- 测试基础
- 测试场景
- 编程基础
- 中间件与框架
- 计算机网络
- OSI七层模型
- TCP/IP协议
- cookie和session是什么,
- DNS协议和作用,DNS的查询方式
- ipv4和ipv6区别
- 数据库
- COMMIT是指提交事务,即试图把事务内的所有SQL所做的修改永久保存
- 如果COMMIT语句执行失败了,整个事务也会失败
- 些时候,我们希望主动让事务失败,这时,可以用ROLLBACK回滚事务,整个事务会失败
- SQL优化
- 数据库架构
- 案例题
- 其他
- 配置开启binlog日志,日志的文件前缀为mysqlbin ——-> 生成的文件名如 : mysqlbin.000001,mysqlbin.000002
- 配置二进制日志的格式
- 该参数用来控制慢查询日志是否开启,可取值:1 和 0 ,1 代表开启,0 代表关闭
- 该参数用来指定慢查询日志的文件名
- 该选项用来配置查询的时间限制,超过这个时间将认为值慢查询,将需要进行日志记录,默认10s
- 查看磁盘空间
- 查看文件大小
- 统计当前目录下文件的个数(不包括目录)
- 统计当前目录下文件的个数(包括子目录)
- 查看某目录下文件夹(目录)的个数(包括子目录)
- 智力题
准备主要分为三大块
1.基础知识,有计算机网络(重点TCP/IP),操作系统(进程线程),数据库(主要是MySQL和redis相关),编程语言(我擅长的是python所以就对python的一些常考知识进行了复习)
2.刷题,每天晚上回来必刷一题,刚刚开始从简单的开始,熟悉了后就开始刷中等难度的题目, 最后一共刷了差不多150题
3.简历中项目,这个呢主要是看看网上别人问项目的时候会被问到哪些方面,然后针对性的拷问自己,并整理相关的问题,这样被问到就不至于不知所措
一面(2月21日):
1.操作系统方面的问题:进程和线程的区别,进程通信的方法,僵尸线程
2.计算机网络方面的问题:滑动窗口的原理;拥塞控制是和滑动窗口的区别;浏览网站输入url后网络侧的行为;SSL握手的过程
3.项目问题,为什么要做这个项目
5.手撕代码,最大连续数组的和,这个由于有点紧张没想出来这么解,最后使用暴力方法解出,然后面试官让优化,我说应该是用双指针但是具体不记得了,面试官人也很好,给我提供了大致思路,然后我就写出了,这里感觉表现很差,之前明明刷过,所以刷题还是要理解才行
二面(2月25日)
二面有点针对一面补充的意思,大家可以用排除法在二面之前针对性复习一遍(一面问过的就不用复习了)
1.操作系统方面:操作系统原子性的概念;页面置换算法
2.网络相关:http的header有哪些;http的特点;cookie和session的区别
3.数据库相关:mysql里面索引有哪些;主键索引和非主键索引是如何实现的
索引作用是什么?什么结构实现?
- 数据库怎么建索引,有哪些索引
4.测试实战:session可以设计失效时间吗,根据这个设计测试用例
6.手撕代码,最长不重复子串
三面(2月28日)
2.设计抖音发布视频的测试用例
3.如果不同安卓版本上的抖音,一个能发布视频,一个不能,可能是什么原因
测试基础
- 软件的分类
- 什么是接口测试
- 微信红包的测试用例
- 微信评论功能的测试用例
- 测试一下支付宝付款码,设计测试用例
- 黑盒测试的方法
- 白盒测试的方法
- 登录功能怎么设计测试用例?
- 网上银行转账是怎么测的,设计一下测试用例。
- 给你一个网站,你应该如何测试?
- 一个有广告的纸杯子,请设计测试用例?
- 想象一个登录框,包括ID、密码、登录、取消,记住密码(复选框),尽可能的写出你想到的测试点?
- 测试淘宝购物车的测试案例
- 设计一下抖音上下滑动视频的测试用例
- 设计抖音app用户登录测试
- 中断测试
- 测试在一个场景下,推荐滤镜
- 朋友圈点赞评论测试用例
- 测试过QPS吗?
- 项目前中后期的质量保障手段
- 项目资损的保障手段
- 说说xss和csrf的区别,原理,防范措施?
- 说说sql注入的原理,类型,防范措施?
- 玩过抖音吧,你觉得抖音可能存在哪些安全漏洞(缺陷),怎么去解决?
- csrf和ssrf区别,原理,防范措施?
- SQL注入有哪些,会测试哪些方面的SQL注入
- 高并发情况下响应延迟有实际操作过吗,怎么模拟高并发
- 正向代理和反向代理
常用git命令、git 分支如何创建与合并、git一次提交过程的流程
测试场景
网页崩溃的原因
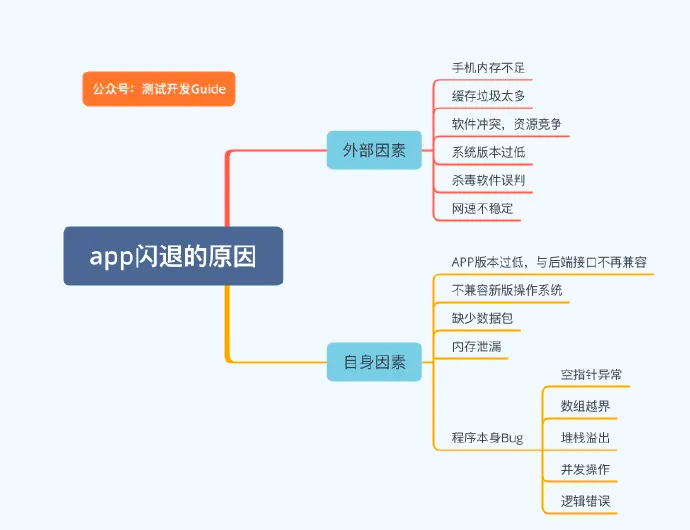
如果抖音一个地区的许多用户无法下载视频的原因
- 如果用户收到了银行短信提示已经扣款成功了,但是商家没有收到钱,你觉得会是什么问题
- 如何实现一个用户登录功能
- 高并发下减少事务带来的性能消耗?
- 如果一个API接口出现一个不稳定出现的bug,如何去确定?
- 访问页面加载缓慢的原因以及如何解决
- 如何你和你的领导意见不一致,你会怎么做
- 设计加入购物车和购物车页面的测试用例,安全测试加密什么
- 如果url加载不出来页面,怎么排查问题
- 如果图片上传失败,分析原因
- 针对评论功能,你如何设计接口,主要回答需要传递的参数有哪些?
- app页面白屏了什么原因
- 全链路压测中,找到了某一个服务器CPU负载率100%,磁盘和内存使用率正常,请问你会怎么去分析可能的原因
- 设计买火车票的系统,输入出发站和到达站,返回所有可能的结果
- 添加购物车请求后发生了什么
- 淘宝用户支付失败的原因
- 测试b站播放、B站弹幕的测试举例
- 如何针对微信聊天界面的抢红包功能设计测试用例?
- 怎么测试抖音平台带货界面
- 手机端访问一个站点出现白屏可能出现的原因,怎么定位是前端还是后端的问题
- 怎样保证数据库、数据库到ES、ES到前端 数据是正确的
- 网易云播放器与歌单(播放列表)的测试
- 抖音视频画面跟声音不同步,怎样排查问题
- 设计测试用例:扫码支付
- 线上大量用户反映抖音视频画面跟声音不同步,怎样排查
- 用例设计:抖音点赞功能的测试点
- 发朋友圈设计测试用例
- app崩溃了可能是哪些原因
- 测试一个人脸识别机器的功能、性能
- 设计微信发送消息测试用例
- 测试用例:微信余额提现
- 测试用例设计:满减红包
- 测试微信聊天框
- 对于二维码的功能测试
- 抖音下拉框的测试用例
- 视频播放器的测试用例
- 朋友圈评论的测试用例
- 如果头条突然崩溃了会是什么原因?这里的崩溃是指应用突然异常终止跳回到桌面了
- 抖音评论设计测试用例
- 发布评论如果页面没有显示会是什么问题
- 对于抖音的直播卡顿测试用例
- 怎么实现12306买票过程中输入两个城市,输出所有车次
- 怎么实现单点登录
- 怎么实现登录后保持登录状态
编程基础
面向对象
面向对象与面向过程
- 面向过程:是一种以过程为中心的编程思想,分析出解决问题的步骤,然后用函数把这些步骤一步一步实现。面向过程编程中数据和对数据的操作是分离的。
- 优点:性能比面向对象高,因为在类调用是需要实例化,开销比较大,比较消耗资源。
- 缺点:没有面向对象易维护、易复用、易扩展。
面向对象:是将事物对象化,通过对象通信来解决问题。面向对象编程中数据和对数据的操作是在一起
继承:子类继承父类非私有的属性和方法,子类可以添加自己的属性和方法,子类可以重新定义父类的方法。
- 注意:Java中是单继承,即一个子类只能继承一个父类;Java中object类是所有类的直接或间接父类;每一个子类被实现按时(new),父类会在它之前实现(被new)。
- 构造函数不能被继承,子类可以通过super()显式调用父类的构造函数;创建子类时,默认调用父类的无参构造函数;如果父类没有定义无参构造函数,子类必须在构造函数的第一行使用 super()显式调用(先父后子)。
- 优点:① 代码复用;② 父类的引用变量可以指向子类对象
- 封装:即隐藏对象的属性和实现方法,仅对外提供公共的访问方法。
- 为什么需要封装呢:封装符合面向对象设计的单一性原则,一个类把自己该做的事情封装起来,而不是暴露给其他类去处理,当内部的逻辑发生变化时,外部调用不用因此而修改,它们只调用开放的接口,而不用去关心内部的实现。
- 实现:将属性私有化;仅提供公开的方法(一个负责获取内容(get),一个负责修改内容(put))访问私有属性。
- 优点:提升了代码的安全性和隐私性;能减少耦合;类内部的结构可以自由修改
多态:一个对象在不同时刻体现出来的不同状态(一对多的关系)(父类引用子类对象)
- 实现:
- 重写:子类重写父类方法的实现,它是一种垂直层次关系。父类的引用变量不仅可以指向父类的实例对象,还可以指向子类的实例对象。当父类的引用指向子类的对象时,只有在运行时才能确定调用哪个方法。
- 重载:指一个类中,存在方法名相同,但参数(个数、顺序、类型)不同的方法,在编译时就可以确定到底调用哪个方法。它是一种水平层次关系。
- 特别注意:只有类中方法才有多态的概念,类中成员变量没有多态的概念
- 重写和重载的区别:重写是一种垂直关系,它是子类重写父类的方法,要求结构相同;而重载是一种水平关系,它是类内部书写多个相同名称的方法,它们通过形参列表来区分。
- 在形参声明过程中,一般会声明的范围比较大,就可以传递父类也可以传递子类,代码的通用性就比较强。
- 多态可以分为两种类型:编译时多态(方法的重载)和运行时多态(方法的重写)。
- 运行时多态依赖于继承、重写和向上转型,向上转型是自动的,Father f = new Children(),不需要强转;向下转型需要强转,即Children c =(Children) new Father()。
- Java中重写的两同两小一大规则:
- 实现:
接口实现
- 继承父类进行方法重写
- 同一个类中进行方法重载???
多态存在的必要条件:
- 要有继承
- 要有重写
- 父类引用指向子类对象,编译看左边,运行看右边
多态的好处:
- 可替换性(substitutability)
- 可扩充性(extensibility)
- 接口性(interface-ability)
- 灵活性(flexibility)
-
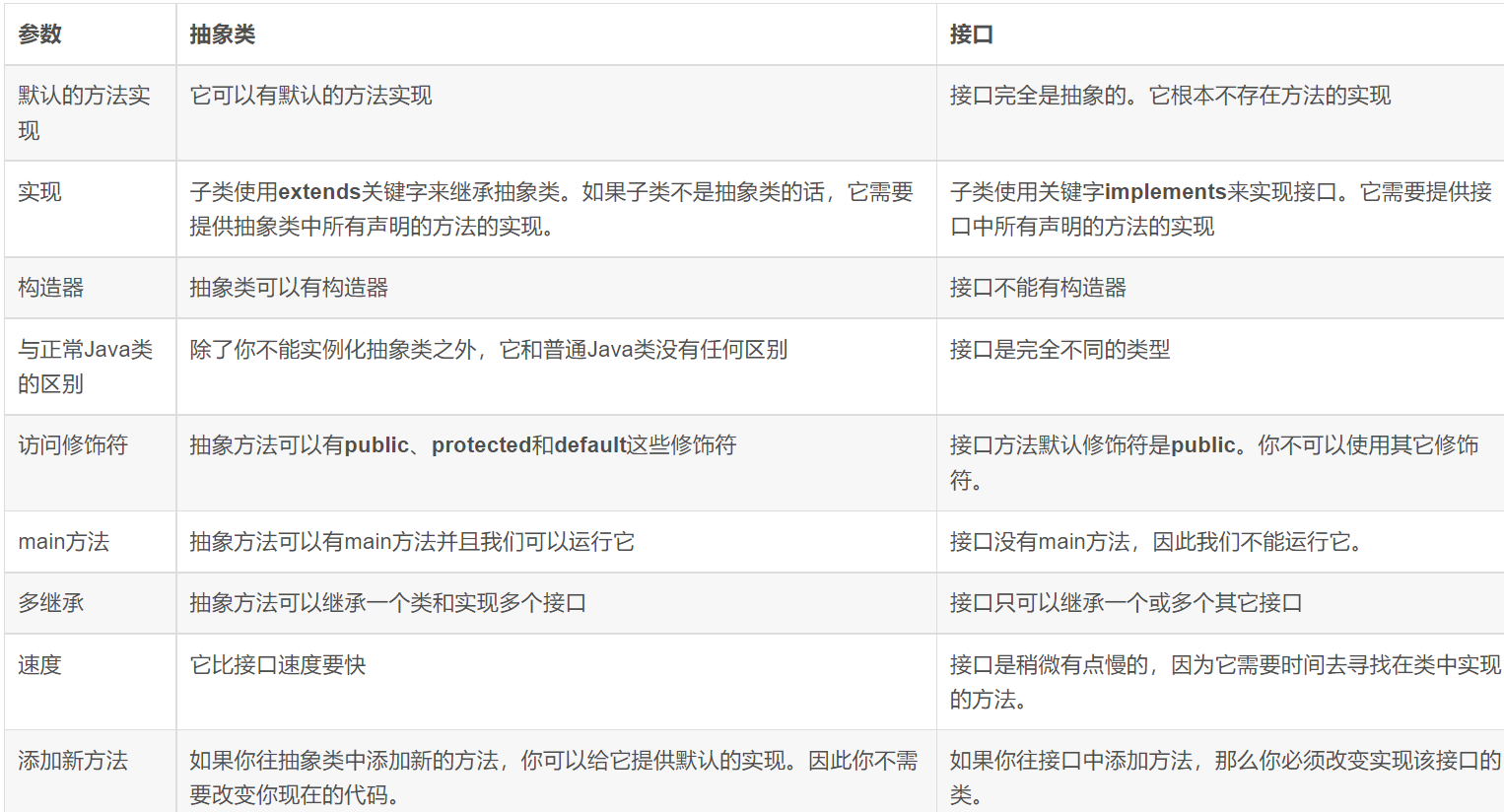
抽象类和接口的区别
抽象类可以提供成员方法的实现细节,而接口中只能存在public abstract (隐式声明)方法
- 抽象类中的成员变量可以是各种类型的,而接口中的成员变量只能是public static final(隐式声明)类型的(必须在声明时赋值)
- 抽象类可以有静态代码块和静态方法,接口中不能含有静态代码块以及静态方法
- 一个类只能继承一个抽象类,而一个类却可以实现多个接口
- 抽象类是对一种事务的抽象,是对整个类进行抽象,包括属性,行为(方法)。接口是对行为(行为)的抽象。如果一个类继承或实现了某个抽象类,那么一定是抽象类的种类(拥有同一种属性或行为的类)
- 设计层面不同,抽象类作为很多子类的父类,是一种模板设计,而接口是一种规范,它是一种辐射式设计,也就是说对于抽象类,如果需要添加新的方法,可以直接在抽象方法中添加实现,子类可以不用变更,而对于接口不行,如果接口进行了变更,那么实现它的类都需要做变更。
抽象类与抽象方法的区别
- 如果父类的方法本身不需要实现任何功能,仅仅是为了定义方法签名,目的是让子类去覆盖它,那么,可以把父类的方法声明为抽象方法
- 如果一个class定义了方法,但没有具体执行代码,这个方法就是抽象方法,抽象方法用abstract修饰。因为无法执行抽象方法,因此这个类也必须声明为抽象类(abstract class)
抽象类本身被设计成只能用于被继承,因此,抽象类可以强迫子类实现其定义的抽象方法,否则编译会报错。抽象方法实际上相当于定义了”规范”
类方法、实例方法、构造方法区别
类方法:有static修饰,也叫静态方法
- 当类的字节码文件被加载到内存时,类方法的入口地址就会完成分配,所以类方法不仅可以被该类的对象调用,也可以直接通过类名完成调用,类方法的入口地址只有程序退出时才消失。
- 类方法中不能引用实例变量,因为给类方法分配内存地址的时候,实例变量还未分配内存地址。
- 在类方法中不能使用super和this关键字,因为super和this分别是指向父类和本类的对象,在类方法中调用的时候,这些指代的对象可能还没有创建出来。
- 类方法中不能调用实例方法
实例方法:无static修饰,也叫非静态方法
- 当类的字节码文件被加载到内存时,类的实例方法并没有被分配入口地址,只有该类的对象被创建后,才会给实例方法分配入口地址,从而实例方法可以被类创建的所有对象调用 ,还有一点就是,当第一个类的对象被创建时,实例方法的入口地址会完成分配,后续创建对象时,不会再分配入口地址,即该类的所有对象共用实例方法的入口地址,当该类的所有对象都被销毁时,入口地址才会消失。
- 实例方法可以引用实例变量和类变量
- 实例方法可以使用super和this关键字
- 实例方法中可以调用类方法
构造方法:负责对象的初始化工作,并为实例变量赋予合适的初始值
- 作用:构造出一个类的实例;
- 构造方法在调用执行之后是有返回值的,但是不用写“return”语句,因为构造方法结束的时候java程序自动返回值,返回值类型是构造方法所在类的类型,由于构造方法的返回值类型就是类本身,所以返回值类型不需要编写。
- 当一个类你没有自定义构造方法的话,系统默认提供一个无参构造,这个构造方法称为缺省构造器。
- 如果手动定义了构造方法,那么系统将不再提供缺省构造器。
- 构造方法支持重载
- 实例变量的内存空间是在构造方法执行的过程中完成开辟的,同样的,实例变量的初始化也是在构造方法执行的过程中完成的。
- 书写要求:方法名与类名相同;不要写返回类型(如void、return等);不能被static、final、native、abstract和synchronized修饰,不能被子类继承。
- 调用无参构造方法会默认给当前类的实例变量初始化
静态变量和实例变量的区别
静态变量属于类的级别,而实例变量属于对象的级别
- 静态变量和实例变量的主要区别有两点:
- 存放位置不同:类变量随着类的加载存在于方法区中,实例变量随着对象的对象的建立存在于堆内存中
- 生命周期不同:类变量的生命周期最长,随着类的加载而加载,随着类的消失而消失,实例变量随着对象的消失而消失
静态的使用注意事项:
定义:表示“最终的”,可以用来修饰的结构:类、方法、变量
- final修饰类:此类不可以被继承。比如:String / StringBuffer类
- final修饰方法:此方法不能被重写。比如:Object类的getClass()
- final修饰变量:final标记的变量(成员变量或局部变量)即称为常量。名称大写,且只能被赋值一次。比如:Math类中的PI
- final修饰属性:final标记的成员变量必须在声明时或在每个构造器中或代码块中显式赋值,然后才能使用。可以考虑的赋值的位置:
- 显式初始化
- 代码块中初始化
- 构造器中
- 方法中不行
- final修饰局部变量
- final修饰方法体中的局部变量,此时为常量,不能再进行赋值操作
- final修饰形参时,当调用此方法时,给常量形参赋一个实参,一旦赋值以后,就只能在方法体内使用此形参,但不能进行重新赋值
-
访问权限控制符
| 访问权限控制符 | 本类 | 包内 | 包外⼦类 | 任何地⽅ | | —- | —- | —- | —- | —- | | public | √ | √ | √ | √ | | protected | √ | √ | √ | × | | ⽆ | √ | √ | × | × | | private | √ | × | × | × |
public:表示紧跟其后的成员可以被任何人引用
- private:表示紧跟其后的成员除了类型创建者和类型内部的方法,任何人都不可引用,否者程序编译报错
- protected:protected关键字与private效果相当,差别仅在于继承的类可以访问protected成员
默认访问权限(即定义属性时不加任何关键字修饰):默认访问权限通常被称为“包访问权限”,在这种权限下的成员变量可被同一个包中的其他类访问
static关键字作用
在java语言中有四种使用情况:成员变量、成员方法、代码块和内部类
- static成员变量:java中可以通过statin关键字修饰变量达到全局变量的效果。static修饰的变量(静态变量)属于类,在类第一次通过类加载器到jvm时被分配内存空间
- static成员方法:static修饰的方法属于类方法,不需要创建对象就可以调用。static方法中不能使用this和super等关键字,不能调用非static方法,只能访问所属类的静态成员变量和静态方法
- static 代码块:JVM在加载类时会执行static代码块,static代码块常用于初始化静态变量,static代码只会在类被加载时执行且执行一次
static内部类:static内部类可以不依赖外部类实例对象而被实例化,而内部类需要在外部类实例化后才能被实例化。静态内部类不能访问外部类的普通变量,只能访问外部类的静态成员变量和静态方法
反射
Java反射机制是在运行状态中,对于任意一个类,都能够知道这个类中的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性;这种动态获取的信息以及动态调用对象的方法的功能称为 java 语言的反射机制
- 实际上,我们创建的每一个类也都是对象,即类本身是java.lang.Class类的实例对象。这个实例对象称之为类对象,也就是Class对象
在运行时获得类的各种内容,进行反编译,对于Java这种先编译再运行的语言,能够让我们很方便的创建灵活的代码,这些代码可以在运行时装配,无需在组件之间进行源代码的链接,更加容易实现面向对象
获取类对象:Class class = Class.forName("pojo.Hero");获取构造器对象:Constructor con = clazz.getConstructor(形参.class);获取对象:Hero hero =con.newInstance(实参);
Java 反射机制的功能
在运行时判断任意一个对象所属的类
- 在运行时构造任意一个类的对象
- 在运行时判断任意一个类所具有的成员变量和方法
- 在运行时调用任意一个对象的方法
-
Java反射机制的应用场景
逆向代码 ,例如反编译
- 与注解相结合的框架,例如Retrofit
- 单纯的反射机制应用框架,例如EventBus
- 动态生成类框架 例如Gson
获取Class对象的三种方式
```java // 第一种方式 通过Class类的静态方法——forName()来实现 class1 = Class.forName(“com.tsp.reflection.Person”);
// 第二种方式 通过类的class属性 class1 = Person.class;
// 第三种方式 通过对象getClass方法 Person person = new Person(); Class<?> class1 = person.getClass();
