Spark简介
00Spark介绍.doc
1.运行速度较快,速度大约是MapReduce的10倍
Apache Spark使用最先进的DAG调度程序,查询优化器和物理执行引擎,实现批处理和流数据的高性能。
2.便于使用
使用Java,Scala,Python,R和SQL快速编写应用程序。
3.范围广
结合Sql,Stream和复杂的分析
4.到处运行
spark可以在Hadoop,Apache Mesos kuberNetes,独立访问各种数据源
spark与hadoop的区别
Spark是基于内存的,Hadoop是基于磁盘的
Spark的计算模型非常丰富,hadoop非常的单一(算子,SQL,Streaming计算)
Spark处理数据是迭代计算的,而hadoop是非迭代的
Spark支持批处理和流处理,而hadoop只处理离线数据
Spark的大数据存储依赖于hdfs
Spark和Storm的比较
Storm是一个实时流处理
Spark是一个准实时流处理
Spark基本工作原理
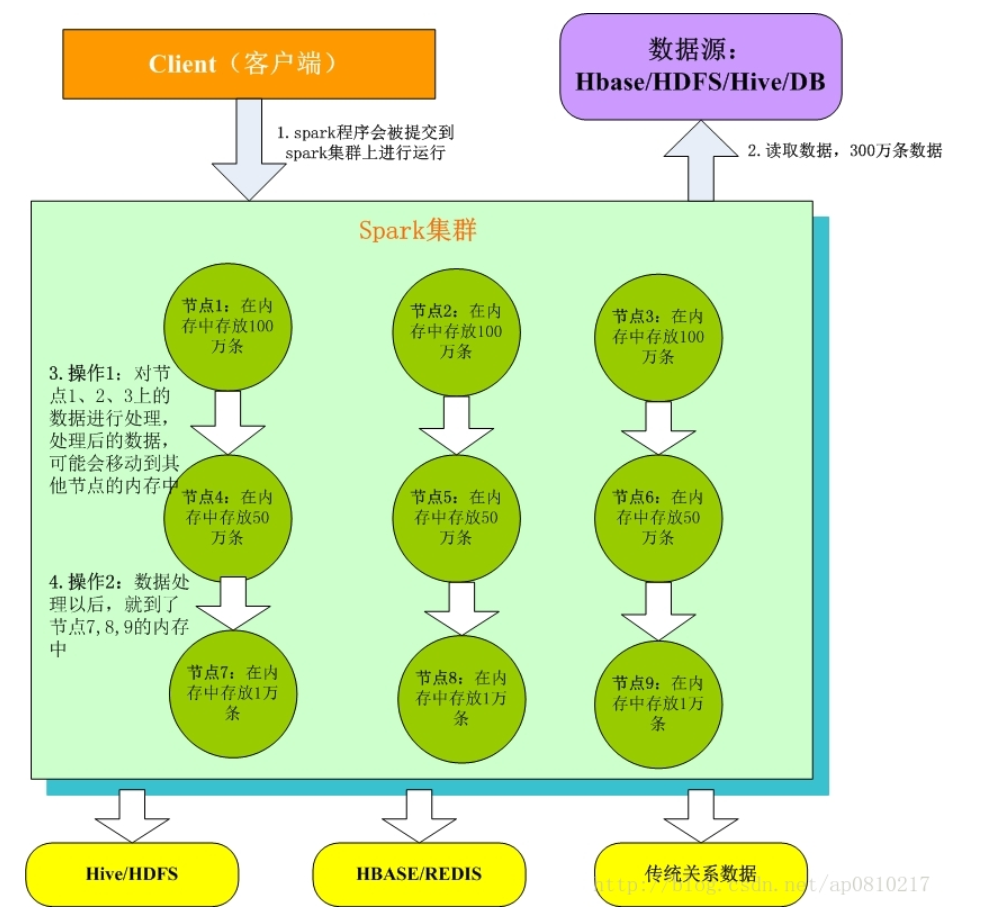
- Client客户端:我们在本地编写了spark程序,打成jar包,或python脚本,通过spark submit命令提交到Spark集群;
2. 只有Spark程序在Spark集群上运行才能拿到Spark资源,来读取数据源的数据进入到内存里;
3. 客户端就在Spark分布式内存中并行迭代地处理数据,注意每个处理过程都是在内存中并行迭代完成;注意:每一批节点上的每一批数据,实际上就是一个RDD!!!一个RDD是分布式的,所以数据都散落在一批节点上了,每个节点都存储了RDD的部分partition。
4. Spark与MapReduce最大的不同在于,迭代式计算模型:MapReduce,分为两个阶段,map和reduce,两个阶段完了,就结束了,所以我们在一个job里能做的处理很有限; Spark,计算模型,可以分为n个阶段,因为它是内存迭代式的。我们在处理完一个阶段以后,可以继续往下处理很多个阶段,而不只是两个阶段。所以,Spark相较于MapReduce来说,计算模型可以提供更强大的功能。
Spark开发
- 核心开发:离线批处理 / 延迟性的交互式数据处理
