url输入和浏览器渲染:
url输入
从输入 URL 到页面加载完成的过程中都发生了什么事情?
大抵的过程可以简化为:
输入URL,发起请求:URL解析/DNS解析找到对应ip/服务器,网络连接:三次握手,服务器响应请求:返回数据 ,客户端接收响应:浏览器加载/渲染页面
dns解析优先级: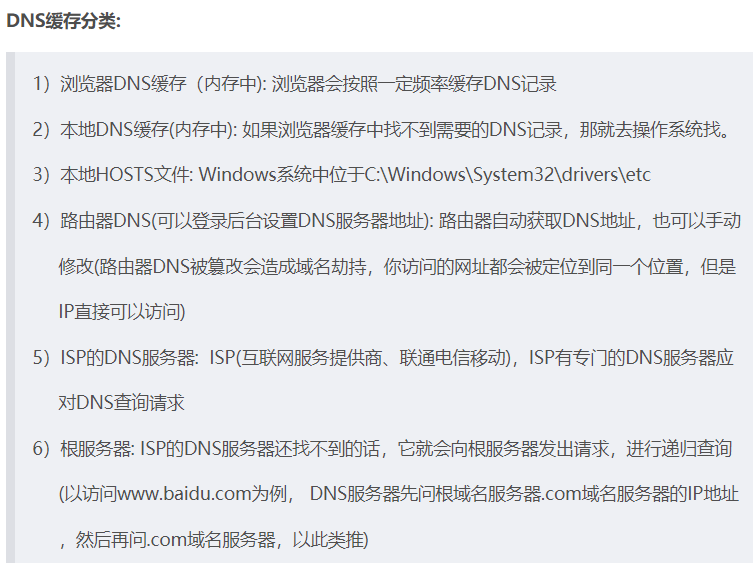
渲染机制
DOM树的构建、CSSOM树的构建、RenderObject树的构建、布局、绘制
l js执行会阻塞DOM的解析和渲染;
l CSS加载不会阻塞DOM树的解析;
l CSS加载会阻塞DOM树的渲染
l css加载会阻塞后面js语句的执行
http://www.pianshen.com/article/8659159470/
简单总结:
html需要等head中所有的js和css加载完成后才会开始绘制,但是html不需要等待放在body最后的js下载执行就会开始绘制,因此将js放在body的最后面,可以避免资源阻塞,同时使静态的html页面迅速显示。将脚本文件都放在网页尾部加载,还有一个好处。
html同样不会等待放在body最后的css加载完再绘制,只会等待head中的css。
将css放在head中可以使样式较快解析,使白屏时间尽量的短。head中css在解析完成之前,屏幕白屏。若放在body后,html解析完成后会先绘制在页面,css解析完成后会回流和重绘,造成起初没有样式,后续重刷闪烁。
head中的css和js是并行下载的,但按顺序解析。意味着js的执行,css的解析都会互相阻塞,同时也阻塞了dom渲染。
css加载不会阻塞html解析,会阻塞渲染。js下载会阻塞html解析。
1、如果遇到link和style,那就就会去下载这些外部的css资源,但是css跟DOM的构建是并行的,就是说不会阻塞DOM树的构建。
2、如果遇到script,那么页面就会把控制权交给JavaScript,直到脚本加载完毕或者是执行完毕。
3、页面的渲染是依靠render树,也就是说如果css没有加载完成,页面也不会渲染显示。
4、JavaScript执行过程中有可能需要改变样式,所以css加载也会阻塞JavaScript的加载。
5、JavaScript执行过程中如果操作DOM,但是DOM树又是在JavaScript之后才能构建,就会报错,找不到节点。
这就是HTML的渲染过程,因为DOM和css并行构建,我们会把css用外部引入,可以更快的构建DOM,因为JavaScript会阻塞DOM和css构建,且操作DOM一定要在DOM构建完成,我们选择把script放在最下面。
link引入外部css文件,放在head标签中和body标签中有什么区别
l 放在任何位置都是可行的,之所以推荐放在head标签里是因为浏览器代码解析是从上到下的。如果把css放在底部,当网速慢时,html代码加载完成后而css没加载完的话,会导致页面没有样式而难以阅读,所以先加载css样式能让页面正常显示。FOUC flash of unstyles content 产生原因是没有吧样式表放在head顶部,或者使用了@import导入(即便放在前面了,样式表还是会最后下载)
l css文件放head里面,防止布局错乱。当样式表晚于结构性html加载,当加载到此样式表时,页面将停止之前的渲染。此样式表被下载和解析后,将重新渲染页面,也就出现了短暂的花屏现象。
l js放body最后,防止js需要获取dom中的元素但dom还未构建,造成返回endefined或内容不显示。而且脚本放在头部会阻塞dom和cssom的构建,减慢页面呈现的速度。
移动端布局:
l Vw
l Viewport
l Rem
viewport标签仅被移动端浏览器支持
PC端浏览器的渲染窗口即为窗口大小减去额外浏览器自身元素
n 如果没有viewport标签,移动端浏览器会主以980像素的浏览器窗口渲染页面(即手机浏览器宽度为980px)
n 如果有,如果viewport写为width=X,则移动端浏览器就以Xpx为初始包含块渲染页面
n 如果写为width=device-width,则移动端浏览器会以出厂设置的宽度为初始包含块的宽度渲染,出厂设置的值一般来说与屏幕物理尺寸正相关,范围一般为320到400左右,目前最主流的是360
js获取屏幕宽度调整字体
function setRootFontSize() {
var width = document.documentElement.clientWidth || document.body.clientWidth;
if (width > 540) {
width = 540;
}
fontSize = (width / 10);
document.getElementsByTagName(‘html’)[0].style[‘font-size’] = fontSize + ‘px’;
}
setRootFontSize();