<a name="FwwyZ"></a>## Java集合<br /><br />[https://www.yuque.com/fangniudexingxing-uymcu/wxedug/be3gwq#vfH27](https://www.yuque.com/fangniudexingxing-uymcu/wxedug/be3gwq#vfH27)<a name="VhdML"></a>### HashMap的理解在Java中HashMap是一个散列表,它存储的内容是键值对(key-value)映射。HashMap实现了Map接口,根据键的HashCode值存储数据,具有很快的访问速度,最多允许一条记录的键为null,不支持线程同步。HashMap 是无序的,即不会记录插入的顺序。HashMap继承于AbstractMap,实现了Map、Cloneable、java.io.Serializable 接口<a name="StTup"></a>### ArrayList和LinkedList的区别1. 数据结构不同1. ArrayList是Array(**动态数组**)的数据结构,LinkedList是Link(**双向链表**)的数据结构。2. 效率不同1. 当随机访问List(get和set操作)时,ArrayList比LinkedList的效率更高,因为LinkedList是线性的数据存储方式,所以需要移动指针从前往后依次查找,重新排序2. 当对数据进行增加和删除的操作(add和remove操作)时,LinkedList比ArrayList的效率更高,因为ArrayList是数组,所以在其中进行增删操作时,会对操作点之后所有数据的下标索引造成影响,需要进行数据的移动3. 自由性不同1. ArrayList自由性较低,因为它需要手动的设置固定大小的容量,但是它的使用比较方便,只需要创建,然后添加数据,通过调用下标进行使用;而LinkedList自由性较高,能够动态的随数据量的变化而变化,但是它不便于使用4. 主要控件开销不同1. ArrayList主要控件开销在于需要在lList列表预留一定空间;而LinkList主要控件开销在于需要存储节点信息以及节点指针<a name="DzZCa"></a>### HashMap和Hashtable区别1. Hashtable实现原理和HashMap相同,功能相同。底层都使用**哈希表结构**,查询速度快,很多情况下可以互用2. 不同于HashMap,Hashtable是线程安全的3. 与HashMap不同,Hashtable不允许使用null作为key和value4. 与HashMap一样,Hashtable也不能保证其中Key-Value对的顺序5. Hashtable判断两个key相等、两个value相等的标准,与HashMap一致1. HashMap判断两个key相等的标准是:两个key通过equals()方法返回true,hashCode值也相等2. HashMap判断两个value相等的标准是:两个value通过equals()方法返回true6. Map中的**key**:无序的、不可重复的,**使用Set存储所有的key**7. Map中的**value**:无序的、可重复的,**使用Collection存储所有的value**8. LinkedHashMap:LinkedHashMap是HashMap的子类,使用了一对**双向链表**来记录添加元素的顺序9. TreeSet底层使用**红黑树结构**存储数据<a name="vKlFE"></a>### 集合的线程安全<a name="c45lU"></a>#### ArrayList线程不安全1. 解决方案 - Vector2. 解决方案 - Collections。Collections 提供了方法 synchronizedList 保证 list 是同步线程安全的3. 解决方案 - CopyOnWriteArrayList(重点、常用、写时复制技术)<a name="ijr0E"></a>#### HashSet线程不安全1. 解决方案CopyOnWriteArraySet<a name="znhzI"></a>#### HashMap线程不安全1. 解决方案:ConcurrentHashMap2. ConcurrentHashMap 是 J.U.C 包里面提供的一个线程安全并且高效的 HashMap,所以 ConcurrentHashMap 在并发编程的场景中使用的频率比较高3. **用分段锁机制实现多个线程间的并发写操作**4. **ConcurrentHashMap不同于HashMap,它既不允许key值为null,也不允许value值为null**<a name="joDZH"></a>## Java数据类型<a name="zKY5Q"></a>### 数据存储的单位1. 位、字节、字 是计算机数据存储的单位。位是最小的存储单位,每一个位存储一个1位的二进制码,一个字节由8位组成。而字通常为16、32或64个位组成。2. 位(bit):是计算机中最基本的单位,位是最基本的概念,在计算机中,由于只有逻辑0和逻辑1的存在,即每一个逻辑0或者1便是一个位3. 字节(byte):计算机中处理数据的基本单位,是由八个位组成的一个单元,8个bit组成1个Byte4. 字(word):代表计算机处理指令或数据的二进制数位数,是计算机进行数据存储和数据处理的运算的单位,在常见的计算机编码格式下,一个字等于两个字节(十六位)(1word = 2Byte = 16bit)<a name="nRO1j"></a>### 基本数据类型<br /><a name="ywBDs"></a>### 包装类型<a name="s62hL"></a>#### 基本类型与包装类的区别1. 存储位置不同:1. 基本数据类型直接将值放在栈中2. 包装类型是把对象放在堆中,然后通过对象的引用来调用他们2. 初始值不同:1. int的初始值为0 、 boolean的初始值为false2. 包装类型的初始值为null3. 使用方式不同:1. 基本数据类型直接赋值使用就好2. 在集合如 coolectionMap中只能使用包装类型<a name="lLUJ3"></a>#### 数据类型转换自动类型转换:容量小的类型自动转换为容量大的数据类型 --> 总结:小容量转大容量<br />```java// 包装类型向字符串的转换String str = "11.1";Double d = new Float("11.1");String str1 = d.toString();// 字符串向包装类型的转换String str = "11.1";Double d = new Float("11.1");Double d = Double.parseDouble("11.1");Double d = Double.valueOf("11.1");// 基本类型向字符串的转换Integer a = 1;a.toString(); // 调用转字符串的方法String s =a + ""; // 加上""自动转换String类型String.valueOf(a); // 使用String的方法
float和int能直接比较吗
short x1 = 1 x1 = x1+1。以上这段代码有错误吗
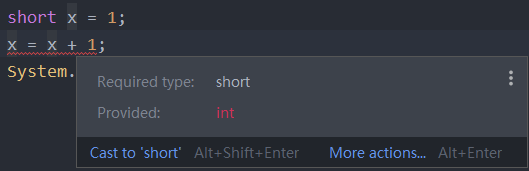
常见区别
equals与==的区别
- 最本质的区别:== 是像 +、-、* 这类的运算符,可直接使用,而equals是一种非静态的方法,需要对象调用
- == 既可以比较基本数据类型,也可以比较引用数据类型,比较基本数据类型比较的是值,比较引用数据类型比较的是地址值
equals只能比较引用数据类型,且Object类的equals默认情况下是比较的是地址值,无意义,子类一般会重写,改为比较:属性值
String、StringBuilder、StirngBuffer区别
String
- String是不可变的,即一旦一个String对象被创建以后,包含在这个对象中的字符序列是不可改变的,直至这个对象被销毁
- 再次给s赋值时,并不是对原来堆中实例对象进行重新赋值,而是生成一个新的实例对象。之前的实例对象仍然存在,如果没有被再次引用,则会被垃圾回收
- StringBuffer
- StringBuffer对象则代表一个字符序列可变的字符串,当一个StringBuffer被创建以后,通过StringBuffer提供的append()、insert()、reverse()、setCharAt()、setLength()等方法可以改变这个字符串对象的字符序列。一旦通过StringBuffer生成了最终想要的字符串,就可以调用它的toString()方法将其转换为一个String对象。
- StringBuffer对象是一个字符序列可变的字符串,它没有重新生成一个对象,而且在原来的对象中可以连接新的字符串
- StringBuilder
- StringBuilder类也代表可变字符串对象。实际上,StringBuilder和StringBuffer基本相似,两个类的构造器和方法也基本相同。不同的是:StringBuffer是线程安全的,而StringBuilder则没有实现线程安全功能,所以性能略高
- StringBuffer类中的方法都添加了synchronized关键字,也就是给这个方法添加了一个锁,用来保证线程安全
- String、StringBuffer、StringBuilder比较:
- 三者共同之处:都是final类,不允许被继承,主要是从性能和安全性上考虑的,因为这几个类都是经常被使用着,且考虑到防止其中的参数被参数修改影响到其他的应用
- StringBuffer是线程安全,可以不需要额外的同步用于多线程中
- StringBuilder是非同步,运行于多线程中就需要使用着单独同步处理,但是速度就比StringBuffer快多了
- StringBuffer与StringBuilder两者共同之处:可以通过append、indert进行字符串的操作
- 运行速度:执行速度由快到慢:StringBuilder > StringBuffer > String
使用总结:
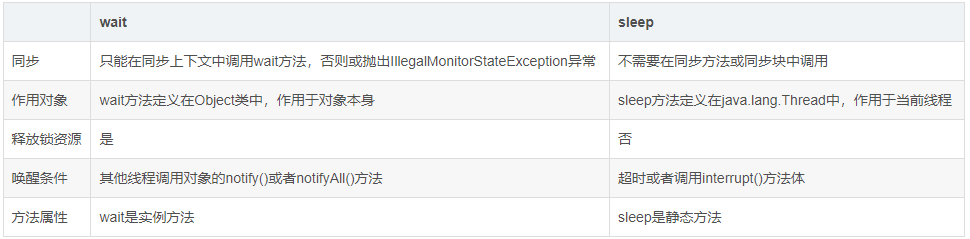
sleep是线程类(Thread)的方法,导致此线程暂停执行指定时间,将CPU放给线程调度器,但是监控状态依然保持,到时后会自动恢复。调用sleep不会释放对象锁。
- wait是Object类的方法,对此对象调用wait方法导致本线程放弃对象锁,进入等待此对象的等待锁定池,只有针对此对象发出notify方法(或notifyAll)后本线程才进入对象锁定池准备获得对象锁进入运行状态
- wait()与sleep()应用场景的区别:
- Sleep一般用于使当前线程进入阻塞状态并且继续持有锁,一般是让线程等待。
- wait一般用于多线程之间的通信,需要配合notify或者notifyall来进行使用,例如:生产者,消费者模式就需要使用wait,notify方法
final、finally、finalize区别
- final是java中的关键字,表示这部分是“不可修改的”。使用final可以修饰:变量、方法、类。表示变量不可变(常量),方法不可以被覆盖,类不可以被继承。
- final变量必须在声明的时候初始化或是在构造函数中初始化
- finally是java中异常处理结构的一部分,表示这段代码总会被执行
- 当try{}里面出现return语句时,后面的finally是否会被执行呢?答案是会,而且是先执行finally语句,再执行return语句。因为return表示整个方法体返回,所以finally一定在这之前就已经执行了
finalize()表示是object类一个方法,在垃圾回收机制中执行的时候会被调用被回收对象的方法。允许回收此前未回收的内存垃圾。所有object都继承了finalize()方法
深浅拷贝区别
浅拷贝:在拷贝一个对象时,对对象的基本数据类型的成员变量进行拷贝,但对引用类型的成员变量(类变量)只进行引用的传递,并没有创建一个新的对象,当对引用类型的内容修改会影响被拷贝的对象。
深拷贝:在拷贝一个对象时,除了对基本数据类型的成员变量进行拷贝,对引用类型的成员变量进行拷贝时,创建一个新的对象来保存引用类型的成员变量。
数据结构与算法
几种常用的数据结构及内部实现原理
链表:一个链表由很多节点组成,每个节点包含表示内容的数据域和指向下一个节点的链域两部分。正是通过链域将节点连接形成一个表。围绕链表的基本操作有添加节点、删除节点和查找节点等。
- 堆栈:限定了只能从线性表的一端进行数据的存取,这一端称为栈顶,另一端为栈底。入栈操作是先向栈顶方向移动一位,存入数据;出栈操作则是取出栈顶数据,然后向栈底移动一位。体现LIFO/FILO的思想。
- 队列:限定了数据只能从线性表的一端存入,从另一端取出。存入一端成为队尾,取出一端称为队首。体现LILO/FIFO的思想。
二叉树:树中的每个节点最多有两个子节点。这两个子节点分别称为左子节点和右子节点。在建立二叉搜索树时,要求一个节点的左子节点的关键字值小于这个节点而右子节点的关键字值大于或等于这个节点。常见的遍历操作有前序、中序和后序遍历
栈和队列的区别
队列先进先出,栈先进后出
- 队列和栈同属于Java合集框架,由Collcetion接口实现
- 队列(LinkedList类、ArrayDeque类)由Queue接口实现:LinkedList实现Deque接口,Deque继承Queue接口,Queue继承Collection接口
- 栈(Stack类)由List接口实现:Stack继承Vector类,Vector实现List接口,List继承Collection接口
- 栈是限定只能在表的一端进行插入和删除操作的线性表;队列是限定只能在表的一端进行插入并且在另一端进行删除操作的线性表
- 栈只能从头部取数据,也就是说最先放入的需要遍历整个栈后才能取出来,而且在遍历数据的时候还要为数据开辟临时空间,保持数据在遍历前后的一致性;队列基于地址指针进行遍历,而且可以从头或尾部开始遍历,无需开辟临时空间,速度要快的多
- 常见栈的应用场景包括括号问题的求解、表达式的转换和求值、函数调用和递归实现、深度优先搜索遍历等;
常见的队列的应用场景包括计算机系统中各种资源的管理、消息缓冲器的管理、广度优先搜索遍历等
堆和树有什么关系
堆是具有以下性质的完全二叉树:每个结点的值都大于或等于其左右孩子结点的值,称为大顶堆。每个结点的值都小于或等于其左右孩子结点的值,称为小顶堆
注意:没有要求结点的左孩子的值和右孩子的值的大小关系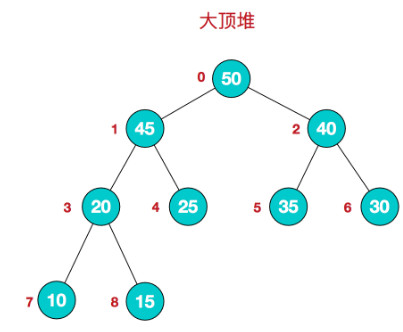
大顶堆特点:arr[i] >= arr[2i+1] && arr[i] >= arr[2i+2] // i 对应第几个节点,i从0开始编号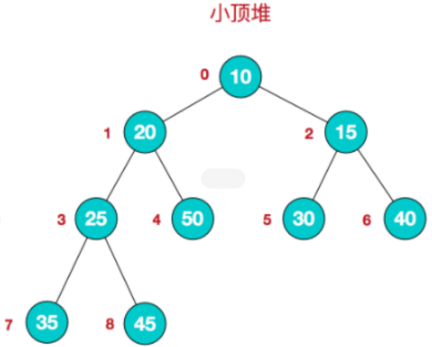
小顶堆:arr[i] <= arr[2i+1] && arr[i] <= arr[2i+2] // i 对应第几个节点,i从0开始编号深度遍历和广度遍历的本质区别是什么,用到的数据结构是什么样的
指代不同:
- 深度优先遍历:是对每一个可能的分支路径深入到不能再深入为止,而且每个节点只能访问一次。
- 广度优先遍历:系统地展开并检查图中的所有节点,以找寻结果。
- 特点不同:
- 深度优先遍历:所有的搜索算法从其最终的算法实现上来看,都可以划分成两个部分──控制结构和产生系统。正如前面所说的,搜索算法简而言之就是穷举所有可能情况并找到合适的答案,所以最基本的问题就是罗列出所有可能的情况,这其实就是一种产生式系统
- 广度优先遍历:并不考虑结果的可能位置,彻底地搜索整张图,直到找到结果为止
算法不同:
- 深度优先遍历:把根节点压入栈中。每次从栈中弹出一个元素,搜索所有在它下一级的元素,把这些元素压入栈中。并把这个元素记为它下一级元素的前驱。找到所要找的元素时结束程序。如果遍历整个树还没有找到,结束程序
- 广度优先遍历:把根节点放到队列的末尾。每次从队列的头部取出一个元素,查看这个元素所有的下一级元素,把它们放到队列的末尾。并把这个元素记为它下一级元素的前驱。找到所要找的元素时结束程序。如果遍历整个树还没有找到,结束程序
Java的异常处理机制
https://blog.csdn.net/quiet_1/article/details/124487540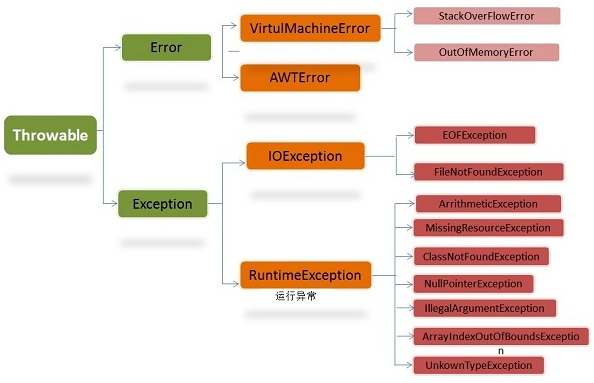
Error:Error及其子类用来描述Java运行系统中的内部错误以及资源耗尽的错误,是程序无法处理的错误,这类错误比较严重。这类的大多数错误与代码编写者执行的操作无关,如,运行代码时,JVM(Java虚拟机)出现的问题,例如,Java虚拟机运行错误(Virtual MachineError),当 JVM 不再有继续执行操作所需的内存资源时,将出现 OutOfMemoryError。这些异常发生时,Java虚拟机(JVM)一般会选择线程终止。 这些错误是不可查的,因为它们在应用程序的控制和处理能力之外,而且绝大多数是程序运行时不允许出现的状况。对于设计合理的应用程序来说,即使确实发生了错误,本质上也不应该试图去处理它所引起的异常状况。
- Exception:可以通过捕捉处理使程序继续执行,是程序自身可以处理的异常,也称为非致命性异常类。根据错误发生原因可分为RuntimeException异常和除RunTimeException之外的异常,如IOException异常。RuntimeException 类及其子类表示“JVM 常用操作”引发的错误。例如,若试图使用空值对象引用、除数为零或数组越界,则分别引发运行时异常 NullPointerException、ArithmeticException 和 ArrayIndexOutOfBoundException。
- 方法可以捕获到这个异常并进行处理。Java的异常处理是通过5个关键词来实现的:try、catch、throw、throws和finally。
一般情况下是用try来执行一段程序,如果出现异常,系统会抛出(throws)一个异常,这时候你可以通过它的类型来捕捉(catch)它,或最后(finally)由缺省处理器来处理。用try来指定一块预防所有”异常”的程序。紧跟在try程序后面,应包含一个catch子句来指定你想要捕捉的”异常”的类型。throw语句用来明确地抛出一个”异常”。throws用来标明一个成员函数可能抛出的各种”异常”。
Java中会常出现Error异常和Exception异常。Error和Exception都是Throwable的子类
- Error类一般是与虚拟机相关的问题,如系统崩溃,虚拟机错误,内存空间不足,方法调用栈溢等。对于这类错误的导致的应用程序中断,仅靠程序本身无法恢复和和预防,遇到这样的错误,建议让程序终止。
- Exception类表示程序可以处理的异常,可以捕获且可能恢复。遇到这类异常,应该尽可能处理异常,使程序恢复运行,而不应该随意终止异常。
- 异常处理机制是用来处理那些可能存在的异常,但是无法通过修改逻辑完全规避的场景。
如果通过修改逻辑可以规避的异常是bug,不应当用异常处理机制在运行期间解决!应当在编码时及时修正
Java异常可以分为可检测异常、非检测异常
可检测异常:可检测异常经编译器验证,它是编译器要求必须处理的异常,这类异常的发生在一定程度上是可以预计的,而且这类异常一旦发生,就必须采用某种方式进行处理。除了RuntimeException及其子类以外的其它异常类都属于可查异常。这种异常的特点是Java编译器会检查它,也就是说,出现这种异常,要么用try-catch语句捕捉它,要么用throws语句声明抛出它,否则编译不通过(不捕捉这个异常,编译器就通不过,不允许编译)
非检测异常:非检测异常不遵循处理或者声明规则。在产生此类异常时,编译器不要求强制处理的异常,包括运行时异常(RuntimeException与其子类)和错误(Error),编译器不会检查是否已经解决了这样一个异常
Exception异常
Exception 异常又可分为两大类:运行时异常和非运行时异常(编译异常)。程序中应当尽可能去处理这些异常
运行时异常:RuntimeException类及其子类异常,如NullPointerException(空指针异常)、IndexOutOfBoundsException(下标越界异常)等,这些异常是不可查异常,程序中可以选择捕获处理,也可以不处理。这些异常一般是由程序逻辑错误引起的,程序应该从逻辑角度尽可能避免这类异常的发生
- 运行时异常的特点:Java编译器不会检查它,也就是说,当程序中出现这类异常时,也会编译通过。
非运行时异常 (编译异常):是RuntimeException以外的异常,类型上都属于Exception类及其子类。从程序语法角度讲是必须进行处理的异常,如果不处理,程序就不能编译通过。如IOException、SQLException等以及用户自定义的Exception异常,一般情况下不自定义检查异常。
throw和throws关键字的区别
throw通常用在方法体中或者用来抛出用户自定义异常,并且抛出一个异常对象。程序在执行到throw语句时立即停止,如果要捕捉throw抛出的异常,则必须使用try-catch语句块或者try-catch-finally语句
- throws通常被用在声明方法时,用来指定方法可能抛出的异常,多个异常可使用逗号分隔。throws关键字将异常抛给上一级,如果不想处理该异常,可以继续向上抛出,但最终要有能够处理该异常的代码
- 子类抛出的异常必须是父类的异常的子类或者子集
- 如果父类或者接口没有异常抛出时,子类覆盖出现异常,只能try,不能使用throws抛出
异常中常用的方法
try {String str = "abc";System.out.println(Integer.parseInt(str));} catch (NumberFormatException e) {//异常最常用的方法,用于将当前错误信息输出到控制台e.printStackTrace();//获取错误消息.记录日志的时候或提示给用户可以使用它String message = e.getMessage();System.out.println(message);}try {Object obj = new Date();String str = (String) obj;System.out.println("1111111111"); // 出现异常后,不会执行该语句}catch (Exception e){e.printStackTrace();}System.out.println("2222222222"); // 出现异常后,仍会执行该语句
常见的异常以及举例
- NullPointerException(空指针异常) ```java // 在给新建对象的时候,因为某些原因导致对象不存在或者未被赋值的时候会抛出空指针异常 Boy boy = null; System.out.println(boy.getName());
// 空指针异常不仅会在调用对象的时候发生,还可能会发生在数组和字符串身上 int arr[] = null; System.out.println(arr[0]);
String str = “abc”; str = null; System.out.println(str.charAt(0));
// 因为在Java语言中,任何类型都可以赋值为null,所以Java语言中导致出现空指针异常的情况常常出现
2. **ArrayIndexOutOfBoundsException(数组索引越界异常)**```javaint arr[] = {1,2,3};System.out.println(arr[3]);// 访问没有对应索引的位置所导致的异常
- ClassCastException(类型转换异常) ```java Object obj = new Date(); String str = (String) obj;
Exception in thread “main” java.lang.ClassCastException: java.util.Date cannot be cast to java.lang.String
// 不能强行转换的时候容易引发的异常
