我们学习hive的时候 都知道hive 是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能 它的本质是:将HQL转化成MapReduce程序
这篇文章就是从源码角度看看 hive的底层是如何进行转化的
SQL转化为MapReduce任务的,整个编译过程分为六个阶段:
1.Antlr定义SQL的语法规则,完成SQL词法,语法解析,将SQL转化为抽象语法树AST Tree
2.遍历AST Tree,抽象出查询的基本组成单元QueryBlock
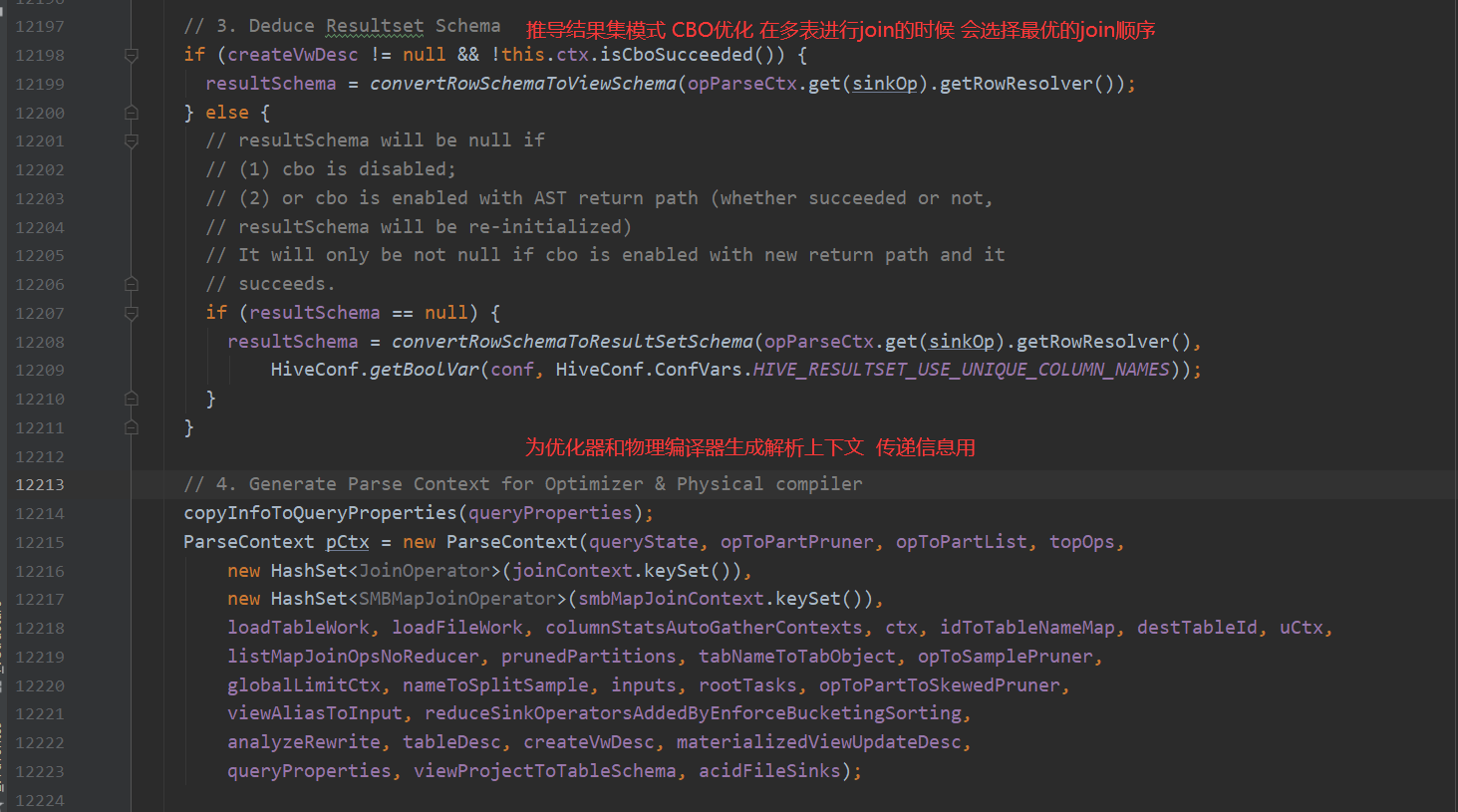
3.遍历QueryBlock,翻译为执行操作树OperatorTree
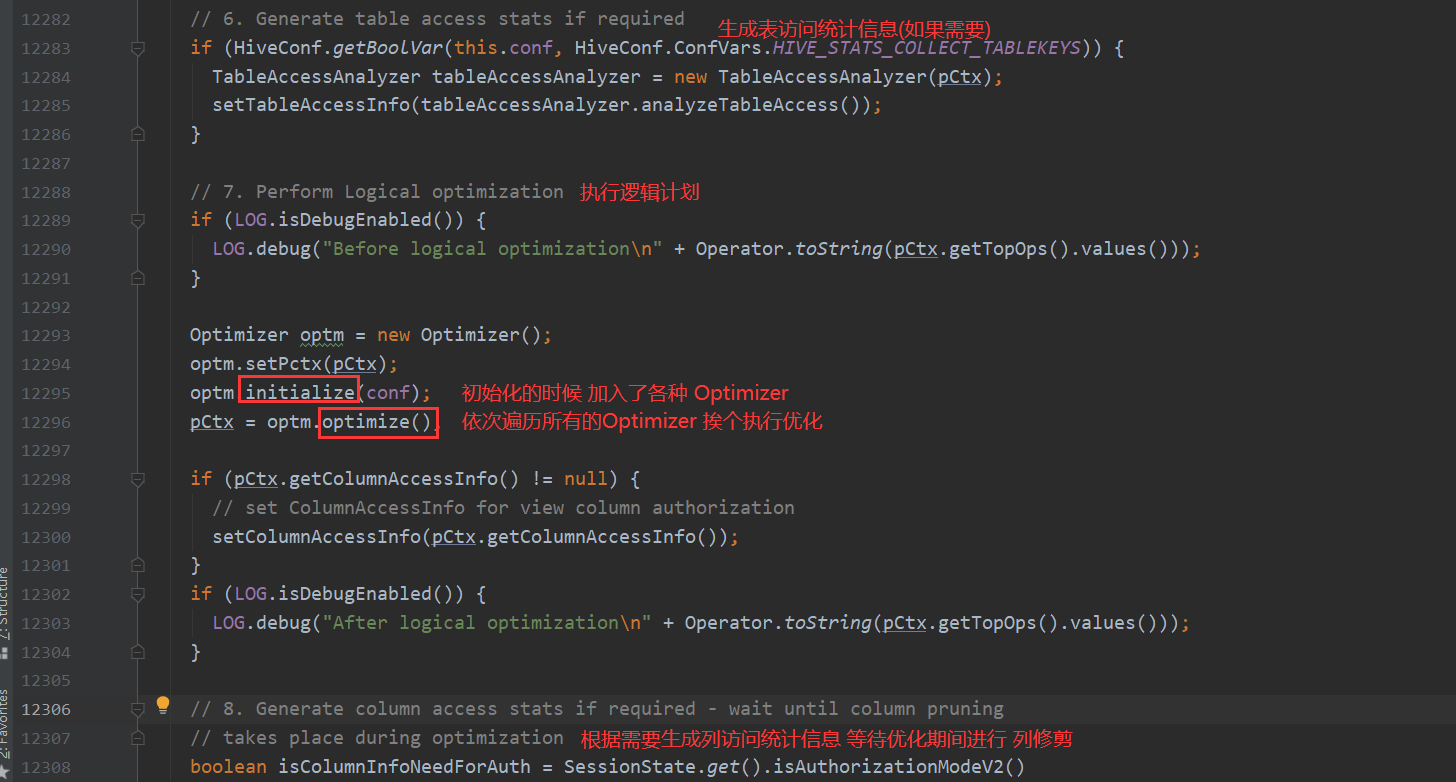
4.逻辑层优化器进行OperatorTree变换,合并不必要的ReduceSinkOperator,减少shuffle数据量
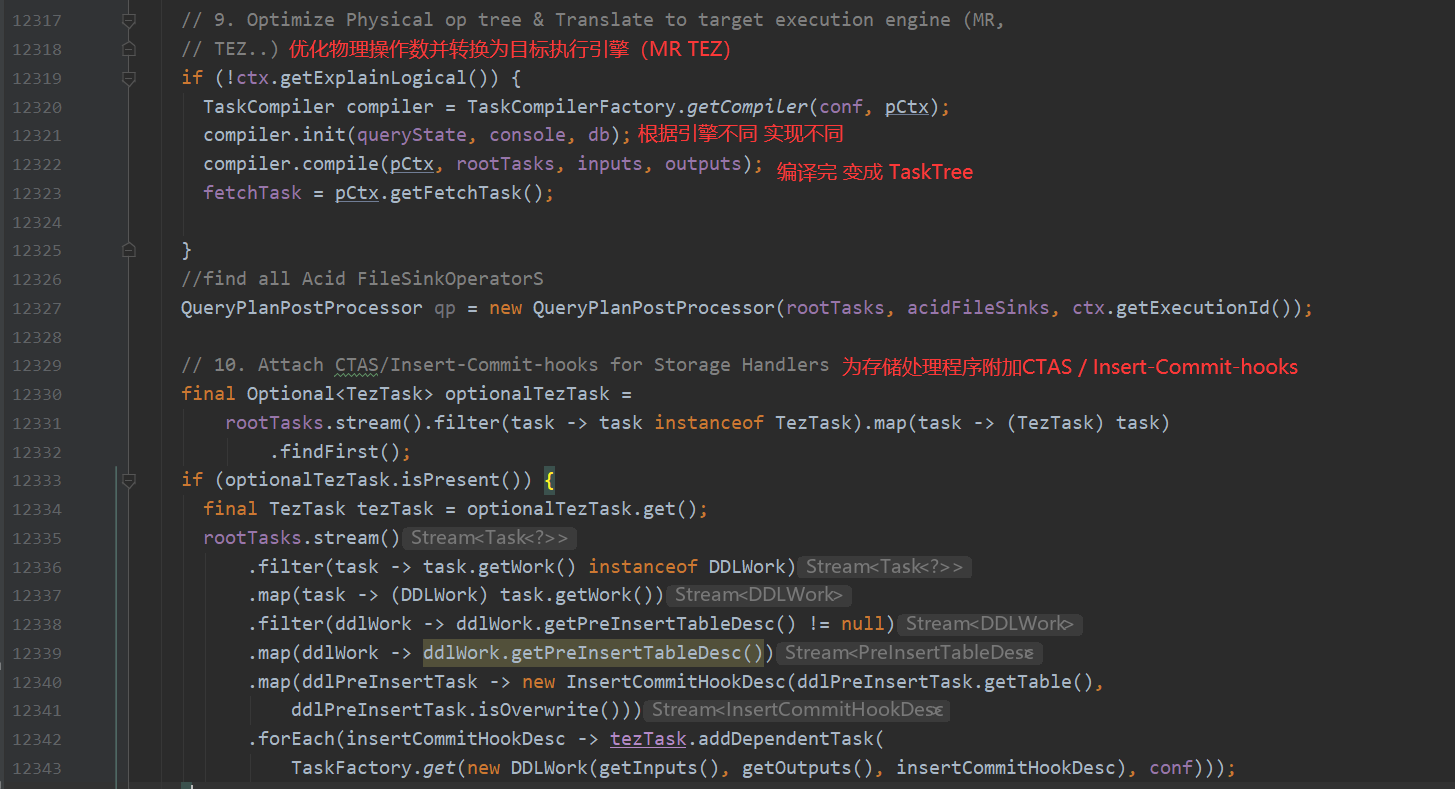
5.遍历OperatorTree,翻译为MapReduce任务
6.物理层优化器进行MapReduce任务的变换,生成最终的执行计划
接下来就开始看源码 一点点找到上述流程对应的位置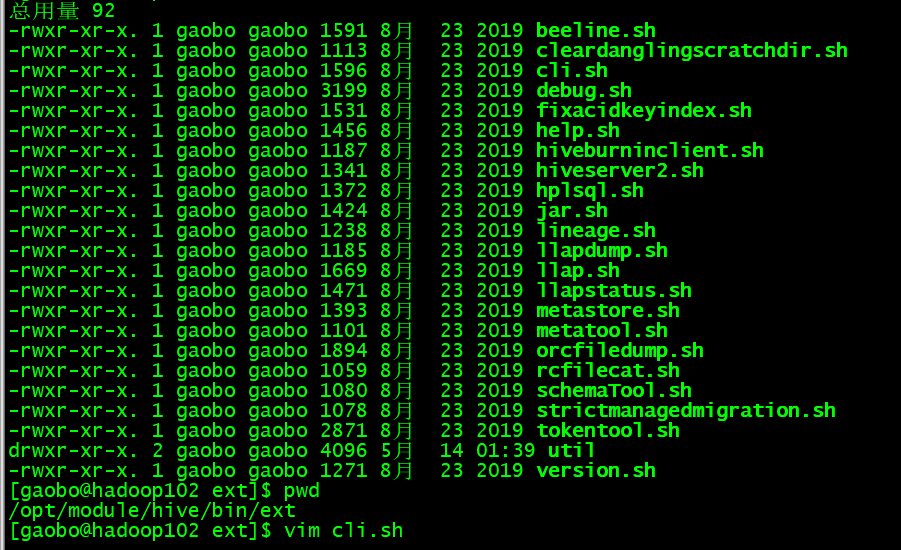
