EasyNLP提供常见的中文数据集的下载,同时提供如下接口加载和处理中文数据。
使用DataHub数据进行训练
对于已经过huggingface或easynlp预处理的数据,您可以直接使用以下方式加载与训练:
from easynlp.core import Trainerfrom easynlp.appzoo import GeneralDataset, SequenceClassification, load_datasetfrom easynlp.utils import initialize_easynlpargs = initialize_easynlp()row_data = load_dataset('clue', 'afqmc')["train"]train_dataset = GeneralDataset(dataset, args.pretrained_model_name_or_path, args.sequence_length)model = SequenceClassification(pretrained_model_name_or_path=args.pretrained_model_name_or_path)Trainer(model=model, train_dataset=train_dataset).train()
对于新的数据集,您可以使用下面方式加载(以文本分类为例):
from easynlp.core import Trainerfrom easynlp.appzoo import ClassificationDataset, SequenceClassificationfrom easynlp.utils import initialize_easynlpargs = initialize_easynlp()train_dataset = ClassificationDataset(pretrained_model_name_or_path=args.pretrained_model_name_or_path,data_file=args.tables,max_seq_length=args.sequence_length,input_schema=args.input_schema,first_sequence=args.first_sequence,label_name=args.label_name,label_enumerate_values=args.label_enumerate_values,is_training=True)model = SequenceClassification(pretrained_model_name_or_path=args.pretrained_model_name_or_path)Trainer(model=model, train_dataset=train_dataset).train()
具体的例子详见quick start。
预训练数据
| 数据 | 描述 | 数据格式 |
|---|---|---|
| Wudao(中文)(链接) | 5900万文本数据 | json格式,包括Topic(标题),Text(正文) |
| WuDaoMM-base(链接) | WuDao大数据的一个子数据集,共500万图文对。支持了文澜、Cogview 等中文多模态预训练) | json格式,数据包含19个大类,分别为:能源、表情、工业、医疗、风景、动物、新闻、花卉、教育、艺术、人物、科学、大海、树木、汽车、社交、科技、运动等,单类别数据约7万~40万左右。每个json文件包括name,tag,图片url,和captions。 |
| CLUE-news2016(直接下载) | CLUE社区收集的250万篇新闻,含关键词和描述 | 8G新闻语料,分成两个上下两部分,总共有2000个小文件 |
| CLUE-webText2019(直接下载) | CLUE社区收集的419万个高质量社区问答,适合训练通用预训练模型或者问答模型 | 社区互动3G语料,包含3G文本,总共有900多个小文件 |
| CLUE-wiki2019(直接下载) | CLUE社区的维基百科语料,104万个结构良好的中文词条 | 1.1G左右文本,包含300左右小文件 |
| CLUE-baike2018qa(直接下载) | CLUE社区收集的百科问答数据,150万个问答数据,包括问答数据和问题类型。数据集划分:数据去重并分成三个部分。训练集:142.5万;验证集:4.5万,测试集无。 | 含有150万个预先过滤过的、高质量问题和答案,每个问题属于一个类别。总共有492个类别,其中频率达到或超过10次的类别有434个。 |
| CLUE-translation2019(直接下载) | CLUE社区收集的中文机器翻译数据,520万个中英文句子对。数据集划分:数据去重并分成三个部分。训练集:516万;验证集:3.9万 | 每一个对,包含一个英文和对应的中文。中文或英文,多数情况是一句带标点符号的完整的话。对于一个平行的中英文对,中文平均有36个字,英文平均有19个单词 |