4. **NumberFormatException(格式异常)**```javaString str = "abc";int num = Integer.parseInt(str);// 抛出以表示应用程序已尝试将字符串转换为其中一个数字类型,但该字符串不具有相应的格式
InputMismatchException(输入类型不匹配异常)
// 当输入不为int型数字的时候,容易导致InputMismatchExceptionScanner scanner = new Scanner(System.in);int i = scanner.nextInt();System.out.println(i);
ArithmeticException(算术异常)
// 数学上无除以0的说法int a = 10;int b = 0;System.out.println(a / b);
Java的垃圾回收机制
介绍JVM垃圾回收机制和垃圾收集器
- Java的jvm调优,jvm如何类加载
- 双亲委派机制
- 内存泄露和查找定位
- 怎么主动触发垃圾回收
- 堆区的垃圾回收是如何工作的
加密算法
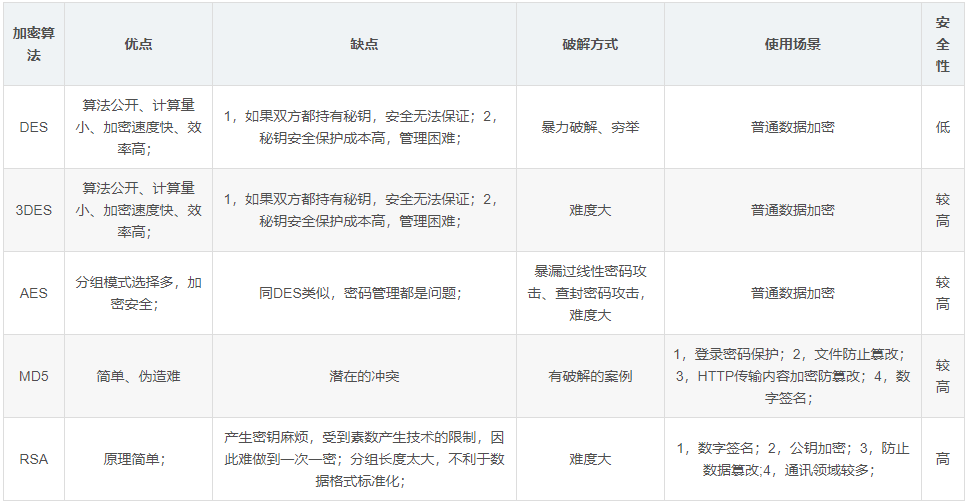
MD5加密算法
- MD5消息摘要算法(MD5 Message-Digest Algorithm),一种被广泛使用的密码散列函数(单向散列哈希算法),可以产生出一个128位(16字节)的散列值(hash value),用于确保信息传输完整一致。 不算是一种加密算法,应该叫做信息摘要算法
- MD5加密是一种不可逆的加密算法,不可逆加密算法的特征是加密过程中不需要使用密钥,输入明文后由系统直接经过加密算法处理成密文,这种加密后的数据是无法被解密的,只有重新输入明文,并再次经过同样不可逆的加密算法处理,得到相同的加密密文并被系统重新识别后,才能真正解密
适用场景
- 用户密码保护:在数据库记录密码时,并不记录密码本身,而是记录密码经过MD5加密后所产生的结果。当用户输入密码时,只需要把输入的密码再进行MD5校验,再与数据库中的结果进行对比就可以了。 这样的好处是,即便数据库被盗,也无法通过结果反推出密码是什么
- 文件传输完整性校验:当在网络中传输文件时,可能会导致文件数据丢失,或者被篡改,这个时候,在传输文件之前,往往先把文件经过MD5加密之后的结果传输过去,再传输文件,当文件传输过去后,再进行MD5加密,把两次的MD5结果进行对比,来判断文件是否完整,以及是否被篡改
- 数字签名:当发布程序时,可以同时发布该程序的MD5,这样在别人下载之后,只需要再经过MD5加密一遍,只需要判断自己下载程序的MD5与发布商的发布的MD5是否相同,从而可以判断程序是否被植入木马
- 云盘秒传:有的时候我们在云盘上上传一个很大文件,它几乎很快就传上去了,其实它并不是把文件传上去,它是先计算一下文件的MD5,并且在数据库中查找一个,看看有没有该MD5,如果有的话则直接使用该文件,从而实现文件妙传
非对称加密和对称的优缺点,各自的用途是什么
对称加密:双方使用的同一个密钥,既可以加密又可以解密,这种加密方法称为对称加密,也称为单密钥加密。
- 优点:速度快,对称性加密通常在消息发送方需要加密大量数据时使用,算法公开、计算量小、加密速度快、加密效率高。
- 缺点:在数据传送前,发送方和接收方必须商定好秘钥,然后 使双方都能保存好秘钥。其次如果一方的秘钥被泄露,那么加密信息也就不安全了。另外,每对用户每次使用对称加密算法时,都需要使用其他人不知道的唯一秘钥,这会使得收、发双方所拥有的钥匙数量巨大,密钥管理成为双方的负担。
- 在对称加密算法中常用的算法有: AES、DES、3DES、Blowfish、IDEA、RC4、RC5、RC6等。
- AES:密钥的长度可以为128、192和256位,也就是16个字节、24个字节和32个字节。
- DES:密钥的长度64位,8个字节。
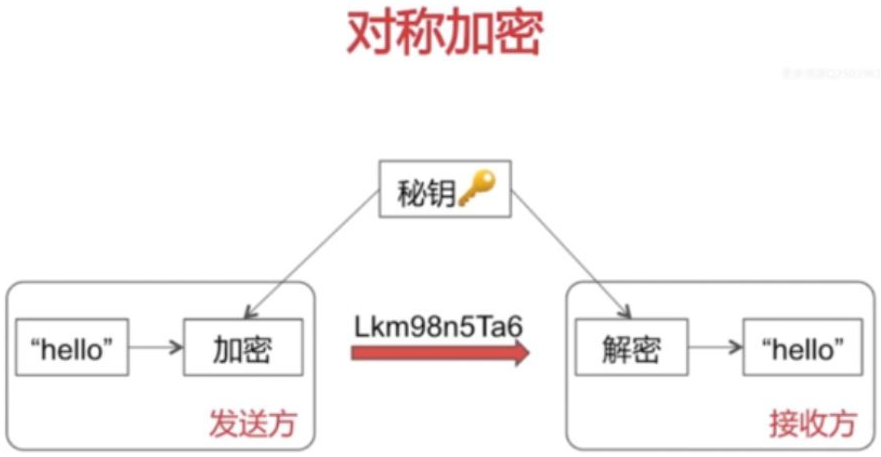
- 非对称加密:一对密钥由公钥和私钥组成(可以使用很多对密钥)。私钥解密公钥加密数据,公钥解密私钥加密数据(私钥公钥可以互相加密解密)。私钥只能由一方保管,不能外泄。公钥可以交给任何请求方。
- 优点:安全。
- 缺点:速度较慢。
- 在非对称加密算法中常用的算法有: RSA、DSA、ECC等。

对称加密和非对称加密的区别:对称加密算法相比非对称加密算法来说,加解密的效率要高得多。但是缺陷在于对于秘钥的管理上,以及在非安全信道中通讯时,密钥交换的安全性不能保障。所以在实际的网络环境中,会将两者混合使用。 例如针对C/S模型:
- 服务端计算出一对秘钥pub/pri。将私钥保密,将公钥公开。
- 客户端请求服务端时,拿到服务端的公钥pub。
- 客户端通过AES计算出一个对称加密的秘钥X。 然后使用pub将X进行加密。
- 客户端将加密后的密文发送给服务端。服务端通过pri解密获得X。
- 然后两边的通讯内容就通过对称密钥X以对称加密算法来加解密。
Java接口签名与验证实现
在一些项目中,客户端在调用服务的接口时,通常需要设置签名验证,以保证对客户端的认证。在签名过程中一般每个公司都有自己的签名规则和签名算法,广泛使用的是使用非对称加密算法RSA为核心,在客户端使用私钥对参数进行加密生成一个密钥,传给服务端,然后在服务端再对这个这个密钥使用公钥进行解密,解密出来的字符串参数与客户端传过来的参数进行对比,如果一样,验证成功。总结起来就是:
客户端:
- 首先获取所有的参数,然后对他们进行排序,生成一个字符串
- 对这个字符串MD5加密,然后转为大写
- 然后使用私钥对MD5再次加密,生成最终的签名sign
- 把这个签名sign传给服务端
- 服务端
- 获取所有的参数
- 把参数中签名sign参数去除,然后排序,生成一个字符串
- 对这个字符串MD5加密,然后转为大写
- 使用公钥对sign字符串进行解密获取一个String,然后和第三步中获取的字符串相对,如果相等,则验证成功
哈希冲突
- 哈希:
- 概念:hash音译为哈希,是把任意长度的输入通过散列算法变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间。
- 哈希算法其实是一个复杂的运算,它的输入可以是字符串,可以是数据,可以是任何文件,经过哈希运算后,变成一个固定长度的输出,该输出就是哈希值。但是哈希算法有一个很大的特点,就是你不能从结果推算出输入,所以又称为不可逆的算法。
- 哈希冲突:
- 就是键(key)经过hash函数得到的结果作为地址去存放当前的键值对,但是却发现该地址已经被占用,这个时候就会发生冲突。这个冲突就是hash冲突了
- 概括:如果两个不同对象的hashCode相同,这种现象称为哈希冲突。
- 哈希冲突解决办法:
- 开放地址法:开放定址法就是一旦发生了冲突,就去寻找下一个空的散列地址,只要散列表足够大,空的散列地址总能找到,并将记录存入
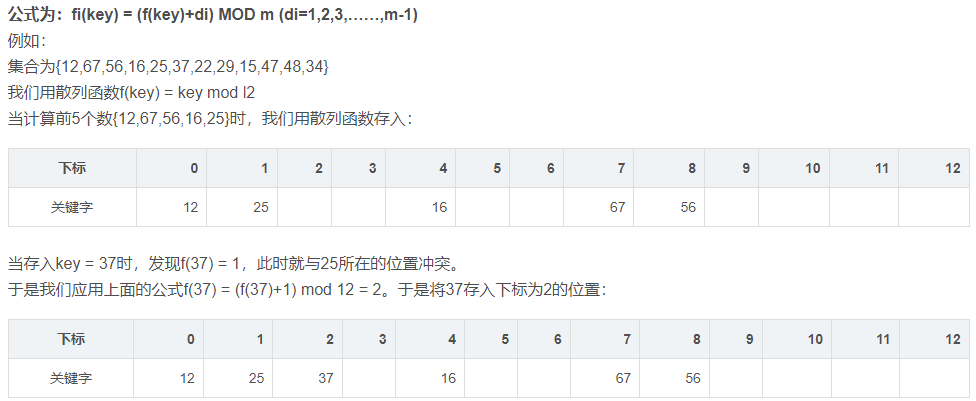
- 再哈希法:这种方法是同时构造多个不同的哈希函数:Hi=RH1(key) i=1,2,…,k。当哈希地址Hi=RH1(key)发生冲突时,再计算Hi=RH2(key)……直到冲突不再产生。这种方法不易产生聚集,但增加了计算时间。
- 链地址法:将所有哈希地址为i的元素构成一个称为同义词链的单链表,并将单链表的头指针存在哈希表的第i个单元中,因而查找、插入和删除主要在同义词链中进行。链地址法适用于经常进行插入和删除的情况。
- 建立公共溢出区:这种方法的基本思想是:将哈希表分为基本表和溢出表两部分,凡是和基本表发生冲突的元素,一律填入溢出表
中间件与框架
Redis
Redis为什么这么快
- 基于内存操作:Redis的所有数据都存在内存中,因此所有的运算都是内存级别的,所以它的性能比较高。
- 数据结构简单:Redis的数据结构比较简单,是为Redis专门设计的,而这些简单的数据结构的查找和操作的时间复杂度都是O(1)。
- 多路复用和非阻塞IO:Redis使用IO多路复用功能来监听多个socket连接的客户端,这样就可以使用一个线程来处理多个情况,从而减少线程切换带来的开销,同时也避免了IO阻塞操作,从而大大提高了Redis的性能。
- 避免上下文切换:因为是单线程模型,因此就避免了不必要的上下文切换和多线程竞争,这就省去了多线程切换带来的时间和性能上的开销,而且单线程不会导致死锁的问题发生。
官方使用的基准测试结果表明,单线程的Redis可以达到10W/S的吞吐量
Redis常见使用场景
缓存、数据共享分布式、分布式锁、全局 ID、计数器、限流、位统计、购物车、用户消息时间线 timeline、消息队列、抽奖、点赞、签到、打卡、商品标签、商品筛选、用户关注、推荐模型、排行榜
- 缓存:String类型,热点数据缓存、对象缓存、全页缓存,可以提升热点数据的访问数据
- 数据共享分布式:String类型,因为Redis是分布式的独立服务,可以在多个应用之间共享。例如:分布式Session
- 分布式锁:String类型setnx方法,只有不存在时才能添加成功,返回true
- 全局ID:int类型,incrby,利用原子性
- incrby userid 1000
- 分库分表的场景,一次性拿一段
- 计数器:int类型,incr方法,例如:文章的阅读量、微博点赞数、允许一定的延迟,先写入Redis再定时同步到数据库
- 限流:int类型,incr方法。以访问者的ip和其他信息作为key,访问一次增加一次计数,超过次数则返回false
- 位统计:
- 例如在线用户统计,留存用户统计
- 支持按位与、按位或等等操作
- 计算出7天都在线的用户
- 购物车:String或hash。所有String可以做的hash都可以做
- key:用户id;field:商品id;value:商品数量。
- +1:hincr。-1:hdecr。删除:hdel。全选:hgetall。商品数:hlen
- 用户消息时间线timeline:list,双向链表,直接作为timeline就好了。插入有序
- 消息队列:List提供了两个阻塞的弹出操作:blpop/brpop,可以设置超时时间
- blpop:blpop key1 timeout 移除并获取列表的第一个元素,如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。
- brpop:brpop key1 timeout 移除并获取列表的最后一个元素,如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。
- 上面的操作。其实就是java的阻塞队列
- 队列:先进先除:rpush blpop,左头右尾,右边进入队列,左边出队列
- 栈:先进后出:rpush brpop
- 抽奖:自带一个随机获得值。spop myset
- 点赞、签到、打卡
- 假如微博ID是t1001,用户ID是u3001
- 用like:t1001来维护 t1001 这条微博的所有点赞用户
- 点赞了这条微博:sadd like:t1001 u3001
- 取消点赞:srem like:t1001 u3001
- 是否点赞:sismember like:t1001 u3001
- 点赞的所有用户:smembers like:t1001
- 点赞数:scard like:t1001
- 商品标签:用tags:i5001来维护商品所有的标签
- sadd tags:i5001 画面清晰细腻
- sadd tags:i5001 真彩清晰显示屏
- sadd tags:i5001 流程至极
- 商品筛选: ``` // 获取差集 sdiff set1 set2
// 获取交集(intersection ) sinter set1 set2
// 获取并集 sunion set1 set2
15. **用户关注、推荐模型**follow 关注 fans 粉丝1. 相互关注:1. sadd 1:follow 22. sadd 2:fans 13. sadd 1:fans 24. sadd 2:follow 12. 我关注的人也关注了他(取交集):3. s inter 1:follow 2:fans4. 可能认识的人:1. 用户1可能认识的人(差集):sdiff 2:follow 1:follow2. 用户2可能认识的人:sdiff 1:follow 2:follow16. **排行榜**1. id为6001的新闻点击数加:zincrby hotNews:20190926 1 n60012. 获取今天点击最多的15条:zrevrange hotNews:20190926 0 15 withscores<a name="CO5wD"></a>### 缓存一致性解决**1、双写模式**<br /><br />**2、失效模式**<br /><br />**3、改进方法1-分布式读写锁**<br /><br />**4、改进方法2-使用 cananl**<br /><a name="DXx9K"></a>### Redis实现限流**第一种:基于Redis的setnx的操作**<br />在CAS(Compare and swap)的操作的时候,同时给指定的key设置了过期实践(expire),我们在限流的主要目的就是为了在单位时间内,有且仅有N数量的请求能够访问我的代码程序。所以依靠setnx可以很轻松的做到这方面的功能。<br />比如我们需要在10秒内限定20个请求,那么我们在setnx的时候可以设置过期时间10,当请求的setnx数量达到20时候即达到了限流效果。<br />当然这种做法的弊端是很多的,比如当统计1-10秒的时候,无法统计2-11秒之内,如果需要统计N秒内的M个请求,那么我们的Redis中需要保持N个key等等问题。<br />**第二种:基于Redis的数据结构zset**<br />其实限流涉及的最主要的就是滑动窗口,上面也提到1-10怎么变成2-11。其实也就是起始值和末端值都各+1即可。而我们如果用Redis的list数据结构可以轻而易举的实现该功能<br />zset是set的一个升级版本,他在set的基础上增加了一个顺序属性,这一属性在添加修改元素的时候可以指定,每次指定后,zset会自动重新按新的值调整顺序。 可以对指定键的值进行排序权重的设定,它应用排名模块比较多。<br />我们可以将请求打造成一个zset数组,当每一次请求进来的时候,value保持唯一,可以用UUID生成,而score可以用当前时间戳表示,因为score我们可以用来计算当前时间戳之内有多少的请求数量。而zset数据结构也提供了range方法让我们可以很轻易的获取到2个时间戳内有多少请求```javapublic Response limitFlow(){Long currentTime = new Date().getTime();System.out.println(currentTime);if(redisTemplate.hasKey("limit")) {// intervalTime是限流的时间// rangeByScore(K key, double min, double max)表示获取指定score区间的值,返回值为setInteger count = redisTemplate.opsForZSet().rangeByScore("limit", currentTime-intervalTime, currentTime).size();System.out.println(count);if (count != null && count > 5) {return Response.ok("每分钟最多只能访问5次");}}// 向指定key中添加元素,按照score值由小到大进行排列,UUID.randomUUID().toString()表示value,currentTime表示分数redisTemplate.opsForZSet().add("limit", UUID.randomUUID().toString(), currentTime);return Response.ok("访问成功");}ZSetOperations.TypedTuple<String> objectTypedTuple1 = new DefaultTypedTuple<>("eee",9.6);ZSetOperations.TypedTuple<String> objectTypedTuple2 = new DefaultTypedTuple<>("fff",1.5);ZSetOperations.TypedTuple<String> objectTypedTuple3 = new DefaultTypedTuple<>("ggg",7.4);Set<ZSetOperations.TypedTuple<String>> typles = new HashSet<>();typles.add(objectTypedTuple1);typles.add(objectTypedTuple2);typles.add(objectTypedTuple3);redisTemplate.opsForZSet().add("zSet", typles);
通过上述代码可以做到滑动窗口的效果,并且能保证每N秒内至多M个请求,缺点就是zset的数据结构会越来越大。实现方式相对也是比较简单的。
第三种:基于Redis的令牌桶算法
令牌桶算法提及到输入速率和输出速率,当输出速率大于输入速率,那么就是超出流量限制了。也就是说我们每访问一次请求的时候,可以从Redis中获取一个令牌,如果拿到令牌了,那就说明没超出限制,而如果拿不到,则结果相反。
依靠上述的思想,我们可以结合Redis的List数据结构很轻易的做到这样的代码,只是简单实现依靠List的leftPop来获取令牌
// 输出令牌public Response limitFlow2(Long id){Object result = redisTemplate.opsForList().leftPop("limit_list");if(result == null){return Response.ok("当前令牌桶中无令牌");}return Response.ok(articleDescription2);}
再依靠Java的定时任务,定时往List中rightPush令牌,当然令牌也需要唯一性,所以我这里还是用UUID进行了生成
// 每10S的速率往令牌桶中添加UUID,只为保证唯一性@Scheduled(fixedDelay = 10,initialDelay = 0)public void setIntervalTimeTask(){redisTemplate.opsForList().rightPush("limit_list",UUID.randomUUID().toString());}
综上,代码实现起始都不是很难,针对这些限流方式我们可以在AOP或者filter中加入以上代码,用来做到接口的限流,最终保护你的网站
分布式锁的实现逻辑
分布式锁的定义:保证同一时间只能有一个客户端对共享资源进行操作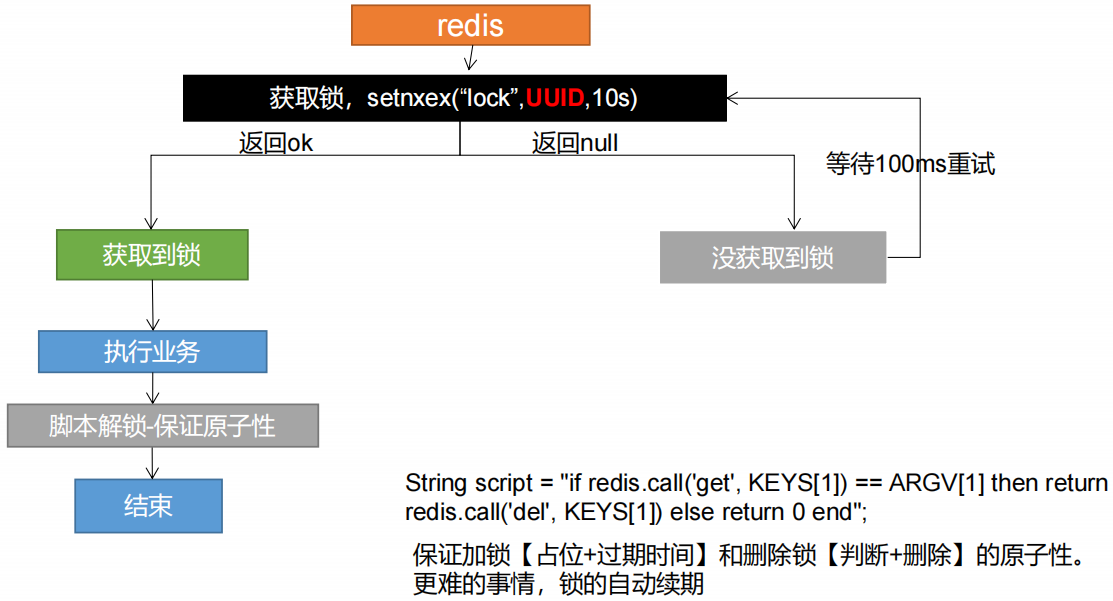
Redis提供了Lua脚本的支持,Lua脚本是一种轻量小巧的脚本语言,它支持原子性操作,Redis会将整个Lua脚本作为一个整体执行,中间不会被其他请求插入,因此Redis执行Lua脚本是一个原子操作。
把get key value、判断value是否属于当前线程、删除锁这三步写到Lua脚本中,使它们变成一个整体交个Redis执行。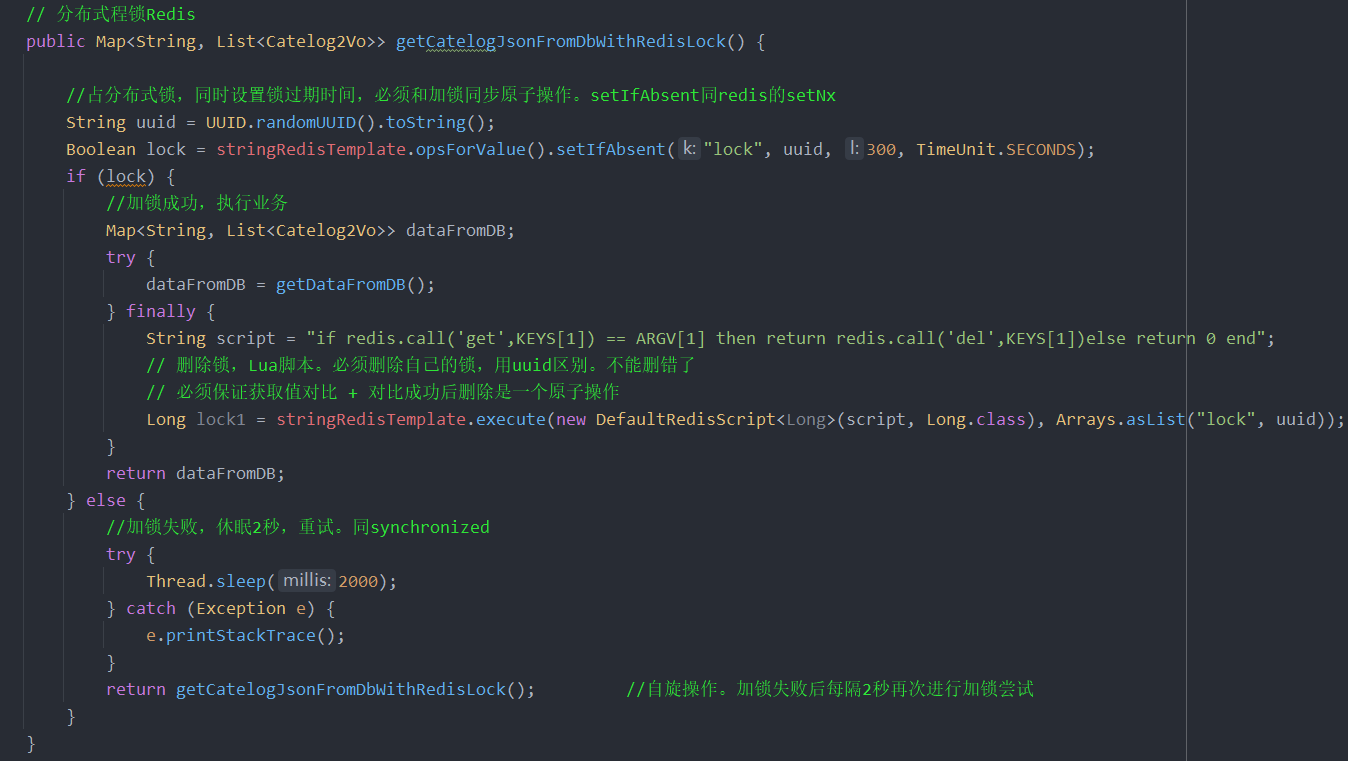
缓存失效问题
1、缓存穿透
缓存穿透是指查询一个一定不存在的数据,由于缓存是不命中,将去查询数据库,但是数据库也无此记录,我们没有将这次查询的null写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义。
在流量大时,可能DB就挂掉了,要是有人利用不存在的key频繁攻击我们的应用,这就是漏洞。l
解决:
缓存空结果、并且设置短的过期时间。布隆过滤器、mvc拦截器
2、缓存雪崩
缓存雪崩是指在我们设置缓存时采用了相同的过期时间,导致缓存在某一时刻同时失效,请求全部转发到DB,DB 瞬时压力过重雪崩。
解决:
- 规避雪崩:缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。
- 如果缓存数据库是分布式部署,将热点数据均匀分布在不同缓存数据库中。
- 设置热点数据永远不过期。
- 出现雪崩:降级 熔断
- 事前:尽量保证整个redis 集群的高可用性,发现机器宕机尽快补上。选择合适的内存淘汰策略。
- 事中:本地ehcache缓存 + hystrix限流&降级,避免MySQL崩掉
-
3、缓存击穿
对于一些设置了过期时间的key,如果这些key可能会在某些时间点被超高并发地访问,是一种非常“热点”的数据。
这个时候,需要考虑一个问题:如果这个key在大量请求同时进来前正好失效,那么所有对这个key 的数据查询都落到 db,我们称为缓存击穿
解决: 设置热点数据永远不过期。
- 加互斥锁:业界比较常用的做法,是使用mutex。简单地来说,就是在缓存失效的时候(判断拿出来的值为空),不是立即去load db去数据库加载,而是先使用缓存工具的某些带成功操作返回值的操作(比如Redis的SETNX或者Memcache的ADD)去set一个mutex key,当操作返回成功时,再进行load db的操作并回设缓存;否则,就重试整个get缓存的方法。
Redis是单线程的吗?
