- 对抗反汇编:就是在程序中使用一些特殊构造的代码或数据,让反汇编分析工具产生不正确的程序代码列表(混淆控制流)
- 恶意代码编写者会使用对抗反汇编技术来延缓或者阻止分析人员分析恶意代码
- 任何可执行的恶意代码都可以被逆向,但使用了对抗反汇编技术或反调试技术的恶意代码,对分析人员提出了更高的技术要求
- 恶意代码的调查分析过程对时间非常敏感,如果分析人员不能及时把握恶意代码真实意图,不能提取恶意代码的主机和网络特征,无法开发出解码算法,将导致分析被延误。
- 对抗反汇编也能在一定程度上阻碍特定的自动化分析技术
15.1 何谓对抗反汇编技术
- 可执行代码的序列可以有多种反汇编代码的表达,无效的反汇编表达的目的仅仅是掩盖程序的真实意图。
- 恶意代码编写者会创建一段代码序列,欺骗反汇编器,让反汇编器展示与真正执行的代码不同的指令列表
- 对抗反汇编技术是利用反汇编器的错误假设与局限性来实现,让反汇编器生成不正确的指令序列
- 反汇编器在某个时刻只能将程序的每一个字节作为一条指令的组成部分,欺骗反汇编器,在一个错误的偏移量处开始反汇编

- 线性反汇编技术生成
- call的跳转地址很荒谬
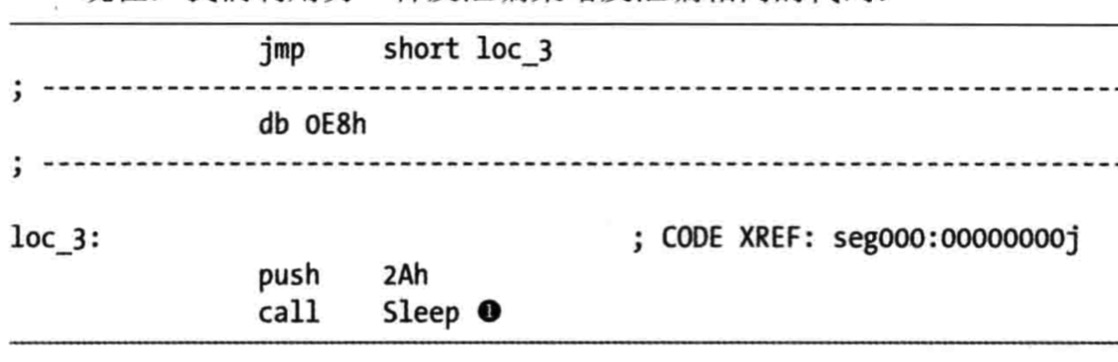
- 面向代码流的反汇编器反汇编产生,更准确,不去反汇编不在程序执行流中的字节
- 反汇编器在某个时刻只能将程序的每一个字节作为一条指令的组成部分,欺骗反汇编器,在一个错误的偏移量处开始反汇编
- 有些对抗反汇编技术只针对某些特定版本的反汇编器
15.2 挫败反汇编算法
- 对抗反汇编技术是基于反汇编算法的天生漏洞而产生的。为了清晰地显示反汇编代码,反汇编器在事前都会做某种特定的假设。一旦这种假设不成立,恶意代码作者就有机会欺骗分析人员。
