Pulsar简介
Pulsar是云原生分布式消息流平台(即可作为消息中间件),最初源于Yahoo,支持Yahoo应用服务140万个主题,日处理超过1000亿条消息。Pulsar于2016年开源并捐赠给Apache软件基金会,现为Apache软件基金会顶级项目。
Pulsar的特性如下:
- 支持多租户,通过多租户可为每个租户单独设置认证机制、存储配额、隔离策略等。
- 具有高吞吐、低延时、强容错等特性
- 原生支持多集群部署,集群间支持无缝的数据复制(Geo-replication)
- 高扩展性,能够支撑上百万个topic
- 支持多语言客户端,如Java、Go、Python和C++
- 支持多种消息订阅模式(exclusive, shared, failover,下文会有介绍)
- 高可靠的消息持久化存储
- 支持数据分层式存储,可将冷数据保存到S3、GCS等低成本的存储系统中
为什么使用Pulsar
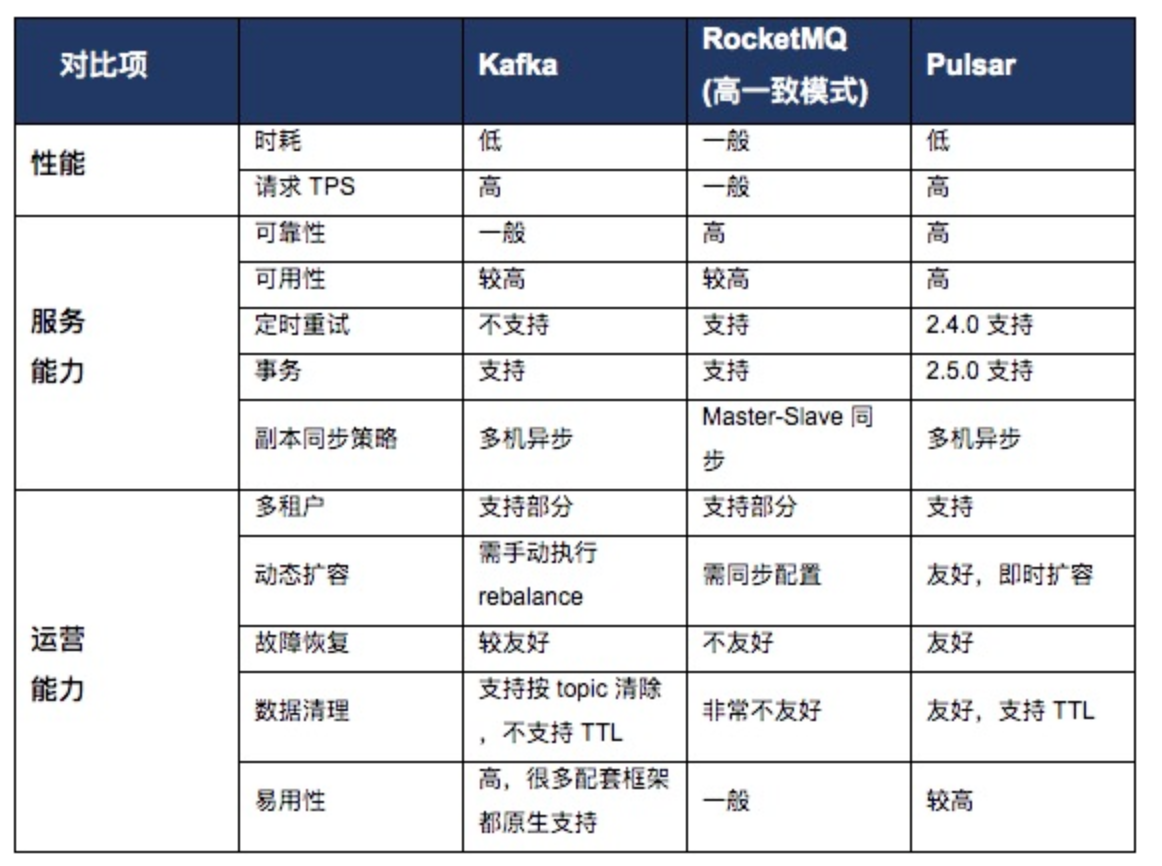
MQ对比
Pulsar除了性能好、可靠性高之外,Pulsar有多租户、GEO-replication以及横向扩展能力等方面上的优势。
Pulsar基础知识
Topic组成部分
在Pulsar中topic的格式为:{persistent|non-persistent}://tenant/namespace/topic
如persistent://public/default/order_status_changed_event
这里会涉及到几个概念
| topic名称组成 | 描述 |
|---|---|
| 持久化/非持久化 | pulsar支持两种主题类型:持久化和非持久化,默认是持久化。对于持久化的主题,消息会持久化到磁盘中,而非持久化则不会。 |
| 租户(tenant) | 租户是topic最基本单位,租户可以跨集群分布,每个租户都可以有单独的认证和授权机制,租户也是存储配额、消息TTL(即消息自动确认时间)和隔离策略的管理单元。 |
| 命名空间(namespace) | 将相关联的topic作为一个组来管理,是管理topic的基本单元。大多数对topic的管理都是以命名空间为粒度,比如GEO-replication是以namespace为单元。 |