- Redis4.0之前是单线程运行的;Redis4.0后开始支持多线程
- Redis4.0之前使用单线程的原因:
- 单线程模式方便开发和调试
- Redis内部使用了基于epoll的多路复用
- Redis主要的性能瓶颈是内存或网络带宽
- 不同版本的Redis是不同的,在Redis4.0之前,Redis是单线程运行的,但单线程并不代表效率低,像Nginx、Nodejs也是单线程程序,但是它们的效率并不低
- 原因是Redis是基于内存的,它的瓶颈在于机器的内存、网络带宽,而不是CPU,在CPU还没达到瓶颈时机器内存可能就满了、或者带宽达到瓶颈了。因此CPU不是主要原因,那么自然就采用单线程了,况且使用多线程比较麻烦。
- Redis在4.0之前使用单线程的模式是因为以下三个原因:
- 使用单线程模式的Redis,其开发和维护更简单,因为单线程模式方便开发和调试。
- 即使使用单线程模型也能够并发地处理多客户端的请求,主要是因为Redis内部使用了基于epoll的多路复用。
- 对于Redis来说,主要的性能瓶颈是内存或网络带宽,而非CPU。
Redis6.0中的多线程
- Redis单线程的优点非常,不但降低了Redis内部实现的负责性,也让所有操作都可以在无锁的情况下进行,并且不存在死锁和线程切换带来的性能以及时间上的消耗;但是其缺点也很明显,单线程机制导致Redis的QPS(Query Per Second,每秒查询数)很难得到有效的提高(虽然够快了,但人毕竟还是要有更高的追求的)。
- Redis在4.0版本中虽然引入了多线程,但是此版本的多线程只能用于大数据量的异步删除,对于非删除操作的意义并不是很大。
- 如果我们使用Redis多线程就可以分摊Redis同步读写IO的压力,以及充分利用多核CPU资源,并且可以有效的提升Redis的QPS。在Redis中虽然使用了IO多路复用,并且是基于非阻塞的IO进行操作的,但是IO的读写本身是阻塞的。比如当socket中有数据时,Redis会先将数据从内核态空间拷贝到用户态空间,然后再进行相关操作,而这个拷贝过程是阻塞的,并且当数据量越大时拷贝所需要的的时间就越多,而这些操作都是基于单线程完成的。
- 因此在Redis6.0中新增了多线程的功能来提高IO的读写性能,它的主要实现思路是将主线程的IO读写任务拆分给一组独立的线程去执行,这样就可以使用多个socket的读写并行化了,但Redis的命令依旧是主线程串行执行的。
- 但是注意:Redis6.0是默认禁用多线程的,但可以通过配置文件redis.conf中的io-threads-do-reads 等于 true 来开启。但是还不够,除此之外我们还需要设置线程的数量才能正确地开启多线程的功能,同样是修改Redis的配置,例如设置 io-threads 4,表示开启4个线程。
Redis集群
主从复制
- 主从复制架构仅仅用来解决数据的冗余备份,从节点仅仅用来同步数据
- 无法解决:1. master节点出现故障的自动故障转移
- 哨兵机制
- Sentinel(哨兵)是Redis 的高可用性解决方案:由一个或多个Sentinel 实例 组成的Sentinel 系统可以监视任意多个主服务器,以及这些主服务器属下的所有从服务器,并在被监视的主服务器进入下线状态时,自动将下线主服务器属下的某个从服务器升级为新的主服务器。简单的说哨兵就是带有自动故障转移功能的主从架构。
- 无法解决: 1.单节点并发压力问题 2.单节点内存和磁盘物理上限
- 集群模式
MQ
MQ作用
- 异步处理
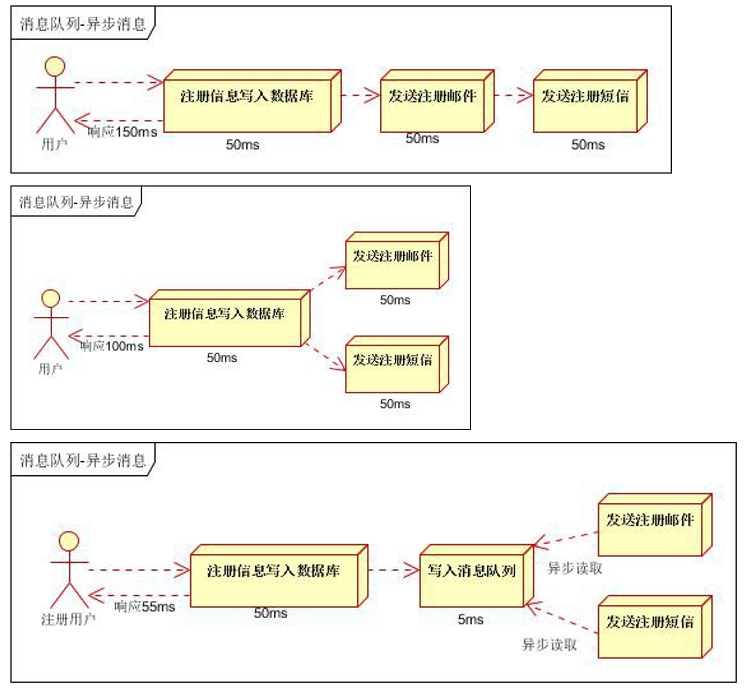
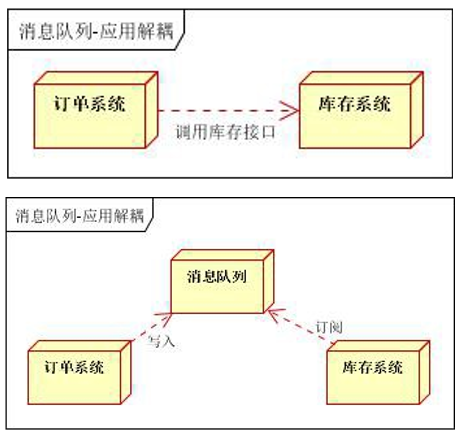
- 应用解耦
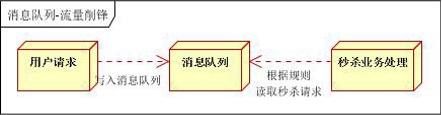
- 流量控制
Spring
Spring 有两个核心部分: IOC 和 Aop
- IOC:控制反转, 把创建对象过程交给 Spring 进行管理
- Aop:面向切面,不修改源代码进行功能增强
IOC 容器
IOC底层原理:IOC容器底层就是对象工厂
第一步:xml 解析
第二步:工厂模式
第三步:反射 ```java
//1、加载spring配置文件,此时不会创建对象
BeanFactory context = new ClassPathXmlApplicationContext(“bean1.xml”);
```java
//1、加载spring配置文件,此时不会创建对象
BeanFactory context = new ClassPathXmlApplicationContext(“bean1.xml”);
//2、获取配置时,才创建的对象 User user = context.getBean(“user”, User.class); System.out.println(user);
1. **反转(转移)控制(IOC Inverse of Control)**1. 控制:对于成员变量赋值的控制权2. 反转控制:把对于成员变量赋值的控制权,从代码中反转(转移)到Spring工厂和配置文件中完成3. 好处:解耦合4. 底层实现:**工厂设计模式**2. **依赖注入 (Dependency Injection DI)**1. 注入:通过Spring的工厂及配置文件,为对象(bean,组件)的成员变量赋值2. 依赖注入:当一个类需要另一个类时,就意味着依赖,一旦出现依赖,就可以把另一个类作为本类的成员变量,最终通过Spring配置文件进行注入(赋值)。3. 好处:解耦合<a name="UWUtn"></a>### bean生命周期1. 通过构造器创建 bean 实例(无参数构造)2. 为bean的属性设置值和对其他bean引用(调用set方法)3. 把bean实例传递bean后置处理器的方法postProcessBeforeInitialization4. 调用bean的初始化的方法(需要进行配置初始化的方法)5. 把bean实例传递bean后置处理器的方法postProcessAfterInitialization6. bean 可以使用了(对象获取到了)7. 当容器关闭时候,调用 bean 的销毁的方法(需要进行配置销毁的方法)<a name="CHtQu"></a>### AOP面向切面编程1. AOP面向切面编程 = Spring动态代理开发1. 以切面为基本单位的程序开发,通过切面间的彼此协同,相互调用,完成程序的构建2. 切面 = 切入点 + 额外功能2. OOP面向对象编程 Java1. 以对象为基本单位的程序开发,通过对象间的彼此协同,相互调用,完成程序的构建3. POP面向过程(方法、函数)编程 C1. 以过程为基本单位的程序开发,通过过程间的彼此协同,相互调用,完成程序的构建4. AOP的概念:1. 本质就是Spring的动态代理开发,通过代理类为原始类增加额外功能2. AOP本质是**动态对方法增强,避免代码入侵,优雅的实现横向扩展**,是对OOP的补充3. 好处:利于原始类的维护5. AOP编程的开发步骤1. 原始对象2. 额外功能 (MethodInterceptor)3. 切入点4. 组装切面 (额外功能+切入点)6. AOP应用场景1. 场景一:记录日志2. 场景二:监控方法运行时间(监控性能)3. 场景三:权限控制4. 场景四:缓存优化1. 第一次调用查询数据库,将查询结果放入内存对象2. 第二次调用, 直接从内存对象返回,不需要查询数据库5. 场景五:事务管理。调用方法前开启事务,调用方法后提交关闭事务<a name="ZL3Gc"></a>### Filter、Interceptor、AOP<a name="Eccjs"></a>#### Filter过滤器1. 过滤器拦截web访问url地址。 严格意义上讲,filter只是适用于web中,依赖于Servlet容器,利用Java的回调机制进行实现。Filter需要在web.xml中配置,依赖于Servlet2. 过滤器可以拦截到方法的请求和响应(ServletRequest request, ServletResponseresponse),并对请求响应做出像响应的过滤操作, 比如设置字符编码,鉴权操作等<a name="M2MDr"></a>#### Interceptor拦截器1. 拦截器拦截以 .action结尾的url,拦截Action的访问。Interfactor是基于Java的反射机制(AOP思想)进行实现,不依赖Servlet容器2. 拦截器可以在方法执行之前(preHandle)和方法执行之后(afterCompletion)进行操作,回调操作(postHandle),可以获取执行的方法的名称,请求(HttpServletRequest)3. Interceptor:可以控制请求的控制器和方法,但控制不了请求方法里的参数(只能获取参数的名称,不能获取到参数的值)4. 用于处理页面提交的请求响应并进行处理,例如做国际化,做主题更换,过滤等<a name="DlGg0"></a>#### 请求处理顺序过滤器 -> 拦截器 -> 切面<a name="lChjz"></a>#### 报错处理顺序切面 -> controllerAdvice -> 拦截器 -> 过滤器 -> 服务<a name="DbJ7L"></a>#### AOP拦截器1. 只能拦截Spring管理Bean的访问(业务层Service)2. 实际开发中,AOP常和事务结合:Spring的事务管理:声明式事务管理(切面)3. AOP操作可以对操作进行横向的拦截,最大的优势在于他可以获取执行方法的参数( ProceedingJoinPoint.getArgs()4. 常见使用日志,事务,请求参数安全验证等<a name="aNoLc"></a>#### Filter与Interceptor联系与区别1. 拦截器是基于java的反射机制,使用代理模式,而过滤器是基于函数回调。2. 拦截器不依赖servlet容器,过滤器依赖于servlet容器。3. 拦截器只能对action起作用,而过滤器可以对几乎所有的请求起作用(可以保护资源)。4. 拦截器可以访问action上下文,堆栈里面的对象,而过滤器不可以。5. 执行顺序:过滤前-拦截前-Action处理-拦截后-过滤后<a name="ObAlI"></a>#### 三者使用场景1. 三者功能类似,但各有优势,从过滤器–》拦截器–》切面,拦截规则越来越细致,执行顺序依次是过滤器、拦截器、切面。2. 一般情况下数据被过滤的时机越早对服务的性能影响越小,因此我们在编写相对比较公用的代码时,优先考虑过滤器,然后是拦截器,最后是aop。3. 比如权限校验,一般情况下,所有的请求都需要做登陆校验,此时就应该使用过滤器在最顶层做校验4. 日志记录,一般日志只会针对部分逻辑做日志记录,而且牵扯到业务逻辑完成前后的日志记录,因此使用过滤器不能细致地划分模块,此时应该考虑拦截器,然而拦截器也是依据URL做规则匹配,因此相对来说不够细致,因此我们会考虑到使用AOP实现,AOP可以针对代码的方法级别做拦截,很适合日志功能。<a name="Qsywl"></a>### Spring事务<a name="GaI68"></a>#### 事务几种实现方式1. 编程式事务管理:transactionTemplate,自动的事务管理,无需手动开启、提交、回滚2. 基于TransactionProxyFactoryBean的声明式事务管理3. 基于@Transactional的声明式事务管理4. 基于Aspectj AOP开启事务<a name="lBL6b"></a>#### Spring事务失效的各种场景[https://www.jb51.net/article/256104.htm](https://www.jb51.net/article/256104.htm)<a name="TzfBL"></a>### 简述SpringBootSpringBoot是一个脚手架,构建与Spring框架基础之上,基于快速构建理念,提供了自动配置功能,可实现开箱即用,起步依赖,自动配置,健康检查等<a name="QIxab"></a>### Spring和SpringBoot区别<a name="AQqB6"></a>### SpringBoot的been为什么默认单例1. Spring提供了5种scope分别是singleton、prototype、request、session、global session2. 单例bean的优势:由于不会每次都新创建新对象所以有一下几个性能上的优势1. **减少了新生成实例的消耗:**新生成实例消耗包括两方面,第一,spring会通过反射或者cglib来生成bean实例这都是耗性能的操作,其次给对象分配内存也会涉及复杂算法。2. **减少jvm垃圾回收:**由于不会给每个请求都新生成bean实例,所以自然回收的对象少了。3. **可以快速获取到bean:**因为单例的获取bean操作除了第一次生成之外其余的都是从缓存里获取的所以很快3. 单例bean的劣势:单例的bean一个很大的劣势就是他不能做到线程安全!由于所有请求都共享一个bean实例,所以这个bean要是有状态的一个bean的话可能在并发场景下出现问题,而原型的bean则不会有这样问题(但也有例外,比如他被单例bean依赖),因为给每个请求都新创建实例<a name="Oh6LH"></a>## K8S<a name="jtePY"></a>## docker<a name="ZFvem"></a># 操作系统<a name="W0Gp5"></a>## 线程<a name="JEScu"></a>### 线程、进程、协程区别1. **进程是资源分配的最小单位**。进程是程序执行的基本单位,进程是程序执行一次的过程,也就是说,一个程序就代表了进程从创建到运行再到消亡的整个过程2. **线程是CPU调度的最小单位**。线程是包含于进程的,一个进程可以对应多个进程,但是一个线程只能对应一个进程,与进程不同的是同类的线程共享进程中的堆和方法区,但是他们有着属于自己的本地方法栈、虚拟机栈、程序计数器3. 多进程、多线程区别:1. 共同点 :表示可以同时执行多个任务,进程和线程的调度是由操作系统自动完成2. 区别:进程:每个进程都有自己独立的内存空间,不同进程之间的内存空间不共享。进程之间的通信有操作系统传递,导致通讯效率低,切换开销大。3. 区别:线程:一个进程可以有多个线程,所有线程共享进程的内存空间,通讯效率高,切换开销小。共享意味着竞争,导致数据不安全,为了保护内存空间的数据安全,引入"互斥锁"。一个线程在访问内存空间的时候,其他线程不允许访问,必须等待之前的线程访问结束,才能使用这个内存空间4. 协程是线程的一种表现形式,协程又称微线程。在单线程上执行的多个任务,用函数切换,开销极小5. 多线程、协程区别:1. 共同点:都是并发操作,多线程同一时间点只能有一个线程在执行,协程同一时间点只能有一个任务在执行;2. 不同点:多线程,是在I/O阻塞时通过切换线程来达到并发的效果,在什么情况下做线程切换是由操作系统来决定的,开发者不用操心,但会造成竞争条件。协程是用函数切换,开销极小。不通过操作系统调度,没有进程、线程的切换开销。<a name="s3l9g"></a>### 多进程和多线程各自的优点1. 多进程的优点:1. 编程相对容易;通常不需要考虑锁和同步资源的问题。2. 更强的容错性:比起多线程的一个好处是一个进程崩溃了不会影响其他进程。3. 有内核保证的隔离:数据和错误隔离。 对于使用如C/C++这些语言编写的本地代码,错误隔离是非常有用的:采用多进程架构的程序一般可以做到一定程度的自恢复;(master守护进程监控所有worker进程,发现进程挂掉后将其重启)2. 多线程的优点:1. 创建速度快,方便高效的数据共享。共享数据:多线程间可以共享同一虚拟地址空间;多进程间的数据共享就需要用到共享内存、信号量等IPC技术。2. 较轻的上下文切换开销 - 不用切换地址空间,不用更改寄存器,不用刷新TLB。3. 提供非均质的服务。如果全都是计算任务,但每个任务的耗时不都为1s,而是1ms-1s之间波动;这样,多线程相比多进程的优势就体现出来,它能有效降低“简单任务被复杂任务压住”的概率。<a name="d3Yop"></a>### 多进程和多线程之间的应用场景1. 多进程应用场景1. nginx主流的工作模式是多进程模式(也支持多线程模型)2. 几乎所有的web server服务器服务都有多进程的,至少有一个守护进程配合一个worker进程,例如apached、httpd等等以d结尾的进程包括init.d本身就是0级总进程,所有你认知的进程都是它的子进程3. chrome浏览器也是多进程方式。 原因:1. 可能存在一些网页不符合编程规范,容易崩溃,采用多进程一个网页崩溃不会影响其他网页;而采用多线程会。2. 网页之间互相隔离,保证安全,不必担心某个网页中的恶意代码会取得存放在其他网页中的敏感信息4. redis也可以归类到“多进程单线程”模型(平时工作是单个进程,涉及到耗时操作如持久化或aof重写时会用到多个进程)2. 多线程应用场景:1. 线程间有数据共享,并且数据是需要修改的(不同任务间需要大量共享数据或频繁通信时)。2. 提供非均质的服务(有优先级任务处理)事件响应有优先级。3. 单任务并行计算,在非CPU Bound的场景下提高响应速度,降低时延。4. 与人有IO交互的应用,良好的用户体验(键盘鼠标的输入,立刻响应)5. 案例:桌面软件,响应用户输入的是一个线程,后台程序处理是另外的线程;memcached6. **多线程的常见应用场景:**1. 后台任务,例如:定时向大量(100w以上)的用户发送邮件2. 异步处理,例如:发微博、记录日志等3. 分布式计算3. python在多线程处理CPU密集型程序时可以选择多进程实现,有效的利用多核提升效率;而IO密集型的由于99%的时间都花在IO上,花在CPU上的时间很少,所以多线程也能提高很大效率。<a name="o6zxF"></a>### 如何合理地选择多线程和多进程1. 需要频繁创建销毁的优先用线程(进程的创建和销毁开销过大)1. 这种原则最常见的应用就是Web服务器了,来一个连接建立一个线程,断了就销毁线程,要是用进程,创建和销毁的代价是很难承受的2. 需要进行大量计算的优先使用线程(CPU频繁切换)1. 所谓大量计算,当然就是要耗费很多CPU,切换频繁了,这种情况下线程是最合适的。2. 这种原则最常见的是图像处理、算法处理。3. 强相关的处理用线程,弱相关的处理用进程1. 一般的Server需要完成如下任务:消息收发、消息处理。“消息收发”和“消息处理”就是弱相关的任务,而“消息处理”里面可能又分为“消息解码”、“业务处理”,这两个任务相对来说相关性就要强多了。因此“消息收发”和“消息处理”可以分进程设计,“消息解码”、“业务处理”可以分线程设计。4. 可能要扩展到多机分布的用进程,多核分布的用线程<a name="H7Kwy"></a>### 创建线程方法1. **继承Thread**```java// 构造方法的参数是给线程指定名字,推荐Thread t1 = new Thread("t1") {@Override// run 方法内实现了要执行的任务public void run() {log.debug("hello");}};t1.start();输出:19:19:00 [t1] c.ThreadStarter - hello
- 实现Runnable接口
```java
// 创建任务对象
Runnable task2 = new Runnable() {
@Override
public void run() {
} };log.debug("hello");
// 参数1:是任务对象; 参数2:是线程名字,推荐 Thread t2 = new Thread(task2, “t2”); t2.start();
输出:19:19:00 [t2] c.ThreadStarter - hello
3. **实现Callable接口 + FutureTask ** (可以拿到返回结果,可以处理异常)```java// 创建任务对象FutureTask<Integer> task3 = new FutureTask<>(() -> {log.debug("hello");Thread.sleep(2000);return 100;});// 参数1:是任务对象; 参数2:是线程名字,推荐new Thread(task3, "t3").start();// 主线程阻塞,同步等待 task 执行完毕的结果Integer result = task3.get();log.debug("结果是:{}", result);输出:19:22:27 [t3] c.ThreadStarter - hello19:22:27 [main] c.ThreadStarter - 结果是:100
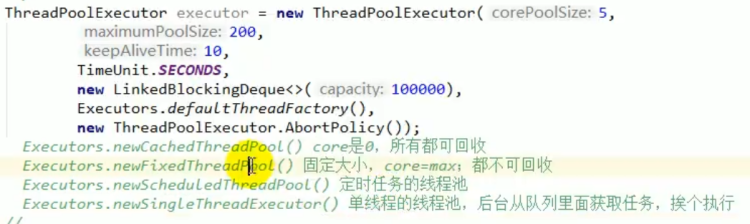
- 线程池

线程池
线程池的7大参数

运行流程:
- 线程池创建,准备好core数量的核心线程,准备接受任务
- 新的任务进来,用core准备好的空闲线程执行。
- core满了,就将再进来的任务放入阻塞队列中。空闲的core就会自己去阻塞队列获取任务执行
- 阻塞队列满了,就直接开新线程执行,最大只能开到max指定的数量
- max都执行好了。Max-core数量空闲的线程会在keepAliveTime指定的时间后自动销毁。最终保持到core大小
- 如果线程数开到了 max 的数量,还有新任务进来,就会使用reject指定的拒绝策略进行处理
- 所有的线程创建都是由指定的factory创建的。
面试:
一个线程池 core 7; max 20 ,queue:50 ,100 并发进来怎么分配的;
先有 7 个能直接得到执行,接下来 50 个进入队列排队,在多开 13 个继续执行。现在 70 个 被安排上了。剩下 30 个默认拒绝策略。
常见的4种线程池
- newCachedThreadPool
- 创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。
- newFixedThreadPool
- 创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。
- newScheduledThreadPool
- 创建一个定长线程池,支持定时及周期性任务执行。
- newSingleThreadExecutor
- 创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。
线程通信的方式
- 线程的通信可以被定义为:线程通信就是当多个线程共同操作共享的资源时,互相告知自己的状态以避免资源争夺
线程通信主要可以分为三种方式,分别为共享内存、消息传递和管道流。每种方式有不同的方法来实现
- 共享内存:线程之间共享程序的公共状态,线程之间通过读-写内存中的公共状态来隐式通信。
- volatile共享内存
- ① 线程A把本地内存A更新过的共享变量刷新到主内存中
② 线程B到内存中去读取线程A之前已更新过的共享变量 - volatile有一个关键的特性:保证内存可见性,即多个线程访问内存中的同一个被volatile关键字修饰的变量时,当某一个线程修改完该变量后,需要先将这个最新修改的值写回到主内存,从而保证下一个读取该变量的线程取得的就是主内存中该数据的最新值,这样就保证线程之间的透明性,便于线程通信
- 消息传递:线程之间没有公共的状态,线程之间必须通过明确的发送信息来显示的进行通信。
- wait/notify等待通知方式:等待通知机制就是将处于等待状态的线程将由其它线程发出通知后重新获取CPU资源,继续执行之前没有执行完的任务。最典型的例子生产者—消费者模式
- join方式:在当前线程A调用线程B的join()方法后,会让当前线程A阻塞,直到线程B的逻辑执行完成,A线程才会解除阻塞,然后继续执行自己的业务逻辑,这样做可以节省计算机中资源
- 管道流
- 共享内存:线程之间共享程序的公共状态,线程之间通过读-写内存中的公共状态来隐式通信。
NEW - 新建
- RUNNABLE - 准备就绪
- BLOCKED - 阻塞
- WAITING - 不见不散
- TIMED_WAITING - 过时不候
-
多线程并发安全问题
线程安全问题:当多个线程下,线程没有按照我们预期的想法执行,导致共享变量出现异常
- 解决线程安全的方式:原子类(juc包)、volatile关键字、加锁(synchronized锁、lock锁)
- 原子类是juc atomic包下的一系列类,通过CAS比较与交换的方式实现共享变量的更新,当期望值与预期值相同时,才对共享变量进行修改
- volatile关键字:保证内存的可见性,不保证原子性,防止指令从排序,保证了【单个变量】读写的线程安全。可见性问题是JMM内存模型中定义每个核心存在一个内存副本导致的,核心只操作他们的内存副本,volatile保证了一旦修改变量则立即刷新到共享内存中,且其他核心的内存副本失效,需要重新读取(以上两种方式都是只保证了单个变量的安全)
加锁:锁则可以保证临界区内的多个共享变量线程安全。加锁有两种方式(synchronized和lock)synchronized可以加在代码块上,普通方法上,静态方法上,在1.6之后引入轻量级锁、偏向锁等优化。lock锁是通过lock加锁,unlock解锁的方式锁住一段代码,基于AQS实现,其加锁解锁就是操作AQS的state变量
进程和线程的上下文切换
进程上下文切换:包含了进程执行所需要的所有信息
- 用户地址空间:包括程序代码,数据,用户堆栈等;
- 控制信息:进程描述符,内核栈等;
- 硬件上下文:进程恢复前,必须装入寄存器的数据统称为硬件上下文。
- 进程切换分为三步骤
- 切换页目录以使用新的地址空间
- 切换内核栈
- 切换硬件上下文
- 刷新TLB
- 系统调度器的代码执行
- 线程上下文切换:对于linux来说,线程和进程的最大区别就在于地址空间。对于线程切换,第1步是不需要做的,第2和3步是进程和线程切换都要做的。所以明显是进程切换代价大
- 线程上下文切换和进程上下文切换一个最主要的区别是线程的切换虚拟内存空间依然是相同的,但是进程切换是不同的。这两种上下文切换的处理都是通过操作系统内核来完成的。内核的这种切换过程伴随的最显著的性能损耗是将寄存器中的内容切换出。
另外一个隐藏的损耗是上下文的切换会扰乱处理器的缓存机制。简单的说,一旦去切换上下文,处理器中所有已经缓存的内存地址一瞬间都作废了。还有一个显著的区别是当你改变虚拟内存空间的时候,处理的页表缓冲(processor’s Translation Lookaside Buffer (TLB))或者相当的神马东西会被全部刷新,这将导致内存的访问在一段时间内相当的低效。但是在线程的切换中,不会出现这个问题。
线程的同步机制
什么是线程同步?
