数据同步
复制命令
| 版本 | 命令 |
|---|---|
| redis<2.8 | sync |
| redis>=2.8 | psync |
同步类型
- 全量复制:一般首次启用主从复制时;当数据量大时,会占用大量的主从性能和网络开销。
- 部分复制:用于处理当网络等原因引起的部分主从复制异常,导致的资料丢失;会在条件允许的情况下,进行补发;性能消耗会降低很多。
psync 命令
依赖支持
- 主从节点各自复制偏移量。
- 主节点复制积压缓冲区。
- 主节点运行id。
复制偏移量
参与复制的主从节点都会维护自身复制偏移量。主节点(master)在处理完写入命令后,会把命令的字节长度做累加记录。从节点(slave)每秒钟上报自身的复制偏移量给主节点,因此主节点也会保存从节点的复制偏移量。

主和从节点的统计信息在主节点查看:info relication 中的 master_repl_offset 和 slave0 指标中。
主节点信息:
# Replicationrole:masterconnected_slaves:1slave0:ip=127.0.0.1,port=6380,state=online,offset=121765,lag=0 // # offset为从节点0节点的偏移量master_replid:8f185636f16b9d7ca04404a6f8b428afe3fdcb86master_replid2:0000000000000000000000000000000000000000master_repl_offset:121765 # <<<<<<<<< 主节点当前偏移量second_repl_offset:-1repl_backlog_active:1repl_backlog_size:1048576repl_backlog_first_byte_offset:1repl_backlog_histlen:121765
从节点信息:slave_repl_offset
# Replication
role:slave
master_host:0.0.0.0
master_port:6379
master_link_status:up
master_last_io_seconds_ago:6
master_sync_in_progress:0
slave_repl_offset:122059 # <<<<< 当前从节点偏移量
slave_priority:100
slave_read_only:1
connected_slaves:0
master_replid:8f185636f16b9d7ca04404a6f8b428afe3fdcb86
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:122059
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:868
repl_backlog_histlen:121192
总结:**可通过主从句节点的偏移量查看主从是否存在延迟或数据是否一致情况。
运维知识:主从延迟较大的原因可能是:网络延迟、命令阻塞等。
复制积压缓冲区
复制积压缓冲区是保存在主节点的一个固定长度队列,默认为 1MB,当有从节点连接时,主节点相应的写命令,不仅会发送到从节点,也会写入到复制积压缓冲区。
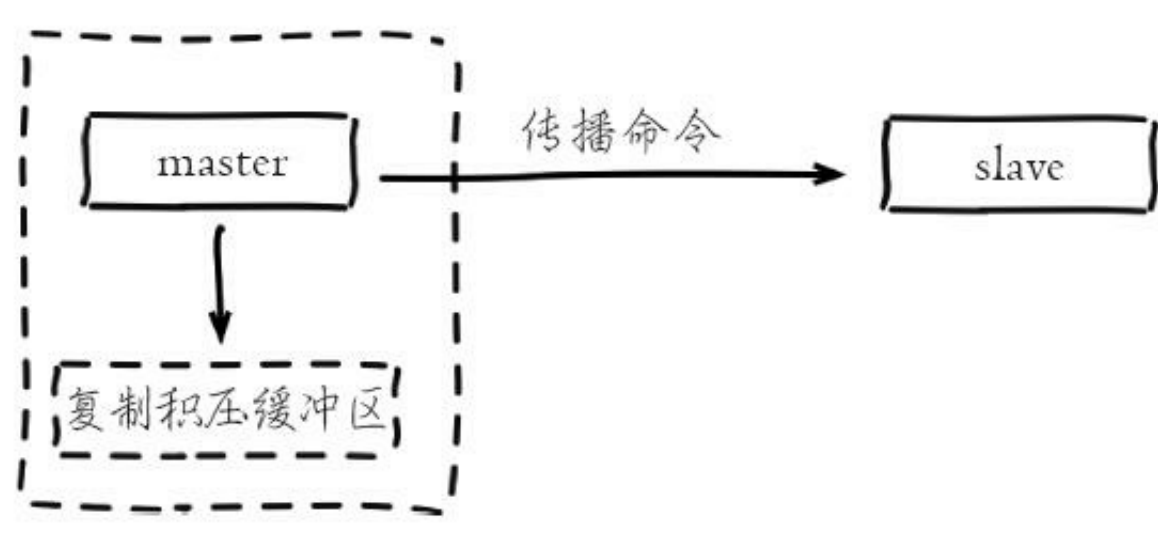
说明:复制积压缓冲区主要用于部分复制和复制命令丢失时的数据补救。
主节点运行id
每个 Redis 启动后,会动态生产一个约 40 位的十六进制字符串作为运算符。主要用于识别唯一 Redis 实例。
从节点会保存主节点运行的 ID,以便知道在复制哪个主节点。而不能仅仅使用 IP + PORT 方式,因为当主节点的数据变化了(如:RDB、AOF 方式恢复),从节点因为偏移量差异,会导致异常。所以当主节点的运行 ID 变化时,从节点会全量复制。
如何可让不变更运行 ID 来重启?
