部署4个exporter
老套路,下载docker镜像,准备资源配置清单,应用资源配置清单:
部署kube-state-metrics
准备docker镜像
[root@alice001 ~]# docker pull prom/node-exporter:v0.15.0[root@alice001 ~]# docker tag prom/node-exporter:v0.15.0 harbor.od.com/public/node-exporter:v0.15.0[root@alice001 ~]# docker push harbor.od.com/public/node-exporter:v0.15.0
准备目录
[root@alice001 ~]# mkdir /data/k8s-yaml/kube-state-metrics
[root@alice001 ~]# cd /data/k8s-yaml/kube-state-metrics
应用资源配置清单
任意node节点执行
[root@alice002 ~]# kubectl apply -f http://k8s-yaml.od.com/kube-state-metrics/rbac.yaml
[root@alice002 ~]# kubectl apply -f http://k8s-yaml.od.com/kube-state-metrics/deployment.yaml
验证测试
kubectl get pod -n kube-system -o wide|grep kube-state-metrics
~]# curl http://172.187.177.6:8080/healthz
ok
部署node-exporter
由于node-exporter是监控node的,需要每个节点启动一个,所以使用ds控制器
准备docker镜像
[root@alice001 ~]# docker pull google/cadvisor:v0.28.3
[root@alice001 ~]# docker tag google/cadvisor:v0.28.3 harbor.od.com/public/cadvisor:0.28.3
[root@alice001 ~]# docker push harbor.od.com/public/cadvisor:0.28.3
准备目录
[root@alice001 ~]# mkdir /data/k8s-yaml/cadvisor
[root@alice001 ~]# cd /data/k8s-yaml/cadvisor
准备ds资源清单
主要用途就是将宿主机的
/proc,sys目录挂载给容器,是容器能获取node节点宿主机信息
应用资源配置清单:
任意node节点
kubectl apply -f http://k8s-yaml.od.com/node-exporter/ds.yaml
kubectl get pod -n kube-system -o wide|grep node-exporter
部署cadvisor
准备docker镜像
[root@alice001 cadvisor]# docker pull prom/blackbox-exporter:v0.15.1
[root@alice001 cadvisor]# docker tag prom/blackbox-exporter:v0.15.1 harbor.od.com/public/blackbox-exporter:v0.15.1
[root@alice001 cadvisor]# docker push harbor.od.com/public/blackbox-exporter:v0.15.1
准备目录
[root@alice001 cadvisor]# mkdir /data/k8s-yaml/blackbox-exporter
[root@alice001 cadvisor]# cd /data/k8s-yaml/blackbox-exporter
准备ds资源清单
cadvisor由于要获取每个node上的pod信息,因此也需要使用daemonset方式运行
应用资源配置清单:
应用清单前,先在每个node上做以下软连接,否则服务可能报错
阿里云的可以不做 亲测没问题
mount -o remount,rw /sys/fs/cgroup/
ln -s /sys/fs/cgroup/cpu,cpuacct /sys/fs/cgroup/cpuacct,cpu
应用清单
kubectl apply -f http://k8s-yaml.od.com/cadvisor/ds.yaml
检查:
kubectl -n kube-system get pod -o wide|grep cadvisor
部署blackbox-exporter
准备docker镜像
[root@alice001 blackbox-exporter]# docker pull prom/prometheus:v2.14.0
[root@alice001 blackbox-exporter]# docker tag prom/prometheus:v2.14.0 harbor.od.com/infra/prometheus:v2.14.0
[root@alice001 blackbox-exporter]# docker push harbor.od.com/infra/prometheus:v2.14.0
准备目录
[root@alice001 blackbox-exporter]# mkdir /data/k8s-yaml/prometheus-server
[root@alice001 blackbox-exporter]# cd /data/k8s-yaml/prometheus-server
准备cm资源清单
准备dp资源清单
准备svc资源清单
准备ingress资源清单
添加域名解析
这里用到了一个域名,添加解析
vi /var/named/od.com.zone
