- 数据加密是指以隐藏真实意图为目的的内容修改
13.1 分析加密算法的目的
- 分析目的:
- 隐藏配置信息
- 如:命令和控制服务器的域名
- 窃取之前将信息保存到临时文件
- 存储恶意代码需要使用的字符串,并在使用前对其解密
- 将恶意代码伪装成合法的工具,隐藏可疑的字符串
- 隐藏配置信息
- 分析目标:识别加密算法,进行解密
13.2 简单的加密算法
- 简单的加密技术常被用来隐藏内容, 从而让内容看起来 不明显、不可读
- 为什么还会使用简单加密?
- 它们容易被破解,但是,它们足够小,所以可以用在空间受限的环境中,如漏洞利用的shellcode
- 它们没有复杂加密算法那么明显
- 它们开销低,因此它们对性能几乎没有影响
- 是混淆而不是加密
- 它们使得识别数据变得困难,但不能免于被探测,只是用来阻止基本的分析(自动化分析)
- 凯撒密码
- 循环右移三位
- XOR
- 易于使用,加解密仅需单机器码指令
- 加密解密方法相同
- 数据: 0100 1000 0100 1001 秘钥: 0011 1100 0011 1100 结果: 0111 0100 0111 0101
- 暴力破解 XOR 加密:如果秘钥是一个字节,只有256个可能的秘钥
- 暴力破解多个文件:查找常见字符串,如:”This Program”,用每一个可能的XOR值生产原始字符串所有可能的排列,然后作为特征集合

- XOR 和空字节:
- 空字节暴漏了秘钥,因为0x00 XOR KEY = KEY,如果加密内容中有大量的NULL字节,那么单字节密钥变得十分明显
- 解决方法:
- 如果明文中字符是NULL或者密钥本身,跳过