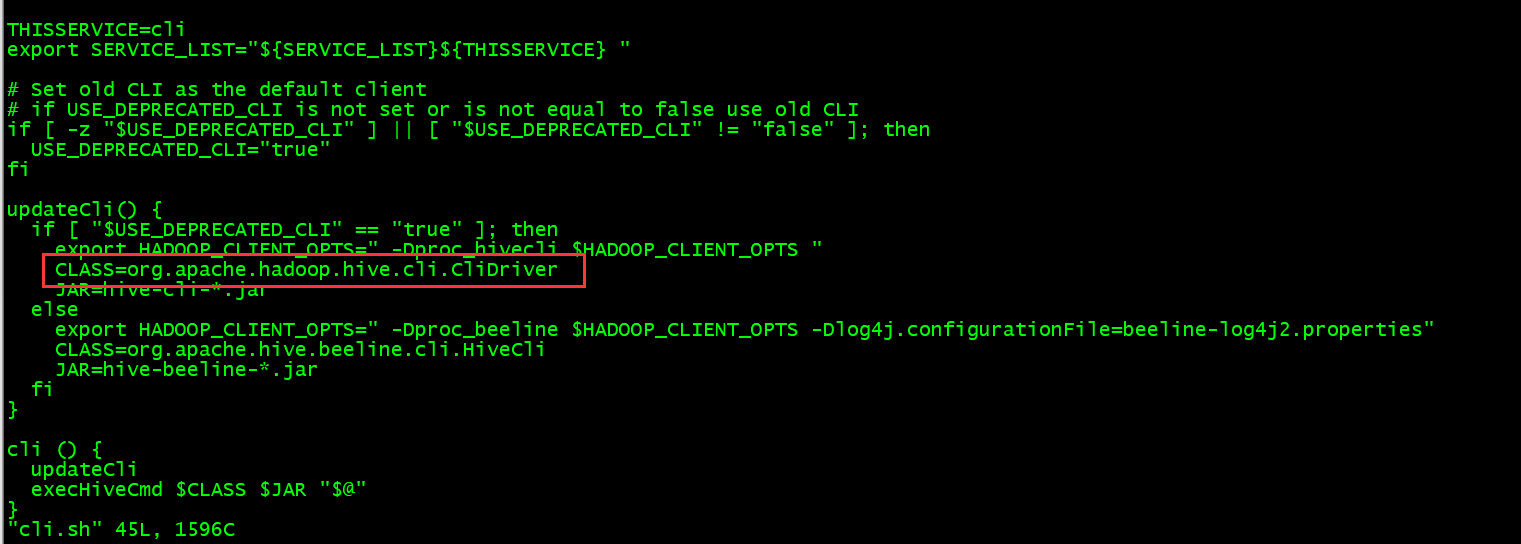
首先CliDriver类是hive的入口 先看一下它的main方法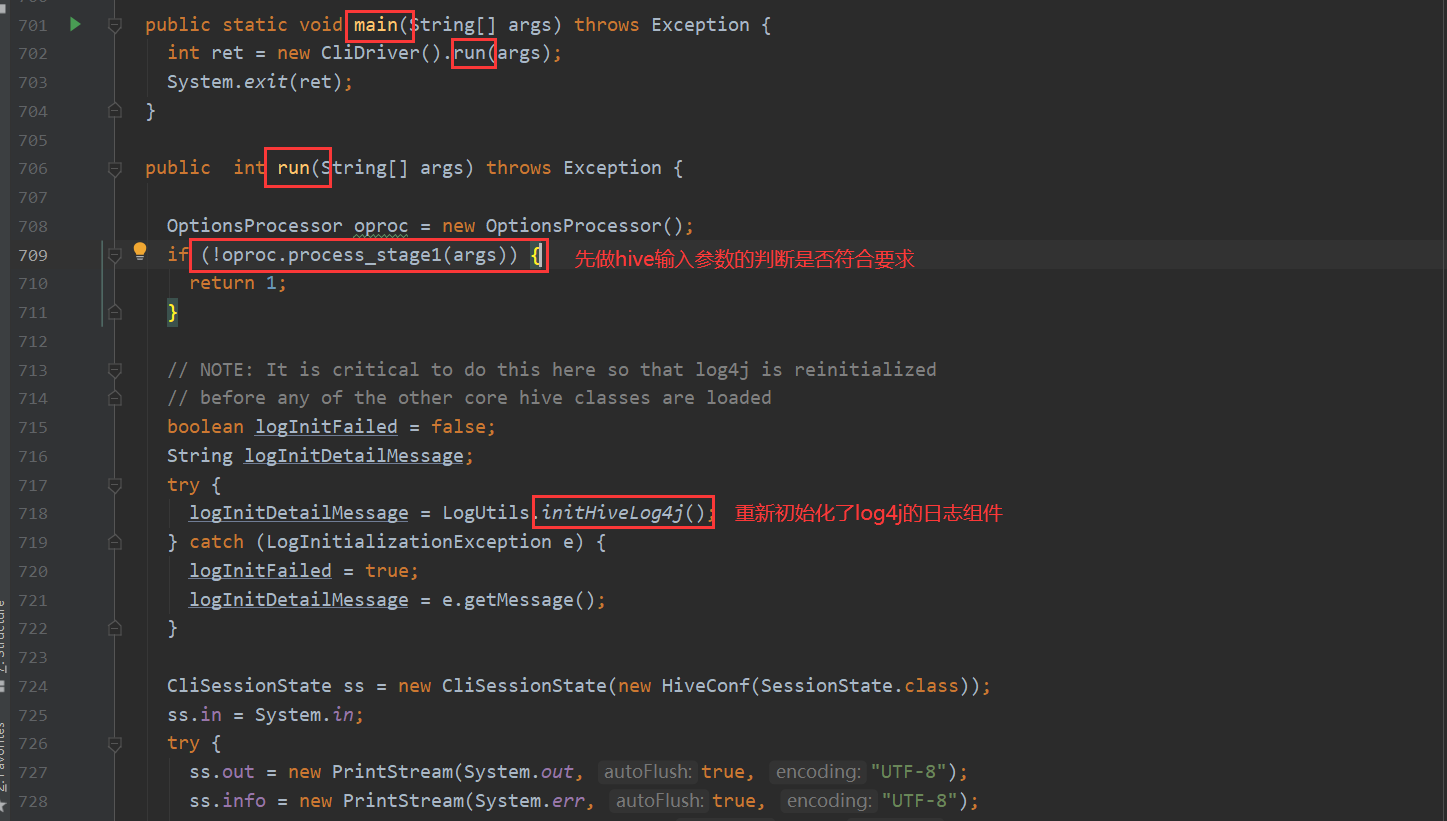
点进去 会发现一块代码专门处理 记录历史指令
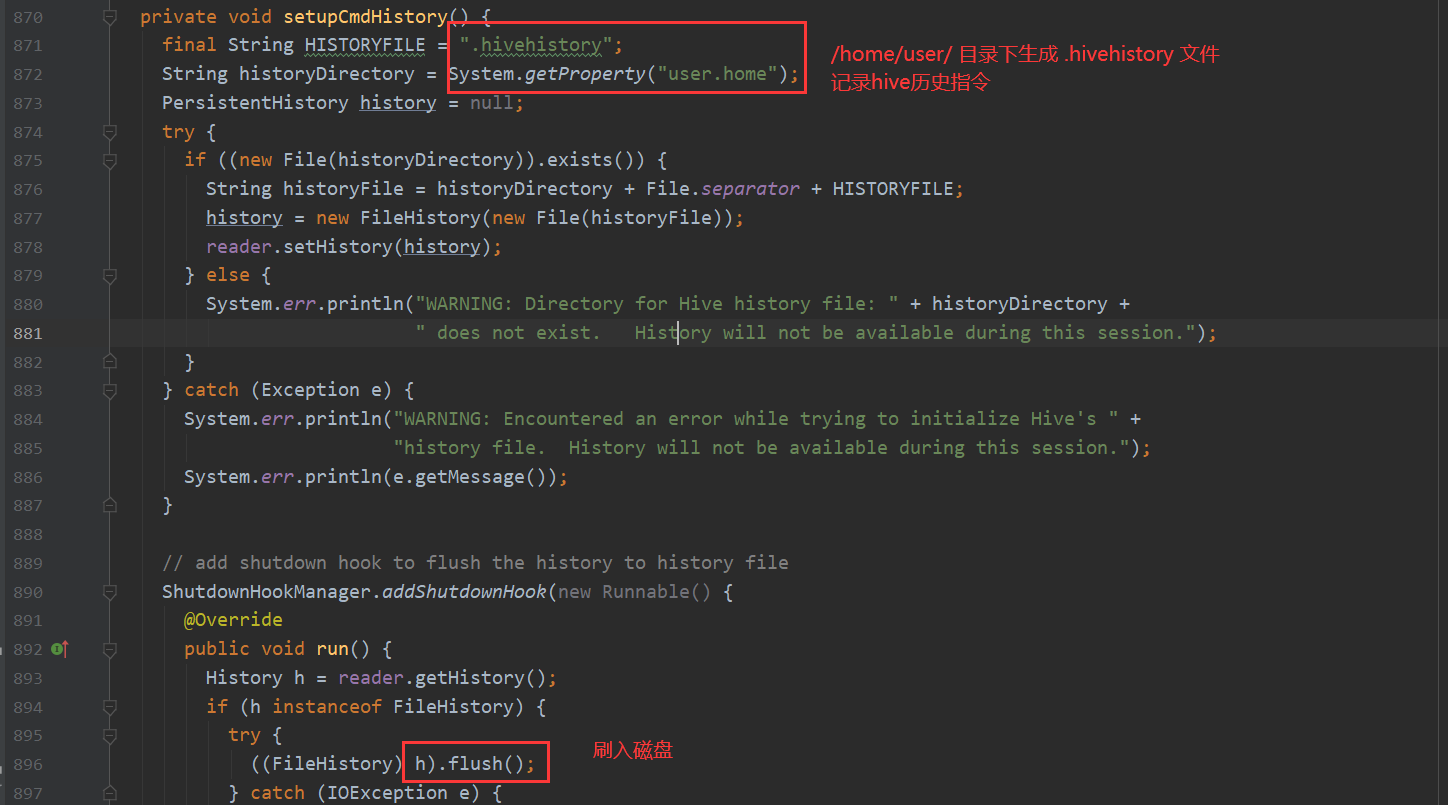
记录历史指令的代码下面 会看到一处while循环 不停的读取命令执行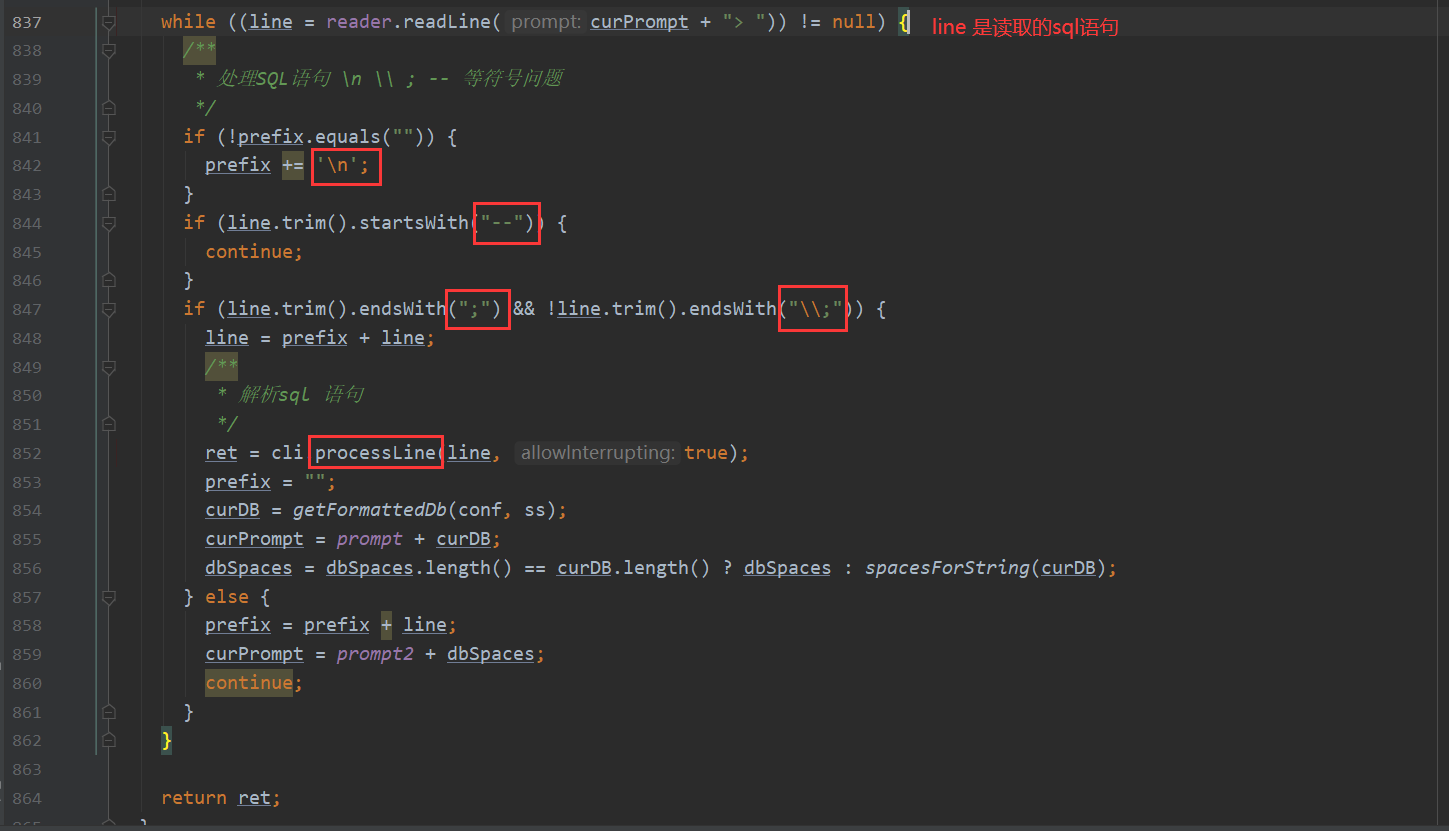
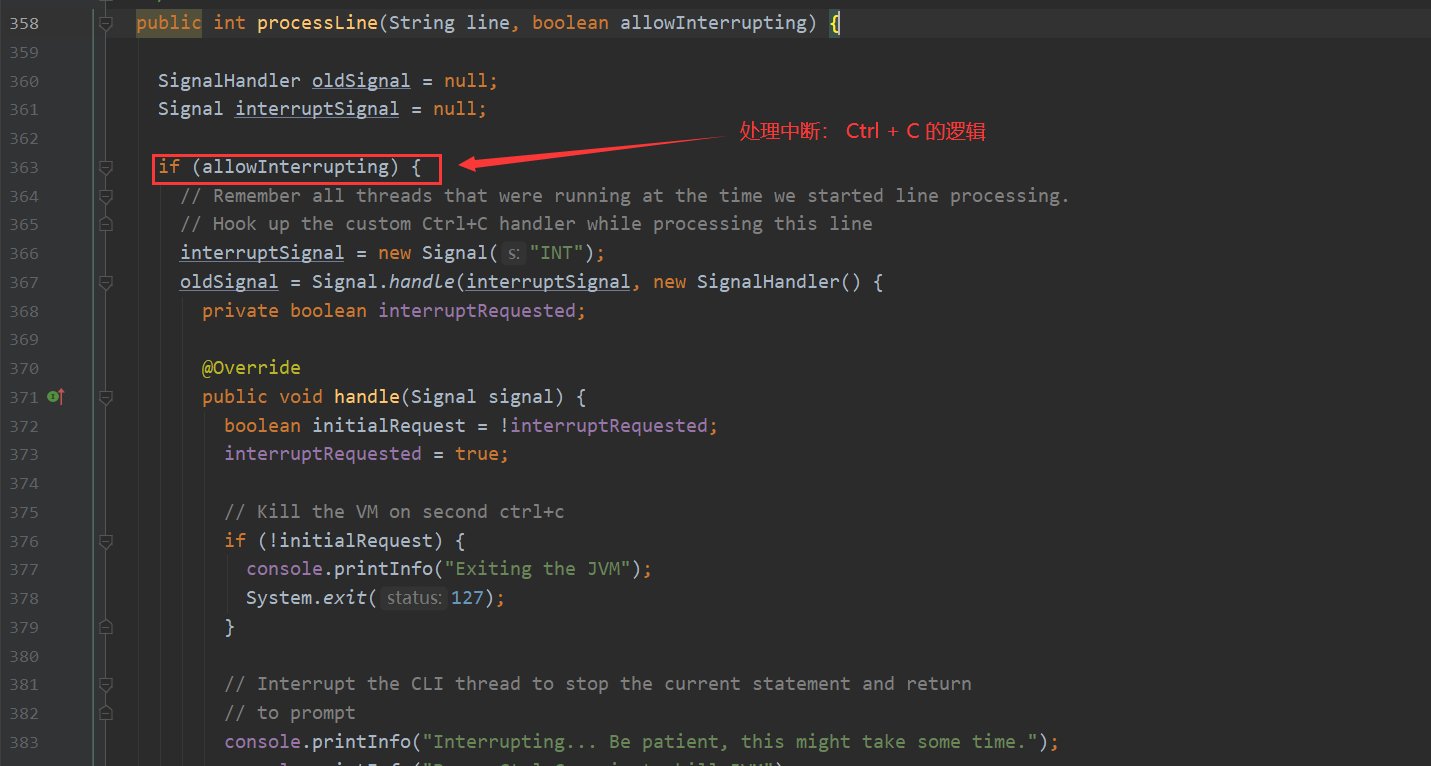
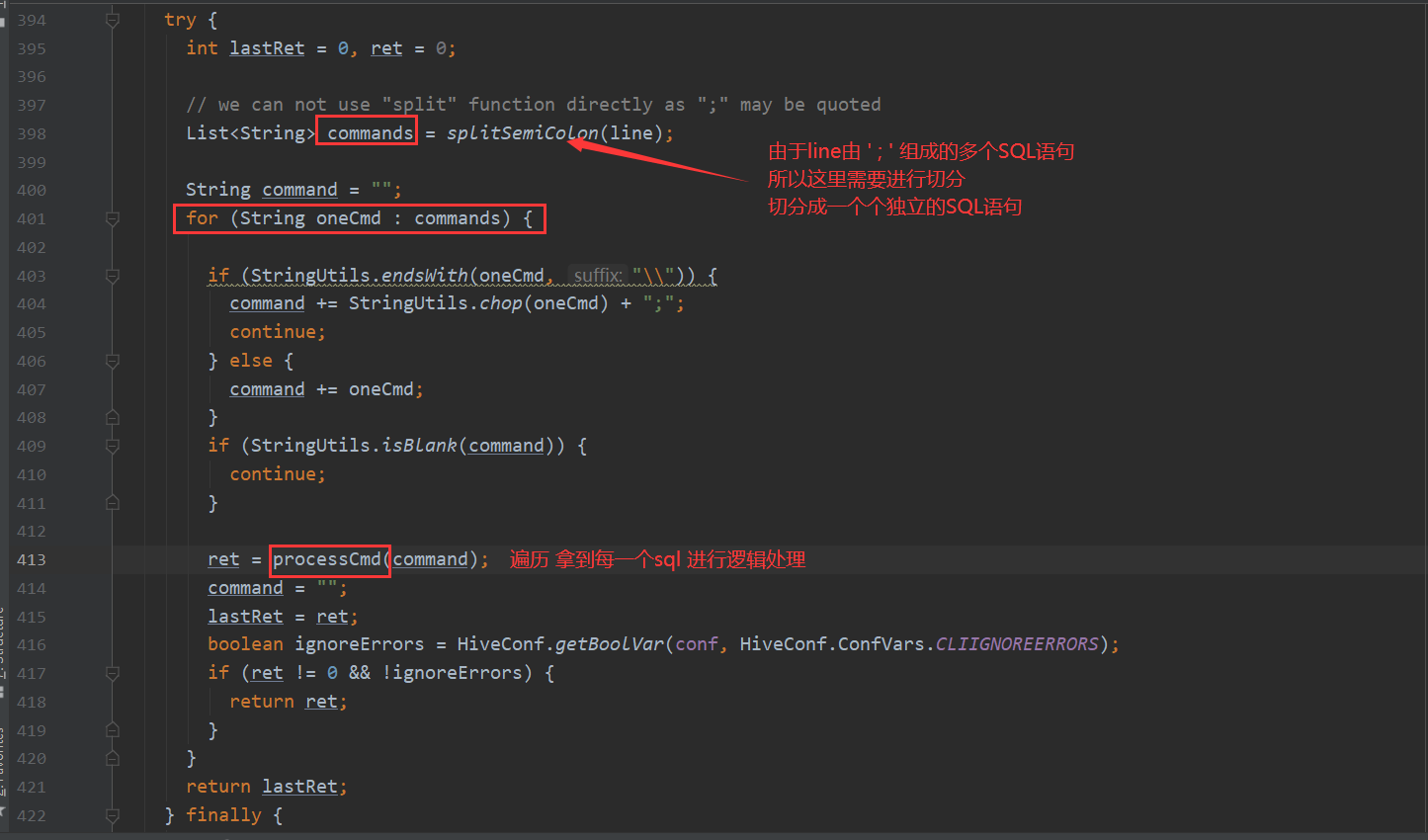
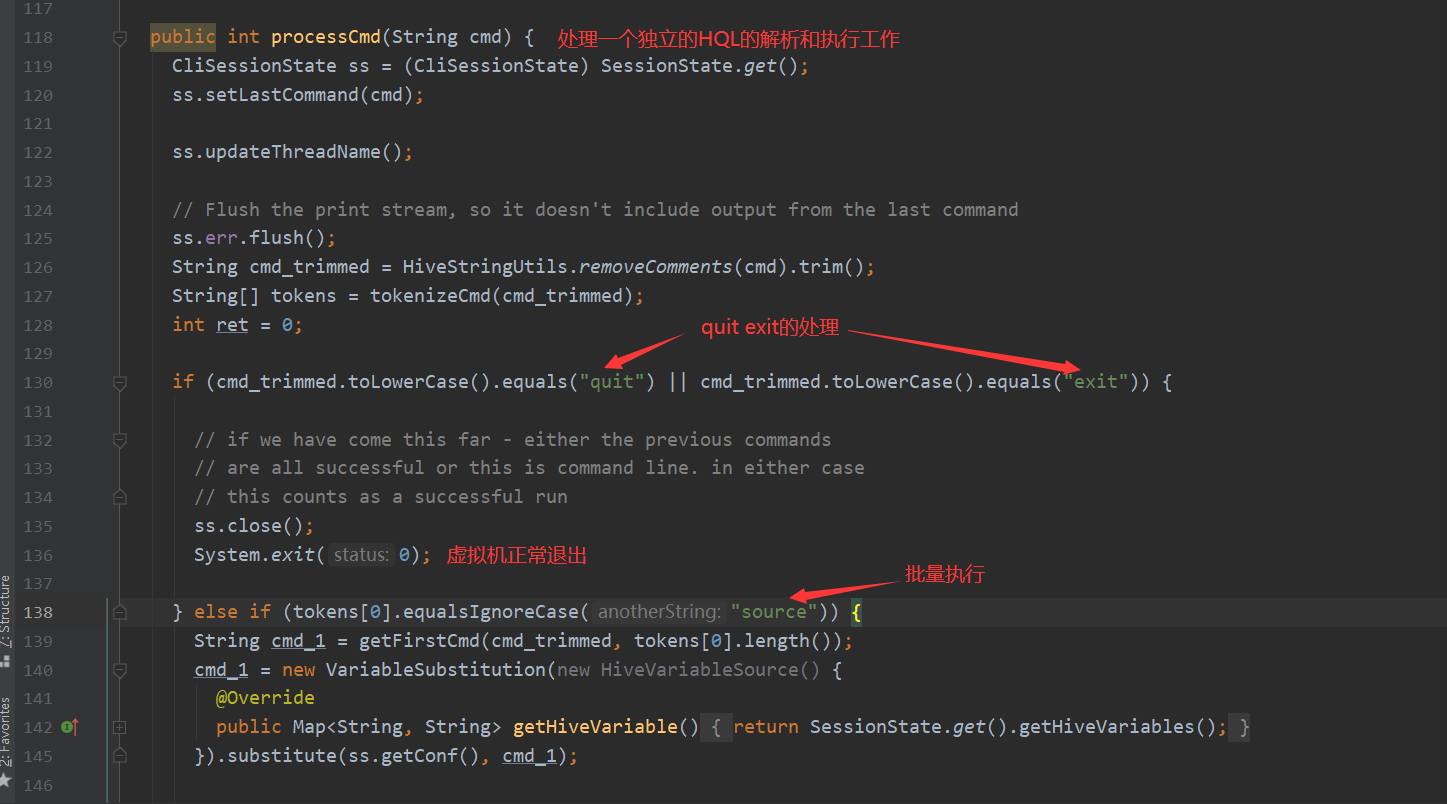
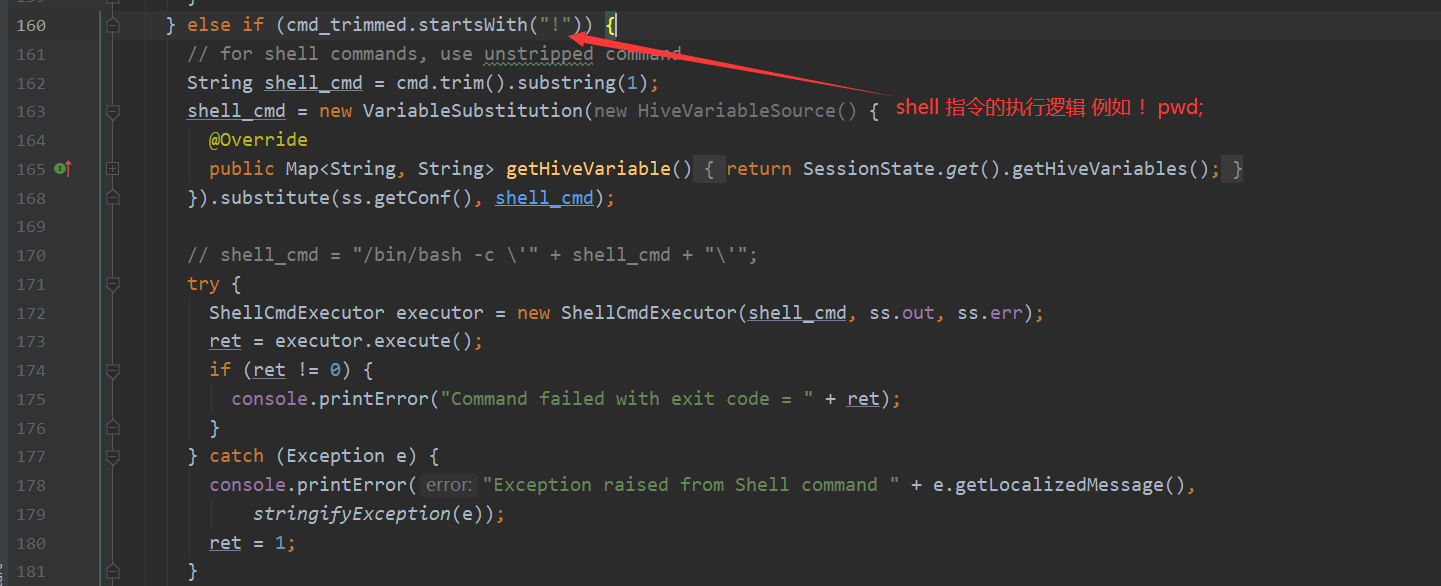
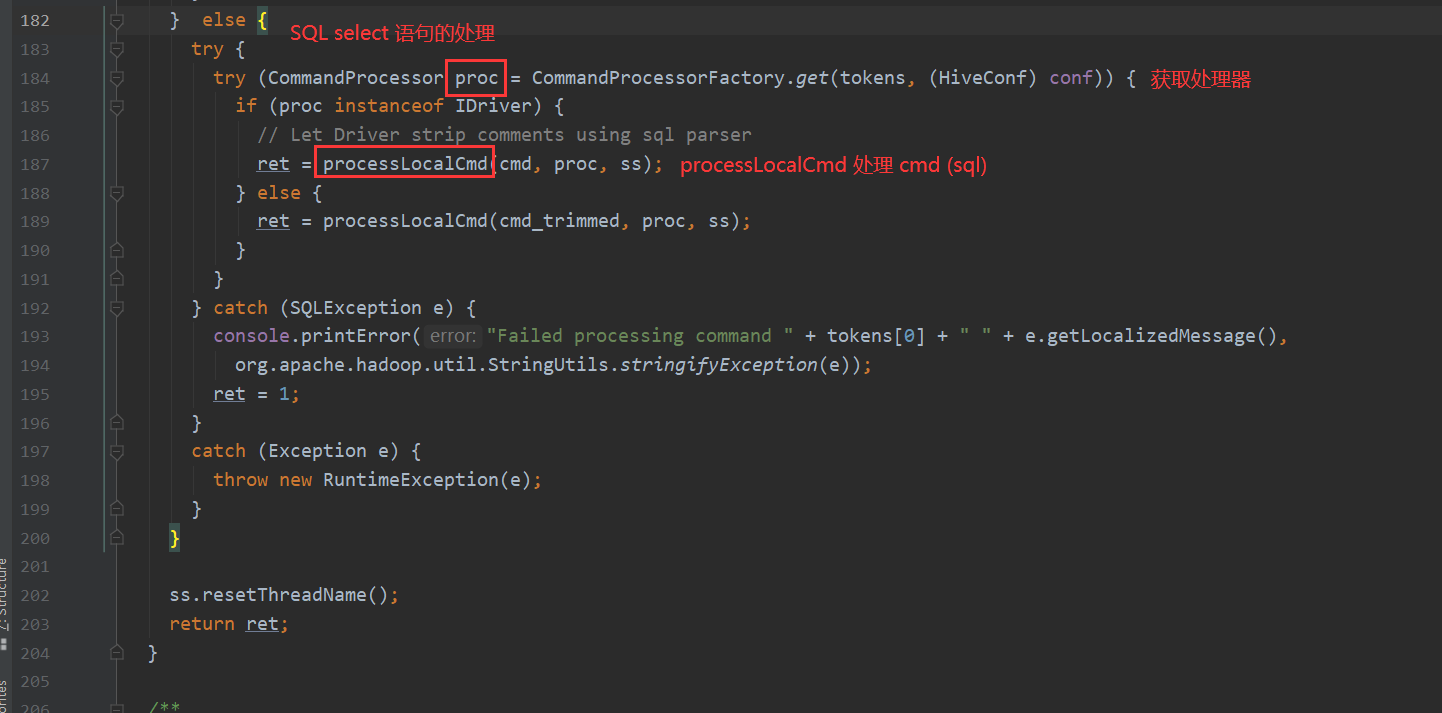
processLocalCmd 这个方法有4个主要流程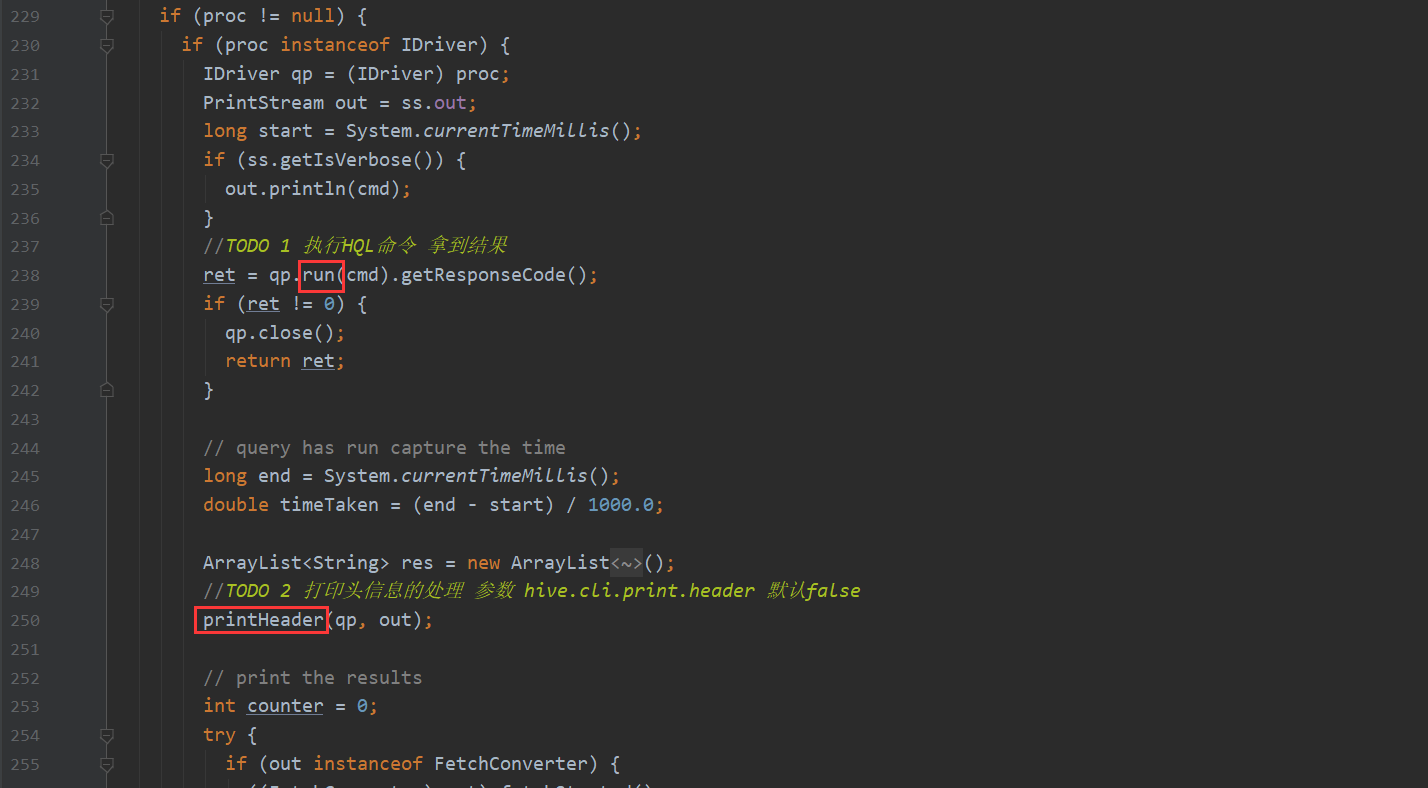
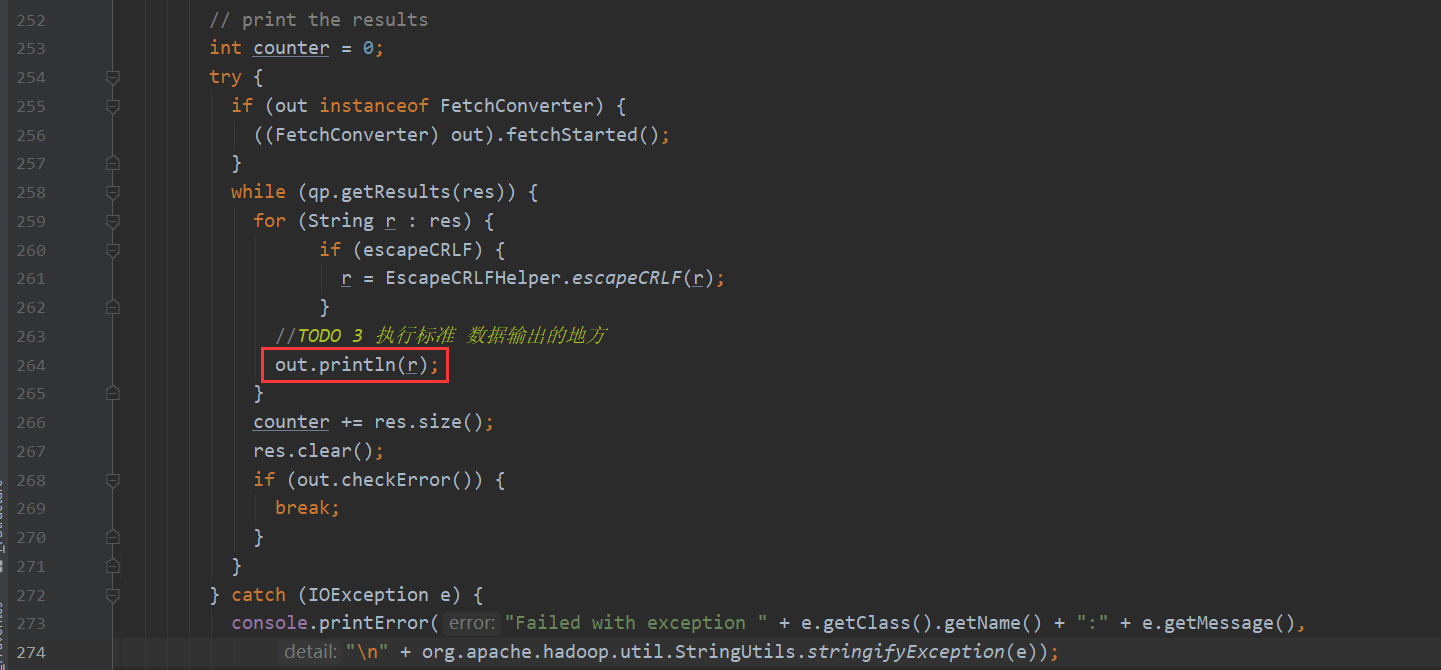
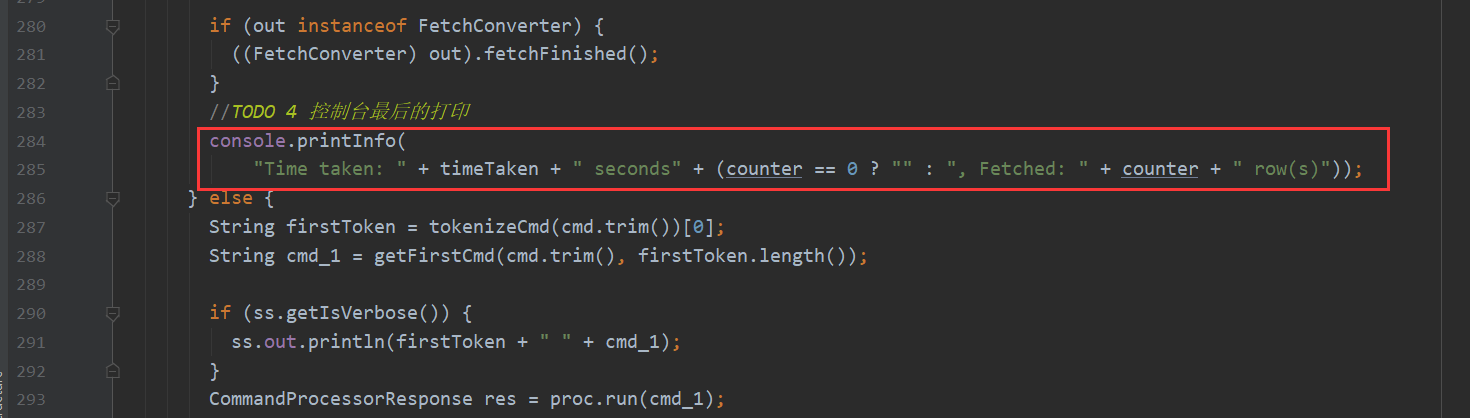