blackbox A 47.243.20.250
systemctl restart named
应用资源配置清单
kubectl apply -f http://k8s-yaml.od.com/blackbox-exporter/cm.yaml
kubectl apply -f http://k8s-yaml.od.com/blackbox-exporter/dp.yaml
kubectl apply -f http://k8s-yaml.od.com/blackbox-exporter/svc.yaml
kubectl apply -f http://k8s-yaml.od.com/blackbox-exporter/ingress.yaml
访问域名测试
访问http://blackbox.od.com,显示如下界面,表示blackbox已经运行成
部署prometheus server
准备prometheus server环境
准备docker镜像
[root@alice001 blackbox-exporter]# docker pull prom/prometheus:v2.14.0
[root@alice001 blackbox-exporter]# docker tag prom/prometheus:v2.14.0 harbor.od.com/infra/prometheus:v2.14.0
[root@alice001 blackbox-exporter]# docker push harbor.od.com/infra/prometheus:v2.14.0
[root@alice001 blackbox-exporter]# mkdir /data/k8s-yaml/prometheus-server
[root@alice001 blackbox-exporter]# cd /data/k8s-yaml/prometheus-server
准备目录
[root@alice001 blackbox-exporter]# mkdir /data/k8s-yaml/prometheus-server
[root@alice001 blackbox-exporter]# cd /data/k8s-yaml/prometheus-server
准备rbac资源清单
准备dp资源清单
加上
--web.enable-lifecycle启用远程热加载配置文件,配置文件改变后不用重启prometheus 调用指令是curl -X POST http://localhost:9090/-/reloadstorage.tsdb.min-block-duration=10m只加载10分钟数据到内storage.tsdb.retention=72h保留72小时数据
添加域名解析
这里用到一个域名prometheus.od.com,添加解析:
vi /var/named/od.com.zone
prometheus A 47.243.20.250
systemctl restart named
部署prometheus server
准备目录和证书
这里的/infra_volume目录我的用的glusterfs的复制卷 所以每node上都有一份数据配置,文件里用的hostpath
[root@alice002 ~]# mkdir -p /infra_volume/prometheus/etc
[root@alice002 ~]# mkdir -p /infra_volume/prometheus/prom-db
[root@alice002 ~]# cd /infra_volume/prometheus/etc/
# 拷贝配置文件中用到的证书:
[root@alice002 etc]# scp alice001:/opt/certs/ca.pem .
[root@alice002 etc]# scp alice001:/opt/certs/client.pem .
[root@alice002 etc]# scp alice001:/opt/certs/client-key.pem .
创建prometheus配置文件
配置文件说明: 此配置为通用配置,除第一个job
etcd是做的静态配置外,其他8个job都是做的自动发现 因此只需要修改etcd的配置后,就可以直接用于生产环境
应用资源配置清单
kubectl apply -f http://k8s-yaml.od.com/prometheus-server/rbac.yaml
kubectl apply -f http://k8s-yaml.od.com/prometheus-server/dp.yaml
kubectl apply -f http://k8s-yaml.od.com/prometheus-server/svc.yaml
kubectl apply -f http://k8s-yaml.od.com/prometheus-server/ingress.yaml
浏览器验证
访问http://prometheus.od.com,如果能成功访问的话,表示启动成功
点击status->configuration就是我们的配置文件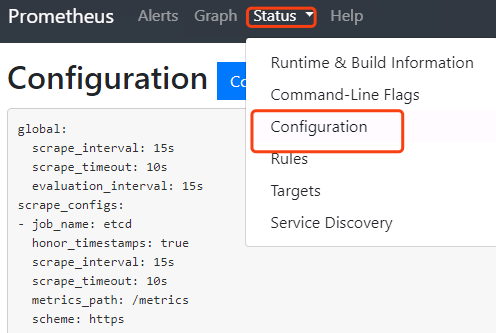
使服务能被prometheus自动监控
点击status->targets,展示的就是我们在prometheus.yml中配置的job-name,这些targets基本可以满足我们收集数据的需求。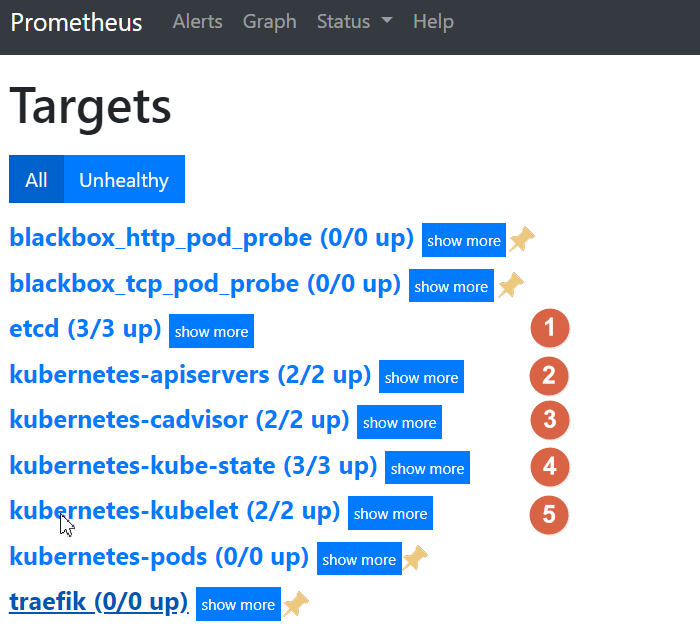
5个编号的job-name已经被发现并获取数据 接下来就需要将剩下的4个ob-name对应的服务纳入监控 纳入监控的方式是给需要收集数据的服务添加annotations
让traefik能被自动监控
修改traefik的yaml
修改fraefik的yaml文件,跟labels同级,添加annotations配置
vim /data/k8s-yaml/traefik/ds.yaml
........