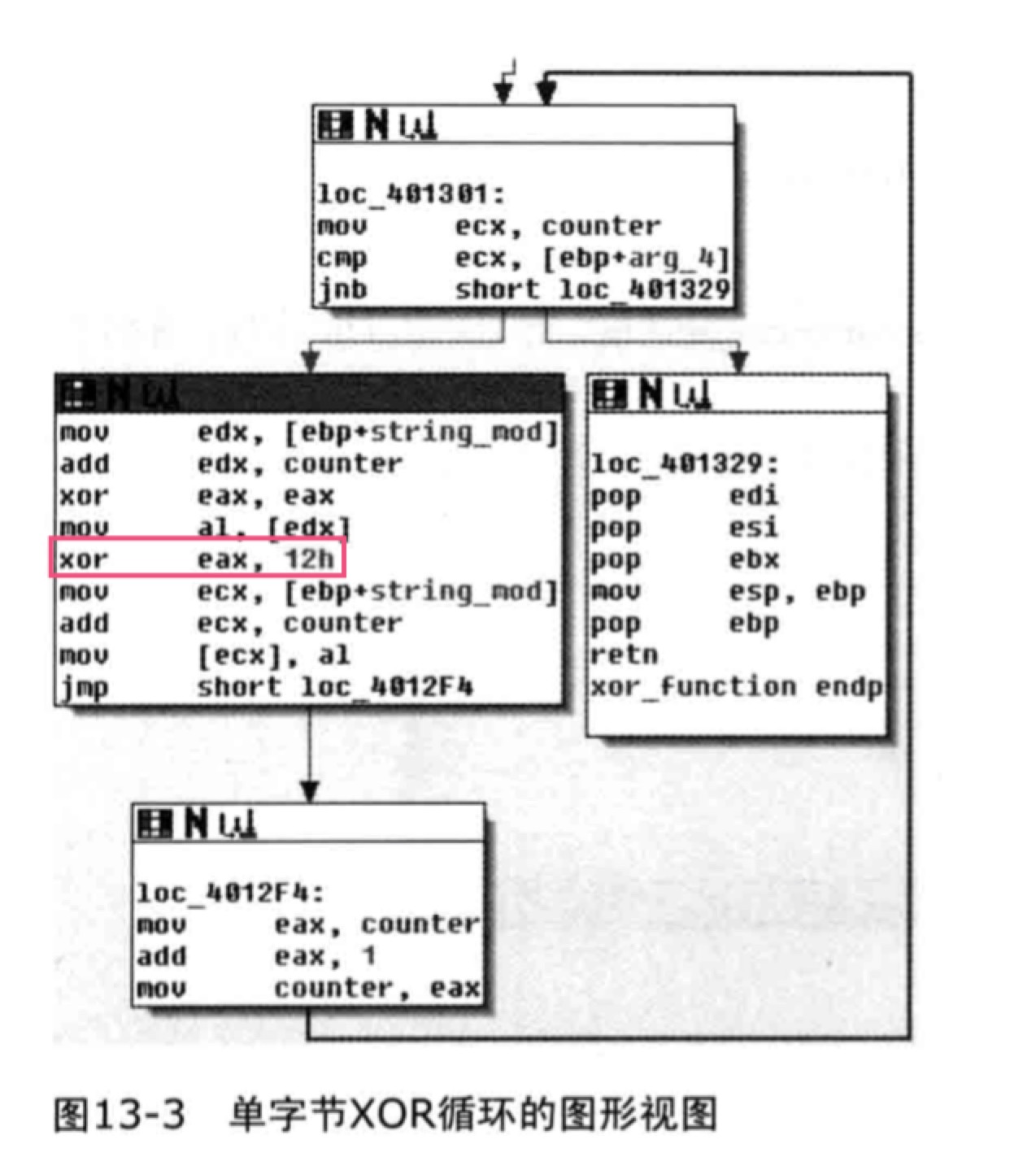
- 用IDA pro识别xor循环
- 小内循环内使用XOR指令
- 打开“IDAView”(查看代码)
- 选择Search->Text
- 输入xor并选中Findalloccurrences
- 搜索到XOR指令并不意味着它一定用于加密,XOR指令以三种形式存在
- 用一个寄存器XOR自身,如 xor edx, edx
- 寄存器清零的常用方式
- 用一个常数XOR一个寄存器或一个内存引用
- 可能是个加密循环,秘钥就是那个常数
- 使用一个寄存器或内存引用XOR一个不同的寄存器或内存引用
- 可能是一个加密循环,秘钥并不明显
- 可能是一个加密循环,秘钥并不明显
- 用一个寄存器XOR自身,如 xor edx, edx
- 其他一些简单的加密策略

- Base64
- 用ASCII字符串格式表示二进制数据,广泛用于HTTP和XML
- 原理:将二进制数据转换成64个字符的有限字符集,另外通常用一个额外字符表示填充,通常是“=”
- 最常用的字符集是MIME Base64,它使用 AZ、az和0~9作为前62个值,+和/作为最 后两个值。 =表示填充
- 数据转化成base64:
- 把三个字节(3x8=24位)构成的块,分成四个字节(4x6)构成的块,把每一个块转换成Base64(通过十进制索引参 考字符串得出字符:ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/ )
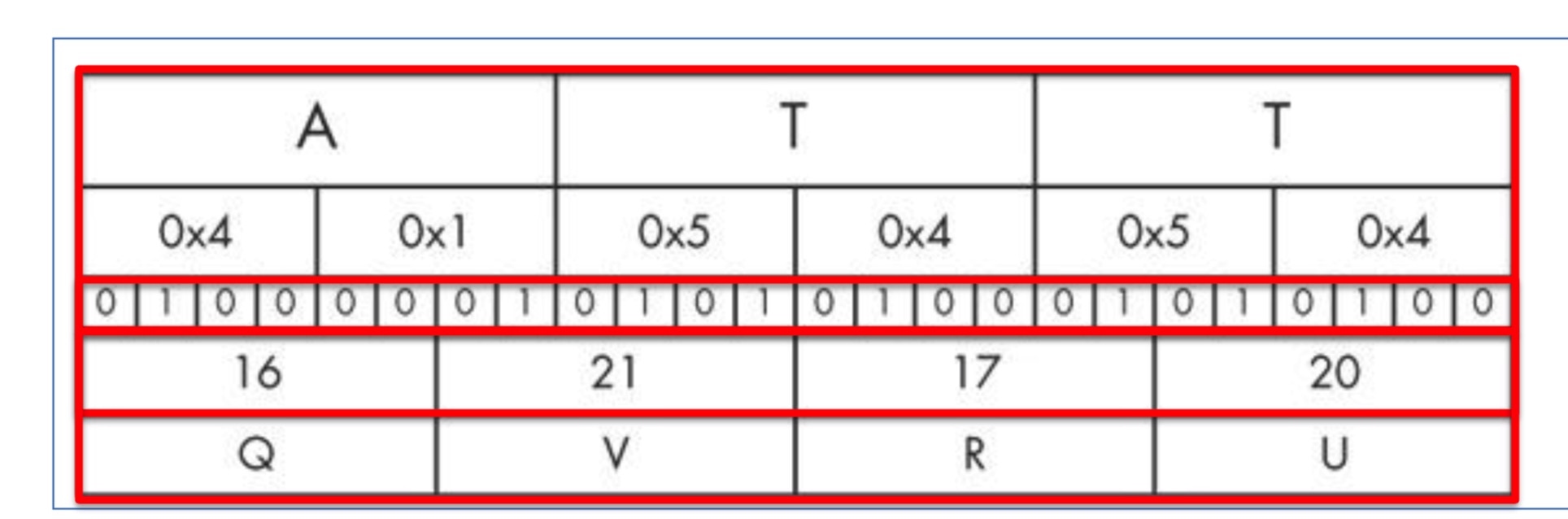