window.addEventListener(‘resize’, function() {
setRootFontSize();
}, false)
假定视觉稿宽度为X
Rem布局
使用rem布局结合在html上根据不同分辨率设置不同font-size有很多不好解决的麻烦,网易是如何解决的呢?最根本的原因在于,网易页面上html的font-size不是预先通过媒介查询在css里定义好的,而是通过js计算出来的,所以当分辨率发生变化时,html的font-size就会变。
它是根据什么计算的,这就跟设计稿有关了,拿网易来说,它的设计稿应该是基于iphone4或者iphone5来的,所以它的设计稿竖直放时的横向分辨率为640px,为了计算方便,取一个100px的font-size为参照,那么body元素的宽度就可以设置为width: 6.4rem。这个6.4怎么来的,当然是根据设计稿的横向分辨率/100得来的。于是html的font-size=deviceWidth / 6.4。这个deviceWidth就是viewport设置中的那个deviceWidth(非屏幕像素)。布局时,设计图标注的尺寸除以100得到css中的尺寸。根据这个计算规则,可得出本部分开始的四张截图中html的font-size大小如下:
最终计算式:100rem/640==Xrem/deviceWidth,每份单位在屏幕中占比相同
选100计算比较方便,量出像素值/100即为rem。
播放器高度为210px,写样式的时候css应该这么写:height: 2.1rem。之所以取一个100作为参照,就是为了这里计算rem的方便!
Html{font-size:device-width/(设计稿宽度 /100);}
Html { font-size:initial;}
https://www.cnblogs.com/Charliexie/p/6900640.html
对于针对移动端的页面,一般有两种情况:
1. 页面较复杂,希望页面在不同的手机上效果和比例一致([图片]mi.com移动端)
页面需要等比缩放,即视觉稿宽度跟浏览器/手机屏幕一样宽
且我们希望从视觉稿里测量出来的数据能直接用在代码里
所有用户的设备都支持设定视口宽度的产品来说,直接把视口宽度设置为视觉稿宽度,页面使用px为单位开发,数值直接从视觉稿量出来
l 对于并不是所有用户的设备都支持设定视口宽度的产品来说,我们同样希望视觉稿里测量出来的数据可以直接用在代码里,于是要找一个可以灵活缩放的单位(因为不同的手机窗口宽度不一样),让X倍的这个单位正好等于宽屏宽度
Xrem = 100vw
rem = (100vw / X)
html {font-size: calc(100vw / X)}有些浏览器不允许最小字号小于12px,而上面的公式算出来的值过小,会被重置,所以将其放大100倍,即
html {font-size: calc(ideal viewport / X 100)}
l 还有些浏览器不支持calc/vw,所以这个值通过js读取出浏览器视口的宽度并自行算出,然后设置到html元素上, 之后从视觉稿量出来的尺寸将小数点移动两位后加rem单位即可用在代码里。
2. 页面较简单,希望页面在更大的手机上显示更多的内容(github移动端)
直接使用device-width且使用px以及流式布局(块元素自动占满宽度)
3. 对于杂合形页面,即布局复杂,又有很多文字
布局使用rem,文字使用px,width=device-width
盒模型百分比
width和padding指为百分比时,基数是包含块(父级元素)content-box的宽度。
height指为百分比时,基数是包含块(父级元素)content-box的高度。
margin如果设为百分数,其基数是包含块(父级元素)content-box的宽度。不管是margin-top/margin-bottom还是margin-left/margin-right
外边距合并产生的条件:
(1).水平方位不可能产生外边距合并现象,垂直方位有可能出现。
(2).绝对定位(absolute/fixed)元素或者浮动元素不会出现外边距合并。
(3).相邻的外边距之间内容为空,这里的内容是指边框和内边距等。
上下块级元素的margin值会被合并,两正值留下较大的。
两负值留下绝对值较大的,然后较大绝对值的负margin线对齐另一块的零margin线。
正负均有时,正负各取绝对值较大的一个,然后求和,结果为正则有间距,为负则为重合。
解决方法:
父子元素:
可以为父元素定义1像素的上边框或上内边距。
可以为父元素添加overflow:hidden以及触发BFC的设置。
相邻元素:
设置自身为浮动/定位
将自身抱在一个新的父元素,触发父元素BFC,一般为overflow-hidden。
居中
block居中
水平居中
方法一:自身添加margin: 0 auto;
方法二:利用自身padding上下相等;
垂直居中