- 当使用多个线程来访问同一个数据时,非常容易出现线程安全问题(比如多个线程都在操作同一数据导致数据不一致),所以我们用同步机制来解决这些问题。
- 实现同步机制有两个方法:
- 同步代码块:synchronized(同一个数据){} 同一个数据:就是N条线程同时访问一个数据。
- 同步方法:public synchronized 数据返回类型 方法名(){}
就是使用synchronized来修饰某个方法,则该方法称为同步方法。对于同步方法而言,无需显示指定同步监视器,同步方法的同步监视器是 this 也就是该对象的本身(这里指的对象本身有点含糊,其实就是调用该同步方法的对象)通过使用同步方法,可非常方便的将某类变成线程安全的类,具有如下特征:- 该类的对象可以被多个线程安全的访问。
- 每个线程调用该对象的任意方法之后,都将得到正确的结果。
- 每个线程调用该对象的任意方法之后,该对象状态依然保持合理状态。
- 注:synchronized关键字可以修饰方法,也可以修饰代码块,但不能修饰构造器,属性等。
- 多线程是解决IO密集型的任务还是解决CPU密集型的任务
开启100个线程,对于同一个变量,初始值为0,做+1的操作,最后输出是多少,答,不确定,给个范围?
进程
进程通信方式
管道
- 消息队列
- 共享内存
- 信号量
- 信号
-
进程调度方法
非剥夺(非抢占)调度方式:当一个进程正在处理机上执行时,即使有某个更为重要或者紧迫的进程进入就绪队列,仍然让正在执行的进程继续执行,知道该进程完成或发生某种事件而进入阻塞态时,才把处理机分配给更为重要或紧迫(优先级更高)的进程。其优点是实现简单,系统开销小,适用于大多数批处理系统,但它不能用于分时系统和大多数实时系统
剥夺(抢占)调度方式:当一个进程正在处理机上执行时,若有某个更为重要或紧迫的进程(优先级更高)的进程需要使用处理机,则立即暂停正在执行的进程,将处理机分配给这个更重要的进程。这种方式对提高系统吞吐率和响应效率都有明显的好处。但抢占也要遵循一定原则
进程之间状态的转换
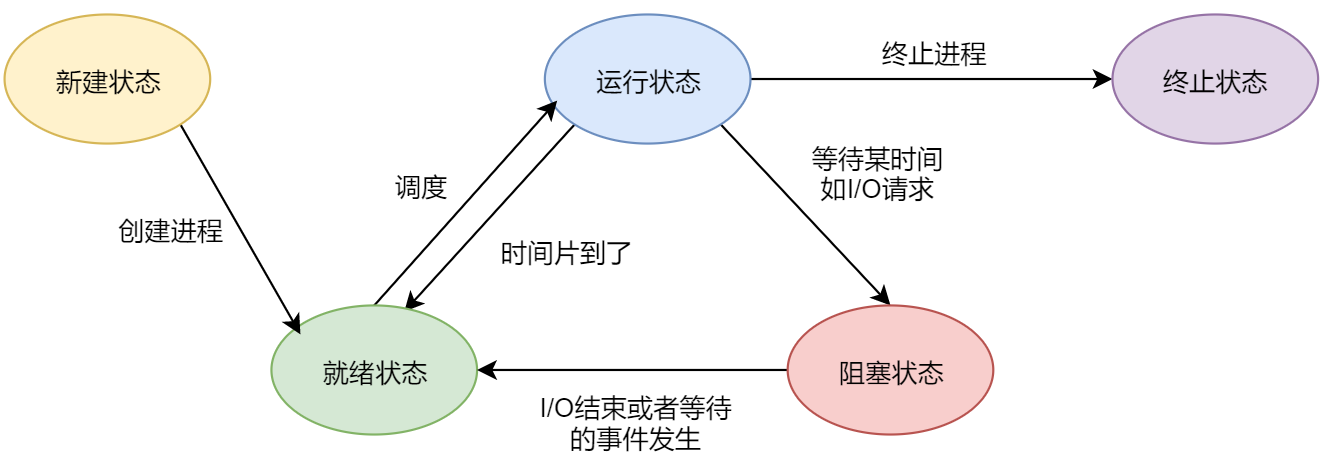
创建状态:进程在创建时需要申请一个空白PCB,向其中填写控制和管理进程的信息,完成资源分配。如果创建工作无法完成,比如资源无法满足,就无法被调度运行,把此时进程所处状态称为创建状态。
- 就绪状态:进程已经准备好,已经分配到所需资源,只要分配到CPU就能够立即运行。
- 执行状态:进程处于就绪状态被调度后,进程进入执行状态
- 阻塞状态:正在执行的进程由于某些事件(I/O请求,申请缓存区失败)而暂时无法运行,进程受到阻塞。在满足请求时进入就绪状态等待系统调用
- 终止状态:进程结束,或出现错误,或被系统终止,进入终止状态。无法再执行
- 用户进程和内核进程有什么区别
- http请求中客户端和服务端也可以看成两个进程,它们是怎么通信的
- 进程之间的数据共享
锁
读写锁,不同点,应用场景
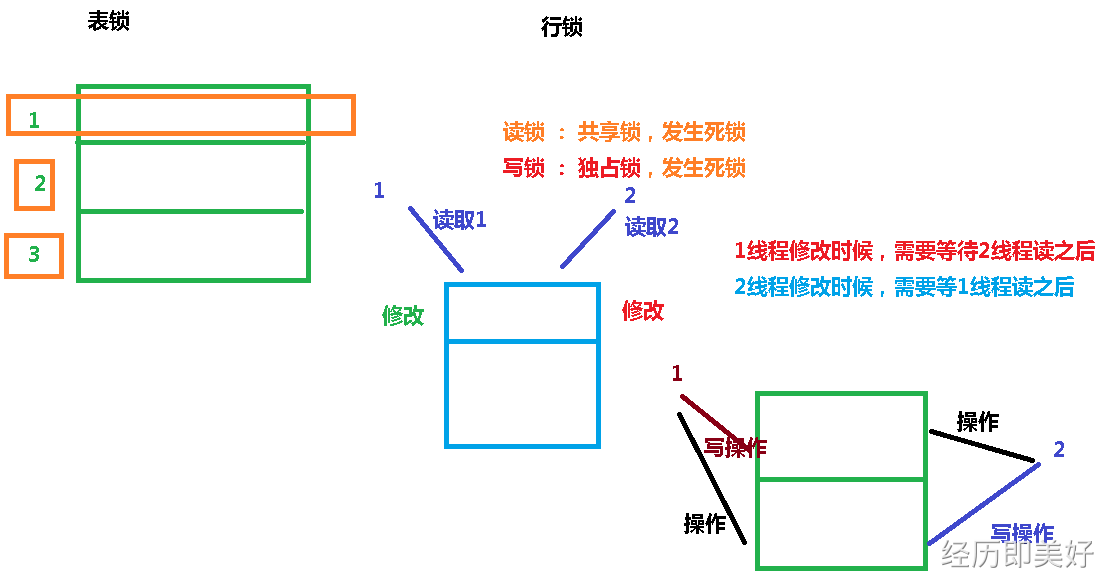
表锁:整个表操作,不会发生死锁行锁:每个表中的单独一行进行加锁,会发生死锁读锁:共享锁(可以有多个人读),会发生死锁写锁:独占锁(只能有一个人写),会发生死锁读写锁:一个资源可以被多个读线程访问,也可以被一个写线程访问,但不能同时存在读写线程,读写互斥,读读共享读写锁ReentrantReadWriteLock读锁为ReentrantReadWriteLock.ReadLock,readLock()方法写锁为ReentrantReadWriteLock.WriteLock,writeLock()方法创建读写锁对象private ReadWriteLock rwLock = new ReentrantReadWriteLock();写锁 加锁 rwLock.writeLock().lock();,解锁为rwLock.writeLock().unlock();读锁 加锁rwLock.readLock().lock();,解锁为rwLock.readLock().unlock();
死锁的四个条件
- 互斥条件:指进程对所分配到的资源进行排它性使用,即在一段时间内某资源只由一个进程占用。如果此时还有其它进程请求资源,则请求者只能等待,直至占有资源的进程用毕释放。
- 请求和保持条件:指进程已经保持至少一个资源,但又提出了新的资源请求,而该资源已被其它进程占有,此时请求进程阻塞,但又对自己已获得的其它资源保持不放。
- 不剥夺条件:指进程已获得的资源,在未使用完之前,不能被剥夺,只能在使用完时由自己释放。
环路等待条件:指在发生死锁时,必然存在一个进程——资源的环形链
预防死锁
多个进程并发执行,由于竞争资源而造成的一种僵局(互相等待),若无外力作用,这些进程都将无法推进,这就是死锁现象
破坏互斥条件
- 破坏不可剥夺条件: 当进程的新资源不可取得时,释放自己已有的资源,待以后需要时重新申请。 但这种方法可能导致迁移阶段工作的失效,反复地申请和释放资源会增加系统开销,降低系统吞吐量。
- 破坏请求并保持条件:进程在运行前一次申请完它所需要的全部资源,在它的资源为满足前,不把它投入运行。一旦投入运行,这些资源都归它所有,不能被剥夺。但这种方法系统资源被严重浪费,而且可能导致饥饿现象,由于个别进程长时间占用某个资源,导致等待该资源的进程迟迟无法运行。
破坏循环等待条件: 给资源编号,规定每个进程必须按编号递增地顺序请求资源,同类资源一次性申请完。这种方法存在问题是发生作业使用资源地顺序与系统规定的顺序不同,造成系统地浪费,并且给编程带来麻烦
死锁解除
一旦检测出死锁,就应该立即采取措施来接触死锁。死锁解除的主要方法有:
资源剥夺法。 挂起某些死锁进程,抢占它的资源,分配给其他死锁进程。
- 撤销进程法。 强制撤销部分进程并剥夺这些进程的资源,让其他进程顺利执行。
-
进程有哪些锁
表锁:整个表操作,不会发生死锁
- 行锁:每个表中的单独一行进行加锁,会发生死锁
- 悲观锁:单独每个人完成事情的时候,执行上锁解锁。解决并发中的问题,不支持并发操作,只能一个一个操作,效率低
- 乐观锁:每执行一件事情,都会比较数据版本号,谁先提交,谁先提交版本号
- 共享锁(S锁):又称为读锁(可以有多个人读),可以查看但无法修改和删除的一种数据锁。如果事务T对数据A加上共享锁后,则其他事务只能对A再加共享锁,不能加排它锁。获准共享锁的事务只能读数据,不能修改数据。共享锁下其它用户可以并发读取,查询数据。但不能修改,增加,删除数据。资源共享
- 排它锁(X锁):又称为写锁、独占锁(只能有一个人写),若事务T对数据对象A加上X锁,则只允许T读取和修改A,其他任何事务都不能再对A加任何类型的锁,直到T释放A上的锁。这就保证了其他事务在T释放A上的锁之前不能再读取和修改A
互斥锁:在编程中,引入了对象互斥锁的概念,来保证共享数据操作的完整性。每个对象都对应于一个可称为” 互斥锁” 的标记,这个标记用来保证在任一时刻,只能有一个线程访问该对象。
Java中的自旋锁
自旋锁是指当一个线程尝试获取某个锁时,如果该锁已被其他线程占用,就一直循环检测锁是否被释放,而不是进入线程挂起或睡眠状态
- 为什么要使用自旋锁
- 多个线程对同一个变量一直使用CAS操作,那么会有大量修改操作,从而产生大量的缓存一致性流量,因为每一次CAS操作都会发出广播通知其他处理器,从而影响程序的性能
- 对比互斥锁和自旋锁:
- 互斥锁:从等待到解锁过程,线程会从block状态变为running状态,过程中有线程上下文的切换,抢占CPU等开销。
- 自旋锁:从等待到解锁过程,线程一直处于running状态,没有上下文的切换
- 虽然自旋锁效率比互斥锁高,但它会存在下面两个问题:
- 自旋锁一直占用CPU,在未获得锁的情况下,一直运行,如果不能在很短的时间内获得锁,会导致CPU效率降低。
- 试图递归地获得自旋锁会引起死锁。递归程序决不能在持有自旋锁时调用它自己,也决不能在递归调用时试图获得相同的自旋锁
由于自旋锁只是在当前线程不停地执行循环体,不进行线程状态的切换,因此响应速度更快。但当线程数不停增加时,性能下降明显,因为每个线程都需要占用CPU时间。如果线程竞争不激烈,并且保持锁的时间很短,则适合使用自旋锁。
synchronized与lock区别
synchronized是一个关键字而lock是一个接口(lock、lockInterruptibly、tryLock、unlock、newCondition)。
- synchronized是隐式的加锁,lock是显示的加锁。
- synchronized可以作用在方法和代码块上,而lock只能作用在代码块上。
- synchronized作用在静态方法上锁的是当前类的class,作用在普通方法上锁的是当前类的对象。
- 在javap反编译成字节码后,synchronized关键字需要有一个代码块进入的点monitorenter,代码块退出和代码块异常的出口点monitorexit。
- synchronized是阻塞式加锁,而lock中的trylock支持非阻塞式加锁。
- synchronized没有超时机制,而lock中的trylcok可以支持超时机制。
- synchronized不可中断,而lock中的lockInterruptibly可中断的获取锁
- ReentrantLock.lockInterruptibly允许在等待时由其它线程调用等待线程的Thread.interrupt方法来中断等待线程的等待而直接返回,这时不用获取锁,而会抛出一个InterruptedException。 ReentrantLock.lock方法不允许Thread.interrupt中断,即使检测到Thread.isInterrupted,一样会继续尝试获取锁,失败则继续休眠。只是在最后获取锁成功后再把当前线程置为interrupted状态,然后再中断线程
- synchronized采用的是monitor对象监视器,lock的底层原理是AQS
- synchronized只有一个同步队列和一个等待队列,而lock有一个同步队列,可以有多个等待队列。
- 同步队列:排队取锁的线程所在的队列。
- 等待队列:调用 wait 方法后,线程会从同步队列转移到等待队列。
- synchronized是非公平锁,而lock可以是公平锁也可以是非公平锁。
- synchronized用object的notify方法进行唤醒,而lock用condition进行唤醒。
-
JUC三大辅助类
JUC 中提供了三种常用的辅助类,通过这些辅助类可以很好的解决线程数量过多时 Lock 锁的频繁操作。这三种辅助类为:
CountDownLatch: 减少计数
- CountDownLatch类可以设置一个计数器,然后通过countDown方法来进行减 1 的操作,使用 await方法等待计数器不大于0,然后继续执行 await 方法之后的语句
- 场景: 6 个同学陆续离开教室后值班同学才可以关门
- CyclicBarrier: 循环栅栏
- 在使用中CyclicBarrier 的构造方法第一个参数是目标障碍数,每次执行CyclicBarrier 一次障碍数会加一,如果达到了目标障碍数,才会执行cyclicBarrier.await()之后的语句。可以将CyclicBarrier 理解为加1 操作
- 场景:集齐7 颗龙珠就可以召唤神龙
- Semaphore: 信号灯
同步异步区别(同步阻塞/同步非阻塞/异步)
什么是系统调用?库函数和系统调用的区别?
- 系统调用是通向操作系统本身的接口,是面向底层硬件的。通过系统调用,可以使得用户态运行的进程与硬件设备(如CPU、磁盘、打印机等)进行交互,是操作系统留给应用程序的一个接口
- 库函数(Library function)是把函数放到库里,供别人使用的一种方式。方法是把一些常用到的函数编完放到一个文件里,供不同的人进行调用。一般放在.lib文件中。库函数调用则是面向应用开发的,库函数可分为两类,一类是C语言标准规定的库函数,一类是编译器特定的库函数
- 区别:
- 库函数是语言或应用程序的一部分,而系统调用是内核提供给应用程序的接口,属于系统的一部分
- 库函数在用户地址空间执行,系统调用是在内核地址空间执行,库函数运行时间属于用户时间,系统调用属于系统时间,库函数开销较小,系统调用开销较大
- 库函数是有缓冲的,系统调用是无缓冲的
- 系统调用依赖于平台,库函数并不依赖
- 堆和栈的区别以及存储模式有什么区别
- 操作系统内存寻址了解吗?
- 虚存与物理内存等相关
- 计算机内存管理的方式
- 什么是Linux用户态和内核态
- 虚拟内存是干嘛的
虚拟内存和物理内存有什么样的区别。举个例子,为什么会需要有虚拟内存和物理内存这两个
计算机网络
TCP三次握手与四次挥手
TCP三次握手,四次挥手的过程
- TCP三次握手中SYN和ACK包有什么不同,包含什么
- ACK(ACKnowledgment) 仅当ACK=1时确认号字段才有效。当ACK= 0时,确认号无效。TCP规建立连接后,所有报文ACK都为必须为1(ACK报文段可以携带数据,但如果不携带也不消耗序号)
- SYN(SYNchronization) 在建立连接时用来同步序号,当SYN=1而ACK=0时,表明是一个连接请求报文段。因此,SYN=1就表示连接请求或连接接受报文(在三次握手中SYN=1时,报文不携带数据,但要消耗一个序号)
- 三次握手过程中是否存在安全问题?描述一下存在什么样的安全问题?针对这样的安全问题如何防御?
- tcp三次握手,除了常规的过程、报文结构,还有觉得为什么要用三次,半连接队列、全连接队列,哪些握手能带数据?为什么第一次不可以?什么是syn攻击,举几个例子?这些分别怎么预防。
- tcp四次挥手,介绍过程,为什么等待timewait才能断开? 为什么要设置成2msl?
- 为什么要四次挥手?第二次和第三次为什么不合并?
