Spark RDD
1、Spark的核心概念是RDD (resilient distributed dataset,弹性分布式数据集),指的是一个只读的,可分区的分布式数据集,这个数据集的全部或部分可以缓存在内存中,在多次计算间重用。
2、RDD在抽象上来说是一种元素集合,包含了数据。它是被分区的,分为多个分区,每个分区分布在集群中的不同Worker节点上,从而让RDD中的数据可以被并行操作。(分布式数据集)
3、RDD通常通过Hadoop上的文件,即HDFS文件或者Hive表,来进行创建;有时也可以通过RDD的本地创建转换而来。
4、传统的MapReduce虽然具有自动容错、平衡负载和可拓展性的优点,但是其最大缺点是采用非循环式的数据流模型,使得在迭代计算式要进行大量的磁盘IO操作(每跑完一个Job,拿到其中间结果后,再跑下一个Job,联想使用MR做数据清洗的案例)。RDD正是解决这一缺点的抽象方法。RDD最重要的特性就是,提供了容错性,可以自动从节点失败中恢复过来。即如果某个节点上的RDD partition,因为节点故障,导致数据丢了,那么RDD会自动通过自己的数据来源重新计算该partition。这一切对使用者是透明的。RDD的lineage特性(类似于族谱,像上面的图,假如某个partition的数据丢失了,找到其父partition重新计算即可,我们称之为溯源)。
5、RDD的数据默认情况下存放在内存中的,但是在内存资源不足时,Spark会自动将RDD数据写入磁盘。(弹性)
Spark的产生原因及RDD在Spark中的地位
(1)Spark是为了解决 迭代计算(iterative)和交互式计算(interactive)这两个问题而产生的
(2)Spark如何解决迭代计算?其主要实现思想就是RDD,把所有计算的数据保存在分布式的内存中。迭代计算通常情况下都是对同一个数据集做反复的迭代计算,数据在内存中将大大提升IO操作.
(3)Spark如何实现交互式计算?因为Spark是用scala语言实现的,Spark和scala能够紧密的集成,所以Spark可以完美的运用scala的解释器,使得其中的scala可以向操作本地集合对象一样轻松操作分布式数据集。
(4)Spark和RDD的关系?可以理解为:RDD是一种具有容错性基于内存的集群计算抽象方法,Spark则是这个抽象方法的实现。
Spark RDD持久化
RDD持久化工作原理
Spark非常重要的一个功能特性就是可以将RDD持久化在内存中。当对RDD执行持久化操作时,每个节点都会将自己操作的RDD的partition持久化到内存中,并且在之后对该RDD的反复使用中,直接使用内存缓存的partition。这样的话,对于针对一个RDD反复执行多个操作的场景,就只要对RDD计算一次即可,后面直接使用该RDD,而不需要反复计算多次该RDD。
要持久化一个RDD,只要调用其cache()或者persist()方法即可。在该RDD第一次被计算出来时,就会直接缓存在每个节点中。而且Spark的持久化机制还是自动容错的,如果持久化的RDD的任何partition丢失了,那么Spark会自动通过其源RDD,使用transformation操作重新计算该partition。
cache()和persist()的区别在于,cache()是persist()的一种简化方式,cache()的底层就是调用的persist()的无参版本,同时就是调用persist(MEMORY_ONLY),将数据持久化到内存中。如果需要从内存中去除缓存,那么可以使用unpersist()方法。
RDD持久化策略
持久化策略的选择
默认情况下,性能最高的当然是MEMORY_ONLY,但前提是你的内存必须足够足够大,可以绰绰有余地存放下整个RDD的所有数据。因为不进行序列化与反序列化操作,就避免了这部分的性能开销;对这个RDD的后续算子操作,都是基于纯内存中的数据的操作,不需要从磁盘文件中读取数据,性能也很高;而且不需要复制一份数据副本,并远程传送到其他节点上。但是这里必须要注意的是,在实际的生产环境中,恐怕能够直接用这种策略的场景还是有限的,如果RDD中数据比较多时(比如几十亿),直接用这种持久化级别,会导致JVM的OOM内存溢出异常。