方法一:利用绝对定位,将top设为50%,同时将自身margin-top设为自身高度一半的负值。此时原有margin:0 auto失效,需重新设定left:50%,同时将自身margin-left设为自身高度一半的负值。
方法二:利用绝对定位,将top设为50%,同时将transform: translateY(-50%)。此时原有margin:0 auto失效,需重新设定left:50%,同时将自身margin-left设为自身高度一半的负值。transform: translateX(-50%)或合并为transform: translate (-50%,-50%)
方法三:利用相对定位,将top设为50%,同时将transform: translateY(-50%)。此时原有margin:0 auto不失效。
方法四:利用绝对位置来指定,但垂直居中的做法又和我们正统的绝对位置不太相同,是要将上下左右的数值都设为0,再搭配一个margin:auto,就可以办到垂直居中,不过要特别注意的是,设定绝对定位的子元素,其父元素的position必须要指定为relative喔!而且绝对定位的元素是会互相覆盖的,所以如果内容元素较多,可能就会有些问题。
Inline-block居中
水平居中
方法一:利用text-align: center可以实现在块级元素内部的内联元素水平居中。;
垂直居中
方法一:单行内联(inline-)元素垂直居中
通过设置内联元素的高度(height)和行高(line-height)相等,从而使元素垂直居中。一般配合vertical-align:middle使用。
方法二:使用伪元素,在子元素前加伪元素::before,将伪元素和需要居中的子元素vertical-align:middle且display:inline-block,为元素height:100%。
方法三:
浮动
浮动元素会生成块级框,成为行内块元素。
浮动元素不能超过所在父元素框顶端或兄弟浮动元素的顶端。
浮动的框可以向左或向右移动,直到它的外边缘碰到包含框或另一个浮动框的边框为止。浮动元素间是有占位关系的,即使不在同一父级元素内。
触发了BFC的元素,父级元素可将结构内浮动完整包裹。Overflow:hidden可满足这种效果。
由于浮动框不在文档的普通流中,所以文档的普通流中的块级元素表现得就像浮动框不存在一样。
Float浮动
l left 元素向左浮动。
l right 元素向右浮动。
l none 默认值。元素不浮动,并会显示在其在文本中出现的位置。
l inherit 规定应该从父元素继承 float 属性的值。
块级元素会忽视浮动,行内元素会围绕浮动。
浮动后,文字(span标签等行内元素)围绕浮动内容展示,不会被浮动元素压住。
但连续的字符或者数字,不会自动截断换行。
可修改文本的word-break属性。

清除浮动 和 闭合浮动的区别
清除浮动:对被影响文档位置的块级元素添加属性clear:left | right | both | none;,使其下移,直到元素两边没有浮动元素。
闭合浮动:更确切的含义是使浮动元素闭合,使父元素高度不再塌陷,高度被撑开了,使父元素能够包围浮动元素,从而减少浮动带来的影响。
Clear清除浮动
用于块元素
l left 在左侧不允许浮动元素。
l right 在右侧不允许浮动元素。
l both 在左右两侧均不允许浮动元素。
l none 默认值。允许浮动元素出现在两侧。
l inherit 规定应该从父元素继承 clear 属性的值。

Clear闭合浮动
l 触发bfc
u Overflow:hidden(无法显示要溢出的元素)
u 父元素Display: inline-block/table-cell/flow-root
u 父元素Position:absolute/fixed
u 父元素Float:left
l 在末尾使用一个行元素生成的行框将其撑高
u 缺点:会生成一个行框,有一定的高度。使用fontsize,lineheight0解决。
l 父元素标签用after伪元素,块级,clear:both。推荐使用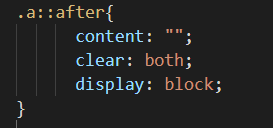
l 额外标签法(在最后一个浮动标签后,新加一个标签,给其设置clear:both;)(添加无意义标签,语义化差,不推荐)
定位
Position:
/static(默认值,不定位,在常规流)
/fixed(相对于视窗固定,定位的元素会脱离常规流)
/relative(相对定位,基准是自己原来的位置,原来的位置会保留,还在常规流)
/absolute(绝对定位,定位的元素会脱离常规流,定位基准是最近的定了位的祖先元素的padding-box,以及自身的margin-box,若无则以html的margin-box为基准(第一屏))
/sticky(sticky综合了 static,rel ative,fxed几种定位方式,元素即将从视口的某个方向离开时,该方向以fixed定位,当元素的某一方要离开其包含块时,随其包含块离开。
无论何种情况,元素在常规流中的位置保留)