- TCP三次握手和四次挥手,为什么要三次握手,为什么不是四次或者更多次
- 一句话概括tcp三次握手,只能用一句话(继续懵逼,仔细复习了三次握手四次挥手,结果只让说一句话回答,卡了半天不知道说什么好,最后瞎回答了一下。答案应该是确保双方能否正常收发)
- 三次握手,syn,ack,seq代表什么意思,中文含义

- 为什么客户端要在TIME_WAIT状态等待一段时间
- CLOSING状态
如果server端没有收到第三次ack,但是收到了client端发送的数据,server端会怎么处理
https://blog.csdn.net/MrLiar17/article/details/118893121
http协议
讲一讲get和post
- get:发送一个请求常用来获取服务器资源
- post:向URL指定的资源提交数据或附加新的数据

http状态码
- 200 – 服务器成功返回网页 404 – 请求的网页不存在 503 – 服务不可用
- 2xx (成功):表示成功处理了请求的状态代码
- 3xx (重定向):表示要完成请求,需要进一步操作。 通常,这些状态代码用来重定向
- 4xx(请求错误):这些状态代码表示请求可能出错,妨碍了服务器的处理
- 400 (错误请求) 服务器不理解请求的语法
- 401 (未授权) 请求要求身份验证。 对于需要登录的网页,服务器可能返回此响应
- 403 (禁止) 服务器拒绝请求
- 404 (未找到) 服务器找不到请求的网页
- 405 (方法禁用) 禁用请求中指定的方法
- 5xx(服务器错误):这些状态代码表示服务器在尝试处理请求时发生内部错误。 这些错误可能是服务器本身的错误,而不是请求出错
- 输入一个url到网页出现涉及的协议以及协议的功能

https://www.cnblogs.com/zccfrancis/p/14613031.html
浏览器是如何渲染的
https的加密过程
什么是非对称加密和对称加密,https用到了什么加密
http和https
https://blog.csdn.net/qq_35642036/article/details/82788421
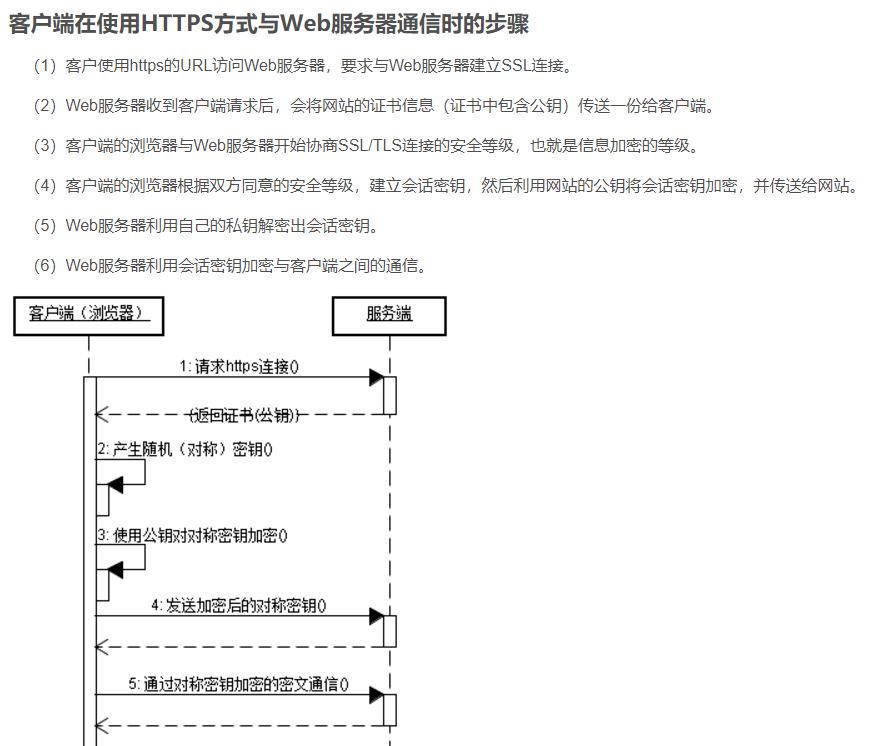
https就一定安全吗?
https://blog.csdn.net/wo541075754/article/details/120073424
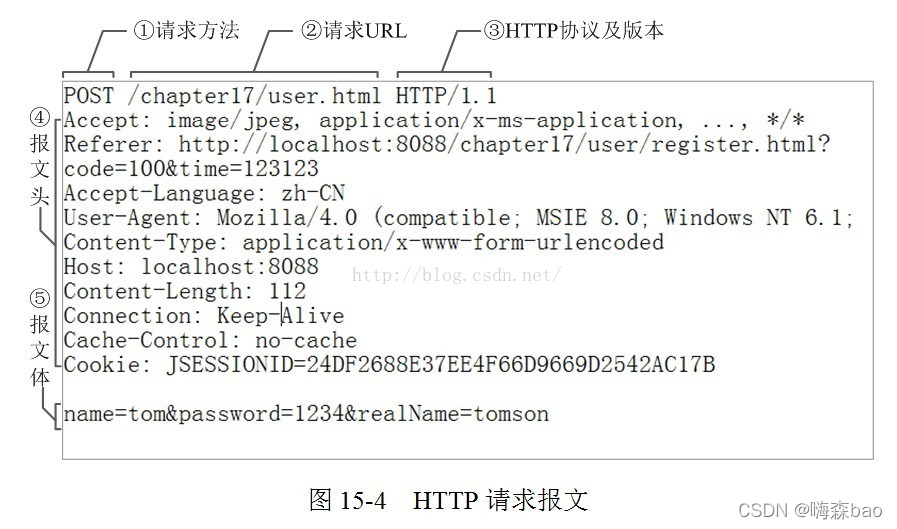
HTTP协议请求报文结构
https://blog.csdn.net/HeyWeCome/article/details/104504387
https://blog.csdn.net/weixin_49782150/article/details/124170304
HTTP 请求报文由请求行、请求头、空行和请求包体(body)组成
 HTTP响应报文也由三部分组成:响应行、响应头、响应体
HTTP响应报文也由三部分组成:响应行、响应头、响应体

Content-Type
在HTTP协议消息头中,使用Content-Type来表示媒体类型信息。它被用来告诉服务端如何处理请求的数据,以及告诉客户端(一般是浏览器)如何解析响应的数据,比如显示图片,解析html或仅仅展示一个文本等
(1)application/x-www-form-urlencoded:浏览器原生的form表单类型,或者说是表单默认的类型
(2)application/json:post会将序列化后的json字符串直接塞进请求体中
(3)multipart/form-data:用于在表单中上传文件
(4)multipart/form-data:与application/x-www-form-urlencoded不同,这是一个多部分多媒体类型。首先生成了一个 boundary 用于分割不同的字段,在请求实体里每个参数以———boundary开始,然后是附加信息和参数名,然后是空行,最后是参数内容。多个参数将会有多个boundary块。如果参数是文件会有特别的文件域。最后以———boundary–为结束标识。multipart/form-data支持文件上传的格式,一般需要上传文件的表单则用该类型
(5)application/xml 和 text/xml:与application/json类似,这里用的是xml格式的数据,text/xml的话,将忽略xml数据里的编码格式
http请求头包含哪些内容
- Accept: 浏览器可接受的MIME类型。
- Accept-Charset:浏览器可接受的字符集。
- Accept-Encoding:浏览器能够进行解码的数据编码方式,比如gzip。Servlet能够向支持gzip的浏览器返回经gzip编码的HTML页面。许多情形下这可以减少5到10倍的下载时间。
- Accept-Language:浏览器所希望的语言种类,当服务器能够提供一种以上的语言版本时要用到。
- Authorization:授权信息,通常出现在对服务器发送的WWW-Authenticate头的应答中。
- Content-Length:表示请求消息正文的长度。
- Host:客户机通过这个头告诉服务器,想访问的主机名。Host头域指定请求资源的Intenet主机和端口号,必须表示请求url的原始服务器或网关的位置。HTTP/1.1请求必须包含主机头域,否则系统会以400状态码返回
- Referer:客户机通过这个头告诉服务器,它是从哪个资源来访问服务器的(防盗链)。包含一个URL,用户从该URL代表的页面出发访问当前请求的页面。
- User-Agent:User-Agent头域的内容包含发出请求的用户信息。浏览器类型,如果Servlet返回的内容与浏览器类型有关则该值非常有用。
- Cookie:客户机通过这个头可以向服务器带数据,这是最重要的请求头信息之一。
无状态和无连接
https://blog.csdn.net/weixin_39618279/article/details/114794917
- 无连接:指HTTP协议每次连接只处理一个HTTP请求,服务器处理完客户端的请求并且得到客户端的应答后,就会断开连接。
- 无状态:无状态是指HTTP协议对于事务处理是没有记忆能力的,缺少状态就意味着后续的处理需要用到前面的信息时需要重新发送。
OSI七层模型
- (高)OSI七层模型,各层有哪些协议
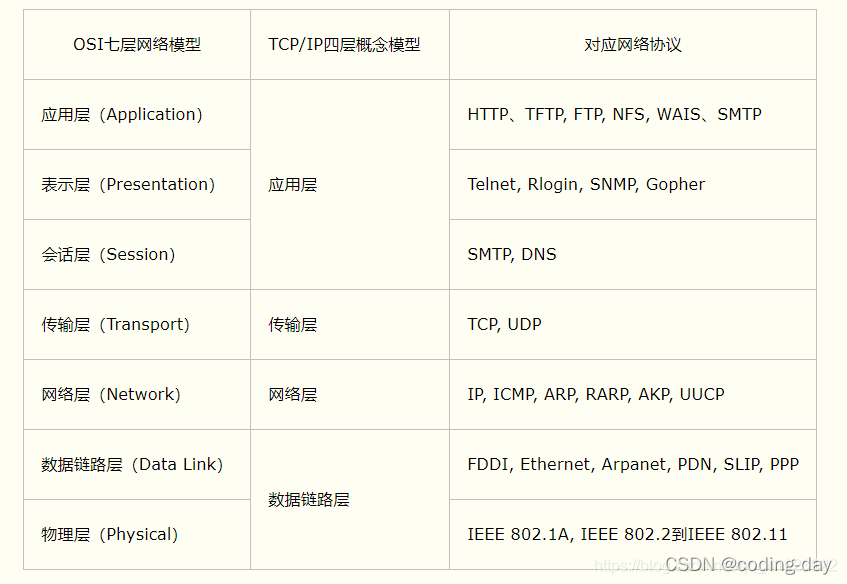
- 路由器和交换机分别在哪层
- 网卡、中继器、集线器工作在OSI的第一层:物理层
- 交换机、网桥工作在OSI的第二层:数据链路层,跟据mac地址决定转发
- 路由器工作在OSI的第三层:网络层,根据ip地址决定转发
- 网关工作在OSI的第四层:传输层,根据段口号决定转发
- 交换机、网关、路由器作用是什么
- 应用层协议举例
- 负责完成网络中应用程序与网络操作系统之间的联系,建立与结束使用者之间的联系,并完成网络用户提出的各种网络服务及应用所需的监督、管理和服务等各种协议
- TELENT:使用远程计算机上所拥有的本地计算机没有的信息资源,是常用的远程控制Web服务器的方法
- DNS(域名解析协议):将域名解析为IP地址
- HTTP(超文本传输协议):规定web服务端和客户端的数据传输格式
- HTTPS(超文本传输安全协议):是HTTP加上TLS/SSL协议构成的可加密传输的网络协议
- FTP(文件传输协议):网络共享文件传输
- NFS(网络文件系统):用户和程序可以像访问本地文件一样访问远端系统上的文件
- http在应用层
- tcp、udp在传输层
- 详细说ARP和DNS协议
- CDN
- 数据链路层的作用
- 网络层会有哪些错误信息
TCP/IP协议
- TCP如何保证可靠传输,丢包怎么办
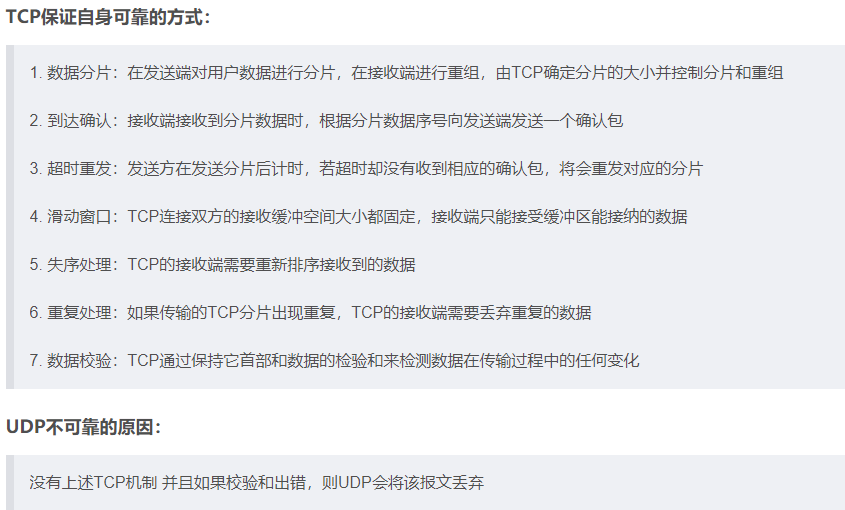
- 讲一下滑动窗口
- UDP想要可靠怎么实现 RUDP
- 半连接攻击
- TCP粘包和拆包
- DNS解析用的什么协议:UDP
- ARP协议作用、工作方式
- 以太网数据包的大小最大为多少

- web攻击,CSRF攻击
- TCP如何进行拥塞控制?拥塞控制如何判断发生拥塞?(滑动窗口,拥塞控制:重点)
- tcp的流量控制是什么(说成了拥塞控制)
- TCP快重传如何判断丢失?
- ip报文头部都有什么
- 长连接和短连接以及他们分别适用的场景

- tcp与udp区别,举例应用场景
https://blog.csdn.net/Azreax/article/details/126985975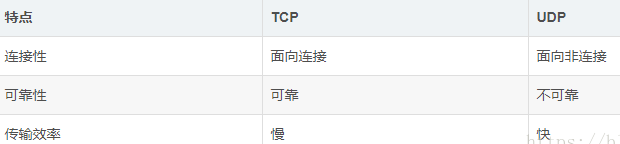

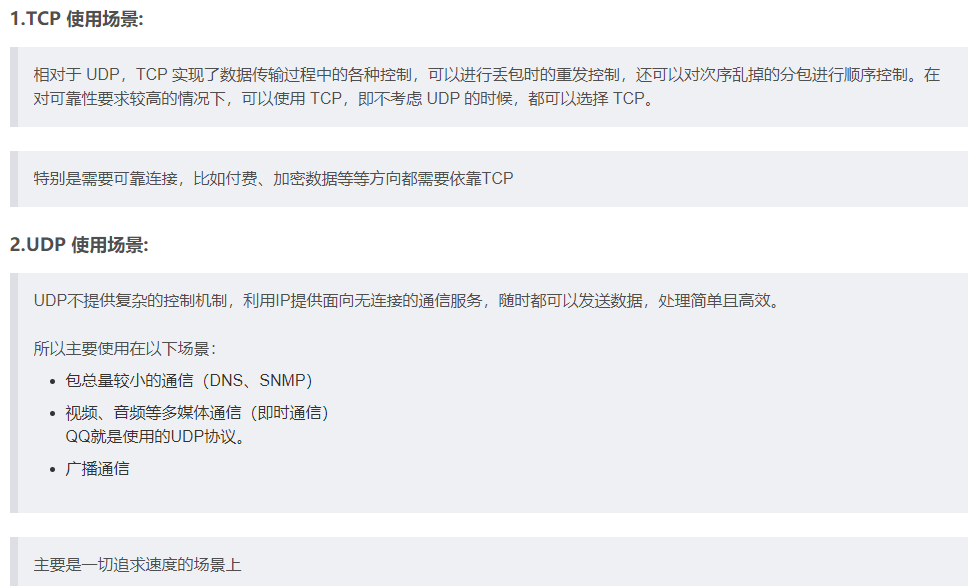
- 我们现在的视频面试使用的是UDP还是TCP 为什么。
- 说了几个场景,让我判断适合tcp还是udp。
- udp,它应用于对实时性要求高的场景,例如:直播,视频、通话。宁愿丢包,也不愿卡顿
- 用于对数据可靠性要求高的场景:例如:文件的发送,短信的发送等
- TCP、UDP区别表
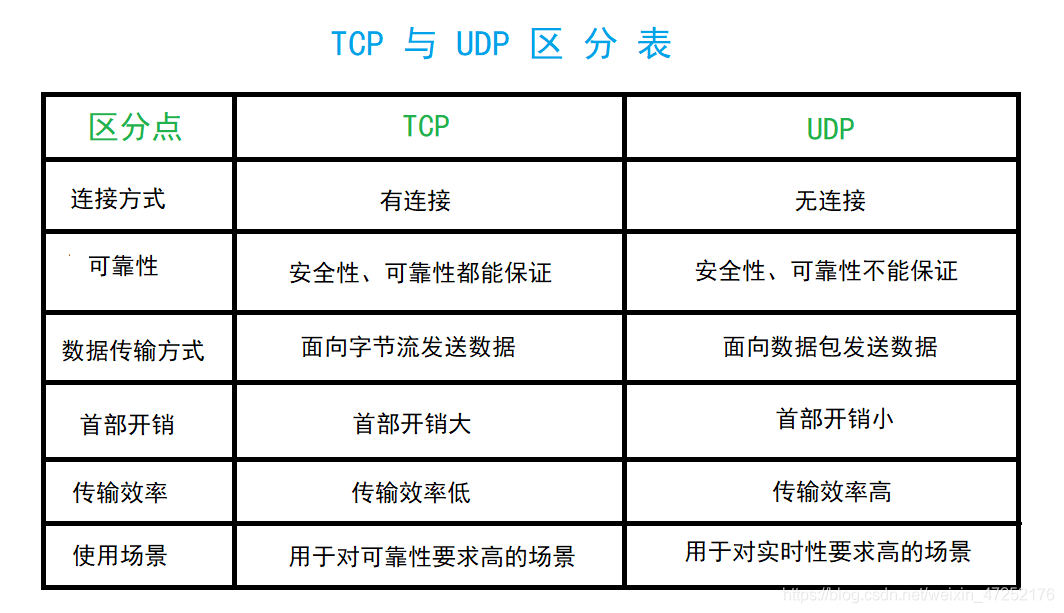
udp,报文结构、优缺点????