这样就跟hive中查询到的结果有了匹配 如下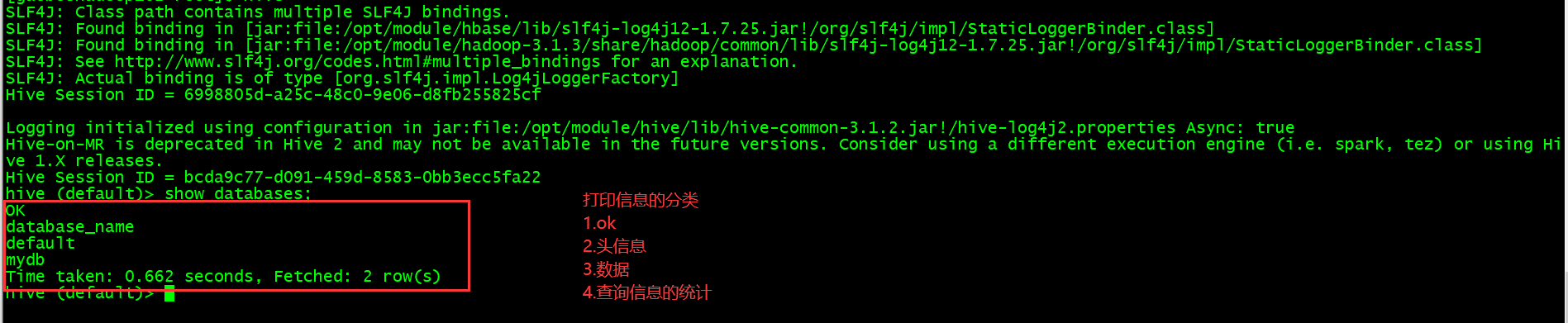
既然数据都查出来 并且展示了 那么还是没有看到是哪块代码进行转化的
这里就需要看一下流程1的部分 里面包含了复杂的逻辑 下面一点点进行分析 底层是如何解析sql 然后一步步转化Mapreduce 最后查询结果的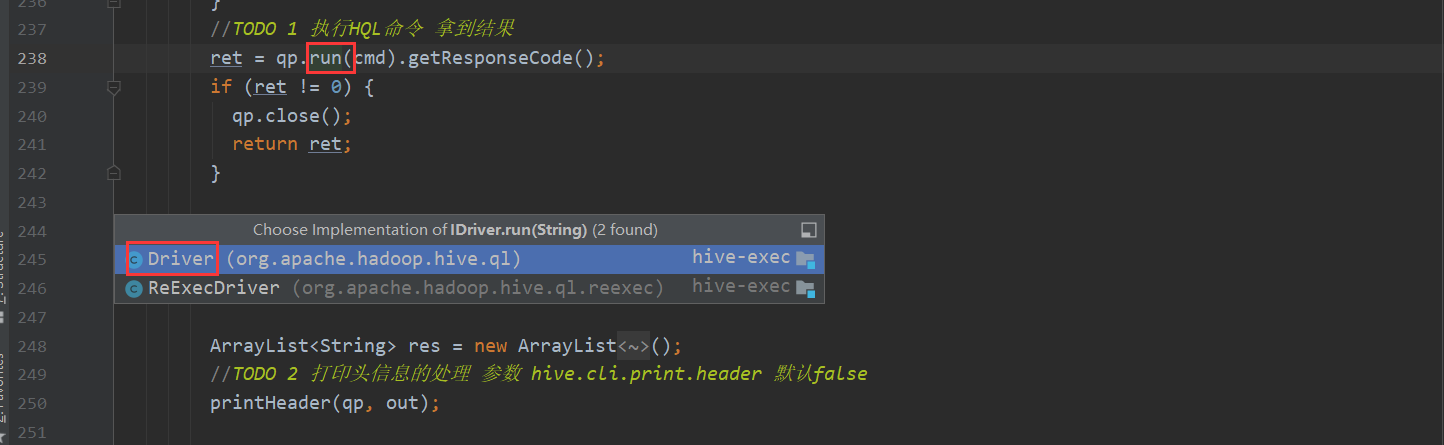
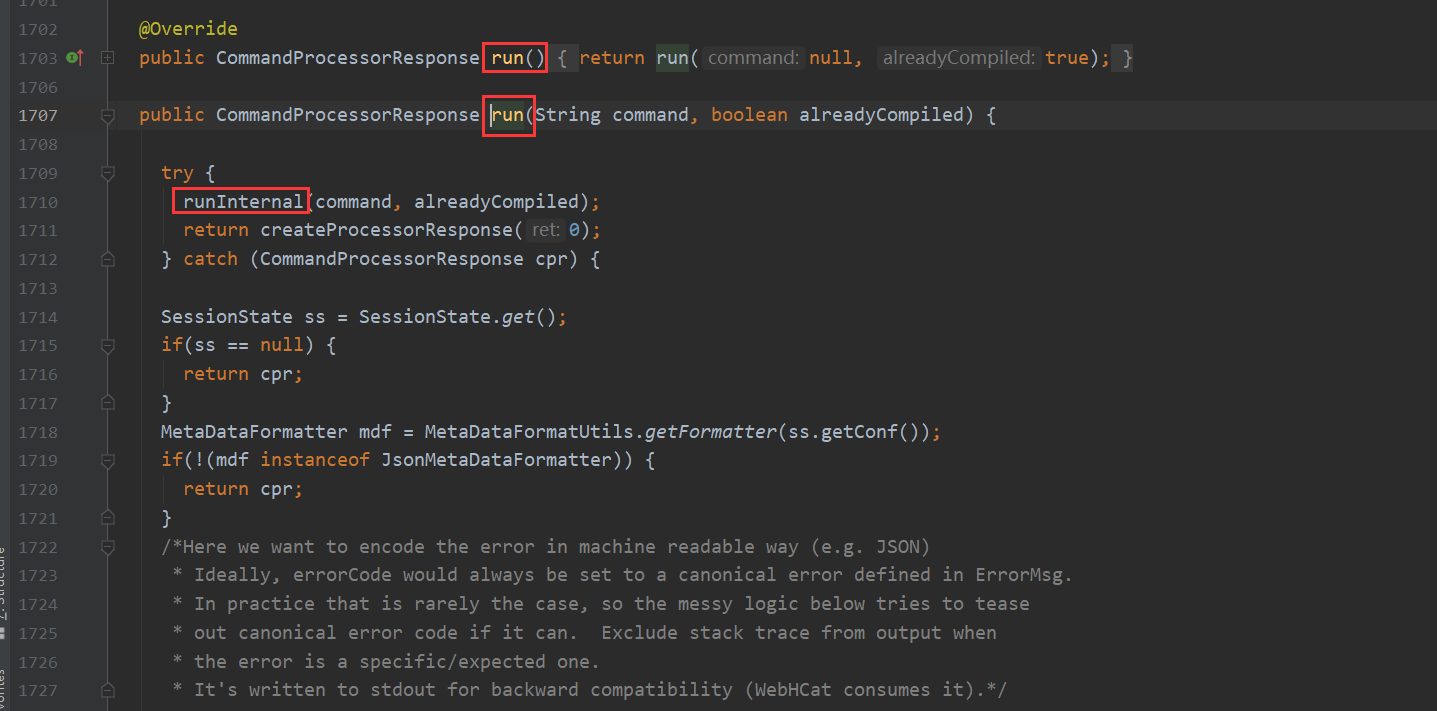
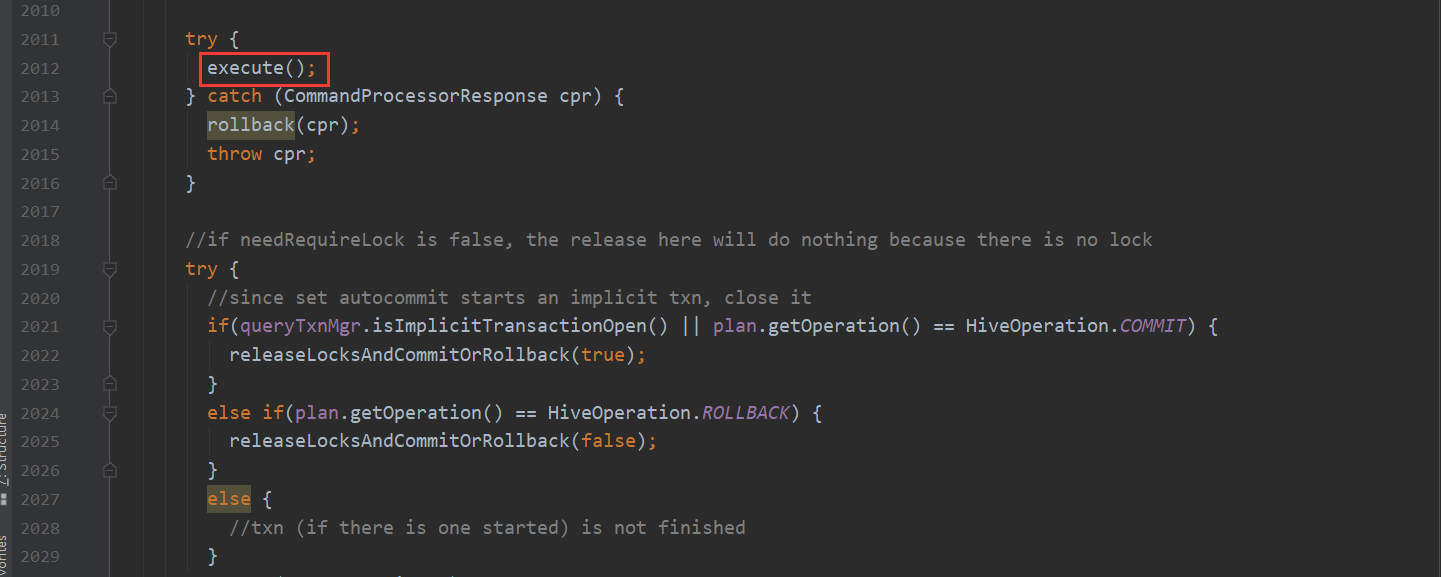
而runInternal这个方法 又包含两个步骤 一个是编译 一个是执行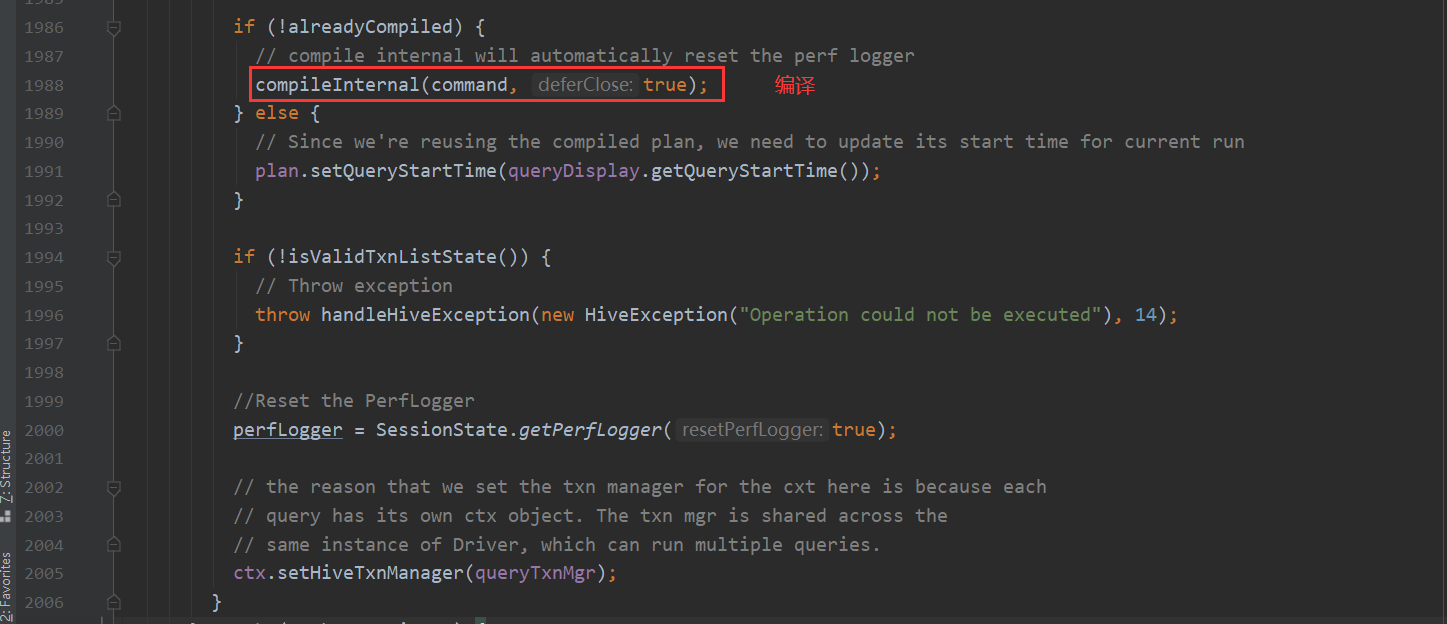
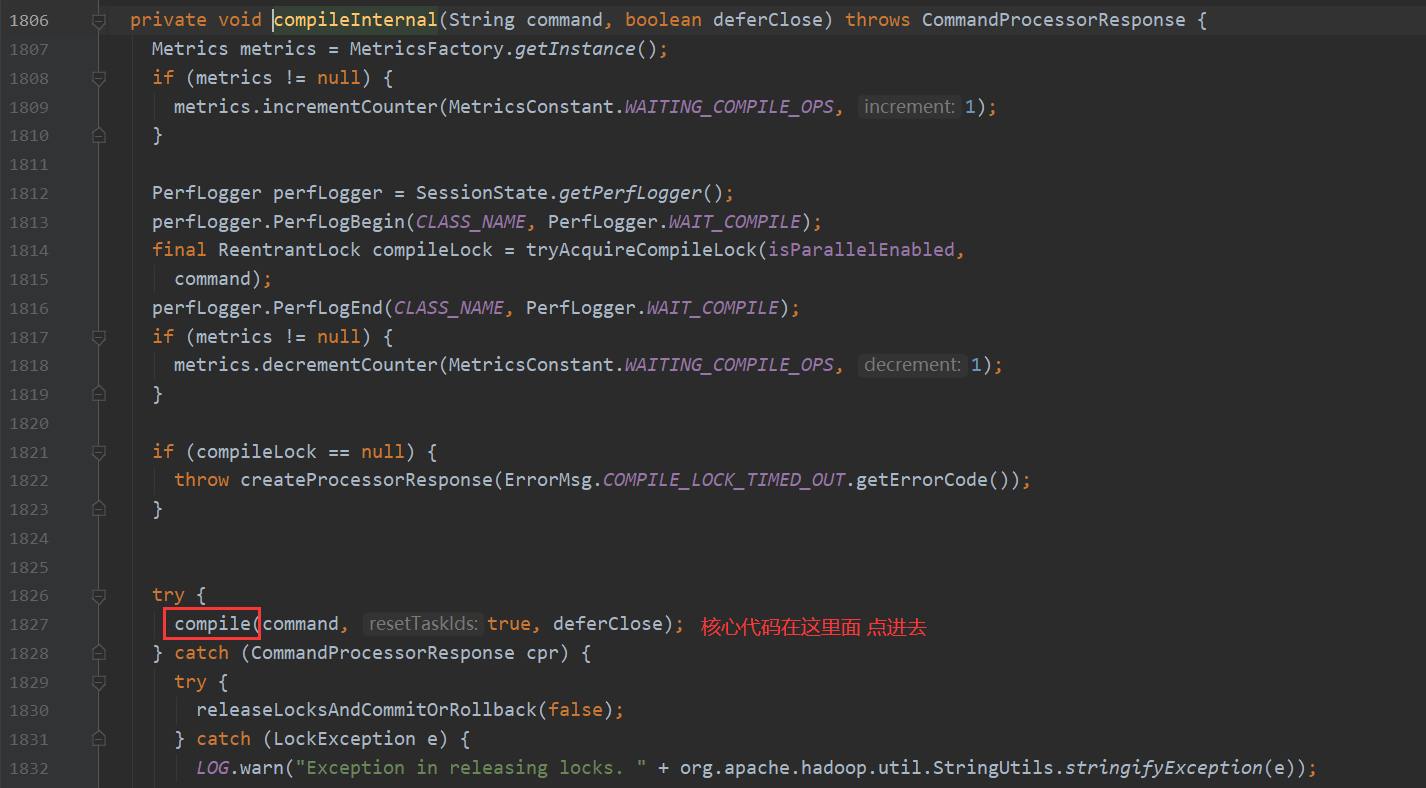
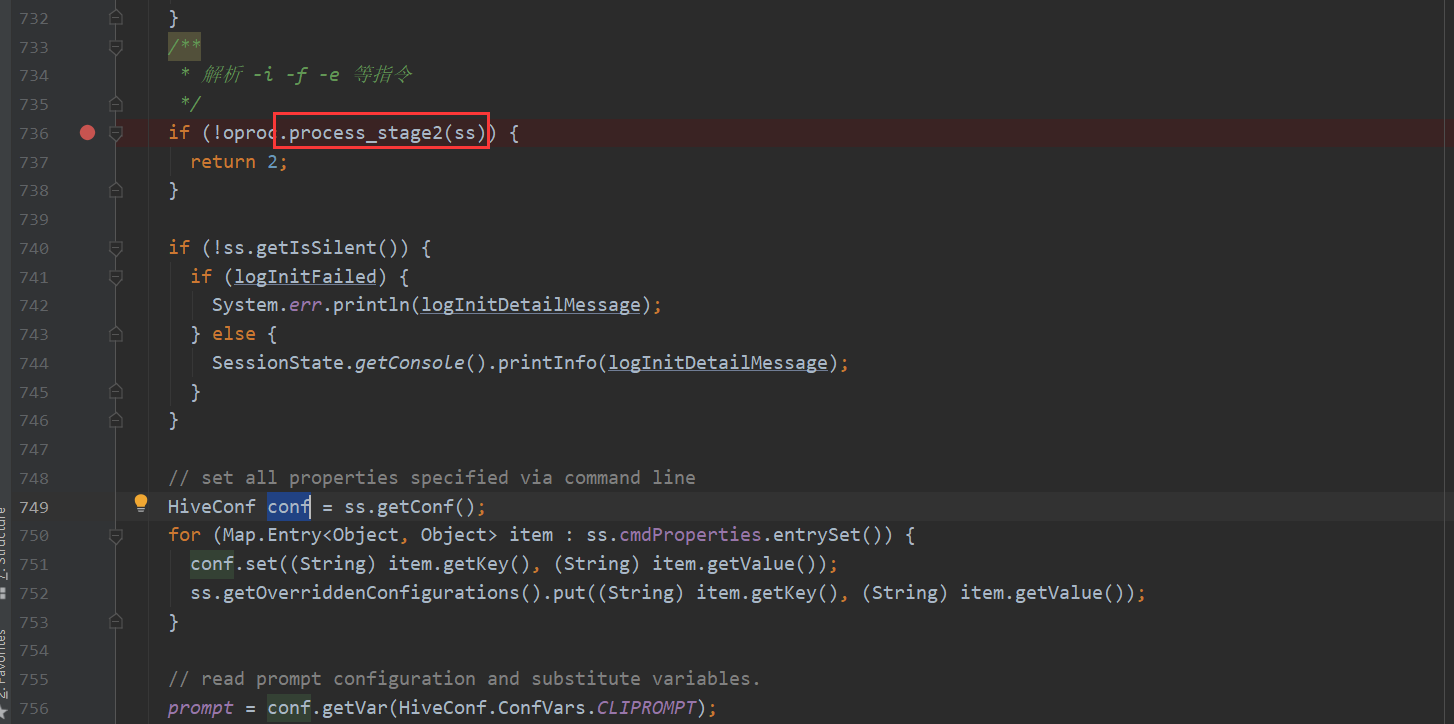
compile 里面包含三个步骤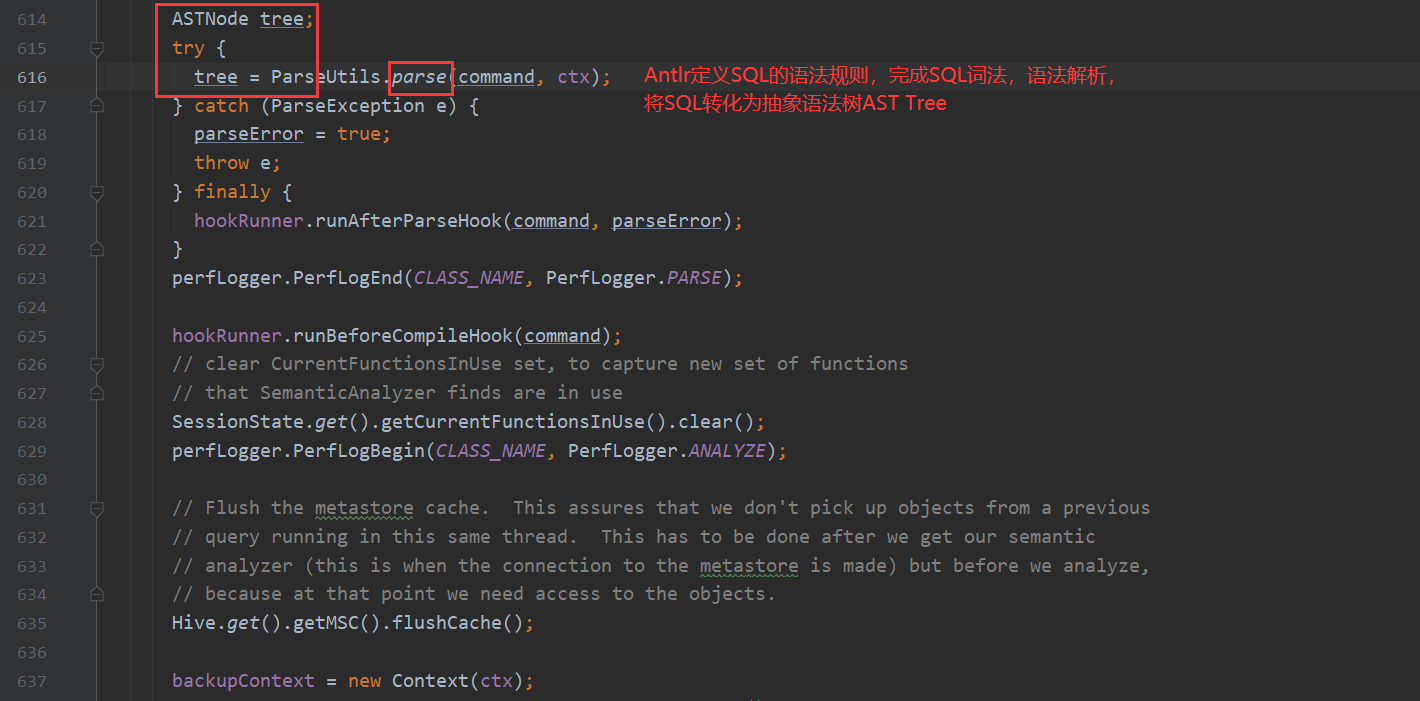
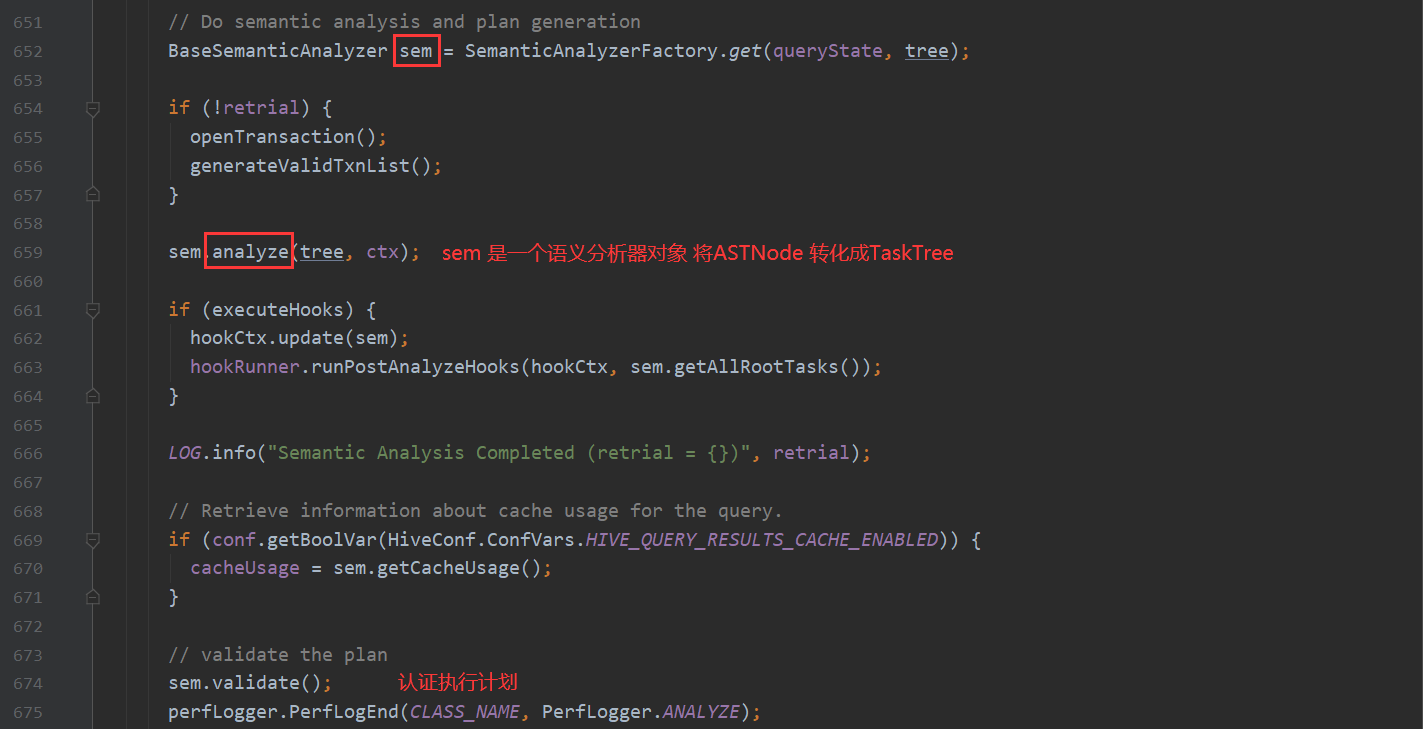
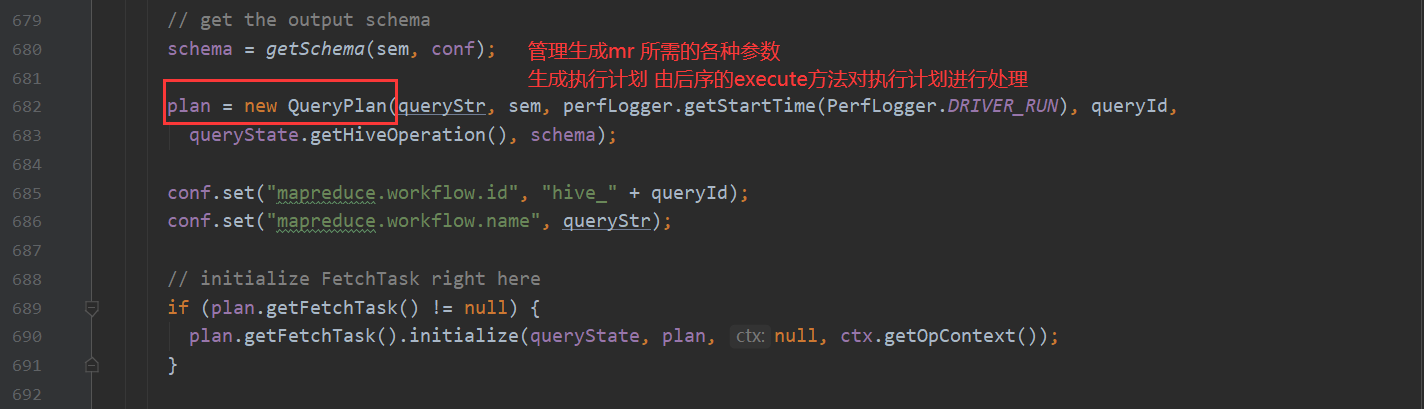
第一个步骤点进去 会看到
这里是靠antlr 的解析器对sql语句转化成 抽象语法树 ASTNode 如果想对antlr有过多的了解 根据下面链接 自行了解 这里不深入说明