z-index:越大越靠上,为负时被常规流盖住。相同时后盖前。当祖先及后代都定位时,后代的z-index失效
元素的方位:top left right bottom。以上值为正时,该方向向元素中心方向移动即top为正为向下移动,为负向上移。left为正时向右移动,为负时向左移动。取百分比时,百分比相对于包含块(或定位祖先)的content-box的对应尺寸。
Flex布局
可以将任意元素设置为弹性布局,弹性布局会对其内部的子元素产生影响:
(1).块级元素不再单独占据一行。
(2).如果块级元素没有显式规定宽度,也不会横向铺满父元素。
(3).float、clear和vertical-align属性会失效。
正是因为打破一些原有的规则,所以弹性布局会在一些场景下非常的灵活强大。
flex-direction(应用于容器)
l .row:默认值,默认主轴是水平的,并且左侧为main start,也就是起始位置。
l .row-reverse:与row类似,主轴是水平的,但是方向相反,也就是右侧为main start。<—
l .column:主轴为垂直方向,上侧为main start。V
l .column-reverse:主轴为垂直方向,下侧为main start。^
flex
三个属性的省略值
flex-wrap:(应用于容器)
l nowrap:默认值,不进行换行,item自动收缩以适应。
l .wrap:如果排列不开会自动换行,换行方式默认,自动转到下一行
l .wrap-reverse:很容易猜测,这个顺序是反的
flex-flow属性:(应用于容器)
上面两个属性的简写形式,可以认为是一个复合属性。
默认属性值是row nowrap。
justify-content(应用于容器)
l .flex-start:默认值,规定项目从主轴的main start位置开始排列。
l .flex-end:规定项目从主轴的main end位置开始排列。
l .center :规定项目在主轴上居中排列。
l .space-between:规定项目在主轴上两端对齐,且项目之间间隔均匀。
l .space-around:规定项目在主轴方向两侧持有相同的空间,类似于外边距
align-items(应用于容器)
l .flex-start:规定从交叉轴cross start方向开始排列。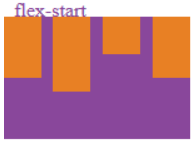
l .flex-end:规定从交叉轴cross end方向开始排列。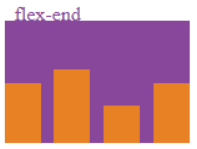
l .center:规定项目在交叉轴中心点对齐。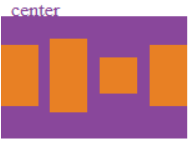
l .baseline:根据项目第一行文本的基线对齐。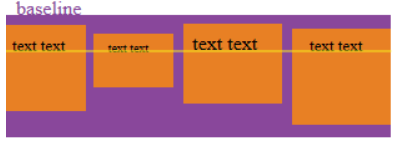
l .stretch:默认值,如果项目未设置高度或设为auto,将占满整个容器的高度。
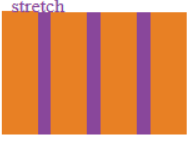
align-content(应用于容器)
l .flex-start:规定从交叉轴cross start方向开始排列。
l .flex-end:规定从交叉轴cross end方向开始排列。
l .center:规定项目在交叉轴中心点对齐。
l .space-between:规定与交叉轴两端对齐,轴线之间的间隔平均分布。
l .space-around:规定项目在交叉轴方向两侧持有相同的空间,类似于外边距。
l .stretch:默认值,占满整个容器的交叉轴的高度
align-items和align-content的区别
align-content:center对单行是没有效果的,而align-items:center不管是对单行还是多行都有效果,而在我们日常开发中用的比较多的就是align-items.(其可以配合align-self实现align-content)









align-content在于将容器空间作为整体,子级作为零散部件来布局。
align-items:在于将子级作为局部整体,将容器空间分配给子级来布局。
Order(items属性)
属性值是数值类型,数值越小,排列越靠前,就和考试名次一样,默认值为0。
flex-grow(items属性)
此属性可以定义项目放大的倍数。
默认值为0,也就是不放大,当然放大必须有在父元素有多余空间的条件下。
根据父级元素空余空间和子元素属性值比例进行放大。大于1时(如1,3,1)将剩余空间按份数分,小于一时(如0.1,0.3,0.2),将剩余空间的0.6按比例分,保留余下的0.4剩余空间。
flex-shrink(items属性)
此属性就是用来定义缩小倍数的,默认值为1,如果空间不足则自动缩小。
类似flex-grow,只不过变成缩小量。同时权重与自身宽度/高度有关。若父级元素宽400,共4个子元素,分别为200,100,100,100。若flex-shrink均为1,则第一个子元素的伸缩量为(500-400)/5*2,其余为(500-400)/5。
