数据分布理论
理论简介
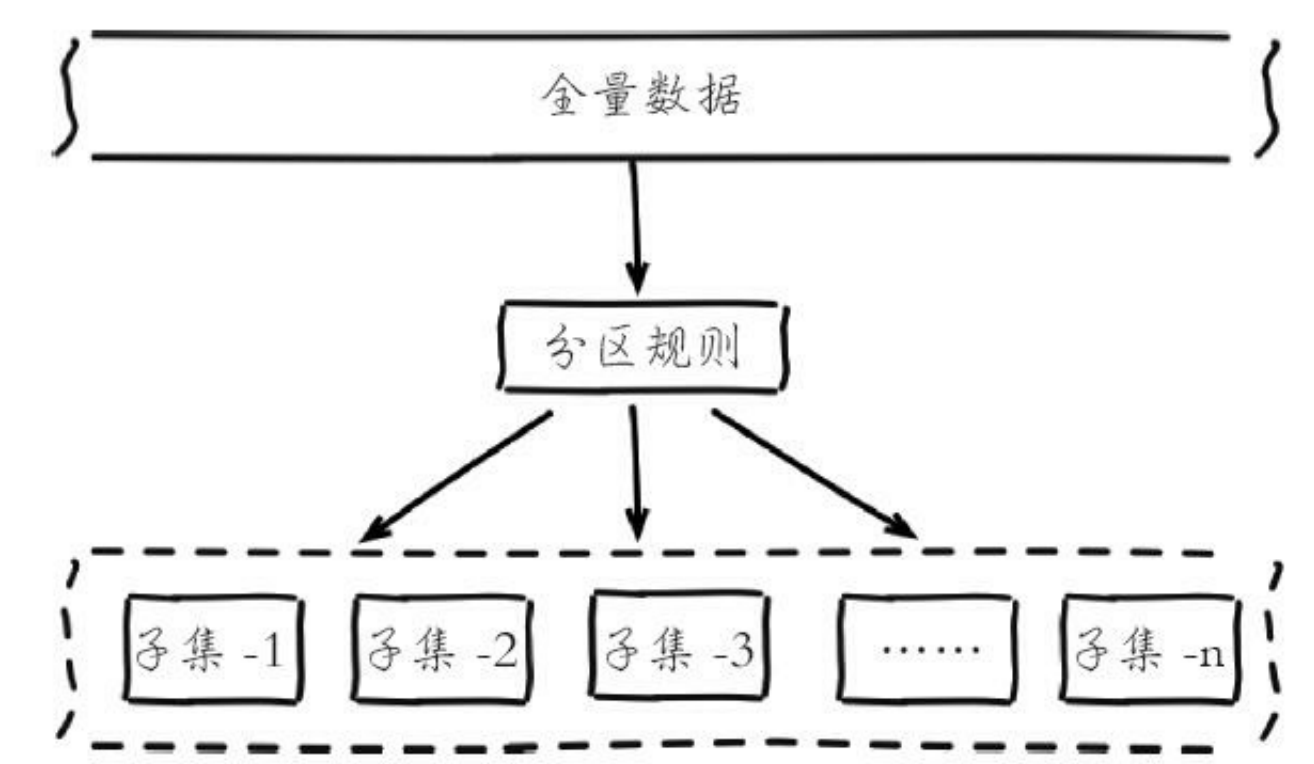
分布式数据库需要存储整个数据,会按照分布规则,将数据拆分映射到不同的节点,每个节点负责整个数据的一个子集。
常见的分区规则有:
- 哈希分区
- 顺序分区
哈希分区与顺序分区的区别:
| 分区方式 | 特点 | 代表产品 |
|---|---|---|
| 哈希分区 | - 离散度好 - 数据分布业务无关 - 无法顺序访问 |
- Redis Cluster - Cassandra - Dynamo |
| 顺序分区 | - 离散度易倾斜 - 数据分布业务相关 - 可顺序访问 |
- Bigtable - HBase - Hypertable |
哈希分区
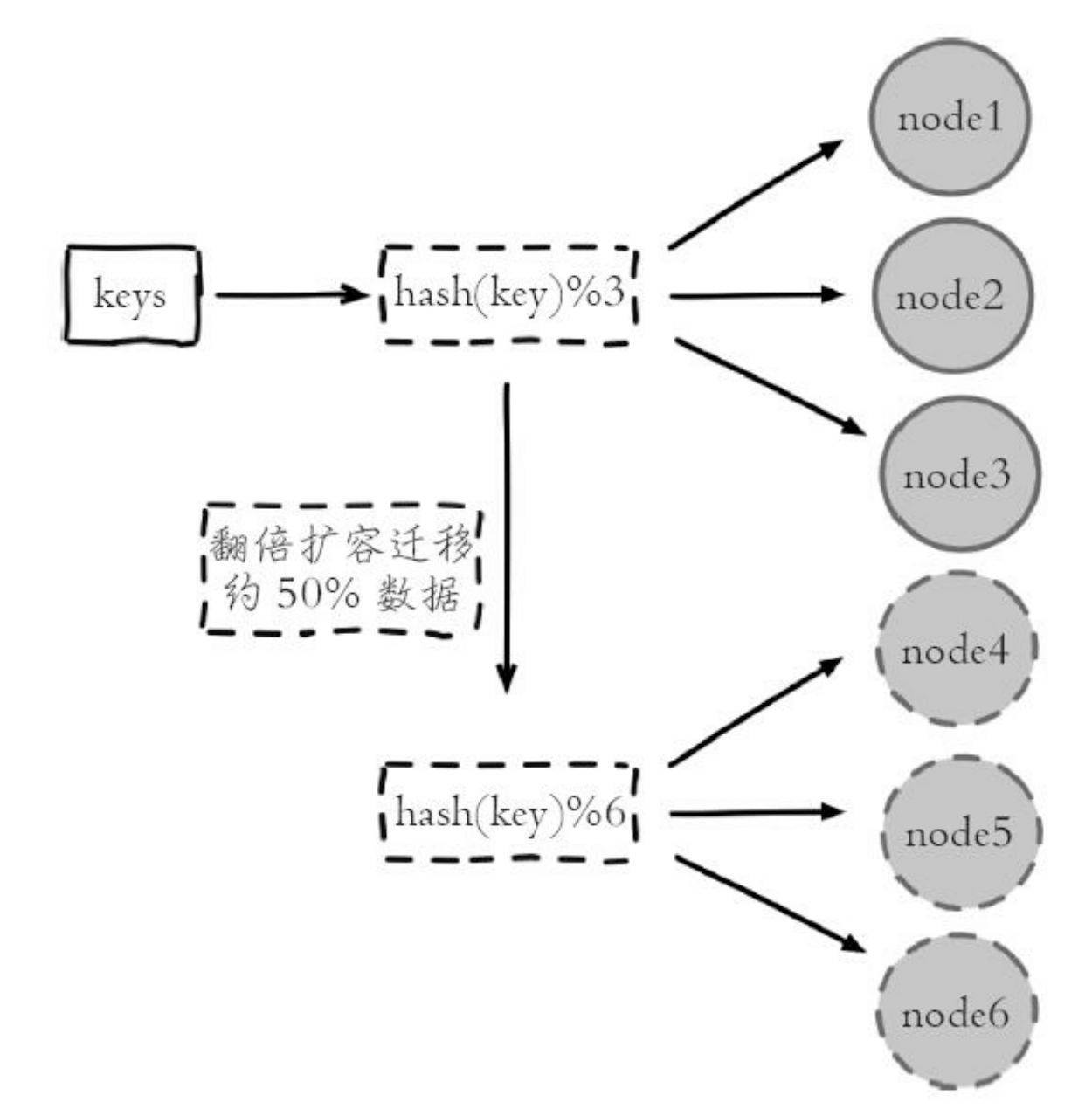
节点取余分区