spec:
template:
metadata:
labels:
k8s-app: traefik-ingress
name: traefik-ingress
#--------增加内容--------
annotations:
prometheus_io_scheme: "traefik"
prometheus_io_path: "/metrics"
prometheus_io_port: "8080"
#--------增加结束--------
spec:
serviceAccountName: traefik-ingress-controller
........
任意节点重新应用配置
kubectl delete -f http://k8s-yaml.od.com/traefik/ds.yaml
kubectl apply -f http://k8s-yaml.od.com/traefik/ds.yaml
应用配置查看
等待pod重启以后,再在prometheus上查看traefik是否能正常获取数据了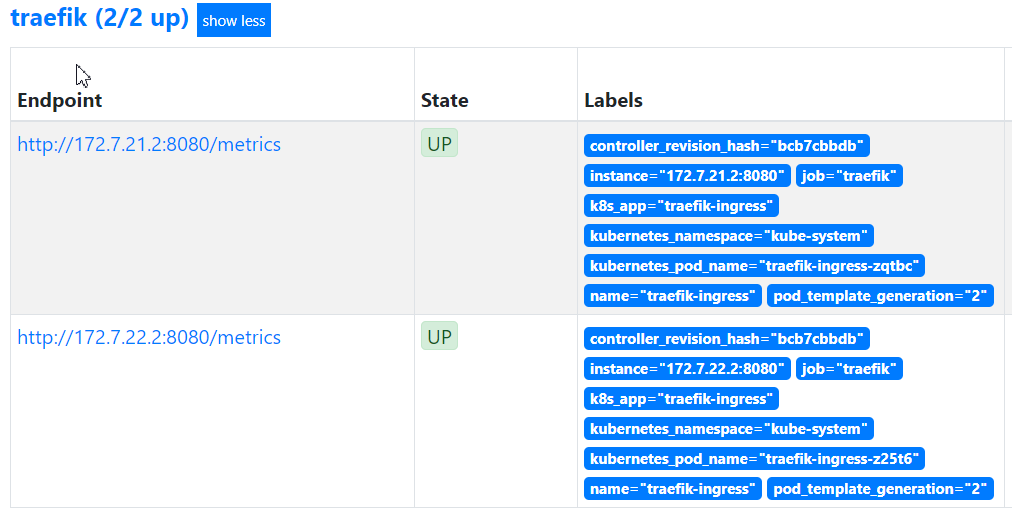
用blackbox检测TCP/HTTP服务状态
blackbox是检测容器内服务存活性的,也就是端口健康状态检查,分为tcp和http两种方法
能用http的情况尽量用http,没有提供http接口的服务才用tcp
被检测服务准备
使用测试环境的dubbo服务来做演示,其他环境类似
- dashboard中开启apollo-portal和test空间中的apollo
- dubbo-demo-service使用tcp的annotation
- dubbo-demo-consumer使用HTTP的annotation
添加tcp的annotation
等两个服务起来以后,首先在dubbo-demo-service资源中添加一个TCP的annotation
任意节点重新应用配置vim /data/k8s-yaml/test/dubbo-demo-server/dp.yaml ...... spec: ...... template: metadata: labels: app: dubbo-demo-service name: dubbo-demo-service #--------增加内容-------- annotations: blackbox_port: "20880" blackbox_scheme: "tcp" #--------增加结束-------- spec: containers: image: harbor.od.com/app/dubbo-demo-service:apollo_200512_0746
浏览器中查看http://blackbox.od.com/和http://prometheus.od.com/targetskubectl delete -f http://k8s-yaml.od.com/test/dubbo-demo-server/dp.yaml kubectl apply -f http://k8s-yaml.od.com/test/dubbo-demo-server/dp.yaml