Spark的核心编程是什么?其实,就是: 首先,第一,定义初始的RDD,就是说,你要定义第一个RDD是从哪里,读取数据,hdfs、linux本地文件、程序中的集合。 第二,定义对RDD的计算操作,这个在spark里称之为算子,map、reduce、flatMap、groupByKey,比mapreduce提供的map和reduce强大的太多太多了。 第三,其实就是循环往复的过程,第一个计算完了以后,数据可能就会到了新的一批节点上,也就是变成一个新的RDD。然后再次反复,针对新的RDD定义计算操作。。。。 第四,最后,就是获得最终的数据,将数据保存起来。 - SQL查询:底层都是RDD和计算操作
- 实时计算:底层都是RDD和计算操作
Spark常用核心模块
1、核心模块开发:离线批处理 Spark Core
2、实时计算:底层也是基于RDD Spark Streaming
3、Spark SQL/Hive:交互式分析
4、Spark Graphx:图计算
5、Spark Mlib: 数据挖掘和机器学习
核心概念名词
1.ClusterManager:在Standalone模式中即为Master(主节点),控制整个集群,监控Worker。在YARN模式中为 资源管理器。
2.Worker:从节点,负责控制计算节点,启动Executor。在YARN模式中为NodeManager,负责计算节点的控制。
3.Driver:运行Application的main()函数并创建SparkContext。
4.Executor:执行器,在worker node上执行任务的组件、用于启动线程池运行任务。每个Application拥有独立的一 组Executors。
5.SparkContext:整个应用的上下文,控制应用的生命周期。
6.RDD:Spark的基本计算单元,一组RDD可形成执行的有向无环图RDD Graph。
7.DAG Scheduler:实现将Spark作业分解成一到多个Stage,每个Stage根据RDD的Partition个数决定Task的个数,然后生成相应的Task set放到TaskScheduler中。
8.TaskScheduler:将任务(Task)分发给Executor执行。(所以Executor执行的就是我们的代码)
9.·Stage:一个Spark作业一般包含一到多个Stage。
10.Task:一个Stage包含一到多个Task,通过多个Task实现并行运行的功能。
11.Transformations:转换(Transformations) (如:map, filter, groupBy, join等),Transformations操作是Lazy的, 也就是说从一个RDD转换生成另一个RDD的操作不是马上执行,Spark在遇到Transformations操作时只会记录需 要这样的操作,并不会去执行,需要等到有Actions操作的时候才会真正启动计算过程进行计算。