| 主题(topic) | 即主题名 |
下图以一个直观的视角来看一个topic的组成: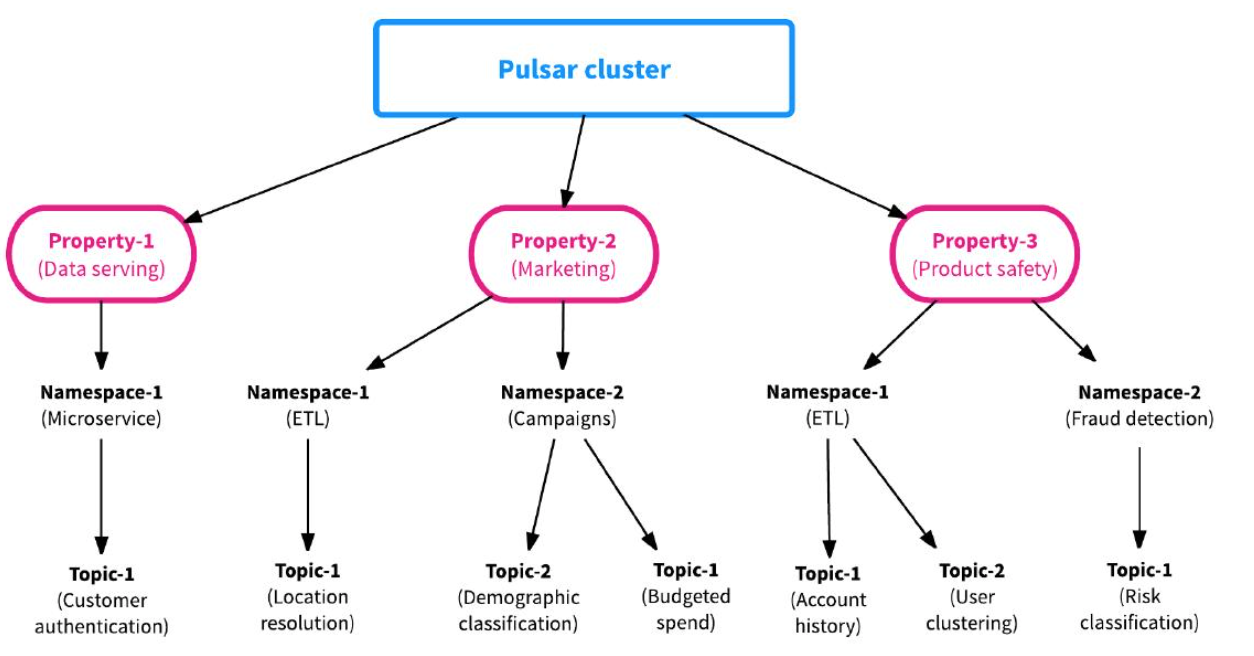
多租户下的topic
主题订阅模式
pulsar的主题订阅模式包括四种:独占(exclusive)、共享(shared)、灾备(failover)、key共享(key_shared)。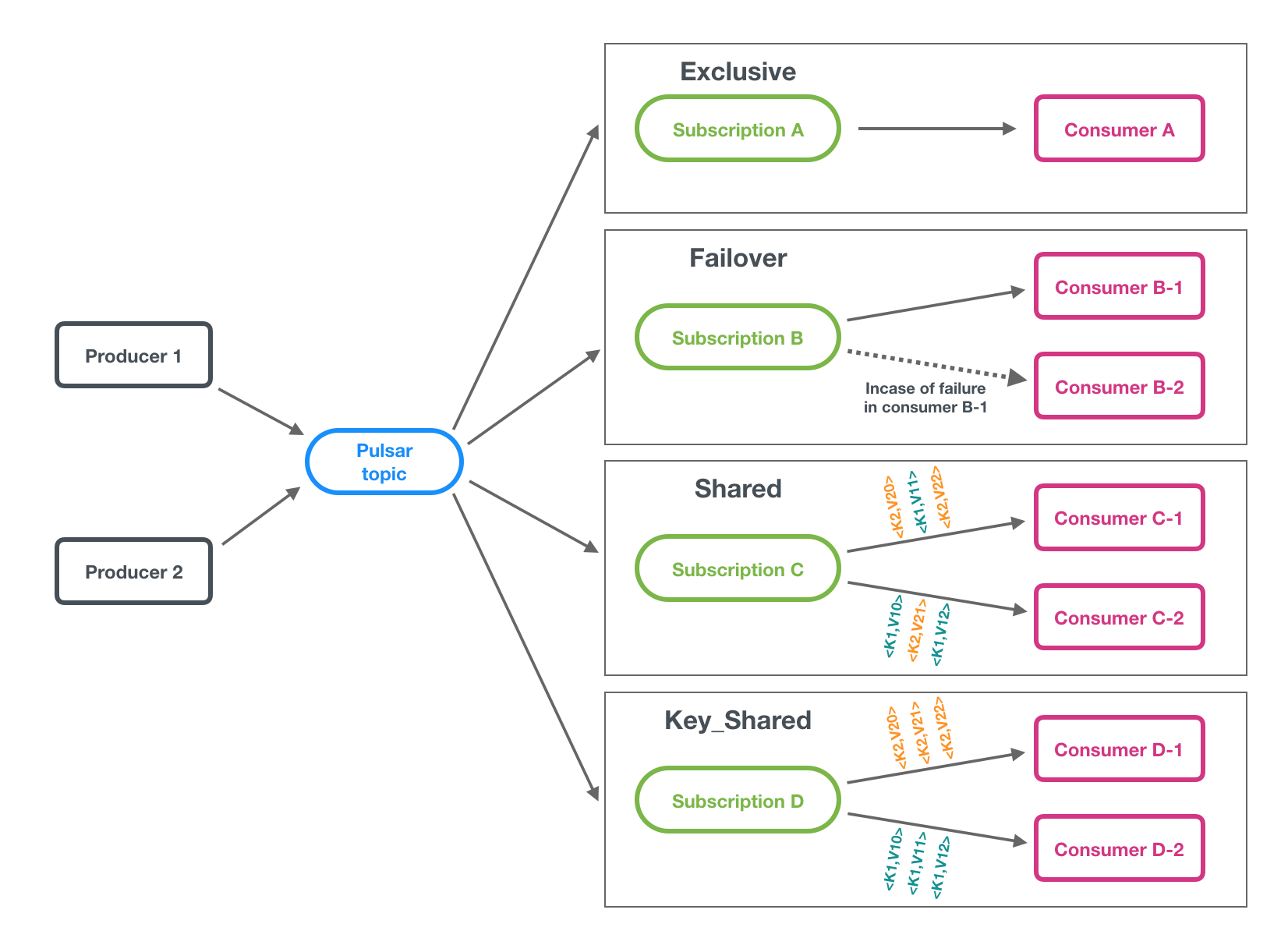
订阅模式
- 独占:一个订阅只与一个消费者可以关联,只有这个消费者接收到topic的全部消息,如果这个消费者故障了就会停止消费。该模式适用于全局有序的消息消费。
- 灾备:一个订阅可以与多个消费者关联,但只有一个消费者会消费到数据,当该消费者故障时,由另一个消费者来继续消费。该模式适用于全局有序的消息消费。
- 共享:一个订阅可以与多个消费者关联,消息通过轮询机制发送给不同的消费者。该模式适用于对消费顺序无要求的消息消费。
- key共享:一个订阅可以与多个消费者关联,消息根据给定的映射规则,相同key的消息由同一个消费者消费。该模式适用于按key有序的消息消费。
Pulsar架构设计
分层架构
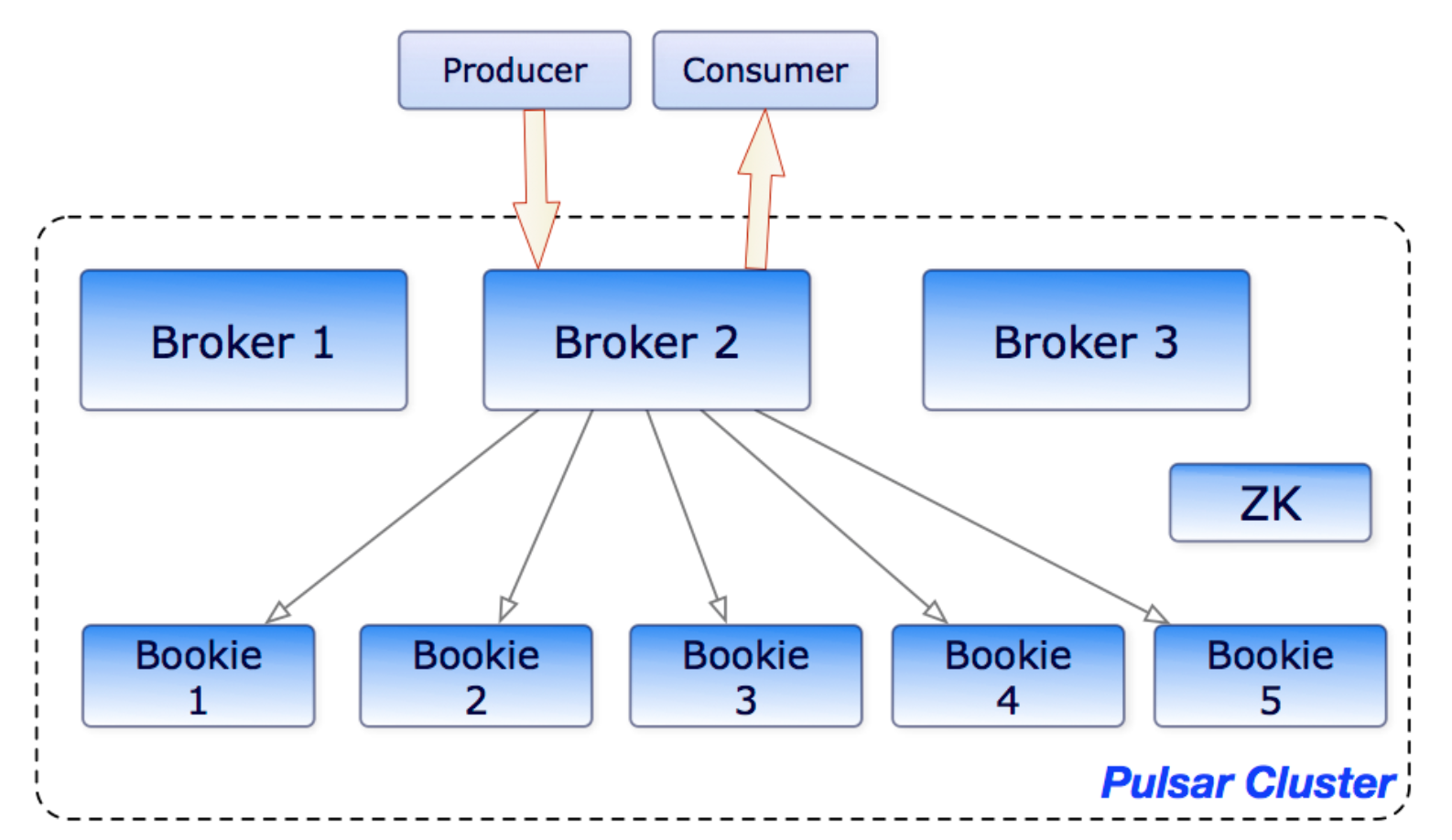
Pulsar各组件交互示意图
一个pulsar实例可以由多个集群组成,集群间的消息数据可以进行复制。单个集群由以下三部分组成:
- 一个或者多个broker:负责处理producer发出的消息,并将消息给consumer消费;
- 一个或多个BookKeeper(又称bookies):bookies提供消息的持久化存储能力,broker将消息存储在bookies中。
- 一个ZooKeeper集群:ZooKeeper提供分布式配置和协调能力,存储归属信息、broker负载报告、bookies ledger信息等。
可以看出,Pulsar采用了分层架构,由两层组成:
- 无状态服务层:由一组接收和传递消息的Broker组成
- 有状态持久层:由一组 bookies存储节点组成,可持久化地存储消息
这样的好处是可以独立进行扩展,即