如果使用MEMORY_ONLY级别时发生了内存溢出,那么建议尝试使用MEMORY_ONLY_SER级别。该级别会将RDD数据序列化后再保存在内存中,此时每个partition仅仅是一个字节数组而已,大大减少了对象数量,并降低了内存占用。这种级别比MEMORY_ONLY多出来的性能开销,主要就是序列化与反序列化的开销。但是后续算子可以基于纯内存进行操作,因此性能总体还是比较高的。此外,可能发生的问题同上,如果RDD中的数据量过多的话,还是可能会导致OOM内存溢出的异常。
如果纯内存的级别都无法使用,那么建议使用MEMORY_AND_DISK_SER策略,而不是MEMORY_AND_DISK策略。因为既然到了这一步,就说明RDD的数据量很大,内存无法完全放下。序列化后的数据比较少,可以节省内存和磁盘的空间开销。同时该策略会优先尽量尝试将数据缓存在内存中,内存缓存不下才会写入磁盘。
通常不建议使用DISK_ONLY和后缀为_2的级别:因为完全基于磁盘文件进行数据的读写,会导致性能急剧降低,有时还不如重新计算一次所有RDD。后缀为_2的级别,必须将所有数据都复制一份副本,并发送到其他节点上,数据复制以及网络传输会导致较大的性能开销,除非是要求作业的高可用性,否则不建议使用。
共享变量
Spark提供了两种有限类型的共享变量,广播变量和累加器。
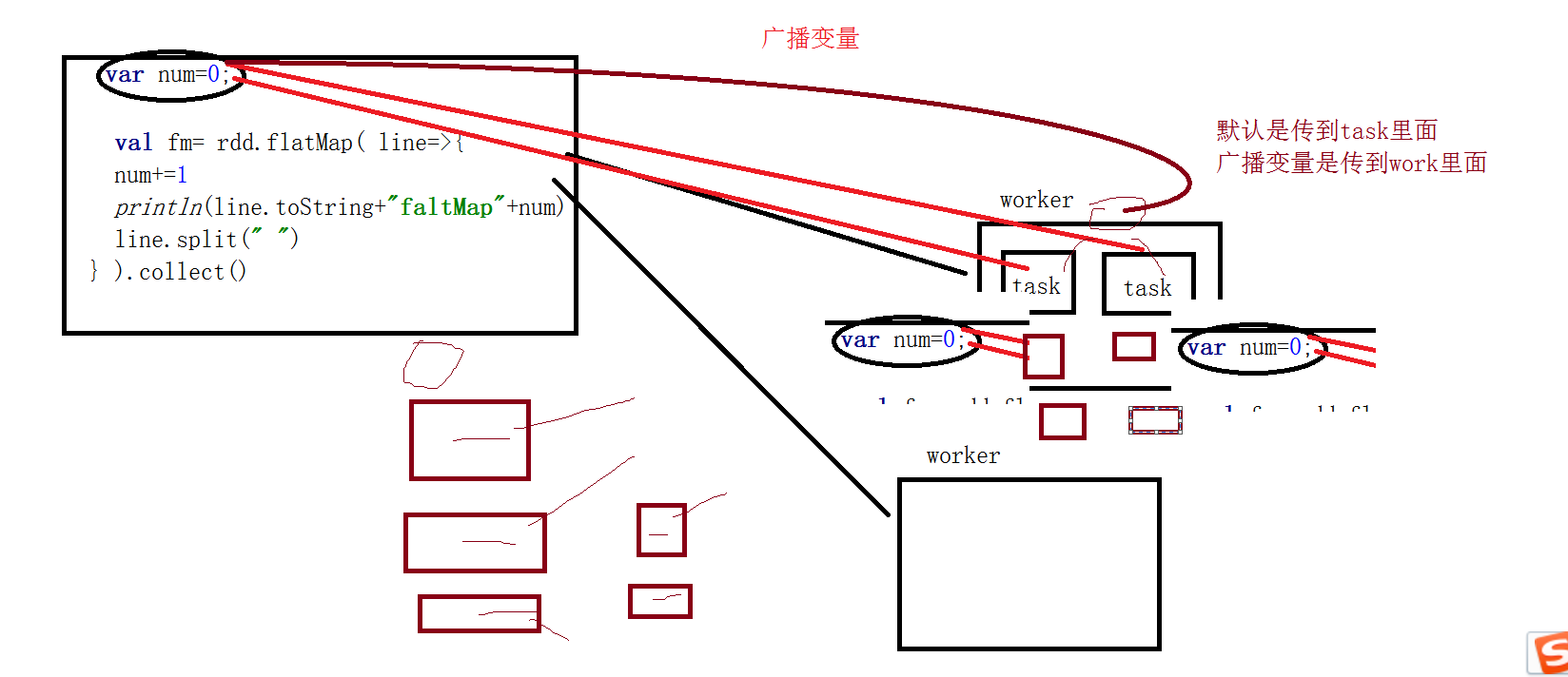
package com.zhiyou100.sparkimport org.apache.log4j.{Level, Logger}import org.apache.spark.{SparkConf, SparkContext}object Demo2 {def main(args: Array[String]): Unit = {val conf=new SparkConf()conf.setAppName("demo2").setMaster("local[2]")val sc=new SparkContext(conf)Logger.getLogger("org.apache.spark").setLevel(Level.OFF)Logger.getLogger("org.apache.hadoop").setLevel(Level.OFF)val list=List("a a","b b","c c")val rdd=sc.parallelize(list)var num=0//var mb=sc.broadcast(num)var numAcc=sc.accumulator(num)val fm=rdd.flatMap(line=>{//mb.value= mb.value +"1"numAcc.add(1)println(line+"flatmap"+num)line.split(" ")}).collect()/* fm.map(t=>{//mb.value.toInt+=1//println(t+"map"+ mb.value)(t,1)}).collect()*/println(numAcc)println(num)}}
Spark算子概述
RDD:弹性分布式数据集,是一种特殊集合、支持多种来源、有容错机制、可以被缓存、支持并行操作,一个RDD代表多个分区里的数据集。
RDD有两种操作算子:
· Transformation(转换):Transformation属于延迟计算,当一个RDD转换成另一个RDD时并没有立即进行转换,仅仅是记住了数据集的逻辑操作
· Action(执行):触发Spark作业的运行,真正触发转换算子的计算
如何获取rdd
1.Rdd=sc.textFile(“文件的路径”)
2.rdd=sc.parallelize(集合)
Transformation算子
map(func)
