贪婪模式?
原字符
\
| 将下一个字符标记为一个特殊字符、或一个原义字符、或一个 向后引用、或一个八进制转义符。例如,’n’ 匹配字符 “n”。’\n’ 匹配一个换行符。序列 ‘\\‘ 匹配 “\“ 而 “\(“ 则匹配 “(“。 |
|
^
$
匹配输入字符串的结束位置。如果设置了RegExp 对象的 Multiline 属性,$ 也匹配 ‘\n’ 或 ‘\r’ 之前的位置。
*
| 匹配前面的子表达式零次或多次。例如,zo 能匹配 “z” 以及 “zoo”。 等价于{0,}。 |
|
.
匹配除换行符(\n、\r)之外的任何单个字符。要匹配包括 ‘\n’ 在内的任何字符,请使用像”(.|\n)“的模式。
?
匹配前面的子表达式零次或一次。例如,”do(es)?” 可以匹配 “do” 或 “does” 。? 等价于 {0,1}。
+
| 匹配前面的子表达式一次或多次。例如,’zo+’ 能匹配 “zo” 以及 “zoo”,但不能匹配 “z”。+ 等价于 {1,}。 |
|
{n,}
| n 是一个非负整数。至少匹配n 次。例如,’o{2,}’ 不能匹配 “Bob” 中的 ‘o’,但能匹配 “foooood” 中的所有 o。’o{1,}’ 等价于 ‘o+’。’o{0,}’ 则等价于 ‘o*’。 |
|
{n,m}
| m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。例如,”o{1,3}” 将匹配 “fooooood” 中的前三个 o。’o{0,1}’ 等价于 ‘o?’。请注意在逗号和两个数之间不能有空格。 |
|
————————————————————————————————————

\b
| 匹配一个单词边界,也就是指单词和空格间的位置。例如, ‘er\b’ 可以匹配”never” 中的 ‘er’,但不能匹配 “verb” 中的 ‘er’。 |
|
\B
| 匹配非单词边界。’er\B’ 能匹配 “verb” 中的 ‘er’,但不能匹配 “never” 中的 ‘er’。 |
|
\d
\D
\f
\n
\r
\s
| 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。 |
|
\S
| 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 |
|
\t
\v
| 匹配一个垂直制表符。等价于 \x0b 和 \cK。 |
|
\w
| 匹配字母、数字、下划线。等价于’[A-Za-z0-9_]’。 |
|
\W
| 匹配非字母、数字、下划线。等价于 ‘[^A-Za-z0-9_]’。 |
|
———————————————————————————————————
x|y
| 匹配 x 或 y。例如,’z|food’ 能匹配 “z” 或 “food”。’(z|f)ood’ 则匹配 “zood” 或 “food”。 |
|
[xyz]
| 字符集合。匹配所包含的任意一个字符。例如, ‘[abc]’ 可以匹配 “plain” 中的 ‘a’。 |
|
[^xyz]
| 负值字符集合。匹配未包含的任意字符。例如, ‘[^abc]’ 可以匹配 “plain” 中的’p’、’l’、’i’、’n’。 |
|
[a-z]
| 字符范围。匹配指定范围内的任意字符。例如,’[a-z]’ 可以匹配 ‘a’ 到 ‘z’ 范围内的任意小写字母字符。 |
|
[^a-z]
| 负值字符范围。匹配任何不在指定范围内的任意字符。例如,’[^a-z]’ 可以匹配任何不在 ‘a’ 到 ‘z’ 范围内的任意字符。 |
|
单个字符匹配和连续字符匹配
单个匹配/[]/
连续匹配//
在中括号中,^意思是非xxx字符,不在则为以xxx字符开始
在中括号中,. 表示一个 . ,不在则匹配除换行符(\n、\r)之外的任何单个字符
若要使用原本意思,在符号前加\
引用型分组

这个在表达式中的引用叫做反向引用

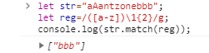

- 需要注意的是,如果引用了越界或者不存在的编号的话,就被被解析为普通的表达式
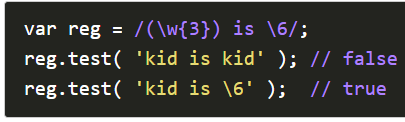
Replace()方法中引用,通过$number方式引用。

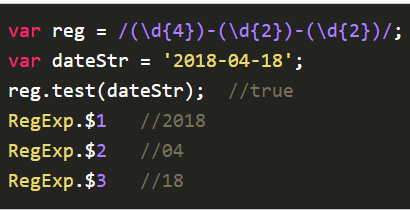
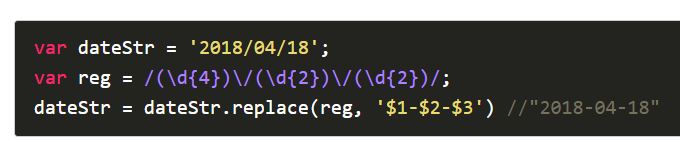