- 当需要支持更多的消费者或生产者时,由于Broker是无状态的,可以简单地添加更多的 Broker。触发负载均衡条件后,主题分区将在Brokers中做Load Balance,一些主题分区的所有权会转移到新的Broker。
- 当需要更多存储空间来将消息保存更长时间时,只需添加更多 Bookie,流量将自动切换到新的 Bookie 中。Pulsar中不会涉及到不必要的数据搬迁,不会将旧数据从现有存储节点重新复制到新存储节点。
一条消息的旅程
在讲Pulsar各组件的设计之前,我们可以从一个整体的视角,去看一条消息是如何从生产走到消费的。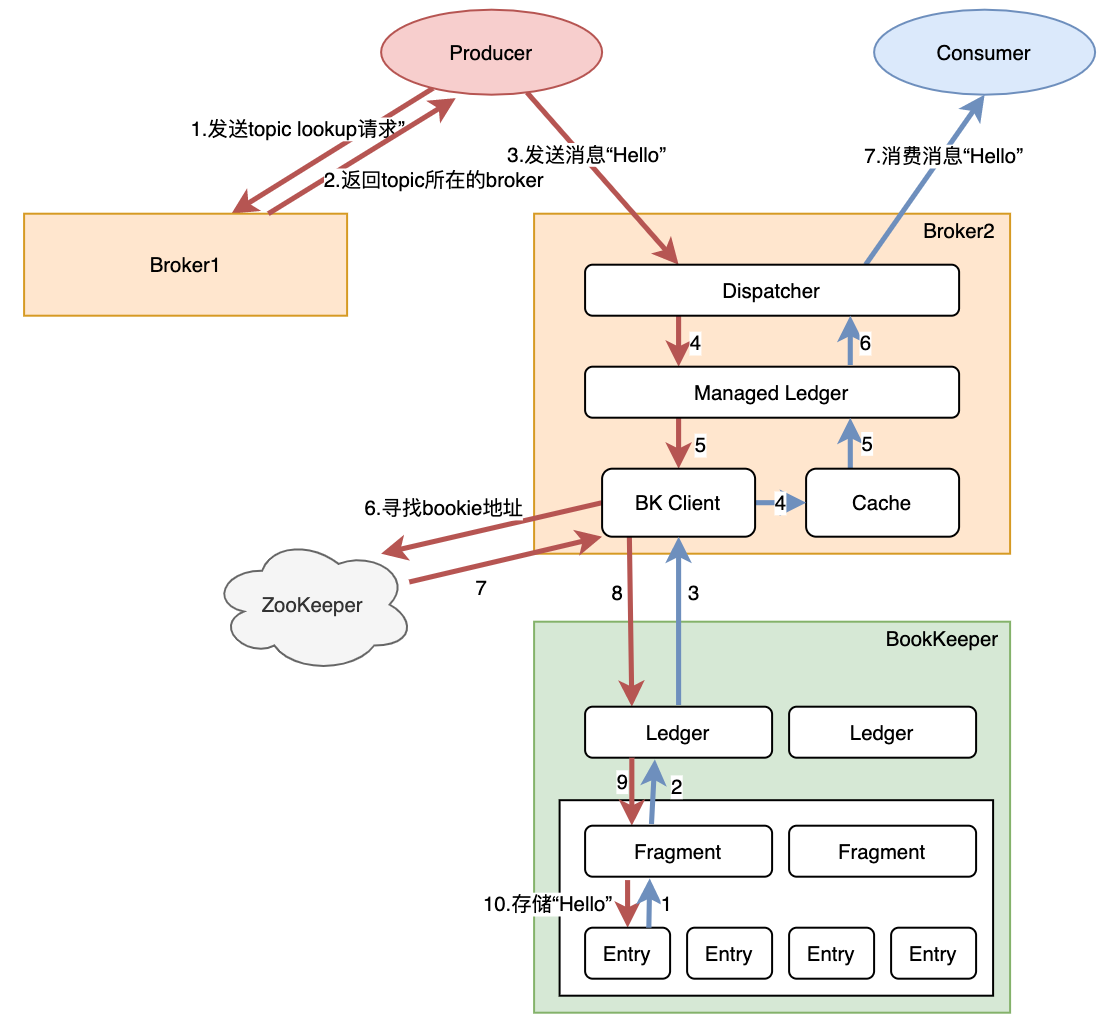
消息“Hello”生产与消费的执行链路
注:1)红色线代表生产消息的链路,蓝色线代表消息被消费时数据流动链路;2)为了简化流程,上图不代表只有这种执行链路,消息到达bookie实际上是先到达journal文件,再异步刷到EntryLogFile
- 发送消息:我们在使用pulsar时会指定pulsar broker的地址,生产者会发起一个lookup请求,找到topic所在的broker,再与这个broker建立tcp长连接,进行后续的消息发送
- broker处理消息:broker启动时会通过ZooKeeper找到BookKeeper,然后通过BK Client与bookkeeper建立连接。在收到生产者的消息后,会以Entry的形式通过Ledger API发送到BookKeeper当中。当收到存储成功的ack后,先将消息保存到Cache中,再返回给生产者消息已发送成功。
- BookKeeper处理消息:收到消息后,以Entry形式存储在Fragment中。
- 消费消息:先与生产者类似,消费者与对应的broker建立连接。当正常订阅消息时,消费者只需要从Cache中读取数据。当需要读某一些历史数据时,Cache中不存在话需要从Bookie中获取。
Broker核心设计
基本概念
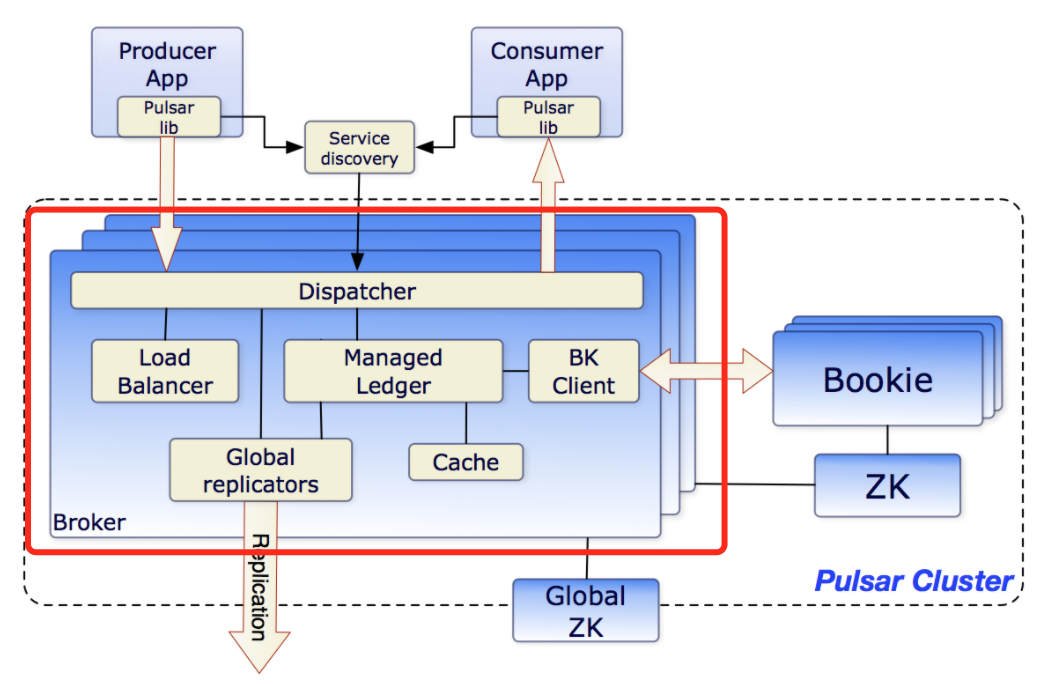
Broker组成部分
在Broker中包含多个组件:
- Dispatcher:调度分发器,通过自定义的二进制协议,与生产者、消费者进行数据传输
- Load Balancer:用于做负载均衡,即分配合适的topic数量到自身