我们运行的dubbo-demo-server服务,tcp端口20880已经被发现并在监控中
添加http的annotation
接下来在dubbo-demo-consumer资源中添加一个HTTP的annotation:
任意节点重新应用配置vim /data/k8s-yaml/test/dubbo-demo-consumer/dp.yaml spec: ...... template: metadata: labels: app: dubbo-demo-consumer name: dubbo-demo-consumer #--------增加内容-------- annotations: blackbox_path: "/hello?name=health" blackbox_port: "8080" blackbox_scheme: "http" #--------增加结束-------- spec: containers: - name: dubbo-demo-consumer ......kubectl delete -f http://k8s-yaml.od.com/test/dubbo-demo-consumer/dp.yaml kubectl apply -f http://k8s-yaml.od.com/test/dubbo-demo-consumer/dp.yaml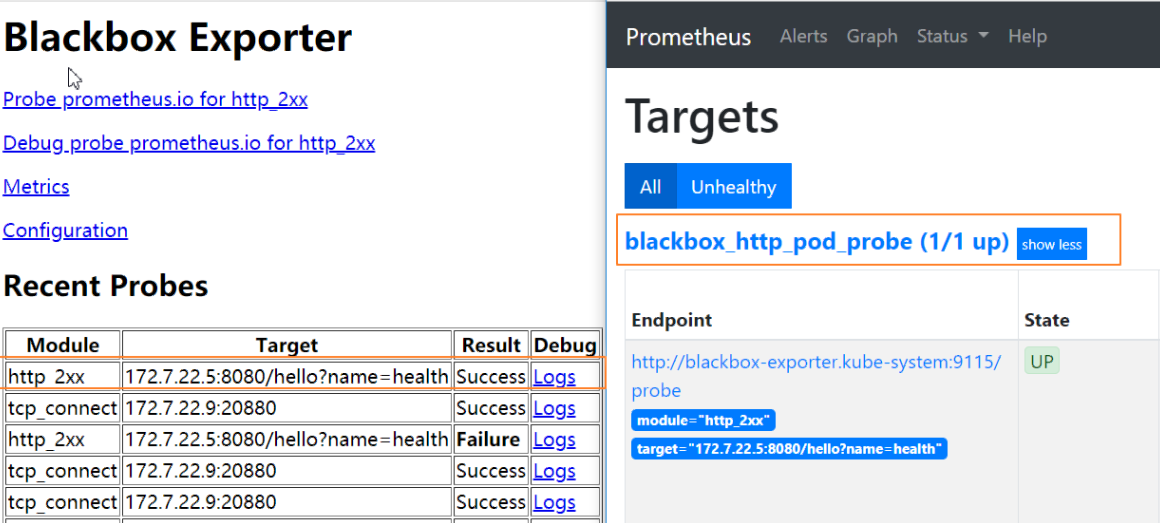
添加监控jvm信息
dubbo-demo-service和dubbo-demo-consumer都添加下列annotation注解,以便监控pod中的jvm信息vim /data/k8s-yaml/test/dubbo-demo-server/dp.yaml vim /data/k8s-yaml/test/dubbo-demo-consumer/dp.yaml annotations: #....已有略.... prometheus_io_scrape: "true" prometheus_io_port: "12346" prometheus_io_path: "/"12346是dubbo的POD启动命令中使用jmx_javaagent用到的端口,因此可以用来收集jvm信息
任意节点重新应用配置
kubectl apply -f http://k8s-yaml.od.com/test/dubbo-demo-server/dp.yaml
kubectl apply -f http://k8s-yaml.od.com/test/dubbo-demo-consumer/dp.yaml
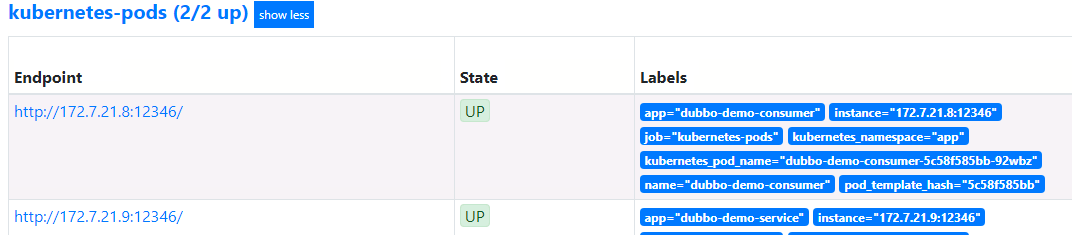
至此,所有9个服务,都获取了数据

若有收获,就点个赞吧
0 人点赞