flex-basis(items属性)
l .number:长度单位或者百分比,规定flex项目的初始长度。
l .auto:默认值,长度等于flex项目本身长度,如果项目未指定长度,根据内容决定。
l .initial:flex项目默认方式显示
l .inherit:从父元素继承该属性。
Flex-basis与width的区别:
flex-basis属性优先级高于width属性,所以在弹性布局中只使用flex-basis属性即可。
flex-basis实质上规定的是主轴方向,项目的尺寸,并不能一概以宽度来论,因为主轴不但可以水平方位,也可以是垂直方位,width则是实实在在规定元素的宽度。
flex-basis属性并不能为所欲为,它的最大值和最小值可以被max-width与min-width两个属性限制。
align-self(items属性)
align-items属性在容器元素上设置,作用于所有项目,是面的设置。
align-self属性在项目元素上设置,作用于当前项目,是点的设置。
l auto:默认值,继承弹性容器的align-items属性值,如果弹性容器未设置align-items,默认值为stretch。
l stretch:规定项目被拉伸以使用容器在交叉轴上的尺寸。
l center:规定项目在行中交叉轴方向居中对齐。
l flex-start:规定项目在行中交叉轴方向起始位置对齐。
l flex-end:规定项目在行中交叉轴方向结束位置对齐。
l baseline:规定项目在所在行中基线对齐。
in,of,对象,数组
l for…in 语句以任意顺序迭代对象的可枚举属性。
for in会遍历数组所有的可枚举属性,包括原型。
整数属性有顺序,其他是按照创建的顺序
我们把整数属性转换成非整数的,在前面增加一个 “+” 就可以按照创建顺序列举。
l for…of 语句遍历可迭代对象定义要迭代的数据。(数组的遍历器接口只返回具有数字索引的值)
具有迭代器的数据结构Set。Map。字符串。TypedArray。
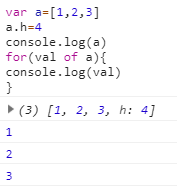
对象

Object.keys方法只能遍历自己的对象上的可枚举的属性,不能遍历自己原型上可枚举的属性。
整数属性有顺序,其他是按照创建的顺序
我们把整数属性转换成非整数的,在前面增加一个 “+” 就可以按照创建顺序列举。
l Object.defineProperty(obj, prop, descriptor)
ü Obj:要在其上定义属性的对象。
ü Prop:要定义或修改的属性的名称。
ü Descriptor:将被定义或修改的属性描述符。
ü Configurable:当且仅当该属性的 configurable 为 true 时,该属性描述符才能够被改变,同时该属性也能从对应的对象上被删除。默认为 false。
ü Enumerable:当且仅当该属性的enumerable为true时,该属性才能够出现在对象的枚举属性中。默认为 false。
ü 
delete
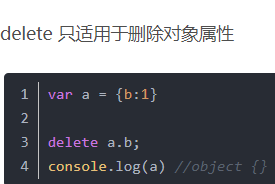
数组
l Array.prototype.includes() includes() 方法用来判断一个数组是否包含一个指定的值,根据情况,如果包含则返回 true,否则返回false。
可以判断NaN,null
l concat() 连接两个或更多的数组,并返回结果。
l Array.prototype.flat() 方法会按照一个可指定的深度递归遍历数组,并将所有元素与遍历到的子数组中的元素合并为一个新数组返回。
find方法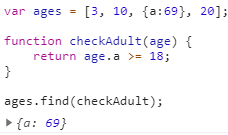
findIndex返回第一个的索引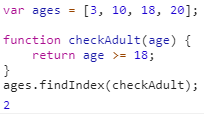
For In /for of/includes/indexOf/
使用for in会遍历数组所有的可枚举属性,包括原型。
所以for in更适合遍历对象,不要使用for in遍历数组。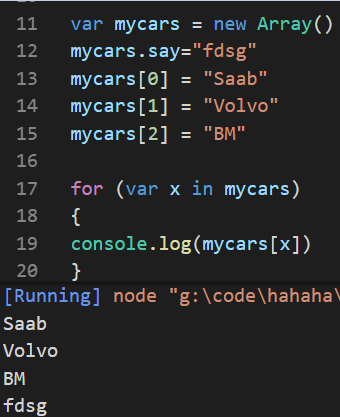
for..of适用遍历数/数组对象/字符串/map/set等拥有迭代器对象的集合.但是不能遍历对象,因为没有迭代器对象
for of遍历的只是数组内的元素,而不包括数组的原型属性method和索引name
Includes()可判断NaN是否存在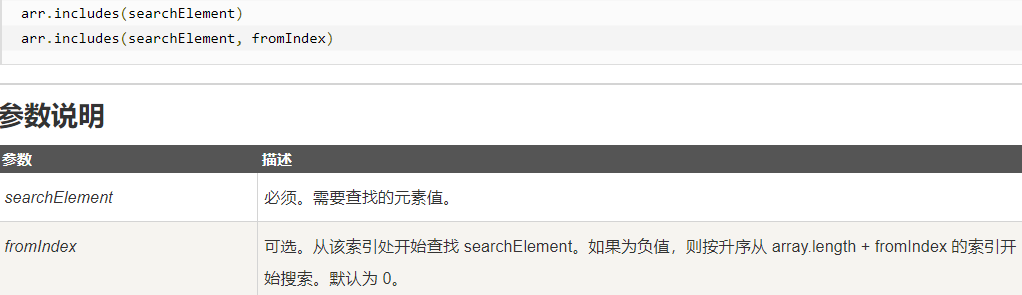
indexOf()无法判断NaN的下标(会返回-1)
箭头函数
没有 “this”
不具有 this 自然意味着另一个限制:箭头函数不能用作构造函数。
他们不能用 new 调用。
有原型,没有原型属性(原型属性认为用于构造实例,箭头函数不能构造实例,所以没有prototype??)