- 线性反汇编
- 容易实现,易出错
- 策略:遍历一个代码段,一次反汇编一条指令,根据指令的大小决定下一个要反汇编指令的字节,不考虑代码流的控制指令
- 过程
- 位置指针(pStart)指向代码段开始处
- 从pStart处开始尝试匹配指令,并得到指令长度n
- 如果2成功,则按照Intel风格或AT&T风格反汇编 pStart~pStart+n的数据;否则pStart赋值为pStart+1,转2
- pStart赋值为pStart+n,pStart如果未超出代码结尾则转 2,否则退出
- 示例:利用反汇编库libdisasm实现线性反汇编

- buffer数据缓冲区:包含需要反汇编的指令
- x86_disasm:用刚刚反汇编后的具体指令填充一个数据结构,返回这条指令的大小size
- 如果是合法指令,position+size,反汇编下一条指令,否在position+1,尝试是否是合法指令
- 缺点:会反汇编过多代码(从头到尾),即使控制流指令只执行很少一部分代码;不能区分代码与数据
- 即使只反汇编.text段也存在问题:代码段也包含不是指令的数据内容
- 代码段中最常见的数据项类型是指针项,常被用在表驱动的开关中,线性反汇编器会错误的反汇编这些数据项
- 对抗线性反汇编器的方法:植入能够组成多字节指令机器码的数据字节
- 面向代码流的反汇编(IAD)
- 与线性反汇编的区别:面向代码流的反汇编器并不盲目地反汇编整个缓冲区,也不假设代码段中仅包含指令而不包含数据;相反它会检查每一条指令,建立一个需要反汇编的地址列表
- 仅适用于面向代码流反汇编的情况:

- 扫描到1处的条件分支指令jz时,会记下将来需要反汇编的位置,即5处的loc_1A
- 2处的指令也有可能被执行,所以反汇编器也会反汇编它
- 2和3之后是jmp指令,反汇编器会将jmp指令的跳转目标loc_1D加入列表,以便将来反汇编它
- 因为jmp指令是 无条件跳转指令,因此面向代码流的汇编器并不会自动反汇编内存中紧随其后的指令,而是退后一步,检查此前放入需要反汇编列表的数据,如loc_1A,然后从它开始反汇编
- 上述代码在线性反汇编中会反汇编错误,将字符串“Failed”当作代码来执行,后续代码也将反编译错误
- 条件分支的反汇编:
- 条件分支使面向代码流的反汇编器从true或false两 个分支处选择一个进行反汇编。
- 在传统编译产生的代码中,反汇编优先选择true 分支或优先选择false分支进行反汇编,输出的代 码并没有任何区别。
- 在人工编写的汇编代码与采用对抗反汇编编写的 代码中,同一段代码块的两个分支经常会产生不同的反汇编结果。
- 大多数面向代码流的反汇编器会首先处理条件跳转的false分支(紧随跳转语句之后的字节)
- call指令的反汇编
- call指令调用位置和紧随call指令之后的位置都被加入需要反汇编的列表中
- 大多数反汇编器会首先反汇编紧随call调用的字节,其次是call调用位置的字节
- 产生错误的情况
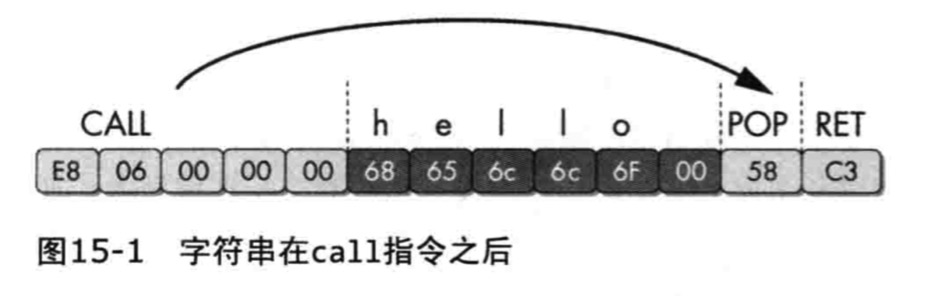
- IDA反汇编紧跟call之后1处的字节,再反汇编call的调用目标,把hello当成指令反汇编了
- 如果IDA Pro产生了不正确的反汇编代码,可以利用键盘上的C键或D键,手动将指令转换成数据或者将数据转换成指令
- C键:将光标位置的数据转换成代码
