列式存储格式的适用场景
列式存储,顾名思义就是按照列进行存储数据,把某一列的数据连续的存储,每一行中的不同列的值离散分布。列式存储技术并不新鲜,在关系数据库中都已经在使用,尤其是在针对OLAP场景下的数据存储,由于OLAP场景下的数据大部分情况下都是批量导入,基本上不需要支持单条记录的增删改操作,而查询的时候大多数都是只使用部分列进行过滤、聚合,对少数列进行计算(基本不需要select * from xx之类的查询)。
下图展示了行和列的区别: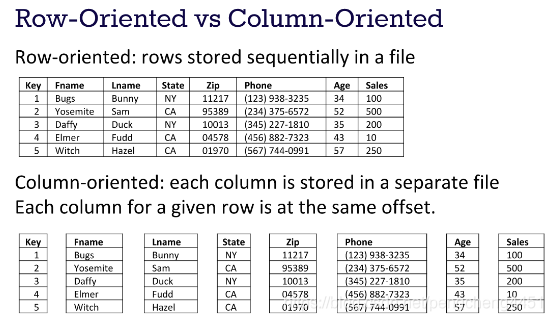
列式存储:
- 只需查询某些列
- 需要大量数据做聚合操作
- 对存储空间较敏感
行式存储:
- 只需查询某些行
- 对数据经常有增删改的要求,俗称的OLTP
行列存储的优缺点
列式存储主要优点表现在三块:压缩(列类型一样,更好的压缩比,省空间)、投影下推(只需读取某些列,不需要读取整行)、谓词下推(过滤条件)
| 项目 | 行式存储 | 行式存储 |
|---|---|---|
| 优点 | 数据被保存在一起 INSERT/UPDATE容易 |
查询时只有涉及到的列会被读取 投影(projection)很高效 任何列都能作为索引 |
| 缺点 | 选择(Selection)时即使只涉及某几列,所有数据也都会被读取 | 选择完成时,被选择的列要重新组装 INSERT/UPDATE比较麻烦 |
ORC VS Parquet
二者的文件结构图
Parquet
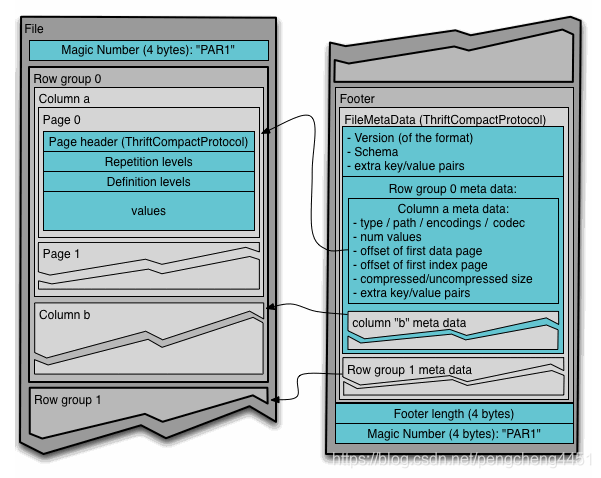
Parquet的一个独特的特点是它也可以以列式结构存储嵌套结构的数据。这意味着在Parquet文件格式中,即使是嵌套的字段也可以单独读取,而不需要读取嵌套结构中的所有字段。Parquet格式底层使用record shredding和assembly algorithm(Google Dremel论文)来实现列式存储。其文件结构主要由三块信息构成:
- Row group:多行数据的在逻辑水平方向上的分区。Row group是由数据集里每个列的列块(column chunk)构成;
- Column chunk:某个特定列的数据块。这些列块位于特定的行组中,并且保证在文件中是连续的;
- Page:列块(Column chunk)被划分为连续、紧凑的页面。这些页面共享一个共同的标题(header),在读取数据的时候可以跳过他们不感兴趣的页。
Parquet整体架构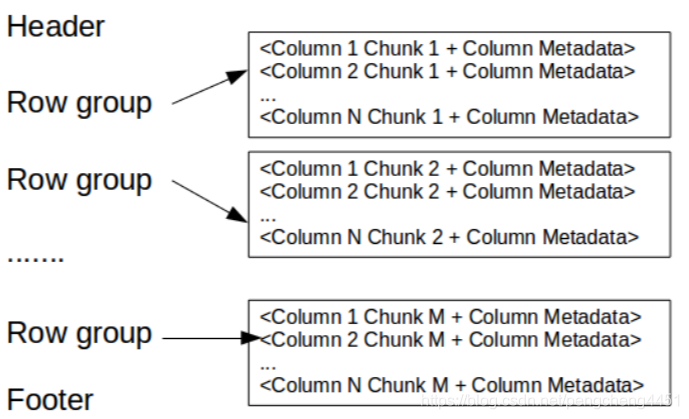
从这里可以看到,Header里面仅仅只包含一个魔术数,指明这是一个Parquet格式的文件。中间是一到多个Row group,包含了真正的文件数据信息,最后是Footer,包含了元数据信息。
Footer中有以下几项:
- 文件元数据:文件元数据包含所有列的元数据起始位置信息。当读取文件时,首先应该读取文件的元数据,从而找到感兴趣的所有列块,然后应该按顺序读取列块。另外,它还包括格式的版本版本、数据结构和一些额外的键-值对信息
- 文件元数据的大小
-
ORC
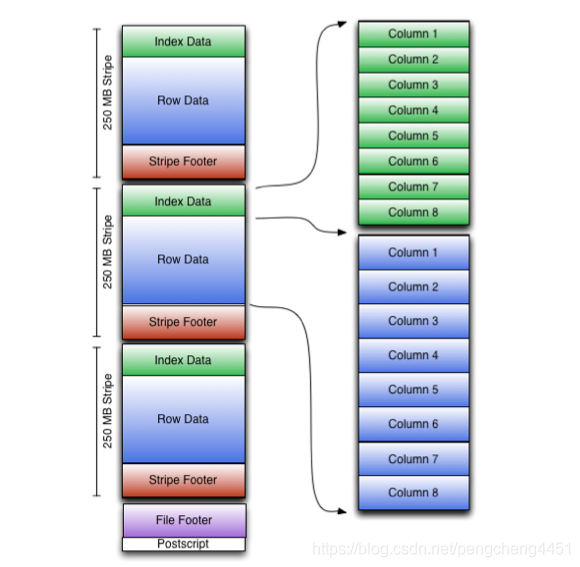
ORC文件包含称为Stripe的行数据组,File Footer的辅助信息,以及在文件的末尾,一个Postscript保存压缩参数和压缩页脚的大小。
默认的stripe大小是250mb。stripe设置的越大,则允许从HDFS读取的数据规模也越大、越高效。 File Footer包含文件中的stripe列表、每个stripe的行数和每个列的数据类型。它还包含列级聚合计数、最小值、最大值和总和。
- Stripe Footer包含一个目录的流位置。
- Row Data是真正的数据所在位置,扫描表的过程就是在发生在这里。