非引用型分组

(?:)表示非捕获分组,和捕获分组唯一的区别在于,非捕获分组匹配的值不会保存起来
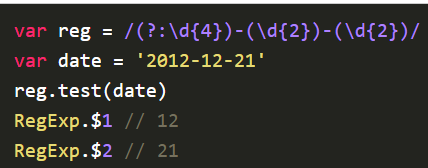
可选组
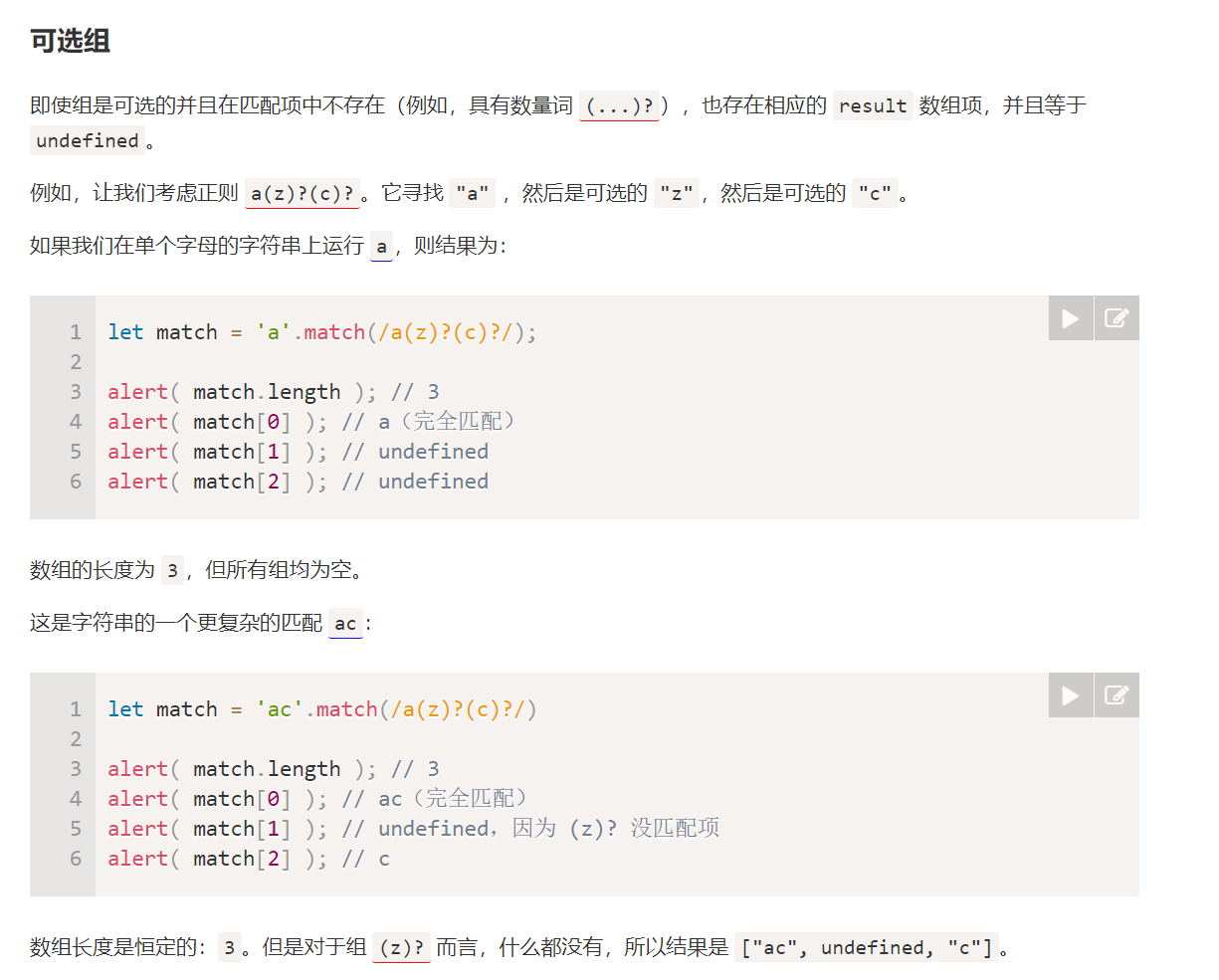
命名组
竖杠选择

特别说明:一旦发现有匹配成功的选项,那么立即终止对其他选项的尝试
零宽断言
正向:表示接下来的字符必须被匹配。
先行:表示匹配模式右侧的字符,表示一个方向。
零宽:表示必须满足匹配条件,但是并不会真正被匹配。
前瞻:正向先行零宽断言?=(右侧是)

“ant”的右侧必须存在一个字符”x”,但是我们并不真正匹配到”x”。

负前瞻:负向先行零宽断言?!(右侧不是)

表示紧接(右侧)的字符不能被匹配。
后顾:正向后行零宽断言?<=(左侧是)
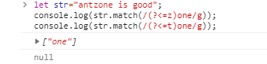
目的是要匹配字符串”one”,但是只会匹配它左侧字符为”z”或者”t”的”one”,否则匹配失败。
再强调一下,作为条件的字符并不会被纳入匹配结果。
负后顾:负向后行零宽断言?<!(左侧不是)
表示左侧字符不被匹配。

例子
^bucket$
这个模式与”Who kept all of this cash in a bucket”匹配,与”buckets”不匹配。字符 ^ 和 $ 同时使用时,表示精确匹配(字符串与模式一样)