- D键:将光标位置的代码转换成数据
15.3 对抗反汇编技术
- 主要方法:利用反汇编器选择算法和假设算法的漏洞,使反汇编器产生错误的反汇编代码
- 更先进的技术:利用反汇编器通常不能获取的信息,并产生出一些不可能被传统反汇编技术完全解析的代码
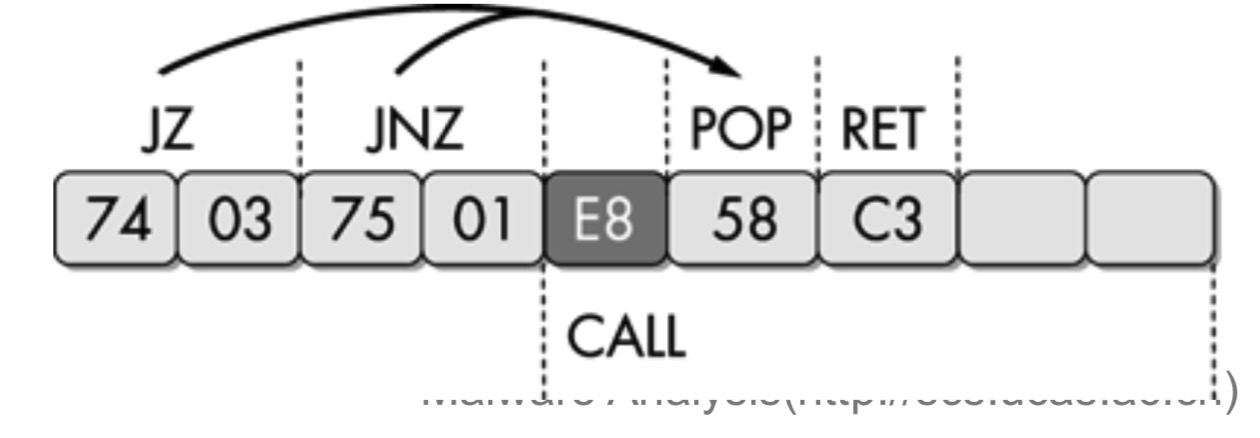
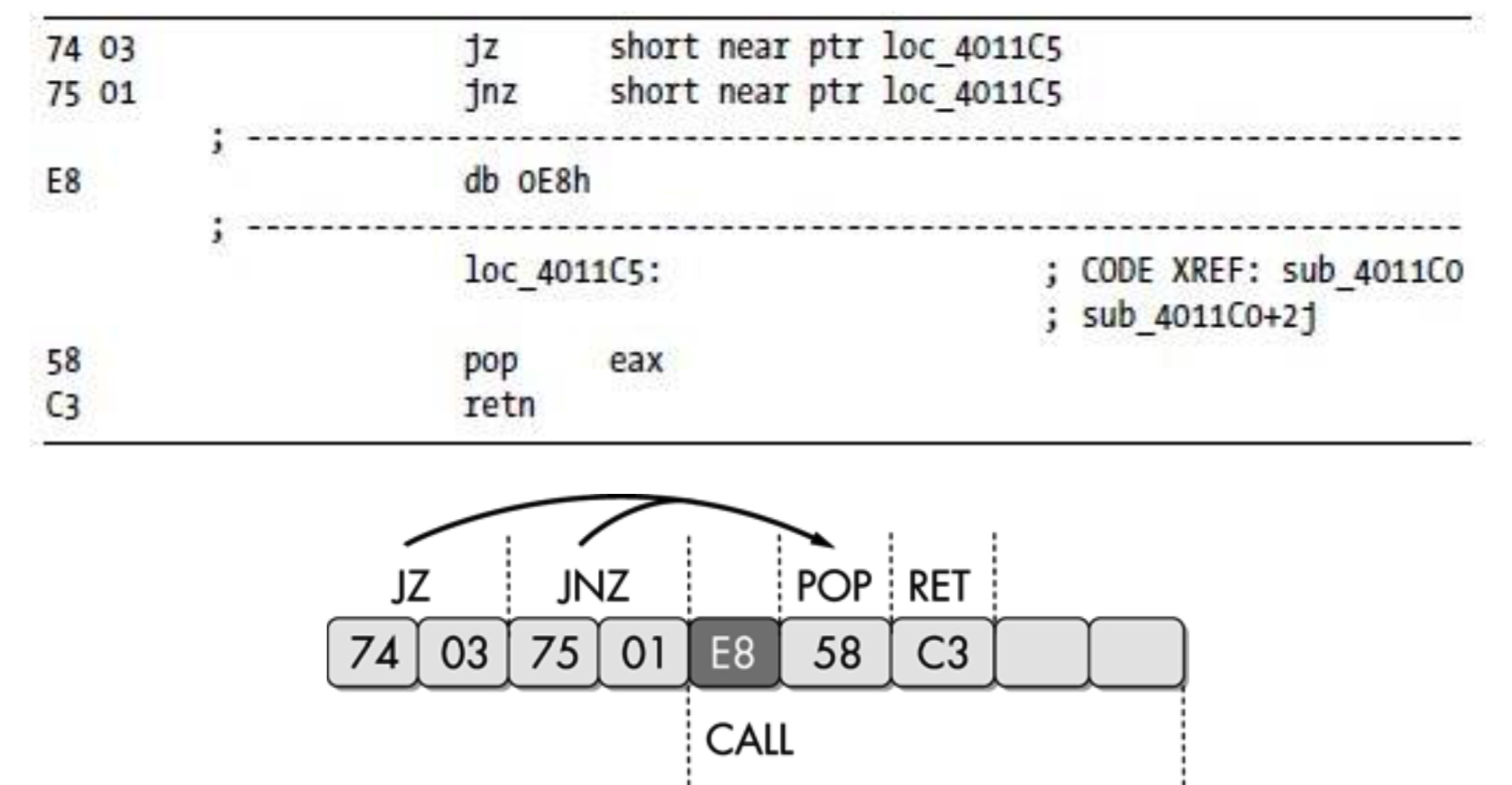
- 相同目标的跳转指令
- 使用指向同一目的地址的两个连续条件跳转指令
- jz+jnz=jmp:反汇编器逐条指令反汇编,不会意识到存在永远不会执行的分支,错误的反汇编发现跳转地址位于call指令的中间
- 例:
- IDA直接反汇编结果
- 使用指向同一目的地址的两个连续条件跳转指令

- D键修正后的结果
- 固定条件的跳转指令
- 由跳转条件总是相同的一条跳转指令构成
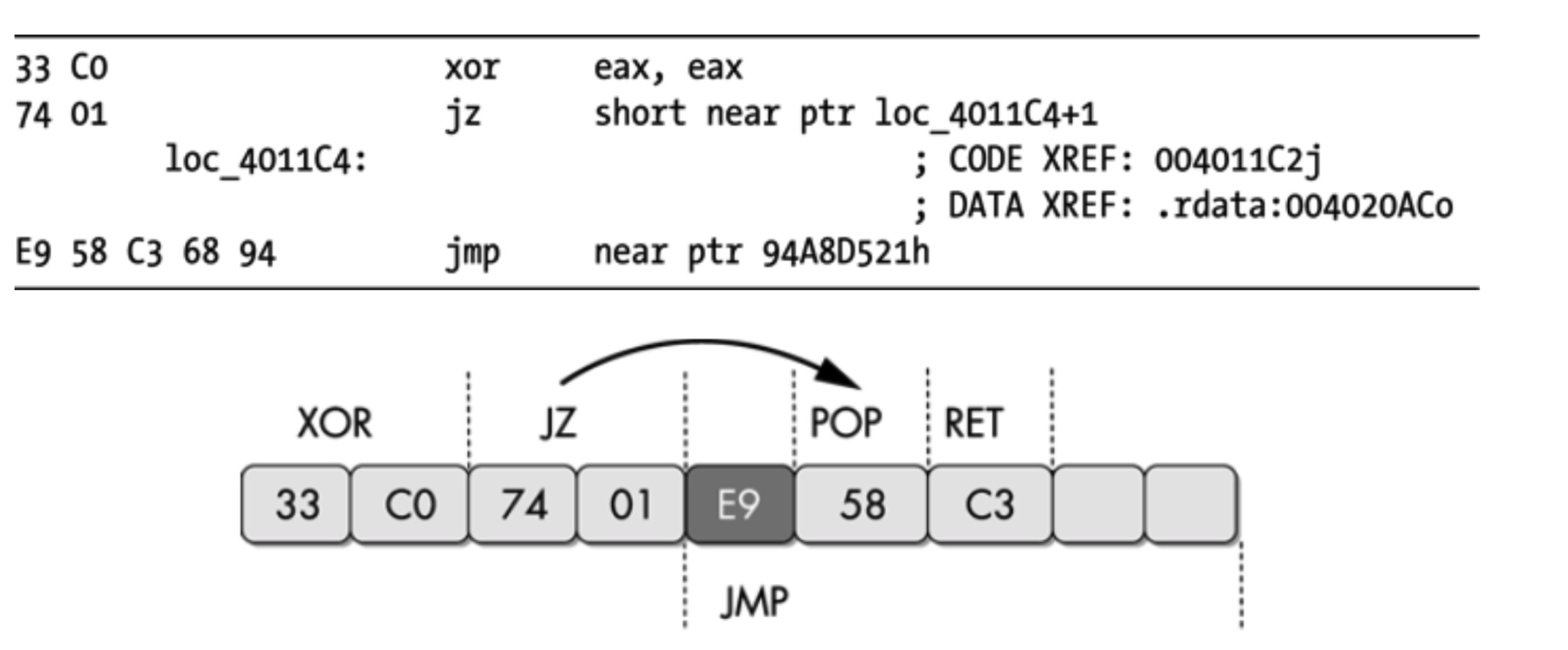
- xor使zf标识为置1,jz恒为真,相当于jmp
- 但是反编译器仍会反编译jz后判定为flase的分支字节,这样跳转地址错误的变成了jmp指令的中间
- 解决办法
- IDA中将光标定位到jmp指令
- 按D将E9转化为数据
- 正确的结果为:

- 由跳转条件总是相同的一条跳转指令构成
- 无效的反汇编指令
- 定义:在某些条件下常规的汇编列表不能表达运行指令
- 思想:插入流氓字节,迷惑反汇编器从这个字节开始反汇编,阻止其后真正的指令被反汇编,这种情况下流氓字节是可以被忽略的
- 如果流氓字节不能被忽略怎么办?如果它是 合法指令的一部分,且在运行时能够被正确执行怎么办?