12.Actions:操作(Actions) (如:count, collect, save等),Actions操作会返回结果或把RDD数据写到存储系统中。 Actions是触发Spark启动计算的动因 。
13.SparkEnv:线程级别的上下文,存储运行时的重要组件的引用。
SparkEnv内创建并包含如下一些重要组件的引用。
MapOutPutTracker:负责Shuffle元信息的存储。
BroadcastManager:负责广播变量的控制与元信息的存储。
BlockManager:负责存储管理、创建和查找块。
MetricsSystem:监控运行时性能指标信息。
SparkConf:负责存储配置信息。
Spark单机安装部署
(提示,如果使用xshell之类的软件,测试安装是否完成时需要在,让环境变量生效的那个页面测试,否则会出错)
1.首先安装scala
上传scala压缩包
解压scala压缩文件 [root@master scala]# tar -zxvf scala-2.10.5.tgz
配置环境变量
#scala
export SCALA_HOME=/usr/scala/scala-2.10.5
export PATH=$PATH:$SCALA_HOME/bin
2.然后安装spark
上传spark压缩包
解压spark压缩文件 [root@master spark]# tar -zxvf spark-2.1.1-bin-hadoop2.7.tgz
配置环境变量
#spark
export SPARK_HOME=/usr/spark/spark-2.1.1-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin
3.测试是否安装成功
scala
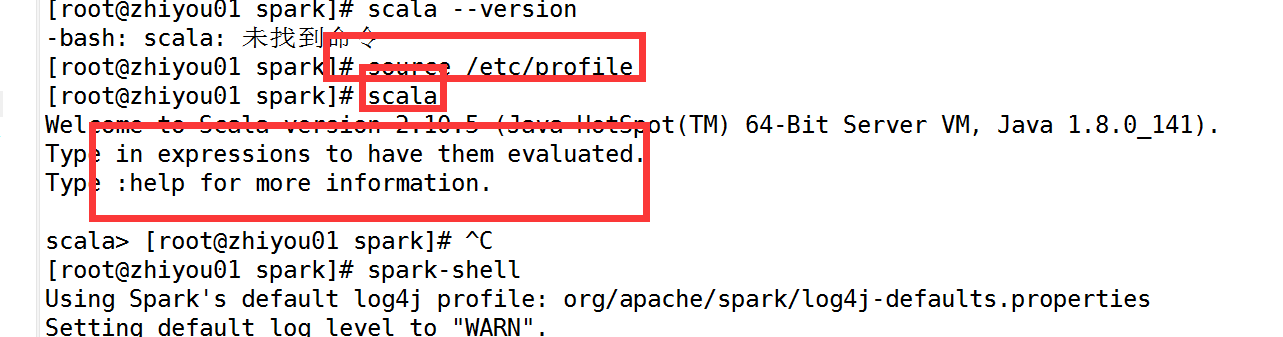
spark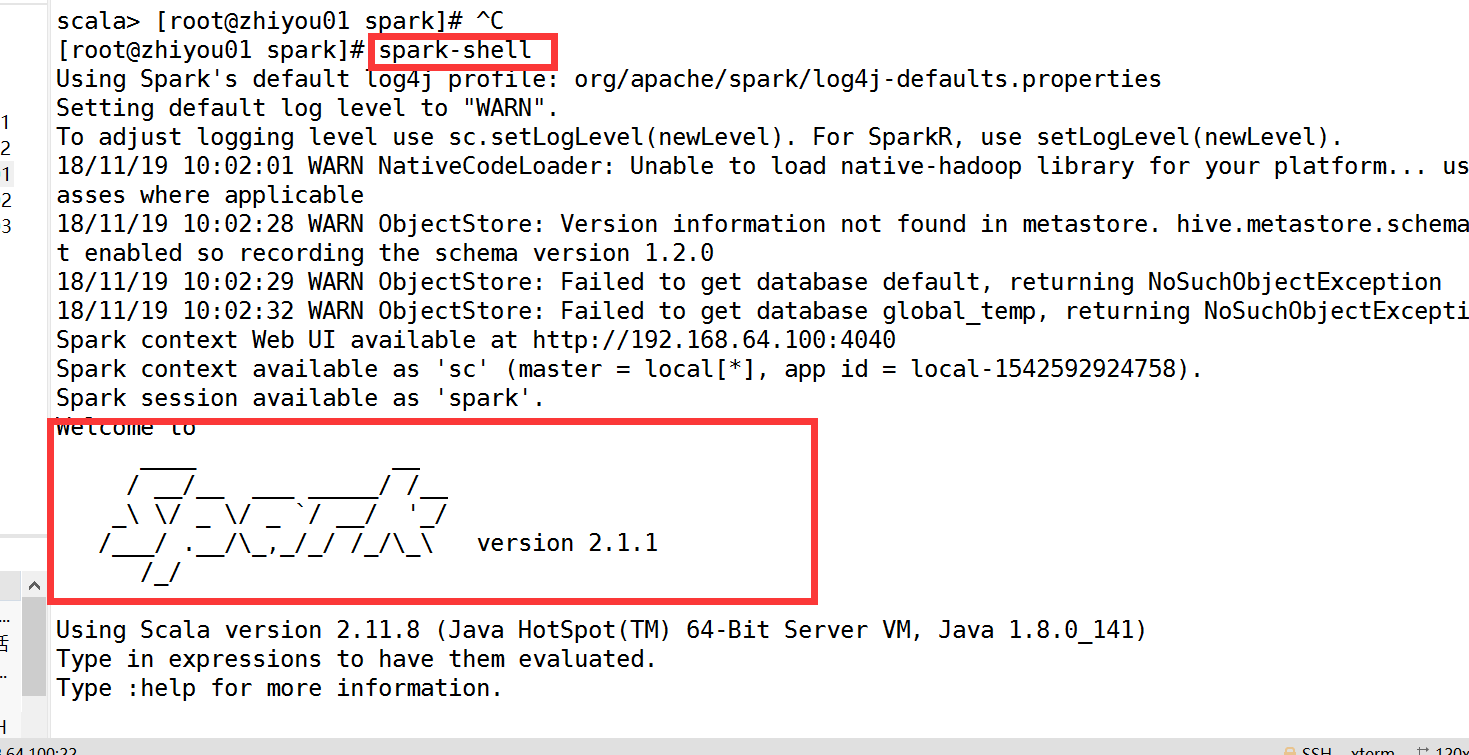
Spark集群安装(完全分布式安装)
在单节点安装的基础上
1.修改spark-env.sh
进入到conf目录 /usr/spark/spark-2.1.1-bin-hadoop2.7/conf
重命名文件 cp spark-env.sh.template spark-env.sh
编辑spark-en.sh文件 vim spark-env.sh
添加以下内容
#jdk的安装目录