返回一个新的分布式数据集,由每个原元素经过func函数转换后组成
filter(func)
返回一个新的数据集,由经过func函数后返回值为true的原元素组成
flatMap(func)
类似于map,但是每一个输入元素,会被映射为0到多个输出元素(因此,func函数的返回值是一个Seq,而不是单一元素)
sample(withReplacement, frac, seed)
根据给定的随机种子seed,随机抽样出数量为frac的数据
随机从数据中抽取部分数据,0.2的概率的话,1000个大概得到200个数据
package com.zhiyou100.sparkimport org.apache.spark.{SparkConf, SparkContext}object RDDTest {def main(args: Array[String]): Unit = {val conf=new SparkConf();conf.setAppName("rdd").setMaster("local")val sc=new SparkContext(conf);val list = 1 to 1000val listRDD = sc.parallelize(list)val sampleRDD = listRDD.sample(false, 0.2)sampleRDD.foreach(num => print(num + " "))printlnprintln("sampleRDD count: " + sampleRDD.count())println("Another sampleRDD count: " + sc.parallelize(list).sample(false, 0.2).count())}}

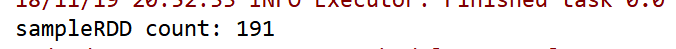

union(otherDataset)
返回一个新的数据集,由原数据集和参数联合而成,两个数据集联合成为一个
groupByKey([numTasks])
在一个由(K,V)对组成的数据集上调用,返回一个(K,Seq[V])对的数据集。注意:默认情况下,使用8个并行任务进行分组,你可以传入numTask可选参数,根据数据量设置不同数目的Task
reduceByKey(func, [numTasks])
在一个(K,V)对的数据集上使用,返回一个(K,V)对的数据集,key相同的值,都被使用指定的reduce函数聚合到一起。和groupbykey类似,任务的个数是可以通过第二个可选参数来配置的。
join(otherDataset, [numTasks])
在类型为(K,V)和(K,W)类型的数据集上调用,返回一个(K,(V,W))对,每个key中的所有元素都在一起的数据集
类似于SQL中的内连接
sortByKey(ascending = false, numPartitions = 1)
combineByKey与aggregateByKey
待补充
Actions算子
reduce(func)
通过函数func聚集数据集中的所有元素。Func函数接受2个参数,返回一个值。这个函数必须是关联性的,确保可以被正确的并发执行
collect()
在Driver的程序中,以数组的形式,返回数据集的所有元素。这通常会在使用filter或者其它操作后,返回一个足够小的数据子集再使用,直接将整个RDD集Collect返回,很可能会让Driver程序OOM(内存溢出)
count()
take(n)
返回一个数组,由数据集的前n个元素组成。注意,这个操作目前并非在多个节点上,并行执行,而是Driver程序所在机器,单机计算所有的元素(Gateway的内存压力会增大,需要谨慎使用)
first()
saveAsTextFile(path)
将数据集的元素,以textfile的形式,保存到本地文件系统,hdfs或者任何其它hadoop支持的文件系统。Spark将会调用每个元素的toString方法,并将它转换为文件中的一行文本
saveAsSequenceFile(path)
