小样本学习简介
预训练语言模型的参数空间比较大,如果在下游任务上直接对这些模型进行微调,为了达到较好的模型泛化性,需要较多的训练数据。在实际业务场景中,特别是垂直领域、特定行业中,训练样本数量不足的问题广泛存在,极大地影响这些模型在下游任务的准确度,因此,预训练语言模型学习到的大量知识无法充分地发挥出来。EasyNLP框架支持多种小样本学习算法,实现基于预训练语言模型的小样本数据调优,从而解决大模型与小训练集不相匹配的问题。
小样本学习算法概述
PET算法
小样本学习算法从2020年GPT3的论文“Language Models are Few-Shot Learners”(LM-BFF)问世后,成为了NLP研究领域的热门话题。近一年来,涌现了许多基于提示的微调方法,这些方法的核心在于将下游分类任务从用[CLS] Head 做分类,转化为与预训练过程类似的MLM任务,从而保留预训练模型的MLM head,相比于传统微调更多地保留模型在预训练阶段学习的信息。基于提示的微调方法也证明在SuperGLUE、FewCLUE等榜单的小样本任务上效果大大优于传统微调。 在基于提示的微调算法,例如Pattern-Exploiting Training(PET)中,主要需要设计两个关键元素:模版(Prompt)和标签词(Verbalizer)。模版通过一些提示语,将经典的分类任务转化为MLM任务,即将任务转化为预测提示语中[MASK]对应的词是什么。标签词给出了[MASK]的预测结果到真实类别的映射关系。下图以影评情感分类为例,展示了模版和标签词在这一方法中的作用:
P-Tuning算法
基于提示的微调算法的难点在于设计足够好的模版和标签词。在现有的算法中,LM-BFF、PET等算法需要通过搜索或人工给定的形式,制定任务相关的模版和标签词。这一过程费时费力,而且算法的实际效果受到不同模版和标签词的组合影响较大。为了解决这一问题,P-tuning等算法解决了模版的自动化搜索问题,采用连续性的Prompt Embedding作为模板,使得在模型的训练时无需指定模板,其架构如下所示: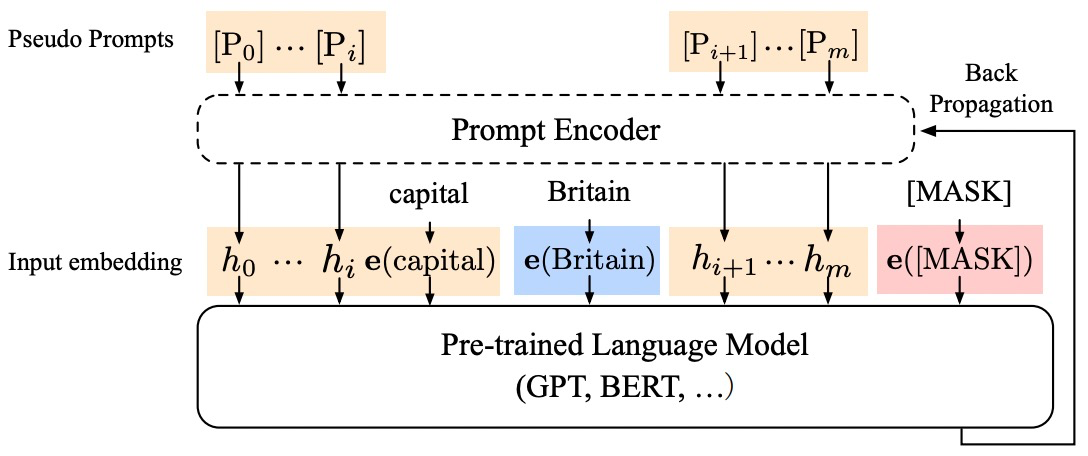
在EasyNLP框架中,为了模型训练的简便性,框架支持直接使用用连续性的Prompt Embedding作为模板进行小样本学习训练,避免学习Prompt Encoder的参数。
自研CP-Tuning算法
此外,结合经典的基于提示的微调算法和P-tuning算法的优点,同时基于对比学习的思路,EasyNLP框架中提成了基于对比学习的小样本学习算法CP-Tuning(Contrastive Prompt Tuning)。这一算法的核心框架图如下所示:
如上图,CPT算法放弃了经典算法中以“[MASK]”字符对应预训练模型MLM Head的预测输出作为分类依据,而是参考对比学习的思路,将句子通过预训练模型后,以“[MASK]”字符通过预训练模型后的连续化表征作为features。在小样本任务的训练阶段,训练目标为最小化同类样本features的组内距离,最大化非同类样本的组间距离。在上图中,[OMSK]即为我们所用于分类的“[MASK]”字符,其优化的features表示为[EMB]。因此,CPT算法不需要定义分类的标签词。在输入侧,除了输入文本和[OMSK],我们还加入了模版的字符[PRO]。除此之外,CPT还引入了输入文本的Mask,表示为[TMSK],用于同时优化辅助的MLM任务,提升模型在小样本学习场景下的泛化性。CPT算法的损失函数由两部分组成:
分别为基于对比学习的Pair-wise Cost-sensitive Contrastive Loss(PCCL)和辅助的MLM损失。
完整流程示例
环境准备
设置环境变量,并且下载示例数据集。
WORKER_COUNT=1WORKER_GPU=1if [ ! -f ./fewshot_train.tsv ]; thenwget https://atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com/release/tutorials/fewshot_learning/fewshot_train.tsvfiif [ ! -f ./fewshot_dev.tsv ]; thenwget https://atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com/release/tutorials/fewshot_learning/fewshot_dev.tsvfi
PET算法的训练与预测
在调用小样本算法时,需要给定参数enable_fewshot=True,调用PET算法时需要指定type=pet_fewshot。