| 互联网图片库2.0(SogouP2.0)(链接) | 来自搜狗识图搜http://pic.sogou.com/shitu/index.html 索引的部分数据。其中收集了包括人物、动物、建筑、机械、风景、运动等类别,总数高达1000万张图片。图片库还包括了一个识图搜索结果人工标注集合,用于训练和评测。 |
共包括三个文件:Meta_Data,Original_Pic,Evaluation_Data。其中Meta_Data存储图片的相关元数据;Original_Pic中存储图片的原图;Evaluation_Data是识图搜索结果的人工标注集合。对于每张图片,搜狗给出了图片的原图文件、图片的URL、图片所在网页的URL、图片所在网页中的Surrounding Text文本、同主题系列图片等信息。 |
通用NLU数据
| 数据 | 描述 | 数据格式 |
|---|---|---|
| AFQMC (直接下载) | 蚂蚁金融语义相似度 数据量:训练集(34334)验证集(4316)测试集(3861) | 任务:文本分类, json格式,包括句子1,句子2,和标签,样例:{“sentence1”: “xxx”, “sentence2”: “xxx”, “label”: “0”} |
| TNEWS1.1 id: clue/tnews (直接下载) | 今日头条中文新闻(短文本)分类 数据量:训练集(53,360),验证集(10,000),测试集(10,000) | 任务:文本分类,json格式,包括id,sentence,和label |
| IFLYTEK(直接下载) | 长文本分类 数据量:训练集(12,133),验证集(2,599),测试集(2,600) | json格式,包括分类ID,分类名称,和新闻文本,样例:{“label”: “102”, “label_des”: “news_entertainment”, “sentence”: “xxx”} |
| WSC1.1(直接下载) | 代词消歧 (小样本文本分类)数据量:训练集(1000),验证集(300),测试集(300) | json格式,包括span2_index, span1_index, span2_text, span1_text, id, text (原始文本),span2为原始文本中的指代词,span1为指代的内容 |
| CSL(直接下载) | 论文关键词识别(文本分类)数据量:训练集(20,000),验证集(3,000),测试集(3,000) | json格式,包括id,abst,label, 和keyword,其中label取值为0/1 |
| CMNLI(直接下载) | 语言推断任务 CMNLI数据由两部分组成:XNLI和MNLI。数据来自于fiction,telephone,travel,government,slate等。该数据集可用于判断给定的两个句子之间属于蕴涵、中立、矛盾关系。每一条数据有三个属性 | json格式,包括sentence1,sentence2,和label,其中label标签有三种:neutral,entailment,contradiction |
中文文本匹配/问答数据
| 数据 | 描述 | 数据格式 |
|---|---|---|
| OCNLI_50k(下载链接) | 中文自然语言推理 50k | json域为:level,sentence1, sentence2, label, label0, label1, label2, label3, label4, genre, prem_id, id |
| OCNLI_30k(下载链接) | 中文自然语言推理 30k | json域为:level,sentence1, sentence2, label, label0, label1, label2, label3, label4, genre, prem_id, id |
| QBQTC(下载链接) | QQ浏览器搜索匹配数据 200k data | json域为: id, query, title, label |
| CMNLI(下载链接) | XNLI和MNLI (多领域数据)400k data | json域为: sentence1, sentence2, label |
| cMedQA2(下载链接) | 医疗问答数据 10.8k | 分为正文内容和索引,正文(问题)(问题)格式为csv(question_id, conten回答(ans_id, question_id,content)索引为csv(question_id, ans_id, cnt, lable)t), 回答(ans_id, question_id,content)索引为csv(question_id, ans_id, cnt, lable) |
