数据清洗
通常,我们从 Excel、CSV 或数据库中获取到的数据并不是非常完美的,里面可能因为系统或人为的原
因混入了重复值或异常值,也可能在某些字段上存在缺失值;再者, DataFrame 中的数据也可能存在格
式不统一、量纲不统一等各种问题。因此,在开始数据分析之前,对数据进行清洗就显得特别重要。
缺失值
可以使用 DataFrame 对象的 isnull 或 isna 方法来找出数据表中的缺失值,如下所示。
import pandas as pdimport pymysqlconn = pymysql.connect( host='47.104.31.138', port=3306,user='guest', password='Guest.618',database='hrs', charset='utf8mb4' )dept_df = pd.read_sql('select * from tb_dept', conn, index_col='dno')emp_df = pd.read_sql('select * from tb_emp', conn, index_col='eno')print(emp_df.isnull())或者print(emp_df.isna())
两条结果一样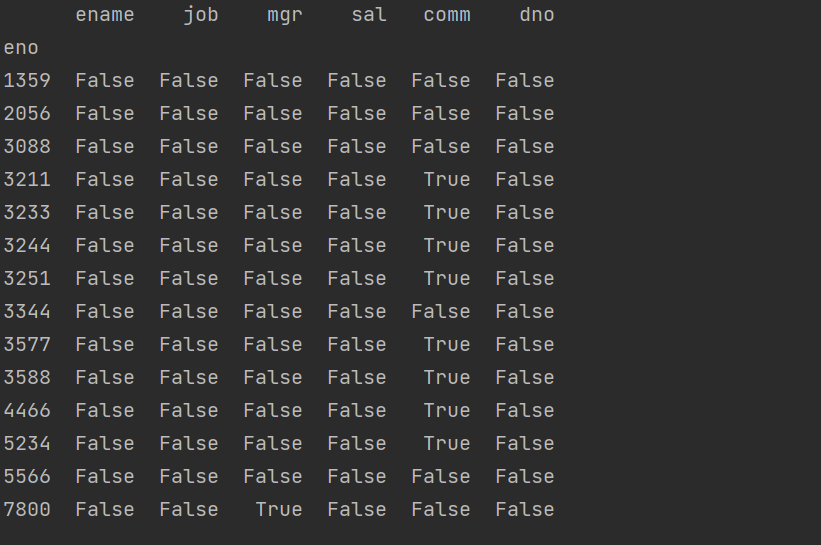
相对应的, notnull 和 notna 方法可以将非空的值标记为 True 。如果想删除这些缺失值,可以使用
DataFrame 对象的 dropna 方法,该方法的 axis 参数可以指定沿着0轴还是1轴删除,也就是说当遇到
空值时,是删除整行还是删除整列,默认是沿0轴进行删除的,代码如下所示。
print(emp_df.dropna())
输出: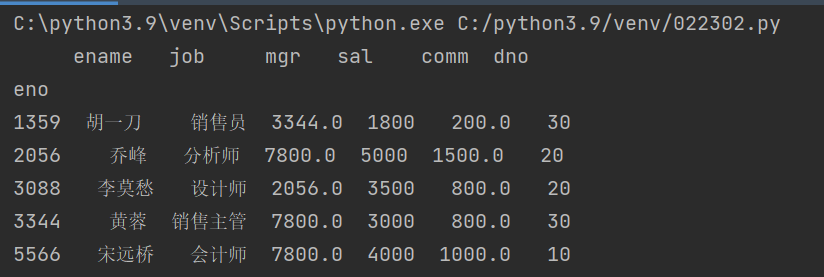
axis:轴。0或’index’,表示按行删除;1或’columns’,表示按列删除。
如果要沿着1轴进行删除,可以使用下面的代码。
print(emp_df.dropna(axis=1))
结果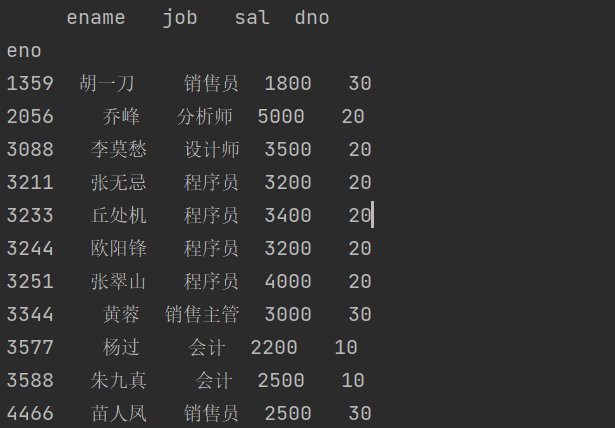
注意: DataFrame 对象的很多方法都有一个名为 inplace 的参数,该参数的默认值为 False ,表
示我们的操作不会修改原来的 DataFrame 对象,而是将处理后的结果通过一个新的 DataFrame 对
象返回。如果将该参数的值设置为 True ,那么我们的操作就会在原来的 DataFrame 上面直接修
改,方法的返回值为 None 。简单的说,上面的操作并没有修改 emp_df ,而是返回了一个新的
DataFrame 对象。
在某些特定的场景下,我们可以对空值进行填充,对应的方法是 fillna ,填充空值时可以使用指定的
值(通过 value 参数进行指定),也可以用表格中前一个单元格(通过设置参数 method=ffill )或后
一个单元格(通过设置参数 method=bfill )的值进行填充,当代码如下所示。