将数据集的元素,以sequencefile的格式,保存到指定的目录下,本地系统,hdfs或者任何其它hadoop支持的文件系统。RDD的元素必须由key-value对组成,并都实现了Hadoop的Writable接口,或隐式可以转换为Writable(Spark包括了基本类型的转换,例如Int,Double,String等等)
foreach(func)
在数据集的每一个元素上,运行函数func。这通常用于更新一个累加器变量,或者和外部存储系统做交互
示例代码
package com.zhiyou100.sparkimport org.apache.spark.{SparkConf, SparkContext}object RDDTest {def main(args: Array[String]): Unit = {val conf=new SparkConf();conf.setAppName("rdd").setMaster("local")val sc=new SparkContext();/*如何获取rdd1.Rdd=sc.textFile("文件的路径")2.rdd=sc.parallelize(集合)*/val list=List(1,2,3,4,5,6,7,8,9)val rdd=sc.parallelize(list)//map 返回一个新的数据集RDD,元素个数与原来的一样rdd.map((_,1)).foreach(print(_))//flatMap 输入一个元素,会返回有一个到多个元素//rdd.flatMap(_.toString.split(" ")).foreach(print(_))//filter 返回一个新的Rdd,由经过fun函数后返回值为true的元素rdd.filter(_%2==0)//union 联合,把两个rdd 联合在一起组成一个新的rddval list2=List(1,2,3,4,5,6,7,8,9)val rdd2=sc.parallelize(list2)rdd.union(rdd2).foreach(print(_))//groupbykeyrdd.map((_,1)).groupByKey()//reducebykey 5,表示分区数rdd.map((_,1)).reduceByKey(_+_,5)//joinval a=rdd.map((_,1))val b=rdd2.map((_,1))a.join(b).foreach(print(_))// rdd.map((_,1)).join()a.saveAsTextFile("/ttttt")sc.stop()}}
宽依赖和窄依赖
窄依赖(narrow dependencies)
子RDD的每个分区依赖于常数个父分区(与数据规模无关)
输入输出一对一的算子,且结果RDD的分区结构不变。主要是map/flatmap输入输出一对一的算子
但结果RDD的分区结构发生了变化,如union/coalesce
从输入中选择部分元素的算子,如filter、distinct、substract、sample
宽依赖(wide dependencies)
子RDD的每个分区依赖于所有的父RDD分区
对单个RDD基于key进行重组和reduce,如groupByKey,reduceByKey
对两个RDD基于key进行join和重组,如join
经过大量shuffle生成的RDD,建议进行缓存。这样避免失败后重新计算带来的开销。
本地开发所需的依赖
<dependency><groupId>org.scala-lang</groupId><artifactId>scala-library</artifactId><version>2.10.5</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.10</artifactId><version>1.6.2</version></dependency>

若有收获,就点个赞吧
0 人点赞
