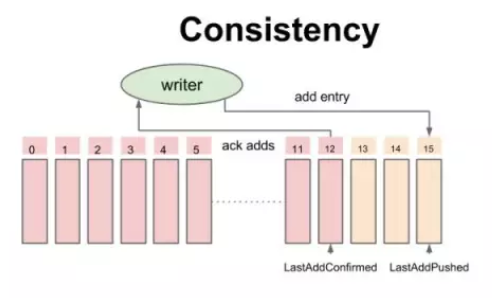
一致性模型-追加数据时的中间状态
伴随着写成功的 ack,writer 不断地更新一个指针叫做 Last-Add-Confirm(LAC),所有 Entry id 小于等于 LAC 的记录保证持久化并复制到大多数副本上,而 LAC 与 LAP(Last-Add-Pushed)之间的记录就是已经发送到 Bookie 上但还未被 ack 的数据。
LAC作为Entry元数据的一部分,通过Entry保存到Bookie中,而Ledger本身并不存储LAC,这样设计的好处是:
- 不需要频繁更新ZK元数据
- 因为LAC保证了之前的entry已经持久化成功了,那么在做ledger恢复的时候,只需要从LAC后面开始处理就可以了
LAC由客户端生成,在动态插入Entry的时候,记录的是当前已经ACK成功的Entry ID。比如插入Entry5的时候,LAC是4,那么存储在bookie的Entry5中LAC是4。我们知道Ledger包含了元数据Last Entry ID,当Ledger关闭时,会更新5到Last Entry ID中。
读一致性
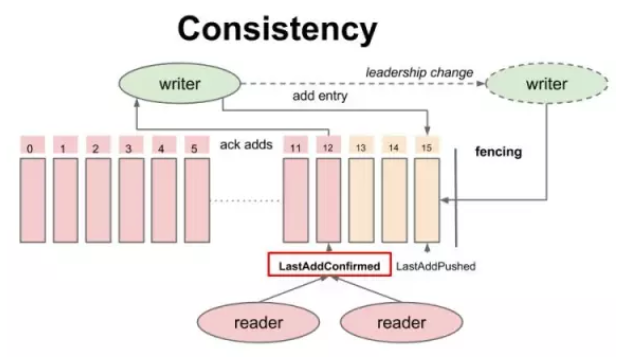
所有的 Reader 都可以安全读取 Entry ID 小于或者等于 LAC 的记录,从而保证 reader 不会读取未确认的数据,保证了 reader 之间的一致性
写一致性:Fencing机制
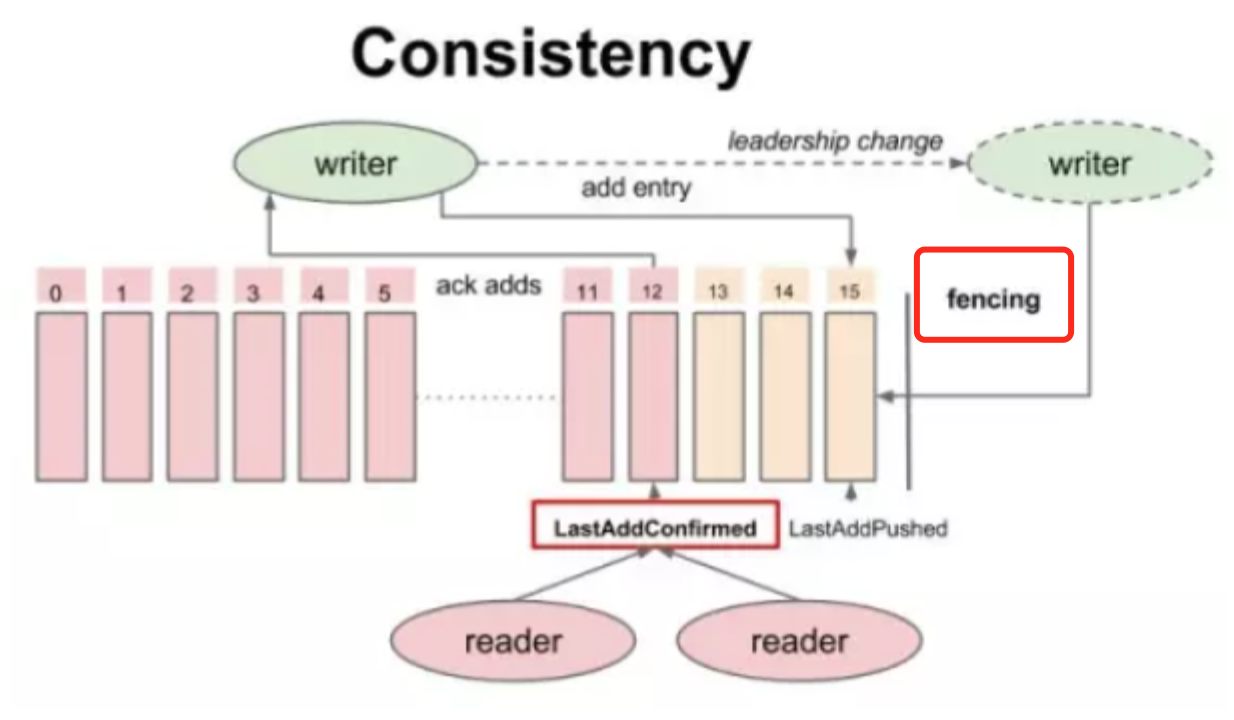
简单来说,Fencing机制用于防止有多个writer(pulsar中即为broker)同时写同一个topic/partition
什么时候会出现多个writer同时写同一个topic呢?在pulsar中,当zk检测到有一个broker1挂掉了,那么会把该broker1拥有的topic所有权转移到另一个broker2。如果broker1实际上没挂掉(类似出现脑裂的情况),那么会出现broker1、broker2同时写同一个topic,对于broker1写入完成的数据,由于topic已经给broker2接管了,在broker2看来并不知道broker1写入了数据,就会出现写入数据的不一致。
那么bookkeeper是如果解决这个问题呢?它引入了Fencing机制,工作机制如下:
- 假设Topic X当前拥有者Broker1(B1)不可用(通过zk判断)
- 其它broker(B2)将TopicX当前Ledger状态从OPEN修改为IN_RECOVERY
- B2向Ledger的当前Fragment的Bookies发送fence信息,并等待Qw-Qa + 1个Bookie响应。收到此响应后Ledger将变成fenced。如果旧的broker仍然处于活跃状态,将无法继续写入,因为无法获得Qa个确认(由于fencing导致异常响应)
- 接着B2从Fragment的Bookies获得bookie各自最后的LAC是什么,然后从该位置开始向前读,得到未满足Qw数的Entry(因为可能存在已写入Qa个bookie,但由于broker故障导致bookie数不足Qw的情况)。将这些Entry进行复制,使之达到Qw个Bookie
- B2将Ledger的状态更改为CLOSED
- B2现在可以创建新的Ledger并接受写入请求。
BookKeeper的fencing特性可以很好的处理Broker脑裂问题。没有脑裂,没有分歧,没有数据丢失。
参考链接

若有收获,就点个赞吧
0 人点赞