print(emp_df.fillna(value=0))
注意:填充的值如何选择也是一个值得探讨的话题,实际工作中,可能会使用某种统计量(如:均
值、众数等)进行填充,或者使用某种插值法(如:随机插值法、拉格朗日插值法等)进行填充,
甚至有可能通过回归模型、贝叶斯模型等对缺失数据进行填充。
结果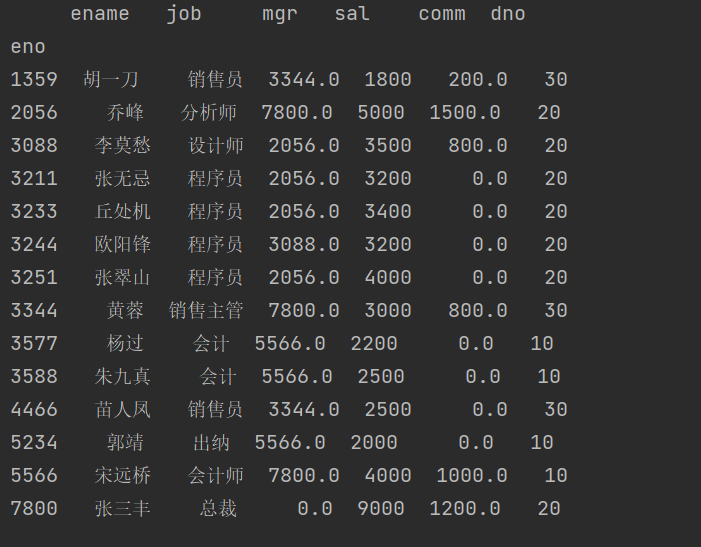
重复值
接下来,我们先给之前的部门表添加两行数据,让部门表中名为“研发部”和“销售部”的部门各有两个。
import pandas as pdimport pymysqlconn = pymysql.connect( host='47.104.31.138', port=3306,user='guest', password='Guest.618',database='hrs', charset='utf8mb4' )dept_df = pd.read_sql('select * from tb_dept', conn, index_col='dno')dept_df.loc[50] = {'dname': '研发部', 'dloc': '上海'}dept_df.loc[60] = {'dname': '销售部', 'dloc': '长沙'}print(dept_df)
结果
现在,我们的数据表中有重复数据了,我们可以通过 DataFrame 对象的 duplicated 方法判断是否存在
重复值,该方法在不指定参数时默认判断行索引是否重复,我们也可以指定根据部门名称 dname 判断部
门是否重复,代码如下所示。
print(dept_df.duplicated('dname'))
结果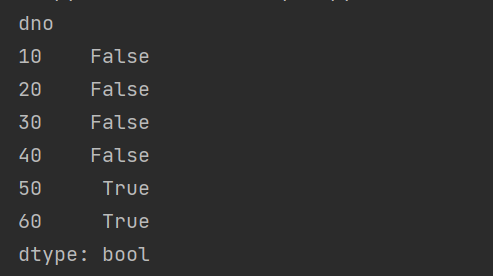
从上面的输出可以看到, 50 和 60 两个部门从部门名称上来看是重复的,如果要删除重复值,可以使用
drop_duplicates 方法,该方法的 keep 参数可以控制在遇到重复值时,保留第一项还是保留最后一
项,或者多个重复项一个都不用保留,全部删除掉。
print(dept_df.drop_duplicates('dname'))
结果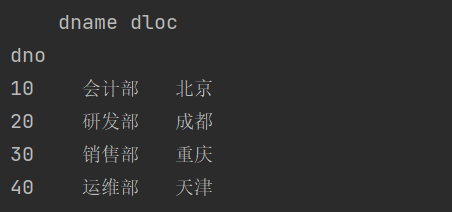
keep 包含三个参数first, last, False,first是指,保留搜索到的第一个重复数据,之后的都删除;last是指,保留搜索到的最后一个重复数据,之前的搜索到的重复数据都删除,False是指,把所有搜索到的重复数据都删除,一个都不保留,即如果有两行数据重复,把两行数据都删除,而不是保留其中一行。默认参数是first。
将 keep 参数的值修改为 last 。
print(dept_df.drop_duplicates('dname', keep='last'))
结果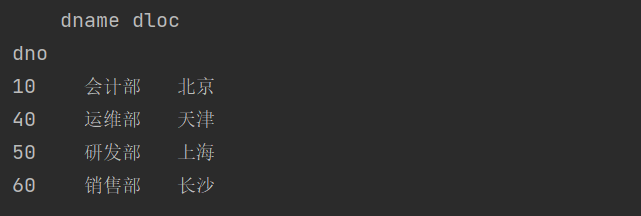
异常值
略
预处理
数据离散化

若有收获,就点个赞吧
0 人点赞