echo '=========[ Fewshot Training: PET on Text Classification ]========='easynlp \--app_name=text_classify \--mode=train \--worker_count=${WORKER_COUNT} \--worker_gpu=${WORKER_GPU} \--tables=./fewshot_train.tsv,./fewshot_dev.tsv \--input_schema=sid:str:1,sent1:str:1,sent2:str:1,label:str:1 \--first_sequence=sent1 \--second_sequence=sent2 \--label_name=label \--label_enumerate_values=0,1 \--checkpoint_dir=./fewshot_model/ \--learning_rate=1e-5 \--epoch_num=1 \--random_seed=42 \--save_checkpoint_steps=100 \--sequence_length=512 \--micro_batch_size=8 \--user_defined_parameters="pretrain_model_name_or_path=hfl/chinese-roberta-wwm-extenable_fewshot=Truelabel_desc=否,能type=pet_fewshotpattern=sent1,label,用,sent2,概括。"echo '=========[ Fewshot Prediction: PET on Text Classification ]========='easynlp \--app_name=text_classify \--mode=predict \--worker_count=${WORKER_COUNT} \--worker_gpu=${WORKER_GPU} \--tables=./fewshot_train.tsv \--outputs=pred.tsv \--output_schema=predictions \--input_schema=sid:str:1,sent1:str:1,sent2:str:1,label:str:1 \--worker_count=1 \--worker_gpu=1 \--first_sequence=sent1 \--second_sequence=sent2 \--label_name=label \--append_cols=sid,label \--label_enumerate_values=0,1 \--checkpoint_dir=./fewshot_model/ \--micro_batch_size=8 \--sequence_length=512 \--user_defined_parameters="enable_fewshot=Truelabel_desc=否,能type=pet_fewshotpattern=sent1,label,用,sent2,概括。"
P-Tuning算法的训练与预测
echo '=========[ Fewshot Training: P-tuning on Text Classification ]========='easynlp \--app_name=text_classify \--mode=train \--worker_count=${WORKER_COUNT} \--worker_gpu=${WORKER_GPU} \--tables=./fewshot_train.tsv,./fewshot_dev.tsv \--input_schema=sid:str:1,sent1:str:1,sent2:str:1,label:str:1 \--first_sequence=sent1 \--second_sequence=sent2 \--label_name=label \--label_enumerate_values=0,1 \--checkpoint_dir=./fewshot_model/ \--learning_rate=1e-5 \--epoch_num=1 \--random_seed=42 \--save_checkpoint_steps=100 \--sequence_length=512 \--micro_batch_size=8 \--user_defined_parameters="pretrain_model_name_or_path=hfl/chinese-roberta-wwm-extenable_fewshot=Truelabel_desc=否,能type=pet_fewshotpattern=sent1,<pseudo>,label,<pseudo>,sent2"echo '=========[ Fewshot Prediction: P-tuning on Text Classification ]========='easynlp \--app_name=text_classify \--mode=predict \--worker_count=${WORKER_COUNT} \--worker_gpu=${WORKER_GPU} \--tables=./fewshot_train.tsv \--outputs=pred.tsv \--output_schema=predictions \--input_schema=sid:str:1,sent1:str:1,sent2:str:1,label:str:1 \--worker_count=1 \--worker_gpu=1 \--first_sequence=sent1 \--second_sequence=sent2 \--label_name=label \--append_cols=sid,label \--label_enumerate_values=0,1 \--checkpoint_dir=./fewshot_model/ \--micro_batch_size=8 \--sequence_length=512 \--user_defined_parameters="enable_fewshot=Truelabel_desc=否,能type=pet_fewshotpattern=sent1,<pseudo>,label,<pseudo>,sent2"
值得注意的是,P-Tuning算法与PET算法使用同样的算法入口(即type=pet_fewshot),采用
CP-Tuning算法的训练与预测
echo '=========[ Fewshot Training: CP-Tuning on Text Classification ]========='
easynlp \
--app_name=text_classify \
--mode=train \
--worker_count=${WORKER_COUNT} \
--worker_gpu=${WORKER_GPU} \
--tables=./fewshot_train.tsv,./fewshot_dev.tsv \
--input_schema=sid:str:1,sent1:str:1,sent2:str:1,label:str:1 \
--first_sequence=sent1 \
--second_sequence=sent2 \
--label_name=label \
--label_enumerate_values=0,1 \
--checkpoint_dir=./fewshot_model/ \
--learning_rate=1e-5 \
--epoch_num=1 \
--random_seed=42 \
--save_checkpoint_steps=100 \
--sequence_length=512 \
--micro_batch_size=8 \
--user_defined_parameters="
pretrain_model_name_or_path=hfl/chinese-roberta-wwm-ext
enable_fewshot=True
type=cpt_fewshot
pattern=sent1,label,用,sent2,概括。
"
echo '=========[ Fewshot Prediction: CP-Tuning on Text Classification ]========='
easynlp \
--app_name=text_classify \
--mode=predict \
--worker_count=${WORKER_COUNT} \
--worker_gpu=${WORKER_GPU} \
--tables=./fewshot_train.tsv \
--outputs=pred.tsv \
--output_schema=predictions \
--input_schema=sid:str:1,sent1:str:1,sent2:str:1,label:str:1 \
--worker_count=1 \
--worker_gpu=1 \
--first_sequence=sent1 \
--second_sequence=sent2 \
--label_name=label \
--append_cols=sid,label \
--label_enumerate_values=0,1 \
--checkpoint_dir=./fewshot_model/ \
--micro_batch_size=8 \
--sequence_length=512 \
--user_defined_parameters="
enable_fewshot=True
type=cpt_fewshot
pattern=sent1,label,用,sent2,概括。
"
CP-Tuning算法在调用时需要指定type=cpt_fewshot,并且无需填写label_desc参数。

若有收获,就点个赞吧
0 人点赞