- 例如:
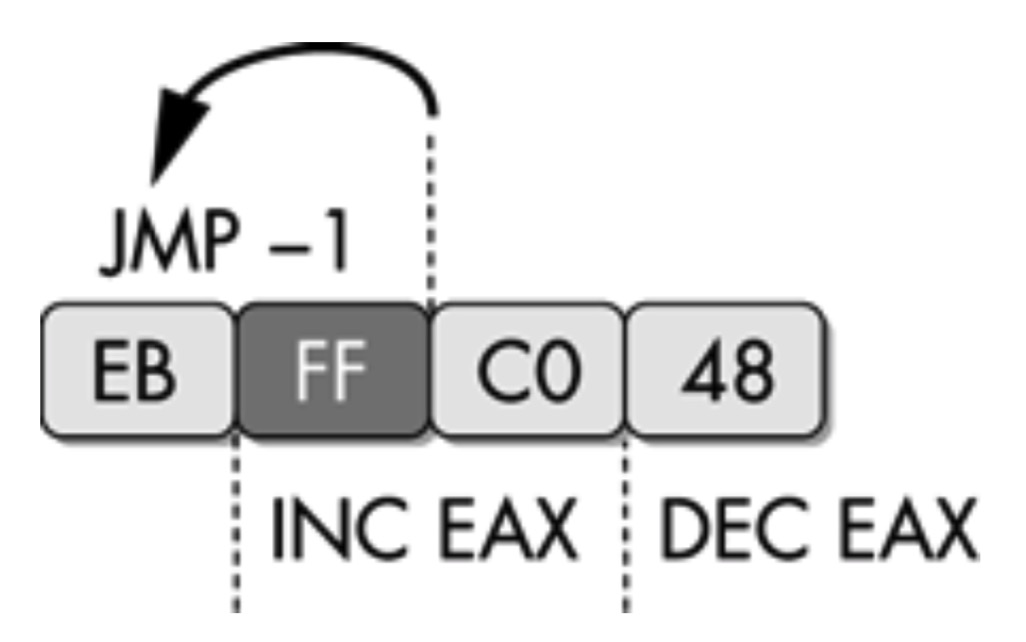
- 字节FF同时作为两条实际运行指令的一部分,而现代反汇编器并没有办法表达这种情况。
- 这4个字节的功能是:首先递增EAX,然后递减EAX,这是一个复杂的NOP序列,几乎可以插入程序的任何位置,从而破坏有效的反汇编链
- 解决方法:用NOP指令序列替换这些字节或者把这些字节标记成数据
- 更复杂的例子:
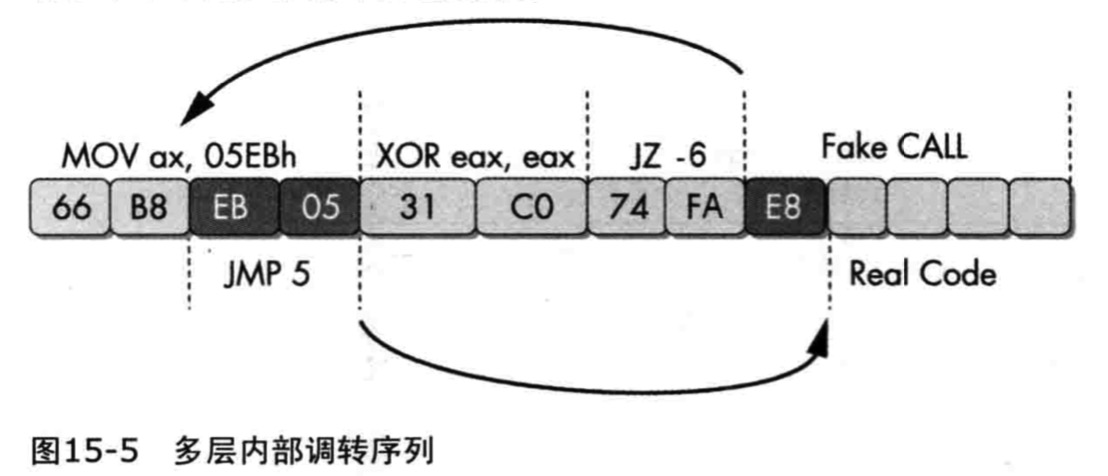
- 有多个字节是多条指令的组成部分
- EB05既是mov指令的一部分,同时也作为随后运行的一条指令
- JZ总会跳转,它后面的分支(0xE8开头会被反汇编成代码,虽然永远执行不到)
- 反汇编器不能正确反汇编jz指令目标,因为这个字节已经被正确表达为mov指令的一部分
- 解决办法:
- D键转化为数据,保留正确的指令,有损的去除有影响指令
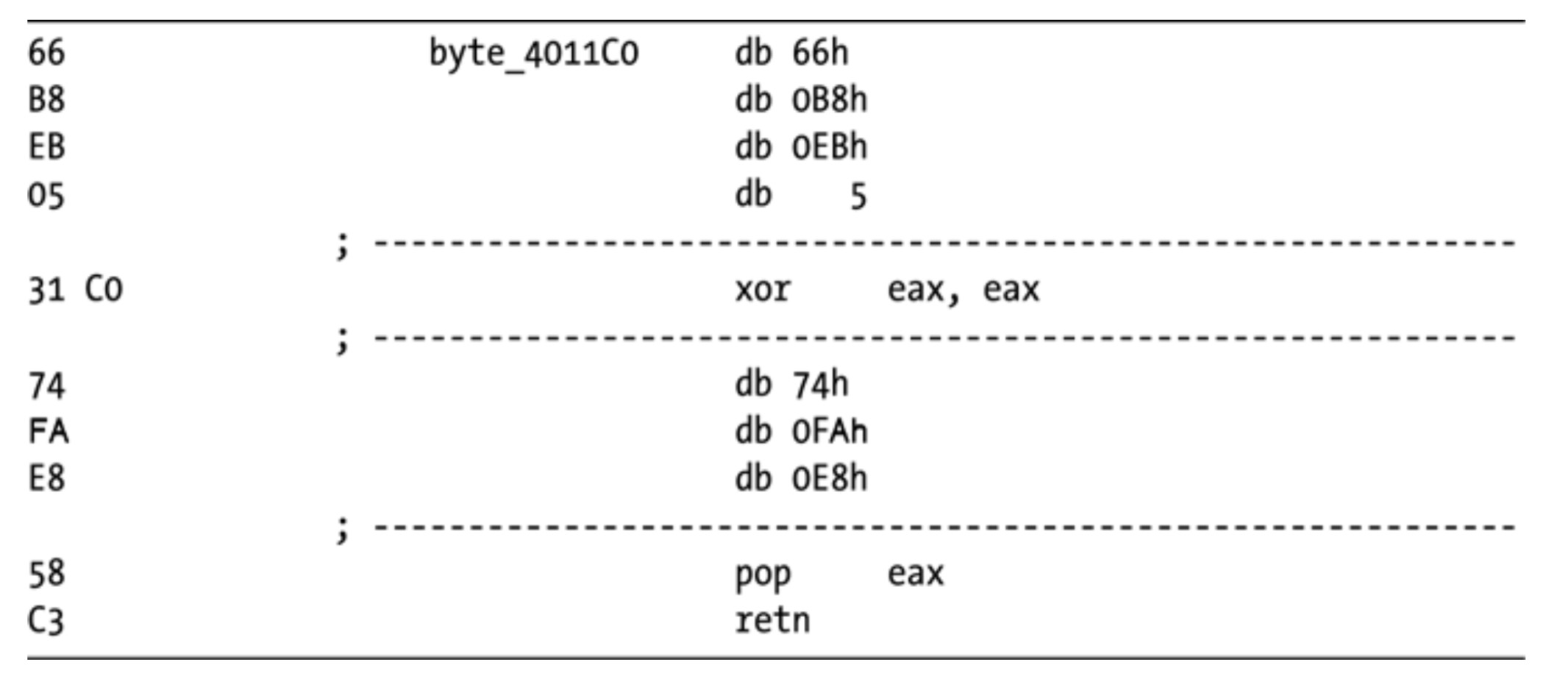
- 利用IDC脚本语言中的PatchByte函数,修改其余的字节为NOP
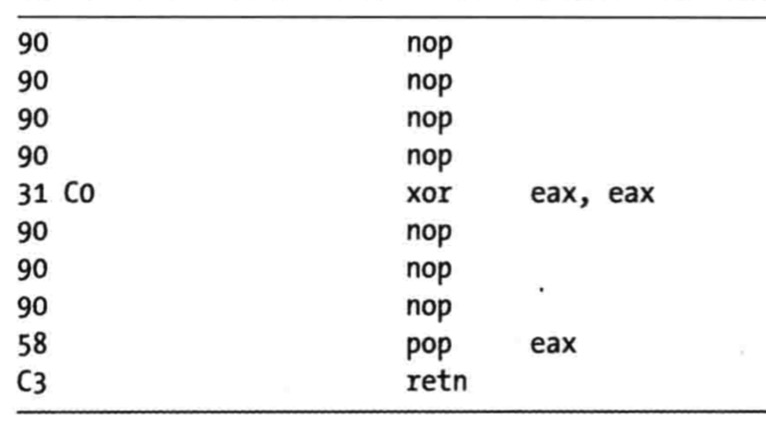
- D键转化为数据,保留正确的指令,有损的去除有影响指令
- 例如:
- 用IDA pro对指令进行NOP替换
- 脚本:用户按下 ALT+N 组合键,IDA pro会使用NOP指令替换当前光标位置处的字节