| CAIL2019相似案例匹配大赛(下载链接) | 文书事实描述匹配数据集 | json域为: A, B,C, label |
| CAIL2019相似案例匹配大赛(下载链接) | 文书事实描述匹配数据集 | json域为: A, B,C, label |
| ChineseTextualInference(下载链接) | 中文文本推断项目,包括88万文本蕴含中文文本蕴含数据集的翻译与构建 | tsv格式,三个域为sentence1,sentence2,label |
| ChineseSTS(下载链接) | STS 中文文本语义相似度语料库建设,相似度为0-5,数值越高相似度越高 | tsv格式,5个域为:index1,sentence1, index2, sentence2, 相似度 |
中文文本分类
| 数据 | 描述 | 数据格式 |
|---|---|---|
| TNEWS1.1 id: clue/tnews | 详见通用NLU任务 | |
| IFLYTEK id: clue/iflytek | 详见通用NLU任务 | |
| AFQMC id: clue/afqmc | 详见通用NLU任务 | |
| WSC1.1 id: clue/wsc | 详见通用NLU任务 | |
| CSL id: clue/csl | 详见通用NLU任务 | |
| tc-corpus-answer id: tc_corpus_answer (直接下载) | 复旦大学计算机信息与技术系国际数据库中心自然语言处理小组,训练9804篇(train),测试9833篇(answer),标签为20个类别 | 压缩包,包括train.rar, answer.rar |
| Sogou-CA(链接) | 数据来自若干新闻站点2012年6月—7月期间国内,国际,体育,社会,娱乐等18个频道的新闻数据 | 压缩包 |
| Sogou-CS(链接) | 数据来源为搜狐新闻2012年6月—7月期间国内,国际,体育,社会,娱乐等18个频道的新闻数据 | 压缩包 |
| online_shopping(直接下载) | 10 个类别,共 6 万多条评论数据,正、负向评论各约 3 万条,包括书籍、平板、手机、水果、洗发水、热水器、蒙牛、衣服、计算机、酒店。来源:SophonPlus | rar格式,10 个类别(书籍、平板、手机、水果、洗发水、热水器、蒙牛、衣服、计算机、酒店),共 6 万多条评论数据,正、负向评论各约 3 万条,包括label和review两个字段 |
| weibo_senti(直接下载) | 10 万多条,带情感标注 新浪微博 | csv格式,正负向评论约各 5 万条 |
| simplifyweibo(直接下载) | 36 万多条,带情感标注 新浪微博 | csv格式,包含 4 种情感,其中喜悦约 20 万条,愤怒、厌恶、低落各约 5 万条 |
| dmsc_v2(直接下载) | 28 部电影,超 70 万 用户,超 200 万条 评分/评论 数据 | csv格式,包含movieid,title,和tile cn,即id和中英文标题 |
| yf_dianping(直接下载) | 24 万家餐馆,54 万用户,440 万条评论/评分数据 | csv格式,包括userid,restid(餐馆id),rating(评分),rating_env(环境评分),rating_flavor(口味评分), rating_service(服务评分), timestamp, commenet |
| yf_amazon(直接下载) | 52 万件商品,1100 多个类目,142 万用户,720 万条评论/评分数据 | csv格式,包括userid,product id, rating, timestamp, title, commenet |
| ChnSentiCorp(直接下载) | 7000 多条酒店评论数据,5000 多条正向评论,2000 多条负向评论,来源:SophonPlus | csv格式,包括label和review两个字段,label包括正向和负向。 数据来源:携程网, 原数据集由谭松波 老师整理的一份数据集 |
| waimai(直接下载) | 某外卖平台收集的用户评价,正向 4000 条,负向 约 8000 条。来源:SophonPlus | csv格式,包括label和review两个字段,label包括正向和负向 |
中文序列标注
| 数据 | 描述 | 数据格式 |
|---|---|---|
| Chinese Treebank(链接) | 词性标注任务 | 每个单词对应的词性信息 |
| ResumeNER(链接) | 中文命名实体标注任务,微博数据构造(ACL2018) | 每个字对应一行,同时包含标签,句子以空行间隔 |
| People’s Daily(链接) | 中文命名实体标注任务,人民日报 | 每个字对应一行,同时包含标签,句子以空行间隔 |