- Managed Ledger:Ledger是一个只追加的数据结构,其中存储着一条条消息。而Managed Ledger作为Ledger的上一层抽象,负责管理消息流,作为添加消息和消费消息的入口,有一个写入器进程添加消息,并且有多个cursor消费消息,每个cursor有自己的消费位置。
- BK Client:请求Bookie的客户端
- Cache:为了提升性能,broker会将消费者要消费的消息提前放到Cache中。如果积压的消息超过了缓存大小,Broker就直接从BooKeeper读取消息(存在的场景如消息未确认ack,但消费者继续请求数据,这时积压的消息就可能超过缓存大小)
- Global replicators:用于做Geo复制
Pulsar是一个横向可伸缩的消息系统,对于服务层即Broker来说,可伸缩意味着一个集群中的流程需尽可能均匀地分布在所有可用的Brokers上。可伸缩的场景包括:
- Broker遇到负载高时需要做负载均衡
- 扩充Broker以支撑集群流量增加
- 缩减Broker时需要平摊该broker的流量到其它broker
- Broker故障处理
流量建立在topic之上,因此要理解Broker如何做到可伸缩,需要先了解topic是如何被分配到不同的broker。
Topic分配到Broker的粒度
向broker分配topic(后续讨论假定一个topic只有一个分区)不是在topic级别完成的,而是在Namespace Bundle级别(更高级别)完成的。所谓bundle列表,是指对一个namespace中的topic进行切分得到的列表,一个bundle包含多个topic,如图: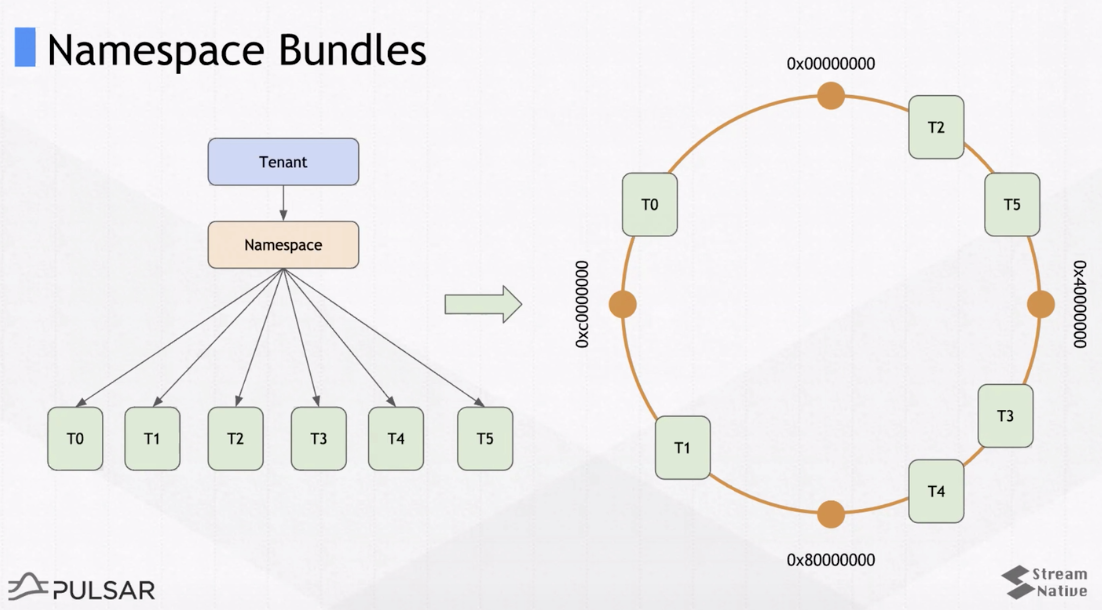
Namespace Bundles
topic通过一致性哈希得到自己处于哪个分组。如图6个topic,bundle数是4,这样每个bundle分配到1到2个topic。假设有3个broker,那bundle就均匀分配到broker上,即topic均匀分配到了broker上。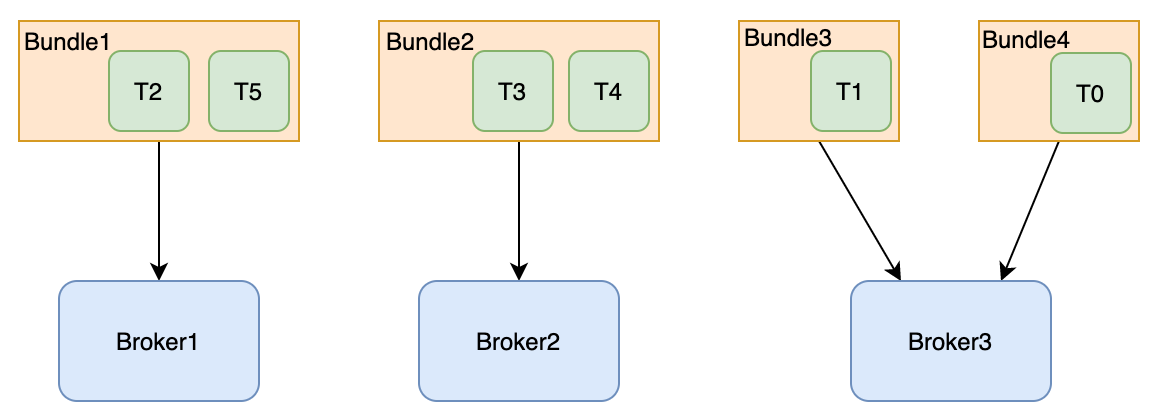
bundle分配到broker