- 脚本:用户按下 ALT+N 组合键,IDA pro会使用NOP指令替换当前光标位置处的字节
15.4 混淆控制流图
- 反汇编器,例如IDA Pro,在关联函数调用并根据函数之间的相关性推导高层信息方面容易被恶意代码编写者挫败
- 函数指针问题
- 在C程序中使用函数指针可以降低反汇编器自动推导出程序流的信息量
- 在源码中构造不标准的函数指针格式,会导致在没有动态分析的前提下很难进进行逆向工程
- 例如:第二个函数通过函数指针调用第一个函数


- 1处使用了交叉引用,因为IDA能探测到函数的初始化引用,但是没有探测到2、3处的调用,函数的原型信息丢失
- 难以跟踪调用流,难以添加引用注释
- 在IDA Pro中添加代码的交叉引用
- 所有不能自动向上转化的信息,例如函数的参数名,都可以由恶意代码分析师将其作为注释手动添加
- 使用IDC中名为AddCodeXref的函数。它有三个参数:交叉引用来源的位置、交叉引用指向的位置,以及流的类型
- 普通call指令类型为 fl_CF,跳转指令类型为fl_JF

- 滥用返回指针
- 函数的调用和返回
- call/retn 指令一般用于函数调用和函数返回
- retn指令的作用取出返回值地址,然后跳转跳转到该地址 ,call将返回地址压栈,然后跳转到后面跟的内存地址
- call指令等同于push指令加jmp指令
- retn指令等同于pop指令加jmp指令