| CNMER(链接) | 中文医学实体识别数据集,实体包括身体部位、症状体征、检查、疾病以及治疗。 | 每个字对应一行,同时包含标签,句子以空行间隔 |
| CCKS2018数据(链接) | 识别疾病和诊断、解剖部位、影像检查、实验室检验、手术和药物6种命名实体 | 例句与标注文件分开 |
| CCKS2019数据(链接) | 识别中文医学命名实体 | json |
| SRL(链接) | 中文语义角色标注任务(OntoNotes Release 5.0一部分) | 需要进一步处理 |
| OntoNotes(链接) | 中文命名实体识别任务 总共 15740 | 有18种命名实体类型;每条sample包含3条数据项:输入文本和标注出来的实体位置和对应的实体类型。 |
| MSRA (链接) | 中文命名实体识别任务 训练集:46675 |
有3种命名实体类型;每条sample包含3条数据项:输入文本和标注出来的实体位置和对应的实体类型。 |
文本生成/摘要数据
| 数据 | 描述 | 数据格式 |
|---|---|---|
| Dureader(链接) | 百度中文阅读理解数据集(改造成:问题生成任务)200,000 问题/1,000,000 文档 | 每条sample包含5个数据项:question:输入的问题;question type:问题类型(yes-no,entity-fact等);answer:问题的对应答案;support sentence:答案在文档中的支持句;document:输入文档 |
| KdConv(链接) | 多领域对话生成任务 总共:4,500对话轮次 | 每条sample包含2条数据项:user1-userN用户的对话记录;knowledge triple:用户对话记录文本中对应识别出来的知识三元组 |
| WMT20-enzh(链接) | 中英文机器翻译任务 | 每条sample包含2条数据项:源语言和目标语言对应的翻译文本。 |
| 教育培训行业摘要数据(直接下载) | 标题生成任务(短文本生成式摘要) 教育培训行业摘要数据是github作者wonderfulsuccess整理,数据主要由教育培训行业主流垂直媒体的历史文章 总数量:24423个样本;摘要:平均字数 52 正文:平均字数 2016 | json格式包括title,content.其中content为新闻正文 title为新闻的标题 |
| lcsts摘要数据(直接下载) | 标题生成任务(短文本生成式摘要) lcsts摘要数据是哈尔滨工业大学整理,基于新闻媒体在微博上发布的新闻摘要创建了该数据集 总数量:2108915个样本;摘要:平均字数 18 正文:平均字数 104 | json格式包括title,content.其中content新闻正文title为新闻的标题 |
| THUCNews(直接下载) | 标题生成任务(短文本生成式摘要) 清华新闻(THUCNews)数据是清华大学自然语言处理实验室整理,根据新浪新闻RSS订阅频道2005~2011年间的历史数据筛选过滤生成.利用其正文与标题,可以构成新闻标题生成数据 总数量:830749个样本;标题:平均字数 19 正文:平均字数 892 | json格式包括title,content.其中content新闻正文 title为新闻的标题 |
| SogouCS(直接下载) | 标题生成任务(短文本生成式摘要) 搜狗新闻(SogouCS)数据是搜狗实验室整理,来自搜狐新闻2012年6月—7月 利用其正文与标题,可以构成新闻标题生成数据。整理后数据信息如下:总数量:1245835个样本;标题:平均字数 17 正文:平均字数 494 | json格式包括title,content.其中content新闻正文 title为新闻的标题 |
| nlpcc2017(直接下载) | 标题生成任务(短文本生成式摘要) nlpcc2017摘要数据是2017年NLPCC比赛Task3任务的数据集。总数量:50000个样本;摘要:平均字数 44 正文:平均字数 990 | json格式包括title,content.其中content新闻正文 title为新闻的标题 |
| 神策杯2018摘要数据(直接下载) | 标题生成任务(短文本生成式摘要) 神策杯2018摘要数据是“神策杯”2018高校算法大师赛的比赛数据 总数量:108089个样本;摘要:平均字数 24 正文:平均字数 1055 | json格式包括title,content.其中content新闻正文title为新闻的标题 |
| 微信公众号摘要数据(直接下载) | 标题生成任务(短文本生成式摘要) 微信公众号摘要数据是github作者nonamestreet整理 整理后数据信息如下: 总数量:712826个样本;标题:平均字数 22 正文:平均字数 1499 | json格式包括title,content.其中content新闻正文 title为新闻的标题 |