概念:使用特定的数据,如 Redis 的键或用户 ID,根据节点数量 N(或大于N)使用公式: hash(key)%N 计算哈希值,确定数据映射到哪个节点。
不足:当节点数量变化时,如扩容或收缩节点,数据节点的映射关系会跟随变化,导致数据迁移。
优势:简单,常用于数据库分库分表规则;
- 扩容一般采用翻倍扩容,避免全量数据导致迁移。如图示:
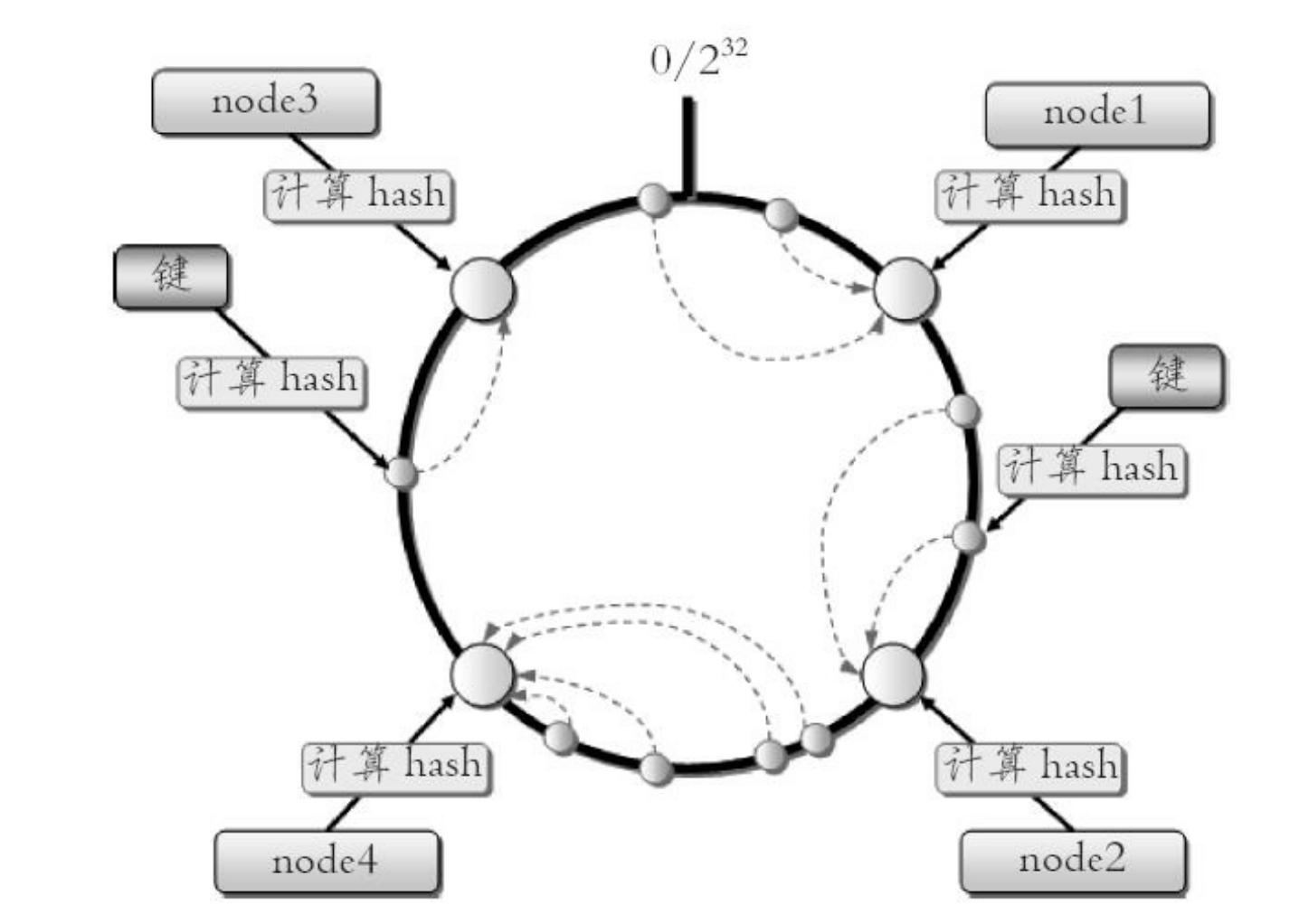
一致性哈希分区
概念:系统每个节点分配一个 token(范围一般在 0 ~2^32),并构成一个哈希环。数据计算成 hash 值后,顺时针找到第一个相邻的哈希值的 token(即对应节点)。
- Dynamo 系统使用的是该分区方式
不足:
- 删减节点,存在数据偏移,导致部分数据无法命中;
- 节点删减,一般建议增加一倍或减少一半节点,以达到数据和负载均衡
- 不适用少量节点的架构
- 数据倾斜