export JAVA_HOME=/usr/etc/jdk1.8.0_181
#scala的安装目录
export SCALA_HOME=/usr/scala/scala-2.10.5
#主节点名
export SPARK_MASTER_IP=master
export SPARK_MASTER_PORT=7077
export SPARK_WORKER_CORES=1
export SPARK_WORKER_INSTANCES=1
export SPARK_WORKER_MEMORY=1g
#hadoop配置文件的目录
export HADOOP_CONF_DIR=/usr/hadoop-2.7.7/etc/hadoop
创建slaves文件 cp slaves.template slaves
修改slaves配置文件 vim slaves
将该文件中的localhost删除,然后添加两个子节点的主机名(Ip)
然后从主节点分发 scala ,spark 和 /etc/profile 文件 到每个子节点
命令格式(以下以spark为例)
scp -r /usr/spark/ root@slaver1:/usr/
启动spark
进入到spark的sbin目录执行 ./start-all.sh
修改事宜
为了避免和hadoop中的start/stop-all.sh脚本发生冲突,将spark/sbin/start/stop-all.sh重命名
在spark的sbin目录下执行以下的命令(也可以不做,每次执行的时候到spark中sbin目录下执行命令)
mv start-all.sh start-spark-all.sh
mv stop-all.sh stop-spark-all.sh
也可以jps查看是否启动成功

启动shell
在spark的bin目录下执行 ./spark-shell
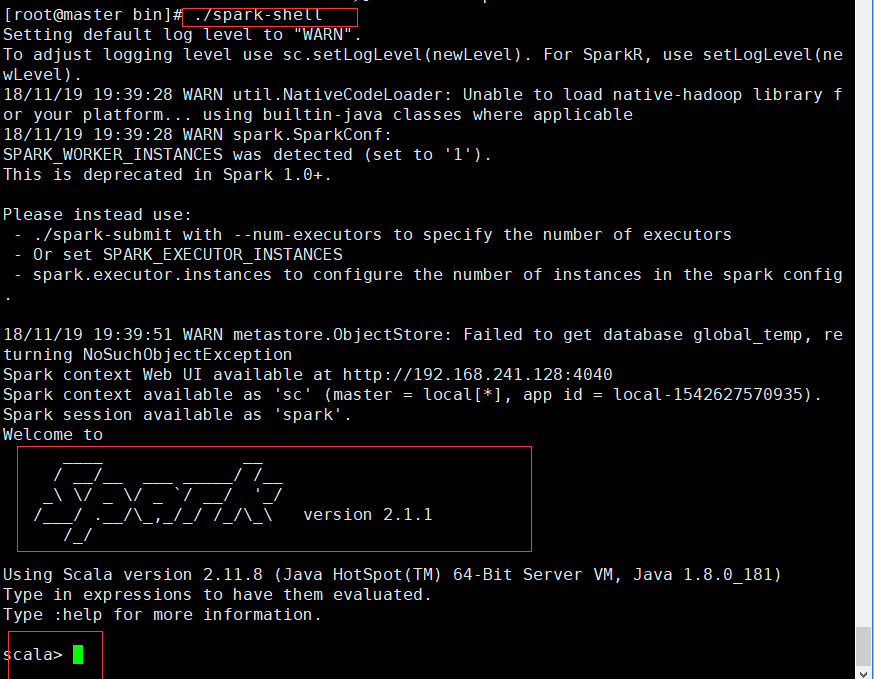
端口号
8080—>spark集群的访问端口,类似于hadoop中的50070和8088的综合
4040—>sparkUI的访问地址
7077—>hadoop中的9000端口
Spark开发 wc (IDEA开发)
创建Scala+Maven工程
创建java工程+scala类添加maven即可,添加maven即可(添加)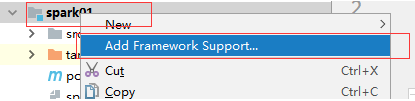
然后在最下面选择maven,然后点击ok

代码的发布
首先编写代码