客户端在指定 topic 时,需要查找 topic 所属哪个 broker。这时候通过 topic 全限定名相关的 namespace 来确定落在哪个namespace bundle 上,然后通过查找 namespace bundle 所属 broker 来确定分配情况。这里相关的元数据都在zk上。
通过bundle,可以减少pulsar在处理topic与broker分配关系时需要保存的元数据大小。每个Borke拥有一个或多个bundle,也就是拥有一个namespace下所有topic的一个子集的所有权。
负载均衡
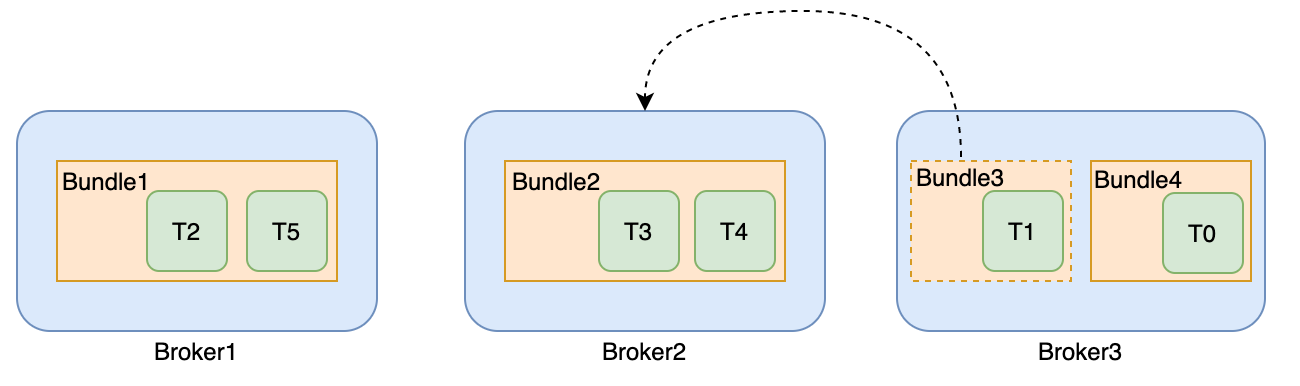
Bundle3分配到Broker2
Pulsar的Load Balancer支持自动的负载均衡,在broker集群内部,会通过 zookeeper 选举一个Master,对Broker的负载进行监控。
当检测到某个broker过载时,会强制将一些流量分配到低负载的broker,也就是说,broker会强制“卸载”bundle的一些流量较大的子集,以降低broker的负载。
例如,默认卸载阈值是85%,如果broker资源使用率(基于cpu、网络、内存等指标计算)使用超过了95%,那么需要卸载的bundle的资源使用率为95% - 85% + 5%(百分比差) = 15%。
再重分配topic后,生产者和消费者再与新的broker建立连接。
扩充/缩减Broker
- 对于扩充Broker来说,Pulsar不会直接进行topic的重分配,而是把broker放入可用broker集合中,当触发负载均衡时,再用到新的broker。
- 对于缩减Broker来说,与负载均衡类似,即将Broker负责的topic分配给其它的Broker,生产者和消费者再进行重连接。
Broker故障处理
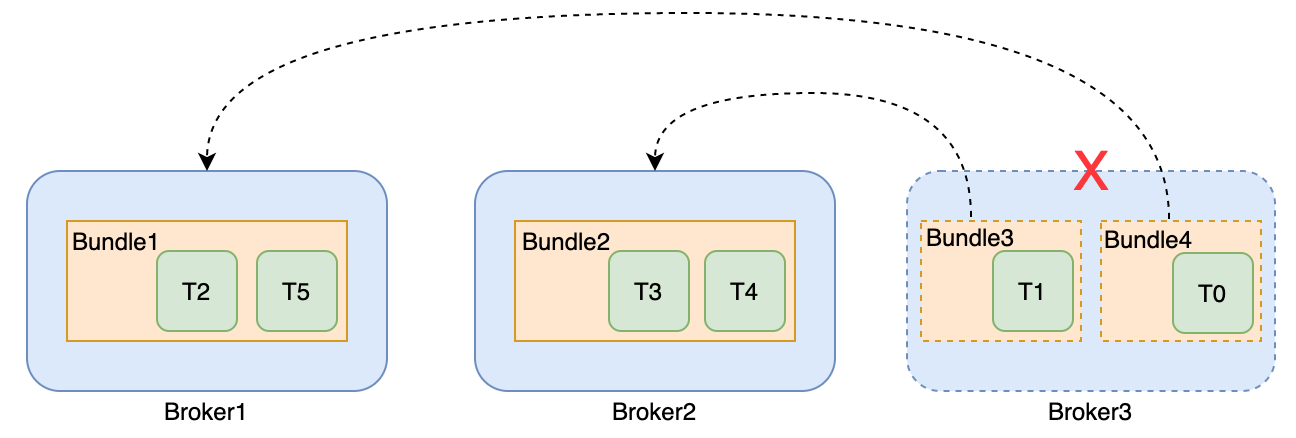
Broker3宕机时的容灾
当broker故障时,对于procuder和consumer来说,会出现连接超时的情况,这时会进入重试。
在broker集群内部,同样是通过 zookeeper 选举一个Master,对Broker是否宕机做判断。当发现故障后,会触发故障broker负责的topic的重分配,分配到其它可用的broker。这样producer和consumer会与重分配后的broker建立连接。