- 把三个字节(3x8=24位)构成的块,分成四个字节(4x6)构成的块,把每一个块转换成Base64(通过十进制索引参 考字符串得出字符:ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/ )
- 将base64解密
- 每个字符转换成6个比特位放在一起,8个一组读取,表示原来的字节
- 解密时如果位数不对尝试用“=”(填充字符)填充后再解密
- 有时会使用自定义的字符集
- 查找Base64加密函数
- 先查找实现算法常用的64字节长度的字符串。因为base64加密的实现通常使用索引字符串,所以含有base64加密的代码经常会存在这个64字符组成的加密字符串
- 查找单独的填充字符(常为=),该字符被 硬编码到函数中
13.3 现代加密算法
- 现代的加密算法考虑了增加指数级的计算能力,并且确保设计的算法需要大量的计算能力,从而使破解它们不切实际
- 优点:足以抵抗暴力攻击
- 缺点:
- 需要很大的加密库
- 降低代码的可移植性
- 标准加密库容易被探测出来
- 通过函数导入表、函数匹配或加密常量识别
- 对称加密需要隐藏秘钥
- 识别标准加密方法——识别字符串和导入表
- 一种识别标准加密算法的方法是识别涉及加密算法使用的字符串。
- 例如:采用OpenSSL加密的恶意代码中发现的字符串
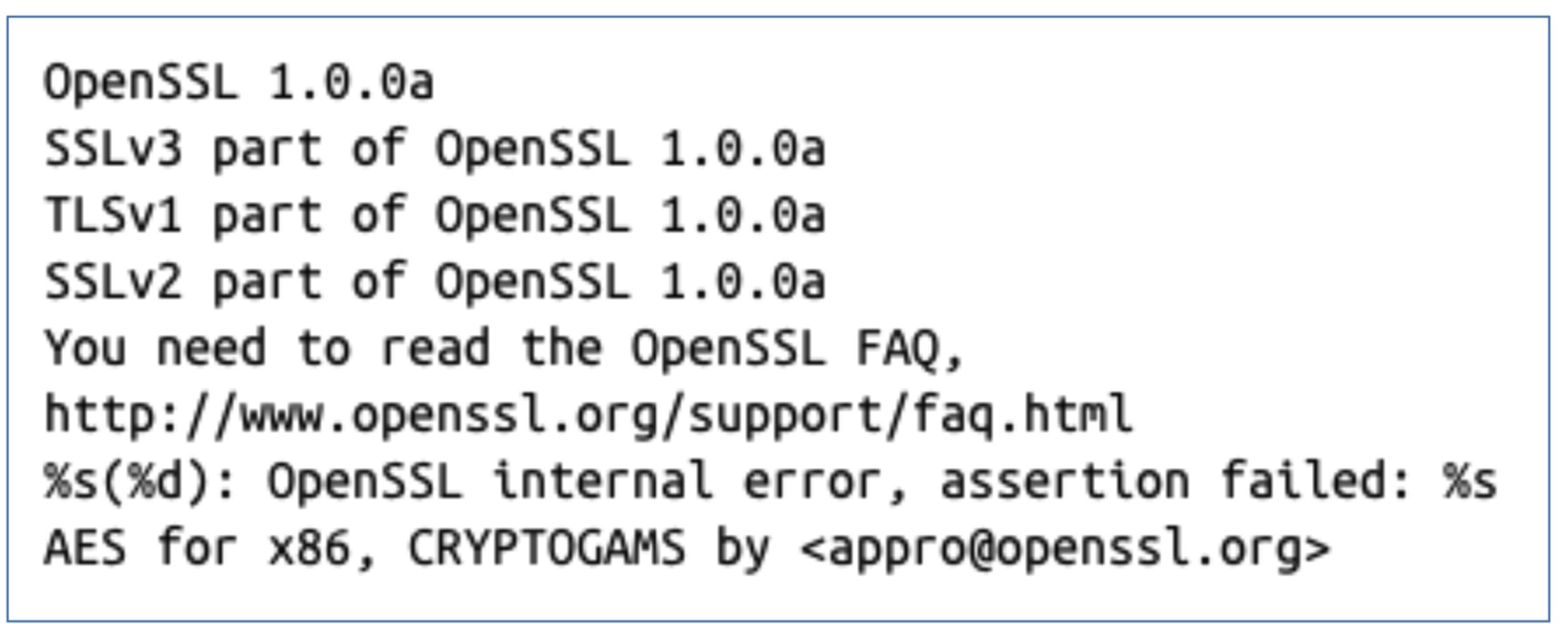
- 例如:采用OpenSSL加密的恶意代码中发现的字符串
- 另一种是识别引用表导入的加密函数
- 大多以Crypt、CP、Cert为前缀
- 一种识别标准加密算法的方法是识别涉及加密算法使用的字符串。