antlr :https://baike.baidu.com/item/antlr/9368750?fr=aladdin
第二个步骤点进去 会看到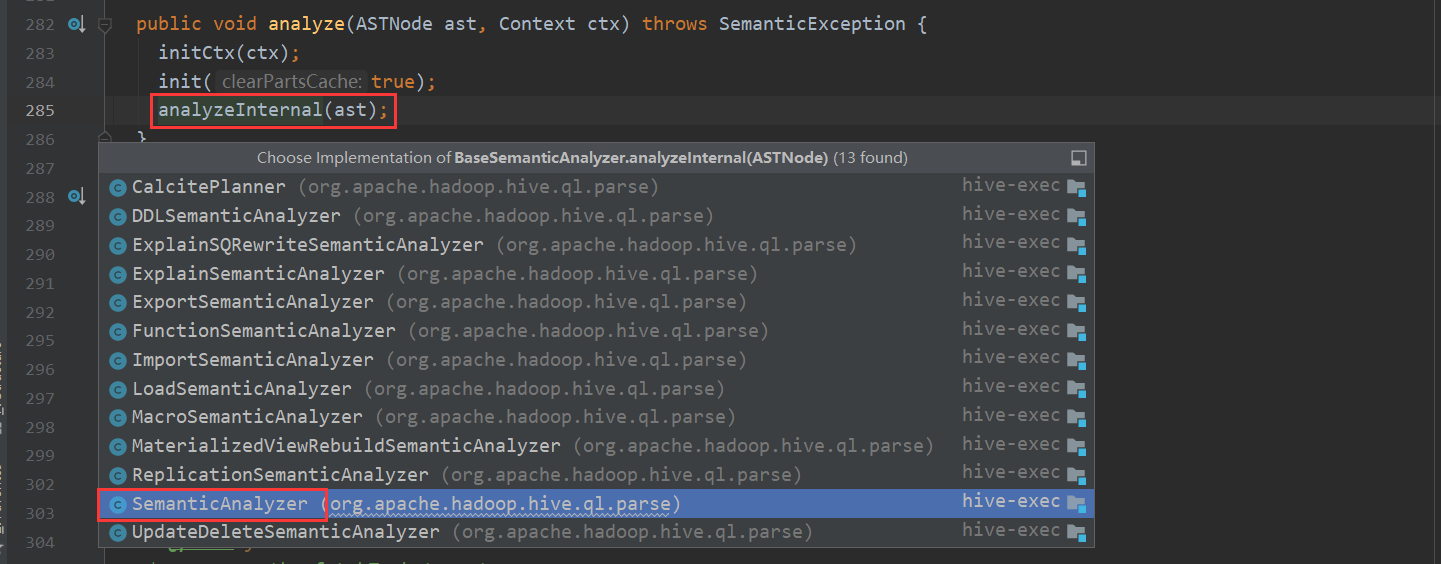

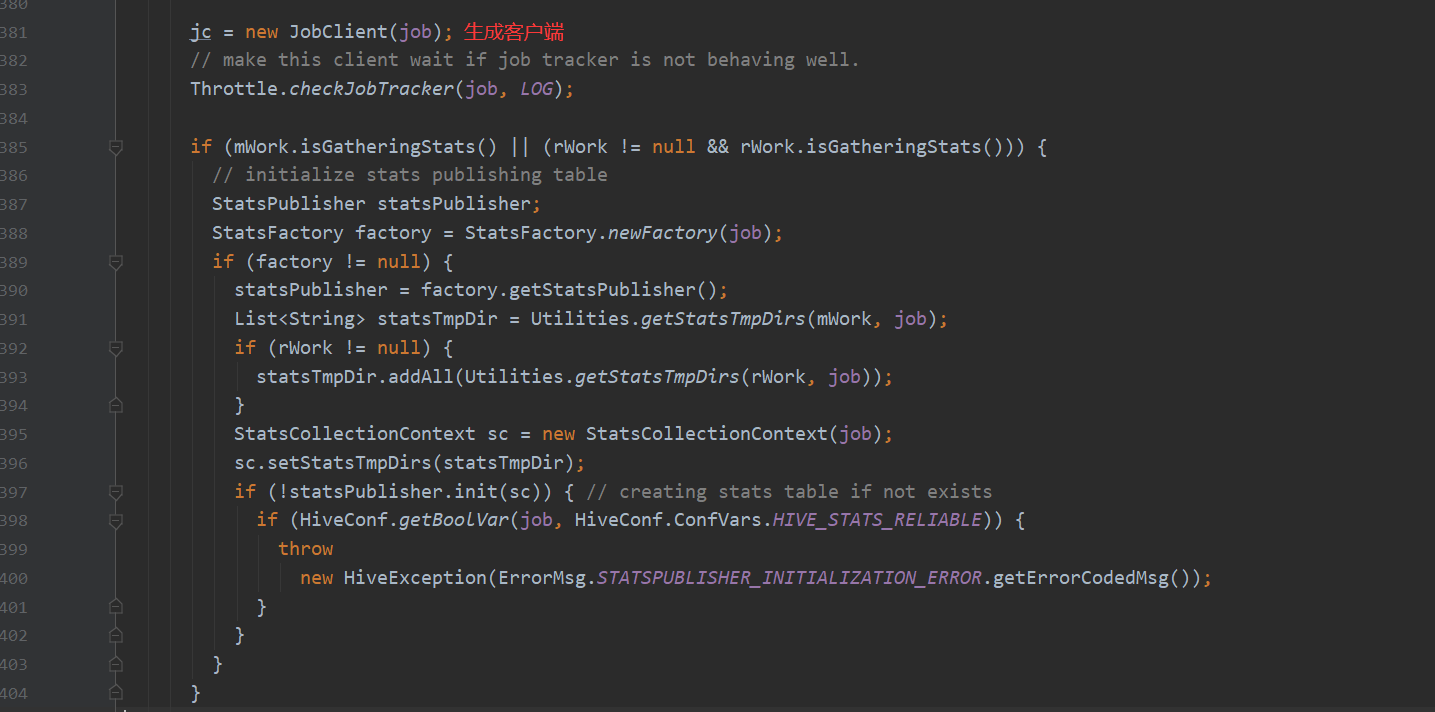
analyzeInternal 这个方法设计的很有意思 它包含了11个步骤 并且作者每个步骤处都写好了注释 一个个分开说明 下面来看一下这11个小步骤都干了什么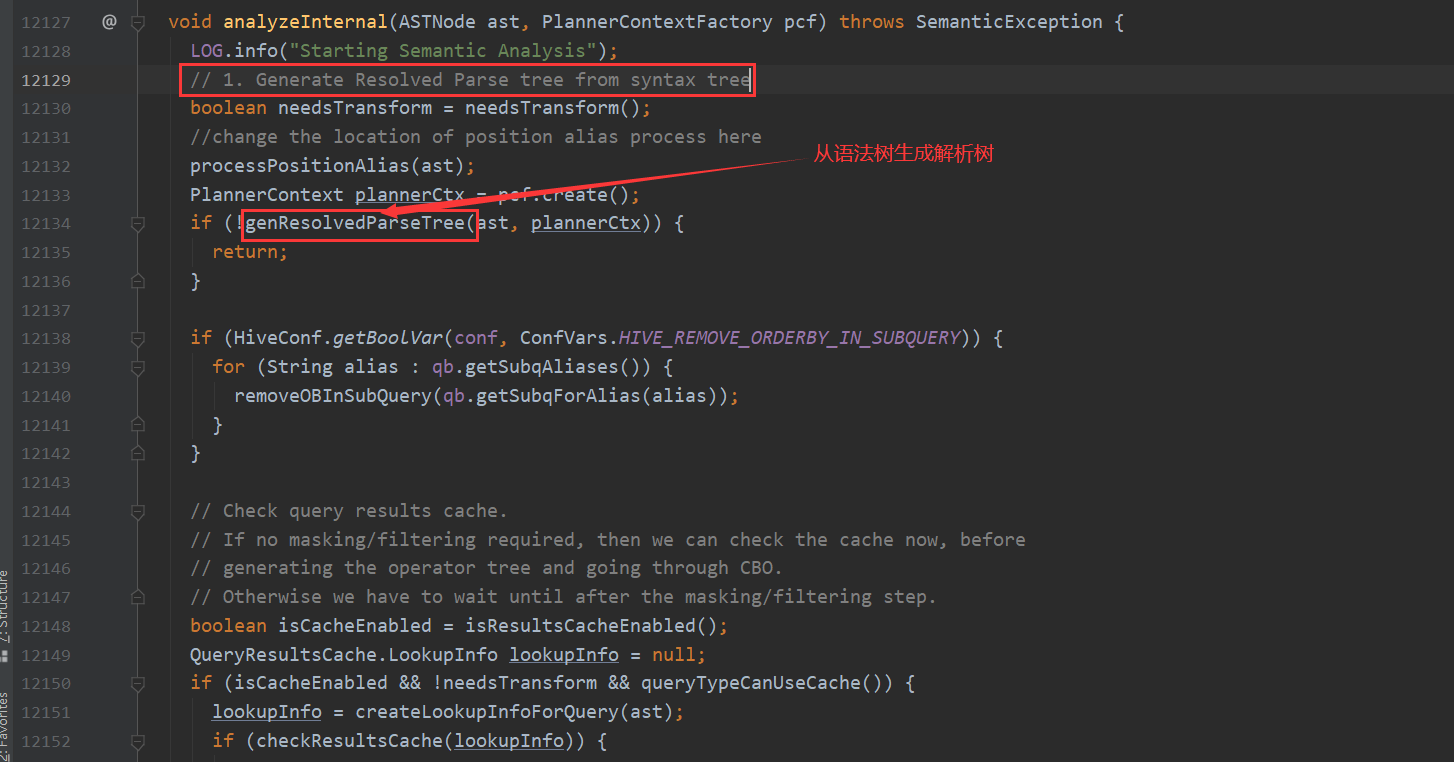
这里可以了解一下 Operator:
Operator
Hive最终生成的MapReduce任务,Map阶段和Reduce阶段均由OperatorTree组成。逻辑操作符,就是在Map阶段或者Reduce阶段完成单一特定的操作。
基本的操作符包括TableScanOperator,SelectOperator,FilterOperator,JoinOperator,GroupByOperator,ReduceSinkOperator
从名字就能猜出各个操作符完成的功能,TableScanOperator从MapReduce框架的Map接口原始输入表的数据,控制扫描表的数据行数,标记是从原表中取数据。JoinOperator完成Join操作。FilterOperator完成过滤操作