由于Broker是无状态的,重分配后相关元数据都是记录在ZK上,因此不会进行数据复制,且单个Broker的故障不会影响数据的处理。
BookKeeper核心设计
Pulsar使用BookKeeper作为消息持久化层实现。Apache BookKeeper是一个高扩展、强容错、低延迟的分布式预写日志(WAL)系统。它相当于把底层的存储系统服务化,这样可以使得依赖BookKeeper的分布式系统(如分布式消息队列)在设计时可以只关注应用层和功能层的内容,而存储层比较难解决问题,如一致性、容错能力,BookKeeper已经实现了。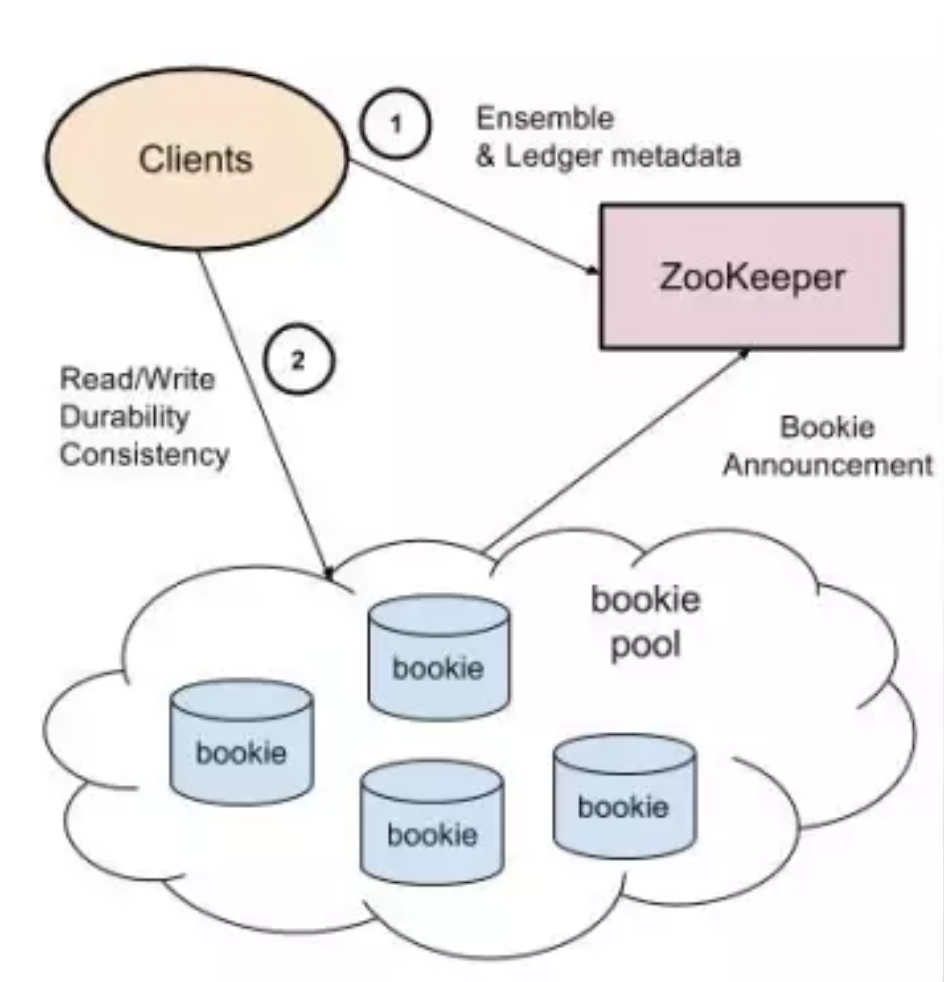
BookKeeper整体架构
BookKeeper整体由三个部分组成:客户端 (Client)、数据存储节点 (Bookie集群) 和元数据注册发现服务 (ZooKeeper),Bookies 在启动的时候向 ZooKeeper 注册节点,Client 通过 ZooKeeper 发现可用的 Bookie。在讲pulsar架构中的BK Client可以与这里的Client对应上。
基本概念
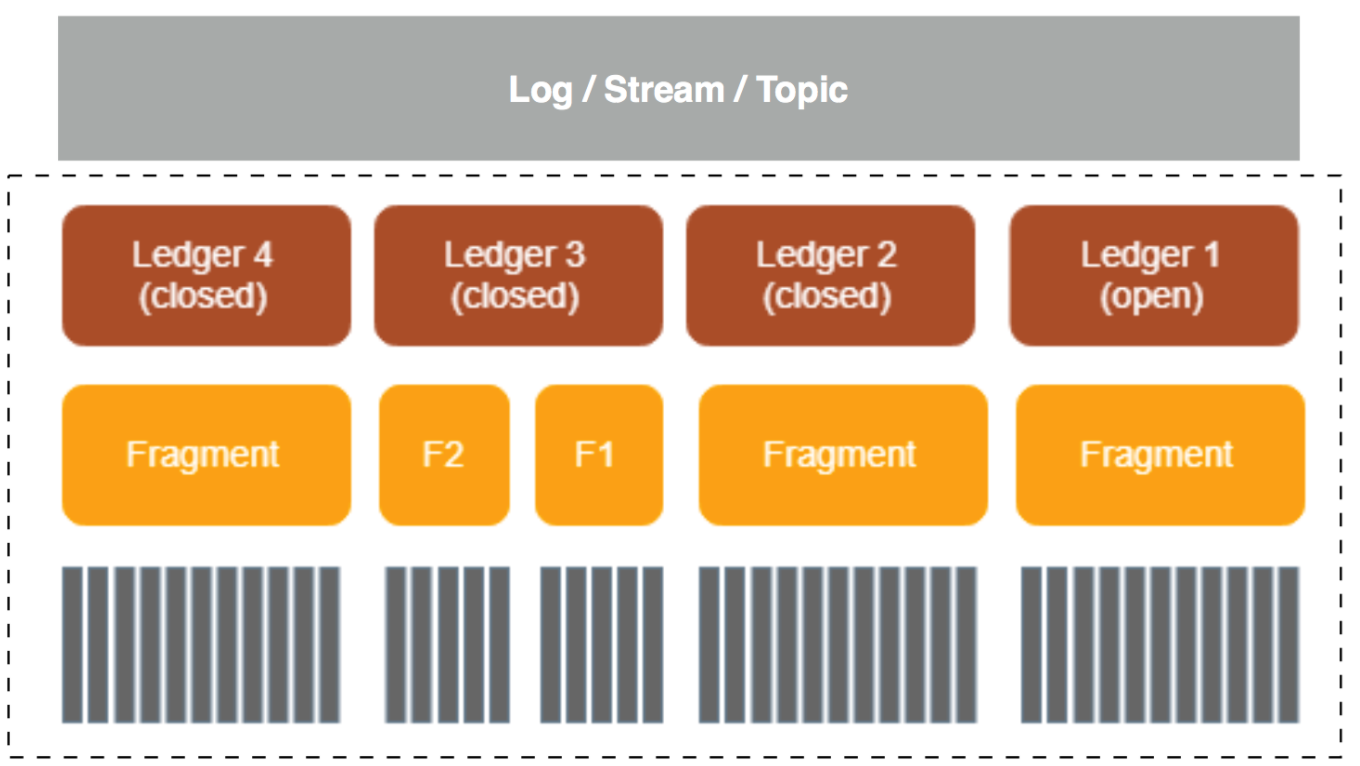
bookie的存储设计如下:
- Ledger:它是 bookie逻辑上的一个基本存储单元,是对存储消息的log文件的抽象,BK Client 的读写操作也都是以 Ledger 为粒度的;
- Fragment:bookie的最小分布单元(实际上也是物理上的最小存储单元),也是 Ledger 的组成单位
- Entry:每条数据都是一个 Entry,它代表一个 record,每条 record 都会有一个对应的 entry id。这里数据的内容对应到消息上的话,如果是单条消息发送,每条消息对应一个entry,如果是批量消息发送的话,批量消息对应一个entry。
当broker与bookie建立连接后,会通过BK Client新建一个Ledger,这个Ledger包含一些元数据,包括:
- 状态,是open还是close
- Last Entry ID:关闭状态时,最后一个EntryID是多少