| news2016zh新闻数据( 直接下载part1 直接下载part2 直接下载part3 直接下载part4 直接下载part5 ) |
标题生成任务(短文本生成式摘要) news2016zh新闻数据是 CLUEbenchmark整理 总数量:2317427个样本;标题:平均字数 20 正文:平均字数 1250 | json格式包括title,content.其中content新闻正文 title为新闻的标题 |
| CN-Fin(下载) | 文本摘要任务 48410篇中文新闻文本,新闻中的摘要是网站提供的人工筛选或人工撰写摘要。工业场景中的摘要质量不高,仅能为计算摘要标签提供参考。 | json格式文件,包含:新闻标题(title),新闻正文(article),和新闻摘要(summary) |
知识图谱
| 数据 | 描述 | 数据格式 |
|---|---|---|
| CN-DBpedia(2015版dump数据和mention2entity )(开放API) |
中文通用知识图谱 来源:中文百科(如百度百科、互动百科、中文维基百科等)包含900万+的百科实体以及6700万+的三元组关系。 | txt格式,每行一条数据,每条数据是一个(实体名称,属性名称,属性值)的三元组,中间用tab分隔: 实体名称 \t 属性名称 \t 属性值 |
| AliOpenKG(下载链接-需申请) | 开放数字商业知识图谱 包含18亿的三元组,多达67万的核心概念,2681类关系。 | subject \t predicate \t objec 例如:link1 \t link2 \t 正装长袖衬衫 |
| Zhishi.me(dump-turtle格式和jsonld格式) | 中文通用知识图谱 来源:中文百科(如百度百科、互动百科、中文维基百科等) | json或者turtle格式 |
| XLore(开放API) | 多语言通用知识图谱 来源:中英文维基和百度百科 包含2615万实例,235万概念,51万属性。 | api接口 |
知识任务数据
| 数据 | 描述 | 数据格式 |
|---|---|---|
| FinRE(链接) | 金融领域新闻关系抽取 18000+样本 | 44种关系分类类型,每条sample包含4个数据项:输入文本;待分类的头、尾实体位置;关系类型 |
| SanWen (链接) | 中文文献关系抽取 | 9种关系分类类型,每条sample包含4个数据项:输入文本;待分类的头、尾实体位置;关系类型 |
| OntoNotes (链接) | 中文命名实体识别任务 总共 15740 | 有18种命名实体类型;每条sample包含3条数据项:输入文本和标注出来的实体位置和对应的实体类型。 |
| MSRA (链接) | 中文命名实体识别任务 训练集:46675 | 有3种命名实体类型;每条sample包含3条数据项:输入文本和标注出来的实体位置和对应的实体类型。 |
零样本学习/小样本学习
| 数据 | 描述 | 数据格式 |
|---|---|---|
| EPRSTMT(直接下载) | 电商产品评论情感分析数据集 数据量:训练集(32),验证集(32),公开测试集(610),测试集(753),无标签语料(19565) | json格式,包括id,句子,和标签,样例:{“id”: “xxx”, “sentence”: “xxx”, “label”: “xxx”} |
| CSLDCP(直接下载) | 中文科学文献学科分类数据集 数据量:训练集(536),验证集(536),公开测试集(1784),测试集(2999),无标签语料(67) | json格式,包括id,sentence,和label |
| TNEWS(直接下载) | 今日头条中文新闻(短文本)分类数据集 该数据集来自今日头条的新闻版块,共提取了15个类别的新闻,包括旅游、教育、金融、军事等。 | json格式,包括分分类ID,分类名称,新闻字符串(仅含标题)。 |
| IFLYTEK(直接下载) | 长文本分类数据集 该数据集关于app应用描述的长文本标注数据,包含和日常生活相关的各类应用主题,共119个类别:”打车”:0,”地图导航”:1,”免费WIFI”:2,”租车”:3,….,”女性”:115,”经营”:116,”收款”:117,”其他”:118(分别用0-118表示)。 | json格式,每一条数据有三个属性,从前往后分别是 类别ID,类别名称,文本内容。 |
| OCNLI(直接下载) | 中文原版自然语言推理数据 数据量:训练集(32),验证集(32),公开测试集(2520),测试集(3000),无标签语料(20000) | json格式,包括level,sentence1,sentence2, label,label0,label1,label2,label3,label4,genre,prem_id和id。 |