cookie和session是什么,
- 为什么要用cookie和session
- cookie和session,如果用户拒绝cookie,那session会怎样
- https://www.yuque.com/fangniudexingxing-uymcu/wxedug/phnuyt#UglYv
- https://blog.csdn.net/qq_41723615/article/details/104364061
DNS协议和作用,DNS的查询方式
https://blog.csdn.net/TABE_/article/details/123595573

ipv4和ipv6区别
数据库
DDL数据定义语言
用来定义数据库对象,如数据库、数据表和数据字段
mysql -u root -p查询所有数据库show databases;查询当前数据库select database();查看数据库编码show variables like 'character%';使用数据库use 数据库名;创建数据库create database [if not exists] 数据库名 [DEFAULT CHARSET 字符集] [COLLATE 排序规则] ;删除数据库drop database [if exists] 数据库名;创建数据表create table 表名(字段1 字段1类型 [comment 字段1注释],字段2 字段2类型 [comment 字段2注释],字段3 字段3类型 [comment 字段3注释],......字段n 字段n类型 [comment 字段n注释])[comment 表注释];查询当前数据库所有数据表show tables;查询表结构desc 表名;修改数据表名alter table 表名 rename to 新表名;添加数据表字段alter table 表名 add 字段名 类型(长度) [comment 字段注释] [约束]修改字段名、字段类型alter table 表名 change 旧字段名 新字段名 字段类型(长度) [comment 注释] [约束]删除数据表字段alter table 表名 drop 字段名;删除数据表truncate table 表名; #删除指定表,并重新创建该表drop table [if exists] 表名; #删除数据表
DML数据操作语言
用来对数据库表中的数据进行增删改查操作
-- insert into 表名([字段名1,字段名2,字段名3])values('值1'),('值2'), ('值3')-- 方式一:没有指明要添加的字段,要按照声明字段的先后顺序添加insert into emp1 values(1,'wanli','2022-12-12',4000)-- 由于主键自增我们可以省略insert into emp1 values('wanli','2022-12-12',4000)-- 方式二:指明要添加的字段,没有指明的字段值为nullINSERT INTO `grade`(`gradeid`,`gradename`) VALUES('11114','大七')INSERT INTO dependents (first_name, last_name, relationship, employee_id) VALUES('Avg','Lee', 'Child', 192 ),('Michelle','Lee', 'Child', 193);将dependents表中的所有行复制到dependents_archive表中:INSERT INTO dependents_archive SELECT *FROM dependents;UPDATE table_name SET column1 = value1,column2 = value2 WHERE condition;DELETE FROM table_name WHERE condition;
DQL数据查询语言
用来查询数据库中表的记录
# 编写顺序SELECT DISTINCT<select list>FROM<left_table> <join_type>JOIN<right_table> ON <join_condition>WHERE<where_condition>GROUP BY<group_by_list>HAVING<having_condition>ORDER BY<order_by_condition>LIMIT<limit_params>执行顺序FROM <left_table>ON <join_condition><join_type> JOIN <right_table>WHERE <where_condition>GROUP BY <group_by_list>HAVING <having_condition>SELECT DISTINCT <select list>ORDER BY <order_by_condition>LIMIT <limit_params>
语法说明:
(1)使用 select 关键字来做查询;
(2)字段列表是使用英文逗号来进行分割 ;
(3)from关键字后跟表的,可以是多个表名称或视图名称;
(4)group by:用于分组查询;
(5)having:用于结分组查询时进行过滤——条件的筛选;
(6)order by:用于数据显示时的排序;
(7)asc:表示长序,它是默认值;
(8)desc:表示降序;
(9)limit:用于分页显示,它有两个参数,第一个参数是起始值,第二个参数是显示的数量
聚合函数
模糊查询(like)
模糊查询需要使用like关键字,也可使用 not like 来进行查询。要模糊查询中,我们还可以使用
通配符:
(1)% :表示 0 ~ n 个字符。 ename like ‘%孙%’
(2) :表示一个字符。like ‘孙‘
分页查询(limit)
分组查询(group by)
排序查询(order by)
排序查询会使用到 order by 关键字,还会使用到 asc(升序) 或 desc(降序) 关键字。
where和having的区别
关联查询
表的连接查询的约束条件有三种方式:
(1)where:适用于所有的关联查询。
(2)on:只能和 join一起使用,只能写在关联条件中,但是它可以和 where 一起使用。
(3)using:只能和 join 一起使用,并且要求两个关联的字段在关联表中名称一致。
内连接
在 MySQL 中内连接( inner join )有两种:显示的内连接和隐式的内连接,返回的结果是符合条件的所有数据。
隐式的内连接语法为:select [columns] from 表1,表2,... where [condition];显式的内连接语法为:select [columns] from 表1 inner join 表2 on [condition] where [其它条件];select [columns] from 表1 cross join 表2 on [condition] where [其它条件];select [columns] from 表1 join 表2 on [condition] where [其它条件];
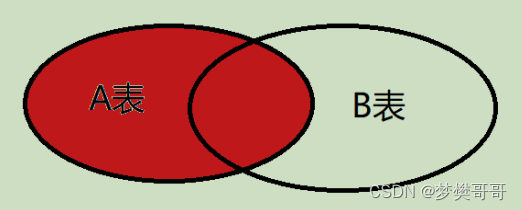
执行关联查询后的结果为如上图所示的红色区域内的数据。也就是两张表中共同的部分。
外连接
外连接( outer join )在 MySQL 有以下几种外连接:
(1) 左外连接( left outer join ):简称左连接( left join )
(2) 右外连接( right outer join ):简称右连接( right join )
(3)全外连接( full outer join ):简称全外连接( full join )
左外连接(left join)
左外连接是以左表要基准表,如果右表中没有数据和左表匹配,则以空值( null 值)为填充。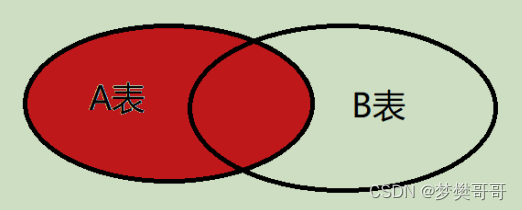
右外连接(right join)
返回右表中所有行,如果右表中的行在左表中没有匹配的行,则左表中以空值来填充。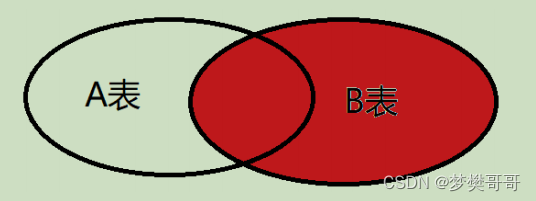
全外连接(union)
在 MySQL 中不支持全外连接( full join ),但是我们可以使用 union 关键字来代替,它代表联合查询的意思。可以使用如下语法来代替:
select column_listfrom 表1 left join 表2on 条件unionselect column_listfrom 表1 right join 表2on 条件
子查询
在某些情况下,我们在做查询时,需要的条件或数据是另一个查询的结果,这时就用到子查询。
在 MySQL 中,子查询有以下几种:
(1)where 型子查询:把子查询作为 where 的条件(条件)
(2)from 型子查询:把子查询作为 from 的临时表(数据)
(3) exists 型子查询:把子查询作为判断是否存在的条件(条件)
(4) copy 型子查询:用于复制表数据或结构
DCL数据控制语言
用来创建数据库用户、控制数据库的访问权限
授予admin3对bbs库所有的表,具有所有的权限(不包含授权)mysql> GRANT ALL ON bbs.* TO admin3@'localhost' identified by 'QianFeng@123';mysql> select user,host from mysql.user;//准备测试帐号mysql> CREATE USER admin3@'%' identified by 'Qian@123';//授权帐号mysql> CREATE ALL ON bbs.* TO admin3@'%' identified by 'Qian@123';//使用测试账户操作数据库[root@localhost ~]# mysql -uadmin3 -p'Qian@123'mysql> crate database bbs;进入bbs库,创建数据表和插入数据,授权验证完毕,别的库会报错
// 开启慢查询日志功能。默认慢查询日志未开启vim /etc/my.cnf加入下面两行配置slow_query_log=1log_query_time=3systemctl restart mysqld //重启数据库// 查看慢查询日志文件ll /var/lib/mysql/*slow* //查看日志文件已经生成// 模拟慢查询mysql> select benchmark(500000000,2*3); //基本测试语句,测试一个超长时间的查询// 验证慢查询日志tail /var/lib/mysql/localhost-slow.log //管擦和长查询日志,记录了刚才超长的查询结果vim /etc/my.cnf // 进入主配置日志,观察日志是否启动log-error=/var/log/mysqld.log //该字段,标记是否启动日志,以及日志位置//如果哪天mysql服务起不来了,来这个日志文件看看
delete、truncate、drop
- truncate:删除表中的内容,不删除表结构,释放空间
- delete:删除内容,不删除表结构,但不释放空间
- drop:删除内容和定义,并释放空间。执行drop语句,将使此表的结构一起删除
- 内存空间:truncate删除数据后重新写数据会从1开始,而delete删除数据后只会从删除前的最后一行续写;内存空间上,truncate省空间
- 处理速度:drop>truncate>delete。因为truncate是直接从1开始,即全部清空开始,而delete需要先得到当前行数,从而进行续写;所以truncate删除速度比delete快
- 语句类型:delete属于DML语句,而truncate和drop都属于DDL语句,这造成了它们在事务中的不同现象
- delete在事务中,因为属于DML语句,所以可以进行回滚和提交操作(由操作者)
- truncate和drop则属于DDL语句,在事务中,执行后会自动commit,所以不可以回滚
- delete from 表名 (where…可写可不写,写的话进行选择性删除,不选清空表中数据)
- truncate 表名(删除表中的数据,无法回滚的)
- delete可以在后续加上where进行针对行的删除
- truncate和drop后面只能加上表名,直接删除表,无法where
事务相关
事务(Transaction)指一个操作,由多个步骤组成,要么全部成功,要么全部失败。 ```sqlCOMMIT是指提交事务,即试图把事务内的所有SQL所做的修改永久保存
如果COMMIT语句执行失败了,整个事务也会失败
BEGIN; UPDATE accounts SET balance = balance - 100 WHERE id = 1; UPDATE accounts SET balance = balance + 100 WHERE id = 2; COMMIT;
些时候,我们希望主动让事务失败,这时,可以用ROLLBACK回滚事务,整个事务会失败
BEGIN; UPDATE accounts SET balance = balance - 100 WHERE id = 1; UPDATE accounts SET balance = balance + 100 WHERE id = 2; ROLLBACK;
<a name="d6Fd4"></a>### 事务的特性(ACID)| **ACID属性** | **含义** || --- | --- || **原子性**(Atomicity) | 事务是一个原子操作单元,其对数据的修改,要么全部成功,要么全部失败 || 一致性(Consistent) | 在事务开始和完成时,数据都必须保持一致状态 || **隔离性**(Isolation) | 数据库系统提供一定的隔离机制,保证事务在不受外部并发操作影响的 “独立” 环境下运行,**不能被其他事务的操作所干扰,多个并发事务事务之间要相互隔离** || **持久性**(Durable) | 事务完成之后,对于数据的修改是永久的,即便是在数据库系统遇到故障的情况下也不会对事提交事务的操作 |<a name="Ddvax"></a>### 并发事务处理带来的问题| **问题** | **含义** || --- | --- || 丢失更新(Lost Update) | 当两个或多个事务选择同一行,最初的事务修改的值,会被后面的事务修改的值覆盖。 || 脏读(Dirty Reads) | 当一个事务正在访问数据,并且对数据进行了修改,而这种修改还没有提交到数据库中,这时另外一个事务也访问这个数据,然后使用了这个数据 || 不可重复读(Non-Repeatable Reads) | 一个事务对同一行数据重复读取两次,但却得到了不同的结果。事务T1读取某一数据后,事务T2对其做了修改。当T1再次读取数据时得到与之前的结果不一致 || 幻读(Phantom Reads) | 一个事务按照相同的查询条件重新读取以前查询过的数据,却发现其他事务插入了满足其查询条件的新数据(前后两次查询数据结果不一致) |**幻读和不可重复读的区别**<br />幻读(虚读):一个事务在两次统计某张表的时候,发现最终的统计结果不一致<br />不可重复的:一个事物两次读取同一条数据,两次的读取结果不一致<a name="pmkHj"></a>### 事务的隔离级别为了解决上述提到的事务并发问题,数据库提供一定的事务隔离机制来解决这个问题。数据库的事务**隔离越严格,并发副作用越小,但付出的代价也就越大**,因为事务隔离实质上就是使用事务在一定程度上“串行化” 进行,这显然与“并发” 是矛盾的。 <br />数据库的隔离级别有4个,由低到高依次为Read uncommitted读未提交、Read committed读已提交、Repeatable read可重复读、Serializable串行化,这四个级别可以逐个解决脏写、脏读、不可重复读、幻读这几类问题1. READ UNCOMMITTED(**读未提交**)1. 如果一个事务已经开始写数据,则另一个事务则不允许同时进行写操作,但允许其他事务读此行数据。(排他写锁)**,避免了更新丢失,却可能出现脏读**2. READ COMMITTED(**读提交**)1. 如果一个读事务(线程),则允许其他事务读写;如果是写事务将会禁止其他事务访问该行数据。**该隔离避免了脏读,但却可能出现不可重复读。解决了更新丢失和脏读问题**2. Oracle 和 SQL Server 的默认隔离级别3. REPEATABLE READ(**可重复读**)1. 该隔离级别是**MySQL 默认的隔离级别**,在同一个事务里,select的结果是事务开始时时间点的状态,因此,同样的**select 操作读到的结果会是一致的(即使其他用户已经修改了该数据)**,但是,会有**幻读**现象。MySQL的 InnoDB 引擎可以通过 next-key locks 机制(参考下文"行锁的算法"一节)来避免幻读4. SERIALIZABLE(**序列化**)1. 事务只能一个接着一个地执行但不能并发执行。序列化是最高级的事务隔离级别,但性能低,很少使用。可以避免上述各情况2. 在该隔离级别下事务都是串行顺序执行的,MySQL数据库的InnoDB引擎会给读操作隐式加一把读共享锁,从而避免了脏读、不可重读复读和幻读问题。| **隔离级别** | **丢失更新** | **脏读** | **不可重复读** | **幻读** || --- | --- | --- | --- | --- || Read uncommitted:读未提交 | × | √ | √ | √ || Read committed:读已提交 | × | × | √ | √ || Repeatable read:可重复读(默认) | × | × | × | √ || Serializable:串行化 | × | × | × | × |备注 : √ 代表可能出现 , × 代表不会出现<a name="QiWhe"></a>## 索引相关1. 主键、外键、索引的各自的含义以及区别1. **主键(primary key)**能够唯一标识表中某一行的属性或属性组。一个表只能有一个主键,但可以有多个候选索引。主键常常与外键构成参照完整性约束,防止出现数据不一致。主键可以保证记录的唯一和主键域非空,数据库管理系统对于主键自动生成唯一索引,所以主键也是一个特殊的索引2. **外键(foreign key)**是用于建立和加强两个表数据之间的链接的一列或多列。外键约束主要用来维护两个表之间数据的一致性。简言之,表的外键就是另一表的主键,外键将两表联系起来。一般情况下,要删除一张表中的主键必须首先要确保其它表中的没有相同外键(即该表中的主键没有一个外键和它相关联)3. 索引(index)是用来快速地寻找那些具有特定值的记录。主要是为了检索的方便,是为了加快访问速度, 按一定的规则创建的,一般起到排序作用。所谓唯一性索引,这种索引和前面的“普通索引”基本相同,但有一个区别:索引列的所有值都只能出现一次,即必须唯一4. 总结:1. 主键一定是唯一性索引,唯一性索引并不一定就是主键2. 一个表中可以有多个唯一性索引,但只能有一个主键3. 主键列不允许空值,而唯一性索引列允许空值4. 主键可以被其他字段作外键引用,而索引不能作为外键引用2. 什么是聚簇索引、什么是非聚簇索引1. 聚簇索引叶子节点存储的是行数据;而非聚集索引的叶子节点是不存放数据的,所以非聚集索引的更新代价就没有聚集索引那么大了2. 聚簇索引查询效率更高,而非聚簇索引需要进行回表查询,因此性能不如聚簇索引3. 聚簇索引一般为主键索引,而主键一个表中只能有一个,因此聚簇索引一个表中也只能有一个,而非聚簇索引则没有数量上的限制3. 索引越来越大越来越臃肿怎么去优化?<a name="ohCp4"></a>### 索引的原理**索引是帮助Mysql高效获取数据的排好序的数据结构****索引数据结构:**<br />1、二叉树<br />2、红黑树<br />3、Hash表<br />4、B-TreeMysql的Innodb引擎不支持hash索引,而采用的是b+树1. Hash索引适合精确查找,但是范围查找不适合2. 因为存储引擎都会为每一行计算一个hash码,hash码都是比较小的,并且不同键值行的hash码通常是不一样的,hash索引中存储的就是Hash码,hash 码彼此之间是没有规律的,且 Hash 操作并不能保证顺序性,所以值相近的两个数据,Hash值相差很远,被分到不同的桶中。这就是为什么hash索引只能进行全职匹配的查询,因为只有这样,hash码才能够匹配到数据3. MySQL中最常用的索引的数据结构是B+树1. 在 B+ 树中,所有数据记录节点都是按照键值的大小存放在同一层的叶子节点上,而非叶子结点只存储key的信息,这样可以大大减少每个节点的存储的key的数量,降低B+ 树的高度2. B+ 树叶子节点的关键字从小到大有序排列,左边结尾数据都会保存右边节点开始数据的指针3. B+树的层级更少:相较于 B 树 B+每个非叶子节点存储的关键字数更多,树的层级更少所以查询数据更快4. B+ 树查询速度更稳定:B+ 所有关键字数据地址都存在叶子节点上,所以每次查找的次数都相同所以查询速度要比B树更稳定5. B+ 树天然具备排序功能:B+ 树所有的叶子节点数据构成了一个有序链表,在查询大小区间的数据时候更方便,数据紧密性很高,缓存的命中率也会比B树高6. B+ 树全节点遍历更快:B+ 树遍历整棵树只需要遍历所有的叶子节点即可,,而不需要像 B 树一样需要对每一层进行遍历,这有利于数据库做全表扫描。<a name="OK16x"></a>### 索引设计原则1. 对查询频次较高,且数据量比较大的表建立索引2. 索引字段的选择,**最佳候选列应当从where子句的条件中提取**,如果where子句中的组合比较多,那么应当挑选最常用、过滤效果最好的列的组合3. 使用唯一索引,区分度越高,使用索引的效率越高4. 索引可以有效的提升查询数据的效率,但索引数量不是多多益善1. 索引越多,维护索引的代价自然也就水涨船高。对于插入、更新、删除等DML操作比较频繁的表来说,索引过多,会引入相当高的维护代价,降低DML操作的效率,增加相应操作的时间消耗。2. 另外索引过多的话,MySQL也会犯选择困难病,虽然最终仍然会找到一个可用的索引,但无疑提高了选择的代价5. 使用短索引,索引创建之后也是使用硬盘来存储的,因此提升索引访问的I/O效率,也可以提升总体的访问效率。假如**构成索引的字段总长度比较短,那么在给定大小的存储块内可以存储更多的索引值**,相应的可以有效的提升MySQL访问索引的I/O效率6. 利用最左前缀,N个列组合而成的组合索引,那么相当于是创建了N个索引,如果查询时where子句中使用了组成该索引的前几个字段,那么这条查询SQL可以利用组合索引来提升查询效率```sql创建复合索引:CREATE INDEX idx_name_email_status ON tb_seller(NAME, email, STATUS);就相当于对name创建索引对name、email创建了索引对name、email、status创建了索引