- 识别标准加密方法——查找加密常量
- IDAPro的FindCrypt2插件
- 查找神秘的常量 (Magic Bytes,与基本加密算 法结构相关的一些固定位串,可作为加密例程的二进制特征)
- 无法找到RC4 或IDEA 例程,因为它们没有使用 神秘的常量
- RC4常被恶意代码使用,因为它小且易于实现,并且没有明显的加密常量
- RC4是对称加密算法,解密和加密使用相同的密码;RC4是伪随机密码生成算法,相同原文和密码生成 的密文通常每次均不一样;通常使用RC4加密后,再用Base64编码为可见字符
- Krypto ANALyzer (PEiD 插件)
- 拥有一个比FindCrypt2范围更广的常量集合,但是易产生误报
- 还能识别Base64 编码表和加密相关的导入 函数
- IDAPro的FindCrypt2插件
- 识别标准加密方法——查找高熵值内容
- 熵表示混乱程度
- 计算熵,只需要从0到255每个字节出现的 次数,计算每个字符出现的概率Pi ,然后从0到255对Pilog2Pi求和,最后取相反数
- 如果所有字节出现概率相同,熵就是8 (-log21/256=8,最大混乱度,熵最高)
- 如果所有的字节相同,为有序状态,熵为0
- 查找高熵内容
- IDAPro的熵插件,熵图绘制
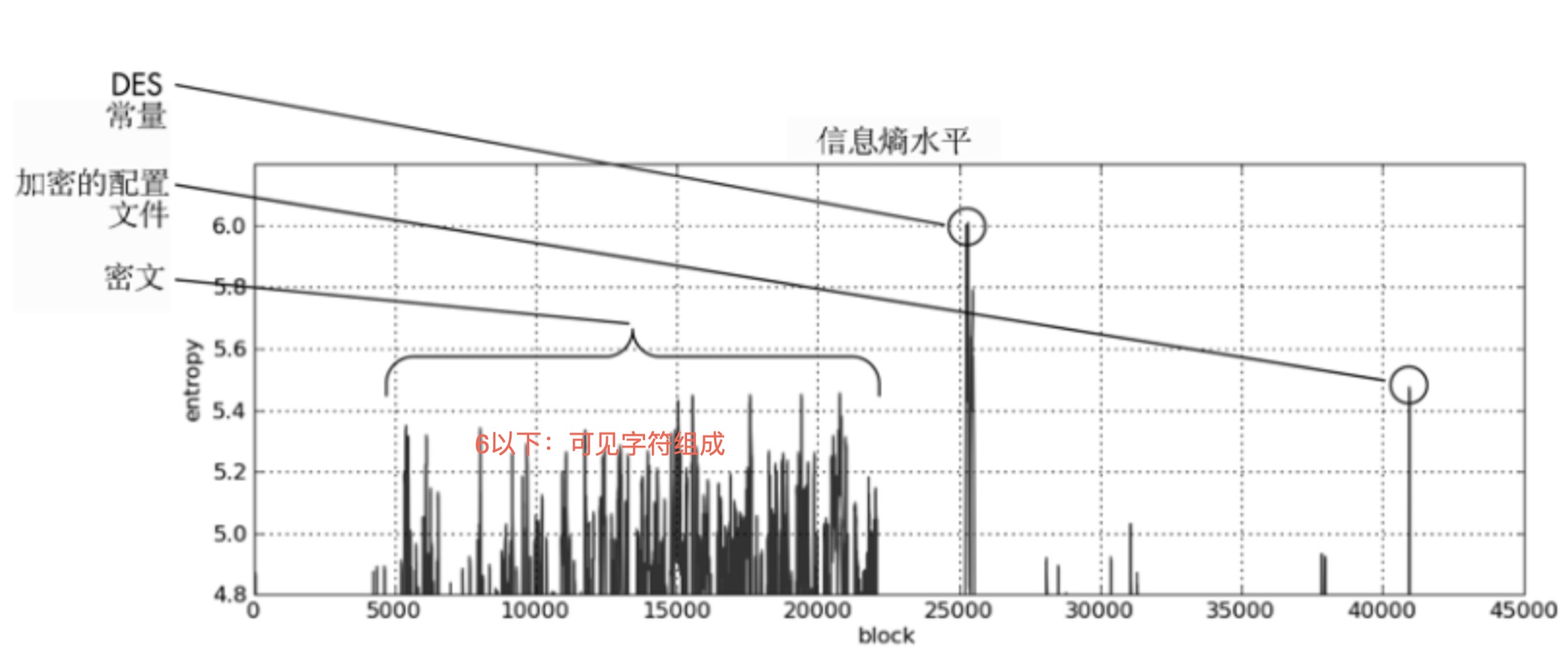
- 查找高熵的区域,表明该区域被加密或压缩
- IDAPro的熵插件,熵图绘制
- 熵值检查中建议选取的块大小
- Chunk size: 64(0~63:所有可见字符) Max. Entropy: 5.95 (高于max判定为异常)