然后将代码打成jar包(IDEA中初次使用maven打成jar包)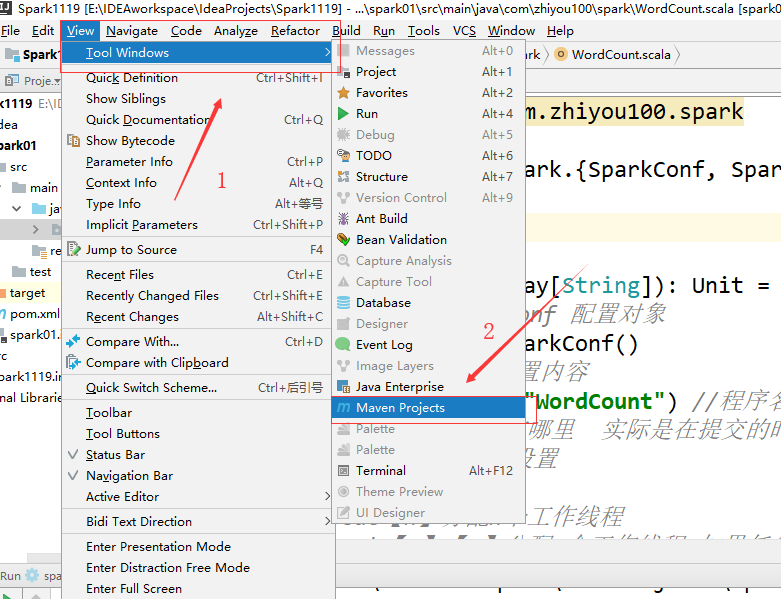
然后在IDEA的右边会出现以下的窗口,按照下图顺序依次点击,也可以直接点击install
然后代码会自动打包并发布到本地的maven仓库中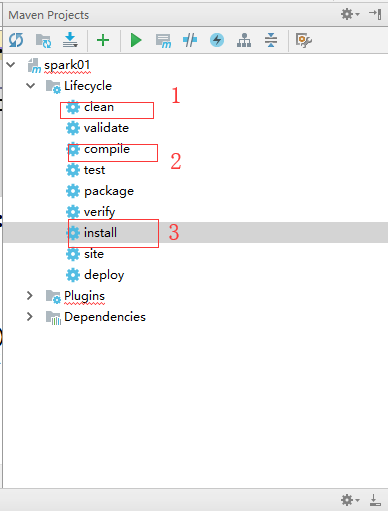
然后去本地仓库找到打好的jar包,上传到linux上,然后再上传到hdfs上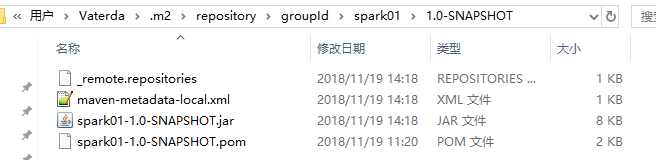
运行在本地
[root@master bin]# ./spark-submit —master local —class main.java.com.zhiyou100.spark.WordCount /spark01-1.0-SNAPSHOT.jar /name.log
命令解析: local 表示运行在linux本机上
main.java.com.zhiyou100.spark.WordCount 表示的是类的位置
/spark01-1.0-SNAPSHOT.jar 表示代码jar包在linux上的位置
/name.log 表示的是传入的参数,即处理文件在hdfs上的位置
运行在集群上面
[root@master bin]# ./spark-submit —master spark://master:7077 —class main.java.com.zhiyou100.spark.WordCount /spark01-1.0-SNAPSHOT.jar /name.log
IDEA开发wc中使用的jar包
<?xml version="1.0" encoding="UTF-8"?><project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>groupId</groupId><artifactId>spark_01</artifactId><version>1.0-SNAPSHOT</version><dependencies><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.11</artifactId><version>2.1.0</version></dependency><dependency><groupId>org.scala-lang</groupId><artifactId>scala-library</artifactId><version>2.10.5</version></