ReduceSinkOperator将Map端的字段组合序列化为Reduce Key/value, Partition Key,只可能出现在Map阶段,同时也标志着Hive生成的MapReduce程序中Map阶段的结束。
Operator在Map Reduce阶段之间的数据传递都是一个流式的过程。每一个Operator对一行数据完成操作后之后将数据传递给childOperator计算。
Operator类的主要属性和方法如下
RowSchema表示Operator的输出字段
InputObjInspector outputObjInspector解析输入和输出字段
processOp接收父Operator传递的数据,forward将处理好的数据传递给子Operator处理
Hive每一行数据经过一个Operator处理之后,会对字段重新编号,colExprMap记录每个表达式经过当前Operator处理前后的名称对应关系,在下一个阶段逻辑优化阶段用来回溯字段名
由于Hive的MapReduce程序是一个动态的程序,即不确定一个MapReduce Job会进行什么运算,可能是Join,也可能是GroupBy,所以Operator将所有运行时需要的参数保存在OperatorDesc中,OperatorDesc在提交任务前序列化到HDFS上,在MapReduce任务执行前从HDFS读取并反序列化。Map阶段OperatorTree在HDFS上的位置在Job.getConf(“hive.exec.plan”) + “/map.xml”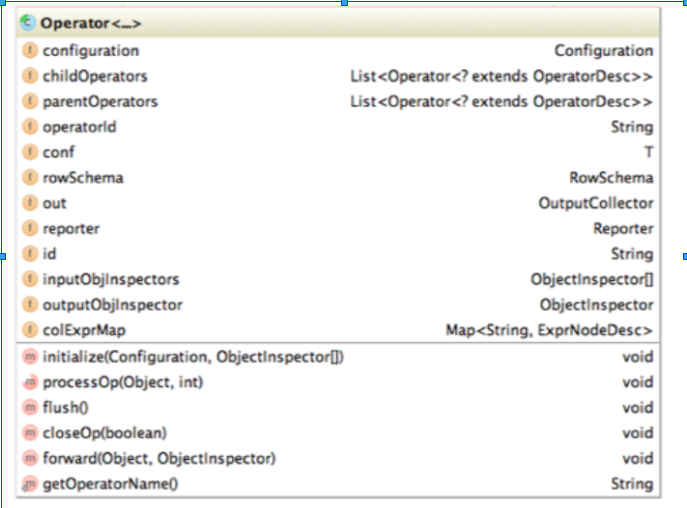
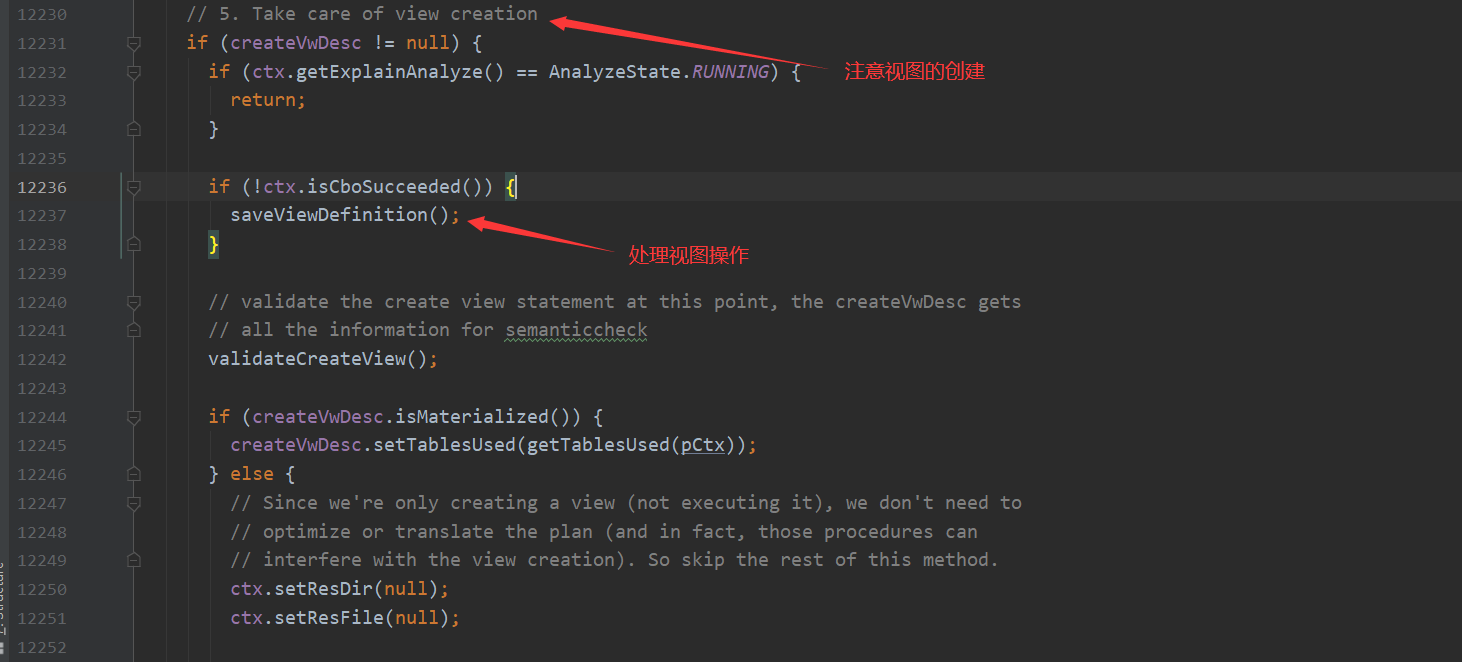
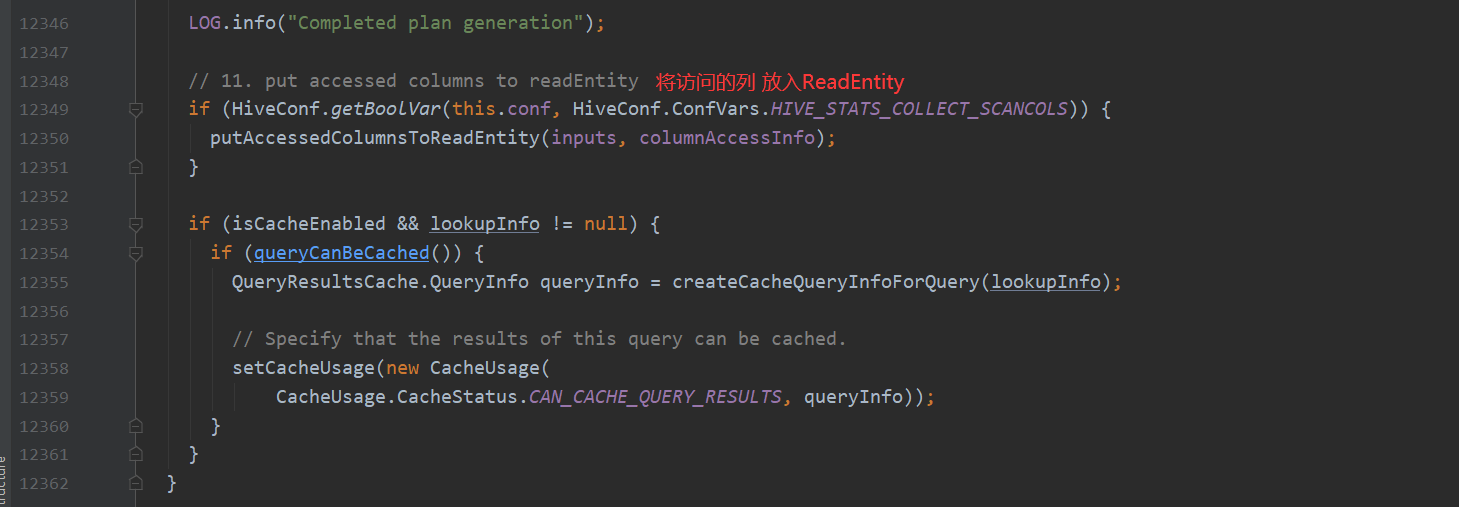
总结 上面这11小个步骤 验证了前面的文字流程
遍历AST Tree,抽象出查询的基本组成单元QueryBlock(步骤1)
遍历QueryBlock,翻译为执行操作树OperatorTree(步骤2)
逻辑层优化器进行OperatorTree变换,合并不必要的ReduceSinkOperator,减少shuffle数据量(步骤7)
在这些步骤走完之后 compileInternal方法会生成一个执行计划 交给execute方法处理 接下来就看execute方法如何转换MapReduce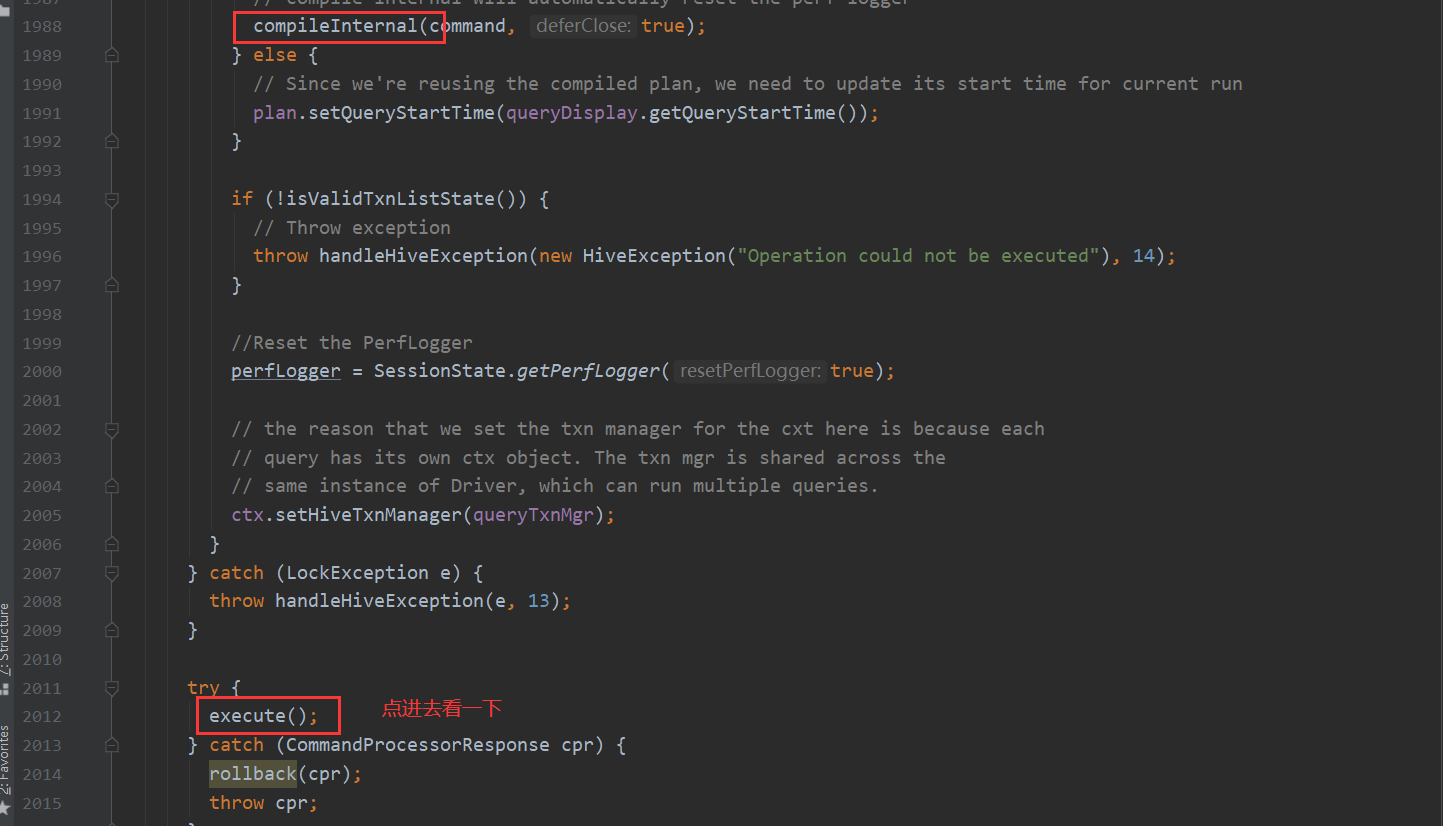
有几个点需要注意一下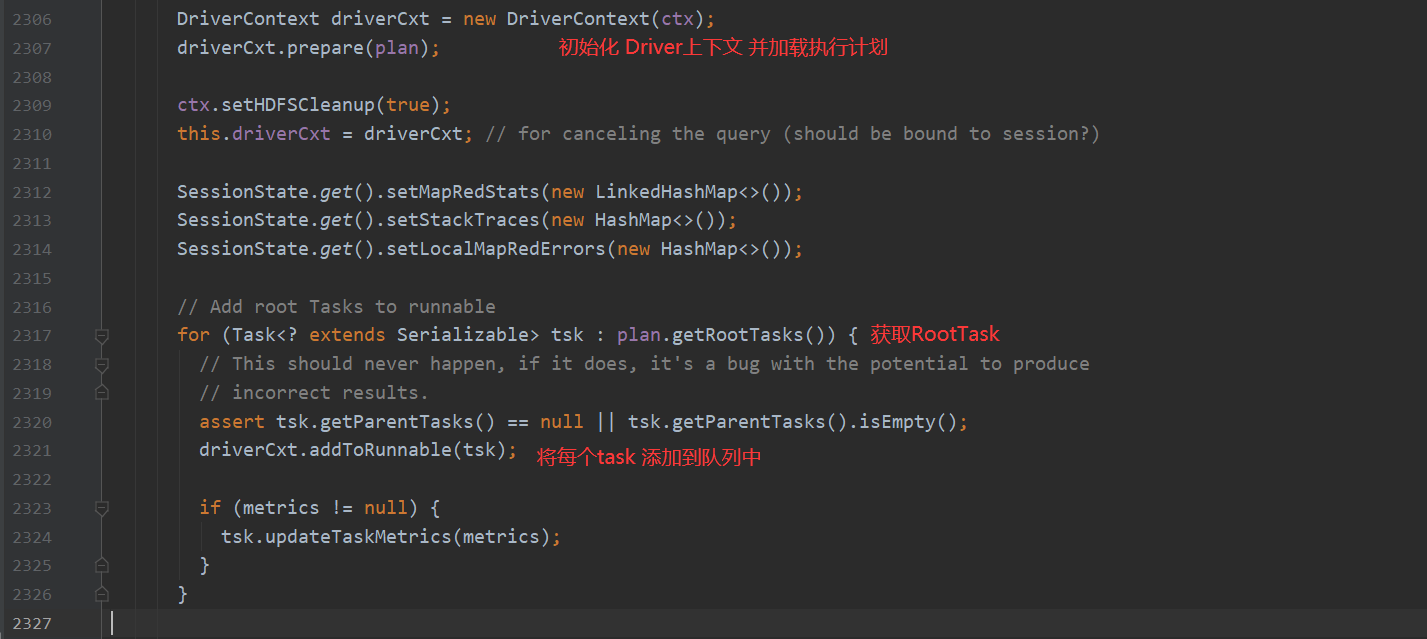
下面基本就是转换MapReduce的入口了 后面详解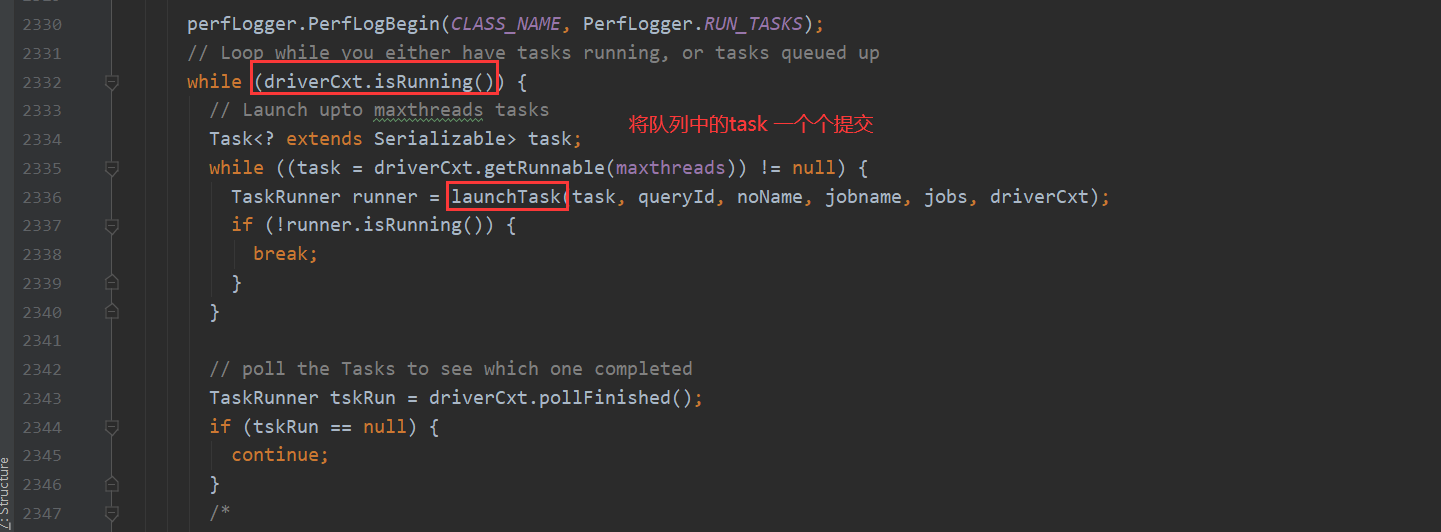