- 有利于发现许多常量
- 包括 Base64编码的字符串
- Chunk size: 256(可见字符+非可见字符) Max. Entropy: 7.9
- 查找非常随机的区域
- Chunk size: 64(0~63:所有可见字符) Max. Entropy: 5.95 (高于max判定为异常)
13.4 解密
- 查找并且分离加密函数是恶意代码分析过程中很重要的一部分,但是通常情况下还需要继续解密隐藏的内容
- 重现恶意代码中加解密函数的方法:
- 重写
- 借用原有函数
- 自解密
- 程序正常 活动期间自己完成解密
- 并在解密例程之后直接设置断点获得解密数据
- 缺点:不好定位解密函数,解出的内容不是期望得到的
- 手动编写解密函数
- python脚本(PyCrypto)
- 使用通用的解密规范(用恶意代码进行解密<前提是可逆的算法>)
- 在调试器中启动恶意代码
- 准备读取的加密文件和准备写入的输出文件
- 在调试器中分配内存空间,让恶意代码能够引用 这块内存
- 加载加密文件到分配的内存区域
- 为恶意代码的加密函数设置合适的变量和参数
- 运行加密函数执行加密
- 将新解密的存储区写入到输出文件
- 工具:Immunity Debugger

- rb:确保正确度读入二进制字符
- cfile.read:将加密文件读入Python缓冲区
- imm.writeMemory:将python缓冲区的内存复制到被调试进程的内存中
- imm.getRegs:获取当前寄存器的值,使EBP定位两个关键参数-解密内存缓冲区及其大小
- imm.readMemory:读出

若有收获,就点个赞吧
0 人点赞