- Index Data包括每个列的最小值和最大值以及行在每个列中的位置。ORC stripe data仅用于stripes和row groups的选择,而不用于应答查询。
关于ORC更详细的介绍,请到该博客。选择哪一种列式存储较好
我自己也查找了很多资料,根据目前收集到的信息,综合比较来说,建议选择orc,尤其是在使用Hive做数仓的时候。如果只是单纯的使用Spark,建议用Parquet。理由如下:
- ORC有更好的压缩比,占有的空间相对较少。下图是从cloudera社区找到的,可以看出压缩比还是挺可观的,最起码可以得到一个结论:无论是使用哪一种列式存储都是比使用textfile这种格式要好,尤其是在使用Hive的时候。

- Hive和Spark的向量化读取都是支持orc的,但是Hive却不支持Parquet格式。Spark在2.3的版本之后,提供了对orc的向量化读取的支持(小声哔哔:jira上面有个issue显示hive支持对Parquet格式的vectorized reader,可是官网却说必须使用orc格式的才能使得Hive的Vectorized Query Execution生效,有点疑惑,希望有大佬回答下)。
- Hive的CBO优化器对orc支持的更好。hive的cbo优化器能够获取orc的列级别元数据信息,从而能够生成更好的执行计划。
- 嵌套格式很复杂的数据就选择Parquet,普通格式的数据多就选择orc。Parquet格式实现了Google Dremel,把数据像树一样存储,对嵌套格式的数据支持的好。
- ORC提供了ACID事务性支持。请记住,尽管orc提供事务性的功能,但是并不是为了满足OLTP的需求,主要是为了解决流式数据在Hive中的一致性问题。(注意:Spark 2系列的版本是不支持读取Hive的内部事务表,但是Hive 3的事务表又是默认的,因此需要改参数关闭事务性。目前的Spark 3系列,正在处理这个问题)
- Parquet查询性能略好于ORC。
在长时间任务执行中,当Hive查询ORC表时,GC调用频率降低了10倍。
对于orc与parquet这两种列式存储格式,网上能找到大量的介绍以及对比,此处简单总结一下:orc VS parquet:
- 默认情况下orc存储压缩率比parquet要高(压缩格式也可以更改,同样的压缩格式下,由于parquet格式数据schema更为复杂,所占空间略高。同snappy压缩格式,orc能达到1:3以上的压缩比,parquet则略低于1:3);
- 一般来说,orc读取效率比parquet要高(hadoop原生存储格式,对hive支持更友好);
- parquet支持嵌套数据格式,orc原生不支持嵌套数据类型(但可通过复杂数据类型如map
- parquet支持字段扩展,orc原生不支持字段扩展(但可手动重写读取方法实现,此处也对应第二条中的“特例”);
应用场景:
原始数据层:数据量大,统一通用化模型结构(无须嵌套数据格式,以一个String类型或map
数据应用层:数据模型直接关联到业务场景逻辑,需要字段可扩展性,需要嵌套数据结构(尽量以扁平式数据结构设计模型,少使用嵌套数据结构,可以更好的利用列式存储性能),数据量较小或不考虑数据量存储问题(已经是具体业务场景,相比原始数据,数据量应该是很小的,设计时保证“高内聚低耦合”)。—— parquet总结:
使用扁平式数据结构设计模型(表),尽量避免嵌套数据结构,可以更好的利用列式存储性能;模型设计适用于退化维度,牺牲空间设计全维度的模型来提高数据查询效率(无须再进行join关联维度表)。
*注:orc格式数据读取时,兼容历史数据字段(原生不支持字段扩展性),可先读取数据,转为json,再合并数据,即可实现数据字段的兼容(此时会拉低读取性能);
当hive加载orc格式数据源时:
此时自定义读取方法(兼容字段扩展性)OrcInputFormatNew()方法,提交jar至集群,add jar 至class path,注册udf函数。(未实践)

若有收获,就点个赞吧
0 人点赞