没有 “arguments”(参数)
箭头函数不能用作Generator函数。
数据类型,Typeof,Object.toString,instanceof


类型转换
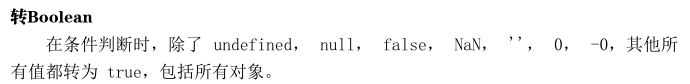
Typeof
特殊的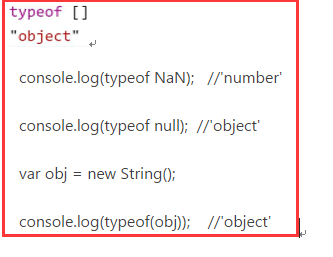
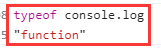
typeof运算符用于判断对象的类型,但是对于一些创建的对象,它们都会返回’object’,适用于判断原始类型(undefined、Boolean、number、string), 对象(object)和函数(function)。
数组,null等被判定为”object”
还有两个symbol和Implementation-dependent我觉得可以忽略。
Object.prototype.toString
若想根据toString方法判断类型,可跳过自身自有和原型属性中的toString方法,如下:(此方法也可用于当原型方法被覆盖时,调用原型方法)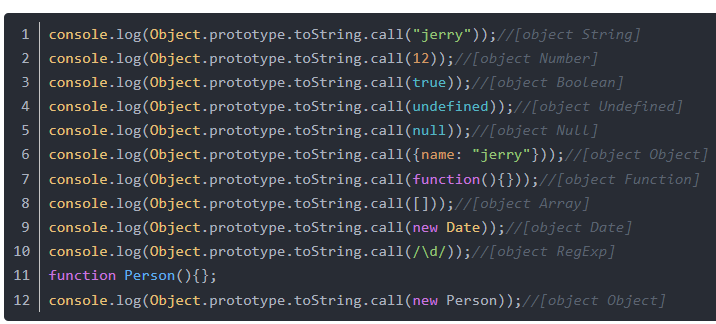
Object.prototype.toString.call()大多数时候可以精准判断对象类型,相较typeof可以主要针对Object类型和null及进行判断
Object.prototype.toString 用来判断内置对象类型
Instanceof
可以判断对象是否是指定构造函数的实例(逐级向上),如果是则返回true,否则返回false。
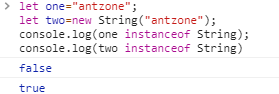
通常来讲,通过构造函数创建的对象应用instanceof运算符才会返回true。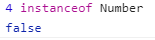
但是数组直接量和对象直接量是例外
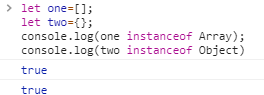
instanceof 用来判断自定义对象类型
闭包
闭包就是能够读取其他函数内部变量的函数


//引用特定局部变量实例的功能叫做闭包。
通常,函数的作用域及其所有变量都会在函数执行结束后被销毁。但是,在创建了一个闭包以后,这个函数的作用域就会一直保存到闭包不存在为止。

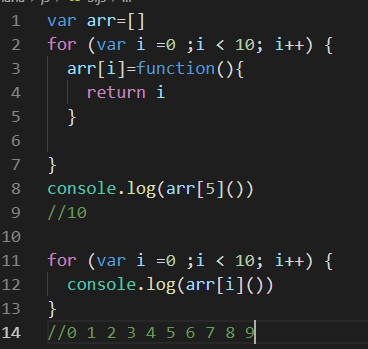