- Ensemble Size, Write Quorum Size, Ack Quorum Size,即ledger可操作的bookie数、写入bookie数和收到ack的bookie数,下文会细讲
- Ensembles:Ledger所在的bookies列表
后续Entry的发送,会挂在这个Ledger当中。当entry数达到Ledger配置的存储空间大小、最大entry数阈值等条件时,会关闭这个Ledger,重新新建一个Ledger。
多副本存储
Pulsar的消息以日志的形式存储在bookie中,日志又被分为多个Segment(Segment与Ledger概念类似,Segment是Pulsar的概念,Ledger是BookKeeper的概念。Pulsar可将Segment的数据脱离BookKeeper,存放在S3等存储介质中,但本文不讨论这种场景,因此可认为本文说的Segment和Ledger是同一个东西),均匀地分布在bookie集群中的多个bookie中。
如图所示为segment分段存储到bookie的示意图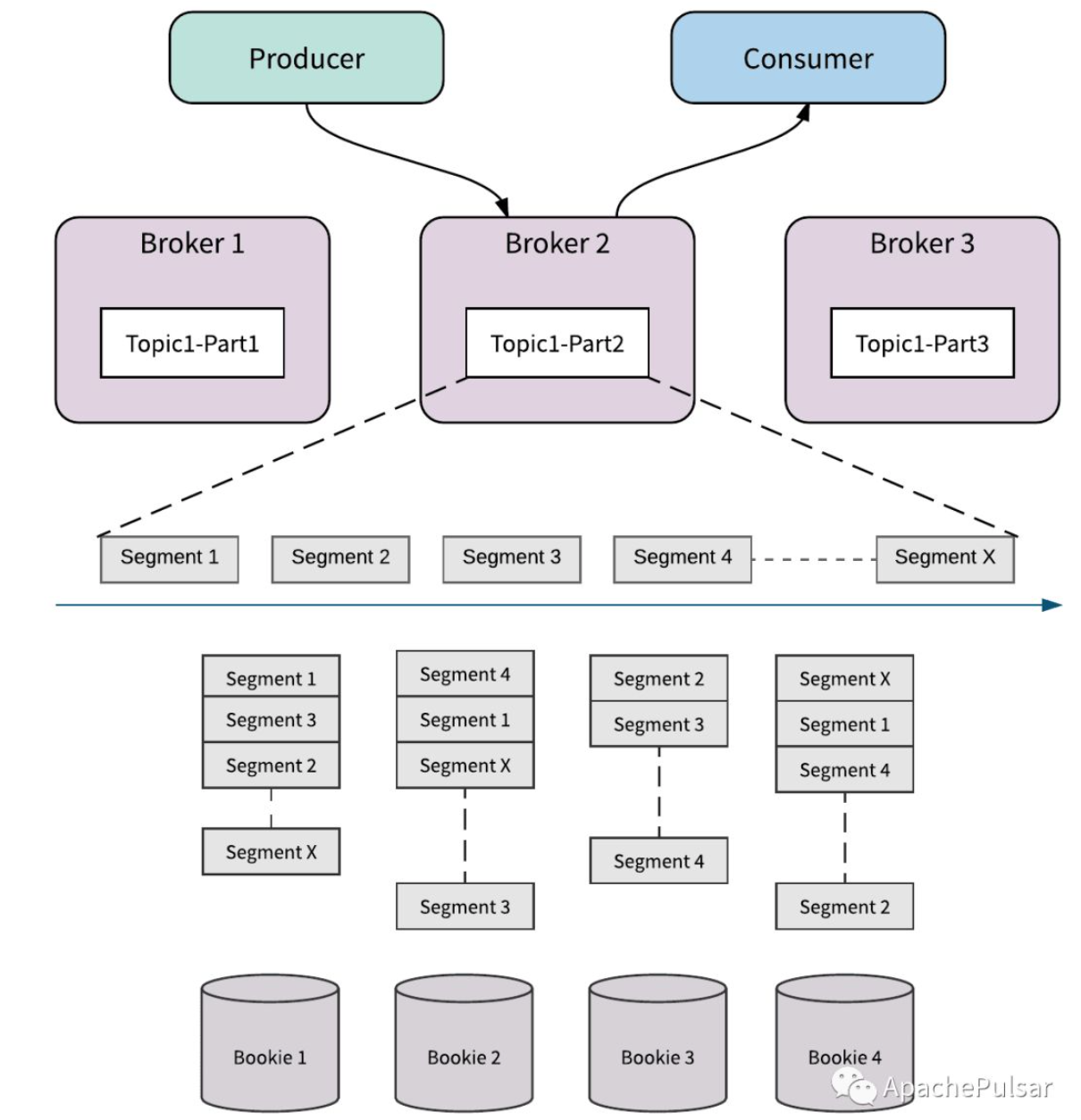
在这里,再看Ledger中的元数据Ensemble Size, Write Quorum Size, Ack Quorum Size:
- Ensemble Size:可供Segment存储选择的Bookie数。如图的Ensemble Size是4,即有4个bookie可以选择存储。Ensemble Size可以控制Ledger的读写带宽,如增加Ensemble Size,就是增加了可写的机器数
- Write Quorum Size:Segment存储的bookie数,如图,每个Segment存储在3个bookie上。Write Quorum Size可以控制数据的副本数,即与可用性相关。
- Ack Quorum Size:需要等待的Bookie Ack 数。如可以配置为2,对于Segment1来说,只要bookie1、bookie2、bookie4当中两个返回ack,就认为Entry存储成功。它的作用是可以减少尾延效应。
Bookie扩容
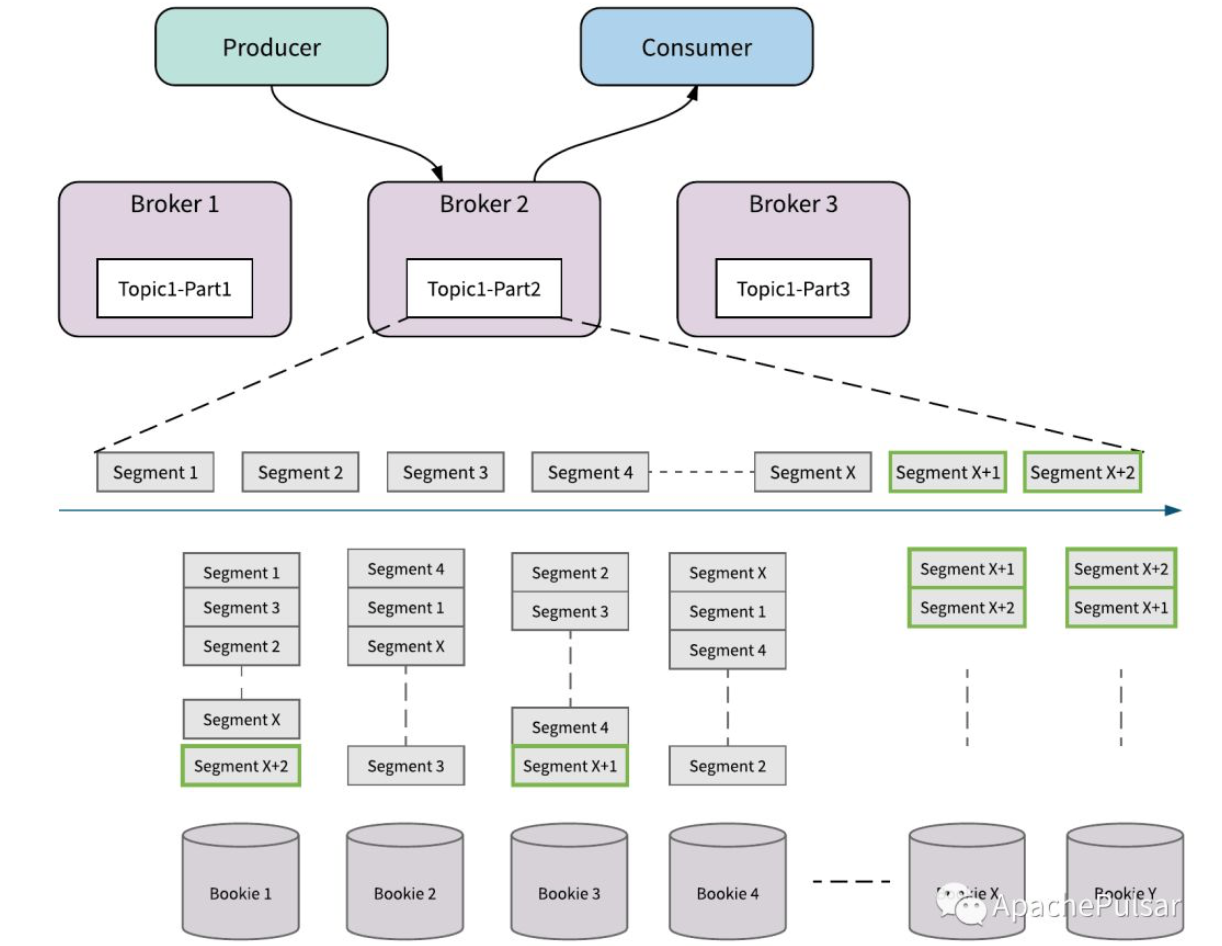