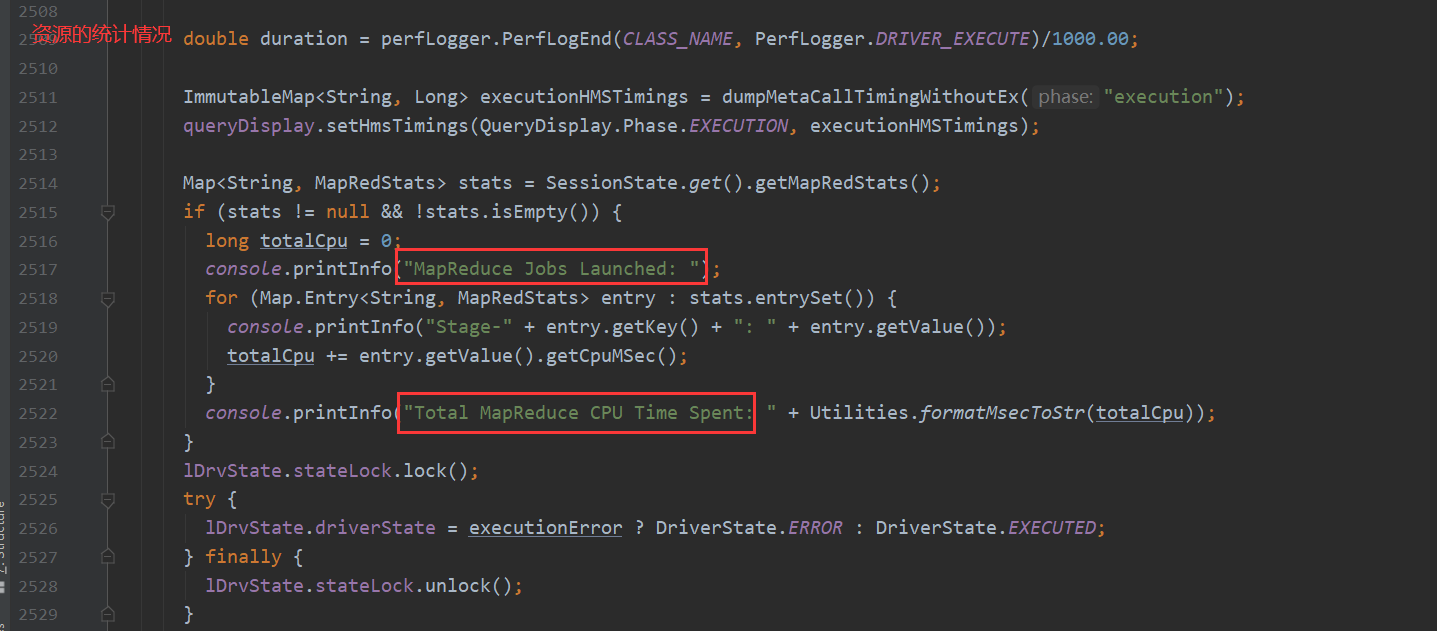
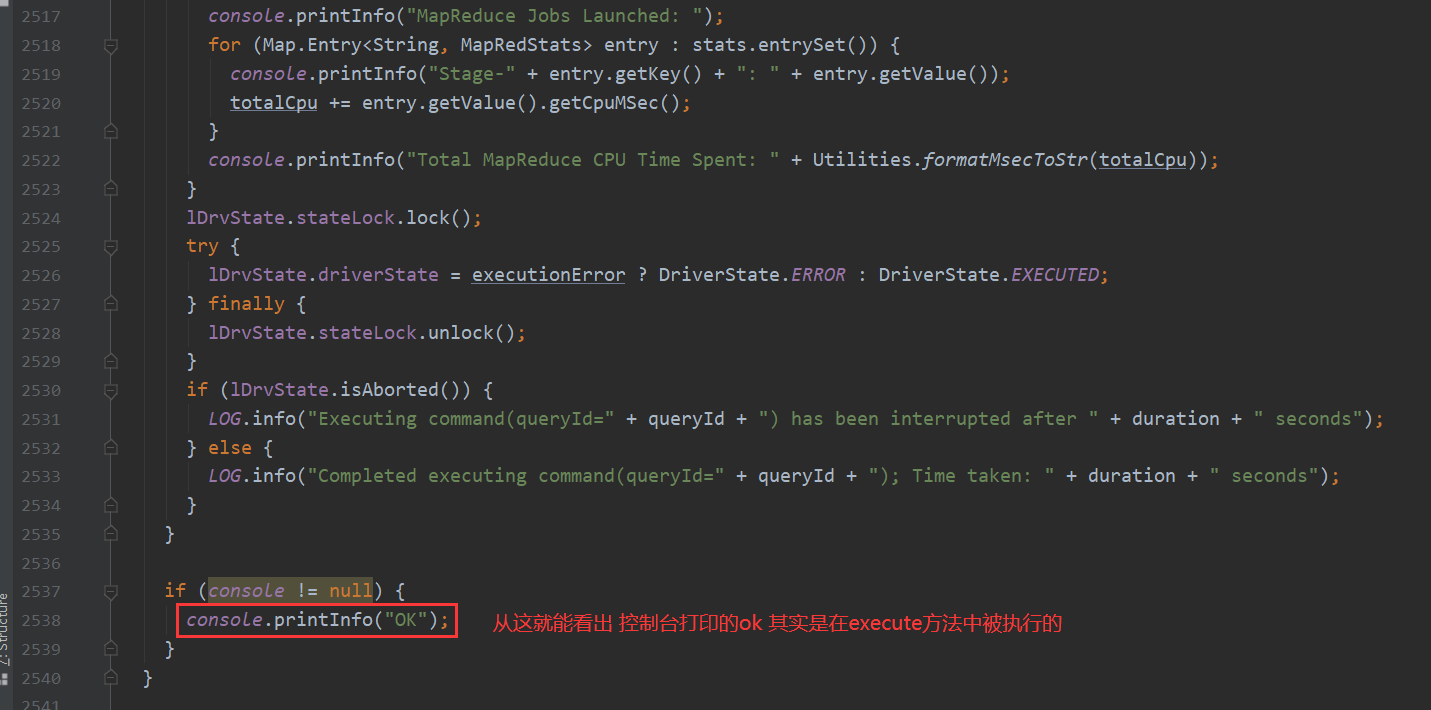
由此 基本可以了解HQl转换MapReduce的整个流程
先是做一些判断处理 然后处理sql 再切分遍历执行每条sql 然后先通过antlr 根据语法文件 生成语法 词法解析器 将sql解析成抽象语法树 ASTNode 再将它解析成QB 然后翻译成一个个的OperatorTree 接下来处理一下逻辑优化 最后生成执行计划 交给execute执行 它将task取出 放入队列然后一个个提交任务 最后得出结果 打印ok 最后对返回数据的控制台打印处理。
整体流程说完了 接下来详细说明一下 转换MapReduce的入口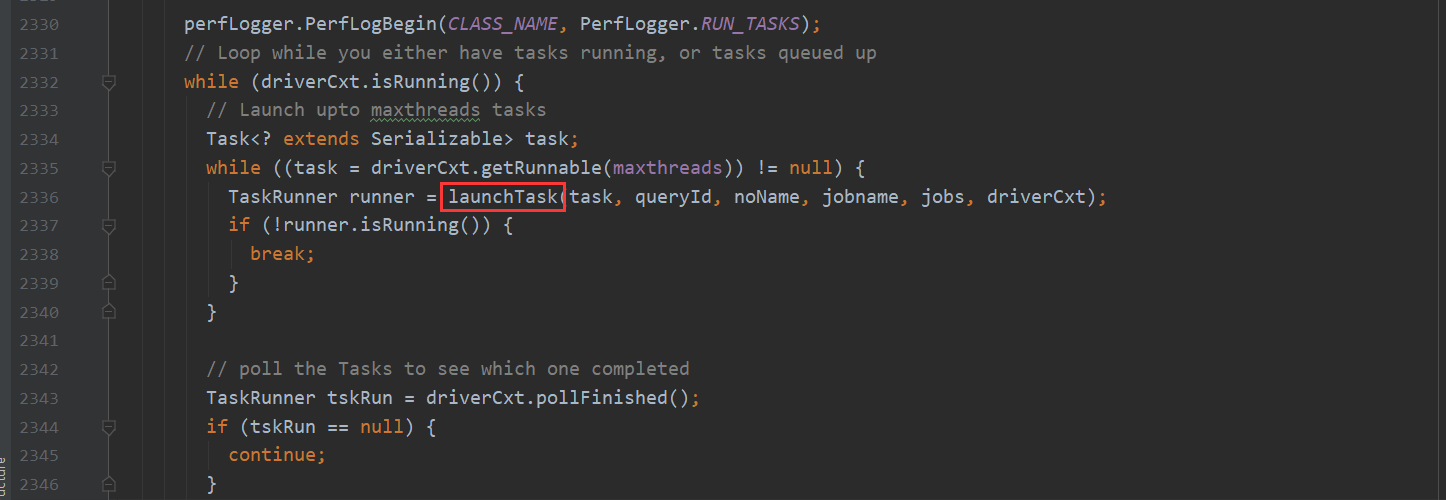
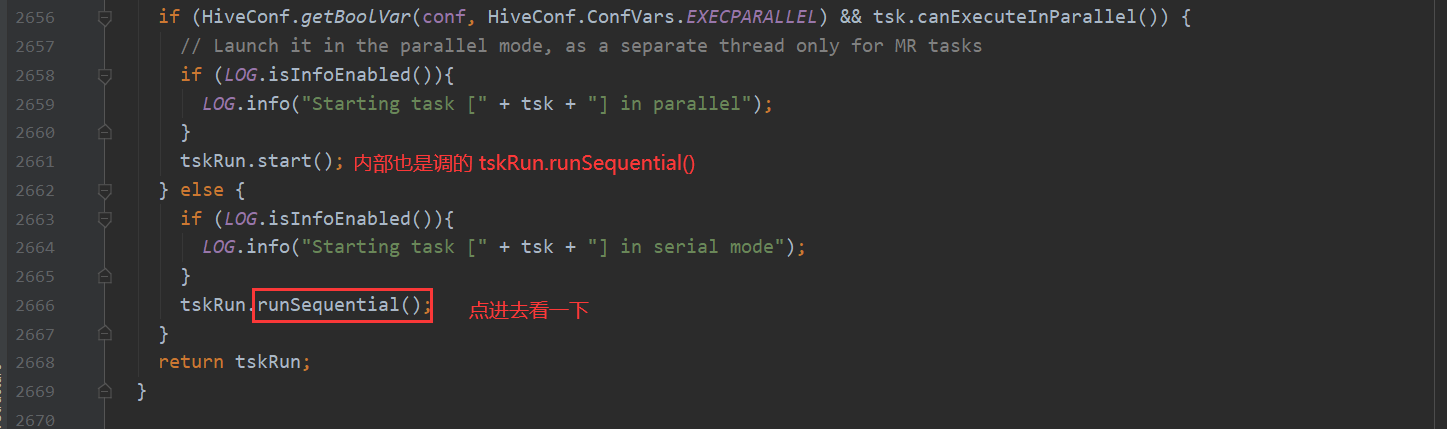
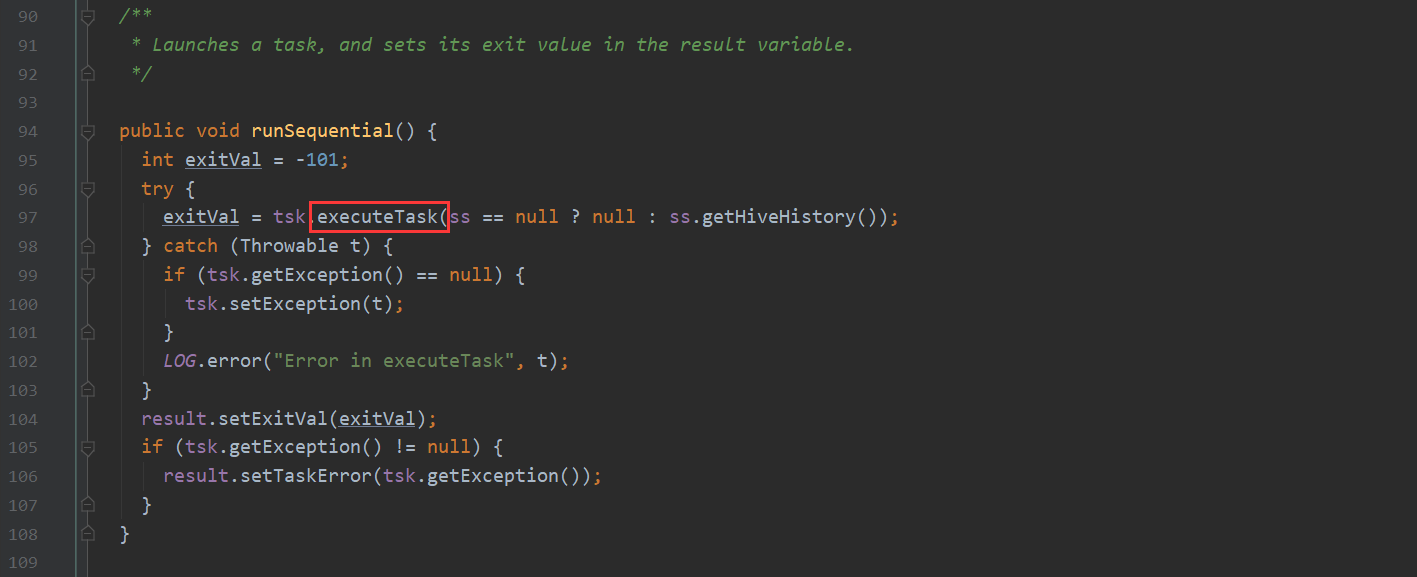
execute 这个方法很重要 根据task的类型不同 进行不同计算引擎的任务提交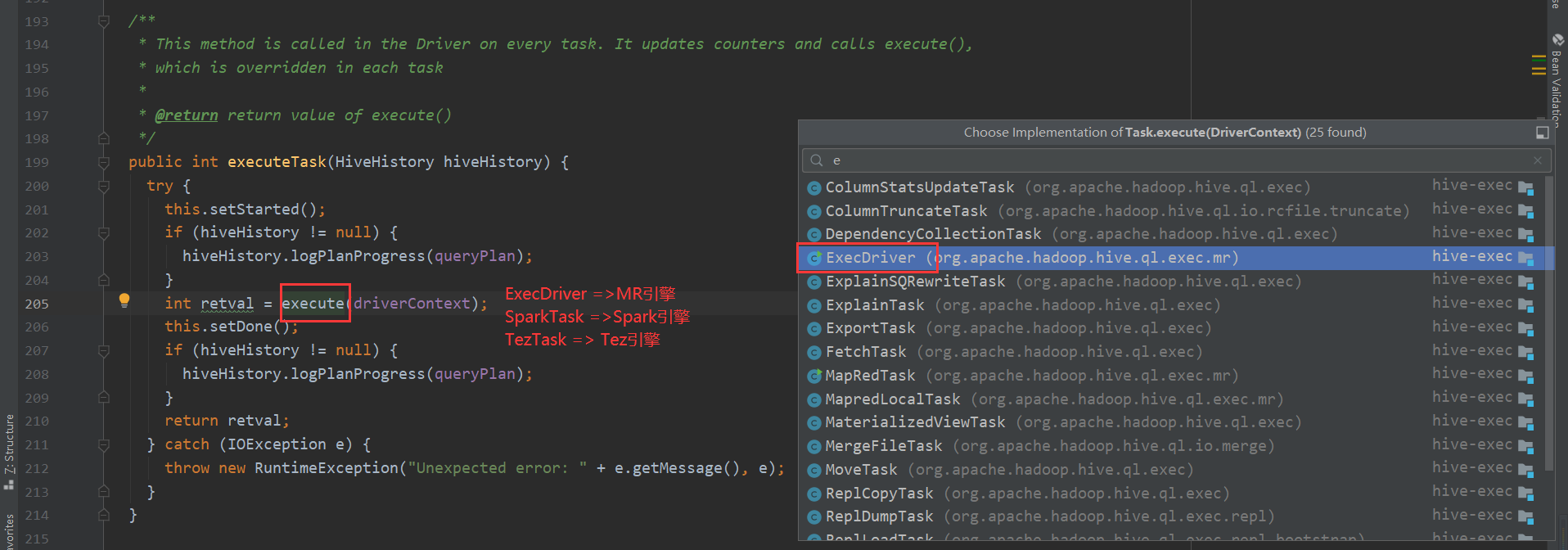
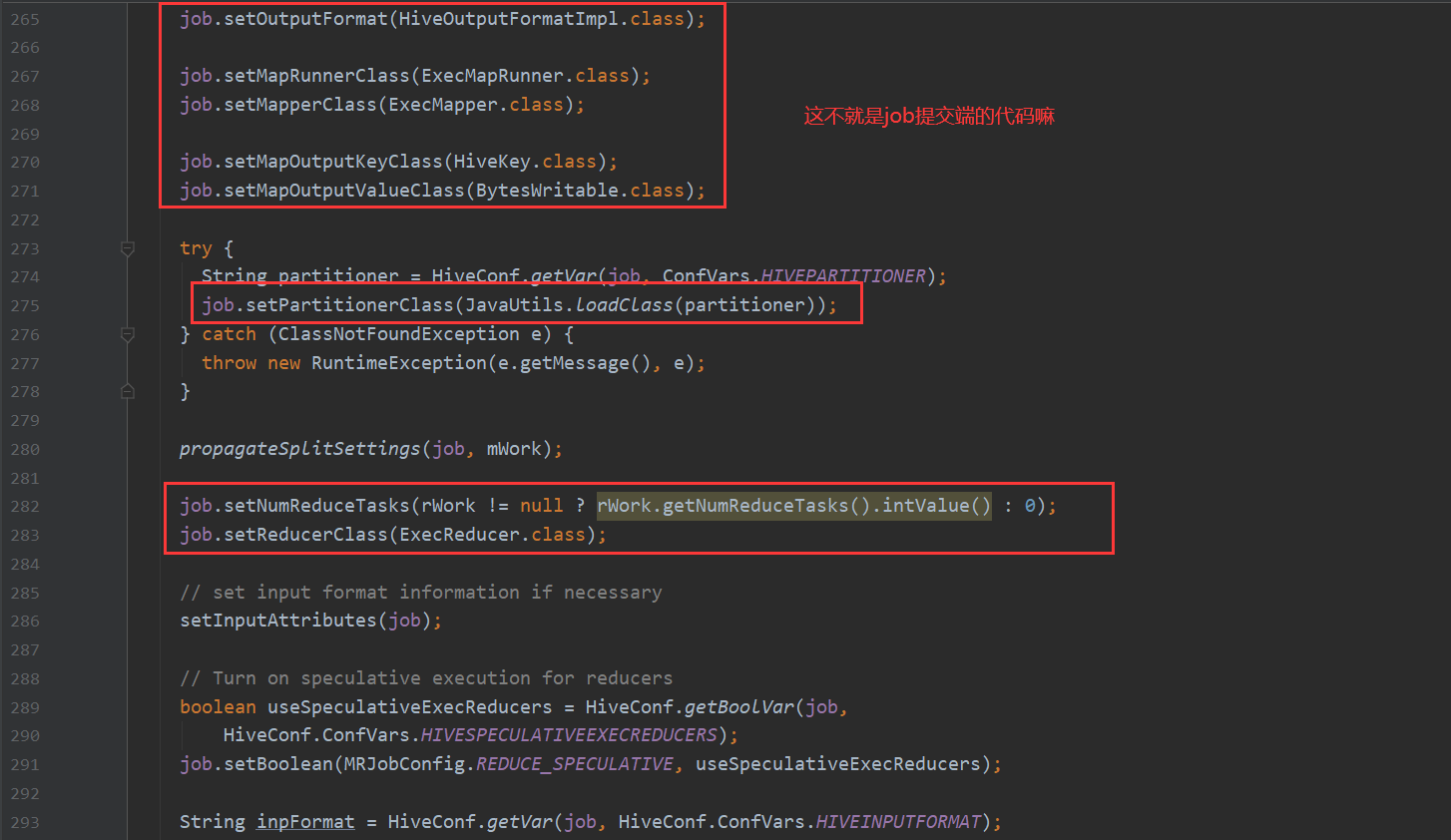
先看一下MR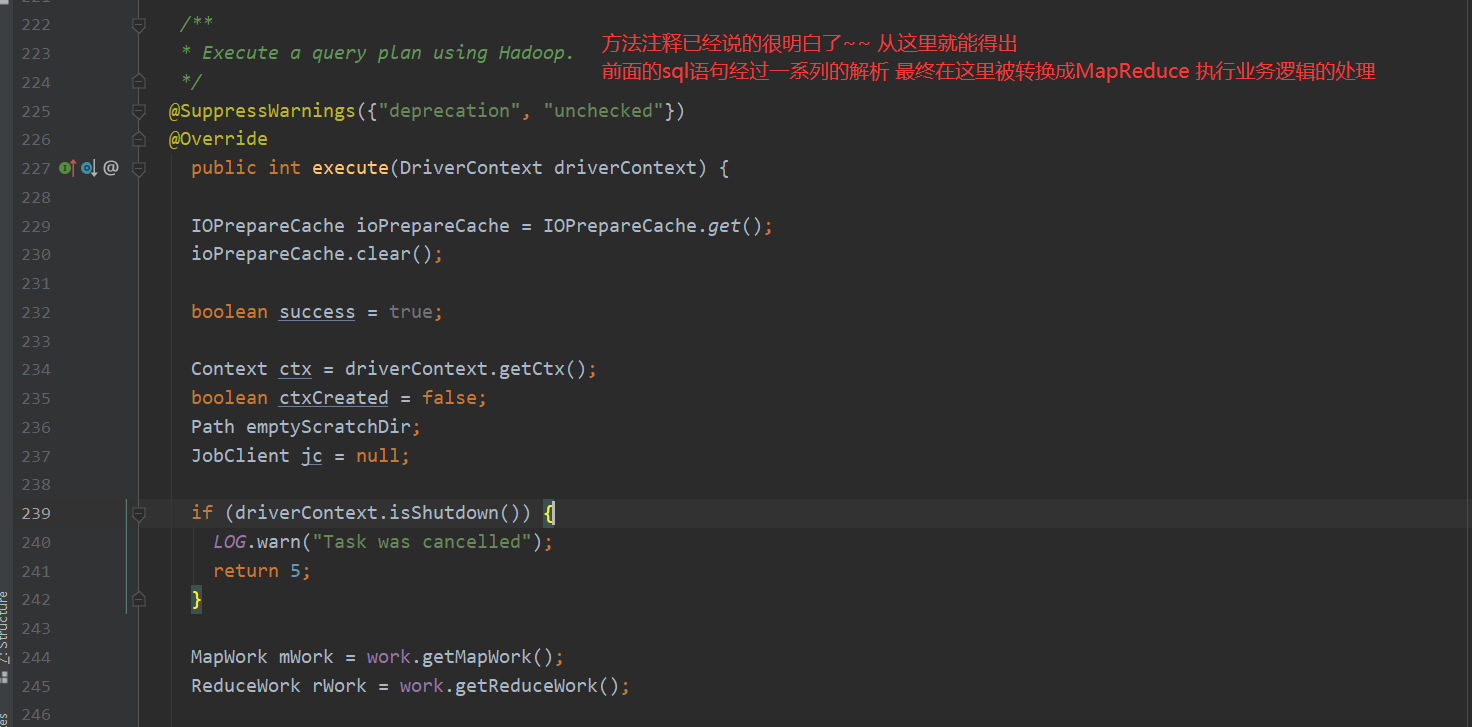