| BUSTM(直接下载) | 小布助手对话短文本匹配数据集 数据量:训练集(32),验证集(32),公开测试集(1772),测试集(2000),无标签语料(4251) | json格式,包括id,sentence1,sentence2,和label |
| ChID (直接下载) | 成语阅读理解填空 数据量:训练集(42),验证集(42),公开测试集(2002),测试集(2000),无标签语料(7585) | json格式,包括id,candidates,content,和answer |
| CSL (直接下载) | 论文关键词识别 数据量:训练集(32),验证集(32),公开测试集(2828),测试集(3000),无标签语料(19841) | 每一条数据有四个属性,从前往后分别是 数据ID,论文摘要,关键词,真假标签。 |
| CLUEWSC (直接下载) | WSC Winograd模式挑战中文版 训练集(32),验证集(32),公开测试集(976),测试集(290),无标签语料(0) | 例子: {“target”: {“span2_index”: 37, “span1_index”: 5, “span1_text”: “床”, “span2_text”: “它”}, “idx”: 261, “label”: “false”, “text”: “这时候放在床上枕头旁边的手机响了,我感到奇怪,因为欠费已被停机两个月,现在它突然响了。”} “true”表示代词确实是指代span1_text中的名词的,”false”代表不是。 |
多模态-检索数据
包括图文检索和文图检索
| 数据 | 描述 | 数据格式 |
|---|---|---|
| Flickr8k-CN(直接下载) | Flickr8k中文描述图文对 每张图片对应5条文本描述:中文描述的翻译包含人工手写、人工翻译(仅test集)、机器翻译(百度翻译、谷歌翻译)数据量: Pairs: 30000/5000/5000 (Images 6k, Text 30k) | caption:txt格式,包含原Flickr8k中image对应的id及不同翻译或手写版本的中文文本描述 image:jpg格式,以id区分,不同split的image id列表保存在txt中 |
| Flickr30k-CN(直接下载) | Flickr30k机器翻译文图对 采用机器翻译原Flickr30k的描述(测试集为人工翻译),每张图片对应5条描述 数据量: Pairs: 148915/5000/5000 (Images 29783, Text 148915) | caption:txt格式,包含原Flickr30k中image对应的id及机器翻译后的中文caption image:jpg格式,以id区分,不同split的image id列表保存在txt中 |
| COCO_CN(Github ,需向原作者提交申请,通过后方可下载) |
MSCOCO人工翻译 每张图片1-2条描述:中文描述的翻译包含人工手写、人工翻译(仅test集)、机器翻译(百度翻译)数据重新划分,与原MSCOCO不同 数据量 Pairs: 20065/1000/1053 (Images: 18341,Text: 20065) | caption:txt格式,包含原MSCOCO2014中image的原id及人工翻译对应的中文caption image:jpg格式,以id区分,不同split的image id列表保存在txt中 |
| MUGE-Retrieval(天池数据集 ,需申请) |
电商领域文到图检索 训练集1条query对应1个image,训练&验证集每条query对应5-6 images 数据量 Pairs: 248786/29806/30399 (Images: 129380, Text: 248786) | query:jsonl格式,每行一条query数据,包含query_id,query_text和对应image的id列表 image:tsv格式,每行一条image数据,包含image_id和image的base64编码 |
| AIC-ICC(AI Challenger比赛官方网址) | AI challenger比赛数据集,包括Image captioning、关键点检测和机器翻译3个任务 每个图片对应5个描述 训练集30w图片,150w描述 验证集3w图片,15w描述 做图文检索任务时,重新划分过训练集验证集 Images:210000/30000/30000 Texts: 1050000/150000/300000 | caption:json格式,文件中每个样本包括url,image_id和5条captions image:jpg格式,以image_id命名 |
| ChineseFoodNet(官方地址 查看数据集并下载) |
中国食物数据集 覆盖208个种类,185628张图片 数据量 Images:145066/20254/20310 Text: 208 | 适合图片分类 |