如图所示,增加了BookieX和BookieY,Topci1-Part2在写到SegmentX+1、SegmentX+2的时候,会将Segment放入新的bookie中,新的bookie也就被利用起来。这里没有任何的数据复制,没有像kafka的rebalance过程。
Bookie故障处理
如图有一个磁盘故障导致Bookie2上的Segment4被破坏,BooKeeper后台会检测到这个错误并进行复制修复。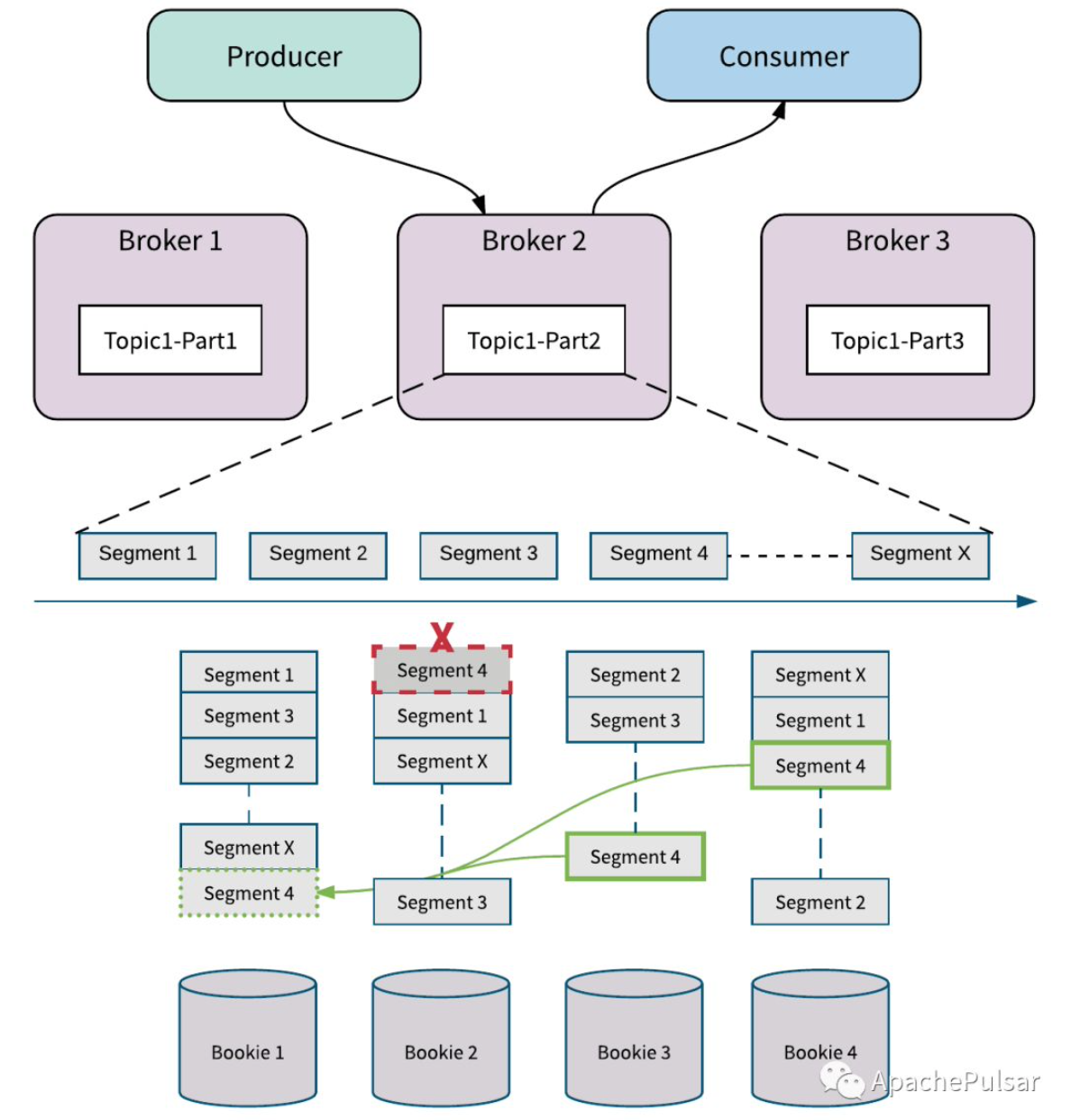
副本修复是Segment(甚至是Entry级别)的修复,并且只复制必须的数据,如图BookKeeper从Bookie3和Bookie4读取Segment4中的数据,并修复到Bookie1中。
对于整个Bookie节点出错的情况,首先由于有副本的存在,Broker可以继续进行接入和读取消息。其次在后台会有一个AutoRecoveryMain线程,将数据复制到Bookie1上,这样就完成了故障修复。
对比kafka的优势
存储扩展能力
kafka在存储上的特点:
- 在单个节点上的存储是以topic的partition为单位,这意味着每个Partition副本都必须完整的存储在kafka节点上,这就要求单个节点必须有足够的磁盘空间来处理副本,因此非常大的副本可能会迫使你是用非常大的磁盘。
- 在集群扩展时必须做Rebalance,将数据复制到其它的节点上,这个过程是比较痛苦的,需要良好的计划和执行来保证没有任何故障。
而对于Pulsar来说,是以Ledger为存储单元,Ledger的容量是可定义的。topic消息的存储由一个个的Ledger组成,Ledger可分配到不同的Bookie中。当存储扩展时,新的Ledger也可分配到新的Bookie当中去,没有Rebalance的数据复制过程带来的复杂度。
参考链接
- https://pulsar.apache.org/
- https://github.com/streamnative/tgip-cn
- http://matt33.com/2019/01/28/bk-store-realize/
- ApachePulsar公众号
- StreamNative公众号

若有收获,就点个赞吧
0 人点赞