- 当retn不以函数调用返回的方式被使用时,反汇编器不能显示代码中任何要跳转的交叉引用目标;而且反汇编器会提前结束这个函数。
- 例如:

- call $+5:调用紧随它的一个地址,导致这个内存地址(0x004011C5)被存到栈中
- add [esp+4+var_4],5:[esp+4+(-4)]的值+5,栈顶元素值+5,即变成0x004011CA
- retn弹出栈顶的值(0x004011CA)并跳转执行
- 0x004011CA处是一个正常函数的开头,由于流氓指令retn的存在,IDA不会将真正的函数作为函数的任何一部分
- 解决方案:使用NOP替换前三个指令,调整函数边界到push处
- 函数的调用和返回
- 滥用结构化异常处理
- 结构化异常处理(SEH)供一种控制流的 方法,该方法不能被反汇编器采用,但可以用来欺骗反汇编器
- SEH:为程序提供一种智能处理错误条件的方法,异常触发可能有多种原因
- SEH链:函数列表,处理线程中的异常,列表中的每个函数,要么处理异常,要 么将异常传递到列表中的下一个函数。在大多数进程中,产生的异常在到达最后状态(程序崩 溃)之前,异常都会被静悄悄地的处理掉
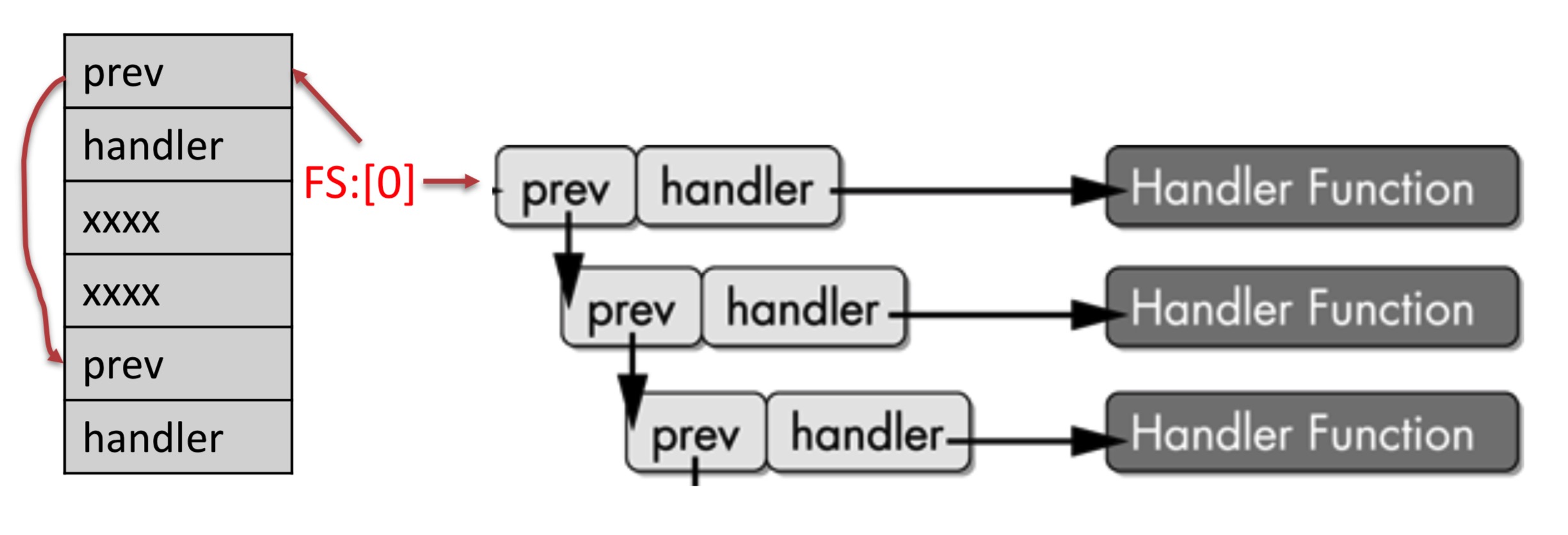
- 查找SEH链:os检查FS段寄存器,段寄存器包含一个段选择子,使用段选择子可以得到线程环境块(TEB),TEB第一个数据结构是线程信息块(TIB),TIB中第一个元素就是SEH链指针。