dependency></dependencies><build><plugins><plugin><groupId>org.scala-tools</groupId><artifactId>maven-scala-plugin</artifactId><executions><execution><goals><goal>compile</goal><goal>testCompile</goal></goals></execution></executions><configuration><sourceDir>src/main/java</sourceDir><jvmArgs><jvmArg>-Xms64m</jvmArg><jvmArg>-Xmx1024m</jvmArg></jvmArgs></configuration></plugin></plugins></build></project>
该例子中所使用的代码
package main.java.com.zhiyou100.sparkimport org.apache.spark.{SparkConf, SparkContext}object WordCount {def main(args: Array[String]): Unit = {//1.新建spark的conf 配置对象val conf =new SparkConf()//2.向conf里面设置内容conf.setAppName("WordCount") //程序名//设置spark运行在哪里 实际是在提交的时候通过shell 指定的//本地运行在这里设置/*local【n】分配n个工作线程local【n】【m】分配n个工作线程,如果任务失败了有m机会重现提交local【*】自动分配资源,由电脑决定*///集群运行时去掉//conf.setMaster("local")//3.创建sparkContextval sc=new SparkContext(conf)//4.WordCount开发步骤val lines=sc.textFile(args(0))//hdfs上传入参数,文件的位置//4.2处理数据//(a,1)(a,1)(b,1)lines.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).foreach(println(_))sc.stop()}}
Spark中的wc开发之java版本
03Spark WC开发与应用部署——参考.doc
.

若有收获,就点个赞吧
0 人点赞