当arrFunc执行完毕后,其作用域被销毁,但它的变量对象仍保存在内存中,得以被匿名访问,这时i的值为10。(若其所在最近作用域有非闭包i,则其为作用域中的i值)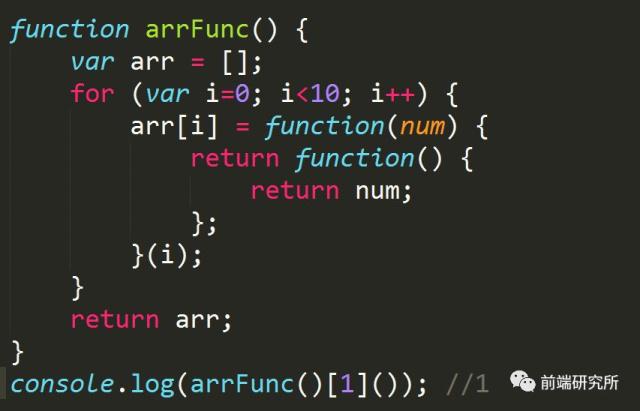
这时最内部的匿名函数访问的是num的值,所以数组中10个匿名函数的返回值就是1-10。
闭包中的this对象
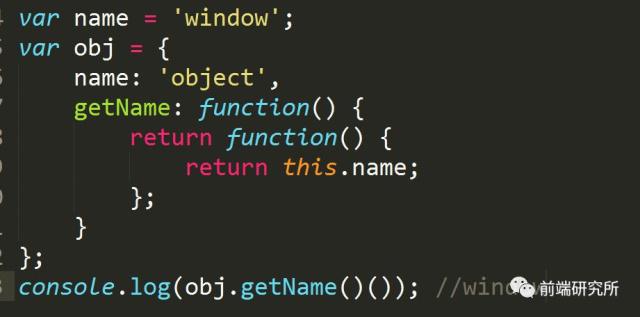
在上面这段代码中,obj.getName()()实际上是在全局作用域中调用了匿名函数,this指向了window。
如果想使this指向外部函数的执行环境,可以这样改写: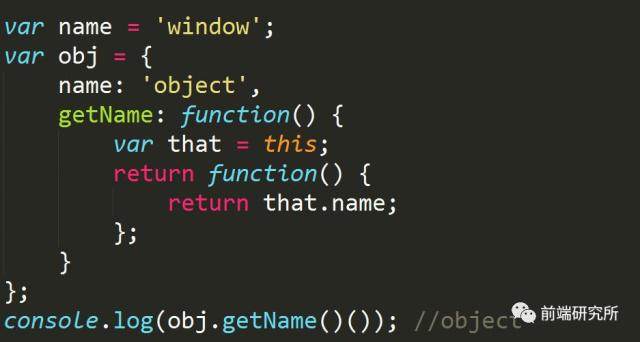
内存泄漏&垃圾回收
一般来说没有被引用的对象就是垃圾,就是要被清除,
垃圾回收机制会定期(周期性)找出那些不再用到的内存(变量),然后释放其内存。
现在各大浏览器通常采用的垃圾回收机制有两种方法:标记清除,引用计数。
不再用到的内存,没有及时释放,就叫做内存泄漏。
内存泄露的几种情况
1、 当页面中元素被移除或替换时,若元素绑定的事件仍没被移除,在IE中不会作出恰当处理,此时要先手工移除事件,不然会存在内存泄露。
2、 在 Internet Explorer 中,如果循环引用中的任何对象是 DOM 节点或者 ActiveX 对象,垃圾收集系统则不会发现它们之间的循环关系与系统中的其他对象是隔离的并释放它们。最终它们将被保留在内存中,直到浏览器关闭。
3、 闭包可以维持函数内局部变量,使其得不到释放。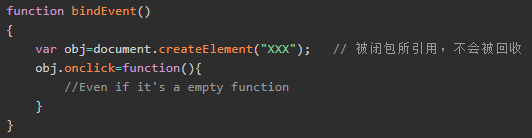 解决之道,将事件处理函数定义在外部,解除闭包
解决之道,将事件处理函数定义在外部,解除闭包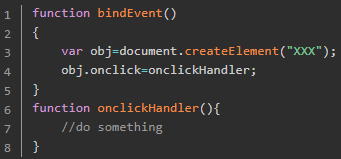
或者在定义事件处理函数的外部函数中,删除对dom的引用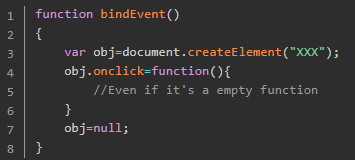
4、 被遗忘的计时器或回调函数

块级作用域&Let&const
l let: 会创建块级作用域, 不存在变量提升现象, 不允许在同一作用域重复声明变量, 全局作用域使用let声明的变量,不是全局属性
暂时性死区
l const:会创建块级作用域, 不存在变量提升现象, 不允许在同一作用域重复声明变量, 暂时性死区”,不允许在同一作用域内重复声明。不会成为全局属性。常量被声明后,值无法被改变,常量在声明的同时必须赋值
高阶函数