- SEH链元素结构:

- prev:指向前一个记录的指针
- handler:指向异常处理函数的指针
- SEH链操作方式:以链的形式,SEH链的增长和缩小等同于程序中异常处理层的改变,SEH记录总是建在栈上,利用SEH实现变相控制程序流
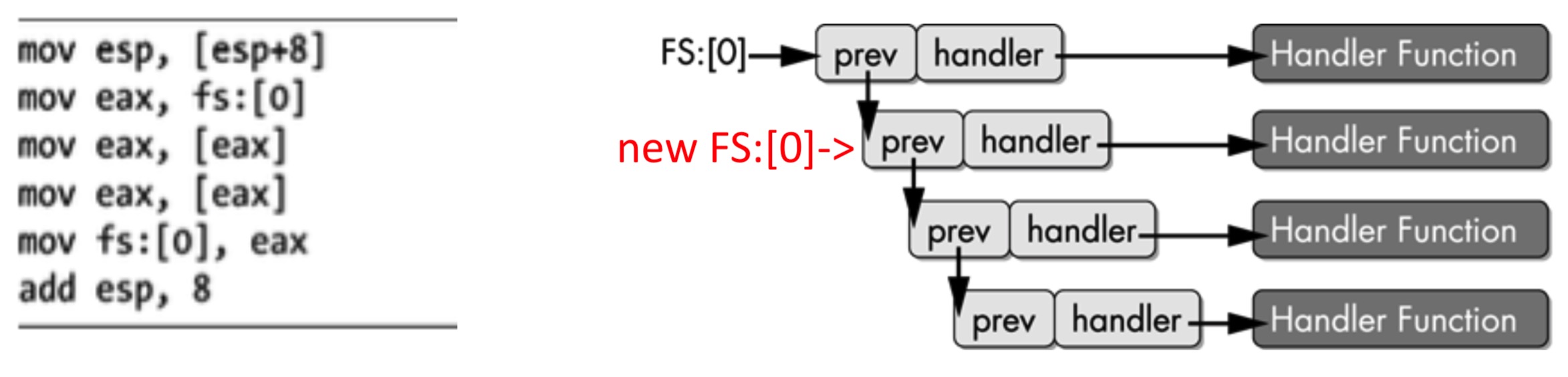
- 构造SEH链,添加一条新纪录:

- 软件DEP:安全功能,阻止handler指向的处理程序运行过程中添加第三方的异常处理
- 绕过技术:使用支持SafeSEH指令的汇编器;或添加/SAFE:NO到链接器命令行
- 滥用结构化异常处理的目的:混淆控制流,使程序不能正确处理异常
- 利用方法:当异常处理被调用时,操作系统添加了其他的SEH 处理。为了让程序恢复正常操作,不仅要将我们的异常处理从异常处理链中断开,还要将系统添加的异常处理从异常处理链中断开
- 变相转换控制流到子例程(函数)的例子

- 2处设置EAX寄存器的值为40106C
- add eax,14h:构造指向401080处函数的指针(IDA没有成功将这个函数反汇编出来)
- push push mov:SEH链中新添加一个异常处理项,其中handler是eax的值,指向401080处函数
- div:除零操作触发上面的异常处理,使401080成功执行
- 分析方法:使用C键将位置401080处的数据转换成代码,看看攻击者想隐藏的代码

若有收获,就点个赞吧
0 人点赞