前缀索引
对文本的前几个字符建立索引(具体是几个字符在建立索引时去指定),比如以产品名称的前 10 位来建索引,这样建立起来的索引更小,查询效率更快
一般来说,当某个字段的数据量太大,而且查询又非常的频繁时,使用前缀索引能有效的减小索引文件的大小,让每个索引页可以保存更多的索引值,从而提高了索引查询的速度。
比如,客户店铺名称,有的名称很长,有的很短,如果完全按照全覆盖来建索引,索引的存储空间可能会非常的大,有的表如果索引创建的很多,甚至会出现索引存储的空间都比数据表的存储空间大很多,因此对于这种文本很长的字段,我们可以截取前几个字符来建索引,在一定程度上,既能满足数据的查询效率要求,又能节省索引存储空间。
但是另一方面,前缀索引也有它的缺点,MySQL 中无法使用前缀索引进行 ORDER BY 和 GROUP BY,也无法用来进行覆盖扫描,当字符串本身可能比较长,而且前几个字符完全相同,这个时候前缀索引的优势已经不明显了,就没有创建前缀索引的必要了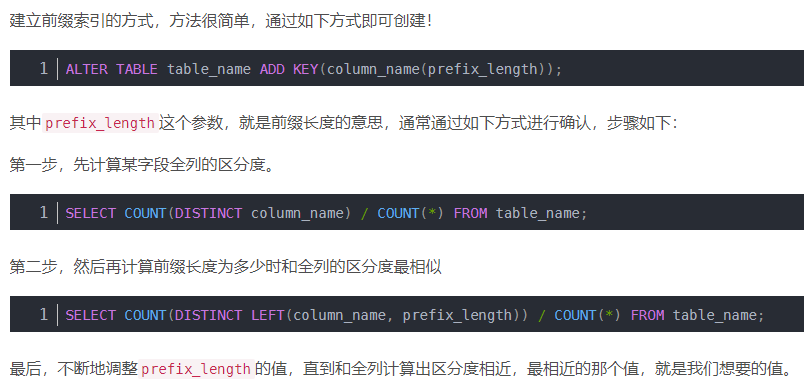
https://blog.csdn.net/dxflqm_pz/article/details/127125151
索引失效的场景
- 违法最左前缀法则,索引失效

- 范围查询右边的列,不能使用索引
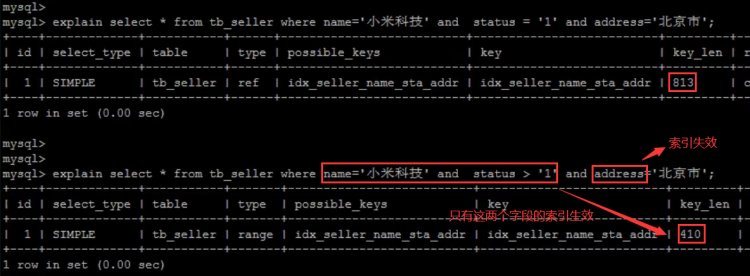
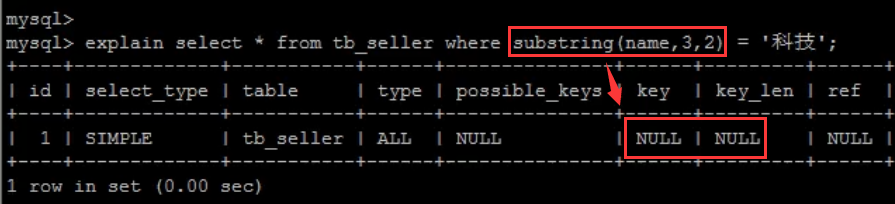
- 不要在索引列上进行运算操作,索引将失效
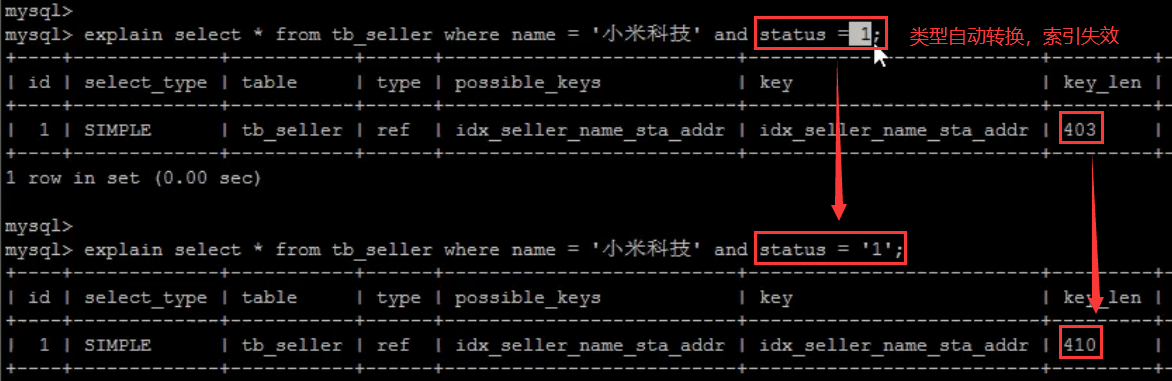
- 字符串不加单引号,MySQL的查询优化器,会自动的进行类型转换,造成索引失效
- 尽量使用覆盖索引,避免select *
- 用or连接查询条件,后面的列没有索引,会导致整个索引失效
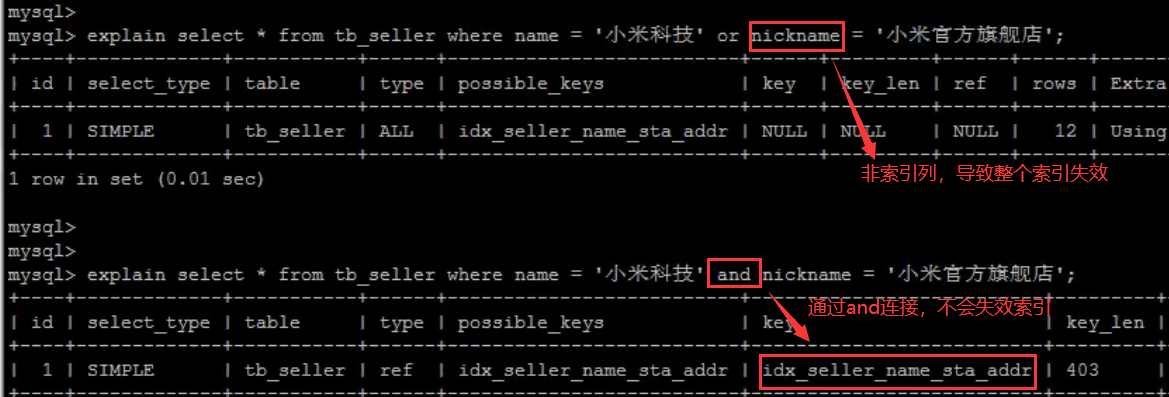
- 以%开头的Like模糊查询,索引失效
- 如果仅仅是尾部模糊匹配,索引不会失效;如果是头部模糊匹配,索引失效
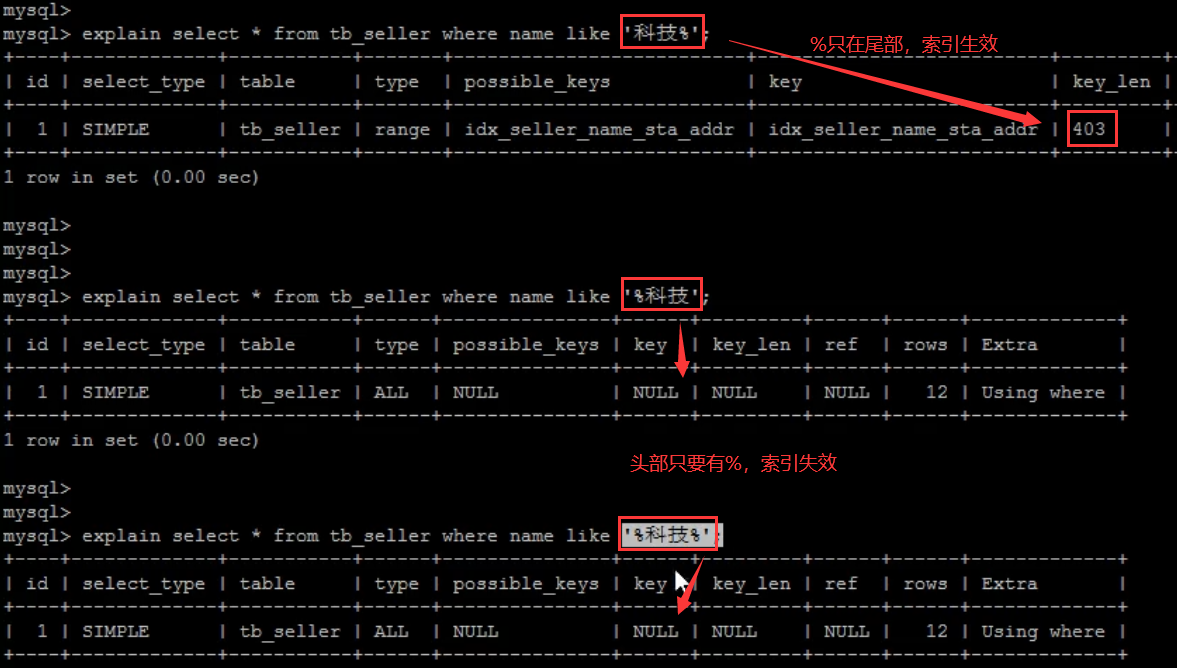
- is NULL,is NOT NULL有时索引失效
- 跟数据库中null值多少有关,若null值较多,is null不走索引(全表扫描),is not null走索引。反之亦然
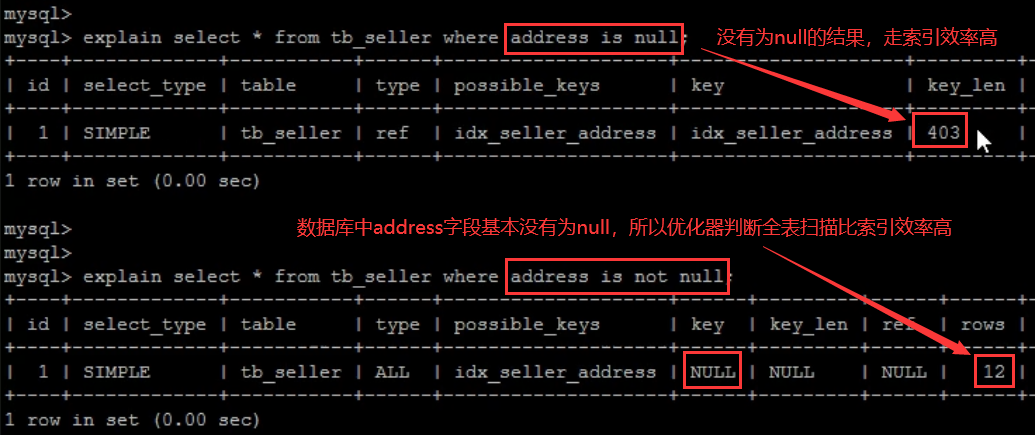
- in 走索引、not in索引失效
-
SQL优化
https://www.yuque.com/fangniudexingxing-uymcu/wxedug/bpm7g3#c3tqb
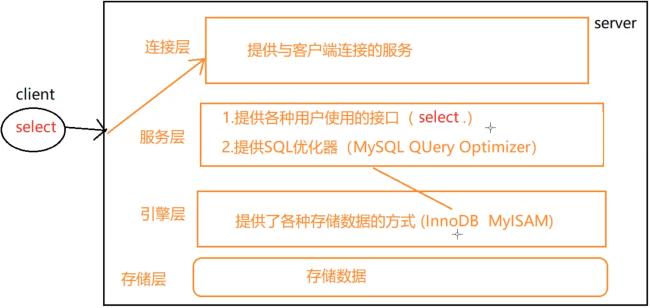
数据库架构
Mysql的软件架构
存储引擎
存储引擎就是存储数据,建立索引,更新查询数据等等技术的实现方式 。存储引擎是基于表的,而不是基于库的。所以存储引擎也可被称为表类型
查看Mysql数据库默认的存储引擎:show variables like '%storage_engine%';
| 特点 | InnoDB | MyISAM | MEMORY | MERGE | NDB | | —- | —- | —- | —- | —- | —- | | 存储限制 | 64TB | 有 | 有 | 没有 | 有 | | 事务安全 | 支持 | 不支持 |
|
|
| | 锁机制 | 行锁(适合高并发) | 表锁 | 表锁 | 表锁 | 行锁 | | B树索引 | 支持 | 支持 | 支持 | 支持 | 支持 | | 全文索引 | 支持(5.6版本之后) | 支持 |
|
|
| | 批量插入速度 | 低 | 高 | 高 | 高 | 高 | | 支持外键 | 支持(唯一支付外键的存储引擎) |
|
|
|
| InnoDB存储引擎提供了具有提交、回滚、崩溃恢复能力的事务安全。但是对比MyISAM的存储引擎,InnoDB写的处理效率差一些,并且会占用更多的磁盘空间以保留数据和索引
- MyISAM:如果应用是以读操作和插入操作为主,只有很少的更新和删除操作,并且对事务的完整性、并发性要求不是很高,那么选择这个存储引擎是非常合适的。
- MEMORY表通常用于更新不太频繁的小表,用以快速得到访问结果。默认使用HASH索引,但是服务一旦关闭,表中的数据就会丢失
MERGE存储引擎是一组MyISAM表的组合,这些MyISAM表必须结构完全相同,MERGE表本身并没有存储数据,对MERGE类型的表可以进行查询、更新、删除操作,这些操作实际上是对内部的MyISAM表进行的
数据库主从架构
https://blog.csdn.net/qq_43665821/article/details/123879509
数据库主库对外提供读写操作,从库对外提供读操作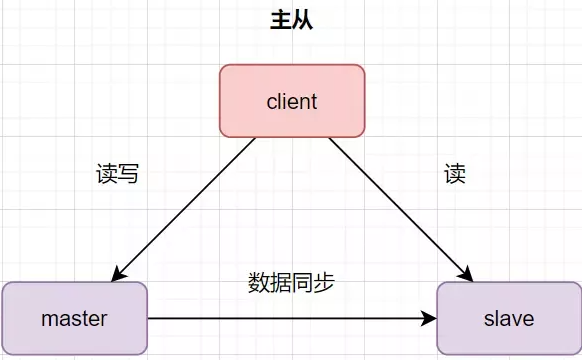
主从复制原理
主数据库有个 binlog 二进制文件,记录了所有增删改的 SQL 语句(binlog 线程)
- 从数据库把主数据库的 binlog 文件的 SQL 语句复制到自己的中继日志 relay log 中(I/O 线程)
- 从数据库的 relay log 重做日志文件,再执行一次这些 SQL 语句(SQL 执行线程)
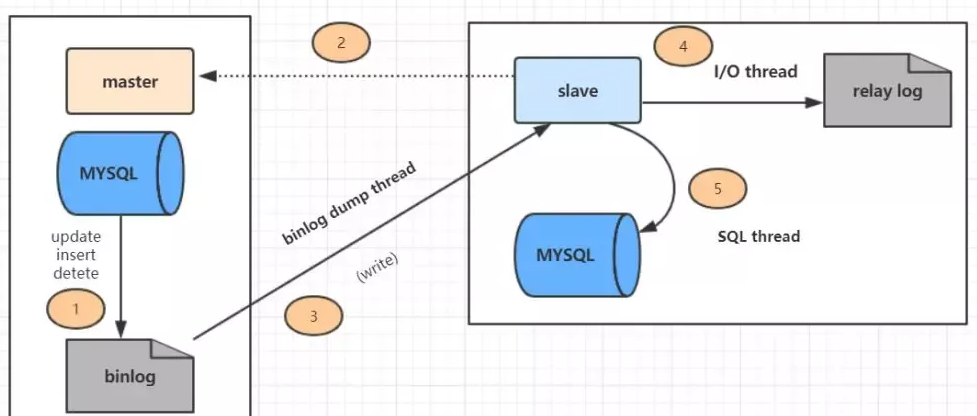
- 主库的更新 SQL(update、insert、delete)被写到 binlog
- 从库发起连接,连接到主库
- 此时主库创建一个 binlog dump thread,把 binlog 的内容发送到从库
- 从库启动之后,创建一个 I/O 线程,读取主库传过来的 binlog 内容并写入到 relay log
从库还会创建一个 SQL 线程,从 relay log 里面读取内容,从 ExecMasterLog_Pos 位置开始执行读取到的更新事件,将更新内容写入 slave 的 db 中
MySQL是怎么保证主从一致的
答案是:长连接
主库和从库在同步数据的过程中为了防止中断导致数据丢失,主库与从库之间维持了一个长连接,主库内部有一个线程,专门服务于从库的这个长连接案例题
筛选出每个小时的记录
- 一个数据库sql查询重复个数
- 查询每门科目都大于80分的学生名字
- 拷贝A表的数据到B表
- 取一个月内的id分组
- 取一个年级中每个班级年龄最小的同学名字
- 成绩表输出前三名的成绩、输出后三名的成绩
- (多次)查询速度慢的原因,如何解决
一个日志表,字段是用户id、视频id、日期、观看开始时间、观看结束时间,找到观看不同视频次数前5名的用户,注意同一个视频多次观看只算一次
其他
死锁四个条件
- 互斥:一个资源只能被一个进程(事务)使用
- 请求与条件保持:一个进程(事务)在等待请求的资源过程中,自身已经占有的资源不可释放
- 不剥夺条件:进程(事务)在运行活跃时候,已经获得的资源未使用完之前,不可强行剥夺
- 循环等待条件:若干个进程(事务)形成首尾相接的循环等待关系
- 一般来说业务基本上就是对商品进行新增、修改和查询等操作,我们在对商品进行新增操作前,先通过select … for update操作进行查询,然后再进行相应的业务逻辑处理,所以当业务量很大时,就有可能出现死锁。
- 三大范式
- 第一范式:确保每列保持原子性
- 第二范式:确保表中的每列都和主键相关
- 第三范式:确保每列都和主键列直接相关,而不是间接相关

- 端口号
- MySQL端口号:3306,可以编辑用户目录下的 .my.cnf文件进行修改
- MongoDb端口号:27017
- Redis端口号:6379
- 查询MySQL日志
配置二进制日志的格式
binlog_format=STATEMENT
2. 在my.ini,指定数据目录:log-bin=E:/mysql_log_bin3. **查询日志**1. 默认情况下是没有开启的```sql# 该选项用来开启查询日志,可选值: 0 或者 1 ; 0 代表关闭, 1 代表开启general_log=1# 设置日志的文件名,如果没有指定,默认的文件名为 host_name.loggeneral_log_file=file_name
2. 在my.ini,指定数据目录:log=E:/mysql_log.txt
- 慢查询日志
该参数用来指定慢查询日志的文件名
slow_query_log_file=slow_query.log
该选项用来配置查询的时间限制,超过这个时间将认为值慢查询,将需要进行日志记录,默认10s
long_query_time=2
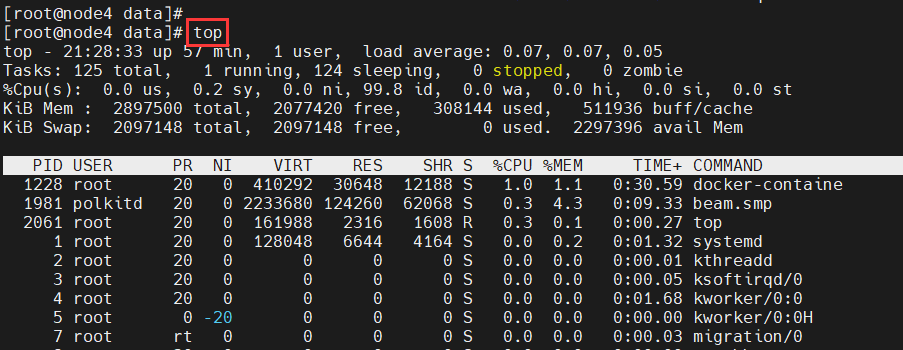
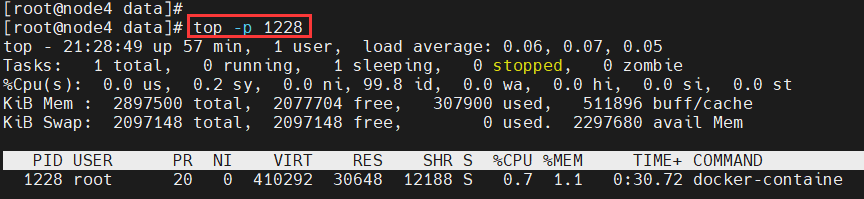
<a name="ZRfHz"></a># Linux<a name="iuumV"></a>## 常见命令<a name="QOFG3"></a>### 查看进程1. **top:动态查看进程变化,监控linux的系统状况**```shell# 观察cpu、内存、进程使用情况。动态查看进程变化,监控linux的系统状况[root@node4 data]# top# 查看指定进程id的top信息[root@node4 data]# top-p 1228# 查看指定进程id的所有线程的top信息[root@node4 data]# top -H -p 1228
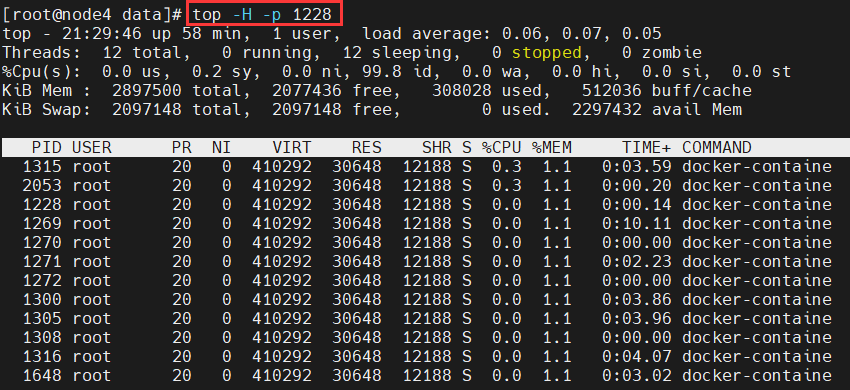
- ps -ef:用于查看全格式的全部进程
- -e:参数代表显示所有进程
- -f:参数代表全格式
- 查看指定进程:ps -ef | grep pid
- ps -aux也是用于查看进程
- -a:显示当前终端下的所有进程信息,包括其他用户的进程
- -u:使用以用户为主的格式输出进程信息
- -x:显示当前用户在所有终端下的进程
- ps -ef和ps aux,这两者的输出结果差别不大,但展示风格不同,COMMADN列如果过长,aux会截断显示,而ef不会
- 如果想查看进程的CPU占用率和内存占用率,可以使用aux,如果想查看进程的父进程ID和完整的COMMAND命令,可以使用ef

linux的进程有5种状态:
- (R)运行状态(正在运行或在运行队列中等待[就绪队列])
- (S)中断状态(休眠中,受阻,在等待某个条件的形成或接受到信号)
- (D)不可中断状态(收到信号不唤醒和不可运行, 进程必须等待直到有中断发生)
- (Z)僵死状态(进程已终止,但进程描述符存在,直到父进程调用wait4()系统调用后释放)
- (T)停止状态(进程收到SIGSTOP、SIGSTP、SIGTIN、SIGTOU信号后停止运行运行)
查看文件大小
```sql查看磁盘空间
[root@node4 data]# df -h 文件系统 容量 已用 可用 已用% 挂载点 /dev/mapper/centos-root 47G 5.6G 42G 12% / devtmpfs 1.4G 0 1.4G 0% /dev tmpfs 1.4G 0 1.4G 0% /dev/shm tmpfs 1.4G 9.5M 1.4G 1% /run tmpfs 1.4G 0 1.4G 0% /sys/fs/cgroup /dev/sda1 1014M 145M 870M 15% /boot tmpfs 283M 0 283M 0% /run/user/0
查看文件大小
[root@node4 data]# ll 总用量 32 -rw-r—r—. 1 root root 166 11月 13 17:46 chaoge.txt -rw-r—r—. 1 root root 142 11月 13 12:38 luffycity1.txt -rw-r—r—. 1 root root 298 11月 13 17:24 luffycity.tx -rw-r—r—. 1 root root 152 11月 12 14:51 luffy.txt -rw-r—r—. 1 root root 1134 11月 12 14:35 pwd.txt -rw-r—r—. 1 root root 38 11月 12 18:56 test1.txt -rw-r—r—. 1 root root 31 11月 12 18:24 test.tx -rw-r—r—. 1 root root 52 11月 12 18:35 test.txt [root@node4 data]# [root@node4 data]# ls -lh pwd.txt -rw-r—r—. 1 root root 1.2K 11月 12 14:35 pwd.txt [root@node4 data]# [root@node4 data]# du -h pwd.txt 4.0K pwd.txt [root@node4 data]# wc -c pwd.txt 1134 pwd.txt
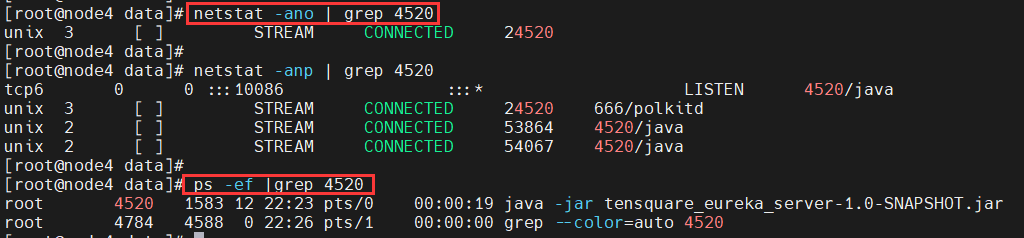
<a name="KyIqm"></a>### 查找文件1. 打印当前文件夹文件 ls -al a所有文件 l详细信息2. 软链接 ln -s a target 硬链接 ln3. 修改权限 chmod4. 查看文件:5. 移动文件mv 也可以重命名6. 复制文件cp7. 删除文件 rm -r 递归删除 -f删除只读文件 通配符?单个字符,*多个字符,[a-z]字符集8. grep 正则搜索 显示行号-n 查询个数-c 反选-v9. 查看指定进程 ps -ef | grep pid10. 查看命令历史 history11. 查找文件 find [目录] 以名字查找-name “h*”以h开头12. 终止一个进程 kill -9 pid13. 如何防止新人误操作rm -rf1. 做好备份2. 建立回收站机制3. 使用safe-rm替代rm14. 24.156.192.2/24 一共有多少个主机号15. 找进程号为199的进程 ls -ef|grep 19916. 某文件中含关键词的行数 grep -c "key" ./file17. 常用Linux命令(特意问了find命令)18. 该目录下以.log结尾的文件中包含关键词a但不包含关键词b的行数 grep "a" ./file | grep -cv "b"19. grep命令20. Linux管道是什么?用法?21. 说下自己知道的命令;给了一个a.log文件,从里面找出以error开头的;查看某一个进程;查看某一个端口号22. Linux命令:chmod命令,改变文件所有者命令是什么(chown),重定向符,怎么把标准输出和错误分别重定向到两个文件23. 如何查看端口被占了(netstat/ps)```shell[root@node4 data]# netstat -anp | grep 4520tcp6 0 0 :::10086 :::* LISTEN 4520/javaunix 3 [ ] STREAM CONNECTED 24520 666/polkitdunix 2 [ ] STREAM CONNECTED 53864 4520/javaunix 2 [ ] STREAM CONNECTED 54067 4520/java[root@node4 data]#[root@node4 data]# ps -ef |grep 4520root 4520 1583 12 22:23 pts/0 00:00:19 java -jar tensquare_eureka_server-1.0-SNAPSHOT.jarroot 4784 4588 0 22:26 pts/1 00:00:00 grep --color=auto 4520
- 查找当前目录下有多少个文件 ```sql [root@node4 data]# ll 总用量 48 -rw-r—r—. 1 root root 166 11月 13 17:46 chaoge.txt drwxr-xr-x. 2 root root 19 11月 18 20:56 data1 -rw-r—r—. 1 root root 142 11月 13 12:38 luffycity1.txt -rw-r—r—. 1 root root 298 11月 13 17:24 luffycity.tx -rw-r—r—. 1 root root 152 11月 12 14:51 luffy.txt -rw-r—r—. 1 root root 1134 11月 12 14:35 pwd.txt -rw-r—r—. 1 root root 16371 11月 3 2014 safe-rm-0.12.tar.gz -rw-r—r—. 1 root root 38 11月 12 18:56 test1.txt -rw-r—r—. 1 root root 31 11月 12 18:24 test.tx -rw-r—r—. 1 root root 52 11月 12 18:35 test.txt [root@node4 data]# [root@node4 data]# cd data1/ [root@node4 data1]# ll 总用量 0 -rw-r—r—. 1 root root 0 11月 18 20:56 tset1
统计当前目录下文件的个数(不包括目录)
[root@node4 data]# ls -l | grep “^-“ | wc -l 9
统计当前目录下文件的个数(包括子目录)
[root@node4 data]# ls -lR| grep “^-“ | wc -l 10
查看某目录下文件夹(目录)的个数(包括子目录)
[root@node4 data]# ls -lR | grep “^d” | wc -l 1
25. Linux命令:查找统计某一目录下所有.txt文件中某一字符的个数26. Linux命令:查找并删除目录下的某一堆进程怎么做?27. kill后面的参数你了解吗?28. 关闭一个进程指令 kill -9/15 进程号29. 查看一个文档的后100行 tail -n 100 文件名30. 查找带有“txt”的名称,并根据找到的内容进一步查找 find "%txt%" | grep "%txtt"31. linux 添加alias命令,alias在哪里配的?32. 什么是软链接、硬链接33. 文件中多行文字进行去重,展示去重之后的内容```shell[root@node4 data]# cat chaoge.txtpyyu1 pyyu2 pyyu3 pyyu4 pyyu5pyyu6 pyyu7 pyyu8 pyyu9 pyyu10pyyu1 pyyu2 pyyu3 pyyu4 pyyu5pyyu21 pyyu22 pyyu23 pyyu5 pyyu25# 去重后顺序乱了[root@node4 data]# cat chaoge.txt | sort | uniqpyyu1 pyyu2 pyyu3 pyyu4 pyyu5pyyu21 pyyu22 pyyu23 pyyu5 pyyu25pyyu6 pyyu7 pyyu8 pyyu9 pyyu10[root@node4 data]# cat chaoge.txtpyyu1 pyyu2 pyyu3 pyyu4 pyyu5pyyu6 pyyu7 pyyu8 pyyu9 pyyu10pyyu1 pyyu2 pyyu3 pyyu4 pyyu5pyyu21 pyyu22 pyyu23 pyyu5 pyyu25[root@node4 data]# awk '!x[$0]++' chaoge.txtpyyu1 pyyu2 pyyu3 pyyu4 pyyu5pyyu6 pyyu7 pyyu8 pyyu9 pyyu10pyyu21 pyyu22 pyyu23 pyyu5 pyyu25
- 查询当前目录下包含error的日志
- Linux lnap lamp区别
- Apache和Nginx区别
- 怎么查看服务器上Nginx状态
- PS怎么查看Nginx
- error.log 文件,找到包含error的信息的命令 把这个语句说出来
- vim的全局替换
- linux远程复制
- 查看端口是否被占用:netstat -anp |grep 端口号

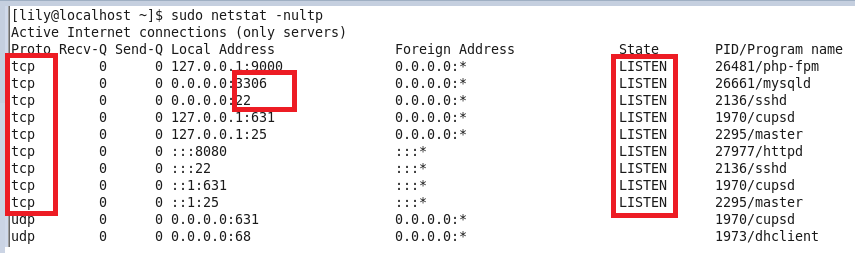
- 查看当前所有已经使用的端口情况:netstat -nultp(此处不用加端口号)
文件和目录
Linux权限管理
智力题
- 一根金条,需要一周每天都发工资,切割两次,请问怎么切割 把金条切分为1/7, 2/7, 4/7,每天找零
- 100个足球队两两比赛角逐出一支冠军队伍,请问至少比赛几次 每场比赛淘汰一只队伍,所以需要99场比赛
- 25匹马5个赛道,求前三名
- 100个豆子,五个囚犯,拿的豆子最多或者最少都要被处死,求谁的生存概率大一点
- 给你两根绳子,燃烧完其中一根是一个小时,怎样得到15分钟
- 有6个数字,每个数字都包含6,所有数字之和是否能为100?1000呢?

若有收获,就点个赞吧
0 人点赞