如果提供initialValue,则accumulator(总和)将等于initialValue,currentValue(当前值)将等于数组中的第一个元素。
如果没有提供initialValue,则accumulator将等于数组中的第一个元素,currentValue将等于数组中的第二个元素。
自实现高阶函数
map: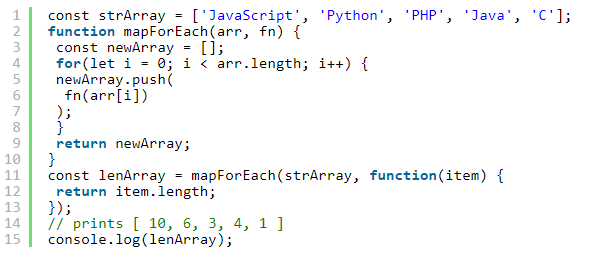
filter: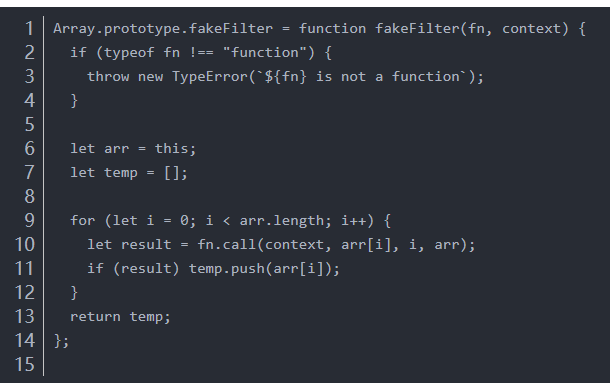
forEach:不能中断,以为return和break均只能设置在fn中,无法打断for循环。无法更改数据,因为fn是用形参接的数据。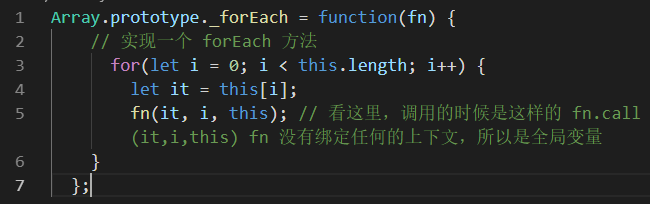
reduce: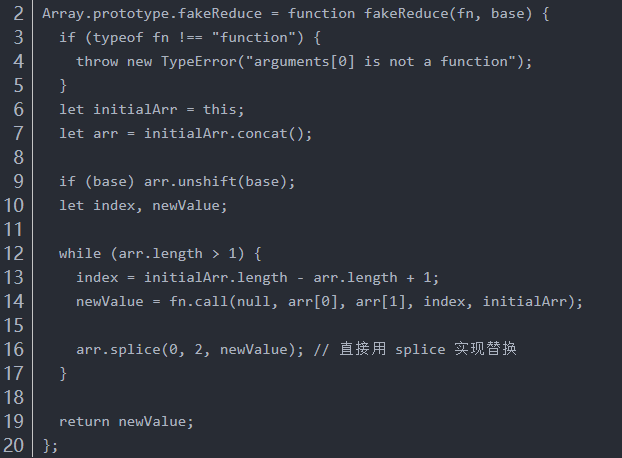
every()是对数组中每一项运行给定函数,如果该函数对每一项返回true,则返回true。
some()是对数组中每一项运行给定函数,如果该函数对任一项返回true,则返回true。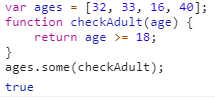
异步
异步原理:
avaScript虽然是单线程的,好像不能实现异步操作。
然而它的运行环境浏览器是多线程的,这是实现异步的决定性因素。
浏览器可以包含如下主要线程:
(1).JavaScript引擎。
(2).界面渲染。
(3).浏览器事件
(4).http(s)请求
下面是一张网络上比较关于此方面比较著名的图片: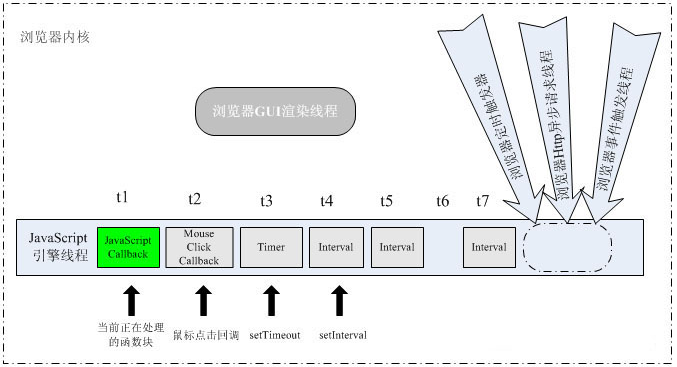

两个比较常见的JavaScript异步操作,一个是ajax操作,另一个是FileReader读取计算机文件。
原有的异步编程方式:
l 在ES2015之前,常见的异步编程方式有以下几种:
(1).回调函数。
(2).发布订阅。
“发布/订阅模式”(publish-subscribe pattern),又称”观察者模式”(observer pattern)。
(3).事件监听。
l ES2015新增异步编程方式:
(1).Promise对象(ES2015对其进行了标准化)。
(2).Generator 函数。
l ES2016新增:
Async/await
setTimeout(func,0)
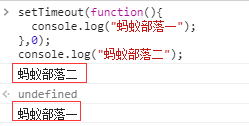
延迟实现为0,但是setTimeout是异步操作,所以首先打印’蚂蚁部落二”。

若有收获,就点个赞吧
0 人点赞