多模态-生成数据
包括图到文,文到图数据
| 数据 | 描述 | 数据格式 |
|---|---|---|
| Flickr30k-CN | 同上 | 同上 |
| COCO_CN | 同上 | 同上 |
| AIC-ICC | 同上 适合文到图生成和图到文生成 | 同上 |
| MSCOCO_CN(英文版下载链接,机器翻译的中文版本未公开) | 适合文到图生成和图到文生成 MSCOCO机器翻译文图对(2017版),每张图片5条描述 Pairs: 591753/25014/- Image: 118287/5000/40671 Text:569002/24794/- | image: jpg格式。 text: json格式,key包括info, licenses, images, annotations。image-caption pairs 在annotations中 |
| MUGE-T2I(天池数据集,需申请) | 电商文到图生成 每张图片对应一条描述 数据量: Pairs: 9w/5k/5k | image: tsv格式, \t分隔: 图片id \t 商品图片内容 (base64编码) text: tsv格式,\t分隔: 图片id \t 商品描述 |
| MUGE-IC(天池数据集,需申请) | 电商图到文生成 每张图片对应一条描述 数据量: Pairs: 5w/5k/1w | image: tsv格式, \t分隔: img_id \t img_content(base64编码) caption: jsonl格式,key包括image_id,text |
机器翻译数据
| 数据 | 描述 | 数据格式 | |
|---|---|---|---|
| News Commentary (oss) |
来源网站 https://opus.nlpl.eu/News-Commentary.php A parallel corpus of News Commentaries provided by WMT for training SMT. The source is taken from WMT 19: http://data.statmt.org/news-commentary/v16/documents.tgz 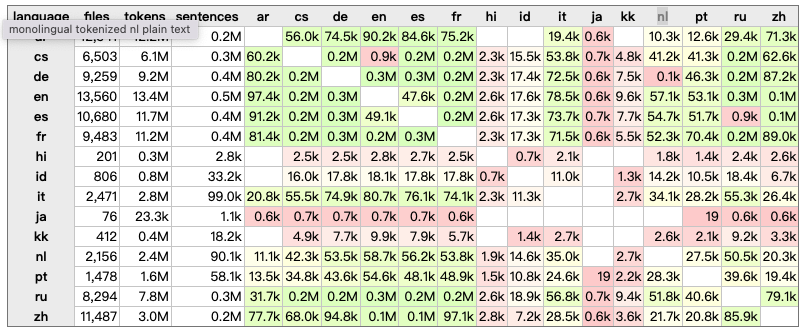 中英数据量 0.1M |
(src)=”1”> 1929 or 1989 ? (trg)=”1”> 1929年还是1989年 ? |
(src)=”2”> PARIS – As the economic crisis deepens and widens , the world has been searching for historical analogies to help us understand what has been happening .
(src)=”3”> At the start of the crisis , many people likened it to 1982 or 1973 , which was reassuring , because both dates refer to classical cyclical downturns .
(trg)=”2”> 巴黎-随着经济危机不断加深和蔓延 , 整个世界一直在寻找历史上的类似事件希望有助于我们了解目前正在发生的情况 。 一开始 , 很多人把这次危机比作1982年或1973年所发生的情况 , 这样得类比是令人宽心的 , 因为这两段时期意味着典型的周期性衰退 。
| |
| AI Challenger - 英中翻译
oss | 冠军方案
https://zhuanlan.zhihu.com/p/54060156
规模最大的口语领域英中双语对照数据集。提供了超过1000万的英中对照的句子对作为数据集合。所有双语句对经过人工检查,数据集从规模、相关度、质量上都有保障。
训练集:10,000,000 句
验证集(同声传译):934 句
验证集(文本翻译):8000 句 |  | |
| OpenSubtitles
| |
| OpenSubtitles
oss | 来源网站
https://opus.nlpl.eu/OpenSubtitles2016.php
This is a new collection of translated movie subtitles from http://www.opensubtitles.org/.
This is a cleaner version of the subtitle collection using improved conversion, sentence alignment, better language checking, more meta data, ….