优势:加入、删除节点只对相邻的节点有影响,其他不影响。且当某节点故障时候,由于瞬时间查找节点,以至于容错性更高。
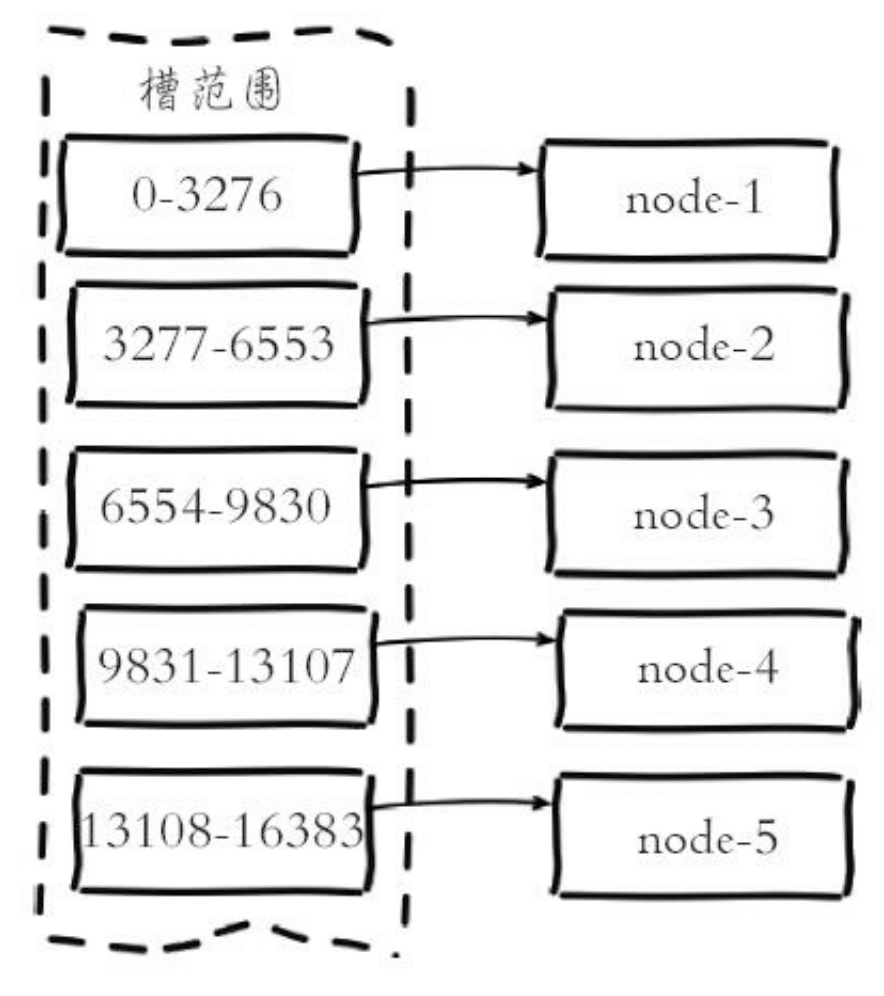
虚拟槽分区
概念:使用哈希空间,结合良好的哈希函数将数据映射到固定范围的整数集合中,其中整数的定义为“槽(slot)”。
- Redis Cluster 即采用该分区方式。
- 一般槽(slot)的数据范围远大于节点数,如 Redis Cluster 槽范围是 0~16383。
目的:方便数据拆分和集群扩展。
**
- 优势:由于采用高质量的哈希算法,每个槽索所映射的数据比较均匀。
Redis 数据分区
Redis Cluster 采用虚拟槽分区,槽范围:0~16383;其中哈希计算方式:slot = CRC16(key) & 16383;
其中每个节点负责维护一部分分槽以及对应的槽的键值数据。如图为槽集合与节点的关系:
Redis 虚拟槽分区的特点:
- 解耦数据与节点关系,简化节点扩容和收缩难度
- 节点自身维护槽的映射关系,无需客户端或代理服务器维护槽分区元数据
- 支持节点、槽、键之间的映射查询,可用于数据路由、在线伸缩灯场景
集群功能限制
Redis Cluster 集群相对于单机,存在一定的功能限制,限制如下:
- key 批量操作支持有限制。如:mset、mget、pipiline 等,只支持具有相同 slot 值的 key 进行批量操作。
- key 支持事物操作有限制。同 slot 值情况。
- key 为 Redis 数据的最小粒度。所以,如:hash、list等集合性数据的 field 等数据不支持分布到不同节点。
- 不支持多数据库空间。单机支持 16 个数据库,集群模式只能用一个数据空间,即 db0。
- 复制结构只支持一层,从节点只能复制主节点,不支持嵌套数状复制结构。

若有收获,就点个赞吧
0 人点赞