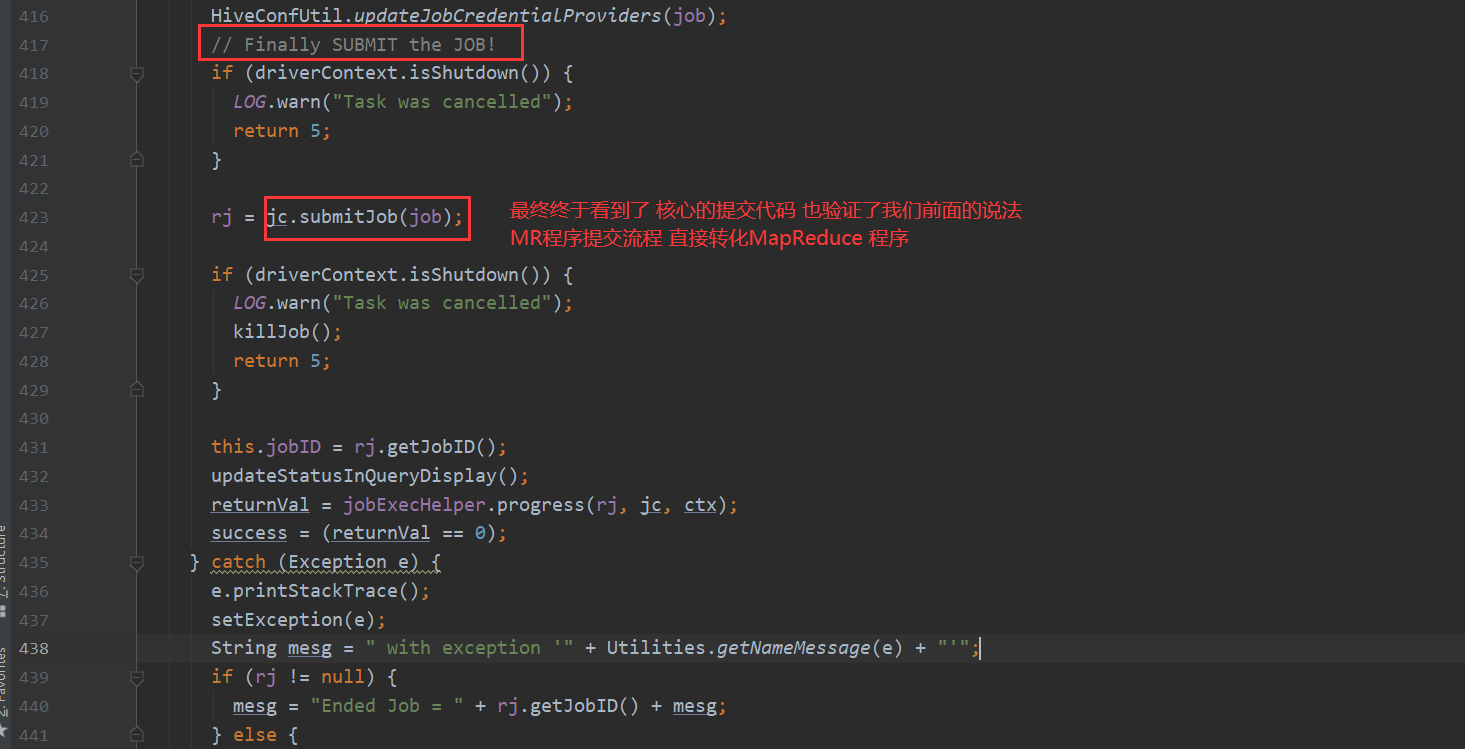
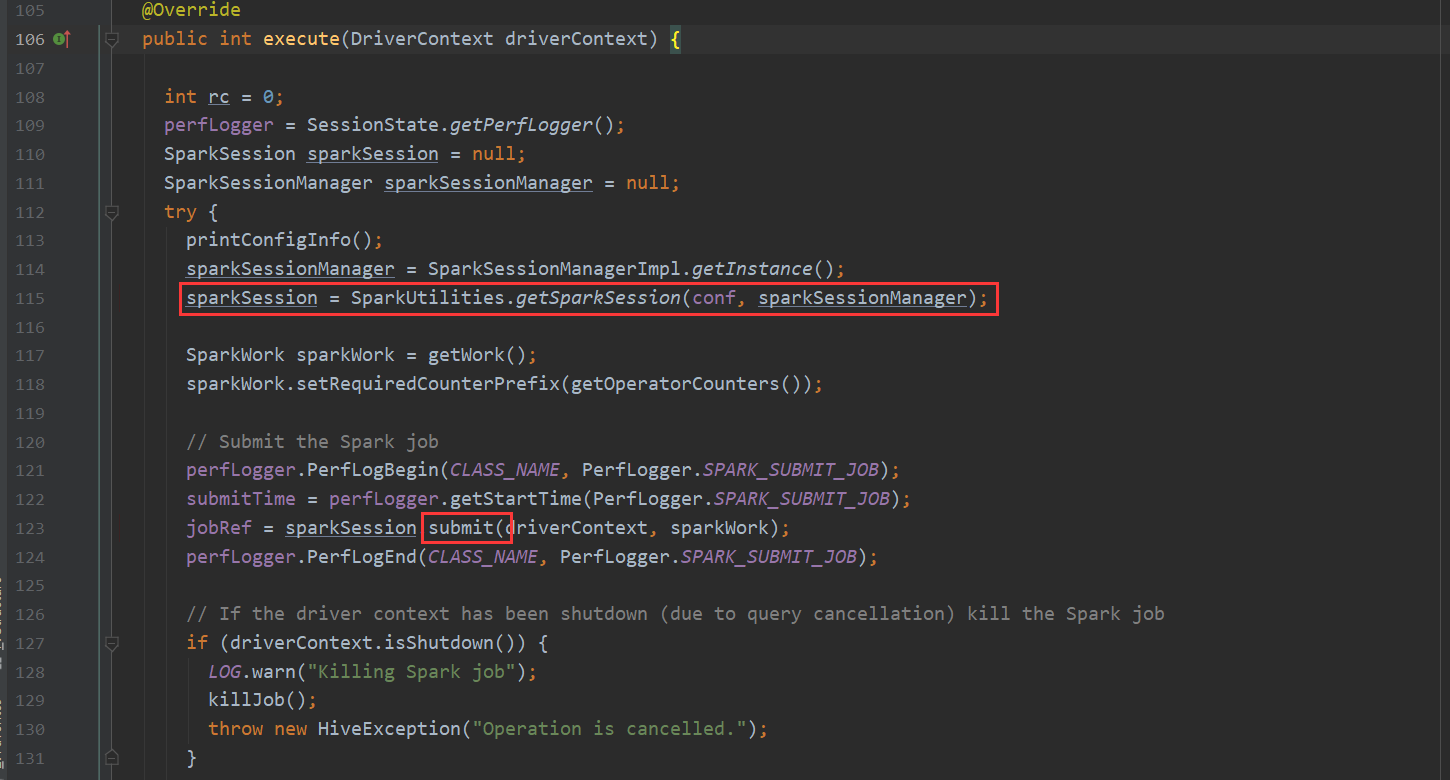
再看一下 Spark 我们都知道hive-on-Spark的说法 那么底层调用也是在这里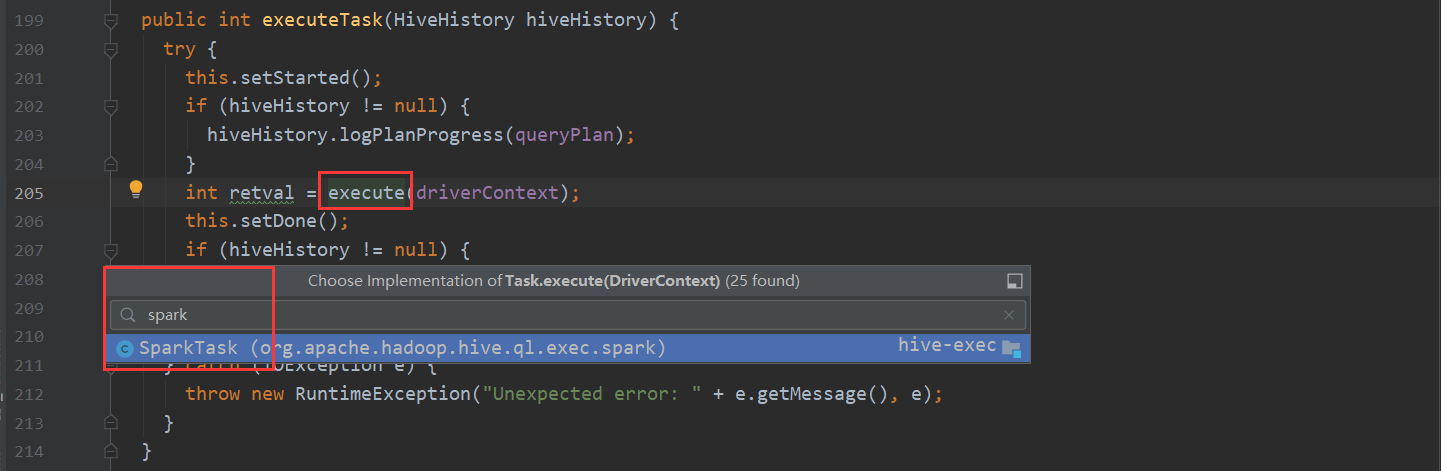

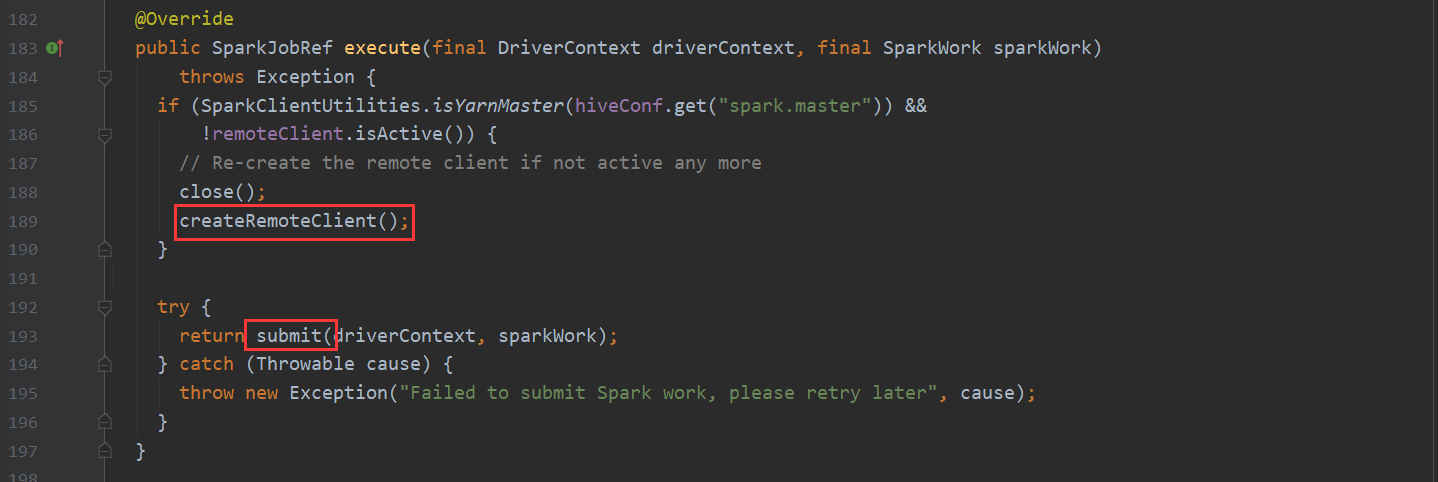
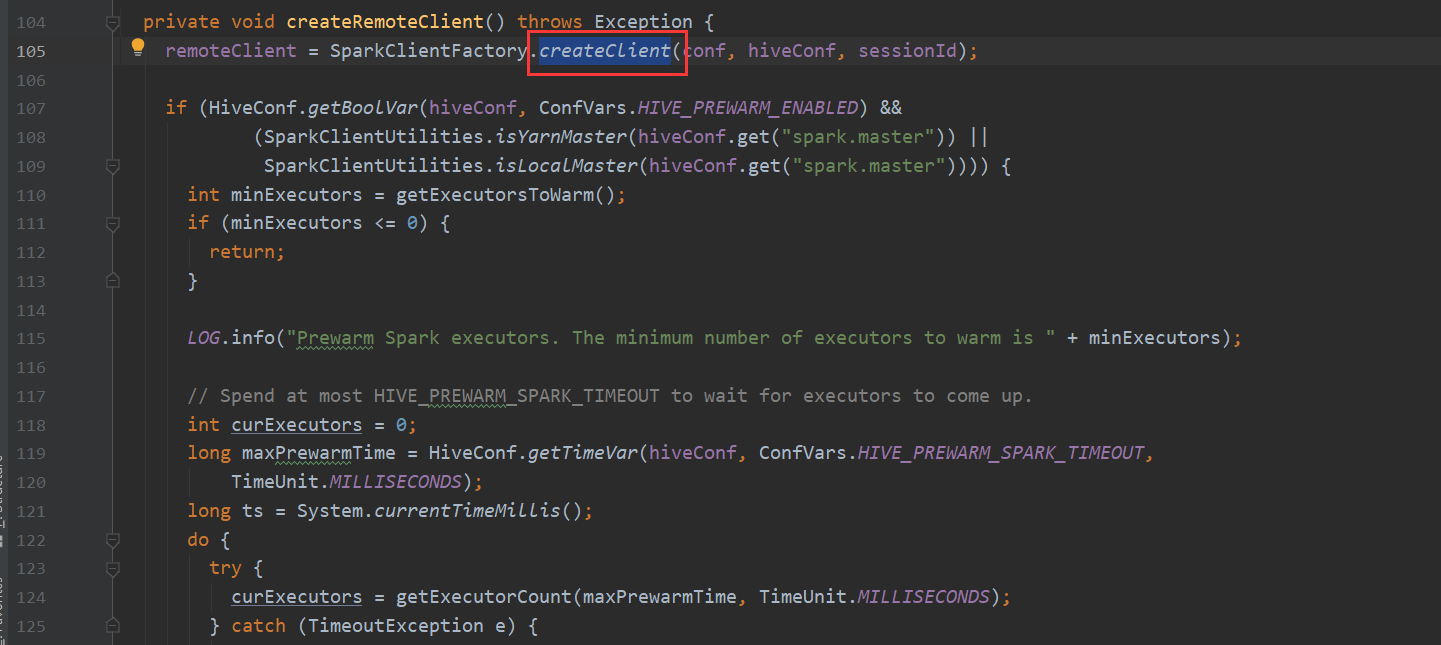
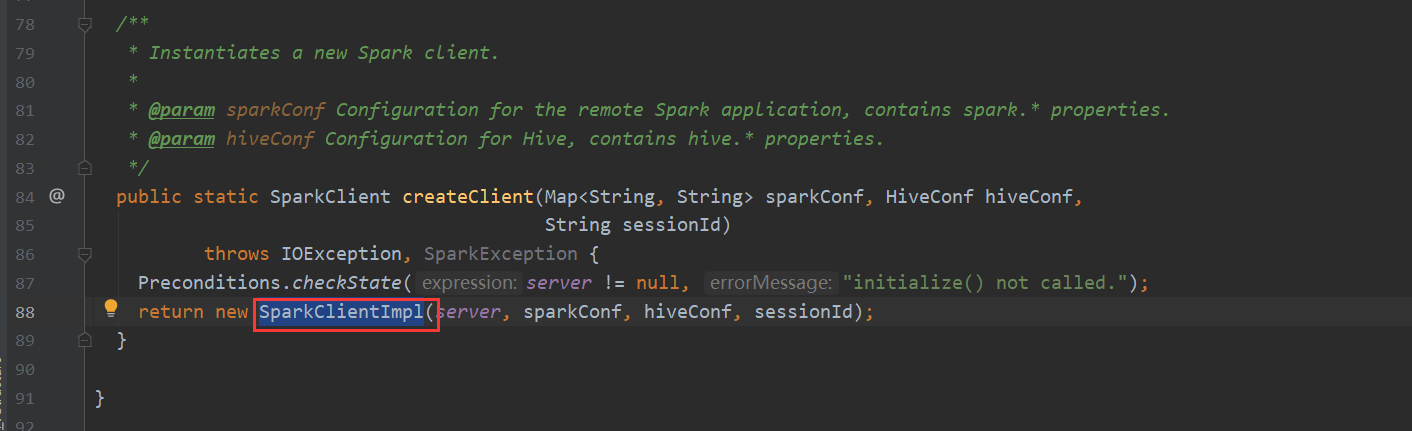
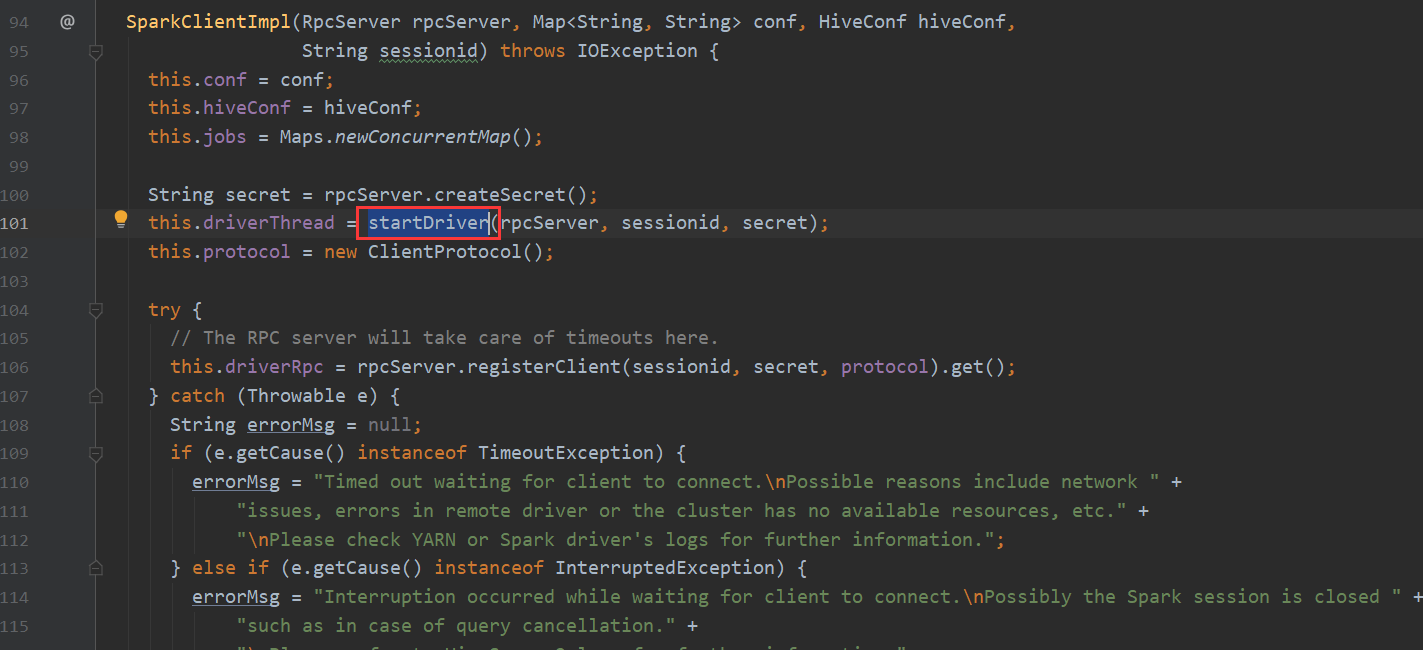
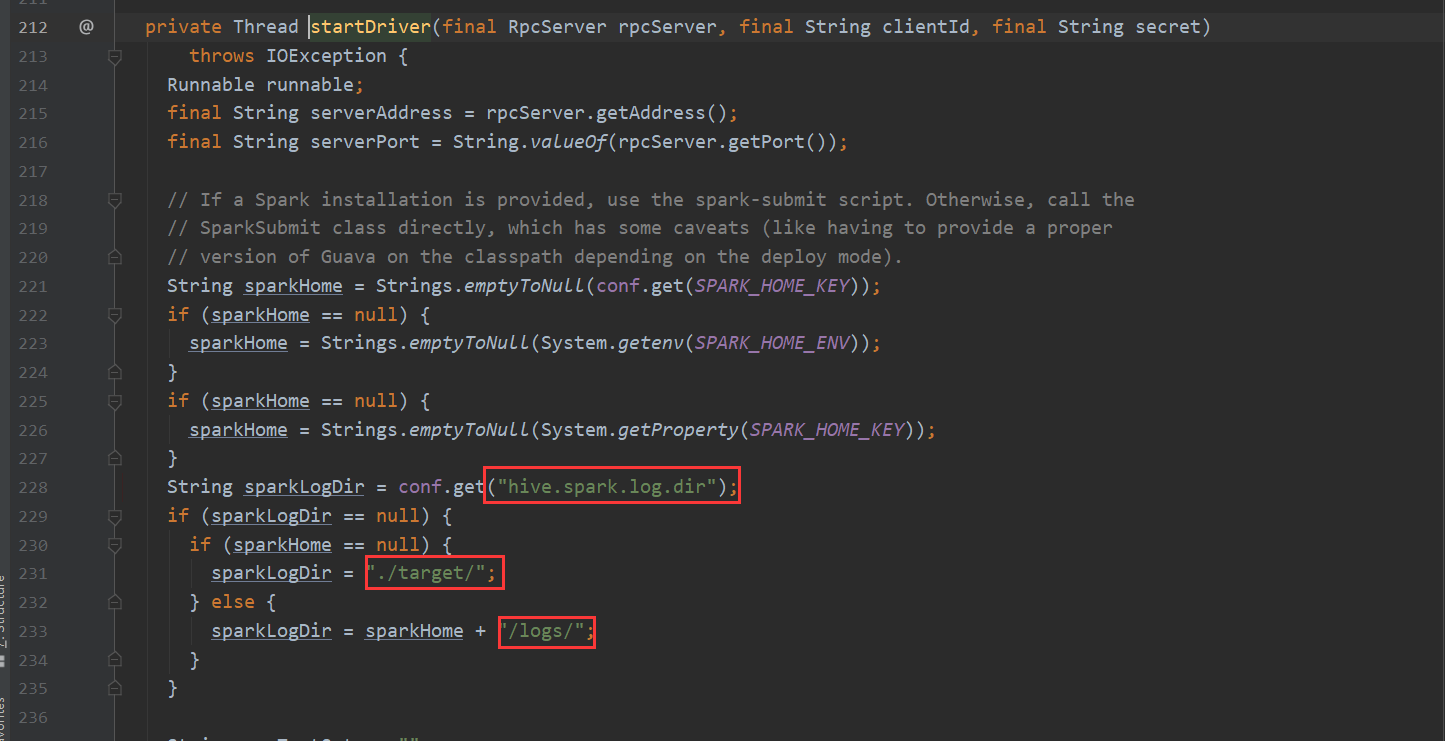
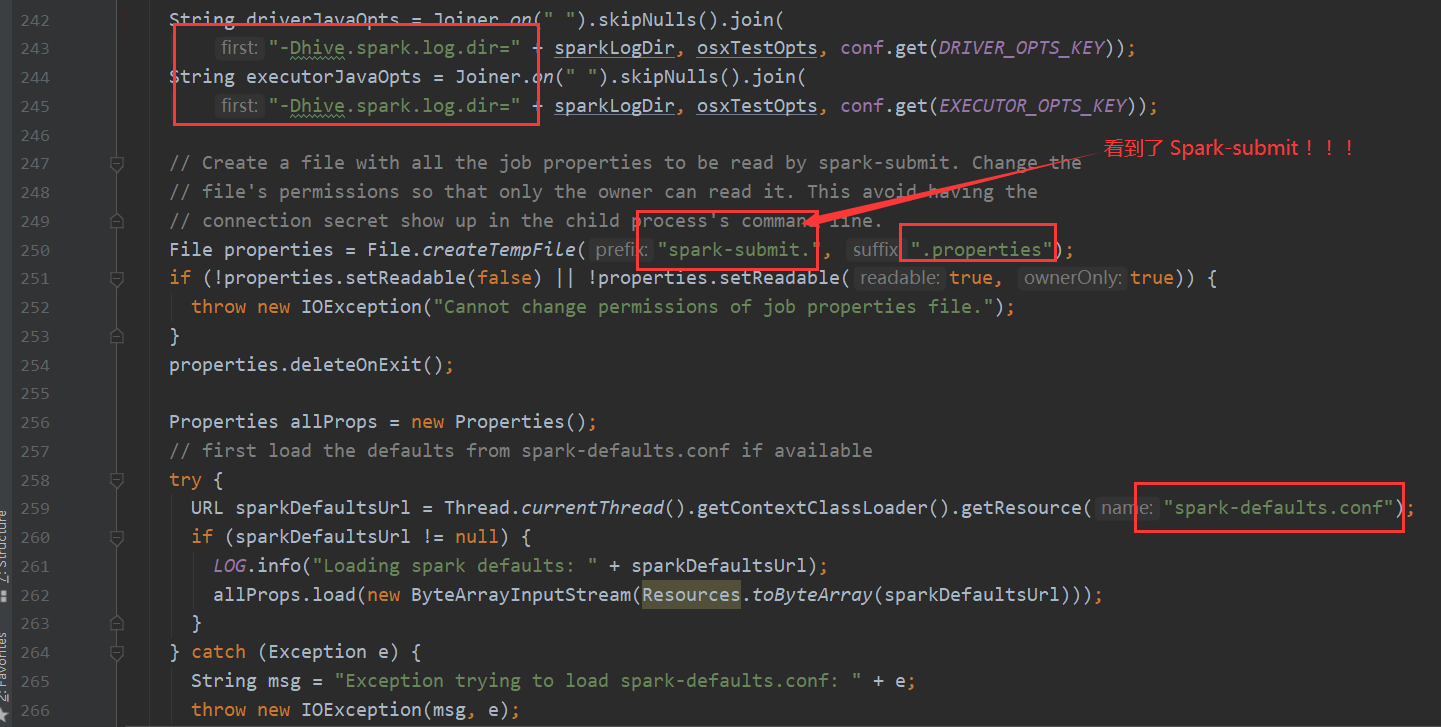
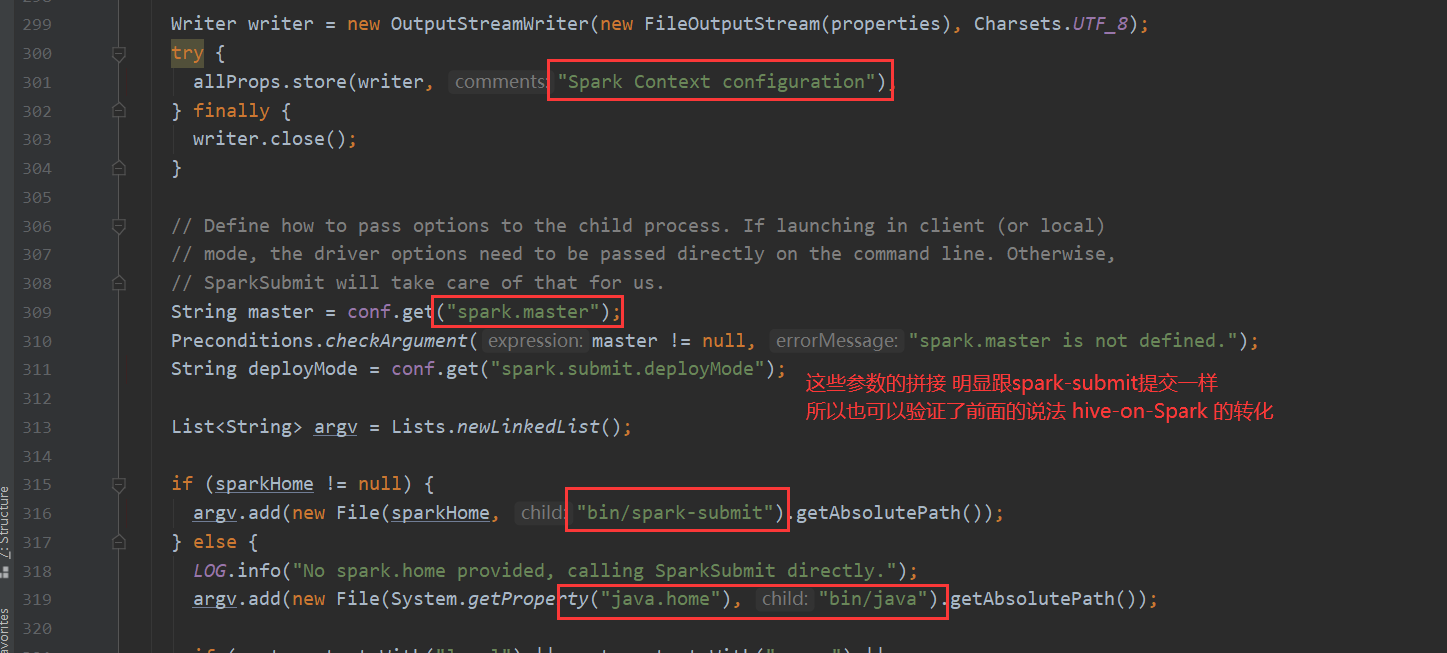
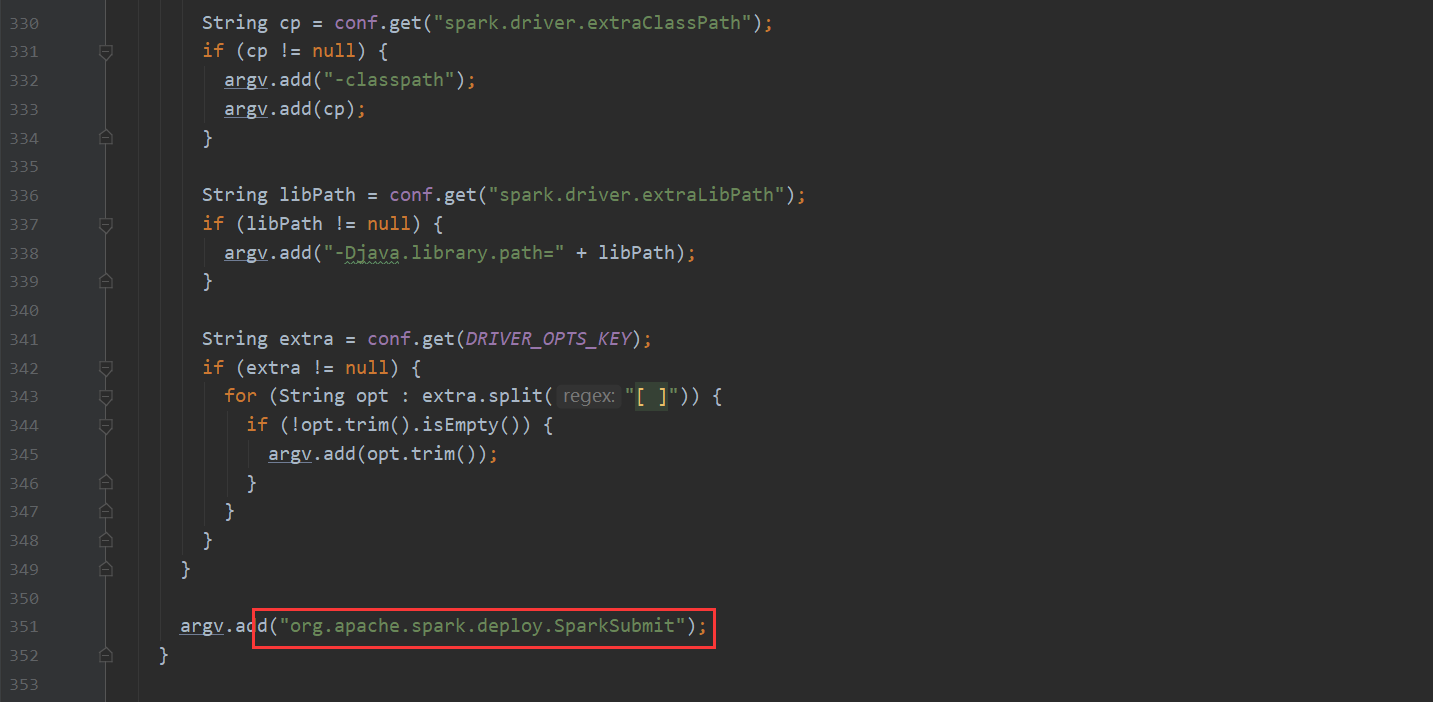
TezTask 不再赘述。
总结:
hive的源码还是值得去学习和思考的
前面通过不同的Task类型 进行可插拔的多计算引擎的选择
不同的类型 不同的提交逻辑 提高程序的高扩展性。

若有收获,就点个赞吧
0 人点赞