65 languages, 1,850 bitexts
total number of files: 2,793,243
total number of tokens: 17.09G
total number of sentence fragments: 2.60G
中英数据量 9.3M
| 中英各有一个文件
另有一个文件指明对应的中英文所在行数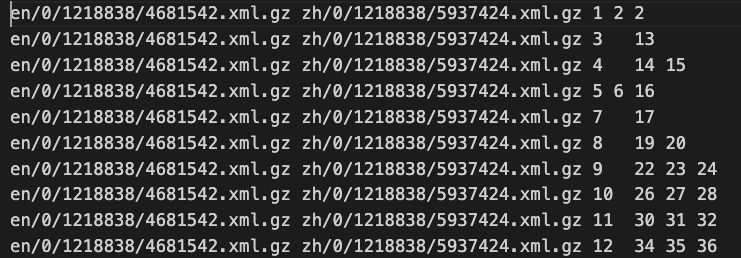 | |
| MultiUN
| |
| MultiUN
oss | 来源网站
https://opus.nlpl.eu/MultiUN.php
This is a collection of translated documents from the United Nations originally compiled by Andreas Eisele and Yu Chen (see http://www.euromatrixplus.net/multi-un/)..) Please cite MultiUN: A Multilingual corpus from United Nation Documents, Andreas Eisele and Yu Chen, LREC 2010
7 languages, 21 bitexts
total number of files: 489,334
total number of tokens: 1.99G
total number of sentence fragments: 81.41M
中英数据量 9.6M
|
同上 | |
| 翻译语料(translation2019zh)
oss | 来源网站
https://github.com/brightmart/nlp_chinese_corpus
数据描述
中英文平行语料520万对。每一个对,包含一个英文和对应的中文。中文或英文,多数情况是一句带标点符号的完整的话。
对于一个平行的中英文对,中文平均有36个字,英文平均有19个单词(单词如“she”)
数据集划分:数据去重并分成三个部分。训练集:516万;验证集:3.9万;测试集,数万,不提供下载。
| {“english”: “In Italy, there is no real public pressure for a new, fairer tax system.”, “chinese”: “在意大利,公众不会真的向政府施压,要求实行新的、更公平的税收制度。”} | |
| United Nations Parallel Corpus
oss | 来源网站
https://conferences.unite.un.org/UNCORPUS/en/DownloadOverview
https://drive.google.com/u/0/uc?id=1rv2Yh5j-5da5RZO3DEaYvYRZKxE841hT&export=download
https://drive.google.com/uc?export=download&id=1cfUezEOv5UPzF-d1uIm9-dkIUjtyZ9ys
We also make available plain-text bitexts that span all documents for a specific language pair and can be used more readily with SMT training pipelines. Inside a language-pair specific archive consists of a plain-text file for each language and one file with ids.
中英数据量16M
| 同OpenSubtitles | |
| wikititles
oss | 来源网站
https://statmt.org/wmt20/translation-task.html#download
中英数据量 83w | tsv格式 | |
| WikiMatrix
| |
| WikiMatrix
oss | 来源网站
https://statmt.org/wmt20/translation-task.html#download
中英数据量 2.6m |  | |
| Back-translated news
| |
| Back-translated news
oss | 来源网站
https://statmt.org/wmt20/translation-task.html#download
Back-translated news. The cs-en data is contained in CzEng. The zh-en and ru-en data was produced for the University of Edinburgh systems in 2017 and 2018.
中英数据量 19m | 
 | |
| UM-Corpus
| |
| UM-Corpus
需要注册
http://nlp2ct.cis.umac.mo/um-corpus/ | 来源网站
http://nlp2ct.cis.umac.mo/um-corpus/
The UM-Corpus has been designed to be a multi-domain and balanced parallel corpus for research and development purpose. In this version, a two million English-Chinese aligned corpus is provided, and it is categorized into eight different text domains, covering several topics and text genres, including: Education, Laws, Microblog, News, Science, Spoken, Subtitles, and Thesis.
中英数据量 2M
注册后等待官方审核,待更新
| | |
| 第十八届全国机器翻译大会机器翻译评测
| 来源网站
https://statmt.org/wmt20/translation-task.html#download
http://mteval.cipsc.org.cn:81/CCMT2022/index.html
需正式注册才可获得数据 | | |
Acknowledge
以上数据收集自网上公开的数据,包括如下几个来源(如有侵权,烦请告知):
- CLUE benchmark:https://www.cluebenchmarks.com
- CLUE datasets: https://github.com/CLUEbenchmark/CLUEDatasetSearch
- Wudao数据:https://git.openi.org.cn/BAAI/WuDao-Data
- Wukong数据:https://readpaper.com/paper/653639982984556544
- SophonPlus:https://github.com/SophonPlus/ChineseNlpCorpus

若有收获,就点个赞吧
0 人点赞