可使用 debug reload 命令(重新加载 RDB 文件),也能减少不必要的全量复制。
命令语法
psync {runId} {offset}
runId:从节点所复制主节点的运行idoffset:当前从节点已复制的数据偏移量
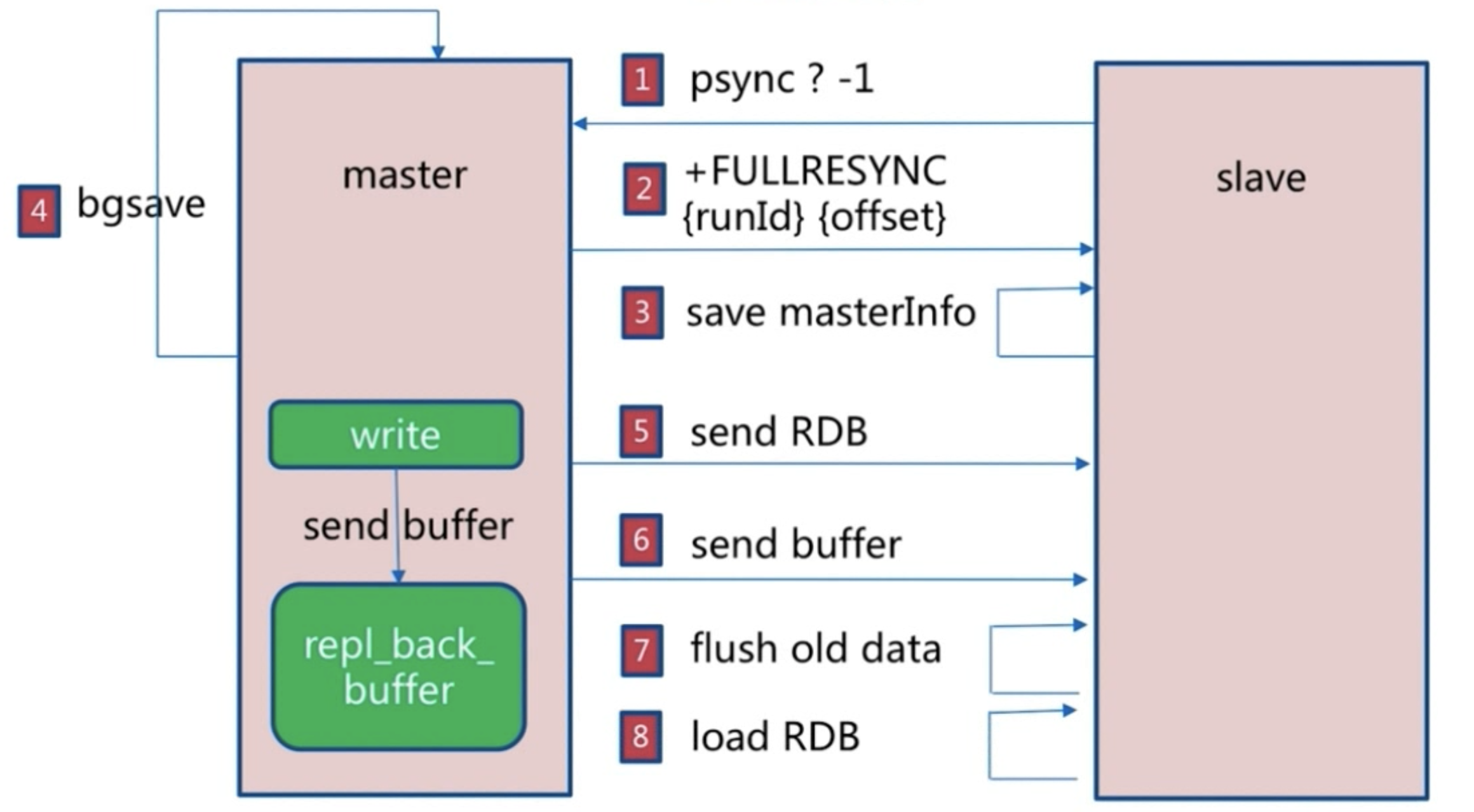
运行流程
psync 运行流程如下:

若有收获,就点个赞吧
0 人点赞
